CS 6453: Parameter Server. Soumya Basu March 7, 2017
|
|
|
- Cecil Pitts
- 6 years ago
- Views:
Transcription
1 CS 6453: Parameter Server Soumya Basu March 7, 2017

 (2, -1, 3) (5, 6, 7) Training")
2 What is a Parameter Server? Server for large scale machine learning problems Machine learning tasks in a nutshell: Feature Extraction (1, 1, 1) (2, -1, 3) (5, 6, 7) Training Design a server that makes the above fast!
3 Why Now? Machine learning is important! Read the news to see why Feature extraction fits nicely into Map-Reduce Many systems take care of this problem So, parameter server focuses on training models
4 Training in ML Training consists of the following steps: 1. Initialize model with small random values 2. Try to guess the right answer for your input set 3. Adjust the model 4. Repeat step 2-3 until your error is small enough
5 Systems view of Training Initialize model with small random values Paid once- fairly trivial to parallelize Try to guess the right answer for your input set Iterate through the input set many many times Adjust the model Send a small update to the model parameters
6 Key Challenges Three main challenges of implementing a parameter server: Accessing parameters requires lots of network bandwidth Training is sequential and synchronization is hard to scale Fault tolerance at scale (~25% failure rate for 10k machine-hour jobs)
7 First Attempts First attempts used memcached for synchronization [VLDB 2010] Key-value stores have very large overheads Synchronization costs are expensive and not always necessary
8 Second Generation Second generation of attempts were application specific parameter servers [WDSM 2012, NIPS 2012, NIPS 2013] Fails to factor out common difficulties between many different types of problems Difficult to deploy multiple algorithms in parallel
9 General Purpose ML General purpose machine-learning frameworks Many have synchronization points -> difficult to scale Key observation: cache state between iterations
10 GraphLab Distributed GraphLab [PVLDB 2012] Uses coarse-grained snapshots for fault tolerance, impeding scalability Doesn t scale elastically like map-reduce frameworks Asynchronous task scheduling is the main contribution
11 Piccolo Piccolo [OSDI 2010] Most similar to this paper Is not optimized for Machine Learning though
12 Technical Contribution Recall the three main challenges: Accessing parameters requires lots of network bandwidth Training is sequential and synchronization is hard to scale Fault tolerance at scale
13 Dealing with Parameters What are parameters of a ML model? Usually an element of a vector, matrix, etc. Need to do lots of linear algebra operations Introduce new constraint: ordered keys Typically some index into a linear algebra structure
14 Dealing with Parameters What are parameters of a ML model? Usually an element of a vector, matrix, etc. Need to do lots of linear algebra operations Introduce new constraint: ordered keys Typically some index into a linear algebra structure
15 Dealing with Parameters High model complexity leads to overfitting Updates don t touch many parameters Range push-and-pull: Can update a range of values in a row instead of single key When sending ranges, use compression
16 Synchronization ML models try to find a good local min/min Need updates to be generally in the right direction Not important to have strong consistency guarantees all the time Parameter server introduces Bounded Delay
17 Fault Tolerance Server stores all state, workers are stateless However, workers cache state across iterations Keys are replicated for fault tolerance Jobs are rerun if a worker fails
18 Evaluation
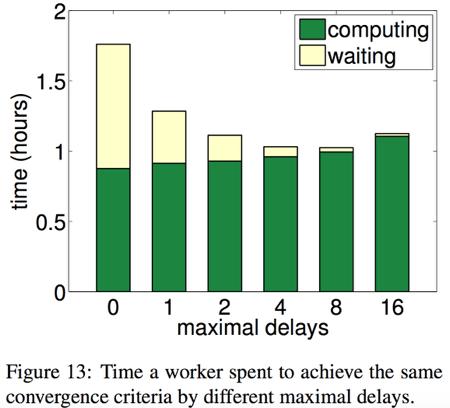
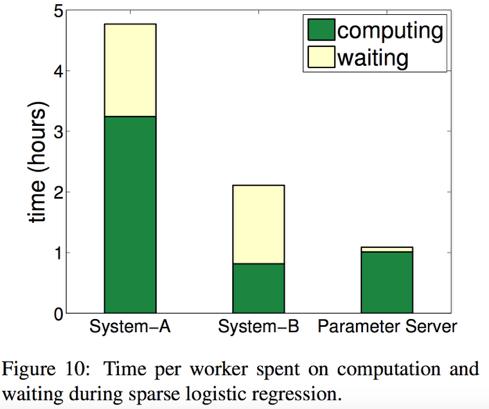
19 Evaluation
20 Limitations Evaluation was done on specially designed ML algorithms Distributed regression and distributed gradient descent How fast is it on a sequential algorithm? Count-Min Sketch is trivially parallelizable No neural networks evaluated?
