Isolation Forest for Anomaly Detection
|
|
|
- Stella Berry
- 5 years ago
- Views:
Transcription
1 Isolation Forest for Anomaly Detection Sahand Hariri PhD Student, MechSE UIUC Matias Carrasco Kind Senior Research Scientist, NCSA LSST Workshop 2018, June 21, NCSA, UIUC
2 Overview Goal: Build a resilient scalable anomaly detection service. Motivation: Astronomical data (both literal and figurative) Algorithm: Extended Isolation Forest Infrastructure: Kubernetes cluster Mapreduce package: Spark














3 Part of the Motivation Astronomy is just one example where data exploration needs to be automated. Large catalogs, Large number of images, many unexpected objects/problems Anomaly detection
4 Isolation Forest (Liu et al IEEE on Data Mining) Few and different to be isolated quicker
5 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data
6 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension y
7 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data
8 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete
9 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete
10 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete
11 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest
12 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest
13 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest Anomalies will be isolated in only a few steps
14 Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a dimension Randomly pick a value in that dimension Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest Anomalies will be isolated in only a few steps Nominal points in more

15 Isolation Forest Single Tree scores for anomaly and nominal points Forest plotted radially. Scores for anomaly and nominal shown as lines
16 Anomaly Detection with Isolation Forest Anomaly Score
17 Anomaly Detection with Isolation Forest Isolation Forest: Model free Computationally efficient Readily applicable to parallelization Readily applicable to high dimensional data Inconsistent scoring observed in score maps
18 Anomaly Detection with Isolation Forest Isolation Forest: Model free Computationally efficient Readily applicable to parallelization Readily applicable to high dimensional data Inconsistent scoring observed in score maps
19 Anomaly Detection with Isolation Forest Isolation Forest: Model free Computationally efficient Readily applicable to parallelization Readily applicable to high dimensional data Inconsistent scoring observed in score maps
20 Anomaly Detection with Isolation Forest
21 Anomaly Detection with Isolation Forest
22 Anomaly Detection with Isolation Forest
23 Anomaly Detection with Isolation Forest


24 Anomaly Detection with Isolation Forest
25 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker
26 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data
27 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept
28 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept Draw a straight line through the data at that value and split data
29 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept Draw a straight line through the data at that value and split data Repeat until tree is complete
30 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept Draw a straight line through the data at that value and split data Repeat until tree is complete
31 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest
32 Anomaly Detection with Extended Isolation Forest Few and different to be isolated quicker For each tree: Get a sample of the data Randomly select a normal vector Randomly select an intercept Draw a straight line through the data at that value and split data Repeat until tree is complete Generate multiple trees forest No artificial extra slicing Same rules about scoring apply Checking for which side of the line the point lies:




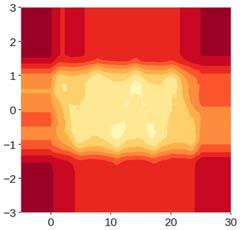
33 Anomaly Detection with Extended Isolation Forest Isolation Forest: Model free Computationally efficient Readily applicable to parallelization Readily applicable to high dimensional data Inconsistent scoring observed in score maps Extended Isolation Forest: Model free Computationally efficient Readily applicable to parallelization Readily applicable to high dimensional data Consistent scoring

34 Anomaly Detection with Extended Isolation Forest
35 Multi-Dimensional Data For N dimensional data, the line becomes an N- 1 dimensional hyperplanes Standard Isolation Forest 2-D 3-D

36 Multi-Dimensional Data For N dimensional data, the line becomes an N- 1 dimensional hyperplanes Extended Isolation Forest 2-D 3-D
37 Multi-Dimensional Data For N dimensional data, the line becomes an N- 1 dimensional hyperplanes With Extended Isolation Forest, there are extension levels
38 Multi-Dimensional Data For N dimensional data, the line becomes an N- 1 dimensional hyperplanes With Extended Isolation Forest, there are extension levels Standard Isolation Forest is recovered Extended Isolation Forest is a natural generalization of the original algorithm
39 Multi-Dimensional Data For N dimensional data, the line becomes an N- 1 dimensional hyperplanes With Extended Isolation Forest, there are extension levels Standard Isolation Forest is recovered Extended Isolation Forest is a natural generalization of the original algorithm





40 Technology Stack For Anomaly Service Use Extended Isolation Forest as core algorithm Use Spark to parallelize trees and scoring Use Redis as a broker communicator To easily deploy in any environment, use Docker For orchestration of Docker containers, use Kubernetes Kubernetes cluster built on top of OpenStack, but it can be deployed also in AWS, GKE, etc.
