Spanner : Google's Globally-Distributed Database. James Sedgwick and Kayhan Dursun
|
|
|
- Morris Stewart
- 6 years ago
- Views:
Transcription
1 Spanner : Google's Globally-Distributed Database James Sedgwick and Kayhan Dursun
2 Spanner - A multi-version, globally-distributed, synchronously-replicated database - First system to - Distribute data globally - Externally-consistent distributed Xacts.
3 Introduction - Spanner? - System that shards data across Paxos machines into data centers all around the world. - Designed to scale up to millions of machines and trillions of database rows.
4 Features - Dynamic replication configurations - Constraints to manage - Read latency - Write latency - Durability, availability - Balancing
5 Features cont. - Externally consistent reads and writes - Globally consistent reads Why consistency matters?

6 Implementation - Set of zones = set of locations of dist. data - Can be more than one zone in a datacenter

7 Spanserver Software Stack Tablet: (key:string, timestamp:int) -> string Paxos: Replication sup. - Writes initiate protocol at leader - Reads from the tablet directly - Lock table - Trans. manager

8 Directories - A bucketing abstraction - Unit of data placement - Movement - Load balancing - Access patterns - Accessors
9 Data model - A data model based on schematized semi-relational tables - With popularity of Megastore - Query language - With popularity of Dremel - General-purpose Xacts. - Experienced the lack with BigTable
10 Data Model cont. - Not purely relational (rows have names) - DB must be partitioned into hierarchies
11 TrueTime Method Returns TT.now() TT.after(t) TT.before(t) TTinterval: [earliest, latest] true if t has definitely passed true if t has definitely not arrived Represents time as intervals with bounded uncertainty Let instantaneous error be e (half of interval width) Let average error be ē Formal guarantee: Let t abs (e) be the absolute time of event e For tt = TT.now(), tt.earliest <= t abs (e) <= tt.latest where e is the invocation event
12 TrueTime implementation Two underlying time references, used together because they have disjoint failure modes GPS: Antenna/receiver failures, interference, GPS system outage Atomic clock: Drift, etc Set of time masters per datacenter (mixed GPS and atomic) Each server runs a time daemon Masters cross-check time against other masters and rate of local clock Masters advertise uncertainty GPS uncertainty near zero, atomic uncertainty grows based on worst case clock drift Masters can evict themselves if their uncertainty grows too high
13 TrueTime implementation, contd. Time daemons poll a variety of masters (local and remote GPS masters as well as atomic) Use variant of Marzullo's algorithm to detect liars Sync local clocks to non-liars Between syncs, daemons advertise slowly increasing uncertainty Derived from worst-case local drift, time master uncertainty, and communication delay to masters e as seen by TrueTime client thus has sawtooth pattern varies from about 1 to 7 ms over each poll interval Time master unavailability and overloaded machines/network can cause spikes in e
14 Spanner Operations Read-write transactions Standalone writes are a subset Read-only transactions Non-snapshot standalone reads are a subset Executed at system-chosen timestamp without locking, such that writes are not blocked. Executed on any replica that is sufficiently up to date w.r.t. chosen timestamp Snapshot reads Client provided timestamp or upper time bound
15 Paxos Invariants Spanner's Paxos implementation used timed (10 second) leader leases to make leadership long lived Candidate becomes leader after receiving quorum of timed lease votes Replicas extend lease votes implicitly on writes. Leader requests a lease extension from a replica if its vote is close to expiration. Define a lease interval as starting when a quorum is achieved, and ending when a quorum is lost Spanner requires monotonically increasing Paxos write timestamps across leaders in a group, so it is critical that leader lease intervals are disjoint To achieve disjointness, a leader could log its interval via Paxos, and subsequent leaders could wait for this interval before taking over. Spanner avoids this Paxos communication and preserves disjointness via a TrueTime-based mechanism described in Appendix A. It's in an appendix because it's complicated. Also: leaders can abdicate, but must wait until TT.after(s max ) is true, where s max is the maximum timestamp used by a leader, to preserve disjointness
16 Proof of Externally Consistent RW Transactions External consistency: if the start of T 2 occurs after the commit of T 1, then the commit timestamp of T 2 is after the commit timestamp of T 1 Let start, commit request, and commit events be e i, start, e i, server, and e i, commit Thus, formally: if t abs (e 1, commit ) < t abs (e 2, start ), then s 1 < s 2 Start: Coordinator leader assigns timestamp s i to transaction T i s.t. s i is no less than TT.now().latest, computed after e i, server Commit wait: Coordinator leader ensures clients can't see effects of T i before TT.after(s i ) is true. That is, s i < t abs (e i, commit ) s 1 < t abs (e 1, commit ) (commit wait) t abs (e 1, commit ) < t abs (e 2, start ) (assumption) t abs (e 2, start ) <= t abs (e 2, server ) (causality) t abs (e 2, server ) <= s 2 (start) s 1 < s 2 (transitivity)
