QUIZ: Buffer replacement policies
|
|
|
- Lucy Turner
- 6 years ago
- Views:
Transcription
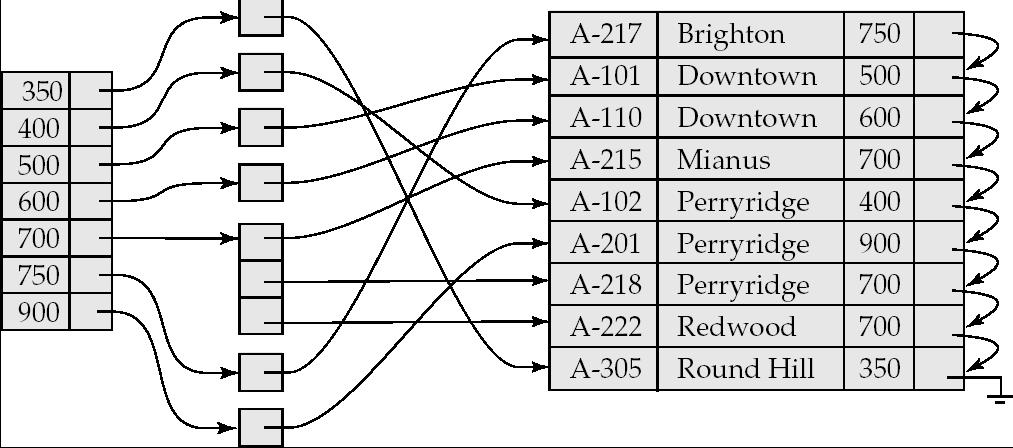
1 QUIZ: Buffer replacement policies Compute join of 2 relations r and s by nested loop: for each tuple tr of r do for each tuple ts of s do if the tuples tr and ts match do something that doesn t require disk access Assume that: tr has 3 tuples ts has 5 tuples All tuples have the same size There is only one buffer, and it can hold 5 tuples total How many disk accesses are needed for the following replacement algorithms: LRU MRU 11.1
2 QUIZ: Buffer replacement policies Compute join of 2 relations r and s by nested loop: for each tuple tr of r do for each tuple ts of s do if the tuples tr and ts match do something Assume that: r has 3 tuples s has 5 tuples All tuples have the same size There is a separate buffer for each table: r buffer can hold 2 tuples, s buffer can hold 3 tuples. How many disk accesses are needed for the following replacement algorithms: LRU(tr)/LRU(ts) LRU(tr)/MRU(ts) These questions are to be solved in the lab; they re included here for reference. 11.2
3 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See for conditions on re-use
4 Basic Concepts Indexing mechanisms are used to speed up access to data. Search Key - attribute to set of attributes used to look up records in a file. An index file consists of records (called index entries) of the form search-key pointer Indices are typically much smaller than the original, e.g.: Table of contents in a book Index in a book Catalog in a library Inventory in a warehouse 11.4
5 Basic Concepts search-key pointer Two basic kinds of indices: Ordered indices: search keys are stored in sorted order Hash indices: search keys are distributed uniformly across buckets using a hash function. 11.5
6 Index Evaluation Metrics What are the access types supported efficiently, e.g.: records with a specified value in the attribute? records with an attribute value falling in a specified range of values? all records in the file? Access time Insertion time Deletion time Space overhead 11.6

7 11.2 Ordered Indices To use an ordered index, we need an index-sequential file = file that is stored sequentially, according to some attribute: This attribute (PK?) will be used as primary index 11.7
8 11.2 Ordered Indices In an ordered index, index entries are stored sorted on the search key value E.g. author catalog in library. Primary index: in a sequentially ordered file, it is the index whose search key specifies the sequential order of the file. Also called clustering index The search key of a primary index is usually (but not necessarily) the PK. Secondary index: an index whose search key specifies an order different from the sequential order of the file. Also called non-clustering index. 11.8
9 QUIZ Is this index primary or secondary? Explain! 11.9

10 Solution Is this index primary or secondary? A: Secondary, b/c the file is not physically sorted on the search key. But what is the search key (Name) has duplicates? 11.10
11 Secondary Index with duplicates Secondary index on salary field of instructor If the search key can have duplicates, we add another level of indirection: The index entry points to a bucket that contains pointers to all the physical records with that particular search-key value


12 Ordered index: Dense Dense index There is an index record for every search-key value E.g.: Dense and primary index on ID attribute (PK) of instructor table 11.12


13 Ordered index: Dense E.g.: Dense and primary index on dept_name, with instructor file sorted on dept_name (not PK) 11.13

14 Ordered index: Sparse Sparse Index: contains index records for only some of the search-key values. It is applicable only as primary index, i.e. when the records are physically ordered on the search-key 11.14
15 Ordered index: Sparse Algorithm for locating a record with search-key value K: Find index record with largest search-key value < K Search the file sequentially starting at the record to which the index record points 11.15

16 Ordered index: Sparse Compared to dense indices, a sparse index: Requires less space and less maintenance overhead for insertions and deletions. It is slower for locating records, b/c it requires multiple accesses to the file. Good tradeoff: sparse index with an index entry for every block in file, corresponding to least search-key value in the block
17 Quick review QUIZ What are the two main type of indices used in DBMS? 11.17
18 Solution What are the two main type of indices used in DBMS? Ordered index Hash index 11.18
19 Quick review QUIZ What are two classifications for ordered indices? 11.19
20 Solution What are two classifications for ordered indices? 1. Primary index (the one on which the physical file is sorted) vs. secondary index (not the one on which the physical file is sorted). 2. Dense index (contains all keys) vs. sparse index (not all keys are present)

21 QUIZ Which index is dense and which is sparse? Database Source: System Concepts - 6 th Edition 11.21

22 Solution Which index is dense and which is sparse? Database Source: System Concepts - 6 th Edition 11.22
23 QUIZ The index pictured is primary and sparse. Can there be secondary sparse indices? Give an example or explain why it s not possible
24 Solution The index pictured is primary and sparse. Can there be secondary sparse indices? No, b/c if we searched for a key that s not in the index, it would be impossible to know where it was in the file! 11.24


25 QUIZ: Classify these indices as primary/secondary and dense/sparse? 11.25
26 QUIZ: Classify these indices as primary/secondary and dense/sparse Images source:
27 QUIZ: What is the difference between these secondary indices? 11.27
28 A: In the one on the right, the pointers are approximate they point to the correct block, but not to the actual record within the block 11.28
29 Performance of ordered indices Pro: substantial speed increase when searching for records. Con: when a table in the DB is modified, every index on that file(s) storing the table must be updated. Pro: Sequential scan using primary index is efficient Con: sequential scan using a secondary index is expensive Each record access may fetch a new block from disk Block fetch requires about 5 to 10 ms (HDD), versus ns for main memory access (RAM) 11.29
30 Hierarchical/Multilevel Index For a large table, the primary index may not fit in main memory store it on disk access becomes expensive. Solution: treat the primary index, kept on disk, as a sequential file and construct a sparse index on it. outer index a sparse index of primary index inner index the primary index file 11.30

31 Two-level index 11.31
32 Hierarchical/Multilevel Index If even the outer index is too large to fit in main memory, yet another level of indexing can be created (three-level), and so on. Overhead is introduced: Indices at all levels must be updated on insertion or deletion of records in/from the file! 11.32

33 Index Update: Deletion Single-level index entry deletion: Dense indices deletion of search-key is similar to file record deletion
34 Index Update: Deletion Single-level index entry deletion: Sparse indices? 11.34
35 Index Update: Deletion Single-level index entry deletion: Sparse indices if an entry for the search key exists in the index, it is deleted by replacing the entry in the index with the next search-key value in the file (in search-key order). If the next search-key value already has an index entry, the entry is deleted instead of being replaced
36 Index Update: Insertion Single-level index insertion: Perform a lookup using the search-key value appearing in the record to be inserted. Dense indices if the search-key value does not appear in the index, insert it. Sparse indices if index stores an entry for each block of the file, no change needs to be made to the index unless a new block is created. If a new block is created, the first search-key value appearing in the new block is inserted into the index. Multilevel insertion and deletion: The algorithms are simple extensions of the single-level algorithms 11.36
37 Disadvantages of indexed-sequential files Performance of all operations degrades as file grows. Periodic reorganization of entire file is required E.g. insertion of a tuple requires either: Overflow block, or Shifting of all records following it EOL 1
38 11.3 B + -Tree Index Files B + -tree indices are an alternative to indexed-sequential files. B + -tree is a type of balanced tree. a.k.a. skinny tree 11.38
39 11.3 B + -Tree Index Files Why do we need balanced trees? Most operations in a tree (search, insert, delete) are Big-Oh of the height 11.39
40 B + -Tree At most n 1 keys and n pointers in each node. (n = 4 here) Nodes may be only partially filled All leaves must be on the same level To avoid skinny trees, all nodes except the root and leaves must have at least n/2 keys. We say that the fill factor is at least 50%. Ceiling function Database Image System source: Concepts th Edition 11.40

41 There are 3 types of pointers in a B + -Tree Those inside the tree point to other nodes of the tree. Horizontal from one leaf to the next Those in the leaves point to the actual tuple of data on the disk. Database Image System source: Concepts th Edition 11.41
42 Redo the figure on the prev. slide to show the entire setup for the tree index, like this: 11.42
 All keys x in the subtree pointed to by P i lie in between the two adjacent keys: K i-1 x < K i")
43 B + -Tree Node Structure The keys are logically in between the pointers The search-keys in a node are ordered K 1 < K 2 < K 3 <... < K n 1 (Initially assume no duplicate keys, address duplicates later) All keys x in the subtree pointed to by P i lie in between the two adjacent keys: K i-1 x < K i Sometimes we write informally: K i-1 P i < K i 11.43

44 Complete the hand-drawn figure on the prev. slide to include the left-most and right-most pointers, like this: 11.44
45 Completing the definition of B + -tree Each internal node (i.e. not root or leaf) has at least n/2 pointers (children). A leaf node has at least (n 1)/2 keys. Special cases: If the root is not a leaf, it has at least 2 children. If the root is a leaf (i.e. there are no other nodes in the tree!), there are no restrictions - it can have between 0 and (n 1) values. In many applications, the fill factor can be adjusted, even with separate values for leaves and internal nodes! 11.45