21 Future Work What happens to sequential ML algorithms? Synchronization cost ignored, rather than resolved Where are the bottlenecks of synchronization? Lots of waiting time, but on what resource(s)?
Scaling Distributed Machine Learning with the Parameter Server
 Scaling Distributed Machine Learning with the Parameter Server Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su Presented
Scaling Distributed Machine Learning with the Parameter Server Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su Presented
Optimizing Network Performance in Distributed Machine Learning. Luo Mai Chuntao Hong Paolo Costa
 Optimizing Network Performance in Distributed Machine Learning Luo Mai Chuntao Hong Paolo Costa Machine Learning Successful in many fields Online advertisement Spam filtering Fraud detection Image recognition
Optimizing Network Performance in Distributed Machine Learning Luo Mai Chuntao Hong Paolo Costa Machine Learning Successful in many fields Online advertisement Spam filtering Fraud detection Image recognition
Scaling Distributed Machine Learning
 Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
15.1 Optimization, scaling, and gradient descent in Spark
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 16, 5/24/2017. Scribed by Andreas Santucci. Overview
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 16, 5/24/2017. Scribed by Andreas Santucci. Overview
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
 Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters Hao Zhang Zeyu Zheng, Shizhen Xu, Wei Dai, Qirong Ho, Xiaodan Liang, Zhiting Hu, Jianliang Wei, Pengtao Xie,
Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters Hao Zhang Zeyu Zheng, Shizhen Xu, Wei Dai, Qirong Ho, Xiaodan Liang, Zhiting Hu, Jianliang Wei, Pengtao Xie,
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
Distributed Machine Learning: An Intro. Chen Huang
 : An Intro. Chen Huang Feature Engineering Group, Data Mining Lab, Big Data Research Center, UESTC Contents Background Some Examples Model Parallelism & Data Parallelism Parallelization Mechanisms Synchronous
: An Intro. Chen Huang Feature Engineering Group, Data Mining Lab, Big Data Research Center, UESTC Contents Background Some Examples Model Parallelism & Data Parallelism Parallelization Mechanisms Synchronous
TensorFlow: A System for Learning-Scale Machine Learning. Google Brain
 TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
Memory Bandwidth and Low Precision Computation. CS6787 Lecture 10 Fall 2018
 Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
 More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server Q. Ho, J. Cipar, H. Cui, J.K. Kim, S. Lee, *P.B. Gibbons, G.A. Gibson, G.R. Ganger, E.P. Xing Carnegie Mellon University
More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server Q. Ho, J. Cipar, H. Cui, J.K. Kim, S. Lee, *P.B. Gibbons, G.A. Gibson, G.R. Ganger, E.P. Xing Carnegie Mellon University
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Send me up to 5 good questions in your opinion, I ll use top ones Via direct message at slack. Can be a group effort. Try to add some explanation.
 Notes Midterm reminder Second midterm next week (04/03), regular class time 20 points, more questions than midterm 1 non-comprehensive exam: no need to study modules before midterm 1 Online testing like
Notes Midterm reminder Second midterm next week (04/03), regular class time 20 points, more questions than midterm 1 non-comprehensive exam: no need to study modules before midterm 1 Online testing like
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability
 Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Memory Bandwidth and Low Precision Computation. CS6787 Lecture 9 Fall 2017
 Memory Bandwidth and Low Precision Computation CS6787 Lecture 9 Fall 2017 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Memory Bandwidth and Low Precision Computation CS6787 Lecture 9 Fall 2017 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Deep Learning Inference as a Service
 Deep Learning Inference as a Service Mohammad Babaeizadeh Hadi Hashemi Chris Cai Advisor: Prof Roy H. Campbell Use case 1: Model Developer Use case 1: Model Developer Inference Service Use case
Deep Learning Inference as a Service Mohammad Babaeizadeh Hadi Hashemi Chris Cai Advisor: Prof Roy H. Campbell Use case 1: Model Developer Use case 1: Model Developer Inference Service Use case
Parallel Stochastic Gradient Descent: The case for native GPU-side GPI
 Parallel Stochastic Gradient Descent: The case for native GPU-side GPI J. Keuper Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Mark Silberstein Accelerated Computer
Parallel Stochastic Gradient Descent: The case for native GPU-side GPI J. Keuper Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Mark Silberstein Accelerated Computer
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
Lecture 22 : Distributed Systems for ML
 10-708: Probabilistic Graphical Models, Spring 2017 Lecture 22 : Distributed Systems for ML Lecturer: Qirong Ho Scribes: Zihang Dai, Fan Yang 1 Introduction Big data has been very popular in recent years.