17 Serving Reads at a Timestamp Each replica tracks safe time t safe, which is the maximum timestamp at which it is up to date. Replica can read at t if t <= t safe t safe = min(t Paxos-safe, t TM-safe ) t Paxos-safe is just the timestamp of the highest applied Paxos write on the replica. Paxos write times increase monotonically, so writes will not occur at or below t Paxos-safe w.r.t. Paxos t TM-safe accounts for uncommitted transactions in the replica's group. Every participant leader (of group g) for transaction T i assigns prepare timestamp s i,g - prepare to its record. This timestamp is propagated to g via Paxos. The coordinator leader ensures that commit time s i of T i >= s i,g - prepare for each participant group g. Thus, t TM-safe = min i (s i,g - prepare ) - 1 Thus, t TM-safe is guaranteed to be before all prepared but uncommitted transactions in the replica's group
18 Assigning Timestamps to RO Transactions To execute a read-only transaction, pick timestamp s read, then execute as snapshot reads at s read at sufficiently up to date replicas. Picking TT.now().latest after the transaction start will definitely preserve external consistency, but may block unnecessarily long while waiting for t safe to advance. Choose the oldest timestamp that preserves external consistency: LastTS. Can do better than now if there are no prepared transactions If the read's scope is a single Paxos group, simply choose the timestamp of the last committed write at that group. If the read's scope encompasses multiple groups, a negotiation could occur among group leaders to determine max g (LastTS g ) Current implementation avoids this communication and simply uses TT.now().latest
19 Details of RW Transactions, pt. 1 Client issues reads to leader replicas of appropriate groups. These acquire read locks and read the most recent data. Once reads are completed and writes are buffered (at the client), client chooses a coordinator leader and sends the identity of the leader along with buffered writes to participant leaders. Non-coordinator participant leaders acquire write locks choose a prepare timestamp larger than any previous transaction timestamps log a prepare record in Paxos notify coordinator of chosen timestamp.
20 Details of RW Transactions, pt. 2 Coordinator leader acquires locks picks a commit timestamp s greater than TT.now().latest, greater than or equal to all participant prepare timestamps, and greater than any previous transaction timestamps assigned by the leader logs commit record in Paxos Coordinator waits until TT.after(s) to allow replicas to commit T, to obey commit wait Since s > TT.now().latest, expected wait is at least 2 * ē After commit wait, timestamp is sent to the client and all participant leaders Each leader logs commit timestamp via Paxos, and all participants then apply at the same timestamp and release locks
21 Schema-Change Transactions Spanner supports atomic schema changes Can't use a standard transaction, since the number of participants (number of groups in the database) could be in the millions Use a non-blocking transaction Explicitly assign a timestamp t in the future to the transaction in the prepare phase Reads and writes synchronize around this timestamp If their timestamps precede t, proceed If their timestamps are after t, block behind schema change
22 Refinements A single prepared transaction blocks T TM-safe from advancing. What if the prepared transactions don't conflict with the read? Augment T TM-safe with mappings from key ranges to prepare timestamps. When calculating T TM-safe as the minimum timestamp of prepared transactions in a group, consult these mappings and only consider transactions which conflict with the read Similar problem with LastTS - when assigning a timestamp to a read-only transaction, we must wait until after all previous commit timestamps, even if those commits don't conflict with the read. Similar solution - maintain mappings of key ranges to commit timestamps, and only consider conflicting commits when calculating a maximum
23 Refinements t Paxos-safe cannot advance without Paxos writes, so snapshots reads at t cannot proceed at groups whose last Paxos write occurred before t. Paxos leaders instead advance t Paxos-safe by keeping track of the timestamp above which future Paxos writes will occur. Maintain mapping MinNextTS(n) from Paxos sequence number n to the minimum timestamp that can be assigned to the Paxos write n + 1 Leaders advance MinNextTS(n) s.t. it doesn't extend past their lease. Advances occur every 8 seconds by default, so in the worst case, replicas can serve reads no more recently than 8 seconds ago Advances can occur by a replica's request as well
24 Evaluation - Availability - TrueTime - Running system F1
25 Availability - Results of 3 experiments in the presence of datacenter failures. - 5 zones, each has 25 spanservers. - Data sharded into 1250 paxos groups.