41 Framework Architecture There are three main components: 1. Storage 2. Computation Stage 3. User Interface / Streaming

42 Framework Architecture Storage: NFS (Kubernetes PV/PVC) Redis RDD for Trees and Spark User Interface: Jupyter notebooks Interactive web app for submitting jobs Streaming service Computation Stage: Spark Master and Workers Communicator with Spark Master Subscription
43 Deployment Kubernetes allows very easy deployment, orchestration, scalability, resilience, replication, workloads and more Federation of services and Jobs From 0 to anomaly service in minutes and config files Scale up/down (spark cluster and front-end) Auto-scaling as an option Prototype support multiple users/projects, batch and streaming process Fault tolerant, disaster recovery
44 Example: Jupyter Notebooks

45 Example: Jupyter Notebooks
46 Examples: User interface
47 Conclusions Open source anomaly detection software package for scientific application using fast and efficient isolation forest Fault tolerant, robust, scalable deployment Train and scoring using Spark Ready-to-deploy infrastructure on Kubernetes Production services for large datasets
48 Thank you! Questions? Sahand Hariri -- NCSA github.com/sahandha sahandhariri.com
49 Variance
50 Convergence
51 Streaming 2 cases: Time evolving data, Time accumulative data Streaming isolation forest exists, not extended We can adapt and retrain trees as new data is presented Replace trees one by one until whole forest is replaced Work with window size to retrain trees
Extended Isolation Forest
 1 Extended Isolation Forest Sahand Hariri, Matias Carrasco Kind, Robert J. Brunner arxiv:1811.02141v1 [cs.lg] 6 Nov 2018 Abstract We present an extension to the model-free anomaly detection algorithm,
1 Extended Isolation Forest Sahand Hariri, Matias Carrasco Kind, Robert J. Brunner arxiv:1811.02141v1 [cs.lg] 6 Nov 2018 Abstract We present an extension to the model-free anomaly detection algorithm,
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
[MS20533]: Implementing Microsoft Azure Infrastructure Solutions
![[MS20533]: Implementing Microsoft Azure Infrastructure Solutions](/thumbs/83/88354663.jpg "[MS20533]: Implementing Microsoft Azure Infrastructure Solutions") [MS20533]: Implementing Microsoft Azure Infrastructure Solutions Length : 5 Days Audience(s) : IT Professionals Level : 300 Technology : Microsoft Products Delivery Method : Instructor-led (Classroom)
[MS20533]: Implementing Microsoft Azure Infrastructure Solutions Length : 5 Days Audience(s) : IT Professionals Level : 300 Technology : Microsoft Products Delivery Method : Instructor-led (Classroom)
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Implementing Microsoft Azure Infrastructure Solutions (20533)
") Implementing Microsoft Azure Infrastructure Solutions (20533) Duration: 5 Days Price: $895 Delivery Option: Attend via MOC On-Demand Students Will Learn Describing Azure architecture components, including
Implementing Microsoft Azure Infrastructure Solutions (20533) Duration: 5 Days Price: $895 Delivery Option: Attend via MOC On-Demand Students Will Learn Describing Azure architecture components, including
MATLAB. Senior Application Engineer The MathWorks Korea The MathWorks, Inc. 2
 1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 CNA1612BU Deploying real-world workloads on Kubernetes and Pivotal Cloud Foundry VMworld 2017 Fred Melo, Director of Technology, Pivotal Merlin Glynn, Sr. Technical Product Manager, VMware Content: Not
CNA1612BU Deploying real-world workloads on Kubernetes and Pivotal Cloud Foundry VMworld 2017 Fred Melo, Director of Technology, Pivotal Merlin Glynn, Sr. Technical Product Manager, VMware Content: Not
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Running MarkLogic in Containers (Both Docker and Kubernetes)
") Running MarkLogic in Containers (Both Docker and Kubernetes) Emma Liu Product Manager, MarkLogic Vitaly Korolev Staff QA Engineer, MarkLogic @vitaly_korolev 4 June 2018 MARKLOGIC CORPORATION Source: http://turnoff.us/image/en/tech-adoption.png
Running MarkLogic in Containers (Both Docker and Kubernetes) Emma Liu Product Manager, MarkLogic Vitaly Korolev Staff QA Engineer, MarkLogic @vitaly_korolev 4 June 2018 MARKLOGIC CORPORATION Source: http://turnoff.us/image/en/tech-adoption.png
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
CloudMan cloud clusters for everyone
 CloudMan cloud clusters for everyone Enis Afgan usecloudman.org This is accessibility! But only sometimes So, there are alternatives BUT WHAT IF YOU WANT YOUR OWN, QUICKLY The big picture A. Users in different
CloudMan cloud clusters for everyone Enis Afgan usecloudman.org This is accessibility! But only sometimes So, there are alternatives BUT WHAT IF YOU WANT YOUR OWN, QUICKLY The big picture A. Users in different
What s in Installing and Configuring Windows Server 2012 (70-410):
:") What s in Installing and Configuring Windows Server 2012 (70-410): The course provides skills and knowledge necessary to implement a core Windows Server 2012 infrastructure in an existing enterprise environment.