10-708: Probabilistic Graphical Models, Spring 2017 Lecture 22 : Distributed Systems for ML Lecturer: Qirong Ho Scribes: Zihang Dai, Fan Yang 1 Introduction Big data has been very popular in recent years.
Toward Scalable Deep Learning
 한국정보과학회 인공지능소사이어티 머신러닝연구회 두번째딥러닝워크샵 2015.10.16 Toward Scalable Deep Learning 윤성로 Electrical and Computer Engineering Seoul National University http://data.snu.ac.kr Breakthrough: Big Data + Machine Learning
한국정보과학회 인공지능소사이어티 머신러닝연구회 두번째딥러닝워크샵 2015.10.16 Toward Scalable Deep Learning 윤성로 Electrical and Computer Engineering Seoul National University http://data.snu.ac.kr Breakthrough: Big Data + Machine Learning
Analyzing Stochastic Gradient Descent for Some Non- Convex Problems
 Analyzing Stochastic Gradient Descent for Some Non- Convex Problems Christopher De Sa Soon at Cornell University cdesa@stanford.edu stanford.edu/~cdesa Kunle Olukotun Christopher Ré Stanford University
Analyzing Stochastic Gradient Descent for Some Non- Convex Problems Christopher De Sa Soon at Cornell University cdesa@stanford.edu stanford.edu/~cdesa Kunle Olukotun Christopher Ré Stanford University
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
SCALABLE DISTRIBUTED DEEP LEARNING
 SEOUL Oct.7, 2016 SCALABLE DISTRIBUTED DEEP LEARNING Han Hee Song, PhD Soft On Net 10/7/2016 BATCH PROCESSING FRAMEWORKS FOR DL Data parallelism provides efficient big data processing: data collecting,
SEOUL Oct.7, 2016 SCALABLE DISTRIBUTED DEEP LEARNING Han Hee Song, PhD Soft On Net 10/7/2016 BATCH PROCESSING FRAMEWORKS FOR DL Data parallelism provides efficient big data processing: data collecting,
CS 677 Distributed Operating Systems. Programming Assignment 3: Angry birds : Replication, Fault Tolerance and Cache Consistency
 CS 677 Distributed Operating Systems Spring 2013 Programming Assignment 3: Angry birds : Replication, Fault Tolerance and Cache Consistency Due: Tue Apr 30 2013 You may work in groups of two for this lab
CS 677 Distributed Operating Systems Spring 2013 Programming Assignment 3: Angry birds : Replication, Fault Tolerance and Cache Consistency Due: Tue Apr 30 2013 You may work in groups of two for this lab
Practice Questions for Midterm
 Practice Questions for Midterm - 10-605 Oct 14, 2015 (version 1) 10-605 Name: Fall 2015 Sample Questions Andrew ID: Time Limit: n/a Grade Table (for teacher use only) Question Points Score 1 6 2 6 3 15
Practice Questions for Midterm - 10-605 Oct 14, 2015 (version 1) 10-605 Name: Fall 2015 Sample Questions Andrew ID: Time Limit: n/a Grade Table (for teacher use only) Question Points Score 1 6 2 6 3 15
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models CIEL: A Universal Execution Engine for
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models CIEL: A Universal Execution Engine for
ECE 901: Large-scale Machine Learning and Optimization Spring Lecture 13 March 6
 ECE 901: Large-scale Machine Learning and Optimization Spring 2018 Lecture 13 March 6 Lecturer: Dimitris Papailiopoulos Scribe: Yuhua Zhu & Xiaowu Dai Note: These lecture notes are still rough, and have
ECE 901: Large-scale Machine Learning and Optimization Spring 2018 Lecture 13 March 6 Lecturer: Dimitris Papailiopoulos Scribe: Yuhua Zhu & Xiaowu Dai Note: These lecture notes are still rough, and have
Mining Distributed Frequent Itemset with Hadoop
 Mining Distributed Frequent Itemset with Hadoop Ms. Poonam Modgi, PG student, Parul Institute of Technology, GTU. Prof. Dinesh Vaghela, Parul Institute of Technology, GTU. Abstract: In the current scenario
Mining Distributed Frequent Itemset with Hadoop Ms. Poonam Modgi, PG student, Parul Institute of Technology, GTU. Prof. Dinesh Vaghela, Parul Institute of Technology, GTU. Abstract: In the current scenario
Practical Near-Data Processing for In-Memory Analytics Frameworks
 Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
CS8803: Statistical Techniques in Robotics Byron Boots. Thoughts on Machine Learning and Robotics. (how to apply machine learning in practice)
") CS8803: Statistical Techniques in Robotics Byron Boots Thoughts on Machine Learning and Robotics (how to apply machine learning in practice) 1 CS8803: Statistical Techniques in Robotics Byron Boots Thoughts
CS8803: Statistical Techniques in Robotics Byron Boots Thoughts on Machine Learning and Robotics (how to apply machine learning in practice) 1 CS8803: Statistical Techniques in Robotics Byron Boots Thoughts
HP Designing and Implementing HP Enterprise Backup Solutions. Download Full Version :
 HP HP0-771 Designing and Implementing HP Enterprise Backup Solutions Download Full Version : http://killexams.com/pass4sure/exam-detail/hp0-771 A. copy backup B. normal backup C. differential backup D.
HP HP0-771 Designing and Implementing HP Enterprise Backup Solutions Download Full Version : http://killexams.com/pass4sure/exam-detail/hp0-771 A. copy backup B. normal backup C. differential backup D.
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
NFSv4 as the Building Block for Fault Tolerant Applications
 NFSv4 as the Building Block for Fault Tolerant Applications Alexandros Batsakis Overview Goal: To provide support for recoverability and application fault tolerance through the NFSv4 file system Motivation:
NFSv4 as the Building Block for Fault Tolerant Applications Alexandros Batsakis Overview Goal: To provide support for recoverability and application fault tolerance through the NFSv4 file system Motivation:
The former pager tasks have been replaced in 7.9 by the special savepoint tasks.
 1 2 3 4 With version 7.7 the I/O interface to the operating system has been reimplemented. As of version 7.7 different parameters than in version 7.6 are used. The improved I/O system has the following
1 2 3 4 With version 7.7 the I/O interface to the operating system has been reimplemented. As of version 7.7 different parameters than in version 7.6 are used. The improved I/O system has the following
Large Scale Distributed Deep Networks
 Large Scale Distributed Deep Networks Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP630030 Data Intensive Computing Report, 2013 Yifu Huang (FDU CS) COMP630030 Report
Large Scale Distributed Deep Networks Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP630030 Data Intensive Computing Report, 2013 Yifu Huang (FDU CS) COMP630030 Report
Distributed and Fault-Tolerant Execution Framework for Transaction Processing
 Distributed and Fault-Tolerant Execution Framework for Transaction Processing May 30, 2011 Toshio Suganuma, Akira Koseki, Kazuaki Ishizaki, Yohei Ueda, Ken Mizuno, Daniel Silva *, Hideaki Komatsu, Toshio
Distributed and Fault-Tolerant Execution Framework for Transaction Processing May 30, 2011 Toshio Suganuma, Akira Koseki, Kazuaki Ishizaki, Yohei Ueda, Ken Mizuno, Daniel Silva *, Hideaki Komatsu, Toshio
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Towards the world s fastest k-means algorithm
 Greg Hamerly Associate Professor Computer Science Department Baylor University Joint work with Jonathan Drake May 15, 2014 Objective function and optimization Lloyd s algorithm 1 The k-means clustering
Greg Hamerly Associate Professor Computer Science Department Baylor University Joint work with Jonathan Drake May 15, 2014 Objective function and optimization Lloyd s algorithm 1 The k-means clustering
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
CSE 5306 Distributed Systems. Consistency and Replication
 CSE 5306 Distributed Systems Consistency and Replication 1 Reasons for Replication Data are replicated for the reliability of the system Servers are replicated for performance Scaling in numbers Scaling
CSE 5306 Distributed Systems Consistency and Replication 1 Reasons for Replication Data are replicated for the reliability of the system Servers are replicated for performance Scaling in numbers Scaling
Parallel Computing. Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides)
, A Grama book (chapter 3 slides)") Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Closing Thoughts on Machine Learning (ML in Practice)
") Closing Thoughts on (ML in Practice) 1 Closing Thoughts on (ML in Practice) 1 When someone asks What is? Learning is any process by which a system improves performance from experience. - Herbert Simon
Closing Thoughts on (ML in Practice) 1 Closing Thoughts on (ML in Practice) 1 When someone asks What is? Learning is any process by which a system improves performance from experience. - Herbert Simon
CSCE 626 Experimental Evaluation.