26 Availability - leader-hard kill: 10 sec. after killing, throughput is recovered
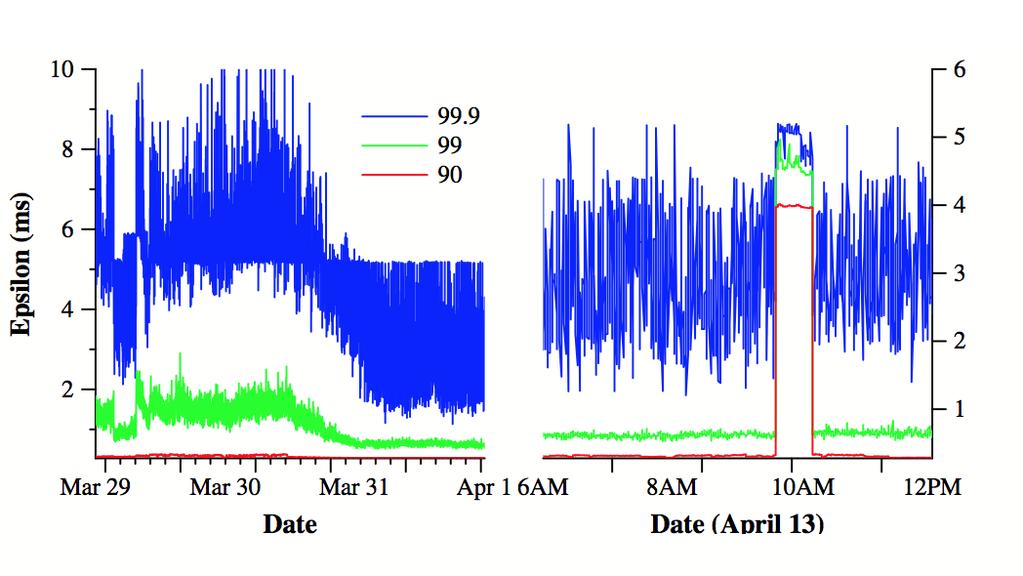
27 TrueTime

28 F1 - First was based on MySql - Spanner removes the need to manually reshard - Provides synchronous replication and automatic failover - F1 requires strong transactional semantics
29 Thank you!
Spanner: Google's Globally-Distributed Database. Presented by Maciej Swiech
 Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
Spanner: Google s Globally- Distributed Database
 Spanner: Google s Globally- Distributed Database Google, Inc. OSDI 2012 Presented by: Karen Ouyang Problem Statement Distributed data system with high availability Support external consistency! Key Ideas
Spanner: Google s Globally- Distributed Database Google, Inc. OSDI 2012 Presented by: Karen Ouyang Problem Statement Distributed data system with high availability Support external consistency! Key Ideas
Corbett et al., Spanner: Google s Globally-Distributed Database
 Corbett et al., : Google s Globally-Distributed Database MIMUW 2017-01-11 ACID transactions ACID transactions SQL queries ACID transactions SQL queries Semi-relational data model ACID transactions SQL
Corbett et al., : Google s Globally-Distributed Database MIMUW 2017-01-11 ACID transactions ACID transactions SQL queries ACID transactions SQL queries Semi-relational data model ACID transactions SQL
Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013
 Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013 *OSDI '12, James C. Corbett et al. (26 authors), Jay Lepreau Best Paper Award Outline What is Spanner? Features & Example Structure
Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013 *OSDI '12, James C. Corbett et al. (26 authors), Jay Lepreau Best Paper Award Outline What is Spanner? Features & Example Structure
Google Spanner - A Globally Distributed,
 Google Spanner - A Globally Distributed, Synchronously-Replicated Database System James C. Corbett, et. al. Feb 14, 2013. Presented By Alexander Chow For CS 742 Motivation Eventually-consistent sometimes
Google Spanner - A Globally Distributed, Synchronously-Replicated Database System James C. Corbett, et. al. Feb 14, 2013. Presented By Alexander Chow For CS 742 Motivation Eventually-consistent sometimes
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database.
 Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Beyond TrueTime: Using AugmentedTime for Improving Spanner
 Beyond TrueTime: Using AugmentedTime for Improving Spanner Murat Demirbas University at Buffalo, SUNY demirbas@cse.buffalo.edu Sandeep Kulkarni Michigan State University, sandeep@cse.msu.edu Spanner [1]
Beyond TrueTime: Using AugmentedTime for Improving Spanner Murat Demirbas University at Buffalo, SUNY demirbas@cse.buffalo.edu Sandeep Kulkarni Michigan State University, sandeep@cse.msu.edu Spanner [1]
Distributed Systems. 19. Spanner. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Distributed Data Management. Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig
 Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Sommerfest! Distributed Data Management Christoph Lofi IfIS TU
Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Sommerfest! Distributed Data Management Christoph Lofi IfIS TU
Spanner: Google s Globally-Distributed Database. Wilson Hsieh representing a host of authors OSDI 2012
 Spanner: Google s Globally-Distributed Database Wilson Hsieh representing a host of authors OSDI 2012 What is Spanner? Distributed multiversion database General-purpose transactions (ACID) SQL query language
Spanner: Google s Globally-Distributed Database Wilson Hsieh representing a host of authors OSDI 2012 What is Spanner? Distributed multiversion database General-purpose transactions (ACID) SQL query language
Distributed Transactions
 Distributed Transactions CS6450: Distributed Systems Lecture 17 Ryan Stutsman Material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University.
Distributed Transactions CS6450: Distributed Systems Lecture 17 Ryan Stutsman Material taken/derived from Princeton COS-418 materials created by Michael Freedman and Kyle Jamieson at Princeton University.
Multi-version concurrency control
 MVCC and Distributed Txns (Spanner) 2P & CC = strict serialization Provides semantics as if only one transaction was running on DB at time, in serial order + Real-time guarantees CS 518: Advanced Computer
MVCC and Distributed Txns (Spanner) 2P & CC = strict serialization Provides semantics as if only one transaction was running on DB at time, in serial order + Real-time guarantees CS 518: Advanced Computer
Concurrency Control II and Distributed Transactions
 Concurrency Control II and Distributed Transactions CS 240: Computing Systems and Concurrency Lecture 18 Marco Canini Credits: Michael Freedman and Kyle Jamieson developed much of the original material.
Concurrency Control II and Distributed Transactions CS 240: Computing Systems and Concurrency Lecture 18 Marco Canini Credits: Michael Freedman and Kyle Jamieson developed much of the original material.
Spanner: Google s Globally- Distributed Database
 Today s Reminders Spanner: Google s Globally-Distributed Database Discuss Project Ideas with Phil & Kevin Phil s Office Hours: After class today Sign up for a slot: 11-12:30 or 3-4:20 this Friday Phil
Today s Reminders Spanner: Google s Globally-Distributed Database Discuss Project Ideas with Phil & Kevin Phil s Office Hours: After class today Sign up for a slot: 11-12:30 or 3-4:20 this Friday Phil
Multi-version concurrency control
 Spanner Storage insights 2P & CC = strict serialization Provides semantics as if only one transaction was running on DB at time, in serial order + Real-time guarantees CS 518: Advanced Computer Systems
Spanner Storage insights 2P & CC = strict serialization Provides semantics as if only one transaction was running on DB at time, in serial order + Real-time guarantees CS 518: Advanced Computer Systems
Distributed Systems. GFS / HDFS / Spanner
 15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
NewSQL Databases. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica NewSQL Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica NewSQL Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES
 MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES Divy Agrawal Department of Computer Science University of California at Santa Barbara Joint work with: Amr El Abbadi, Hatem Mahmoud, Faisal
MINIMIZING TRANSACTION LATENCY IN GEO-REPLICATED DATA STORES Divy Agrawal Department of Computer Science University of California at Santa Barbara Joint work with: Amr El Abbadi, Hatem Mahmoud, Faisal
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Building Consistent Transactions with Inconsistent Replication
 Building Consistent Transactions with Inconsistent Replication Irene Zhang, Naveen Kr. Sharma, Adriana Szekeres, Arvind Krishnamurthy, Dan R. K. Ports University of Washington Distributed storage systems
Building Consistent Transactions with Inconsistent Replication Irene Zhang, Naveen Kr. Sharma, Adriana Szekeres, Arvind Krishnamurthy, Dan R. K. Ports University of Washington Distributed storage systems
10. Replication. Motivation
 10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
Cloud Computing. DB Special Topics Lecture (10/5/2012) Kyle Hale Maciej Swiech
 Kyle Hale Maciej Swiech") Cloud Computing DB Special Topics Lecture (10/5/2012) Kyle Hale Maciej Swiech Managing servers isn t for everyone What are some prohibitive issues? (we touched on these last time) Cost (initial/operational)
Cloud Computing DB Special Topics Lecture (10/5/2012) Kyle Hale Maciej Swiech Managing servers isn t for everyone What are some prohibitive issues? (we touched on these last time) Cost (initial/operational)
Performance and Forgiveness. June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences
 Performance and Forgiveness June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences Margo Seltzer Architect Outline A consistency primer Techniques and costs of consistency
Performance and Forgiveness June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences Margo Seltzer Architect Outline A consistency primer Techniques and costs of consistency
EECS 498 Introduction to Distributed Systems
 EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
There Is More Consensus in Egalitarian Parliaments
 There Is More Consensus in Egalitarian Parliaments Iulian Moraru, David Andersen, Michael Kaminsky Carnegie Mellon University Intel Labs Fault tolerance Redundancy State Machine Replication 3 State Machine
There Is More Consensus in Egalitarian Parliaments Iulian Moraru, David Andersen, Michael Kaminsky Carnegie Mellon University Intel Labs Fault tolerance Redundancy State Machine Replication 3 State Machine
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
How do we build TiDB. a Distributed, Consistent, Scalable, SQL Database
 How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
Consistency in Distributed Systems
 Consistency in Distributed Systems Recall the fundamental DS properties DS may be large in scale and widely distributed 1. concurrent execution of components 2. independent failure modes 3. transmission
Consistency in Distributed Systems Recall the fundamental DS properties DS may be large in scale and widely distributed 1. concurrent execution of components 2. independent failure modes 3. transmission
DrRobert N. M. Watson
 Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
Building Consistent Transactions with Inconsistent Replication
 DB Reading Group Fall 2015 slides by Dana Van Aken Building Consistent Transactions with Inconsistent Replication Irene Zhang, Naveen Kr. Sharma, Adriana Szekeres, Arvind Krishnamurthy, Dan R. K. Ports
DB Reading Group Fall 2015 slides by Dana Van Aken Building Consistent Transactions with Inconsistent Replication Irene Zhang, Naveen Kr. Sharma, Adriana Szekeres, Arvind Krishnamurthy, Dan R. K. Ports
How we build TiDB. Max Liu PingCAP Amsterdam, Netherlands October 5, 2016
 How we build TiDB Max Liu PingCAP Amsterdam, Netherlands October 5, 2016 About me Infrastructure engineer / CEO of PingCAP Working on open source projects: TiDB: https://github.com/pingcap/tidb TiKV: https://github.com/pingcap/tikv
How we build TiDB Max Liu PingCAP Amsterdam, Netherlands October 5, 2016 About me Infrastructure engineer / CEO of PingCAP Working on open source projects: TiDB: https://github.com/pingcap/tidb TiKV: https://github.com/pingcap/tikv
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
Consistency and Replication. Why replicate?