46 Leaf Nodes in B + -Trees Properties of a leaf node: For i = 1, 2,..., n 1, pointer P i points to a file record with search-key value K i, If L i, L j are leaf nodes and i < j, L i s search-key values are less than or equal to L j s search-key values P n points to next leaf node in search-key order 11.46
47 The previous slides contain all the formal requirements that a B+ tree must fulfill To do for next time: List on one page all the requirements (include in your memory sheet!) 11.47
48 B + tree example Find: The value of n The fill limit for the leaf nodes (# of keys) The fill limit for internal nodes (# of pointers/children) The fill limit for the root Is this a valid B+ tree? 11.48
49 B + tree example n = 6 (max # of pointers/children) Leaf nodes must have between at least 3 keys, acc. to fmla. (n 1)/2. Internal nodes must have between at least 3 children, acc. to fmla. n/2. Root must have at least 2 children, since it s not the only node in the tree
50 Another B + tree example Find: The value of n The fill limit for the leaf nodes (# of keys) The fill limit for internal nodes (# of pointers/children) The fill limit for the root Is this a valid B+ tree? 11.50
51 B or B+ tree? Not in text B+ trees are B trees with two additional conditions: In B trees, it is allowed for pointers to records to be placed anywhere in the tree, whereas in B+ trees these pointers to data can only be placed in the leaves. B trees don t have the horizontal pointers from one leaf to the next. Food for thought: Why are these features better for the operation of a DBMS? 11.51
52 To find record with search-key value V: Queries on B + -Trees 1. C=root 2. While C is not a leaf node { 1. Let K i be the smallest key in C such that V K i. 2. If no such exists set C = last non-null pointer in C 3. Else if (V = K i ) set C = P i Else set C = P i } //end while 3. Let K i be the smallest key in C such that K i = V 1. If there is such a value i, follow pointer P i to desired tuple on disk 2. Else no record with search-key value V exists
53 QUIZ: Search for key 25 in this B+ tree
54 QUIZ: Search for key 85 in this B+ tree 11.54
55 QUIZ: Search for key 55 in this B+ tree 11.55
56 Remarks on B + -trees Since the inter-node connections are done by pointers, logically close blocks need not be physically close. The non-leaf levels of the B + -tree form a hierarchy of sparse indices. Insertions and deletions to the main file can be handled efficiently, as the index can be restructured in logarithmic time (next slides)
57 Remarks on B + -trees The B + -tree contains a relatively small number of levels Level below root has at least 2* n/2 values Next level has at least 2* n/2 * n/2 values.. etc. If there are K search-key values in the file, the length of the path (tree height + 1) is no more than log n/2 (K) Thus searches can be conducted efficiently. See pp of Levitin s Algorithms 3 rd ed. for the complete derivation and the exact formula! 11.57
58 Efficiency of Queries on B +- Trees n is typically around 100 K = 1 million search key values Conclusion: L log 50 (1,000,000) = 4 tree nodes are accessed in a lookup. Plus another disk access to retrieve the data! B+ trees tend to be fat and short Contrast this with a balanced binary tree with 1 million search key values around 20 tree nodes are accessed in a lookup! 11.58
59 Your turn! Assume: K =10 million search key values Size of disk block = 8 KB 100 Bytes per entry (i.e. key + pointer together) n =?? Accessing each block on the HDD requires 5 ms Find and compare the time needed to access the data with: B+ tree index Binary tree index Sequential search of a non-indexed file Assume each key is part of a 256-Byte record
60 Your turn! Assume: K =10 million search key values Size of disk block = 8 KB 100 Bytes per entry (i.e. key + pointer together) n = 8 KB / 100 Bytes 80 Accessing each block on the HDD requires 5 ms Find and compare the time needed to access the data with: B+ tree index Binary tree index Sequential search of a non-indexed file Assume each key is part of a 256-Byte record

61 Your turn! Assume: K =10 million search key values Size of disk block = 8 KB 100 Bytes per entry (i.e. key + pointer together) n = 8 KB / 100 Bytes 80 Accessing each block on the HDD requires 5 ms Find and compare the time needed to access the data with: B+ tree index Binary tree index Sequential search of a non-indexed file Assume each key is part of a 256-Byte record
62 Updates on B + -Trees: Insertion 1. Find the leaf node in which the search-key value would appear 2. If the search-key value is already present in the leaf node 1. Add record to the file (duplicate!) 2. If necessary add a pointer to the bucket. 3. If the search-key value is not present, then 1. add the record to the main file (and create a bucket if necessary) 2. If there is room in the leaf node, insert (key-value, pointer) pair in the leaf node 3. Otherwise, split the node (along with the new (key-value, pointer) entry) as discussed in the next slide
63 Insertion may require splitting node(s) Splitting a leaf node: take the n (search-key value, pointer) pairs (including the one being inserted) in sorted order. Place the first n/2 in the original node, and the rest in a new node. let the new node be p, and let k be the least key value in p. Insert (k,p) in the parent of the node being split. If the parent is full, split it and propagate the split further up. Splitting of nodes proceeds upwards till a node that is not full is found. In the worst case the root node may be split increasing the height of the tree by 1. EXAMPLES 11.63

64 B + -Tree insertion example 1 How to split leaf nodes: 1. Split node containing Brandt, Califieri and Crick. 2. Insert the FIRST key in the RIGHT node (Califieri) into parent 11.64
65 B + -Tree insertion example 2 How to split non-leaf nodes: 1. Same as leaf nodes, but 2. The key propagating up (Gold) does not stay on the current level B + -Tree before and after insertion of Lamport 11.65
66 QUIZ: Insert keys 21, 22, 23 in this B+ tree 11.66
67 Read: Deletion (Examples in the lab) 11.67
68 Ways to handle non-unique search keys 1. Store duplicate key only once in the tree, and create bucket of duplicates as separate blocks. Problems: How to deal with variable-sized buckets? What to do when a bucket becomes full? (Chain of buckets?) How to delete from buckets? 11.68
69 Ways to handle non-unique search keys 2. Make search key unique by adding a unique recordidentifier, a.k.a. an uniquifier attribute Extra storage overhead for keys Simpler code for insertion/deletion Widely used What support does PostgreSQL offer for uniquifiers? 11.69
70 See PostgreSQL lab: SERIAL data type! CREATE SEQUENCE test_seq nextval('test_seq'); -- Increments the value of the specified sequence and returns the new value (as an integer) currval('test_seq'); -- Returns the value returned by the most recent nextval(). If nextval() hasn't been used yet, an error is returned. setval('test_seq', n); -- Sets the current value of the sequence to n. DROP SEQUENCE test_seq 11.70
71 Conclusion on B + -Tree Index Files Advantages of B + -tree index files: automatically reorganizes itself with small, local, changes, in the face of insertions and deletions. Reorganization of entire file is not required to maintain performance. (Minor) disadvantage of B + -trees: extra insertion and deletion overhead, space overhead. Advantages of B + -trees outweigh disadvantages B + -trees are used extensively 11.71
72 SKIP sections 11.4 and 11.5 EoL
73 QUIZ: Definition of B+ trees What is n in this tree? Is this a valid B+ tree? (Verify all conditions!) 11.73
74 QUIZ: Definition of B+ trees What is n in this tree? n = 4 Is this a valid B+ tree? Yes, all conditions are satisfied! 11.74
75 QUIZ: Insertion in B+ trees Insert 12. Source:

76 QUIZ: Insertion in B+ trees Insert 12. Source:
77 QUIZ: Insertion in B+ trees Insert 12. Source:

78 QUIZ: Insertion in B+ trees Insert 12. Source:
79 QUIZ We studied two types on indices so far: ordered and B+ tree. Draw a Venn diagram representing the two! 11.79
80 11.6 Hashing Basic ideas: Tree indices are efficient (L log n/2 (N) ) and mathematically well-understood, but When querying for individual tuples we have too much precision: although we need only one tuple, reading from the HDD is still done in entire blocks (~4KB), each of which usually stores multiple tuples. The parable of the two storage cabinets 11.80


81 One little drawer for each item Larger drawers, with multiple items in each Database Image source: System Concepts th Edition 11.81
82 Static Hashing Bucket = unit of storage containing one or more records (typically a disk block). Hash file organization: we obtain the bucket of a record directly from its search-key value using a hash function. Hash function h is a function from the set of all search-key values K to the set of all bucket addresses B. Hash function is used to locate records for query, insertion and deletion. Records w/different search-key values will be mapped to same bucket entire bucket is searched sequentially to locate a record
83 Example of Hash File Organization File stores instructor table, using dept_name as key (See figure in next slide.) There are 8 buckets The binary representation of the ith character is assumed to be the integer i. The hash function returns the sum of the binary representations of the characters modulo 8 E.g. h(music) = 1 h(history) = 2 h(physics) = 3 h(elec. Eng.) =
84 11.84
85 EXAMPLE: Hash functions in Python The hash function returns the sum of the binary representations of the characters modulo 8 E.g. h(music) = 1 h(history) = 2 h(physics) = 3 h(elec. Eng.) = 3 Write in Python the function h(string) described Hints: The Python library function ord() returns the ASCII code of its character argument The modulus is implemented as the operator % 11.85
86 11.86
87 Hash Functions Worst case: hash function maps all search-key values to same bucket; this makes access time proportional to the number of search-key values in the file. Ideal hash function is uniform each bucket is assigned the same average number of search-key values from the set of all possible values. Ideal hash function is random, so each bucket will have the same number of records assigned to it irrespective of the actual distribution of search-key values in the file. To achieve (pseudo) randomness, typical hash functions perform computations on the internal binary representation of the search-key, as in the prev. example
88 What to do when a bucket becomes full? 11.88
89 Handling of Bucket Overflows Bucket overflow can occur because of Insufficient buckets Skew in distribution of records two reasons: multiple records have same search-key value chosen hash function produces non-uniform distribution of key values Although the probability of bucket overflow can be reduced, it cannot be eliminated; it is handled by using overflow buckets

90 Overflow chaining the overflow buckets of a given bucket are chained together in a linked list. This is called closed hashing. An alternative exists, called open hashing, which does not use overflow buckets. Not suitable for DB apps.! E.g. linear probing 11.90
91 Hash Indices Hashing can be used not only for file organization, but also for index-structure creation. A hash index organizes the search keys, with their associated record pointers, into a hash file structure. Strictly speaking, hash indices are always secondary indices if the file itself is organized using hashing, a separate primary hash index on it using the same search-key is unnecessary. However, we use the term hash index to refer to both secondary index structures and hash organized files

92 Example of Hash Index Hash index on instructor.id 11.92
93 Deficiencies of Static Hashing Function h maps search-key values to a fixed set of B of bucket addresses. Databases grow or shrink with time. If initial number of buckets is too small, and file grows, performance will degrade due to too much overflows. If space is allocated for anticipated growth, a significant amount of space will be wasted initially (and buckets will be underfull). If database shrinks, again space will be wasted. One solution: periodic re-organization of the file with a new hash function Expensive, disrupts normal operations Better solution: allow the number of buckets to be modified dynamically
94 11.7 Dynamic Hashing Good for DBs that grow and shrink in size Allows the hash function to be modified dynamically Extendable hashing is one form of dynamic hashing 11.94
95 Dynamic Hashing: Extendable hashing Hash function generates values over a large range, typically b-bit integers, with b = 32. At any time use only a prefix of the hash function to index into a table of bucket addresses. Let the length of the prefix be i bits, 0 i 32. Bucket address table size = 2 i. Initially i = 0 Value of i grows and shrinks as the table grows and shrinks. Multiple entries in the bucket address table may point to the same bucket (why?) Thus, actual # of buckets is < 2 i The # of buckets also changes dynamically due to merging and splitting of buckets
 11.")
96 Extendable Hash Structure In this structure, i 2 = i 3 = i, whereas i 1 = i 1 (see next slide for details) 11.96
97 Use of Extendable Hash Structure Each bucket j stores a value i j All the entries that point to the same bucket have the same values on the first i j bits. To locate the bucket containing search-key K j : 1. Compute h(k j ) = X 2. Use the first i high order bits of X as a displacement into bucket address table, and follow the pointer to appropriate bucket To insert a record with search-key value K j follow same procedure as look-up and locate the bucket, say j. If there is room in the bucket j insert record in the bucket. Else the bucket must be split and insertion re-attempted (next slide.) Overflow buckets used instead in some cases 11.97
98 Insertion in Extendable Hash Structure To split a bucket j when inserting record with search-key value K j : If i > i j (more than one pointer to bucket j) allocate a new bucket z, and set i j = i z = (i j + 1) Update the second half of the bucket address table entries originally pointing to j, to point to z remove each record in bucket j and reinsert (in j or z) recompute new bucket for K j and insert record in the bucket (further splitting is required if the bucket is still full) If i = i j (only one pointer to bucket j) If i reaches some limit b, or too many splits have happened in this insertion, create an overflow bucket Else increment i and double the size of the bucket address table. replace each entry in the table by two entries that point to the same bucket. recompute new bucket address table entry for K j Now i > i j so use the first case above

99 Use of Extendable Hash Structure: Example 11.99
 Initial Hash structure;")
100 Example (Cont.) Initial Hash structure; bucket size =
 Hash structure after insertion of Mozart,")
101 Example (Cont.) Hash structure after insertion of Mozart, Srinivasan, and Wu records
 Hash structure after insertion of")
102 Example (Cont.) Hash structure after insertion of Einstein record
103 Example (Cont.) Hash structure after insertion of Gold and El Said records

 record.")
104 Your turn! Insert (Katz, Comp.Sci.) record
 Hash structure after insertion")
105 Example (Cont.) Hash structure after insertion of Katz record
 And after insertion of 4")
106 Example (Cont.) And after insertion of 4 more records
 And after insertion of Kim record in")
107 Example (Cont.) And after insertion of Kim record in previous hash structure
108 Hashing pros and cons Benefits of extendable hashing: Hash performance does not degrade with growth of file Minimal space overhead Disadvantages of extendable hashing Extra level of indirection to find desired record Bucket address table may itself become very big (larger than memory) Cannot allocate very large contiguous areas on disk either Solution: B + -tree structure to locate desired record in bucket address table Changing size of bucket address table is an expensive operation Linear hashing is an alternative mechanism Allows incremental growth of its directory (equivalent to bucket address table) at the cost of more bucket overflows
109 SKIP 11.8,
110 11.10 Index definition in SQL Note: In keeping with the declarative nature of SQL, there is no standard way provided to specify what type of index, or any other index details
111 Index definition in PostgreSQL PostgreSQL provides several index types: B-tree, Hash, GiST, SP-GiST and GIN. Each index type uses a different algorithm that is best suited to different types of queries. By default, the CREATE INDEX command creates B+ tree indexes, which fit the most common situations
112 What we covered in Chapter 12: Basic Concepts Ordered Indices B + Tree Indices 11.4 B+ Tree Extensions 11.5 Multiple-Key Access Static Hashing Dynamic Hashing 11.8 Comparison of Ordered Indexing and Hashing 11.9 Bitmap indices Index definition in SQL
113 Homework for Ch.11: 3, 4, 6, 15, 16, 17, 20,
Database System Concepts, 6 th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Chapter 11: Indexing and Hashing" Chapter 11: Indexing and Hashing"
 Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Database index structures
 Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Database System Concepts, 5th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Intro to DB CHAPTER 12 INDEXING & HASHING
 Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Hashing file organization
 Hashing file organization These slides are a modified version of the slides of the book Database System Concepts (Chapter 12), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan. Original slides
Hashing file organization These slides are a modified version of the slides of the book Database System Concepts (Chapter 12), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan. Original slides
Chapter 12: Indexing and Hashing (Cnt(
 Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
CS34800 Information Systems
 CS34800 Information Systems Indexing & Hashing Prof. Chris Clifton 31 October 2016 First: Triggers - Limitations Many database functions do not quite work as expected One example: Trigger on a table that
CS34800 Information Systems Indexing & Hashing Prof. Chris Clifton 31 October 2016 First: Triggers - Limitations Many database functions do not quite work as expected One example: Trigger on a table that
CSIT5300: Advanced Database Systems
 CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
Indexing: Overview & Hashing. CS 377: Database Systems
 Indexing: Overview & Hashing CS 377: Database Systems Recap: Data Storage Data items Records Memory DBMS Blocks blocks Files Different ways to organize files for better performance Disk Motivation for
Indexing: Overview & Hashing CS 377: Database Systems Recap: Data Storage Data items Records Memory DBMS Blocks blocks Files Different ways to organize files for better performance Disk Motivation for
Indexing: B + -Tree. CS 377: Database Systems
 Indexing: B + -Tree CS 377: Database Systems Recap: Indexes Data structures that organize records via trees or hashing Speed up search for a subset of records based on values in a certain field (search
Indexing: B + -Tree CS 377: Database Systems Recap: Indexes Data structures that organize records via trees or hashing Speed up search for a subset of records based on values in a certain field (search
key h(key) Hash Indexing Friday, April 09, 2004 Disadvantages of Sequential File Organization Must use an index and/or binary search to locate data
 Hash Indexing Friday, April 09, 2004 Disadvantages of Sequential File Organization Must use an index and/or binary search to locate data") Lectures Desktop (C) Page 1 Hash Indexing Friday, April 09, 004 11:33 AM Disadvantages of Sequential File Organization Must use an index and/or binary search to locate data File organization based on hashing
Lectures Desktop (C) Page 1 Hash Indexing Friday, April 09, 004 11:33 AM Disadvantages of Sequential File Organization Must use an index and/or binary search to locate data File organization based on hashing
File Structures and Indexing
 File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
Physical Level of Databases: B+-Trees
 Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
Chapter 12: Query Processing. Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Indexing. Week 14, Spring Edited by M. Naci Akkøk, , Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel
 Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Physical Database Design: Outline
 Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
QUIZ: Is either set of attributes a superkey? A candidate key? Source:
 QUIZ: Is either set of attributes a superkey? A candidate key? Source: http://courses.cs.washington.edu/courses/cse444/06wi/lectures/lecture09.pdf 10.1 QUIZ: MVD What MVDs can you spot in this table? Source:
QUIZ: Is either set of attributes a superkey? A candidate key? Source: http://courses.cs.washington.edu/courses/cse444/06wi/lectures/lecture09.pdf 10.1 QUIZ: MVD What MVDs can you spot in this table? Source:
Material You Need to Know
 Review Quiz 2 Material You Need to Know Normalization Storage and Disk File Layout Indexing B-trees and B+ Trees Extensible Hashing Linear Hashing Decomposition Goals: Lossless Joins, Dependency preservation
Review Quiz 2 Material You Need to Know Normalization Storage and Disk File Layout Indexing B-trees and B+ Trees Extensible Hashing Linear Hashing Decomposition Goals: Lossless Joins, Dependency preservation
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Announcements. Reading Material. Recap. Today 9/17/17. Storage (contd. from Lecture 6)
") CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow pages!
 Professor: Pete Keleher! keleher@cs.umd.edu! } Keep sorted by some search key! } Insertion! Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow
Professor: Pete Keleher! keleher@cs.umd.edu! } Keep sorted by some search key! } Insertion! Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Advanced Database Systems
 Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Instructor: Amol Deshpande
 Instructor: Amol Deshpande amol@cs.umd.edu } Storage and Query Processing Using ipython Notebook Indexes; Query Processing Basics } Other things Project 4: released Poll on Piazza Query Processing/Storage
Instructor: Amol Deshpande amol@cs.umd.edu } Storage and Query Processing Using ipython Notebook Indexes; Query Processing Basics } Other things Project 4: released Poll on Piazza Query Processing/Storage
Query Processing. Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016
 Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
CMSC 424 Database design Lecture 13 Storage: Files. Mihai Pop
 CMSC 424 Database design Lecture 13 Storage: Files Mihai Pop Recap Databases are stored on disk cheaper than memory non-volatile (survive power loss) large capacity Operating systems are designed for general
CMSC 424 Database design Lecture 13 Storage: Files Mihai Pop Recap Databases are stored on disk cheaper than memory non-volatile (survive power loss) large capacity Operating systems are designed for general
Some Practice Problems on Hardware, File Organization and Indexing
 Some Practice Problems on Hardware, File Organization and Indexing Multiple Choice State if the following statements are true or false. 1. On average, repeated random IO s are as efficient as repeated
Some Practice Problems on Hardware, File Organization and Indexing Multiple Choice State if the following statements are true or false. 1. On average, repeated random IO s are as efficient as repeated
Topics to Learn. Important concepts. Tree-based index. Hash-based index
 CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
Extra: B+ Trees. Motivations. Differences between BST and B+ 10/27/2017. CS1: Java Programming Colorado State University
 Extra: B+ Trees CS1: Java Programming Colorado State University Slides by Wim Bohm and Russ Wakefield 1 Motivations Many times you want to minimize the disk accesses while doing a search. A binary search
Extra: B+ Trees CS1: Java Programming Colorado State University Slides by Wim Bohm and Russ Wakefield 1 Motivations Many times you want to minimize the disk accesses while doing a search. A binary search
Introduction to Indexing 2. Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana
 Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
CS143: Index. Book Chapters: (4 th ) , (5 th ) , , 12.10
 , (5 th ) , , 12.10") CS143: Index Book Chapters: (4 th ) 12.1-3, 12.5-8 (5 th ) 12.1-3, 12.6-8, 12.10 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index
CS143: Index Book Chapters: (4 th ) 12.1-3, 12.5-8 (5 th ) 12.1-3, 12.6-8, 12.10 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index
Physical Database Design
 Physical Database Design These slides are mostly taken verbatim, or with minor changes, from those prepared by Stephen Hegner (http://www.cs.umu.se/ hegner/) of Umeå University Physical Database Design
Physical Database Design These slides are mostly taken verbatim, or with minor changes, from those prepared by Stephen Hegner (http://www.cs.umu.se/ hegner/) of Umeå University Physical Database Design
Storage hierarchy. Textbook: chapters 11, 12, and 13
 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Physical Disk Structure. Physical Data Organization and Indexing. Pages and Blocks. Access Path. I/O Time to Access a Page. Disks.
 Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
Lecture 8 Index (B+-Tree and Hash)
") CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
Chapter 13: Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
DATABASE PERFORMANCE AND INDEXES. CS121: Relational Databases Fall 2017 Lecture 11
 DATABASE PERFORMANCE AND INDEXES CS121: Relational Databases Fall 2017 Lecture 11 Database Performance 2 Many situations where query performance needs to be improved e.g. as data size grows, query performance
DATABASE PERFORMANCE AND INDEXES CS121: Relational Databases Fall 2017 Lecture 11 Database Performance 2 Many situations where query performance needs to be improved e.g. as data size grows, query performance
Indexing. Jan Chomicki University at Buffalo. Jan Chomicki () Indexing 1 / 25
 Indexing 1 / 25") Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
! A relational algebra expression may have many equivalent. ! Cost is generally measured as total elapsed time for
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
(i) It is efficient technique for small and medium sized data file. (ii) Searching is comparatively fast and efficient.
 It is efficient technique for small and medium sized data file. (ii) Searching is comparatively fast and efficient.") INDEXING An index is a collection of data entries which is used to locate a record in a file. Index table record in a file consist of two parts, the first part consists of value of prime or non-prime attributes
INDEXING An index is a collection of data entries which is used to locate a record in a file. Index table record in a file consist of two parts, the first part consists of value of prime or non-prime attributes
Access Methods. Basic Concepts. Index Evaluation Metrics. search key pointer. record. value. Value
 Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Database System Concepts
 Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Chapter 17 Indexing Structures for Files and Physical Database Design
 Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
CPS352 Lecture - Indexing
 Objectives: CPS352 Lecture - Indexing Last revised 2/25/2019 1. To explain motivations and conflicting goals for indexing 2. To explain different types of indexes (ordered versus hashed; clustering versus
Objectives: CPS352 Lecture - Indexing Last revised 2/25/2019 1. To explain motivations and conflicting goals for indexing 2. To explain different types of indexes (ordered versus hashed; clustering versus
CMSC424: Database Design. Instructor: Amol Deshpande
 CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
Query Processing & Optimization
 Query Processing & Optimization 1 Roadmap of This Lecture Overview of query processing Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Introduction
Query Processing & Optimization 1 Roadmap of This Lecture Overview of query processing Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Introduction
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
CSC 261/461 Database Systems Lecture 17. Fall 2017
 CSC 261/461 Database Systems Lecture 17 Fall 2017 Announcement Quiz 6 Due: Tonight at 11:59 pm Project 1 Milepost 3 Due: Nov 10 Project 2 Part 2 (Optional) Due: Nov 15 The IO Model & External Sorting Today
CSC 261/461 Database Systems Lecture 17 Fall 2017 Announcement Quiz 6 Due: Tonight at 11:59 pm Project 1 Milepost 3 Due: Nov 10 Project 2 Part 2 (Optional) Due: Nov 15 The IO Model & External Sorting Today
Something to think about. Problems. Purpose. Vocabulary. Query Evaluation Techniques for large DB. Part 1. Fact:
 Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
CS-245 Database System Principles
 CS-245 Database System Principles Midterm Exam Summer 2001 SOLUIONS his exam is open book and notes. here are a total of 110 points. You have 110 minutes to complete it. Print your name: he Honor Code
CS-245 Database System Principles Midterm Exam Summer 2001 SOLUIONS his exam is open book and notes. here are a total of 110 points. You have 110 minutes to complete it. Print your name: he Honor Code
Indexing and Hashing
 C H A P T E R 1 Indexing and Hashing This chapter covers indexing techniques ranging from the most basic one to highly specialized ones. Due to the extensive use of indices in database systems, this chapter
C H A P T E R 1 Indexing and Hashing This chapter covers indexing techniques ranging from the most basic one to highly specialized ones. Due to the extensive use of indices in database systems, this chapter
RAID in Practice, Overview of Indexing
 RAID in Practice, Overview of Indexing CS634 Lecture 4, Feb 04 2014 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke 1 Disks and Files: RAID in practice For a big enterprise
RAID in Practice, Overview of Indexing CS634 Lecture 4, Feb 04 2014 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke 1 Disks and Files: RAID in practice For a big enterprise
CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE DATABASE APPLICATIONS
 CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE 15-415 DATABASE APPLICATIONS C. Faloutsos Indexing and Hashing 15-415 Database Applications http://www.cs.cmu.edu/~christos/courses/dbms.s00/ general
CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE 15-415 DATABASE APPLICATIONS C. Faloutsos Indexing and Hashing 15-415 Database Applications http://www.cs.cmu.edu/~christos/courses/dbms.s00/ general
Indexing Methods. Lecture 9. Storage Requirements of Databases
 Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Indexing. Chapter 8, 10, 11. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 Indexing Chapter 8, 10, 11 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Tree-Based Indexing The data entries are arranged in sorted order by search key value. A hierarchical search
Indexing Chapter 8, 10, 11 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Tree-Based Indexing The data entries are arranged in sorted order by search key value. A hierarchical search
Tree-Structured Indexes
 Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Indexing. Announcements. Basics. CPS 116 Introduction to Database Systems
 Indexing CPS 6 Introduction to Database Systems Announcements 2 Homework # sample solution will be available next Tuesday (Nov. 9) Course project milestone #2 due next Thursday Basics Given a value, locate
Indexing CPS 6 Introduction to Database Systems Announcements 2 Homework # sample solution will be available next Tuesday (Nov. 9) Course project milestone #2 due next Thursday Basics Given a value, locate
Selection Queries. to answer a selection query (ssn=10) needs to traverse a full path.
 needs to traverse a full path.") Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
The physical database. Contents - physical database design DATABASE DESIGN I - 1DL300. Introduction to Physical Database Design
 DATABASE DESIGN I - 1DL300 Fall 2011 Introduction to Physical Database Design Elmasri/Navathe ch 16 and 17 Padron-McCarthy/Risch ch 21 and 22 An introductory course on database systems http://www.it.uu.se/edu/course/homepage/dbastekn/ht11
DATABASE DESIGN I - 1DL300 Fall 2011 Introduction to Physical Database Design Elmasri/Navathe ch 16 and 17 Padron-McCarthy/Risch ch 21 and 22 An introductory course on database systems http://www.it.uu.se/edu/course/homepage/dbastekn/ht11
CSE 562 Database Systems
 Goal of Indexing CSE 562 Database Systems Indexing Some slides are based or modified from originals by Database Systems: The Complete Book, Pearson Prentice Hall 2 nd Edition 08 Garcia-Molina, Ullman,
Goal of Indexing CSE 562 Database Systems Indexing Some slides are based or modified from originals by Database Systems: The Complete Book, Pearson Prentice Hall 2 nd Edition 08 Garcia-Molina, Ullman,
Data Management for Data Science
 Data Management for Data Science Database Management Systems: Access file manager and query evaluation Maurizio Lenzerini, Riccardo Rosati Dipartimento di Ingegneria informatica automatica e gestionale
Data Management for Data Science Database Management Systems: Access file manager and query evaluation Maurizio Lenzerini, Riccardo Rosati Dipartimento di Ingegneria informatica automatica e gestionale
Remember. 376a. Database Design. Also. B + tree reminders. Algorithms for B + trees. Remember
 376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 14 B + trees, multi-key indices, partitioned hashing and grid files B and B + -trees are used one implementation
376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 14 B + trees, multi-key indices, partitioned hashing and grid files B and B + -trees are used one implementation
 Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
COMP 430 Intro. to Database Systems. Indexing
 COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
CSE 544 Principles of Database Management Systems
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
Datenbanksysteme II: Caching and File Structures. Ulf Leser
 Datenbanksysteme II: Caching and File Structures Ulf Leser Content of this Lecture Caching Overview Accessing data Cache replacement strategies Prefetching File structure Index Files Ulf Leser: Implementation
Datenbanksysteme II: Caching and File Structures Ulf Leser Content of this Lecture Caching Overview Accessing data Cache replacement strategies Prefetching File structure Index Files Ulf Leser: Implementation
System Structure Revisited
 System Structure Revisited Naïve users Casual users Application programmers Database administrator Forms DBMS Application Front ends DML Interface CLI DDL SQL Commands Query Evaluation Engine Transaction
System Structure Revisited Naïve users Casual users Application programmers Database administrator Forms DBMS Application Front ends DML Interface CLI DDL SQL Commands Query Evaluation Engine Transaction
CS 525: Advanced Database Organization 04: Indexing
 CS 5: Advanced Database Organization 04: Indexing Boris Glavic Part 04 Indexing & Hashing value record? value Slides: adapted from a course taught by Hector Garcia-Molina, Stanford InfoLab CS 5 Notes 4
CS 5: Advanced Database Organization 04: Indexing Boris Glavic Part 04 Indexing & Hashing value record? value Slides: adapted from a course taught by Hector Garcia-Molina, Stanford InfoLab CS 5 Notes 4
Classifying Physical Storage Media. Chapter 11: Storage and File Structure. Storage Hierarchy (Cont.) Storage Hierarchy. Magnetic Hard Disk Mechanism
 Storage Hierarchy. Magnetic Hard Disk Mechanism") Chapter 11: Storage and File Structure Overview of Storage Media Magnetic Disks Characteristics RAID Database Buffers Structure of Records Organizing Records within Files Data-Dictionary Storage Classifying
Chapter 11: Storage and File Structure Overview of Storage Media Magnetic Disks Characteristics RAID Database Buffers Structure of Records Organizing Records within Files Data-Dictionary Storage Classifying
Classifying Physical Storage Media. Chapter 11: Storage and File Structure. Storage Hierarchy. Storage Hierarchy (Cont.) Speed
 Speed") Chapter 11: Storage and File Structure Overview of Storage Media Magnetic Disks Characteristics RAID Database Buffers Structure of Records Organizing Records within Files Data-Dictionary Storage Classifying
Chapter 11: Storage and File Structure Overview of Storage Media Magnetic Disks Characteristics RAID Database Buffers Structure of Records Organizing Records within Files Data-Dictionary Storage Classifying
Lecture 13. Lecture 13: B+ Tree
 Lecture 13 Lecture 13: B+ Tree Lecture 13 Announcements 1. Project Part 2 extension till Friday 2. Project Part 3: B+ Tree coming out Friday 3. Poll for Nov 22nd 4. Exam Pickup: If you have questions,
Lecture 13 Lecture 13: B+ Tree Lecture 13 Announcements 1. Project Part 2 extension till Friday 2. Project Part 3: B+ Tree coming out Friday 3. Poll for Nov 22nd 4. Exam Pickup: If you have questions,
Database Management and Tuning
 Database Management and Tuning Index Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 Acknowledgements: The slides are provided by Nikolaus Augsten and have
Database Management and Tuning Index Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 Acknowledgements: The slides are provided by Nikolaus Augsten and have
Introduction to Data Management. Lecture 15 (More About Indexing)
") Introduction to Data Management Lecture 15 (More About Indexing) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Announcements v HW s and quizzes:
Introduction to Data Management Lecture 15 (More About Indexing) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Announcements v HW s and quizzes:
Outline. Database Management and Tuning. What is an Index? Key of an Index. Index Tuning. Johann Gamper. Unit 4
 Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
Chapter 12: Query Processing
 Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
CS127: B-Trees. B-Trees
 CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
Tree-Structured Indexes
 Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Fundamentals of Database Systems Prof. Arnab Bhattacharya Department of Computer Science and Engineering Indian Institute of Technology, Kanpur
 Fundamentals of Database Systems Prof. Arnab Bhattacharya Department of Computer Science and Engineering Indian Institute of Technology, Kanpur Lecture - 18 Database Indexing: Hashing We will start on
Fundamentals of Database Systems Prof. Arnab Bhattacharya Department of Computer Science and Engineering Indian Institute of Technology, Kanpur Lecture - 18 Database Indexing: Hashing We will start on
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part IV Lecture 14, March 10, 015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part III Tree-based indexes: ISAM and B+ trees Data Warehousing/
Database Applications (15-415) DBMS Internals- Part IV Lecture 14, March 10, 015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part III Tree-based indexes: ISAM and B+ trees Data Warehousing/
Spring 2013 CS 122C & CS 222 Midterm Exam (and Comprehensive Exam, Part I) (Max. Points: 100)
 (Max. Points: 100)") Spring 2013 CS 122C & CS 222 Midterm Exam (and Comprehensive Exam, Part I) (Max. Points: 100) Instructions: - This exam is closed book and closed notes but open cheat sheet. - The total time for the exam
Spring 2013 CS 122C & CS 222 Midterm Exam (and Comprehensive Exam, Part I) (Max. Points: 100) Instructions: - This exam is closed book and closed notes but open cheat sheet. - The total time for the exam
amiri advanced databases '05
 More on indexing: B+ trees 1 Outline Motivation: Search example Cost of searching with and without indices B+ trees Definition and structure B+ tree operations Inserting Deleting 2 Dense ordered index
More on indexing: B+ trees 1 Outline Motivation: Search example Cost of searching with and without indices B+ trees Definition and structure B+ tree operations Inserting Deleting 2 Dense ordered index
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
Chapter 17. Disk Storage, Basic File Structures, and Hashing. Records. Blocking
 Chapter 17 Disk Storage, Basic File Structures, and Hashing Records Fixed and variable length records Records contain fields which have values of a particular type (e.g., amount, date, time, age) Fields
Chapter 17 Disk Storage, Basic File Structures, and Hashing Records Fixed and variable length records Records contain fields which have values of a particular type (e.g., amount, date, time, age) Fields
Announcement. Reading Material. Overview of Query Evaluation. Overview of Query Evaluation. Overview of Query Evaluation 9/26/17
 Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Database Technology. Topic 7: Data Structures for Databases. Olaf Hartig.
 Topic 7: Data Structures for Databases Olaf Hartig olaf.hartig@liu.se Database System 2 Storage Hierarchy Traditional Storage Hierarchy CPU Cache memory Main memory Primary storage Disk Tape Secondary
Topic 7: Data Structures for Databases Olaf Hartig olaf.hartig@liu.se Database System 2 Storage Hierarchy Traditional Storage Hierarchy CPU Cache memory Main memory Primary storage Disk Tape Secondary
Overview of Storage and Indexing
 Overview of Storage and Indexing Chapter 8 Instructor: Vladimir Zadorozhny vladimir@sis.pitt.edu Information Science Program School of Information Sciences, University of Pittsburgh 1 Data on External
Overview of Storage and Indexing Chapter 8 Instructor: Vladimir Zadorozhny vladimir@sis.pitt.edu Information Science Program School of Information Sciences, University of Pittsburgh 1 Data on External
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Tree-Structured Indexes. Chapter 10
 Tree-Structured Indexes Chapter 10 1 Introduction As for any index, 3 alternatives for data entries k*: Data record with key value k 25, [n1,v1,k1,25] 25,
Tree-Structured Indexes Chapter 10 1 Introduction As for any index, 3 alternatives for data entries k*: Data record with key value k 25, [n1,v1,k1,25] 25,
CSE 444: Database Internals. Lectures 5-6 Indexing
 CSE 444: Database Internals Lectures 5-6 Indexing 1 Announcements HW1 due tonight by 11pm Turn in an electronic copy (word/pdf) by 11pm, or Turn in a hard copy in my office by 4pm Lab1 is due Friday, 11pm
CSE 444: Database Internals Lectures 5-6 Indexing 1 Announcements HW1 due tonight by 11pm Turn in an electronic copy (word/pdf) by 11pm, or Turn in a hard copy in my office by 4pm Lab1 is due Friday, 11pm