 CSCE 626 Experimental Evaluation http://parasol.tamu.edu Introduction This lecture discusses how to properly design an experimental setup, measure and analyze the performance of parallel algorithms you
CSCE 626 Experimental Evaluation http://parasol.tamu.edu Introduction This lecture discusses how to properly design an experimental setup, measure and analyze the performance of parallel algorithms you
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Huge market -- essentially all high performance databases work this way
 11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
CS454/654 Midterm Exam Fall 2004
 CS454/654 Midterm Exam Fall 2004 (3 November 2004) Question 1: Distributed System Models (18 pts) (a) [4 pts] Explain two benefits of middleware to distributed system programmers, providing an example
CS454/654 Midterm Exam Fall 2004 (3 November 2004) Question 1: Distributed System Models (18 pts) (a) [4 pts] Explain two benefits of middleware to distributed system programmers, providing an example
Parallel Methods for Convex Optimization. A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney
 Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
MapReduce-II. September 2013 Alberto Abelló & Oscar Romero 1
 MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
740: Computer Architecture Memory Consistency. Prof. Onur Mutlu Carnegie Mellon University
 740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
CS273 Midterm Exam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014
 CS273 Midterm Eam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014 Your name: Your UCINetID (e.g., myname@uci.edu): Your seat (row and number): Total time is 80 minutes. READ THE
CS273 Midterm Eam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014 Your name: Your UCINetID (e.g., myname@uci.edu): Your seat (row and number): Total time is 80 minutes. READ THE
Copyright 2013 Thomas W. Doeppner. IX 1
 Copyright 2013 Thomas W. Doeppner. IX 1 If we have only one thread, then, no matter how many processors we have, we can do only one thing at a time. Thus multiple threads allow us to multiplex the handling
Copyright 2013 Thomas W. Doeppner. IX 1 If we have only one thread, then, no matter how many processors we have, we can do only one thing at a time. Thus multiple threads allow us to multiplex the handling
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
COMP6237 Data Mining Data Mining & Machine Learning with Big Data. Jonathon Hare
 COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
Orleans. Cloud Computing for Everyone. Hamid R. Bazoobandi. March 16, Vrije University of Amsterdam
 Orleans Cloud Computing for Everyone Hamid R. Bazoobandi Vrije University of Amsterdam March 16, 2012 Vrije University of Amsterdam Orleans 1 Outline 1 Introduction 2 Orleans Orleans overview Grains Promise
Orleans Cloud Computing for Everyone Hamid R. Bazoobandi Vrije University of Amsterdam March 16, 2012 Vrije University of Amsterdam Orleans 1 Outline 1 Introduction 2 Orleans Orleans overview Grains Promise
Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU?
 Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU? Florin Rusu Yujing Ma, Martin Torres (Ph.D. students) University of California Merced Machine Learning (ML) Boom Two SIGMOD
Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU? Florin Rusu Yujing Ma, Martin Torres (Ph.D. students) University of California Merced Machine Learning (ML) Boom Two SIGMOD
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
what is cloud computing?
 what is cloud computing? (Private) Cloud Computing with Mesos at Twi9er Benjamin Hindman @benh scalable virtualized self-service utility managed elastic economic pay-as-you-go what is cloud computing?
what is cloud computing? (Private) Cloud Computing with Mesos at Twi9er Benjamin Hindman @benh scalable virtualized self-service utility managed elastic economic pay-as-you-go what is cloud computing?
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Mutual consistency, what for? Replication. Data replication, consistency models & protocols. Difficulties. Execution Model.