 Consistency and Replication Today: Introduction Consistency models Data-centric consistency models Client-centric consistency models Thoughts for the mid-term Lecture 14, page 1 Why replicate? Data replication:
Consistency and Replication Today: Introduction Consistency models Data-centric consistency models Client-centric consistency models Thoughts for the mid-term Lecture 14, page 1 Why replicate? Data replication:
Consistency and Replication (part b)
") Consistency and Replication (part b) EECS 591 Farnam Jahanian University of Michigan Tanenbaum Chapter 6.1-6.5 Eventual Consistency A very weak consistency model characterized by the lack of simultaneous
Consistency and Replication (part b) EECS 591 Farnam Jahanian University of Michigan Tanenbaum Chapter 6.1-6.5 Eventual Consistency A very weak consistency model characterized by the lack of simultaneous
The Chubby Lock Service for Loosely-coupled Distributed systems
 The Chubby Lock Service for Loosely-coupled Distributed systems Author: Mike Burrows Presenter: Ke Nian University of Waterloo, Waterloo, Canada October 22, 2014 Agenda Distributed Consensus Problem 3
The Chubby Lock Service for Loosely-coupled Distributed systems Author: Mike Burrows Presenter: Ke Nian University of Waterloo, Waterloo, Canada October 22, 2014 Agenda Distributed Consensus Problem 3
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 (Fall 2018) Part 7: Mutable State (2/2) November 13, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Data-Intensive Distributed Computing CS 451/651 (Fall 2018) Part 7: Mutable State (2/2) November 13, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Consistency and Replication
 Consistency and Replication 1 D R. Y I N G W U Z H U Reasons for Replication Data are replicated to increase the reliability of a system. Replication for performance Scaling in numbers Scaling in geographical
Consistency and Replication 1 D R. Y I N G W U Z H U Reasons for Replication Data are replicated to increase the reliability of a system. Replication for performance Scaling in numbers Scaling in geographical
Distributed Systems. Day 13: Distributed Transaction. To Be or Not to Be Distributed.. Transactions
 Distributed Systems Day 13: Distributed Transaction To Be or Not to Be Distributed.. Transactions Summary Background on Transactions ACID Semantics Distribute Transactions Terminology: Transaction manager,,
Distributed Systems Day 13: Distributed Transaction To Be or Not to Be Distributed.. Transactions Summary Background on Transactions ACID Semantics Distribute Transactions Terminology: Transaction manager,,
CS Amazon Dynamo
 CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CSE 5306 Distributed Systems. Consistency and Replication
 CSE 5306 Distributed Systems Consistency and Replication 1 Reasons for Replication Data are replicated for the reliability of the system Servers are replicated for performance Scaling in numbers Scaling
CSE 5306 Distributed Systems Consistency and Replication 1 Reasons for Replication Data are replicated for the reliability of the system Servers are replicated for performance Scaling in numbers Scaling
CMU SCS CMU SCS Who: What: When: Where: Why: CMU SCS
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Distributed PostgreSQL with YugaByte DB
 Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Shen PingCAP 2017
 Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
MDCC MULTI DATA CENTER CONSISTENCY. amplab. Tim Kraska, Gene Pang, Michael Franklin, Samuel Madden, Alan Fekete
 MDCC MULTI DATA CENTER CONSISTENCY Tim Kraska, Gene Pang, Michael Franklin, Samuel Madden, Alan Fekete gpang@cs.berkeley.edu amplab MOTIVATION 2 3 June 2, 200: Rackspace power outage of approximately 0
MDCC MULTI DATA CENTER CONSISTENCY Tim Kraska, Gene Pang, Michael Franklin, Samuel Madden, Alan Fekete gpang@cs.berkeley.edu amplab MOTIVATION 2 3 June 2, 200: Rackspace power outage of approximately 0
Consistency and Replication
 Topics to be covered Introduction Consistency and Replication Consistency Models Distribution Protocols Consistency Protocols 1 2 + Performance + Reliability Introduction Introduction Availability: proportion
Topics to be covered Introduction Consistency and Replication Consistency Models Distribution Protocols Consistency Protocols 1 2 + Performance + Reliability Introduction Introduction Availability: proportion
Replication in Distributed Systems
 Replication in Distributed Systems Replication Basics Multiple copies of data kept in different nodes A set of replicas holding copies of a data Nodes can be physically very close or distributed all over
Replication in Distributed Systems Replication Basics Multiple copies of data kept in different nodes A set of replicas holding copies of a data Nodes can be physically very close or distributed all over
Consistency and Replication
 Consistency and Replication Introduction Data-centric consistency Client-centric consistency Distribution protocols Consistency protocols 1 Goal: Reliability Performance Problem: Consistency Replication
Consistency and Replication Introduction Data-centric consistency Client-centric consistency Distribution protocols Consistency protocols 1 Goal: Reliability Performance Problem: Consistency Replication
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (2/2) March 16, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (2/2) March 16, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Distributed KIDS Labs 1
 Distributed Databases @ KIDS Labs 1 Distributed Database System A distributed database system consists of loosely coupled sites that share no physical component Appears to user as a single system Database
Distributed Databases @ KIDS Labs 1 Distributed Database System A distributed database system consists of loosely coupled sites that share no physical component Appears to user as a single system Database
Replication and Consistency. Fall 2010 Jussi Kangasharju
 Replication and Consistency Fall 2010 Jussi Kangasharju Chapter Outline Replication Consistency models Distribution protocols Consistency protocols 2 Data Replication user B user C user A object object
Replication and Consistency Fall 2010 Jussi Kangasharju Chapter Outline Replication Consistency models Distribution protocols Consistency protocols 2 Data Replication user B user C user A object object
Distributed Data Management Replication
 Felix Naumann F-2.03/F-2.04, Campus II Hasso Plattner Institut Distributing Data Motivation Scalability (Elasticity) If data volume, processing, or access exhausts one machine, you might want to spread
Felix Naumann F-2.03/F-2.04, Campus II Hasso Plattner Institut Distributing Data Motivation Scalability (Elasticity) If data volume, processing, or access exhausts one machine, you might want to spread
Chapter 4: Distributed Systems: Replication and Consistency. Fall 2013 Jussi Kangasharju
 Chapter 4: Distributed Systems: Replication and Consistency Fall 2013 Jussi Kangasharju Chapter Outline n Replication n Consistency models n Distribution protocols n Consistency protocols 2 Data Replication
Chapter 4: Distributed Systems: Replication and Consistency Fall 2013 Jussi Kangasharju Chapter Outline n Replication n Consistency models n Distribution protocols n Consistency protocols 2 Data Replication
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Lecture 6 Consistency and Replication
 Lecture 6 Consistency and Replication Prof. Wilson Rivera University of Puerto Rico at Mayaguez Electrical and Computer Engineering Department Outline Data-centric consistency Client-centric consistency
Lecture 6 Consistency and Replication Prof. Wilson Rivera University of Puerto Rico at Mayaguez Electrical and Computer Engineering Department Outline Data-centric consistency Client-centric consistency
CS /29/17. Paul Krzyzanowski 1. Fall 2016: Question 2. Distributed Systems. Fall 2016: Question 2 (cont.) Fall 2016: Question 3
 Fall 2016: Question 3") Fall 2016: Question 2 You have access to a file of class enrollment lists. Each line contains {course_number, student_id}. Distributed Systems 2017 Pre-exam 3 review Selected questions from past exams
Fall 2016: Question 2 You have access to a file of class enrollment lists. Each line contains {course_number, student_id}. Distributed Systems 2017 Pre-exam 3 review Selected questions from past exams
DISTRIBUTED COMPUTER SYSTEMS
 DISTRIBUTED COMPUTER SYSTEMS CONSISTENCY AND REPLICATION CONSISTENCY MODELS Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Consistency Models Background Replication Motivation
DISTRIBUTED COMPUTER SYSTEMS CONSISTENCY AND REPLICATION CONSISTENCY MODELS Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Consistency Models Background Replication Motivation
System Models. 2.1 Introduction 2.2 Architectural Models 2.3 Fundamental Models. Nicola Dragoni Embedded Systems Engineering DTU Informatics
 System Models Nicola Dragoni Embedded Systems Engineering DTU Informatics 2.1 Introduction 2.2 Architectural Models 2.3 Fundamental Models Architectural vs Fundamental Models Systems that are intended
System Models Nicola Dragoni Embedded Systems Engineering DTU Informatics 2.1 Introduction 2.2 Architectural Models 2.3 Fundamental Models Architectural vs Fundamental Models Systems that are intended
A Brief Introduction of TiDB. Dongxu (Edward) Huang CTO, PingCAP
 Huang CTO, PingCAP") A Brief Introduction of TiDB Dongxu (Edward) Huang CTO, PingCAP About me Dongxu (Edward) Huang, Cofounder & CTO of PingCAP PingCAP, based in Beijing, China. Infrastructure software engineer, open source
A Brief Introduction of TiDB Dongxu (Edward) Huang CTO, PingCAP About me Dongxu (Edward) Huang, Cofounder & CTO of PingCAP PingCAP, based in Beijing, China. Infrastructure software engineer, open source
Consistency and Replication. Some slides are from Prof. Jalal Y. Kawash at Univ. of Calgary
 Consistency and Replication Some slides are from Prof. Jalal Y. Kawash at Univ. of Calgary Reasons for Replication Reliability/Availability : Mask failures Mask corrupted data Performance: Scalability
Consistency and Replication Some slides are from Prof. Jalal Y. Kawash at Univ. of Calgary Reasons for Replication Reliability/Availability : Mask failures Mask corrupted data Performance: Scalability
Important Lessons. A Distributed Algorithm (2) Today's Lecture - Replication
 Today's Lecture - Replication") Important Lessons Lamport & vector clocks both give a logical timestamps Total ordering vs. causal ordering Other issues in coordinating node activities Exclusive access to resources/data Choosing a single
Important Lessons Lamport & vector clocks both give a logical timestamps Total ordering vs. causal ordering Other issues in coordinating node activities Exclusive access to resources/data Choosing a single
Distributed Systems. Fall 2017 Exam 3 Review. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Beyond FLP. Acknowledgement for presentation material. Chapter 8: Distributed Systems Principles and Paradigms: Tanenbaum and Van Steen
 Beyond FLP Acknowledgement for presentation material Chapter 8: Distributed Systems Principles and Paradigms: Tanenbaum and Van Steen Paper trail blog: http://the-paper-trail.org/blog/consensus-protocols-paxos/
Beyond FLP Acknowledgement for presentation material Chapter 8: Distributed Systems Principles and Paradigms: Tanenbaum and Van Steen Paper trail blog: http://the-paper-trail.org/blog/consensus-protocols-paxos/
殷亚凤. Consistency and Replication. Distributed Systems [7]
![殷亚凤. Consistency and Replication. Distributed Systems [7]](/thumbs/93/113815133.jpg "殷亚凤. Consistency and Replication. Distributed Systems [7]") Consistency and Replication Distributed Systems [7] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Clock synchronization
Consistency and Replication Distributed Systems [7] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Clock synchronization
Paxos Replicated State Machines as the Basis of a High- Performance Data Store
 Paxos Replicated State Machines as the Basis of a High- Performance Data Store William J. Bolosky, Dexter Bradshaw, Randolph B. Haagens, Norbert P. Kusters and Peng Li March 30, 2011 Q: How to build a
Paxos Replicated State Machines as the Basis of a High- Performance Data Store William J. Bolosky, Dexter Bradshaw, Randolph B. Haagens, Norbert P. Kusters and Peng Li March 30, 2011 Q: How to build a
Distributed Transaction Management 2003
 Distributed Transaction Management 2003 Jyrki Nummenmaa http://www.cs.uta.fi/~dtm jyrki@cs.uta.fi General information We will view this from the course web page. Motivation We will pick up some motivating
Distributed Transaction Management 2003 Jyrki Nummenmaa http://www.cs.uta.fi/~dtm jyrki@cs.uta.fi General information We will view this from the course web page. Motivation We will pick up some motivating
Engineering Goals. Scalability Availability. Transactional behavior Security EAI... CS530 S05
 Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Replication. Consistency models. Replica placement Distribution protocols
 Replication Motivation Consistency models Data/Client-centric consistency models Replica placement Distribution protocols Invalidate versus updates Push versus Pull Cooperation between replicas Client-centric
Replication Motivation Consistency models Data/Client-centric consistency models Replica placement Distribution protocols Invalidate versus updates Push versus Pull Cooperation between replicas Client-centric
Applications of Paxos Algorithm
 Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Documentation Accessibility. Access to Oracle Support
 Oracle NoSQL Database Availability and Failover Release 18.3 E88250-04 October 2018 Documentation Accessibility For information about Oracle's commitment to accessibility, visit the Oracle Accessibility
Oracle NoSQL Database Availability and Failover Release 18.3 E88250-04 October 2018 Documentation Accessibility For information about Oracle's commitment to accessibility, visit the Oracle Accessibility
Today s Papers. Google Chubby. Distributed Consensus. EECS 262a Advanced Topics in Computer Systems Lecture 24. Paxos/Megastore November 24 th, 2014
 EECS 262a Advanced Topics in Computer Systems Lecture 24 Paxos/Megastore November 24 th, 2014 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley Today s Papers
EECS 262a Advanced Topics in Computer Systems Lecture 24 Paxos/Megastore November 24 th, 2014 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley Today s Papers
Synchronization. Chapter 5
 Synchronization Chapter 5 Clock Synchronization In a centralized system time is unambiguous. (each computer has its own clock) In a distributed system achieving agreement on time is not trivial. (it is
Synchronization Chapter 5 Clock Synchronization In a centralized system time is unambiguous. (each computer has its own clock) In a distributed system achieving agreement on time is not trivial. (it is
Consensus and related problems
 Consensus and related problems Today l Consensus l Google s Chubby l Paxos for Chubby Consensus and failures How to make process agree on a value after one or more have proposed what the value should be?
Consensus and related problems Today l Consensus l Google s Chubby l Paxos for Chubby Consensus and failures How to make process agree on a value after one or more have proposed what the value should be?
