Jarek Szlichta
|
|
|
- Michael Fox
- 6 years ago
- Views:
Transcription
1 Jarek Szlichta
2 Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns in data Machine Learning using data to make inferences or predictions 2



3 Early data mining success stories Victoria s Secret Walmart Beer and diapers 3
4 We will cover data mining on market-basket data with patterns being frequent itemset and finding association rules Examples of other types of data: graphs (of the node-and-link variety), streams, text (known as text mining ) Examples of other types of patterns: looking for similar items, looking for structural patterns in large networks looking for clusters and/or anomalies 4
5
6 Originated with retail data, specifically grocery stores, where a market basket is a set of items purchased together More generally, market basket data is any data where there is a fixed (possibly very large) set of items, and a (usually large) number of transactions consisting of one or more of the items 6
7 Items: groceries, Transaction: grocery cart Items: online goods, Transaction: (virtual) shopping cart Items: college courses, Transaction: student transcript Items: students, Transaction: party Items: movies, Transaction: person Items: symptoms, Transaction: patient Items: words, Transaction: document 7
8 Sets of items that occur together frequently in transactions How large is a set? What does frequently mean? Look for sets containing at least min-set-size items, may also constrain max-set-size Support: # transactions containing set / total # transactions Look for sets with support > support-threshold 8
9 Transactions T1: beer, eggs, milk T2: beer, diapers, milk T3: chips, eggs T4: eggs, milk T5: beer, chips, diapers, milk Assume min-set-size = 2, support-threshold = 0.3 Frequent itemsets? 9
10 Transactions T1: beer, eggs, milk T2: beer, diapers, milk T3: chips, eggs T4: eggs, milk T5: beer, chips, diapers, milk Assume min-set-size = 2, support-threshold = 0.3 Frequent itemsets? Answer: beer/milk (0.6), beer/diapers (0.4), diapers/milk (0.4), eggs/milk (0.4), beer/diapers/milk (0.4) 10
11 Assume Table Shop(TID, item) Frequent itemsets of two, support-threshold = 0.3 S1 and S2 are aliases to the same table Shop Technique is based on self-join over table Shop Select S1.item, S2.item From Shop S1, Shop S2 Where S1.TID = S2.TID and S1.item < S2.item Group by S1.item, S2.item Having count(*) > (Select count(distinct TID)*0.3 From Shop) 11
12 Table Shop(TID, item) Frequent itemsets of three, support-threshold = 0.3 Select S1.item,S2.item,S3.item From Shop S1,Shop S2,Shop S3 Where S1.TID = S2.TID And S2.TID = S3.TID And S1.item < S2.item And S2.item < S3.item Group By S1.item,S2.item,S3.item Having count(*) > (Select count(distinct TID)*0.3 From Shop) 12
13 Set1 Set2: when Set1 occurs in a transaction, Set2 often occurs in the same transaction Commonly limit to looking for rules where Set2 is a single item How large is Set1? What does often mean? 13
14 Look for sets Set1 containing at least min-set-size items, may also constrain max-set-size Confidence: # transactions containing Set1 and Set2 / # transactions containing Set1 Look for sets with confidence > confidence threshold Still consider Support: # transactions containing Set1 / total # transactions Look for sets with support > support threshold (i.e., Set1 should be frequent itemset) 14
15 Transactions T1: beer, eggs, milk T2: beer, diapers, milk T3: chips, eggs T4: eggs, milk min-set-size = 1, max-set-size = 1, confidencethreshold = 0.5, support-threshold = 0.5 Association rules? 15
16 Transactions T1: beer, eggs, milk T2: beer, diapers, milk T3: chips, eggs T4: eggs, milk min-set-size = 1, max-set-size = 1, confidencethreshold = 0.5, support-threshold = 0.5 Association rules? For instance, Beer Diapers (0.5; 0.5), Beer Milk (1;0.5), Eggs Milk (0.66;0.75), Milk Beer (0.66;0.75), Milk Eggs (0.66;0.75), 16
17
18 Supervised: Create a model from wellunderstood training data, use it for inference or prediction about other data. Examples: regression, classification Unsupervised: Try to understand the data, look for patterns or structure. Examples: data mining, clustering Also in-between approaches, such as semisupervised and active learning 18
19 Goal: Given a set of feature values for an item not seen before, decide which one of a set of predefined categories the item belongs to Customer purchases features: age, income, gender, zipcode, profession; categories: likelihood of buying (high, medium, low) Medical diagnosis features: age, gender, history, symptom-1-severity, symptom-2- severity, test1result, test2result; categories: diagnosis Fraud detection in online purchases features: item, volume, price, shipping, address; categories: fraud or okay 19



20 20
21 Plot the height and weight of dogs in three classes: Beagles, Chihuahuas, and Dachshunds. Each pair (x, y) in the training set consists of: Feature vector x of the form [height, weight]. The associated label y is the variety of the dog. An example of a training-set pair would be ([5 inches, 2 pounds], Chihuahua). 21
22 22
23 The algorithm that implements function f is: Is it supervised on unsupervised learning? 23

24 Computed based on watched movies 24
25 K nearest neighbors is an algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance function). 25

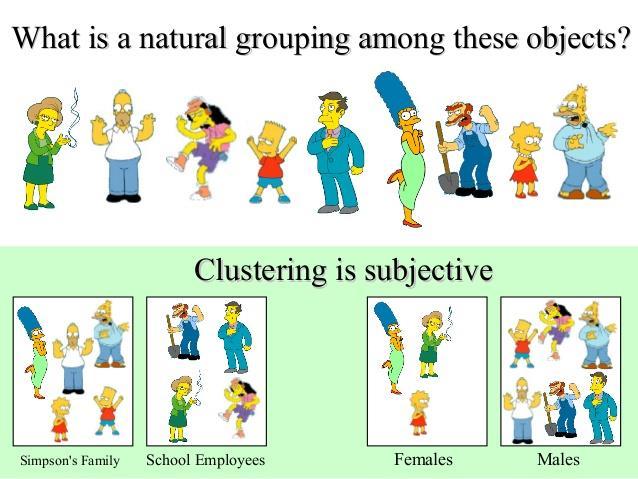
26 A case is classified by a majority vote of its neighbors, with the case being assigned to the class most common amongst its K nearest neighbors measured by a distance function. If K = 1, then the case is simply assigned to the class of its nearest neighbor. 26
 27")
27 It should also be noted that all two distance measures are only valid for continuous variables In the instance of categorical variables the Hamming distance must be used (outputs 0 or 1) 27

28 Choosing the optimal value for K is best done by first inspecting the data In general, a larger K value is more precise as it reduces the overall noise but there is no guarantee Historically, the optimal K for most datasets has been between That produces much better results than 1NN 28
 and Default is the target.")
29 Consider the following data concerning credit default. Age and Loan are two numerical variables (predictors) and Default is the target. We can now use the training set to classify an unknown case (Age=48 and Loan=$142,000) using Euclidean distance 29

30 If K=1 then the nearest neighbor is the last case in the training set with Default=Y With K=3, there are two Default=Y and one Default=N out of three closest neighbors. The prediction for the unknown case is again Default=Y 30
31 Logistic regression uses training data to compute function f(x1,...,xn-1 ), where x1,, xn-1 are features, that gives probability of result xn being yes Lots of hidden math.. 31
32 32
 such that items within groups are close to each other Unsupervised, no training")
33 Multidimensional feature space, distance metric between items Goal: Partition set of items into k groups (clusters) such that items within groups are close to each other Unsupervised, no training data 33
34 34
35 K-Means clustering intends to partition n objects into k clusters in which each object belongs to the cluster with the nearest mean This method produces exactly k different clusters of greatest possible distinction The best number of clusters k leading to the greatest separation (distance) is not known as a priori and must be computed from the data 35
36 The objective of K-Means clustering is to minimize total intra-cluster variance, or, the squared error function: 36
37 Clusters the data into k groups where k is predefined 1. Select k points at random as cluster centers 2. Assign objects to their closest cluster center according to the Euclidean distance function 3. Calculate the centroid or mean of all objects in each cluster 4. Repeat steps 2, 3 and 4 until the same points are assigned to each cluster in consecutive rounds 37
38 Data clustered by age and income 38
39 Suppose we want to group the visitors to a website using just their age (a one-dimensional space) as follows: 15,15,16,19,19,20,20,21,22,28,35,40,41,42,43,44, 60,61,65 39
40 No change between iterations 3 and 4 has been noted. By using clustering, 2 groups have been identified and Initial centroids were chosen randomly 40
41 Provide a useful application of data mining. What K-Means algorithm is used for? Describe how K-Means algorithm works. What is KNN algorithm used for? How to chose the right K? 41

42 Review Slides! Recommended Association rule learning Classification and Clustering Optional This book is used in CSCI 4030, Big Data Analytics; course plug-in 42
Data Mining Algorithms
 Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
Data Mining Clustering
 Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Machine Learning - Clustering. CS102 Fall 2017
 Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently New challenges: with a
 Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Chapter 4 Data Mining A Short Introduction
 Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Intro to Artificial Intelligence
 Intro to Artificial Intelligence Ahmed Sallam { Lecture 5: Machine Learning ://. } ://.. 2 Review Probabilistic inference Enumeration Approximate inference 3 Today What is machine learning? Supervised
Intro to Artificial Intelligence Ahmed Sallam { Lecture 5: Machine Learning ://. } ://.. 2 Review Probabilistic inference Enumeration Approximate inference 3 Today What is machine learning? Supervised
ANU MLSS 2010: Data Mining. Part 2: Association rule mining
 ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Data warehouse and Data Mining
 Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
k-nearest Neighbor (knn) Sept Youn-Hee Han
 Sept Youn-Hee Han") k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
Data mining techniques for actuaries: an overview
 Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Introduction to Data Mining and Data Analytics
 1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Chapter 28. Outline. Definitions of Data Mining. Data Mining Concepts
 Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms
Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
A Survey On Data Mining Algorithm
 A Survey On Data Mining Algorithm Rohit Jacob Mathew 1 Sasi Rekha Sankar 1 Preethi Varsha. V 2 1 Dept. of Software Engg., 2 Dept. of Electronics & Instrumentation Engg. SRM University India Abstract This
A Survey On Data Mining Algorithm Rohit Jacob Mathew 1 Sasi Rekha Sankar 1 Preethi Varsha. V 2 1 Dept. of Software Engg., 2 Dept. of Electronics & Instrumentation Engg. SRM University India Abstract This
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data mining overview. Data Mining. Data mining overview. Data mining overview. Data mining overview. Data mining overview 3/24/2014
 Data Mining Data mining processes What technological infrastructure is required? Data mining is a system of searching through large amounts of data for patterns. It is a relatively new concept which is
Data Mining Data mining processes What technological infrastructure is required? Data mining is a system of searching through large amounts of data for patterns. It is a relatively new concept which is
K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Data Mining Concepts
 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
COMP90049 Knowledge Technologies
 COMP90049 Knowledge Technologies Data Mining (Lecture Set 3) 2017 Rao Kotagiri Department of Computing and Information Systems The Melbourne School of Engineering Some of slides are derived from Prof Vipin
COMP90049 Knowledge Technologies Data Mining (Lecture Set 3) 2017 Rao Kotagiri Department of Computing and Information Systems The Melbourne School of Engineering Some of slides are derived from Prof Vipin
Data mining. Classification k-nn Classifier. Piotr Paszek. (Piotr Paszek) Data mining k-nn 1 / 20
 Data mining k-nn 1 / 20") Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Data Mining. 3.5 Lazy Learners (Instance-Based Learners) Fall Instructor: Dr. Masoud Yaghini. Lazy Learners
 Fall Instructor: Dr. Masoud Yaghini. Lazy Learners") Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC
 Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC 2018 Storage Developer Conference. Dell EMC. All Rights Reserved. 1 Data Center
Correlative Analytic Methods in Large Scale Network Infrastructure Hariharan Krishnaswamy Senior Principal Engineer Dell EMC 2018 Storage Developer Conference. Dell EMC. All Rights Reserved. 1 Data Center
Data Preprocessing. Supervised Learning
 Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Chapter 4 Data Mining A Short Introduction. 2005/6, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1
 Chapter 4 Data Mining A Short Introduction 2005/6, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining
Chapter 4 Data Mining A Short Introduction 2005/6, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining
10/5/2017 MIST.6060 Business Intelligence and Data Mining 1. Nearest Neighbors. In a p-dimensional space, the Euclidean distance between two records,
 10/5/2017 MIST.6060 Business Intelligence and Data Mining 1 Distance Measures Nearest Neighbors In a p-dimensional space, the Euclidean distance between two records, a = a, a,..., a ) and b = b, b,...,
10/5/2017 MIST.6060 Business Intelligence and Data Mining 1 Distance Measures Nearest Neighbors In a p-dimensional space, the Euclidean distance between two records, a = a, a,..., a ) and b = b, b,...,
Mathematics of Data. INFO-4604, Applied Machine Learning University of Colorado Boulder. September 5, 2017 Prof. Michael Paul
 Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
CS377: Database Systems Data Warehouse and Data Mining. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore
 Bangalore") Data Warehousing Data Mining (17MCA442) 1. GENERAL INFORMATION: PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore 560 100 Department of MCA COURSE INFORMATION SHEET Academic
Data Warehousing Data Mining (17MCA442) 1. GENERAL INFORMATION: PESIT- Bangalore South Campus Hosur Road (1km Before Electronic city) Bangalore 560 100 Department of MCA COURSE INFORMATION SHEET Academic
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Oracle9i Data Mining. Data Sheet August 2002
 Oracle9i Data Mining Data Sheet August 2002 Oracle9i Data Mining enables companies to build integrated business intelligence applications. Using data mining functionality embedded in the Oracle9i Database,
Oracle9i Data Mining Data Sheet August 2002 Oracle9i Data Mining enables companies to build integrated business intelligence applications. Using data mining functionality embedded in the Oracle9i Database,
MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods
 MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Supervised Learning: Nonparametric
MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Supervised Learning: Nonparametric
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
Seeing the Big Picture
 Seeing the Big Picture Segmenting Images to Create Data 15.071x The Analytics Edge Image Segmentation Divide up digital images to salient regions/clusters corresponding to individual surfaces, objects,
Seeing the Big Picture Segmenting Images to Create Data 15.071x The Analytics Edge Image Segmentation Divide up digital images to salient regions/clusters corresponding to individual surfaces, objects,
10/14/2017. Dejan Sarka. Anomaly Detection. Sponsors
 Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Fall 2018 CSE 482 Big Data Analysis: Exam 1 Total: 36 (+3 bonus points)
") Fall 2018 CSE 482 Big Data Analysis: Exam 1 Total: 36 (+3 bonus points) Name: This exam is open book and notes. You can use a calculator but no laptops, cell phones, nor other electronic devices are allowed.
Fall 2018 CSE 482 Big Data Analysis: Exam 1 Total: 36 (+3 bonus points) Name: This exam is open book and notes. You can use a calculator but no laptops, cell phones, nor other electronic devices are allowed.
Chapter 1, Introduction
 CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
A REVIEW ON VARIOUS APPROACHES OF CLUSTERING IN DATA MINING
 A REVIEW ON VARIOUS APPROACHES OF CLUSTERING IN DATA MINING Abhinav Kathuria Email - abhinav.kathuria90@gmail.com Abstract: Data mining is the process of the extraction of the hidden pattern from the data
A REVIEW ON VARIOUS APPROACHES OF CLUSTERING IN DATA MINING Abhinav Kathuria Email - abhinav.kathuria90@gmail.com Abstract: Data mining is the process of the extraction of the hidden pattern from the data
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Machine Learning: Symbolische Ansätze
 Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
The k-means Algorithm and Genetic Algorithm
 The k-means Algorithm and Genetic Algorithm k-means algorithm Genetic algorithm Rough set approach Fuzzy set approaches Chapter 8 2 The K-Means Algorithm The K-Means algorithm is a simple yet effective
The k-means Algorithm and Genetic Algorithm k-means algorithm Genetic algorithm Rough set approach Fuzzy set approaches Chapter 8 2 The K-Means Algorithm The K-Means algorithm is a simple yet effective
Data Mining: Models and Methods
 Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Data Mining Concepts. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
Association Rules. Berlin Chen References:
 Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Clustering algorithms and autoencoders for anomaly detection
 Clustering algorithms and autoencoders for anomaly detection Alessia Saggio Lunch Seminars and Journal Clubs Université catholique de Louvain, Belgium 3rd March 2017 a Outline Introduction Clustering algorithms
Clustering algorithms and autoencoders for anomaly detection Alessia Saggio Lunch Seminars and Journal Clubs Université catholique de Louvain, Belgium 3rd March 2017 a Outline Introduction Clustering algorithms
D B M G Data Base and Data Mining Group of Politecnico di Torino
 DataBase and Data Mining Group of Data mining fundamentals Data Base and Data Mining Group of Data analysis Most companies own huge databases containing operational data textual documents experiment results
DataBase and Data Mining Group of Data mining fundamentals Data Base and Data Mining Group of Data analysis Most companies own huge databases containing operational data textual documents experiment results
Data Mining Course Overview
 Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Data Science Course Content
 CHAPTER 1: INTRODUCTION TO DATA SCIENCE Data Science Course Content What is the need for Data Scientists Data Science Foundation Business Intelligence Data Analysis Data Mining Machine Learning Difference
CHAPTER 1: INTRODUCTION TO DATA SCIENCE Data Science Course Content What is the need for Data Scientists Data Science Foundation Business Intelligence Data Analysis Data Mining Machine Learning Difference
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
9 Classification: KNN and SVM
 CSE4334/5334 Data Mining 9 Classification: KNN and SVM Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2017 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
CSE4334/5334 Data Mining 9 Classification: KNN and SVM Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2017 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
Chapter 4: Mining Frequent Patterns, Associations and Correlations
 Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data
 Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
R (2) Data analysis case study using R for readily available data set using any one machine learning algorithm.
 Data analysis case study using R for readily available data set using any one machine learning algorithm.") Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
An Introduction to WEKA Explorer. In part from: Yizhou Sun 2008
 An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy Machine Learning Dr.Ammar Mohammed Nearest Neighbors Set of Stored Cases Atr1... AtrN Class A Store the training samples Use training samples
Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy Machine Learning Dr.Ammar Mohammed Nearest Neighbors Set of Stored Cases Atr1... AtrN Class A Store the training samples Use training samples
Apriori Algorithm. 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
 Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012
 劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012 Overview of Data Mining ( 資料採礦 ) What is Data Mining? Steps in Data Mining Overview of Data Mining techniques Points to Remember Data mining
劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012 Overview of Data Mining ( 資料採礦 ) What is Data Mining? Steps in Data Mining Overview of Data Mining techniques Points to Remember Data mining
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Voronoi Region. K-means method for Signal Compression: Vector Quantization. Compression Formula 11/20/2013
 Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
DATA MINING LECTURE 10B. Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines
 DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Data Mining. Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA.
 Data Mining Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA January 13, 2011 Important Note! This presentation was obtained from Dr. Vijay Raghavan
Data Mining Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA January 13, 2011 Important Note! This presentation was obtained from Dr. Vijay Raghavan
Data mining fundamentals
 Data mining fundamentals Elena Baralis Politecnico di Torino Data analysis Most companies own huge bases containing operational textual documents experiment results These bases are a potential source of
Data mining fundamentals Elena Baralis Politecnico di Torino Data analysis Most companies own huge bases containing operational textual documents experiment results These bases are a potential source of
Data Mining Classification: Alternative Techniques. Lecture Notes for Chapter 4. Instance-Based Learning. Introduction to Data Mining, 2 nd Edition
 Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
I211: Information infrastructure II
 Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Data Structures. Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali Association Rules: Basic Concepts and Application
 Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule