Karthik Narayanan, Santosh Madiraju EEL Embedded Systems Seminar 1/41 1
|
|
|
- Felix Parsons
- 5 years ago
- Views:
Transcription


1 Karthik Narayanan, Santosh Madiraju EEL Embedded Systems Seminar 1/41 1
2 Efficient Search Space Exploration for HW-SW Partitioning Hardware/Software Codesign and System Synthesis, CODES + ISSS International Conference on Computing & Processing (Hardware/Software) 2004 Page(s): /41 2
3 Introduction HW SW partitioning key challenge in embedded systems. Issues addressed by this paper. Large Design Space utilization Scaling to Large Problem sizes. Minimizing the execution time of an application for a system with hard area constraints. 3/41 3
4 Sequential application specified as a call graph DAG. (vertices, edges). Contributions made: Updating the execution time change metric. Cost function for Simulated Annealing (SA). Implementation compared with other similar algorithms. 4/41 4
5 Attributes and Assumptions Target Architecture one SW processor and one HW unit connected by system bus. Assumptions: mutually exclusive units HW unit has no dynamic RTR capability Input DAG CG = (V,E) Each partitioning object corresponds to a vertex (vi V) Each edge (eij E )represents a call or access to a callee vj from caller vi. 5/41 5
6 Each edge eij has 2 weights (ccij, ctij) representing call count and HW-SW communication time. Each vertex vi has 3 weights (ti(s), ti(h), hi), representing execution time of a function on SW, on HW and area respectively. Partitioning attributes (Tp, Hp) representing execution time and aggregate area mapped to HW under partitioning p. 6/41 6
7 Execution time change metric computation. Execution time of vertex vi Ti(p) Ci is set of all children of vi Cdiff set of all children of vi mapped to a different partition. ~Pi represents the change in execution time when vi is moved to a different partition. 7/41 7
8 A simple call graph is as shown. Earlier approach when vi is moved, all ancestors need to be updated (all the way to the root). In figure, consider v2 to be initially in SW. Now v2 moved to HW. Execution time changes due to HW-SW communication on edges (v3,v2) and (v1, v2). It would appear that related metric for v0, v4 and v6 would need to be updated. But proved that when vi is moved, ~Pj needs to be updated on if there is an edge for (vi,vj). 8/41 8
9 Simulated Annealing Move based algorithm. Essentially tries to find an optimal solution to a hard such as partitioning. Systems with minimal energy is the optimal solution. Update the execution time for new partition by updating only the immediate neighbors of a vertex. SA algorithm rapid evaluation of search space. Indegree and outdegree of call graph is expected to be low and so average cost of a move is low. 9/41 9
10 Cost function of SA Force algorithm to accept bad moves when far away from objective Guides it to potentially interesting design points. Force the algorithm to probabilistically reject some good moves That would always be accepted by most heuristics. Cost function defined on parameters that change for a given move. Execution time: same as execution time change metric for a moved vertex HW area: (hi) for SW->HW and ( hi) for HW->SW 10/41 10
11 Figure gives an idea of all the regions a partition can occupy. A weighted cost function is formulated on which regions a partition is allowed to occupy and which regions it is rejected Dynamic Weighting factor for cost functions. To better guide the search. To avoid boundary violations 11/41 11
12 Example Partition P where few components are mapped to HW and execution time is expected to be closer to SW execution time. Cost function is biased as follows. Provide additional weightage to moves like Px where execution time deteriotes slightly but frees up a large amount of HW area. Reduce weightage on Py which improve execution time slightly but consume additional HW area Reduce moves like Pz that improve execution time slightly but free up large HW area. 12/41 12
13 Experiment Comparison made between SA and KLFM algorithm Record program execution times of SA algorithm (with the new cost function) vs. KLFM algorithm. Graphs generated by Varying indegree and outdegree Varying number of vertices Varying CCR(Communication to Computation Ratio) Varying area 13/41 13
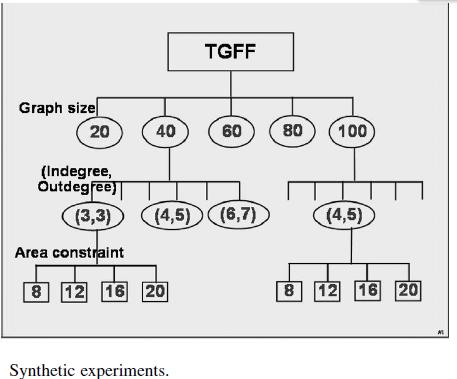
14 Data was generated for over individual runs of SA with following configurations. Max indegree and outdegree set to 4. Graph size (number of vertices) and CCR were selected accordingly. Area constraint varied as a percentage of aggregate area needed to map all the vertices to HW. Vary the max indegree and outdegree set earlier. Performance difference has been calculated by T(kl) T(sa)/T(kl)*100 14/41 14


15 Results Fig 1: v=50, CCR=0.1 Fig 2: v=50, CCR=0.3 15/41 15
16 Aggregated data Graph type BestDev (%) WorstDe v (%) Avg (%) SA rt. KLFM rt. v V V V V V
17 Conclusion Two contributions made: Updating the execution time metric New cost function. Generate partitions with execution times which are often 10% better over KLFM. Quick processing of graphs with large vertices. 17
18 Limitations and Future work: Simple additive HW area estimation model does not consider resource sharing. Can be extended to consider systems with concurrency, looking into scheduling issues during simulation. 18
19 Integrating Physical Constraints in HW-SW Partitioning for Architectures with Partial Dynamic Reconfiguration. Sudarshan Banerjee, Elaheh Bozorgzadeh, Nikil Dutt IEEE Transactions on VLSI systems, VOL.14, No. 11, Nov
20 INTRODUCTION Motivation: HW-SW Partioning for Partially Dynamic Reconfigurable Systems Major Challenges Design Space Exploration Placement Scheduling Proposed Approach Integer Linear Programming (ILP) HW-SW Partioning Heuristic based on KLFM Algorithm 20
21 INTRODUCTION Dynamic Reconfiguration Provides the ability to change the hardware configuration during application execution. Also provides means to reduce reconfiguration overhead by enabling overlap of computation with reconfiguration. Generally HW-SW partioning optimizes design latency and is followed by physical design. Challenges Placement Infeasibility Heterogeneity 21
22 Challenges Placement Infeasibility RTR capability imposes strict linear placement constraints Schedule has to be aware of the exact physical location of the task Heterogeneity FPGA consists of Heterogeneous modules.e.g.- DSP blocks, BRAM s etc.. Dedicated Resources lead to improved efficiency Area Execution time trade off 22
23 Heterogeneity Challenges Additional Challenges Feasibility Issue, exact approach ILP approach incorporates physical layout into HW-SW partitioning problem. Heuristic Approach KLFM based heuristic which considers detailed linear placement along with scheduling. Heterogeneity Arises due to considering placement and multiple task implementation 23
24 Problem Description & Target Architecture HW-SW partitioning of an application on the target architecture is considered Application is specified as a task dependency graph Each vertex represents a task Each edge represents data communicated Target Architecture Software Processor Dynamically Reconfigurable FPGA with PR Processor and FPGA communicate via a system bus Shared Memory 24
25 Architecture Memory Accesses for tasks on processor restricted to local memory Communication overhead for transfer of data incurred HW-SW communication delay should be considered FPGA Hardware unit has a set of CLB s in a 2- D matrix Specialized resource columns are distributed between CLB Reconfiguration time of a task is proportional to the number of columns occupied by the task 25
26 Constraints Device Constraints Columnar implementation of dynamic tasks Single reconfiguration process Location of specialized resource columns Each implementation of task has few parameters Execution time Area occupied in columns Reconfiguration delay 26
27 Issues with Scheduling Criticality of Linear Task Placement Each task is implemented on adjacent columns Linear Task Placement problem Finding a feasible placement on the hardware for a scheduled task under resource constraint and size Two Cases Each task occupies an identical number of columnssolution is simple Each task occupies different number of columns is solution is complex and linear placement feasibility is not guaranteed even with an exact algorithm. 27
28 Issues with Scheduling There are schedules which cannot be placed by optimal placement tools Heterogeneity Considerations: Resource columns are available at fixed locations HW execution time and area vary with placement Scheduling for configuration Prefetch Separating a task into reconfiguration and execution components Reconfiguration component is not constrained by dependencies which poses a challenge. 28
29 Approach Task Graph with n tasks and each task occupies certain number of columns 1 SW and Hw unit with m HW columns Each edge has a weight representing HW- SW comm n time Each task corresponding to a vertex has 4 weights Objective is to obtain an optimal mapping with minimal latency when FPGA has most columns available. 29
30 ILP Formulation Constraints Uniqueness Constraint Each task can start only once Processor resource Constraint Partial Dynamic Reconfiguration Constraints Each task needs at most one reconfiguration Resource Constraints on FPGA At every time step, at most single task is being reconfigured and mutual exclusion of execution and reconfiguration of every column 30
31 ILP Formulation If reconfiguration is needed for task, execution must start in the same column and only after the reconfiguration delay A task can start execution only if there are sufficient available columns to the right Interface Constraints Precedence constraints Tighter placement constraints Tighter timing constraints 31
32 Heuristic Approach KLFM based Heuristic Generic moves between tasks are defined instead of restricting to either HW or SW HW-HW and HW-SW are also taken into consideration Scheduling The schedule quality depends on priority assignment of nodes Scheduler is aware of communication costs Simultaneous scheduling and Placement For each schedulable task, compute (EST), earliest start time of computation (EFT), earliest finish time of computation Choose task that maximizes (EST, longest path, area, EFT) 32
33 Priority Function Key parameters of Priority Function are Earliest Computation Start Time (EST) Earliest Finish Time (EFT) Task Area Longest Path through the task F(EST, longest path, area, EFT) 33

34 EST Computation The EST computation, embeds the placement issues and resource constraints related to reconfiguration 34
35 Heterogeneity A simple type descriptor is added to every column in resource description. Resource queries check the type descriptor of a column while looking for available space. Some initial preprocessing is done to make searches more efficient. Worst Case Complexity Simplistic implementation of the EST computation has a worst case complexity O(n2*C) Worst Case complexity of each list scheduler is O(n4*C) The list scheduler is called O(n2) times The overall worst case complexity is O(n6C) 35

36 Experimental Setup Area and timing data for key tasks like DCT and IDCT, was obtained by synthesizing tasks under columnar placement and routing constraints on the XC2V2000 Tasks implemented on software are found to be 3-5 times slower than that on hardware 36
37 Experiments on Feasibility The Test cases are small graphs between vertices Number of columns available is approx 20-30% of total area of all tasks One unit of time is reconfiguration time for a single column 37
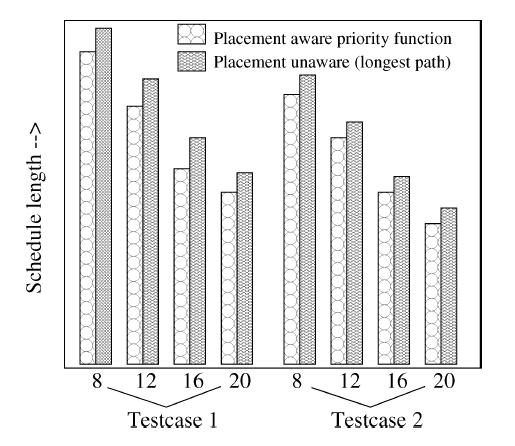
38 Experiments on Heuristic Quality 38

39 Results 39
40 Conclusion Physical and architectural constraints imposed on dynamically reconfigurable architectures by PR was explained in detail. An exact approach based on ILP was formulated Ignoring linear task placement constraints can result in schedules which are optimal but are infeasible. Simultaneous placement of tasks along with scheduling Placement aware HW-SW approach based on KLFM heuristic was proposed Heuristic simultaneously partitions, schedules and performs a linear placement of tasks on the device. A wide range of experiments were conducted which validates the approach. 40
41 Improvements & Future Work An assumption is made that there is sufficient bandwidth available to perform task concurrently which may not be true always. Though the ILP takes into consideration of heterogeneous modules, the heuristic approach considers only homogeneous modules. Due to availability of sophisticated algorithms and data structures complexity of the algorithm can be reduced further. 41
I. INTRODUCTION DYNAMIC reconfiguration, often referred to as run-time
 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 14, NO. 11, NOVEMBER 2006 1189 Integrating Physical Constraints in HW-SW Partitioning for Architectures With Partial Dynamic Reconfiguration
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 14, NO. 11, NOVEMBER 2006 1189 Integrating Physical Constraints in HW-SW Partitioning for Architectures With Partial Dynamic Reconfiguration
HW-SW partitioning for architectures with partial dynamic reconfiguration
 HW-SW partitioning for architectures with partial dynamic reconfiguration Sudarshan Banerjee Elaheh Bozorgzadeh Nikil Dutt Center for Embedded Computer Systems University of California, Irvine, CA, USA
HW-SW partitioning for architectures with partial dynamic reconfiguration Sudarshan Banerjee Elaheh Bozorgzadeh Nikil Dutt Center for Embedded Computer Systems University of California, Irvine, CA, USA
PARLGRAN: Parallelism granularity selection for scheduling task chains on dynamically reconfigurable architectures *
 PARLGRAN: Parallelism granularity selection for scheduling task chains on dynamically reconfigurable architectures * Sudarshan Banerjee, Elaheh Bozorgzadeh, Nikil Dutt Center for Embedded Computer Systems
PARLGRAN: Parallelism granularity selection for scheduling task chains on dynamically reconfigurable architectures * Sudarshan Banerjee, Elaheh Bozorgzadeh, Nikil Dutt Center for Embedded Computer Systems
Physically-Aware HW-SW Partitioning for Reconfigurable Architectures with Partial Dynamic Reconfiguration
 Physically-Aware HW-SW Partitioning for Reconfigurable Architectures with Partial Dynamic Reconfiguration 0. Sudarshan Banerjee Elaheh Bozorgzadeh Nikil Dutt Center for Embedded Computer Systems Uniersity
Physically-Aware HW-SW Partitioning for Reconfigurable Architectures with Partial Dynamic Reconfiguration 0. Sudarshan Banerjee Elaheh Bozorgzadeh Nikil Dutt Center for Embedded Computer Systems Uniersity
A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs
 Politecnico di Milano & EPFL A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs Vincenzo Rana, Ivan Beretta, Donatella Sciuto Donatella Sciuto sciuto@elet.polimi.it Introduction
Politecnico di Milano & EPFL A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs Vincenzo Rana, Ivan Beretta, Donatella Sciuto Donatella Sciuto sciuto@elet.polimi.it Introduction
A New Approach to Execution Time Estimations in a Hardware/Software Codesign Environment
 A New Approach to Execution Time Estimations in a Hardware/Software Codesign Environment JAVIER RESANO, ELENA PEREZ, DANIEL MOZOS, HORTENSIA MECHA, JULIO SEPTIÉN Departamento de Arquitectura de Computadores
A New Approach to Execution Time Estimations in a Hardware/Software Codesign Environment JAVIER RESANO, ELENA PEREZ, DANIEL MOZOS, HORTENSIA MECHA, JULIO SEPTIÉN Departamento de Arquitectura de Computadores
Efficient Search Space Exploration for W
 Efficient Search Space Exploration for W SW Partitioningt Sudarshan Banerjee Nikil Dutt Center for Embedded Computer Systems University of California, Irvine, CA, USA banerjeeqics.uci.edu duttqics.uci.edu
Efficient Search Space Exploration for W SW Partitioningt Sudarshan Banerjee Nikil Dutt Center for Embedded Computer Systems University of California, Irvine, CA, USA banerjeeqics.uci.edu duttqics.uci.edu
Co-synthesis and Accelerator based Embedded System Design
 Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
A Duplication Based List Scheduling Genetic Algorithm for Scheduling Task on Parallel Processors
 A Duplication Based List Scheduling Genetic Algorithm for Scheduling Task on Parallel Processors Dr. Gurvinder Singh Department of Computer Science & Engineering, Guru Nanak Dev University, Amritsar- 143001,
A Duplication Based List Scheduling Genetic Algorithm for Scheduling Task on Parallel Processors Dr. Gurvinder Singh Department of Computer Science & Engineering, Guru Nanak Dev University, Amritsar- 143001,
Ant Colony Optimization for Mapping, Scheduling and Placing in Reconfigurable Systems
 Ant Colony Optimization for Mapping, Scheduling and Placing in Reconfigurable Systems Fabrizio Ferrandi, Pier Luca Lanzi, Christian Pilato, Donatella Sciuto Politecnico di Milano - DEIB Milano, Italy {ferrandi,lanzi,pilato,sciuto}@elet.polimi.it
Ant Colony Optimization for Mapping, Scheduling and Placing in Reconfigurable Systems Fabrizio Ferrandi, Pier Luca Lanzi, Christian Pilato, Donatella Sciuto Politecnico di Milano - DEIB Milano, Italy {ferrandi,lanzi,pilato,sciuto}@elet.polimi.it
Hardware/Software Partitioning and Scheduling of Embedded Systems
 Hardware/Software Partitioning and Scheduling of Embedded Systems Andrew Morton PhD Thesis Defence Electrical and Computer Engineering University of Waterloo January 13, 2005 Outline 1. Thesis Statement
Hardware/Software Partitioning and Scheduling of Embedded Systems Andrew Morton PhD Thesis Defence Electrical and Computer Engineering University of Waterloo January 13, 2005 Outline 1. Thesis Statement
Introduction to Real-Time Systems ECE 397-1
 Introduction to Real-Time Systems ECE 97-1 Northwestern University Department of Computer Science Department of Electrical and Computer Engineering Teachers: Robert Dick Peter Dinda Office: L477 Tech 8,
Introduction to Real-Time Systems ECE 97-1 Northwestern University Department of Computer Science Department of Electrical and Computer Engineering Teachers: Robert Dick Peter Dinda Office: L477 Tech 8,
Hardware-Software Codesign
 Hardware-Software Codesign 4. System Partitioning Lothar Thiele 4-1 System Design specification system synthesis estimation SW-compilation intellectual prop. code instruction set HW-synthesis intellectual
Hardware-Software Codesign 4. System Partitioning Lothar Thiele 4-1 System Design specification system synthesis estimation SW-compilation intellectual prop. code instruction set HW-synthesis intellectual
FPGA. Agenda 11/05/2016. Scheduling tasks on Reconfigurable FPGA architectures. Definition. Overview. Characteristics of the CLB.
 Agenda The topics that will be addressed are: Scheduling tasks on Reconfigurable FPGA architectures Mauro Marinoni ReTiS Lab, TeCIP Institute Scuola superiore Sant Anna - Pisa Overview on basic characteristics
Agenda The topics that will be addressed are: Scheduling tasks on Reconfigurable FPGA architectures Mauro Marinoni ReTiS Lab, TeCIP Institute Scuola superiore Sant Anna - Pisa Overview on basic characteristics
Homework index. Processing resource description. Goals for lecture. Communication resource description. Graph extensions. Problem definition
 Introduction to Real-Time Systems ECE 97-1 Homework index 1 Reading assignment.............. 4 Northwestern University Department of Computer Science Department of Electrical and Computer Engineering Teachers:
Introduction to Real-Time Systems ECE 97-1 Homework index 1 Reading assignment.............. 4 Northwestern University Department of Computer Science Department of Electrical and Computer Engineering Teachers:
Chapter 2 Designing Crossbar Based Systems
 Chapter 2 Designing Crossbar Based Systems Over the last decade, the communication architecture of SoCs has evolved from single shared bus systems to multi-bus systems. Today, state-of-the-art bus based
Chapter 2 Designing Crossbar Based Systems Over the last decade, the communication architecture of SoCs has evolved from single shared bus systems to multi-bus systems. Today, state-of-the-art bus based
Placement Algorithm for FPGA Circuits
 Placement Algorithm for FPGA Circuits ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Placement Algorithm for FPGA Circuits ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Bus Matrix Synthesis Based On Steiner Graphs For Power Efficient System On Chip Communications
 Bus Matrix Synthesis Based On Steiner Graphs For Power Efficient System On Chip Communications M.Jasmin Assistant Professor, Department of ECE, Bharath University Chennai 600073, India ABSTRACT: Power
Bus Matrix Synthesis Based On Steiner Graphs For Power Efficient System On Chip Communications M.Jasmin Assistant Professor, Department of ECE, Bharath University Chennai 600073, India ABSTRACT: Power
Practical Session No. 12 Graphs, BFS, DFS, Topological sort
 Practical Session No. 12 Graphs, BFS, DFS, Topological sort Graphs and BFS Graph G = (V, E) Graph Representations (V G ) v1 v n V(G) = V - Set of all vertices in G E(G) = E - Set of all edges (u,v) in
Practical Session No. 12 Graphs, BFS, DFS, Topological sort Graphs and BFS Graph G = (V, E) Graph Representations (V G ) v1 v n V(G) = V - Set of all vertices in G E(G) = E - Set of all edges (u,v) in
Strategies for Replica Placement in Tree Networks
 Strategies for Replica Placement in Tree Networks http://graal.ens-lyon.fr/~lmarchal/scheduling/ 2 avril 2009 Introduction and motivation Replica placement in tree networks Set of clients (tree leaves):
Strategies for Replica Placement in Tree Networks http://graal.ens-lyon.fr/~lmarchal/scheduling/ 2 avril 2009 Introduction and motivation Replica placement in tree networks Set of clients (tree leaves):
Hardware/Software Codesign
 Hardware/Software Codesign 3. Partitioning Marco Platzner Lothar Thiele by the authors 1 Overview A Model for System Synthesis The Partitioning Problem General Partitioning Methods HW/SW-Partitioning Methods
Hardware/Software Codesign 3. Partitioning Marco Platzner Lothar Thiele by the authors 1 Overview A Model for System Synthesis The Partitioning Problem General Partitioning Methods HW/SW-Partitioning Methods
Unit 2: High-Level Synthesis
 Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Optimization Techniques for Design Space Exploration
 0-0-7 Optimization Techniques for Design Space Exploration Zebo Peng Embedded Systems Laboratory (ESLAB) Linköping University Outline Optimization problems in ERT system design Heuristic techniques Simulated
0-0-7 Optimization Techniques for Design Space Exploration Zebo Peng Embedded Systems Laboratory (ESLAB) Linköping University Outline Optimization problems in ERT system design Heuristic techniques Simulated
Basic Idea. The routing problem is typically solved using a twostep
 Global Routing Basic Idea The routing problem is typically solved using a twostep approach: Global Routing Define the routing regions. Generate a tentative route for each net. Each net is assigned to a
Global Routing Basic Idea The routing problem is typically solved using a twostep approach: Global Routing Define the routing regions. Generate a tentative route for each net. Each net is assigned to a
A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning
 A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning By: Roman Lysecky and Frank Vahid Presented By: Anton Kiriwas Disclaimer This specific
A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning By: Roman Lysecky and Frank Vahid Presented By: Anton Kiriwas Disclaimer This specific
Scheduling with Bus Access Optimization for Distributed Embedded Systems
 472 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 8, NO. 5, OCTOBER 2000 Scheduling with Bus Access Optimization for Distributed Embedded Systems Petru Eles, Member, IEEE, Alex
472 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 8, NO. 5, OCTOBER 2000 Scheduling with Bus Access Optimization for Distributed Embedded Systems Petru Eles, Member, IEEE, Alex
A Level-wise Priority Based Task Scheduling for Heterogeneous Systems
 International Journal of Information and Education Technology, Vol., No. 5, December A Level-wise Priority Based Task Scheduling for Heterogeneous Systems R. Eswari and S. Nickolas, Member IACSIT Abstract
International Journal of Information and Education Technology, Vol., No. 5, December A Level-wise Priority Based Task Scheduling for Heterogeneous Systems R. Eswari and S. Nickolas, Member IACSIT Abstract
EE/CSCI 451 Midterm 1
 EE/CSCI 451 Midterm 1 Spring 2018 Instructor: Xuehai Qian Friday: 02/26/2018 Problem # Topic Points Score 1 Definitions 20 2 Memory System Performance 10 3 Cache Performance 10 4 Shared Memory Programming
EE/CSCI 451 Midterm 1 Spring 2018 Instructor: Xuehai Qian Friday: 02/26/2018 Problem # Topic Points Score 1 Definitions 20 2 Memory System Performance 10 3 Cache Performance 10 4 Shared Memory Programming
HW SW Partitioning. Reading. Hardware/software partitioning. Hardware/Software Codesign. CS4272: HW SW Codesign
 CS4272: HW SW Codesign HW SW Partitioning Abhik Roychoudhury School of Computing National University of Singapore Reading Section 5.3 of textbook Embedded System Design Peter Marwedel Also must read Hardware/software
CS4272: HW SW Codesign HW SW Partitioning Abhik Roychoudhury School of Computing National University of Singapore Reading Section 5.3 of textbook Embedded System Design Peter Marwedel Also must read Hardware/software
Spiral 2-8. Cell Layout
 2-8.1 Spiral 2-8 Cell Layout 2-8.2 Learning Outcomes I understand how a digital circuit is composed of layers of materials forming transistors and wires I understand how each layer is expressed as geometric
2-8.1 Spiral 2-8 Cell Layout 2-8.2 Learning Outcomes I understand how a digital circuit is composed of layers of materials forming transistors and wires I understand how each layer is expressed as geometric
Enhancing Resource Utilization with Design Alternatives in Runtime Reconfigurable Systems
 Enhancing Resource Utilization with Design Alternatives in Runtime Reconfigurable Systems Alexander Wold, Dirk Koch, Jim Torresen Department of Informatics, University of Oslo, Norway Email: {alexawo,koch,jimtoer}@ifi.uio.no
Enhancing Resource Utilization with Design Alternatives in Runtime Reconfigurable Systems Alexander Wold, Dirk Koch, Jim Torresen Department of Informatics, University of Oslo, Norway Email: {alexawo,koch,jimtoer}@ifi.uio.no
Hardware-Software Codesign
 Hardware-Software Codesign 8. Performance Estimation Lothar Thiele 8-1 System Design specification system synthesis estimation -compilation intellectual prop. code instruction set HW-synthesis intellectual
Hardware-Software Codesign 8. Performance Estimation Lothar Thiele 8-1 System Design specification system synthesis estimation -compilation intellectual prop. code instruction set HW-synthesis intellectual
Soft-Core Embedded Processor-Based Built-In Self- Test of FPGAs: A Case Study
 Soft-Core Embedded Processor-Based Built-In Self- Test of FPGAs: A Case Study Bradley F. Dutton, Graduate Student Member, IEEE, and Charles E. Stroud, Fellow, IEEE Dept. of Electrical and Computer Engineering
Soft-Core Embedded Processor-Based Built-In Self- Test of FPGAs: A Case Study Bradley F. Dutton, Graduate Student Member, IEEE, and Charles E. Stroud, Fellow, IEEE Dept. of Electrical and Computer Engineering
OPTICAL NETWORKS. Virtual Topology Design. A. Gençata İTÜ, Dept. Computer Engineering 2005
 OPTICAL NETWORKS Virtual Topology Design A. Gençata İTÜ, Dept. Computer Engineering 2005 Virtual Topology A lightpath provides single-hop communication between any two nodes, which could be far apart in
OPTICAL NETWORKS Virtual Topology Design A. Gençata İTÜ, Dept. Computer Engineering 2005 Virtual Topology A lightpath provides single-hop communication between any two nodes, which could be far apart in
Genetic Algorithm for Circuit Partitioning
 Genetic Algorithm for Circuit Partitioning ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Genetic Algorithm for Circuit Partitioning ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Floorplan and Power/Ground Network Co-Synthesis for Fast Design Convergence
 Floorplan and Power/Ground Network Co-Synthesis for Fast Design Convergence Chen-Wei Liu 12 and Yao-Wen Chang 2 1 Synopsys Taiwan Limited 2 Department of Electrical Engineering National Taiwan University,
Floorplan and Power/Ground Network Co-Synthesis for Fast Design Convergence Chen-Wei Liu 12 and Yao-Wen Chang 2 1 Synopsys Taiwan Limited 2 Department of Electrical Engineering National Taiwan University,
Effective Memory Access Optimization by Memory Delay Modeling, Memory Allocation, and Slack Time Management
 International Journal of Computer Theory and Engineering, Vol., No., December 01 Effective Memory Optimization by Memory Delay Modeling, Memory Allocation, and Slack Time Management Sultan Daud Khan, Member,
International Journal of Computer Theory and Engineering, Vol., No., December 01 Effective Memory Optimization by Memory Delay Modeling, Memory Allocation, and Slack Time Management Sultan Daud Khan, Member,
Parallel Simulated Annealing for VLSI Cell Placement Problem
 Parallel Simulated Annealing for VLSI Cell Placement Problem Atanu Roy Karthik Ganesan Pillai Department Computer Science Montana State University Bozeman {atanu.roy, k.ganeshanpillai}@cs.montana.edu VLSI
Parallel Simulated Annealing for VLSI Cell Placement Problem Atanu Roy Karthik Ganesan Pillai Department Computer Science Montana State University Bozeman {atanu.roy, k.ganeshanpillai}@cs.montana.edu VLSI
Using Dynamic Voltage Scaling to Reduce the Configuration Energy of Run Time Reconfigurable Devices
 Using Dynamic Voltage Scaling to Reduce the Configuration Energy of Run Time Reconfigurable Devices Yang Qu 1, Juha-Pekka Soininen 1 and Jari Nurmi 2 1 Technical Research Centre of Finland (VTT), Kaitoväylä
Using Dynamic Voltage Scaling to Reduce the Configuration Energy of Run Time Reconfigurable Devices Yang Qu 1, Juha-Pekka Soininen 1 and Jari Nurmi 2 1 Technical Research Centre of Finland (VTT), Kaitoväylä
On Cluster Resource Allocation for Multiple Parallel Task Graphs
 On Cluster Resource Allocation for Multiple Parallel Task Graphs Henri Casanova Frédéric Desprez Frédéric Suter University of Hawai i at Manoa INRIA - LIP - ENS Lyon IN2P3 Computing Center, CNRS / IN2P3
On Cluster Resource Allocation for Multiple Parallel Task Graphs Henri Casanova Frédéric Desprez Frédéric Suter University of Hawai i at Manoa INRIA - LIP - ENS Lyon IN2P3 Computing Center, CNRS / IN2P3
Modeling Arbitrator Delay-Area Dependencies in Customizable Instruction Set Processors
 Modeling Arbitrator Delay-Area Dependencies in Customizable Instruction Set Processors Siew-Kei Lam Centre for High Performance Embedded Systems, Nanyang Technological University, Singapore (assklam@ntu.edu.sg)
Modeling Arbitrator Delay-Area Dependencies in Customizable Instruction Set Processors Siew-Kei Lam Centre for High Performance Embedded Systems, Nanyang Technological University, Singapore (assklam@ntu.edu.sg)
Multiobjective Reconfiguration-Aware Scheduling. on FPGA-Based Heterogeneous Architectures
 Multiobjective Reconfiguration-Aware Scheduling on FPGA-Based Heterogeneous Architectures BY ENRICO ARMENIO DEIANA B.S., Politecnico di Milano, Milan, Italy, September 2011 THESIS Submitted as partial
Multiobjective Reconfiguration-Aware Scheduling on FPGA-Based Heterogeneous Architectures BY ENRICO ARMENIO DEIANA B.S., Politecnico di Milano, Milan, Italy, September 2011 THESIS Submitted as partial
Resource-Efficient Scheduling for Partially-Reconfigurable FPGAbased
 Resource-Efficient Scheduling for Partially-Reconfigurable FPGAbased Systems Andrea Purgato: andrea.purgato@mail.polimi.it Davide Tantillo: davide.tantillo@mail.polimi.it Marco Rabozzi: marco.rabozzi@polimi.it
Resource-Efficient Scheduling for Partially-Reconfigurable FPGAbased Systems Andrea Purgato: andrea.purgato@mail.polimi.it Davide Tantillo: davide.tantillo@mail.polimi.it Marco Rabozzi: marco.rabozzi@polimi.it
EEL 4783: HDL in Digital System Design
 EEL 4783: HDL in Digital System Design Lecture 13: Floorplanning Prof. Mingjie Lin Topics Partitioning a design with a floorplan. Performance improvements by constraining the critical path. Floorplanning
EEL 4783: HDL in Digital System Design Lecture 13: Floorplanning Prof. Mingjie Lin Topics Partitioning a design with a floorplan. Performance improvements by constraining the critical path. Floorplanning
A Reconfigurable Multifunction Computing Cache Architecture
 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 9, NO. 4, AUGUST 2001 509 A Reconfigurable Multifunction Computing Cache Architecture Huesung Kim, Student Member, IEEE, Arun K. Somani,
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 9, NO. 4, AUGUST 2001 509 A Reconfigurable Multifunction Computing Cache Architecture Huesung Kim, Student Member, IEEE, Arun K. Somani,
EEL 4783: HDL in Digital System Design
 EEL 4783: HDL in Digital System Design Lecture 9: Coding for Synthesis (cont.) Prof. Mingjie Lin 1 Code Principles Use blocking assignments to model combinatorial logic. Use nonblocking assignments to
EEL 4783: HDL in Digital System Design Lecture 9: Coding for Synthesis (cont.) Prof. Mingjie Lin 1 Code Principles Use blocking assignments to model combinatorial logic. Use nonblocking assignments to
An Automated Scheduling and Partitioning Algorithm for Scalable Reconfigurable Computing Systems
 An Automated Scheduling and Partitioning Algorithm for Scalable Reconfigurable Computing Systems Casey Reardon, Alan D. George, Greg Stitt, and Herman Lam NSF Center for High-Performance Reconfigurable
An Automated Scheduling and Partitioning Algorithm for Scalable Reconfigurable Computing Systems Casey Reardon, Alan D. George, Greg Stitt, and Herman Lam NSF Center for High-Performance Reconfigurable
Bi-Objective Optimization for Scheduling in Heterogeneous Computing Systems
 Bi-Objective Optimization for Scheduling in Heterogeneous Computing Systems Tony Maciejewski, Kyle Tarplee, Ryan Friese, and Howard Jay Siegel Department of Electrical and Computer Engineering Colorado
Bi-Objective Optimization for Scheduling in Heterogeneous Computing Systems Tony Maciejewski, Kyle Tarplee, Ryan Friese, and Howard Jay Siegel Department of Electrical and Computer Engineering Colorado
Controlled duplication for scheduling real-time precedence tasks on heterogeneous multiprocessors
 Controlled duplication for scheduling real-time precedence tasks on heterogeneous multiprocessors Jagpreet Singh* and Nitin Auluck Department of Computer Science & Engineering Indian Institute of Technology,
Controlled duplication for scheduling real-time precedence tasks on heterogeneous multiprocessors Jagpreet Singh* and Nitin Auluck Department of Computer Science & Engineering Indian Institute of Technology,
Chapter 5 Global Routing
 Chapter 5 Global Routing 5. Introduction 5.2 Terminology and Definitions 5.3 Optimization Goals 5. Representations of Routing Regions 5.5 The Global Routing Flow 5.6 Single-Net Routing 5.6. Rectilinear
Chapter 5 Global Routing 5. Introduction 5.2 Terminology and Definitions 5.3 Optimization Goals 5. Representations of Routing Regions 5.5 The Global Routing Flow 5.6 Single-Net Routing 5.6. Rectilinear
Buffer Minimization in Pipelined SDF Scheduling on Multi-Core Platforms
 Buffer Minimization in Pipelined SDF Scheduling on Multi-Core Platforms Yuankai Chen and Hai Zhou Electrical Engineering and Computer Science, Northwestern University, U.S.A. Abstract With the increasing
Buffer Minimization in Pipelined SDF Scheduling on Multi-Core Platforms Yuankai Chen and Hai Zhou Electrical Engineering and Computer Science, Northwestern University, U.S.A. Abstract With the increasing
Applications to MPSoCs
 3 rd Workshop on Mapping of Applications to MPSoCs A Design Exploration Framework for Mapping and Scheduling onto Heterogeneous MPSoCs Christian Pilato, Fabrizio Ferrandi, Donatella Sciuto Dipartimento
3 rd Workshop on Mapping of Applications to MPSoCs A Design Exploration Framework for Mapping and Scheduling onto Heterogeneous MPSoCs Christian Pilato, Fabrizio Ferrandi, Donatella Sciuto Dipartimento
/ Approximation Algorithms Lecturer: Michael Dinitz Topic: Linear Programming Date: 2/24/15 Scribe: Runze Tang
 600.469 / 600.669 Approximation Algorithms Lecturer: Michael Dinitz Topic: Linear Programming Date: 2/24/15 Scribe: Runze Tang 9.1 Linear Programming Suppose we are trying to approximate a minimization
600.469 / 600.669 Approximation Algorithms Lecturer: Michael Dinitz Topic: Linear Programming Date: 2/24/15 Scribe: Runze Tang 9.1 Linear Programming Suppose we are trying to approximate a minimization
Hardware-Software Codesign. 1. Introduction
 Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
Approximately Uniform Random Sampling in Sensor Networks
 Approximately Uniform Random Sampling in Sensor Networks Boulat A. Bash, John W. Byers and Jeffrey Considine Motivation Data aggregation Approximations to COUNT, SUM, AVG, MEDIAN Existing work does not
Approximately Uniform Random Sampling in Sensor Networks Boulat A. Bash, John W. Byers and Jeffrey Considine Motivation Data aggregation Approximations to COUNT, SUM, AVG, MEDIAN Existing work does not
Minje Jun. Eui-Young Chung
 Mixed Integer Linear Programming-based g Optimal Topology Synthesis of Cascaded Crossbar Switches Minje Jun Sungjoo Yoo Eui-Young Chung Contents Motivation Related Works Overview of the Method Problem
Mixed Integer Linear Programming-based g Optimal Topology Synthesis of Cascaded Crossbar Switches Minje Jun Sungjoo Yoo Eui-Young Chung Contents Motivation Related Works Overview of the Method Problem
A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms
 A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern California Los Angeles, California,
A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern California Los Angeles, California,
Graphs. Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1
 Graphs Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1 Warmup Discuss with your neighbors: Come up with as many kinds of relational data as you can (data that can be represented with a graph).
Graphs Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1 Warmup Discuss with your neighbors: Come up with as many kinds of relational data as you can (data that can be represented with a graph).
ii Copyright c Harikrishna Samala 2009 All Rights Reserved
 ii Copyright c Harikrishna Samala 2009 All Rights Reserved iii Abstract Methodology to Derive Resource Aware Context Adaptable Architectures for Field Programmable Gate Arrays by Harikrishna Samala, Master
ii Copyright c Harikrishna Samala 2009 All Rights Reserved iii Abstract Methodology to Derive Resource Aware Context Adaptable Architectures for Field Programmable Gate Arrays by Harikrishna Samala, Master
High-Level Synthesis (HLS)
") Course contents Unit 11: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 11 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Course contents Unit 11: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 11 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
SCHEDULING II Giovanni De Micheli Stanford University
 SCHEDULING II Giovanni De Micheli Stanford University Scheduling under resource constraints Simplified models: Hu's algorithm. Heuristic algorithms: List scheduling. Force-directed scheduling. Hu's algorithm
SCHEDULING II Giovanni De Micheli Stanford University Scheduling under resource constraints Simplified models: Hu's algorithm. Heuristic algorithms: List scheduling. Force-directed scheduling. Hu's algorithm
A Hardware Task-Graph Scheduler for Reconfigurable Multi-tasking Systems
 A Hardware Task-Graph Scheduler for Reconfigurable Multi-tasking Systems Abstract Reconfigurable hardware can be used to build a multitasking system where tasks are assigned to HW resources at run-time
A Hardware Task-Graph Scheduler for Reconfigurable Multi-tasking Systems Abstract Reconfigurable hardware can be used to build a multitasking system where tasks are assigned to HW resources at run-time
COE 561 Digital System Design & Synthesis Introduction
 1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
A Low Energy Clustered Instruction Memory Hierarchy for Long Instruction Word Processors
 A Low Energy Clustered Instruction Memory Hierarchy for Long Instruction Word Processors Murali Jayapala 1, Francisco Barat 1, Pieter Op de Beeck 1, Francky Catthoor 2, Geert Deconinck 1 and Henk Corporaal
A Low Energy Clustered Instruction Memory Hierarchy for Long Instruction Word Processors Murali Jayapala 1, Francisco Barat 1, Pieter Op de Beeck 1, Francky Catthoor 2, Geert Deconinck 1 and Henk Corporaal
Lecture 7: Introduction to Co-synthesis Algorithms
 Design & Co-design of Embedded Systems Lecture 7: Introduction to Co-synthesis Algorithms Sharif University of Technology Computer Engineering Dept. Winter-Spring 2008 Mehdi Modarressi Topics for today
Design & Co-design of Embedded Systems Lecture 7: Introduction to Co-synthesis Algorithms Sharif University of Technology Computer Engineering Dept. Winter-Spring 2008 Mehdi Modarressi Topics for today
A Lost Cycles Analysis for Performance Prediction using High-Level Synthesis
 A Lost Cycles Analysis for Performance Prediction using High-Level Synthesis Bruno da Silva, Jan Lemeire, An Braeken, and Abdellah Touhafi Vrije Universiteit Brussel (VUB), INDI and ETRO department, Brussels,
A Lost Cycles Analysis for Performance Prediction using High-Level Synthesis Bruno da Silva, Jan Lemeire, An Braeken, and Abdellah Touhafi Vrije Universiteit Brussel (VUB), INDI and ETRO department, Brussels,
Hardware Software Partitioning of Multifunction Systems
 Hardware Software Partitioning of Multifunction Systems Abhijit Prasad Wangqi Qiu Rabi Mahapatra Department of Computer Science Texas A&M University College Station, TX 77843-3112 Email: {abhijitp,wangqiq,rabi}@cs.tamu.edu
Hardware Software Partitioning of Multifunction Systems Abhijit Prasad Wangqi Qiu Rabi Mahapatra Department of Computer Science Texas A&M University College Station, TX 77843-3112 Email: {abhijitp,wangqiq,rabi}@cs.tamu.edu
COMPLEX embedded systems with multiple processing
 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 12, NO. 8, AUGUST 2004 793 Scheduling and Mapping in an Incremental Design Methodology for Distributed Real-Time Embedded Systems
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 12, NO. 8, AUGUST 2004 793 Scheduling and Mapping in an Incremental Design Methodology for Distributed Real-Time Embedded Systems
Optimizing Management Functions in Distributed Systems
 Journal of Network and Systems Management, Vol. 10, No. 4, December 2002 ( C 2002) Optimizing Management Functions in Distributed Systems Hasina Abdu, 1,3 Hanan Lutfiyya, 2 and Michael A. Bauer 2 With
Journal of Network and Systems Management, Vol. 10, No. 4, December 2002 ( C 2002) Optimizing Management Functions in Distributed Systems Hasina Abdu, 1,3 Hanan Lutfiyya, 2 and Michael A. Bauer 2 With
Fast Timing Closure by Interconnect Criticality Driven Delay Relaxation
 Fast Timing Closure by Interconnect Criticality Driven Delay Relaxation Love Singhal and Elaheh Bozorgzadeh Donald Bren School of Information and Computer Sciences University of California, Irvine, California
Fast Timing Closure by Interconnect Criticality Driven Delay Relaxation Love Singhal and Elaheh Bozorgzadeh Donald Bren School of Information and Computer Sciences University of California, Irvine, California
Hardware/Software Codesign
 Hardware/Software Codesign SS 2016 Prof. Dr. Christian Plessl High-Performance IT Systems group University of Paderborn Version 2.2.0 2016-04-08 how to design a "digital TV set top box" Motivating Example
Hardware/Software Codesign SS 2016 Prof. Dr. Christian Plessl High-Performance IT Systems group University of Paderborn Version 2.2.0 2016-04-08 how to design a "digital TV set top box" Motivating Example
Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator
 Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator Stanley Bak Abstract Network algorithms are deployed on large networks, and proper algorithm evaluation is necessary to avoid
Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator Stanley Bak Abstract Network algorithms are deployed on large networks, and proper algorithm evaluation is necessary to avoid
asoc: : A Scalable On-Chip Communication Architecture
 asoc: : A Scalable On-Chip Communication Architecture Russell Tessier, Jian Liang,, Andrew Laffely,, and Wayne Burleson University of Massachusetts, Amherst Reconfigurable Computing Group Supported by
asoc: : A Scalable On-Chip Communication Architecture Russell Tessier, Jian Liang,, Andrew Laffely,, and Wayne Burleson University of Massachusetts, Amherst Reconfigurable Computing Group Supported by
Empirical analysis of procedures that schedule unit length jobs subject to precedence constraints forming in- and out-stars
 Empirical analysis of procedures that schedule unit length jobs subject to precedence constraints forming in- and out-stars Samuel Tigistu Feder * Abstract This paper addresses the problem of scheduling
Empirical analysis of procedures that schedule unit length jobs subject to precedence constraints forming in- and out-stars Samuel Tigistu Feder * Abstract This paper addresses the problem of scheduling
Efficient Microarchitecture Modeling and Path Analysis for Real-Time Software. Yau-Tsun Steven Li Sharad Malik Andrew Wolfe
 Efficient Microarchitecture Modeling and Path Analysis for Real-Time Software Yau-Tsun Steven Li Sharad Malik Andrew Wolfe 1 Introduction Paper examines the problem of determining the bound on the worst
Efficient Microarchitecture Modeling and Path Analysis for Real-Time Software Yau-Tsun Steven Li Sharad Malik Andrew Wolfe 1 Introduction Paper examines the problem of determining the bound on the worst
Static Multiprocessor Scheduling of Periodic Real-Time Tasks with Precedence Constraints and Communication Costs
 Static Multiprocessor Scheduling of Periodic Real-Time Tasks with Precedence Constraints and Communication Costs Stefan Riinngren and Behrooz A. Shirazi Department of Computer Science and Engineering The
Static Multiprocessor Scheduling of Periodic Real-Time Tasks with Precedence Constraints and Communication Costs Stefan Riinngren and Behrooz A. Shirazi Department of Computer Science and Engineering The
1. INTRODUCTION AND MOTIVATION
 An Automated Hardware/Software Co-Design Flow for Partially Reconfigurable FPGAs Shaon Yousuf* and Ann Gordon-Ross *Currently affiliated with Intel Corporation NSF Center for High-Performance Reconfigurable
An Automated Hardware/Software Co-Design Flow for Partially Reconfigurable FPGAs Shaon Yousuf* and Ann Gordon-Ross *Currently affiliated with Intel Corporation NSF Center for High-Performance Reconfigurable
Optimization of Task Scheduling and Memory Partitioning for Multiprocessor System on Chip
 Optimization of Task Scheduling and Memory Partitioning for Multiprocessor System on Chip 1 Mythili.R, 2 Mugilan.D 1 PG Student, Department of Electronics and Communication K S Rangasamy College Of Technology,
Optimization of Task Scheduling and Memory Partitioning for Multiprocessor System on Chip 1 Mythili.R, 2 Mugilan.D 1 PG Student, Department of Electronics and Communication K S Rangasamy College Of Technology,
Seminar on. A Coarse-Grain Parallel Formulation of Multilevel k-way Graph Partitioning Algorithm
 Seminar on A Coarse-Grain Parallel Formulation of Multilevel k-way Graph Partitioning Algorithm Mohammad Iftakher Uddin & Mohammad Mahfuzur Rahman Matrikel Nr: 9003357 Matrikel Nr : 9003358 Masters of
Seminar on A Coarse-Grain Parallel Formulation of Multilevel k-way Graph Partitioning Algorithm Mohammad Iftakher Uddin & Mohammad Mahfuzur Rahman Matrikel Nr: 9003357 Matrikel Nr : 9003358 Masters of
SAFETY-CRITICAL applications have to function correctly
 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 17, NO. 3, MARCH 2009 389 Design Optimization of Time- and Cost-Constrained Fault-Tolerant Embedded Systems With Checkpointing and
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 17, NO. 3, MARCH 2009 389 Design Optimization of Time- and Cost-Constrained Fault-Tolerant Embedded Systems With Checkpointing and
Optimal Implementation of Simulink Models on Multicore Architectures with Partitioned Fixed Priority Scheduling
 The 39th IEEE Real-Time Systems Symposium (RTSS 18) Optimal Implementation of Simulink Models on Multicore Architectures with Partitioned Fixed Priority Scheduling Shamit Bansal, Yecheng Zhao, Haibo Zeng,
The 39th IEEE Real-Time Systems Symposium (RTSS 18) Optimal Implementation of Simulink Models on Multicore Architectures with Partitioned Fixed Priority Scheduling Shamit Bansal, Yecheng Zhao, Haibo Zeng,
8ns. 8ns. 16ns. 10ns COUT S3 COUT S3 A3 B3 A2 B2 A1 B1 B0 2 B0 CIN CIN COUT S3 A3 B3 A2 B2 A1 B1 A0 B0 CIN S0 S1 S2 S3 COUT CIN 2 A0 B0 A2 _ A1 B1
 Delay Abstraction in Combinational Logic Circuits Noriya Kobayashi Sharad Malik C&C Research Laboratories Department of Electrical Engineering NEC Corp. Princeton University Miyamae-ku, Kawasaki Japan
Delay Abstraction in Combinational Logic Circuits Noriya Kobayashi Sharad Malik C&C Research Laboratories Department of Electrical Engineering NEC Corp. Princeton University Miyamae-ku, Kawasaki Japan
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Hardware Software Codesign of Embedded Systems
 Hardware Software Codesign of Embedded Systems Rabi Mahapatra Texas A&M University Today s topics Course Organization Introduction to HS-CODES Codesign Motivation Some Issues on Codesign of Embedded System
Hardware Software Codesign of Embedded Systems Rabi Mahapatra Texas A&M University Today s topics Course Organization Introduction to HS-CODES Codesign Motivation Some Issues on Codesign of Embedded System
TIERS: Topology IndependEnt Pipelined Routing and Scheduling for VirtualWire TM Compilation
 TIERS: Topology IndependEnt Pipelined Routing and Scheduling for VirtualWire TM Compilation Charles Selvidge, Anant Agarwal, Matt Dahl, Jonathan Babb Virtual Machine Works, Inc. 1 Kendall Sq. Building
TIERS: Topology IndependEnt Pipelined Routing and Scheduling for VirtualWire TM Compilation Charles Selvidge, Anant Agarwal, Matt Dahl, Jonathan Babb Virtual Machine Works, Inc. 1 Kendall Sq. Building
Hardware/ Software Partitioning
 Hardware/ Software Partitioning Peter Marwedel TU Dortmund, Informatik 12 Germany Marwedel, 2003 Graphics: Alexandra Nolte, Gesine 2011 年 12 月 09 日 These slides use Microsoft clip arts. Microsoft copyright
Hardware/ Software Partitioning Peter Marwedel TU Dortmund, Informatik 12 Germany Marwedel, 2003 Graphics: Alexandra Nolte, Gesine 2011 年 12 月 09 日 These slides use Microsoft clip arts. Microsoft copyright
Task Allocation for Minimizing Programs Completion Time in Multicomputer Systems
 Task Allocation for Minimizing Programs Completion Time in Multicomputer Systems Gamal Attiya and Yskandar Hamam Groupe ESIEE Paris, Lab. A 2 SI Cité Descartes, BP 99, 93162 Noisy-Le-Grand, FRANCE {attiyag,hamamy}@esiee.fr
Task Allocation for Minimizing Programs Completion Time in Multicomputer Systems Gamal Attiya and Yskandar Hamam Groupe ESIEE Paris, Lab. A 2 SI Cité Descartes, BP 99, 93162 Noisy-Le-Grand, FRANCE {attiyag,hamamy}@esiee.fr
Design Space Exploration of Real-time Multi-media MPSoCs with Heterogeneous Scheduling Policies
 Design Space Exploration of Real-time Multi-media MPSoCs with Heterogeneous Scheduling Policies Minyoung Kim, Sudarshan Banerjee, Nikil Dutt, Nalini Venkatasubramanian School of Information and Computer
Design Space Exploration of Real-time Multi-media MPSoCs with Heterogeneous Scheduling Policies Minyoung Kim, Sudarshan Banerjee, Nikil Dutt, Nalini Venkatasubramanian School of Information and Computer
Codesign Framework. Parts of this lecture are borrowed from lectures of Johan Lilius of TUCS and ASV/LL of UC Berkeley available in their web.
 Codesign Framework Parts of this lecture are borrowed from lectures of Johan Lilius of TUCS and ASV/LL of UC Berkeley available in their web. Embedded Processor Types General Purpose Expensive, requires
Codesign Framework Parts of this lecture are borrowed from lectures of Johan Lilius of TUCS and ASV/LL of UC Berkeley available in their web. Embedded Processor Types General Purpose Expensive, requires
Datapath Allocation. Zoltan Baruch. Computer Science Department, Technical University of Cluj-Napoca
 Datapath Allocation Zoltan Baruch Computer Science Department, Technical University of Cluj-Napoca e-mail: baruch@utcluj.ro Abstract. The datapath allocation is one of the basic operations executed in
Datapath Allocation Zoltan Baruch Computer Science Department, Technical University of Cluj-Napoca e-mail: baruch@utcluj.ro Abstract. The datapath allocation is one of the basic operations executed in
Design For High Performance Flexray Protocol For Fpga Based System
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) e-issn: 2319 4200, p-issn No. : 2319 4197 PP 83-88 www.iosrjournals.org Design For High Performance Flexray Protocol For Fpga Based System E. Singaravelan
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) e-issn: 2319 4200, p-issn No. : 2319 4197 PP 83-88 www.iosrjournals.org Design For High Performance Flexray Protocol For Fpga Based System E. Singaravelan
Improving Reconfiguration Speed for Dynamic Circuit Specialization using Placement Constraints
 Improving Reconfiguration Speed for Dynamic Circuit Specialization using Placement Constraints Amit Kulkarni, Tom Davidson, Karel Heyse, and Dirk Stroobandt ELIS department, Computer Systems Lab, Ghent
Improving Reconfiguration Speed for Dynamic Circuit Specialization using Placement Constraints Amit Kulkarni, Tom Davidson, Karel Heyse, and Dirk Stroobandt ELIS department, Computer Systems Lab, Ghent
EE382V: System-on-a-Chip (SoC) Design
 Design") EE382V: System-on-a-Chip (SoC) Design Lecture 8 HW/SW Co-Design Sources: Prof. Margarida Jacome, UT Austin Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu
EE382V: System-on-a-Chip (SoC) Design Lecture 8 HW/SW Co-Design Sources: Prof. Margarida Jacome, UT Austin Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu
Algorithm Design and Analysis
 Algorithm Design and Analysis LECTURE 29 Approximation Algorithms Load Balancing Weighted Vertex Cover Reminder: Fill out SRTEs online Don t forget to click submit Sofya Raskhodnikova 12/7/2016 Approximation
Algorithm Design and Analysis LECTURE 29 Approximation Algorithms Load Balancing Weighted Vertex Cover Reminder: Fill out SRTEs online Don t forget to click submit Sofya Raskhodnikova 12/7/2016 Approximation
Iyad Ouaiss, Sriram Govindarajan, Vinoo Srinivasan, Meenakshi Kaul, and Ranga Vemuri
 An Integrated Partitioning and Synthesis System for Dynamically Recongurable Multi-FPGA Architectures? Iyad Ouaiss, Sriram Govindarajan, Vinoo Srinivasan, Meenakshi Kaul, and Ranga Vemuri DDEL, Department
An Integrated Partitioning and Synthesis System for Dynamically Recongurable Multi-FPGA Architectures? Iyad Ouaiss, Sriram Govindarajan, Vinoo Srinivasan, Meenakshi Kaul, and Ranga Vemuri DDEL, Department
CAD Algorithms. Circuit Partitioning
 CAD Algorithms Partitioning Mohammad Tehranipoor ECE Department 13 October 2008 1 Circuit Partitioning Partitioning: The process of decomposing a circuit/system into smaller subcircuits/subsystems, which
CAD Algorithms Partitioning Mohammad Tehranipoor ECE Department 13 October 2008 1 Circuit Partitioning Partitioning: The process of decomposing a circuit/system into smaller subcircuits/subsystems, which
Crew Scheduling Problem: A Column Generation Approach Improved by a Genetic Algorithm. Santos and Mateus (2007)
") In the name of God Crew Scheduling Problem: A Column Generation Approach Improved by a Genetic Algorithm Spring 2009 Instructor: Dr. Masoud Yaghini Outlines Problem Definition Modeling As A Set Partitioning
In the name of God Crew Scheduling Problem: A Column Generation Approach Improved by a Genetic Algorithm Spring 2009 Instructor: Dr. Masoud Yaghini Outlines Problem Definition Modeling As A Set Partitioning
An Experimental Investigation into the Rank Function of the Heterogeneous Earliest Finish Time Scheduling Algorithm
 An Experimental Investigation into the Rank Function of the Heterogeneous Earliest Finish Time Scheduling Algorithm Henan Zhao and Rizos Sakellariou Department of Computer Science, University of Manchester,
An Experimental Investigation into the Rank Function of the Heterogeneous Earliest Finish Time Scheduling Algorithm Henan Zhao and Rizos Sakellariou Department of Computer Science, University of Manchester,
CLOCK DRIVEN SCHEDULING
 CHAPTER 4 By Radu Muresan University of Guelph Page 1 ENGG4420 CHAPTER 4 LECTURE 2 and 3 November 04 09 7:51 PM CLOCK DRIVEN SCHEDULING Clock driven schedulers make their scheduling decisions regarding
CHAPTER 4 By Radu Muresan University of Guelph Page 1 ENGG4420 CHAPTER 4 LECTURE 2 and 3 November 04 09 7:51 PM CLOCK DRIVEN SCHEDULING Clock driven schedulers make their scheduling decisions regarding
Greedy Algorithms CHAPTER 16
 CHAPTER 16 Greedy Algorithms In dynamic programming, the optimal solution is described in a recursive manner, and then is computed ``bottom up''. Dynamic programming is a powerful technique, but it often
CHAPTER 16 Greedy Algorithms In dynamic programming, the optimal solution is described in a recursive manner, and then is computed ``bottom up''. Dynamic programming is a powerful technique, but it often