 Replication Data replication, consistency models & protocols C. L. Roncancio - S. Drapeau Grenoble INP Ensimag / LIG - Obeo 1 Data and process Focus on data: several physical of one logical object What
Replication Data replication, consistency models & protocols C. L. Roncancio - S. Drapeau Grenoble INP Ensimag / LIG - Obeo 1 Data and process Focus on data: several physical of one logical object What
MapReduce ML & Clustering Algorithms
 MapReduce ML & Clustering Algorithms Reminder MapReduce: A trade-off between ease of use & possible parallelism Graph Algorithms Approaches: Reduce input size (filtering) Graph specific optimizations (Pregel
MapReduce ML & Clustering Algorithms Reminder MapReduce: A trade-off between ease of use & possible parallelism Graph Algorithms Approaches: Reduce input size (filtering) Graph specific optimizations (Pregel
Parallel Streaming Computation on Error-Prone Processors. Yavuz Yetim, Margaret Martonosi, Sharad Malik
 Parallel Streaming Computation on Error-Prone Processors Yavuz Yetim, Margaret Martonosi, Sharad Malik Upsets/B muons/mb Average Number of Dopant Atoms Hardware Errors on the Rise Soft Errors Due to Cosmic
Parallel Streaming Computation on Error-Prone Processors Yavuz Yetim, Margaret Martonosi, Sharad Malik Upsets/B muons/mb Average Number of Dopant Atoms Hardware Errors on the Rise Soft Errors Due to Cosmic
Microservices, Messaging and Science Gateways. Review microservices for science gateways and then discuss messaging systems.
 Microservices, Messaging and Science Gateways Review microservices for science gateways and then discuss messaging systems. Micro- Services Distributed Systems DevOps The Gateway Octopus Diagram Browser
Microservices, Messaging and Science Gateways Review microservices for science gateways and then discuss messaging systems. Micro- Services Distributed Systems DevOps The Gateway Octopus Diagram Browser
MLlib. Distributed Machine Learning on. Evan Sparks. UC Berkeley
 MLlib & ML base Distributed Machine Learning on Evan Sparks UC Berkeley January 31st, 2014 Collaborators: Ameet Talwalkar, Xiangrui Meng, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia,
MLlib & ML base Distributed Machine Learning on Evan Sparks UC Berkeley January 31st, 2014 Collaborators: Ameet Talwalkar, Xiangrui Meng, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia,
Understanding Parallelism and the Limitations of Parallel Computing
 Understanding Parallelism and the Limitations of Parallel omputing Understanding Parallelism: Sequential work After 16 time steps: 4 cars Scalability Laws 2 Understanding Parallelism: Parallel work After
Understanding Parallelism and the Limitations of Parallel omputing Understanding Parallelism: Sequential work After 16 time steps: 4 cars Scalability Laws 2 Understanding Parallelism: Parallel work After
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CS4961 Parallel Programming. Lecture 10: Data Locality, cont. Writing/Debugging Parallel Code 09/23/2010
 Parallel Programming Lecture 10: Data Locality, cont. Writing/Debugging Parallel Code Mary Hall September 23, 2010 1 Observations from the Assignment Many of you are doing really well Some more are doing
Parallel Programming Lecture 10: Data Locality, cont. Writing/Debugging Parallel Code Mary Hall September 23, 2010 1 Observations from the Assignment Many of you are doing really well Some more are doing
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Apache Flink- A System for Batch and Realtime Stream Processing
 Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
Parallel Deep Network Training
 Lecture 26: Parallel Deep Network Training Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Tunes Speech Debelle Finish This Album (Speech Therapy) Eat your veggies and study
Lecture 26: Parallel Deep Network Training Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Tunes Speech Debelle Finish This Album (Speech Therapy) Eat your veggies and study
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models
 Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
CCDP-ARCH. Section 11. Content Networking
 CCDP-ARCH Section 11 As a designer, content networking technologies allows you to intelligently distribute content throughout the network, thereby reducing WAN bandwidth requirements. For example, a user
CCDP-ARCH Section 11 As a designer, content networking technologies allows you to intelligently distribute content throughout the network, thereby reducing WAN bandwidth requirements. For example, a user
Asynchronous Parallel Stochastic Gradient Descent. A Numeric Core for Scalable Distributed Machine Learning Algorithms
 Asynchronous Parallel Stochastic Gradient Descent A Numeric Core for Scalable Distributed Machine Learning Algorithms J. Keuper and F.-J. Pfreundt Competence Center High Performance Computing Fraunhofer
Asynchronous Parallel Stochastic Gradient Descent A Numeric Core for Scalable Distributed Machine Learning Algorithms J. Keuper and F.-J. Pfreundt Competence Center High Performance Computing Fraunhofer
AN exam March
 AN exam March 29 2018 Dear student This exam consists of 7 questions. The total number of points is 100. Read the questions carefully. Be precise and concise. Write in a readable way. Q1. UDP and TCP (25
AN exam March 29 2018 Dear student This exam consists of 7 questions. The total number of points is 100. Read the questions carefully. Be precise and concise. Write in a readable way. Q1. UDP and TCP (25
CS 598: Communication Cost Analysis of Algorithms Lecture 7: parallel algorithms for QR factorization
 CS 598: Communication Cost Analysis of Algorithms Lecture 7: parallel algorithms for QR factorization Edgar Solomonik University of Illinois at Urbana-Champaign September 14, 2016 Parallel Householder
CS 598: Communication Cost Analysis of Algorithms Lecture 7: parallel algorithms for QR factorization Edgar Solomonik University of Illinois at Urbana-Champaign September 14, 2016 Parallel Householder
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Providing Real-Time and Fault Tolerance for CORBA Applications
 Providing Real-Time and Tolerance for CORBA Applications Priya Narasimhan Assistant Professor of ECE and CS University Pittsburgh, PA 15213-3890 Sponsored in part by the CMU-NASA High Dependability Computing
Providing Real-Time and Tolerance for CORBA Applications Priya Narasimhan Assistant Professor of ECE and CS University Pittsburgh, PA 15213-3890 Sponsored in part by the CMU-NASA High Dependability Computing
Distributed Systems Principles and Paradigms
 Distributed Systems Principles and Paradigms Chapter 03 (version February 11, 2008) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.20.
Distributed Systems Principles and Paradigms Chapter 03 (version February 11, 2008) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.20.
Lecture 28 Introduction to Parallel Processing and some Architectural Ramifications. Flynn s Taxonomy. Multiprocessing.
 1 2 Lecture 28 Introduction to arallel rocessing and some Architectural Ramifications 3 4 ultiprocessing Flynn s Taxonomy Flynn s Taxonomy of arallel achines How many Instruction streams? How many Data
1 2 Lecture 28 Introduction to arallel rocessing and some Architectural Ramifications 3 4 ultiprocessing Flynn s Taxonomy Flynn s Taxonomy of arallel achines How many Instruction streams? How many Data
Lecture 6 Consistency and Replication
 Lecture 6 Consistency and Replication Prof. Wilson Rivera University of Puerto Rico at Mayaguez Electrical and Computer Engineering Department Outline Data-centric consistency Client-centric consistency
Lecture 6 Consistency and Replication Prof. Wilson Rivera University of Puerto Rico at Mayaguez Electrical and Computer Engineering Department Outline Data-centric consistency Client-centric consistency
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Byzantine Fault Tolerance and Consensus. Adi Seredinschi Distributed Programming Laboratory
 Byzantine Fault Tolerance and Consensus Adi Seredinschi Distributed Programming Laboratory 1 (Original) Problem Correct process General goal: Run a distributed algorithm 2 (Original) Problem Correct process
Byzantine Fault Tolerance and Consensus Adi Seredinschi Distributed Programming Laboratory 1 (Original) Problem Correct process General goal: Run a distributed algorithm 2 (Original) Problem Correct process
Assignment 5. Georgia Koloniari
 Assignment 5 Georgia Koloniari 2. "Peer-to-Peer Computing" 1. What is the definition of a p2p system given by the authors in sec 1? Compare it with at least one of the definitions surveyed in the last
Assignment 5 Georgia Koloniari 2. "Peer-to-Peer Computing" 1. What is the definition of a p2p system given by the authors in sec 1? Compare it with at least one of the definitions surveyed in the last
Current Topics in OS Research. So, what s hot?
 Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
ACMS: The Akamai Configuration Management System. A. Sherman, P. H. Lisiecki, A. Berkheimer, and J. Wein
 ACMS: The Akamai Configuration Management System A. Sherman, P. H. Lisiecki, A. Berkheimer, and J. Wein Instructor: Fabian Bustamante Presented by: Mario Sanchez The Akamai Platform Over 15,000 servers
ACMS: The Akamai Configuration Management System A. Sherman, P. H. Lisiecki, A. Berkheimer, and J. Wein Instructor: Fabian Bustamante Presented by: Mario Sanchez The Akamai Platform Over 15,000 servers
Training Deep Neural Networks (in parallel)
") Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected