SELECTED TOPICS IN COHERENCE AND CONSISTENCY
|
|
|
- Stewart Ward
- 5 years ago
- Views:
Transcription
1 SELECTED TOPICS IN COHERENCE AND CONSISTENCY Michel Dubois Ming-Hsieh Department of Electrical Engineering University of Southern California Los Angeles, CA
2 INTRODUCTION IN CHIP MULTIPROCESSORS (CMPs) CPUs (cores) SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES SHARED MEMORY IS A COMMUNICATION MECHANISM NO HYPOTHESIS ON THE RELATIVE SPEED OF PROCESSORS
3 INTRODUCTION CACHING CACHES ARE NECESSARY TO MAINTAIN THE HIGH EXECUTION RATE OF CORES MANY COPIES OF THE SAME ADDRESS (IN CACHES OR IN OTHER BUFFERS) MAY BE PRESENT AT ANY TIME THESE COPIES MUST GIVE THE ILLUSION OF BEING COHERENT (I.E., EQUIVALENT TO A SINGLE COPY) COHERENCE IS TRIVIALLY ENFORCED WHEN THERE IS A SINGLE COPY COHERENCE IS ALSO TRIVIALLY ENFORCED WHEN MULTIPLE COPIES OF THE SAME ADDRESS ARE ALWAYS THE SAME
4 INTRODUCTION MEMORY CONSISTENCY MODEL(MCM) THE ORDER IN WHICH ACCESSES (TO ALL ADDRESSES) BY ONE THREAD ARE OBSERVED BY OTHER THREADS MUCH TOUGHER THAN COHERENCE CONSIDER THE FOLLOWING CODE: ASSUME A AND flag ARE BOTH 0 INITIALLY P1 P A:=1; while(flag==0)do nothing; flag:=1; print A; ONE WOULD ASSUME THAT THE VALUE 1 IS PRINTED BY P2 HOWEVER THIS MAY NOT ALWAYS BE THE CASE COHERENCE DOES NOT DO THAT
5 MEMORY CONSISTENCY MODEL <=> PROCESSOR ARCHITECTURE + MEMORY ARCHITECTURE Design each independently
6 INTRODUCTION CONTENT 1.PIPELINES 2.SYNCHRONIZATION 3.STORE ATOMICITY 4.SEQUENTIAL CONSISTENCY 5.RELAXED MEMORY CONSISTENCY MODELS 6.SPECULATIVE VIOLATIONS OF MEMORY CONSISTENCY MODELS 7.QUESTION: DO WE REALLY NEED COHERENCE? 8.OTHER TOPICS
7 1. PIPELINES
8 5-STAGE PIPELINE MEMORY ACCESSES (LOADS AND STORES) ARE BLOCKING AND EXECUTE ONE BY ONE IN PROCESS ORDER IN THE MEMORY STAGE NO MEMORY HAZARDS NO PROBLEM FROM THE PROCESSOR SIDE NO MEMORY HAZARD
9 5-STAGE PIPELINE WITH STORE BUFFER HERE, LOADS ARE BLOCKING BUT STORES ARE NOT LOADS AND STORES REACH THE CACHE OUT OF PROCESS ORDER MEMORY HAZARDS ARE POSSIBLE VALUES MAY OR MAY NOT BE FORWARDED FROM SB


10 Out-of-Order EXECUTION INSTRUCTIONS ARE DISPATCHED IN ORDER THEY EXECUTE OUT OF ORDER THEY COMMIT THEIR RESULTS IN ORDER STORES EXECUTE WHEN THEY ARE AT THE TOP OF ROB LOADS EXECUTE SPECULATIVELY
11 2. SYNCHRONIZATION
12 SHARED-MEMORY COMMUNICATION IMPLICITELY VIA MEMORY PROCESSORS SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES
13 SYNCHRONIZATION THE THREE FORMS OF SYNCHRONIZATION: 1. MUTUAL EXCLUSION 2. BARRIER SYNCHRONIZATION 3. POINT-TO-POINT SYNCHRONIZATION
14 MUTUAL EXCLUSION NEED FOR MUTUAL EXCLUSION ASSUME THE FOLLOWING STATEMENTS ARE EXECUTED BY 2 THREADS, T1 AND T2 T1 T2 A<- A+1 A<- A+1 THE PROGRAMMER S EXPECTATION IS THAT, WHATEVER THE ORDER OF EXECUTION OF THE TWO STATEMENTS, THE FINAL RESULT WILL BE THAT A IS INCREMENTED BY 2 HOWEVER PROGRAM STATEMENTS ARE NOT EXECUTED IN AN ATOMIC FASHION. COMPILED CODE ON A RISC MACHINE WILL INCLUDE SEVERAL INSTRUCTIONS A POSSIBLE TEMPORAL INTERLEAVING IS: T1 r1 <- A r1 <- r1 + 1 A <- r1 T2 r1 <- A r1 <- r1 + 1 A <- r1 IN THE END A IS INCREMENTED BY 1 (NOT 2 AS EXPECTED)
15 MUTUAL EXCLUSION MAKE PROGRAM STATEMENT EXECUTION ATOMIC CRITICAL SECTIONS PROVIDED BY LOCK (ACQUIRE) AND UNLOCK (RELEASE) PRIMITIVES FRAMING THE STATEMENT(S) MODIFICATIONS ARE RELEASED ATOMICALLY AT THE END OF THE CRITICAL SECTION SO THE CODE SHOULD BE: T1 T2 lock(la) lock(la) /acquire A<- A+1 A<- A+1 unlock(la) unlock(la) /release HONOR SYSTEM DEKKER S ALGORITHMS FOR LOCKING ASSUME A AND B ARE BOTH 0 INITIALLY T1 T2 A:=1 B:=1 while(b==1); /acquire while(a==1); <critical section> <critical section> A:=0 release B:=0 AT MOST ONE PROCESS CAN BE IN THE CRITICAL SECTION AT ANY ONE TIME. DEADLOCK IS POSSIBLE COMPLEX (TO SOLVE DEADLOCK AND TO SYNCHRONIZE MORE THAN 2 THREADS)
16 BARRIER SYNCHRONIZATION GLOBAL SYNCHRONIZATION AMONG ALL THREADS ALL THREADS MUST REACH THE BARRIER BEFORE ANY THREAD IS ALLOWED TO EXECUTE BEYOND THE BARRIER P1 P BAR := BAR+1; BAR := BAR +1; while (BAR < 2); while (BAR < 2); NOTE: NEED A CRITICAL SECTION TO INCREMENT BAR
17 POINT-TO-POINT SYNCHRONIZATION SIGNALS THAT A VALUE IS AVAILABLE T1 while (FLAG==0); print A T2 A = 1; FLAG = 1; SIGNAL SENT BY T1 TO T2 THROUGH FLAG (PRODUCER/CONSUMER SYNCHRONIZATION)
18 SYNCHRONIZATION USE NEW MEMORY INSTRUCTIONS TEST AND SET RESET Lock: T&S R1, lock BNEZ R1, Lock RET Unlock: SW R0, lock RET LOAD LINK STORE CONDITIONAL T&S: ADDI R1,R0,1 LL Rx,lock SC R1,lock BEQZ R1, T&S RET
 OPPOSITE IS TRUE FOR")
19 EXAMPLE IN 1ST PHASE ACCESSES TO Xs ARE MUTUALLY EXCLUSIVE IN 2ND PHASE, MULTIPLE ACCESSES TO Xs (READ-ONLY) OPPOSITE IS TRUE FOR Ys
20 3. STORE ATOMICITY
21 MEMORY COHERENCE: WHAT S THE PROBLEM
22 COHERENCE: WHY IT IS SO HARD AFTER EVENT 3, THE CACHES CONTAIN DIFFERENT COPIES. IS THIS STILL COHERENT? THE ANSWER IS YES, FOR AS LONG AS P1 OR P2 DO NOT EXECUTE THEIR LOADs A SYSTEM REMAINS COHERENT FOR AS LONG AS INCOHERENCE IS NOT DETECTED. OTHERWISE SAME RESULT. CAN THE LOADs IN EVENTS 4 AND 5 RETURN 0 OR 1? COHERENT? YES, EITHER COULD STILL BE COHERENT (DEPENDING ON THE DEFINITION) BECAUSE SOFTWARE CANNOT DETECT THE DIFFERENCE P1 OR P2 COULD HAVE RUN SLIGHTLY FASTER, SO THAT EVENTS 4 OR 5 OCCUR BEFORE EVENT 3 IN TIME. IN PRACTICE, MUCH MORE COMPLEX BECAUSE MEMORY EVENTS ARE NOT ATOMIC AND DO SOMETIMES OVERLAP IN TIME FOR EXAMPLE, EVENTS 3, 4, AND 5 MAY BE TRIGGERED IN THE SAME CLOCK CYCLE THEY CONFLICT IN SOME PARTS OF THE HARDWARE WHERE THEY ARE SERIALIZED HOWEVER, THEY CAN PROCEED INDEPENDENTLY IN PARALLEL (TEMPORAL OVERLAP) ON THEIR OWN HARDWARE PATHS
23 STRICT COHERENCE A memory system is coherent if the value returned on a Load is always the value given by the latest Store with the same address SAME DEFINITION AS FOR UNIPROCESSORS DIFFICULT TO EXTEND AS SUCH TO MULTIPROCESSORS ORDER WITHIN EACH THREAD. NO ORDER BETWEEN THREADS. CAN BE APPLIED IF MEMORY ACCESSES DO NOT OVERLAP IN TIME TIME ORDER WON T HAPPEN ALL THE TIME STORES ARE ATOMIC SO THAT ALL COPIES ARE UPDATED INSTANTANEOUSLY (STORE ATOMICITY) STORE/LOAD ORDERS ARE ENFORCED BY ACCESSES TO OTHER MEMORY LOCATIONS (E.G., SYNCHRONIZATION PRIMITIVES)
24 NOTATIONS
25 PROTOCOL MACHINE: MSI INVALIDATE PROTOCOL THE PROTOCOL MACHINES FOR PROTOCOL SPECIFICATION ASSUMES THAT EVENTS ARE ATOMIC (HAPPEN INSTANTANEOUSLY) BLOCK STATES: Invalid (I); same as Not Present (NP) Shared (S): one copy or more, memory is clean; Dirty (D) or Modified (M): one copy, memory is stale PROCESSOR REQUESTS PrRd or PrWr BUS TRANSACTIONS BusRd: requests copy with no intent to modify BusRdX: requests copy with intent to modify Flush: forwards block copy to requester BusRdX/Flush PrWr/-- PrRd/-- BusRd/Flush PrRd/BusRd M S PrRd/-- I(NP) BudRd/-- PrWr/BusRdX BusRdX/-- PrWr/BusRdX BusRd/-- BusRdX/--
26 ATOMIC MEMORY ACCESSES Strict coherence is applicable if all memory accesses are atomic or do not overlap in time CLK T1: T2: Comments t1: S 1 (A)a 1 Data not in C2 and dirty in C1 t2: L 1 (A)a 1 t3: S 1 (A)a 2 t4: L 1 (A)a 2 t5: L 2 (A)a APT: Read Miss in C2; t6: L 1 (A)a 2 A becomes Shared in C1 and C2; both threads can read A= a 2 ; No one can write t7: L 2 (A)a 2 t8: L 1 (A)a 2 t9: S 2 (A)a APT:C1 is invalidated t10: L 2 (A)a 3 and C2 becomes Dirty t11: S 1 (A)a APT:Store miss in C1; C2 is invalidated t13: S 1 (A)a 5

27 MEMORY ACCESS ATOMICITY A long time ago, processors were not pipelined, were connected by a single, circuit-switched bus, no store buffer On a coherence transaction, processor blocks, cache gets access to the bus and complete the transaction in remote caches and memory atomically COHERENCE TRANSACTIONS DO NOT OVERLAP IN TIME THUS THE PROTOCOL WORKS EXACTLY AS ITS PROTOCOL MACHINE THE COHERENCE TRANSACTION IS PERFORMED ATOMICALLY WHEN THE BUS IS RELEASED Today we must deal with non-atomic transactions
28 MEMORY ACCESS ATOMICITY--SUFFICIENT CONDITION COHERENCE TRANSACTIONS CANNOT HAPPEN INSTANTANEOUSLY MUST MAKE THEM LOOK ATOMIC TO THE SOFTWARE WELL-KNOWN PROBLEM: DATABASE SYSTEMS OR CRITICAL SECTIONS CONDITION: MAKE SURE THAT ONLY ONE VALUE IS ACCESSIBLE AT ANY ONE TIME No thread can observe a new value while any thread can still observe the old value
29 DIRECTORY-BASED PROTOCOLS Busy bit BUSY BIT IS ADDED TO EACH DIRECTORY ENTRY THE FUNCTION OF THE BUSY BIT IS TO LOCK THE DIRECTORY ENTRY SO THAT THE DIRECTORY CAN MANAGE MULTIPLE TRANSACTIONS ON DIFFERENT ADDRESSES AT THE SAME TIME
 REMOTE NODE DIRTY (D): NODE HOLDING THE LATEST, MODIFIED COPY SHARED (S) : NODE HOLDING A SHARED")
30 PROTOCOL AGENTS: cc-numa PROTOCOLS HOME NODE (H): NODE WHERE THE MEMORY BLOCK AND ITS DIRECTORY ENTRY RESIDE LOCAL NODE (R): NODE MAKING THE REQUEST (REQUESTER) REMOTE NODE DIRTY (D): NODE HOLDING THE LATEST, MODIFIED COPY SHARED (S) : NODE HOLDING A SHARED COPY
31 MSI INVALIDATE PROTOCOL IN cc-numas (4-LEG PROTOCOL) BASELINE DIRECTORY PROTOCOL HAS FOUR HOPS ON A REMOTE MISS.
32 STORE ATOMICITY IN cc-numas WRITE MISS IN THREAD T0 IN A cc-numa WITH MSI INVALIDATE
33 STORE ATOMICITY IN cc-numas Threads must all observe the same value While a new value is propagated, no thread can read the new value (including the writing thread) if other threads can still read the old value
 IT IS WELL-KNOWN THAT INTERLEAVED MEMORY SYSTEMS ARE EQUIVALENT TO A MONOLITHIC (CENTRALIZED)")
34 STORE ATOMICITY AND MEMORY INTERLEAVING IN A STORE-ATOMIC MEMORY SYSTEM, ONLY ONE VALUE OF EACH ADDRESS IS ACCESSIBLE BY THREADS AT ANY ONE TIME THIS IS THE SAME SITUATION AS INTERLEAVED MEMORIES A STORE-ATOMIC MEMORY SYSTEM BEHAVES LIKE AN INTERLEAVED MEMORY SYSTEM (TYPICAL SYSTEM WITH NO CACHE) IT IS WELL-KNOWN THAT INTERLEAVED MEMORY SYSTEMS ARE EQUIVALENT TO A MONOLITHIC (CENTRALIZED) MEMORY
35 COHERENCE IS NOT SUFFICIENT Point-to-point Synchronization ASSUME A AND flag ARE BOTH 0 INITIALLY P1 P A:=1; while (flag==0) do nothing; flag:=1; print A; Communication ASSUME A AND B ARE BOTH 0 INITIALLY P1 P A:=1; print B; B:=2; print A; Critical section ASSUME A AND B ARE BOTH 0 INITIALLY P1 P A:=1 B:=1 while(b==1) do nothing; while(a==1) do nothing; <critical section> <critical section> A:=0 B:=0 PROGRAMMER S INTUITION HERE IS THAT ACCESSES FROM DIFFERENT PROCESSORS ARE INTERLEAVED IN PROCESS ORDER SEQUENTIAL CONSISTENCY
36 4. SEQUENTIAL CONSISTENCY

37 FORMAL MODEL FOR SEQUENTIAL CONSISTENCY PROGRAM ORDER OF ALL THREADs IS RESPECTED AND ALL MEMORY ACCESSES ARE ATOMIC BECAUSE OF THE MEMORY CONTROLLER A MULTIPROCESSOR IS SEQUENTIALLY CONSISTENT IF THE RESULT OF ANY EXECUTION IS THE SAME AS IF THE MEMORY OPERATIONS OF ALL THE PROCESSORS WERE EXECUTED IN SOME SEQUENTIAL ORDER, AND THE OPERATIONS OF EACH INDIVIDUAL PROCESSOR APPEAR IN THE SEQUENCE IN THE ORDER SPECIFIED BY ITS PROGRAM
38 CONDITIONS FOR SC WE NEED TO FIND A COHERENT ORDER OF ALL MEMORY ACCESSES IN WHICH ACCESSES OF EACH THREAD ARE IN THREAD ORDER FOR EVERY EXECUTION.