What s in Installing and Configuring Windows Server 2012 (70-410): The course provides skills and knowledge necessary to implement a core Windows Server 2012 infrastructure in an existing enterprise environment.
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Contents PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1
 Preface xiii PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1 1 Princi ples of Cloud Computing Systems 3 1.1 Elastic Cloud Systems for Scalable Computing 3 1.1.1 Enabling Technologies for Cloud Computing
Preface xiii PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1 1 Princi ples of Cloud Computing Systems 3 1.1 Elastic Cloud Systems for Scalable Computing 3 1.1.1 Enabling Technologies for Cloud Computing
Kubernetes made easy with Docker EE. Patrick van der Bleek Sr. Solutions Engineer NEMEA
 Kubernetes made easy with Docker EE Patrick van der Bleek Sr. Solutions Engineer NEMEA Docker Enterprise Edition is More than Containers + Orchestration... DOCKER ENTERPRISE EDITION Kubernetes integration
Kubernetes made easy with Docker EE Patrick van der Bleek Sr. Solutions Engineer NEMEA Docker Enterprise Edition is More than Containers + Orchestration... DOCKER ENTERPRISE EDITION Kubernetes integration
利用 Mesos 打造高延展性 Container 環境. Frank, Microsoft MTC
 利用 Mesos 打造高延展性 Container 環境 Frank, Microsoft MTC About Me Developer @ Yahoo! DevOps @ HTC Technical Architect @ MSFT Agenda About Docker Manage containers Apache Mesos Mesosphere DC/OS application = application
利用 Mesos 打造高延展性 Container 環境 Frank, Microsoft MTC About Me Developer @ Yahoo! DevOps @ HTC Technical Architect @ MSFT Agenda About Docker Manage containers Apache Mesos Mesosphere DC/OS application = application
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
FuncX: A Function Serving Platform for HPC. Ryan Chard 28 Jan 2019
 FuncX: A Function Serving Platform for HPC Ryan Chard 28 Jan 2019 Outline - Motivation FuncX: FaaS for HPC Implementation status Preliminary applications - Machine learning inference Automating analysis
FuncX: A Function Serving Platform for HPC Ryan Chard 28 Jan 2019 Outline - Motivation FuncX: FaaS for HPC Implementation status Preliminary applications - Machine learning inference Automating analysis
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager
 Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager Please Note IBM s statements regarding its plans, directions, and intent are subject to change or
Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager Please Note IBM s statements regarding its plans, directions, and intent are subject to change or
Large Scale Computing Infrastructures
 GC3: Grid Computing Competence Center Large Scale Computing Infrastructures Lecture 2: Cloud technologies Sergio Maffioletti GC3: Grid Computing Competence Center, University
GC3: Grid Computing Competence Center Large Scale Computing Infrastructures Lecture 2: Cloud technologies Sergio Maffioletti GC3: Grid Computing Competence Center, University
What Building Multiple Scalable DC/OS Deployments Taught Me about Running Stateful Services on DC/OS
 What Building Multiple Scalable DC/OS Deployments Taught Me about Running Stateful Services on DC/OS Nathan Shimek - VP of Client Solutions at New Context Dinesh Israin Senior Software Engineer at Portworx
What Building Multiple Scalable DC/OS Deployments Taught Me about Running Stateful Services on DC/OS Nathan Shimek - VP of Client Solutions at New Context Dinesh Israin Senior Software Engineer at Portworx
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Convex and Distributed Optimization. Thomas Ropars
 >>> Presentation of this master2 course Convex and Distributed Optimization Franck Iutzeler Jérôme Malick Thomas Ropars Dmitry Grishchenko from LJK, the applied maths and computer science laboratory and
>>> Presentation of this master2 course Convex and Distributed Optimization Franck Iutzeler Jérôme Malick Thomas Ropars Dmitry Grishchenko from LJK, the applied maths and computer science laboratory and
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Beyond 1001 Dedicated Data Service Instances
 Beyond 1001 Dedicated Data Service Instances Introduction The Challenge Given: Application platform based on Cloud Foundry to serve thousands of apps Application Runtime Many platform users - who don
Beyond 1001 Dedicated Data Service Instances Introduction The Challenge Given: Application platform based on Cloud Foundry to serve thousands of apps Application Runtime Many platform users - who don
Large-scale cluster management at Google with Borg
 Large-scale cluster management at Google with Borg Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, John Wilkes Google Inc. Slides heavily derived from John Wilkes s presentation
Large-scale cluster management at Google with Borg Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, John Wilkes Google Inc. Slides heavily derived from John Wilkes s presentation
[MS10992]: Integrating On-Premises Core Infrastructure with Microsoft Azure
![[MS10992]: Integrating On-Premises Core Infrastructure with Microsoft Azure](/thumbs/87/95285048.jpg "[MS10992]: Integrating On-Premises Core Infrastructure with Microsoft Azure") [MS10992]: Integrating On-Premises Core Infrastructure with Microsoft Azure Length : 3 Days Audience(s) : IT Professionals Level : 300 Technology : Azure Delivery Method : Instructor-led (Classroom) Course
[MS10992]: Integrating On-Premises Core Infrastructure with Microsoft Azure Length : 3 Days Audience(s) : IT Professionals Level : 300 Technology : Azure Delivery Method : Instructor-led (Classroom) Course
Real-time personal trainer on the SMACK Jan Anirvan Chakraborty
 Real-time personal trainer on the SMACK stack @honzam399 Jan Machacek @anirvan_c Anirvan Chakraborty Automated personal trainer - muvr Suggests the sequence of exercise sessions Suggests exercises in a
Real-time personal trainer on the SMACK stack @honzam399 Jan Machacek @anirvan_c Anirvan Chakraborty Automated personal trainer - muvr Suggests the sequence of exercise sessions Suggests exercises in a
VMWARE PIVOTAL CONTAINER SERVICE
 DATASHEET VMWARE PIVOTAL CONTAINER SERVICE AT A GLANCE VMware Pivotal Container Service (PKS) is a production-grade Kubernetes-based container solution equipped with advanced networking, a private container
DATASHEET VMWARE PIVOTAL CONTAINER SERVICE AT A GLANCE VMware Pivotal Container Service (PKS) is a production-grade Kubernetes-based container solution equipped with advanced networking, a private container
Containers Infrastructure for Advanced Management. Federico Simoncelli Associate Manager, Red Hat October 2016
 Containers Infrastructure for Advanced Management Federico Simoncelli Associate Manager, Red Hat October 2016 About Me Kubernetes Decoupling problems to hand out to different teams Layer of abstraction
Containers Infrastructure for Advanced Management Federico Simoncelli Associate Manager, Red Hat October 2016 About Me Kubernetes Decoupling problems to hand out to different teams Layer of abstraction
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Understanding and Evaluating Kubernetes. Haseeb Tariq Anubhavnidhi Archie Abhashkumar
 Understanding and Evaluating Kubernetes Haseeb Tariq Anubhavnidhi Archie Abhashkumar Agenda Overview of project Kubernetes background and overview Experiments Summary and Conclusion 1. Overview of Project
Understanding and Evaluating Kubernetes Haseeb Tariq Anubhavnidhi Archie Abhashkumar Agenda Overview of project Kubernetes background and overview Experiments Summary and Conclusion 1. Overview of Project
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Storm. Distributed and fault-tolerant realtime computation. Nathan Marz Twitter
 Storm Distributed and fault-tolerant realtime computation Nathan Marz Twitter Storm at Twitter Twitter Web Analytics Before Storm Queues Workers Example (simplified) Example Workers schemify tweets and
Storm Distributed and fault-tolerant realtime computation Nathan Marz Twitter Storm at Twitter Twitter Web Analytics Before Storm Queues Workers Example (simplified) Example Workers schemify tweets and
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Stream Processing on IoT Devices using Calvin Framework
 Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
CS 398 ACC Streaming. Prof. Robert J. Brunner. Ben Congdon Tyler Kim
 CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
Armon HASHICORP
 Nomad Armon Dadgar @armon Cluster Manager Scheduler Nomad Cluster Manager Scheduler Nomad Schedulers map a set of work to a set of resources Work (Input) Resources Web Server -Thread 1 Web Server -Thread
Nomad Armon Dadgar @armon Cluster Manager Scheduler Nomad Cluster Manager Scheduler Nomad Schedulers map a set of work to a set of resources Work (Input) Resources Web Server -Thread 1 Web Server -Thread
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 CNA2080BU Deep Dive: How to Deploy and Operationalize Kubernetes Cornelia Davis, Pivotal Nathan Ness Technical Product Manager, CNABU @nvpnathan #VMworld #CNA2080BU Disclaimer This presentation may contain
CNA2080BU Deep Dive: How to Deploy and Operationalize Kubernetes Cornelia Davis, Pivotal Nathan Ness Technical Product Manager, CNABU @nvpnathan #VMworld #CNA2080BU Disclaimer This presentation may contain
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
@unterstein #bedcon. Operating microservices with Apache Mesos and DC/OS
 @unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
@unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase. Chen Zhang Hans De Sterck University of Waterloo
 CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
ELASTIC DATA PLATFORM
 SERVICE OVERVIEW ELASTIC DATA PLATFORM A scalable and efficient approach to provisioning analytics sandboxes with a data lake ESSENTIALS Powerful: provide read-only data to anyone in the enterprise while
SERVICE OVERVIEW ELASTIC DATA PLATFORM A scalable and efficient approach to provisioning analytics sandboxes with a data lake ESSENTIALS Powerful: provide read-only data to anyone in the enterprise while
Using the SDACK Architecture to Build a Big Data Product. Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver
 Apache Big Data NA 2016 Vancouver") Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow
 1 IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow Kafka-Native End-to-End IoT Data Integration and Processing Kai Waehner - Technology Evangelist kontakt@kai-waehner.de - LinkedIn Twitter :
1 IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow Kafka-Native End-to-End IoT Data Integration and Processing Kai Waehner - Technology Evangelist kontakt@kai-waehner.de - LinkedIn Twitter :
Document Sub Title. Yotpo. Technical Overview 07/18/ Yotpo
 Document Sub Title Yotpo Technical Overview 07/18/2016 2015 Yotpo Contents Introduction... 3 Yotpo Architecture... 4 Yotpo Back Office (or B2B)... 4 Yotpo On-Site Presence... 4 Technologies... 5 Real-Time
Document Sub Title Yotpo Technical Overview 07/18/2016 2015 Yotpo Contents Introduction... 3 Yotpo Architecture... 4 Yotpo Back Office (or B2B)... 4 Yotpo On-Site Presence... 4 Technologies... 5 Real-Time
YOUR APPLICATION S JOURNEY TO THE CLOUD. What s the best way to get cloud native capabilities for your existing applications?
 YOUR APPLICATION S JOURNEY TO THE CLOUD What s the best way to get cloud native capabilities for your existing applications? Introduction Moving applications to cloud is a priority for many IT organizations.
YOUR APPLICATION S JOURNEY TO THE CLOUD What s the best way to get cloud native capabilities for your existing applications? Introduction Moving applications to cloud is a priority for many IT organizations.