39 ACCESS ORDERING RULES FOR SEQUENTIAL CONSISTENCY EXECUTION GRAPH HAS CYCLES EXECUTION CANNOT BE ORDERED THIS CAN HAPPEN EVEN IF MEMORY IS STORE ATOMIC THE BEST IT CAN BE. HOW? IN A 5-STAGE PIPELINE WITH STORE BUFFERS THE TWO STORES ARE INSERTED IN THE STORE BUFFER OF EACH PROCESSOR THE TWO LOADS BYPASS THE TWO STORES AND BOTH RETURN 0 CONCLUSION: WE MUST ALSO ADDRESS THE BEHAVIOR OF THE PROCESSOR

40 SEQUENTIAL CONSISTENCY LOOK AT MEMORY ACCESSES ORDERS THAT MUST BE OBSERVED (PERFORMED) GLOBALLY IN THE WHOLE SYSTEM IN SC ALL ORDERS MUST BE ENFORCED ASSUME MEMORY STORES ARE ATOMIC WHAT DOES THIS MEAN FOR IN-ORDER PROCESSORS WITH STORE BUFFERS? LOADs ARE BLOCKING, SO LOAD-LOAD AND LOAD-STORE ORDERS ARE ENFORCED STOREs ARE NON-BLOCKING (THEY MOVE TO SB) STORE-LOAD: LOADs MUST BLOCK IN ME UNTIL SB IS EMPTY STORE-STORE: STOREs MUST BE EXECUTED ONE BY ONE FROM SB IN THE STORE ATOMIC MEMORY SYSTEM
41 CONCLUSION ON SC PROBLEM WITH STORE BUFFERS SC CANNOT REALLY TAKE ADVANTAGE OF STORE BUFFERS PROBLEM WITH COMPILERS TAKE AGAIN PT-TO-PT SYNCHRONIZATION P1 P A:=1; while(flag==0)do nothing; flag:=1; print A; SINCE THERE IS NO DEPENDENCY BETWEEN flag AND A, THE COMPILER MAY REORDER THE TWO INSTRUCTIONS IN P1 MIGHT ALSO REMOVE THE LOOP ON flag IN P2 NEXT IDEA: CHANGE THE RULES MEMORY CONSISTENCY MODELS MAY RELY OR NOT ON SYNCHRONIZATION
42 5. RELAXED MEMORY CONSISTENCY MODELS
43 MEMORY CONSISTENCY MODELS FIRST: WHY SHOULD WE BOTHER ABOUT THE PROGRAMMER ANYWAY? WHY NOT DESIGN MEMORY ACCESS RULES THAT ARE HARDWARE FRIENDLY AND THEN ASK THE PROGRAMMER TO ABIDE BY THEM?? SECOND: ARE THERE OTHER PROGRAMMER S INTUITIONS BESIDES SC? SUCH AS PROVIDED BY SYNCHRONIZATION? WHENEVER SHARED VARIABLES ARE READ/WRITE ACCESSES TO THEM SHOULD BE PROTECTED BY LOCKS P1 A:=1; B:=2; BARRIER(BAR,2); BAR IS 0 INITIALLY P2 BARRIER(BAR,2); R1:=A; R2:=B; BECAUSE OF THE BARRIER, THE RESULT IS ALWAYS SC AND P2 RETURNS (A=1 AND B=2) IN ALL CASES WE NEED A MEMORY ACCESS ORDERING MODEL ON WHICH PROGRAMMERS AND MACHINE ARCHITECTS CAN AGREE IT S CALLED THE MEMORY CONSISTENCY MODEL THIS MODEL MUST BE PART OF THE ISA DEFINITION, SINCE IT IS AT THE INTERFACE BETWEEN SOFTWARE AND HARDWARE
44 RELAXED MEMORY CONSISTENCY MODELS WE CAN RELAX SOME OF THE ACCESS ORDERS OF EACH THREAD THE MAJOR RELAXATION IS THE STORE-TO-LOAD ORDER: LOADS CAN BYPASS PRIOR STORES LOAD LOAD STORE STORE LOAD STORE LOAD STORE STORES FROM THE SAME PROCESSOR MUST BE OBSERVED BY ALL OTHER PROCESSORS IN THREAD ORDER (BECAUSE OF STORE-STORE AND LOAD-LOAD ORDERS) WHAT DOES THIS MEAN FOR IO PROCESSORS? ASSUME MEMORY IS ATOMIC: LOADS RETURN VALUES FROM MEMORY ONLY WHEN THE VALUES ARE GPed LOAD-LOAD, LOAD-STORE, STORE-STORE: SAME AS FOR SC STORE-LOAD: LOADs DON T WAIT FOR SB EMPTY
45 RELAXING STORE-TO-LOAD ORDERS EXAMPLE: SUN MICRO TOTAL STORE ORDER (TSO) DEKKER S ALGORITHM DOES NOT WORK POINT-TO-POINT COMMUNICATION STILL WORKS VALUES MAY OR MAY NOT BE FORWARDED FROM SB TO LOADS NO FORWARDING FROM SB STORE ATOMIC FORWARDING FROM SB NOT STORE ATOMIC (as in TSO) THIS MEANS THAT SOME LOADS IN TSO RETURN VALUES EVEN IF THE VALUES ARE NOT VISIBLE TO THE REST OF THE MEMORY SYSTEM
46 IMPLICATIONS OF RELAXING STORE-TO-LOAD ORDER BECAUSE MEMORY ACCESS ORDERS ARE WEAKENED, MORE EXECUTIONS ARE VALID UNDER RELAXED MEMORY MODELS EXAMPLE: T1 S 1 (A)1 L 1 (B)0 INIT: A=B=0 T2 S 2 (B)1 L 2 (A)0 IN SC A LOADS CANNOT BE EXECUTED BEFORE A PREVIOUS STORE IS GLOBALLY PERFORMED. THUS, THIS IS NOT A VALID EXECUTION. NOT SO IN RELAXED MEMORY MODELS!!!!!THIS IS A VALID EXECUTION WITH STORE-TO-LOAD RELAXATION AS A RESULT, SOME PROGRAMS WRITTEN FOR A STRONGER MODEL WON T RUN CORRECTLY ON WEAKER MEMORY MODELS IN THE CASE OF STORE-TO-LOAD RELAXATION DEKKER S ALGORITHM DOES NOT WORK POINT-TO-POINT COMMUNICATION STILL WORKS BECAUSE STORES FROM THE SAME PROCESSOR MUST BE OBSERVED BY ALL OTHER PROCESSORS IN THEIR THREAD ORDER (BECAUSE STORE-STORE AND LOAD-LOAD ORDERS ARE ENFORCED)
47 NO FORWARDING FROM SB VALID EXECUTION T1 S 1 (A)1 L 1 (B)0 INIT: A=B=0 T2 S 2 (B)1 L 2 (A)0 NO ARROW BETWEEN STORE AND LOAD IN EACH THREAD NO GLOBAL ORDER BETWEEN THE STORE AND LOAD IN EACH THREAD STILL GLOBAL MEMORY ORDER IS STORE ATOMIC. THE REASON THIS HAPPENS HAS TO DO WITH THE BEHAVIOR OF THE PROCESSOR
48 MCM USING SYNCHRONIZATION Locks use special instructions RMW (for lock) special stores (for unlocks) Treat locks as FENCES for all memory accesses Also called SYNC in PowerPC s memory model lock and unlock act as fences perform all preceding accesses in T.O. before attempting a SYNC perform SYNC before attempting any following accesses in T.O. In between two SYNC Ops, the order of memory Ops is arbitrary
49 WEAK ORDERING MULTITHREADED EXECUTION USES LOCKING MECHANISMS TO AVOID RACE CONDITIONS. EXECUTIONS INCLUDE VARIOUS PHASES: ACCESSES TO PRIVATE OR READ-ONLY SHARED DATA, OR ACCESSES TO SHARED MODIFIABLE DATA, PROTECTED BY LOCKS AND BARRIERS. IN EACH PHASE THE THREAD HAS EXCLUSIVE ACCESS TO ALL ITS DATA, MEANING NO OTHER THREAD CAN WRITE TO THEM, OR NO OTHER THREAD CAN READ THE DATA IT MODIFIES ACCESSES TO SYNCHRONIZATION DATA (INCLUDING ALL LOCKS AND SHARED DATA IN SYNCHRONIZATION PROTOCOLS) ARE TREATED DIFFERENTLY BY THE HARDWARE FROM ACCESSES TO OTHER SHARED AND PRIVATE DATA. THEY ACT AS FENCES ON ALL ACCESSES MUST GLOBALLY PERFORM ALL ACCESS PRECEDING SYNC ACCESS IN T.O. MUST GLOBALLY PERFORM SYNC ACCESS BEFORE ALL FOLLOWING ACCESSES IN T.O.
50 WEAK ORDERING WEAK ORDERING RELIES ON (HOPEFULLY) CORRECTLY WRITTEN PROGRAMS IN WHICH RACES ON SHARED DATA ARE PREVENTED THROUGH SYNCHRONIZATION A RACE OCCURS WHEN TWO THREADS ACCESS THE SAME ADDRESS AND AT LEAST ONE OF THE ACCESSES IS A WRITE WHICH MEANS THAT THERE WILL BE HAZARDS MULTITHREADED EXECUTION RELIES ON LOCKING MECHANISMS TO AVOID DATA RACE CONDITIONS. DATA-RACE FREE PROGRAMS EXECUTIONS OF DATA-RACE FREE PROGRAMS INCLUDE VARIOUS PHASES: ACCESSES TO PRIVATE OR READ-ONLY SHARED DATA, OR ACCESSES TO SHARED MODIFIABLE DATA, PROTECTED BY LOCKS AND BARRIERS. IN EACH PHASE THE THREAD HAS EXCLUSIVE ACCESS TO ALL ITS DATA, MEANING NO OTHER THREAD CAN WRITE TO THEM, OR NO OTHER THREAD CAN READ THE DATA IT MODIFIES
51 WEAK ORDERING ACCESSES TO OTHER (NON-SYNC) SHARED AND PRIVATE DATA MUST ENFORCE UNIPROCESSOR DEPENDENCIES ON SAME ADDRESS OTHERWISE, NO REQUIREMENT EVEN COHERENCE IS NOT A REQUIREMENT VARIABLES THAT ARE USED FOR SYNCHRONIZATION MUST BE DECLARED AS SUCH (e.g., flag, A and B below) SO THAT EXECUTION ON THESE VARIABLES ARE SAFE. A=flag=0 initially T1 T2 A:=1; while(flag==0)do nothing; flag:=1; print A; Flag MUST BE DECLARED AS SYNC VARIABLE
52 WEAK ORDERING A RMW ACCESS TO A MEMORY LOCATION IS GLOBALLY PERFORMED ONCE BOTH THE LOAD AND THE STORE IN THE RMW ACCESS ARE GLOBALLY PERFORMED. ATOMICITY MUST ALSO BE ENFORCED BETWEEN THE TWO ACCESSES (EASIER IN WRITE-INVALIDATE PROTOCOLS--TREAT THE T&S AS A STORE IN THE PROTOCOL) SYNC OPERATION MUST BE RECOGNIZABLE BY THE HARDWARE AT THE ISA LEVEL RMW (T&S) SPECIAL LOADS AND STORES FOR SYNC VARIABLE ACCESSES ORDERS TO ENFORCE: Op Sync Sync Sync Op Sync Op = regular load or store Sync = any synchronization access, e.g., swap, T&S, special load/store

53 WEAK ORDERING WHAT DOES IT MEAN FOR IO PROCESSORS? NOTE: HERE REGULAR LOADS CAN RETURN VALUES EVEN IF THEY ARE NOT GPed REGULAR STORES IN THE STORE BUFFER CAN BE EXECUTED IN ANY ORDER, IN PARALLEL REGULAR LOADS NEVER WAIT FOR STORES AND CAN BE FORWARDED TO WHEN A SYNC ACCESS IS EXECUTED, IT IS TREATED DIFFERENTLY: IT BLOCKS IN THE MEMORY STAGE UNTIL ALL STORES IN THE STORE BUFFER ARE GLOBALLY PERFORMED WHICH ENFORCES OP-TO-SYNC. SYNC-TO-OP AND SYNC-TO-SYNC ORDERS ARE AUTOMATICALLY ENFORCED BY IO PROCESSOR Op Sync Sync Sync Op Sync
54 RELEASE CONSISTENCY A REFINEMENT OF WEAK ORDERING DISTINGUISHES BETWEEN ACQUIRES AND RELEASES OF LOCK ACQUIRES MUST BE GLOBALLY PERFORMED BEFORE STARTING ANY FOLLOWING MEMORY OPS ALL MEMORY OPS MUST BE GLOBALLY PERFORMED BEFORE A RELEASE CAN START MORE RELAXED THAN WEAK ORDERING PROGRAMMERS MUST MARK (LABEL) SYNCHRONIZATION ACCESSES AS ACQUIRES OR RELEASES ACQUIRES AND RELEASES MUST BE SEQUENTIALLY CONSISTENT ORDERS TO ENFORCE GLOBALLY Op = REGULAR LOAD OR STORE Sync = ACQUIRE OR RELEASE

55 MCM USING SYNCHRONIZATION Locks use special instructions RMW (for lock) special stores (for unlocks) Treat locks as FENCES for all memory accesses Also called SYNC in PowerPC s memory model lock and unlock act as fences, i.e. perform all preceding accesses in T.O. before attempting a SYNC perform SYNC before attempting any following accesses in T.O. In between two SYNC Ops, the order of memory Ops is arbitrary
56 C:=D*E C:=C+K CONSIDER THE CODE OF T2 IN THE TWO EXAMPLE lock(lx) X:=A+X RELEASE CONSISTENCY C:=D*E C:=C+K lock(lx) X:=A+X unlock(lx) unlock(lx) lock(lb) B:=B+1 unlock(lb) while(b<3); <wait> WEAK ORDERING weak ordering lock(lb) while(b<3); <wait> B:=B+1 unlock(lb) RELEASE CONSISTENCY A LOT MORE CONCURRENCY INSIDE PROCESSOR IN RELEASE CONSISTENCY vs WEAK ORDERING THE CODE BEFORE UNLOCK(Lx) IN T2 CAN BE EXECUTED IN PARALLEL THE CODE AFTER LOCK(Lb) IN T2 CAN BE EXECUTED IN PARALLEL THE PROBLEM IS TO BE ABLE TO TAKE ADVANTAGE OF THIS ADDITIONAL CONCURRENCY WITHIN EACH THREAD IN A REGULAR PROCESSOR PLUS PROGRAMMING DIFFICULITES
57 RELEASE CONSISTENCY WHAT DOES IT MEAN FOR IO PROCESSOR? IF ID EX ME WB I-$ store buffer(sb) D-$ Main Memory NO ORDERING RULES AMONG REGULAR LOADs/STOREs REGULAR STORES IN THE STORE BUFFER CAN BE EXECUTED IN ANY ORDER, IN PARALLEL REGULAR LOADS NEVER WAIT FOR REGULAR STORES IN SB AND CAN BE FORWARDED TO ACQUIRES ARE BLOCKING: THUS ACQUIRE-OP AND ACQUIRE-SYNC ORDERS ARE AUTOMATICALLY ENFORCED A RELEASE IS INSERTED IN THE STORE BUFFER WITH REGULAR STORES. OP-RELEASE AND RELEASE-RELEASE ORDERS: RELEASES MUST WAIT IN SB UNTIL ALL PRIOR STORES AND RELEASES ARE GP (LOADS PRIOR TO THE RELEASE HAVE RETIRED) RELEASE-ACQUIRE ORDER: AN ACQUIRE WAITS UNTIL ALL PRIOR RELEASES IN SB HAVE BEEN GPed lw sw
58 6. SPECULATIVE VIOLATIONS OF MEMORY CONSISTENCY MODELS
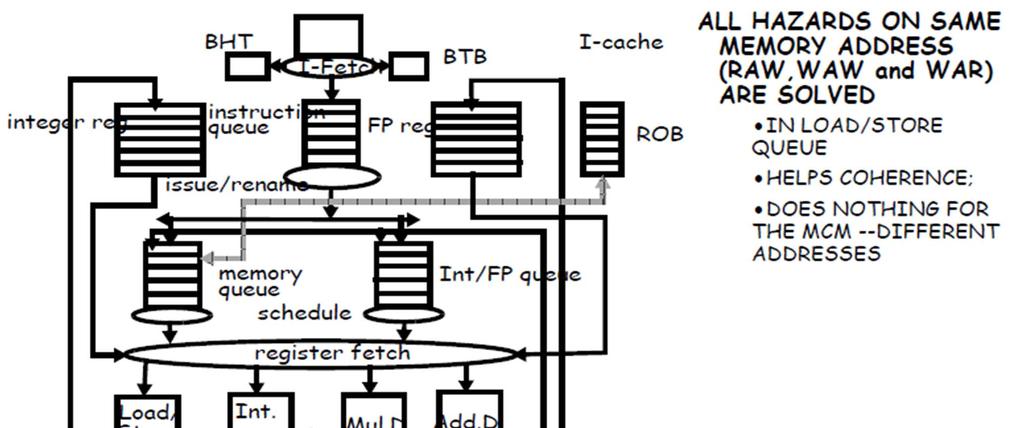
59 OoO PROCESSORS NOTE
60 LOADs/STOREs HANDLING IN SPECULATIVE OoO PROCESSORS WHEN THE LOAD ADDRESS IS KNOWN, THE LOAD CAN ISSUE TO CACHE PROVIDED NO STORE WITH THE SAME OR AN UNKNOWN ADDRESS IS AHEAD IN THE L/S QUEUE (CONSERVATIVE MEMORY DISAMBIGUATION) CAN EVEN BE ISSUED BEFORE ADDRESSES OF PREVIOUS STORES ARE KNOWN (SPECULATIVE MEMORY DISAMBIGUATION) IN BOTH CASES THE VALUE OF A LOAD ISSUED TO CACHE IS RETURNED AND USED SPECULATIVELY BEFORE THE LOAD RETIRES THE LOAD VALUE IS NOT BOUND UNTIL THE LOAD RETIRES THE VALUE CAN BE RECALLED FOR ALL KINDS OF REASONS (MISSPREDICTED BRANCH, EXCEPTION, ETC...) STORES CANNOT UPDATE CACHE UNTIL THEY REACH THE TOP OF THE ROB AS STORES REACH THE TOP OF THE REORDER BUFFER AND OF THE L/S QUEUE THEY COMMIT BY MOVING TO THE STORE BUFFER
61 CONSERVATIVE MCM ENFORCEMENT THE ONLY TIME THAT IT IS KNOWN FOR SURE THAT A MEMORY ACCESS CAN BE PERFORMED IS WHEN IT REACHES THE TOP OF ROB BEFORE THAT AN ACCESS (LOAD OR STORE) IS SPECULATIVE STORES MUST WAIT UNTIL THEN ANYWAY COULD WAIT TO EXECUTE AND PERFORM A LOAD IN CACHE UNTIL IT REACHES THE TOP OF ROB DOWNSIDE: NO MEMORY LATENCY TOLERANCE DUE TO OoO EXECUTION IN THIS CONSERVATIVE SCHEME, LOADs AND STOREs CAN STILL BE PREFETCHED IN CACHE (NON-BINDING PREFETCHES) IF THE LOAD OR STORE DATA IS IN THE RIGHT STATE IN CACHE AT THE TOP OF THE ROB, PERFORMING THE ACCESS TAKES ONE CACHE CYCLE. STILL, LOAD VALUES CAN NOT BE USED SPECULATIVELY NEXT IDEA: EXPLOIT SPECULATIVE EXECUTION TO SPECULATIVELY VIOLATE MEMORY ORDERS WORKS BECAUSE ORDER VIOLATIONS ARE RARE
62 SPECULATIVE VIOLATIONS OF SEQUENTIAL CONSISTENCY LET S LOOK AGAIN AT ORDERS TO ENFORCE GLOBALLY LOAD LOAD STORE STORE LOAD STORE LOAD STORE LOAD-STORE AND STORE-STORE ORDERS ARE ENFORCED BECAUSE STOREs ARE SENT TO THE STORE BUFFER ONLY WHEN THEY RETIRE FROM THE PROCESSOR, AND PROVIDED STOREs ARE GLOBALLY PERFORMED ONE BY ONE IN ORDER FROM THE STORE BUFFER REMAINING ORDERS ARE LOAD-LOAD AND STORE-LOAD THE SECOND ACCESS IN THESE ORDERS IS A LOAD EXPLOIT SPECULATION
63 SPECULATIVE VIOLATIONS OF SEQUENTIAL CONSISTENCY BASIC IDEA: PERFORM ALL LOADs AND USE THE VALUE RETURNED BY EACH LOAD SPECULATIVELY, AS IN UNIPROCESSOR LATER, WHEN THE LOAD RETIRES AT THE TOP OF ROB, CHECK WHETHER THE VALUE OF THE LOAD HAS CHANGED ROLL BACK IF IT HAS. OTHERWISE CONTINUE. TWO MECHANISMS ARE NEEDED: VALIDATION AND ROLLBACK VALIDATION OF LOAD VALUES AT THE TOP OF ROB CHECK THE VALUE OF THE LOAD BY RE-EXECUTING THE LOAD IN CACHE (Pb: TWO CACHE ACCESSES FOR EACH LOAD) OR: MONITOR EVENTS THAT COULD CHANGE THE SPECULATIVE VALUE OF A LOAD BETWEEN THE TIME THE LOAD RETURNS THE VALUE SPECULATIVELY UNTIL THE LOAD COMMITS EVENTS INCLUDE INVALIDATES, UPDATES OR CACHE REPLACEMENTS IN THE NODE S CACHE THESE EVENTS SNOOP THE LOAD Q ROB ROLLBACK USES SAME MECHANISM AS MISPREDICTED BRANCHES OR EXCEPTIONS LOAD VALUE RECALL
64 SPECULATIVE VIOLATIONS OF SEQUENTIAL CONSISTENCY LOAD-LOAD ORDER: USE LOAD VALUE RECALL STORE-LOAD ORDER: USE LOAD VALUE RECALL + STALL LOADS AT TOP OF ROB UNTIL ALL PREVIOUS STOREs HAVE BEEN GLOBALLY PERFORMED LOAD-STORE ORDER: STOREs RETIRE AT TOP OF ROB, BY THAT TIME ALL PREVIOUS LOADS HAVE RETIRED STORE-STORE ORDER: STOREs ARE RETIRED AT TOP OF ROB + STOREs ARE GLOBALLY PERFORMED FROM STORE BUFFER ONE BY ONE IN T.O. PERFORMANCE ISSUES A LOAD MAY REACH THE TOP OF THE ROB BUT CANNOT PERFORM AND IS STALLED BECAUSE OF PRIOR STORES IN THE STORE BUFFER THIS BACKS UP THE ROB (AND OTHER INTERNAL BUFFERS) AND EVENTUALLY STALLS THE PROCESSOR RELAX STORE-LOAD ORDER (TSO)
65 SPECULATIVE TSO VIOLATIONS LOAD-LOAD ORDER: USE LOAD VALUE RECALL STORE-LOAD ORDER: NO NEED TO ENFORCE. THUS VALUE OF LOAD SHOULD NOT BE RECALLED IF ALL PRECEDING PENDING ACCESSES IN THE LOAD/STORE Q ARE STOREs (POSSIBLE OPTIMIZATION) + LOADS DON T WAIT ON STORES IN SB LOAD-STORE ORDER: STOREs RETIRE AT TOP OF ROB STORE-STORE ORDER: STOREs RETIRE AT TOP OF ROB + STOREs ARE GLOBALLY PERFORMED FROM STORE BUFFER IN T.O. PERFORMANCE ISSUES: IF A LONG LATENCY STORE BACKS UP THE STORE BUFFER THEN STORES CANNOT RETIRE, WHICH MAY BACK UP THE ROB AND OTHER Q s AND STALL DISPATCH RELAX ORDERS FURTHER WITH WEAK ORDERING OR RELEASE CONSISTENCY
66 SPECULATIVE EXECUTION OF RMW ACCESSES RMW INSTRUCTIONS ARE MADE OF A LOAD FOLLOWED BY A STORE MUST EXECUTE AS A GROUP AND BE ATOMIC BECAUSE OF THE LOAD, THE VALUE OF THE LOCK IS RETURNED SPECULATIVELY BASED ON THE SPECULATIVE LOCK VALUE THE CRITICAL SECTION IS ENTERED SPECULATIVELY OR THE LOCK IS RETRIED SPECULATIVELY THIS ACTIVITY IS ALL SPECULATIVE IN THE ROB. NO MEMORY UPDATES. LOADs IN RMW ACCESSES MUST REMAIN SUBJECT TO LOAD VALUE RECALL UNTIL THE RMW IS RETIRED IF VIOLATION IS DETECTED LOAD IS ROLLED BACK BECAUSE OF THE STORE, THE RMW ACCESS DOES NOT UPDATE MEMORY (AND CANNOT PERFORM) UNTIL THE TOP OF THE ROB THE LOAD AND THE STORE CAN BE PERFORMED ATOMICALLY IN CACHE WITH A WRITE-INVALIDATE PROTOCOL IF THE STORE CAN EXECUTE AT THE TOP OF THE ROB, THEN NO OTHER THREAD GOT THE LOCK DURING THE TIME THE RMW WAS SPECULATIVE
67 SPECULATIVE EXECUTION OF RMW ACCESSES EXAMPLE: BUSY WAITING ON HIGHLY CONTENDED LOCK Lock: T&S R1, lock Unlock: SW R0, lock BNEZ R1, Lock RET RET ASSUME LOCK BLOCKS Ld RETURNS 1; INVALIDATION COMES IN FOR LOCK ROB Bnez St_1 lock* Ld_1 lock* Bnez St_1 lock* Ld_1 lock* Bnez LOCK IS RELEASED; ROB IS FLUSHED; Ld READS 0 SPECULATIVELY; INV COMES IN St_1 lock* Ld_1 lock* INV lock MUST BE ATOMIC Ins 2 Ins 1 Ret Bnez St_1 lock* Ld_0 lock* IN THIS EXAMPLE, THE THREAD IS LOCKED OUT OF THE CS SPECULATIVELY THEN THE LOCK IS RELEASED, WHICH CAUSES AN INVALIDATION AND ROLLBACK THEN THE Ld IS RE-EXECUTED SPECULATIVELY AND LOCK IS FREE BUT AN INVALIDATION COMES IN BEFORE THE T&S HAS BEEN ABLE TO COMMIT SO THE EXECUTION MUST ROLLBACK AGAIN INV lock
68 SPECULATIVE VIOLATIONS OF WEAK ORDERING Op Sync Sync Op Sync Sync OP-TO-SYNC: ANY ACCESS TO A SYNC VARIABLE MUST BE GLOBALLY PERFORMED ATOMICALLY AT THE TOP OF THE ROB PREVIOUS LOADS HAVE RETIRED PREVIOUS STORES HAVE RETIRED FROM PROCESSOR THE STORES IN THE SB MUST EXECUTE IN CACHE BEFORE THE SYNC CAN START ITS EXECUTION IN CACHE SYNC-TO-OP REGULAR STORES FOLLOWING AN ACCESS TO A SYNC VARIABLE CANNOT PERFORM IN CACHE UNTIL THEY REACH THE TOP OF ROB. REGULAR LOADs RETURN THEIR VALUE SPECULATIVELY AND ARE NOT SUBJECT TO LOAD VALUE RECALL SYNC-TO-SYNC SYNC CAN ONLY EXECUTE IN CACHE AT THE TOP OF ROB PRIOR SYNCs ARE RETIRED BY THEN A LOAD OF A SYNC VARIABLE (INCLUDING THE LOAD IN A RMW ACCESS) CAN RETURN ITS VALUE SPECULATIVELY PROVIDED IT IS SUBJECT TO LOAD VALUE RECALL. Ins 2 Ld a Ret Bnez St_1 lock* Ld_0 lock* EXECUTION IS NOT ROLLED BACK INV a
69 SPECULATIVE VIOLATIONS OF RELEASE CONSISTENCY IN RC, A RELEASE MAY NOT PERFORM UNTIL ALL PREVIOUS ACCESSES ARE GLOBALLY PERFORMED AND ACCESSES FOLLOWING AN ACQUIRE MUST BE DELAYED UNTIL THE ACQUIRE IS GLOBALLY PERFORMED. Acquire-Op: RC REQUIRES THAT ACQUIRES MUST BE PERFORMED BEFORE ANY FOLLOWING REGULAR ACCESS CAN PERFORM. HOWEVER THE VALUE OF REGULAR LOADS MAY BE RETURNED AND USED SPECULATIVELY. REGULAR LOADS ARE NOT SUBJECT TO VALUE RECALL, Op-Release: RELEASES ARE PUT IN THE STORE BUFFER AS SPECIAL STORES BY THAT TIME ALL PREVIOUS LOADS HAVE BEEN EXECUTED RELEASE MUST WAIT IN SB UNTIL ALL PREVIOUS STORES HAVE BEEN PERFORMED Acquire-Acquire & Acquire-Release: ACQUIRES EXECUTE AT THE TOP OF ROB, BEFORE ANY ACQUIRE OR RELEASE HAS A CHANCE TO EXECUTE SYNC LOADS IN ACQUIRES CAN RETURN THEIR VALUE SPECULATIVELY BUT ARE SUBJECT TO VALUE RECALL Release-Release: RELEASES JOIN THE SB ONE BY ONE IN THREAD ORDER RELEASES MUST WAIT IN SB UNTIL ALL PREVIOUS RELEASES HAVE EXECUTED IN CACHE STORES IN SB CAN EXECUTE IN CACHE IN ANY ORDER, EVEN BYPASSING PREVIOUS RELEASES Release-Acquire: ACQUIRES MUST WAIT UNTIL ALL PRIOR RELEASES IN SB ARE PERFORMED IN CACHE STORE BUFFER R S S R S S S R S S
70 8. ADVANCED TOPICS
71 DO WE NEED COHERENCE UNDER WEAK ORDERING? L2 Processors execute from their L1 cache Before a processor can execute a SYNC, it flushes its L1 cache, writing back all dirty block and invalidating Then it executes the SYNC in shared L2 L1 L1 L1 It is coherent if the program is correct It is not if the program is incorrect P P P
72 SPECULATIVE RETIREMENT OF NON-STORE INSTRUCTIONS HOW TO MAKE SEQUENTIAL CONSISTENCY COMPETITIVE WITH RELAXED MODELS IN SPECULATIVE SC, A LOAD AT THE TOP OF THE ROB MUST WAIT UNTIL ALL PRECEDING STORES IN THE STORE BUFFER ARE GLOBALLY PERFORMED BEFORE RETIRING NEW (SCARY!!) IDEA: SPECULATIVE RETIREMENT OF NON-STORE INSTRUCTIONS SPECULATIVELY RETIRE A LOAD AND ALL DEPENDENT NON- STORE INSTRUCTIONS THE LIKELIHOOD THAT THE LOAD WILL BE RECALLED IS VERY LOW THIS DOES NOT HELP TSO, BUT IT HELPS SC
73 SPECULATIVE RETIREMENT OF NON-STORE INSTRUCTIONS HOW TO MAKE SEQUENTIAL CONSISTENCY COMPETITIVE WITH RELAXED MODELS WHEN A LOAD INSTRUCTION REACHES THE TOP OF THE ROB, IS COMPLETE, AND IS STALLED BECAUSE OF PRIOR STORES AND THE PROCESSOR IS BACKED UP BECAUSE OF THAT: THE LOAD IS REMOVED FROM THE ROB AND SPECULATIVELY RETIRES MEANING IT MODIFIES THE ARCHITECTURAL REGISTER AND FREES QUEUES A RECORD FOR THE LOAD IS INSERTED IN A FIFO HISTORY BUFFER FOLLOWING INSTRUCTIONS ARE ALSO RETIRED FROM THE ROB SPECULATIVELY AND RECORDS ARE ALSO INSERTED STORE INSTRUCTIONS ARE PUT IN THE STORE BUFFER HISTORY BUFFER ENTRY CONTAINS THE PC, THE OLD REGISTER VALUE AND THE OLD MAPPING FOR RECOVERY STORES AND BRANCHES ARE NOT INSERTED IN THE HISTORY BUFFER SINCE THEY DO NOT UPDATE ARCHITECTURAL REGISTERS HISTORY BUFFER ENTRIES ARE RECLAIMED AS SOON AS ALL STORES PRIOR TO THEM HAVE RETIRED FROM THE STORE BUFFER

74 SPECULATIVE RETIREMENT OF NON-STORE INSTRUCTIONS HOW TO MAKE SEQUENTIAL CONSISTENCY COMPETITIVE WITH RELAXED MODELS
75 SPECULATIVE RETIREMENT OF NON-STORE INSTRUCTIONS VIOLATION DETECTION INVALIDATION OR REPLACEMENT OF BLOCK WITH SPECULATIVE LOAD RECOVERY IF LOAD IS STILL IN THE ROB, PROCEED AS BEFORE FOR SPECULATIVE LOADS IF LOAD IS SPECULATIVELY RETIRED IN THE HISTORY BUFFER, STATE MUST BE RESTORED BY PROCESSING HISTORY BUFFER ENTRIES IN REVERSE ORDER REMOVE STORES FOLLOWING THE VIOLATING LOAD FROM THE STORE BUFFER SPECULATIVE RETIREMENT OF LOADS CLOSES THE GAP BETWEEN SC AND TSO BECAUSE IT ENABLES THE USE OF STORE BUFFERS IN SC AN ALTERNATIVE IS TO USE A LARGER WINDOW AND SUFFER THE CONSEQUENCES (LONGER CYCLE TIME)
76 SPECULATIVE RETIREMENT OF ALL INSTRUCTIONS A RECORD IS LOGGED IN THE HiQ FOR ALL SPECULATIVELY RETIRED INSTRUCTIONS MODIFYING MACHINE STATE RECORD FOR STORES MUST INCLUDE THE PREVIOUS MEMORY VALUE SO THAT IT CAN BE RESTORED THUS SPECULATIVELY RETIRED STORE MUST EXECUTE AS RMW AS PENDING STORES IN SB PERFORM, THE ENTRIES AT THE TOP OF HiQ ARE DEALLOCATED UP UNTIL THE NEXT PENDING STORE IN SB VIOLATION DETECTION EVERY INVALIDATION/UPDATE, EVERY REMOTE LOAD AND EVERY NODE REPLACEMENT OF A SPECULATIVELY LOADED OR STORED CACHE BLOCK VIOLATION RECOVERY ROLLBACK TO THE FIRST INSTRUCTION IN THREAD ORDER ACCESSING THE FAULTING BLOCK ALL THE MEMORY LOCATIONS ACCESSED IN THE ROLLBACK ARE GUARANTEED TO BE IN THE NODE S CACHE UPON ENDING ROLLBACK FURTHER SPECULATIVE EXECUTION IS INHIBITED WHILE WAITING FOR THE PENDING STORES TO FINISH
SHARED-MEMORY COMMUNICATION
 SHARED-MEMORY COMMUNICATION IMPLICITELY VIA MEMORY PROCESSORS SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES NEED TO SYNCHRONIZE NEED TO KNOW HOW THE HARDWARE INTERLEAVES ACCESSES
SHARED-MEMORY COMMUNICATION IMPLICITELY VIA MEMORY PROCESSORS SHARE SOME MEMORY COMMUNICATION IS IMPLICIT THROUGH LOADS AND STORES NEED TO SYNCHRONIZE NEED TO KNOW HOW THE HARDWARE INTERLEAVES ACCESSES
Computer Architecture
 18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Module 15: "Memory Consistency Models" Lecture 34: "Sequential Consistency and Relaxed Models" Memory Consistency Models. Memory consistency
 Memory Consistency Models Memory consistency SC SC in MIPS R10000 Relaxed models Total store ordering PC and PSO TSO, PC, PSO Weak ordering (WO) [From Chapters 9 and 11 of Culler, Singh, Gupta] [Additional
Memory Consistency Models Memory consistency SC SC in MIPS R10000 Relaxed models Total store ordering PC and PSO TSO, PC, PSO Weak ordering (WO) [From Chapters 9 and 11 of Culler, Singh, Gupta] [Additional
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
Lecture 13: Consistency Models. Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models
 Lecture 13: Consistency Models Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models 1 Coherence Vs. Consistency Recall that coherence guarantees
Lecture 13: Consistency Models Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models 1 Coherence Vs. Consistency Recall that coherence guarantees
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
CMSC Computer Architecture Lecture 15: Memory Consistency and Synchronization. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
NOW Handout Page 1. Memory Consistency Model. Background for Debate on Memory Consistency Models. Multiprogrammed Uniprocessor Mem.
 Memory Consistency Model Background for Debate on Memory Consistency Models CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley for a SAS specifies constraints on the order in which
Memory Consistency Model Background for Debate on Memory Consistency Models CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley for a SAS specifies constraints on the order in which
Memory Consistency Models
 Memory Consistency Models Contents of Lecture 3 The need for memory consistency models The uniprocessor model Sequential consistency Relaxed memory models Weak ordering Release consistency Jonas Skeppstedt
Memory Consistency Models Contents of Lecture 3 The need for memory consistency models The uniprocessor model Sequential consistency Relaxed memory models Weak ordering Release consistency Jonas Skeppstedt
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
M4 Parallelism. Implementation of Locks Cache Coherence
 M4 Parallelism Implementation of Locks Cache Coherence Outline Parallelism Flynn s classification Vector Processing Subword Parallelism Symmetric Multiprocessors, Distributed Memory Machines Shared Memory
M4 Parallelism Implementation of Locks Cache Coherence Outline Parallelism Flynn s classification Vector Processing Subword Parallelism Symmetric Multiprocessors, Distributed Memory Machines Shared Memory
Motivations. Shared Memory Consistency Models. Optimizations for Performance. Memory Consistency
 Shared Memory Consistency Models Authors : Sarita.V.Adve and Kourosh Gharachorloo Presented by Arrvindh Shriraman Motivations Programmer is required to reason about consistency to ensure data race conditions
Shared Memory Consistency Models Authors : Sarita.V.Adve and Kourosh Gharachorloo Presented by Arrvindh Shriraman Motivations Programmer is required to reason about consistency to ensure data race conditions
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Relaxed Memory-Consistency Models
 Relaxed Memory-Consistency Models [ 9.1] In Lecture 13, we saw a number of relaxed memoryconsistency models. In this lecture, we will cover some of them in more detail. Why isn t sequential consistency
Relaxed Memory-Consistency Models [ 9.1] In Lecture 13, we saw a number of relaxed memoryconsistency models. In this lecture, we will cover some of them in more detail. Why isn t sequential consistency
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Overview: Memory Consistency
 Overview: Memory Consistency the ordering of memory operations basic definitions; sequential consistency comparison with cache coherency relaxing memory consistency write buffers the total store ordering
Overview: Memory Consistency the ordering of memory operations basic definitions; sequential consistency comparison with cache coherency relaxing memory consistency write buffers the total store ordering
Symmetric Multiprocessors: Synchronization and Sequential Consistency
 Constructive Computer Architecture Symmetric Multiprocessors: Synchronization and Sequential Consistency Arvind Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology November
Constructive Computer Architecture Symmetric Multiprocessors: Synchronization and Sequential Consistency Arvind Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology November
4 Chip Multiprocessors (I) Chip Multiprocessors (ACS MPhil) Robert Mullins
 Chip Multiprocessors (ACS MPhil) Robert Mullins") 4 Chip Multiprocessors (I) Robert Mullins Overview Coherent memory systems Introduction to cache coherency protocols Advanced cache coherency protocols, memory systems and synchronization covered in the
4 Chip Multiprocessors (I) Robert Mullins Overview Coherent memory systems Introduction to cache coherency protocols Advanced cache coherency protocols, memory systems and synchronization covered in the
Lecture: Consistency Models, TM
 Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) No class on Monday (please watch TM videos) Wednesday: TM wrap-up, interconnection networks 1 Coherence Vs. Consistency
Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) No class on Monday (please watch TM videos) Wednesday: TM wrap-up, interconnection networks 1 Coherence Vs. Consistency
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Today s Outline: Shared Memory Review. Shared Memory & Concurrency. Concurrency v. Parallelism. Thread-Level Parallelism. CS758: Multicore Programming
 CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
Unit 12: Memory Consistency Models. Includes slides originally developed by Prof. Amir Roth
 Unit 12: Memory Consistency Models Includes slides originally developed by Prof. Amir Roth 1 Example #1 int x = 0;! int y = 0;! thread 1 y = 1;! thread 2 int t1 = x;! x = 1;! int t2 = y;! print(t1,t2)!
Unit 12: Memory Consistency Models Includes slides originally developed by Prof. Amir Roth 1 Example #1 int x = 0;! int y = 0;! thread 1 y = 1;! thread 2 int t1 = x;! x = 1;! int t2 = y;! print(t1,t2)!
Switch Gear to Memory Consistency
 Outline Memory consistency equential consistency Invalidation vs. update coherence protocols MI protocol tate diagrams imulation Gehringer, based on slides by Yan olihin 1 witch Gear to Memory Consistency
Outline Memory consistency equential consistency Invalidation vs. update coherence protocols MI protocol tate diagrams imulation Gehringer, based on slides by Yan olihin 1 witch Gear to Memory Consistency
Distributed Shared Memory and Memory Consistency Models
 Lectures on distributed systems Distributed Shared Memory and Memory Consistency Models Paul Krzyzanowski Introduction With conventional SMP systems, multiple processors execute instructions in a single
Lectures on distributed systems Distributed Shared Memory and Memory Consistency Models Paul Krzyzanowski Introduction With conventional SMP systems, multiple processors execute instructions in a single
CS 252 Graduate Computer Architecture. Lecture 11: Multiprocessors-II
 CS 252 Graduate Computer Architecture Lecture 11: Multiprocessors-II Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.eecs.berkeley.edu/~cs252
CS 252 Graduate Computer Architecture Lecture 11: Multiprocessors-II Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.eecs.berkeley.edu/~cs252
Shared Memory Multiprocessors
 Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Cache Coherence. (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri
 Mainak Chaudhuri") Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Page 1. Outline. Coherence vs. Consistency. Why Consistency is Important
 Outline ECE 259 / CPS 221 Advanced Computer Architecture II (Parallel Computer Architecture) Memory Consistency Models Copyright 2006 Daniel J. Sorin Duke University Slides are derived from work by Sarita
Outline ECE 259 / CPS 221 Advanced Computer Architecture II (Parallel Computer Architecture) Memory Consistency Models Copyright 2006 Daniel J. Sorin Duke University Slides are derived from work by Sarita
Lecture: Consistency Models, TM. Topics: consistency models, TM intro (Section 5.6)
") Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) 1 Coherence Vs. Consistency Recall that coherence guarantees (i) that a write will eventually be seen by other processors,
Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) 1 Coherence Vs. Consistency Recall that coherence guarantees (i) that a write will eventually be seen by other processors,
Foundations of the C++ Concurrency Memory Model
 Foundations of the C++ Concurrency Memory Model John Mellor-Crummey and Karthik Murthy Department of Computer Science Rice University johnmc@rice.edu COMP 522 27 September 2016 Before C++ Memory Model
Foundations of the C++ Concurrency Memory Model John Mellor-Crummey and Karthik Murthy Department of Computer Science Rice University johnmc@rice.edu COMP 522 27 September 2016 Before C++ Memory Model
Shared Memory Consistency Models: A Tutorial
 Shared Memory Consistency Models: A Tutorial By Sarita Adve, Kourosh Gharachorloo WRL Research Report, 1995 Presentation: Vince Schuster Contents Overview Uniprocessor Review Sequential Consistency Relaxed
Shared Memory Consistency Models: A Tutorial By Sarita Adve, Kourosh Gharachorloo WRL Research Report, 1995 Presentation: Vince Schuster Contents Overview Uniprocessor Review Sequential Consistency Relaxed
Cache Coherence in Bus-Based Shared Memory Multiprocessors
 Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Lecture 12: TM, Consistency Models. Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations
 Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Concurrent Preliminaries
 Concurrent Preliminaries Sagi Katorza Tel Aviv University 09/12/2014 1 Outline Hardware infrastructure Hardware primitives Mutual exclusion Work sharing and termination detection Concurrent data structures
Concurrent Preliminaries Sagi Katorza Tel Aviv University 09/12/2014 1 Outline Hardware infrastructure Hardware primitives Mutual exclusion Work sharing and termination detection Concurrent data structures
Constructing a Weak Memory Model
 Constructing a Weak Memory Model Sizhuo Zhang 1, Muralidaran Vijayaraghavan 1, Andrew Wright 1, Mehdi Alipour 2, Arvind 1 1 MIT CSAIL 2 Uppsala University ISCA 2018, Los Angeles, CA 06/04/2018 1 The Specter
Constructing a Weak Memory Model Sizhuo Zhang 1, Muralidaran Vijayaraghavan 1, Andrew Wright 1, Mehdi Alipour 2, Arvind 1 1 MIT CSAIL 2 Uppsala University ISCA 2018, Los Angeles, CA 06/04/2018 1 The Specter
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
CS5460: Operating Systems
 CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
Other consistency models
 Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
Multiprocessor Synchronization
 Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Lecture 13: Memory Consistency. + Course-So-Far Review. Parallel Computer Architecture and Programming CMU /15-618, Spring 2014
 Lecture 13: Memory Consistency + Course-So-Far Review Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Beggin Madcon (So Dark the Con of Man) 15-418 students tend to
Lecture 13: Memory Consistency + Course-So-Far Review Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Beggin Madcon (So Dark the Con of Man) 15-418 students tend to
Relaxed Memory Consistency
 Relaxed Memory Consistency Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Relaxed Memory Consistency Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Beyond Sequential Consistency: Relaxed Memory Models
 1 Beyond Sequential Consistency: Relaxed Memory Models Computer Science and Artificial Intelligence Lab M.I.T. Based on the material prepared by and Krste Asanovic 2 Beyond Sequential Consistency: Relaxed
1 Beyond Sequential Consistency: Relaxed Memory Models Computer Science and Artificial Intelligence Lab M.I.T. Based on the material prepared by and Krste Asanovic 2 Beyond Sequential Consistency: Relaxed
Lecture 21: Transactional Memory. Topics: consistency model recap, introduction to transactional memory
 Lecture 21: Transactional Memory Topics: consistency model recap, introduction to transactional memory 1 Example Programs Initially, A = B = 0 P1 P2 A = 1 B = 1 if (B == 0) if (A == 0) critical section
Lecture 21: Transactional Memory Topics: consistency model recap, introduction to transactional memory 1 Example Programs Initially, A = B = 0 P1 P2 A = 1 B = 1 if (B == 0) if (A == 0) critical section
Shared Memory Consistency Models: A Tutorial
 Shared Memory Consistency Models: A Tutorial By Sarita Adve & Kourosh Gharachorloo Slides by Jim Larson Outline Concurrent programming on a uniprocessor The effect of optimizations on a uniprocessor The
Shared Memory Consistency Models: A Tutorial By Sarita Adve & Kourosh Gharachorloo Slides by Jim Larson Outline Concurrent programming on a uniprocessor The effect of optimizations on a uniprocessor The
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
CS252 Spring 2017 Graduate Computer Architecture. Lecture 15: Synchronization and Memory Models Part 2
 CS252 Spring 2017 Graduate Computer Architecture Lecture 15: Synchronization and Memory Models Part 2 Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Project Proposal
CS252 Spring 2017 Graduate Computer Architecture Lecture 15: Synchronization and Memory Models Part 2 Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Project Proposal
Thread-level Parallelism. Synchronization. Explicit multithreading Implicit multithreading Redundant multithreading Summary
 Chapter 11: Executing Multiple Threads Modern Processor Design: Fundamentals of Superscalar Processors Executing Multiple Threads Thread-level parallelism Synchronization Multiprocessors Explicit multithreading
Chapter 11: Executing Multiple Threads Modern Processor Design: Fundamentals of Superscalar Processors Executing Multiple Threads Thread-level parallelism Synchronization Multiprocessors Explicit multithreading
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
Multiprocessor Synchronization
 Multiprocessor Systems Memory Consistency In addition, read Doeppner, 5.1 and 5.2 (Much material in this section has been freely borrowed from Gernot Heiser at UNSW and from Kevin Elphinstone) MP Memory
Multiprocessor Systems Memory Consistency In addition, read Doeppner, 5.1 and 5.2 (Much material in this section has been freely borrowed from Gernot Heiser at UNSW and from Kevin Elphinstone) MP Memory
Multicore Workshop. Cache Coherency. Mark Bull David Henty. EPCC, University of Edinburgh
 Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Sequential Consistency & TSO. Subtitle
 Sequential Consistency & TSO Subtitle Core C1 Core C2 data = 0, 1lag SET S1: store data = NEW S2: store 1lag = SET L1: load r1 = 1lag B1: if (r1 SET) goto L1 L2: load r2 = data; Will r2 always be set to
Sequential Consistency & TSO Subtitle Core C1 Core C2 data = 0, 1lag SET S1: store data = NEW S2: store 1lag = SET L1: load r1 = 1lag B1: if (r1 SET) goto L1 L2: load r2 = data; Will r2 always be set to
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
ECE/CS 757: Advanced Computer Architecture II
 ECE/CS 757: Advanced Computer Architecture II Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri Sohi,
ECE/CS 757: Advanced Computer Architecture II Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri Sohi,
COMP Parallel Computing. CC-NUMA (2) Memory Consistency
 Memory Consistency") COMP 633 - Parallel Computing Lecture 11 September 26, 2017 Memory Consistency Reading Patterson & Hennesey, Computer Architecture (2 nd Ed.) secn 8.6 a condensed treatment of consistency models Coherence
COMP 633 - Parallel Computing Lecture 11 September 26, 2017 Memory Consistency Reading Patterson & Hennesey, Computer Architecture (2 nd Ed.) secn 8.6 a condensed treatment of consistency models Coherence
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
740: Computer Architecture Memory Consistency. Prof. Onur Mutlu Carnegie Mellon University
 740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
Lecture 13: Memory Consistency. + Course-So-Far Review. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 13: Memory Consistency + Course-So-Far Review Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Wanna Be On Your Mind Valerie June (Pushin Against a Stone) Yes,
Lecture 13: Memory Consistency + Course-So-Far Review Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Wanna Be On Your Mind Valerie June (Pushin Against a Stone) Yes,
Relaxed Memory-Consistency Models
 Relaxed Memory-Consistency Models Review. Why are relaxed memory-consistency models needed? How do relaxed MC models require programs to be changed? The safety net between operations whose order needs
Relaxed Memory-Consistency Models Review. Why are relaxed memory-consistency models needed? How do relaxed MC models require programs to be changed? The safety net between operations whose order needs
Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution
 Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution Ravi Rajwar and Jim Goodman University of Wisconsin-Madison International Symposium on Microarchitecture, Dec. 2001 Funding
Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution Ravi Rajwar and Jim Goodman University of Wisconsin-Madison International Symposium on Microarchitecture, Dec. 2001 Funding
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Lecture 5: Cache Coherence. Chris Craik (TA) Carnegie Mellon University
 Carnegie Mellon University") 18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
Data-Centric Consistency Models. The general organization of a logical data store, physically distributed and replicated across multiple processes.
 Data-Centric Consistency Models The general organization of a logical data store, physically distributed and replicated across multiple processes. Consistency models The scenario we will be studying: Some
Data-Centric Consistency Models The general organization of a logical data store, physically distributed and replicated across multiple processes. Consistency models The scenario we will be studying: Some
Using Relaxed Consistency Models
 Using Relaxed Consistency Models CS&G discuss relaxed consistency models from two standpoints. The system specification, which tells how a consistency model works and what guarantees of ordering it provides.
Using Relaxed Consistency Models CS&G discuss relaxed consistency models from two standpoints. The system specification, which tells how a consistency model works and what guarantees of ordering it provides.
Portland State University ECE 588/688. Memory Consistency Models
 Portland State University ECE 588/688 Memory Consistency Models Copyright by Alaa Alameldeen 2018 Memory Consistency Models Formal specification of how the memory system will appear to the programmer Places
Portland State University ECE 588/688 Memory Consistency Models Copyright by Alaa Alameldeen 2018 Memory Consistency Models Formal specification of how the memory system will appear to the programmer Places
Parallel Computer Architecture Spring Memory Consistency. Nikos Bellas
 Parallel Computer Architecture Spring 2018 Memory Consistency Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture 1 Coherence vs Consistency
Parallel Computer Architecture Spring 2018 Memory Consistency Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture 1 Coherence vs Consistency
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II. Prof. Onur Mutlu Carnegie Mellon University 10/12/2012
 18-742 Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II Prof. Onur Mutlu Carnegie Mellon University 10/12/2012 Past Due: Review Assignments Was Due: Tuesday, October 9, 11:59pm. Sohi
18-742 Fall 2012 Parallel Computer Architecture Lecture 16: Speculation II Prof. Onur Mutlu Carnegie Mellon University 10/12/2012 Past Due: Review Assignments Was Due: Tuesday, October 9, 11:59pm. Sohi
CS533 Concepts of Operating Systems. Jonathan Walpole
 CS533 Concepts of Operating Systems Jonathan Walpole Shared Memory Consistency Models: A Tutorial Outline Concurrent programming on a uniprocessor The effect of optimizations on a uniprocessor The effect
CS533 Concepts of Operating Systems Jonathan Walpole Shared Memory Consistency Models: A Tutorial Outline Concurrent programming on a uniprocessor The effect of optimizations on a uniprocessor The effect
Lecture 13: Memory Consistency. + course-so-far review (if time) Parallel Computer Architecture and Programming CMU /15-618, Spring 2017
 Parallel Computer Architecture and Programming CMU /15-618, Spring 2017") Lecture 13: Memory Consistency + course-so-far review (if time) Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Tunes Hello Adele (25) Hello, it s me I was wondering if after
Lecture 13: Memory Consistency + course-so-far review (if time) Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Tunes Hello Adele (25) Hello, it s me I was wondering if after
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Advanced OpenMP. Lecture 3: Cache Coherency
 Advanced OpenMP Lecture 3: Cache Coherency Cache coherency Main difficulty in building multiprocessor systems is the cache coherency problem. The shared memory programming model assumes that a shared variable
Advanced OpenMP Lecture 3: Cache Coherency Cache coherency Main difficulty in building multiprocessor systems is the cache coherency problem. The shared memory programming model assumes that a shared variable
Consistency Models. ECE/CS 757: Advanced Computer Architecture II. Readings. ECE 752: Advanced Computer Architecture I 1. Instructor:Mikko H Lipasti
 ECE/CS 757: Advanced Computer Architecture II Instructor:Mikko H Lipasti Spring 2009 University of Wisconsin Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri Sohi,
ECE/CS 757: Advanced Computer Architecture II Instructor:Mikko H Lipasti Spring 2009 University of Wisconsin Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri Sohi,
Shared Memory Architecture
 1 Multiprocessor Architecture Single global memory space 0,, A 1 Physically partitioned into M physical devices All CPUs access full memory space via interconnection network CPUs communicate via shared
1 Multiprocessor Architecture Single global memory space 0,, A 1 Physically partitioned into M physical devices All CPUs access full memory space via interconnection network CPUs communicate via shared
Potential violations of Serializability: Example 1
 CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
Transaction Management: Introduction (Chap. 16)
") Transaction Management: Introduction (Chap. 16) CS634 Class 14 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke What are Transactions? So far, we looked at individual queries;
Transaction Management: Introduction (Chap. 16) CS634 Class 14 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke What are Transactions? So far, we looked at individual queries;
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 19 Memory Consistency Models
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 19 Memory Consistency Models Krste Asanovic Electrical Engineering and Computer Sciences University of California
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 19 Memory Consistency Models Krste Asanovic Electrical Engineering and Computer Sciences University of California
Processor Architecture
 Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh ymmetric MultiProcessing Each processor in an MP has equal access to all parts of memory same latency and
Cray XE6 Performance Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh ymmetric MultiProcessing Each processor in an MP has equal access to all parts of memory same latency and
Lecture 16: Checkpointed Processors. Department of Electrical Engineering Stanford University
 Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Relaxed Memory-Consistency Models
 Relaxed Memory-Consistency Models [ 9.1] In small multiprocessors, sequential consistency can be implemented relatively easily. However, this is not true for large multiprocessors. Why? This is not the
Relaxed Memory-Consistency Models [ 9.1] In small multiprocessors, sequential consistency can be implemented relatively easily. However, this is not true for large multiprocessors. Why? This is not the
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
EEC 581 Computer Architecture. Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6)
") EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
Cache Coherence and Atomic Operations in Hardware
 Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
CS315A Midterm Solutions
 K. Olukotun Spring 05/06 Handout #14 CS315a CS315A Midterm Solutions Open Book, Open Notes, Calculator okay NO computer. (Total time = 120 minutes) Name (please print): Solutions I agree to abide by the
K. Olukotun Spring 05/06 Handout #14 CS315a CS315A Midterm Solutions Open Book, Open Notes, Calculator okay NO computer. (Total time = 120 minutes) Name (please print): Solutions I agree to abide by the
EECS 470. Lecture 17 Multiprocessors I. Fall 2018 Jon Beaumont
 Lecture 17 Multiprocessors I Fall 2018 Jon Beaumont www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of
Lecture 17 Multiprocessors I Fall 2018 Jon Beaumont www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of
Shared Memory Architectures. Shared Memory Multiprocessors. Caches and Cache Coherence. Cache Memories. Cache Memories Write Operation
 hared Architectures hared Multiprocessors ngo ander ngo@imit.kth.se hared Multiprocessor are often used pecial Class: ymmetric Multiprocessors (MP) o ymmetric access to all of main from any processor A
hared Architectures hared Multiprocessors ngo ander ngo@imit.kth.se hared Multiprocessor are often used pecial Class: ymmetric Multiprocessors (MP) o ymmetric access to all of main from any processor A