IBM Compose Managed Platform for Multiple Open Source Databases
 IBM Compose Managed Platform for Multiple Source Databases Source for Source for Data Layer Blueprint with Compose Source for Comprehensive Catalogue for Simplified Scoping Scalable Platform for FutureProof
IBM Compose Managed Platform for Multiple Source Databases Source for Source for Data Layer Blueprint with Compose Source for Comprehensive Catalogue for Simplified Scoping Scalable Platform for FutureProof
An Introduction to Kubernetes
 8.10.2016 An Introduction to Kubernetes Premys Kafka premysl.kafka@hpe.com kafkapre https://github.com/kafkapre { History }???? - Virtual Machines 2008 - Linux containers (LXC) 2013 - Docker 2013 - CoreOS
8.10.2016 An Introduction to Kubernetes Premys Kafka premysl.kafka@hpe.com kafkapre https://github.com/kafkapre { History }???? - Virtual Machines 2008 - Linux containers (LXC) 2013 - Docker 2013 - CoreOS
INDIGO-DataCloud Architectural Overview
 INDIGO-DataCloud Architectural Overview RIA-653549 Giacinto Donvito (INFN) INDIGO-DataCloud Technical Director 1 st INDIGO-DataCloud Periodic Review Bologna, 7-8 November 2016 Outline General approach
INDIGO-DataCloud Architectural Overview RIA-653549 Giacinto Donvito (INFN) INDIGO-DataCloud Technical Director 1 st INDIGO-DataCloud Periodic Review Bologna, 7-8 November 2016 Outline General approach
Designing Windows Server 2008 Network and Applications Infrastructure
 Designing Windows Server 2008 Network and Applications Infrastructure Course No. 6435B - 5 Days Instructor-led, Hands-on Introduction This five-day course will provide students with an understanding of
Designing Windows Server 2008 Network and Applications Infrastructure Course No. 6435B - 5 Days Instructor-led, Hands-on Introduction This five-day course will provide students with an understanding of
20533B: Implementing Microsoft Azure Infrastructure Solutions
 20533B: Implementing Microsoft Azure Infrastructure Solutions Course Details Course Code: Duration: Notes: 20533B 5 days This course syllabus should be used to determine whether the course is appropriate
20533B: Implementing Microsoft Azure Infrastructure Solutions Course Details Course Code: Duration: Notes: 20533B 5 days This course syllabus should be used to determine whether the course is appropriate
Streaming & Apache Storm
 Streaming & Apache Storm Recommended Text: Storm Applied Sean T. Allen, Matthew Jankowski, Peter Pathirana Manning 2010 VMware Inc. All rights reserved Big Data! Volume! Velocity Data flowing into the
Streaming & Apache Storm Recommended Text: Storm Applied Sean T. Allen, Matthew Jankowski, Peter Pathirana Manning 2010 VMware Inc. All rights reserved Big Data! Volume! Velocity Data flowing into the
Module Day Topic. 1 Definition of Cloud Computing and its Basics
 Module Day Topic 1 Definition of Cloud Computing and its Basics 1 2 3 1. How does cloud computing provides on-demand functionality? 2. What is the difference between scalability and elasticity? 3. What
Module Day Topic 1 Definition of Cloud Computing and its Basics 1 2 3 1. How does cloud computing provides on-demand functionality? 2. What is the difference between scalability and elasticity? 3. What
HIGH AVAILABILITY AND DISASTER RECOVERY FOR IMDG VLADIMIR KOMAROV, MIKHAIL GORELOV SBERBANK OF RUSSIA
 HIGH AVAILABILITY AND DISASTER RECOVERY FOR IMDG VLADIMIR KOMAROV, MIKHAIL GORELOV SBERBANK OF RUSSIA 1 ABOUT SPEAKERS Vladimir Komarov Enterprise IT Architect vikomarov@sberbank.ru in Sberbank since 2010.
HIGH AVAILABILITY AND DISASTER RECOVERY FOR IMDG VLADIMIR KOMAROV, MIKHAIL GORELOV SBERBANK OF RUSSIA 1 ABOUT SPEAKERS Vladimir Komarov Enterprise IT Architect vikomarov@sberbank.ru in Sberbank since 2010.
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Designing MQ deployments for the cloud generation
 Designing MQ deployments for the cloud generation WebSphere User Group, London Arthur Barr, Senior Software Engineer, IBM MQ 30 th March 2017 Top business drivers for cloud 2 Source: OpenStack user survey,
Designing MQ deployments for the cloud generation WebSphere User Group, London Arthur Barr, Senior Software Engineer, IBM MQ 30 th March 2017 Top business drivers for cloud 2 Source: OpenStack user survey,
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Personalizing Netflix with Streaming datasets
 Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Spark and Flink running scalable in Kubernetes Frank Conrad
 Spark and Flink running scalable in Kubernetes Frank Conrad Architect @ apomaya.com scalable efficient low latency processing 1 motivation, use case run (external, unknown trust) customer spark / flink
Spark and Flink running scalable in Kubernetes Frank Conrad Architect @ apomaya.com scalable efficient low latency processing 1 motivation, use case run (external, unknown trust) customer spark / flink
Kuberiter White Paper. Kubernetes. Cloud Provider Comparison Chart. Lawrence Manickam Kuberiter Inc
 Kuberiter White Paper Kubernetes Cloud Provider Comparison Chart Lawrence Manickam Kuberiter Inc Oct 2018 Executive Summary Kubernetes (K8S) has become the de facto standard for Cloud Application Deployments.
Kuberiter White Paper Kubernetes Cloud Provider Comparison Chart Lawrence Manickam Kuberiter Inc Oct 2018 Executive Summary Kubernetes (K8S) has become the de facto standard for Cloud Application Deployments.
Onto Petaflops with Kubernetes
 Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Facilitating Collaborative Analysis in SWAN
 Facilitating Collaborative Analysis in SWAN E. Tejedor, D. Castro, D. Piparo, P. Mato E. Bocchi, J. Moscicki, M. Lamanna, P. Kothuri https://swan.cern.ch July 11th, 2018 CHEP 2018, Sofia (Bulgaria) Introduction
Facilitating Collaborative Analysis in SWAN E. Tejedor, D. Castro, D. Piparo, P. Mato E. Bocchi, J. Moscicki, M. Lamanna, P. Kothuri https://swan.cern.ch July 11th, 2018 CHEP 2018, Sofia (Bulgaria) Introduction
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Declarative Modeling for Cloud Deployments
 Declarative Modeling for Cloud Deployments Giuseppe Attardi Department of Distributed Computing & Storage OpenStack Day Italia Roma 21/9/2018 GARR Federated Cloud Computing Platform Objectives GARR Offer
Declarative Modeling for Cloud Deployments Giuseppe Attardi Department of Distributed Computing & Storage OpenStack Day Italia Roma 21/9/2018 GARR Federated Cloud Computing Platform Objectives GARR Offer
SQL Server Machine Learning Marek Chmel & Vladimir Muzny
 SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
Cloud I - Introduction
 Cloud I - Introduction Chesapeake Node.js User Group (CNUG) https://www.meetup.com/chesapeake-region-nodejs-developers-group START BUILDING: CALLFORCODE.ORG 3 Agenda Cloud Offerings ( Cloud 1.0 ) Infrastructure
Cloud I - Introduction Chesapeake Node.js User Group (CNUG) https://www.meetup.com/chesapeake-region-nodejs-developers-group START BUILDING: CALLFORCODE.ORG 3 Agenda Cloud Offerings ( Cloud 1.0 ) Infrastructure
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Enhanced Model Deployment in GAMS
 Enhanced Model Deployment in GAMS Using R/Shiny to deploy and visualize GAMS models in a Web Interface Lutz Westermann Frederik Proske GAMS Software GmbH GAMS Development Corp. GAMS Software GmbH www.gams.com
Enhanced Model Deployment in GAMS Using R/Shiny to deploy and visualize GAMS models in a Web Interface Lutz Westermann Frederik Proske GAMS Software GmbH GAMS Development Corp. GAMS Software GmbH www.gams.com
IBM Data Science Experience (DSX) Partner Application Validation Quick Guide
 Partner Application Validation Quick Guide") IBM Data Science Experience (DSX) Partner Application Validation Quick Guide VERSION: 2.0 DATE: Feb 15, 2018 EDITOR: D. Rangarao Table of Contents 1 Overview of the Application Validation Process... 3
IBM Data Science Experience (DSX) Partner Application Validation Quick Guide VERSION: 2.0 DATE: Feb 15, 2018 EDITOR: D. Rangarao Table of Contents 1 Overview of the Application Validation Process... 3
Oh.. You got this? Attack the modern web
 Oh.. You got this? Attack the modern web HELLO DENVER!...Known for more than recreational stuff 2 WARNING IDK 2018 Moses Frost. @mosesrenegade This talk may contain comments or opinions that at times may
Oh.. You got this? Attack the modern web HELLO DENVER!...Known for more than recreational stuff 2 WARNING IDK 2018 Moses Frost. @mosesrenegade This talk may contain comments or opinions that at times may
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
VMworld 2018 Content: Not for publication or distribution
 Hybrid IT: HPE s composable, software-defined, dynamic datacenter vision Speaker name and title Month day, year Today s accidental architecture is hybrid by default Describe how IT infrastructure has become
Hybrid IT: HPE s composable, software-defined, dynamic datacenter vision Speaker name and title Month day, year Today s accidental architecture is hybrid by default Describe how IT infrastructure has become
Understanding the latent value in all content
 Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
TEN LAYERS OF CONTAINER SECURITY
 TEN LAYERS OF CONTAINER SECURITY Tim Hunt Kirsten Newcomer May 2017 ABOUT YOU Are you using containers? What s your role? Security professionals Developers / Architects Infrastructure / Ops Who considers
TEN LAYERS OF CONTAINER SECURITY Tim Hunt Kirsten Newcomer May 2017 ABOUT YOU Are you using containers? What s your role? Security professionals Developers / Architects Infrastructure / Ops Who considers
#techsummitch
 www.thomasmaurer.ch #techsummitch Justin Incarnato Justin Incarnato Microsoft Principal PM - Azure Stack Hyper-scale Hybrid Power of Azure in your datacenter Azure Stack Enterprise-proven On-premises
www.thomasmaurer.ch #techsummitch Justin Incarnato Justin Incarnato Microsoft Principal PM - Azure Stack Hyper-scale Hybrid Power of Azure in your datacenter Azure Stack Enterprise-proven On-premises
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Microsoft Azure Stack Hybrid Cloud. The Modern System Architecture
 Microsoft & itnetx 2017 Microsoft Azure Stack Hybrid Cloud. The Modern System Architecture Uwe Lüthy PTS at Microsoft www.microsoft.com Thomas Maurer Solution Architect at itnetx Microsoft MVP / P-TSP
Microsoft & itnetx 2017 Microsoft Azure Stack Hybrid Cloud. The Modern System Architecture Uwe Lüthy PTS at Microsoft www.microsoft.com Thomas Maurer Solution Architect at itnetx Microsoft MVP / P-TSP
Making Non-Distributed Databases, Distributed. Ioannis Papapanagiotou, PhD Shailesh Birari
 Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
RailCloud: A Reliable PaaS Cloud for Railway Applications
 Platzhalter für Bild, Bild auf Titelfolie hinter das Logo einsetzen RailCloud: A Reliable PaaS Cloud for Railway Applications Bijun Li, Rüdiger Kapitza TU Braunschweig 06.10.2016 This work is supported
Platzhalter für Bild, Bild auf Titelfolie hinter das Logo einsetzen RailCloud: A Reliable PaaS Cloud for Railway Applications Bijun Li, Rüdiger Kapitza TU Braunschweig 06.10.2016 This work is supported
Distributed Data on Distributed Infrastructure. Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere
 Distributed Data on Distributed Infrastructure Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere Kunal Kusoorkar Director Solutions Engineering, ArangoDB @neunhoef Jörg Schad Claudius
Distributed Data on Distributed Infrastructure Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere Kunal Kusoorkar Director Solutions Engineering, ArangoDB @neunhoef Jörg Schad Claudius
Windows Azure Services - At Different Levels
 Windows Azure Windows Azure Services - At Different Levels SaaS eg : MS Office 365 Paas eg : Azure SQL Database, Azure websites, Azure Content Delivery Network (CDN), Azure BizTalk Services, and Azure
Windows Azure Windows Azure Services - At Different Levels SaaS eg : MS Office 365 Paas eg : Azure SQL Database, Azure websites, Azure Content Delivery Network (CDN), Azure BizTalk Services, and Azure
Microsoft Operations Management Suite (OMS) Fernando Andreazi RED CLOUD
 Fernando Andreazi RED CLOUD") Microsoft Operations Management Suite (OMS) Fernando Andreazi RED CLOUD Management as a Service Data analytics Shifting landscape at play Modern management Micro-services and containers Cloud Migrations
Microsoft Operations Management Suite (OMS) Fernando Andreazi RED CLOUD Management as a Service Data analytics Shifting landscape at play Modern management Micro-services and containers Cloud Migrations
Exam : Implementing a Cloud Based Infrastructure
 Exam 70-414: Implementing a Cloud Based Infrastructure Course Overview This course teaches students about creating the virtualization infrastructure, planning and deploying virtual machines, monitoring,
Exam 70-414: Implementing a Cloud Based Infrastructure Course Overview This course teaches students about creating the virtualization infrastructure, planning and deploying virtual machines, monitoring,