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/96/128755699.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
Atomicity. Bailu Ding. Oct 18, Bailu Ding Atomicity Oct 18, / 38
 Atomicity Bailu Ding Oct 18, 2012 Bailu Ding Atomicity Oct 18, 2012 1 / 38 Outline 1 Introduction 2 State Machine 3 Sinfonia 4 Dangers of Replication Bailu Ding Atomicity Oct 18, 2012 2 / 38 Introduction
Atomicity Bailu Ding Oct 18, 2012 Bailu Ding Atomicity Oct 18, 2012 1 / 38 Outline 1 Introduction 2 State Machine 3 Sinfonia 4 Dangers of Replication Bailu Ding Atomicity Oct 18, 2012 2 / 38 Introduction
MySQL Group Replication. Bogdan Kecman MySQL Principal Technical Engineer
 MySQL Group Replication Bogdan Kecman MySQL Principal Technical Engineer Bogdan.Kecman@oracle.com 1 Safe Harbor Statement The following is intended to outline our general product direction. It is intended
MySQL Group Replication Bogdan Kecman MySQL Principal Technical Engineer Bogdan.Kecman@oracle.com 1 Safe Harbor Statement The following is intended to outline our general product direction. It is intended
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Advanced Databases Lecture 17- Distributed Databases (continued)
") Advanced Databases Lecture 17- Distributed Databases (continued) Masood Niazi Torshiz Islamic Azad University- Mashhad Branch www.mniazi.ir Alternative Models of Transaction Processing Notion of a single
Advanced Databases Lecture 17- Distributed Databases (continued) Masood Niazi Torshiz Islamic Azad University- Mashhad Branch www.mniazi.ir Alternative Models of Transaction Processing Notion of a single
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Exam 2 Review. October 29, Paul Krzyzanowski 1
 Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
TiDB: NewSQL over HBase.
 TiDB: NewSQL over HBase liuqi@pingcap.com https://github.com/pingcap/tidb weibo: @goroutine Agenda HBase introduction TiDB features Internals of TiDB over HBase Features of HBase Linear and modular scalability.
TiDB: NewSQL over HBase liuqi@pingcap.com https://github.com/pingcap/tidb weibo: @goroutine Agenda HBase introduction TiDB features Internals of TiDB over HBase Features of HBase Linear and modular scalability.
<Insert Picture Here> Oracle NoSQL Database A Distributed Key-Value Store
 Oracle NoSQL Database A Distributed Key-Value Store Charles Lamb The following is intended to outline our general product direction. It is intended for information purposes only,
Oracle NoSQL Database A Distributed Key-Value Store Charles Lamb The following is intended to outline our general product direction. It is intended for information purposes only,
Dynamo: Amazon s Highly Available Key-value Store. ID2210-VT13 Slides by Tallat M. Shafaat
 Dynamo: Amazon s Highly Available Key-value Store ID2210-VT13 Slides by Tallat M. Shafaat Dynamo An infrastructure to host services Reliability and fault-tolerance at massive scale Availability providing
Dynamo: Amazon s Highly Available Key-value Store ID2210-VT13 Slides by Tallat M. Shafaat Dynamo An infrastructure to host services Reliability and fault-tolerance at massive scale Availability providing
Proseminar Distributed Systems Summer Semester Paxos algorithm. Stefan Resmerita
 Proseminar Distributed Systems Summer Semester 2016 Paxos algorithm stefan.resmerita@cs.uni-salzburg.at The Paxos algorithm Family of protocols for reaching consensus among distributed agents Agents may
Proseminar Distributed Systems Summer Semester 2016 Paxos algorithm stefan.resmerita@cs.uni-salzburg.at The Paxos algorithm Family of protocols for reaching consensus among distributed agents Agents may
Final Exam Logistics. CS 133: Databases. Goals for Today. Some References Used. Final exam take-home. Same resources as midterm
 Final Exam Logistics CS 133: Databases Fall 2018 Lec 25 12/06 NoSQL Final exam take-home Available: Friday December 14 th, 4:00pm in Olin Due: Monday December 17 th, 5:15pm Same resources as midterm Except
Final Exam Logistics CS 133: Databases Fall 2018 Lec 25 12/06 NoSQL Final exam take-home Available: Friday December 14 th, 4:00pm in Olin Due: Monday December 17 th, 5:15pm Same resources as midterm Except
10. Replication. CSEP 545 Transaction Processing Philip A. Bernstein Sameh Elnikety. Copyright 2012 Philip A. Bernstein
 10. Replication CSEP 545 Transaction Processing Philip A. Bernstein Sameh Elnikety Copyright 2012 Philip A. Bernstein 1 Outline 1. Introduction 2. Primary-Copy Replication 3. Multi-Master Replication 4.
10. Replication CSEP 545 Transaction Processing Philip A. Bernstein Sameh Elnikety Copyright 2012 Philip A. Bernstein 1 Outline 1. Introduction 2. Primary-Copy Replication 3. Multi-Master Replication 4.
Chapter 11 - Data Replication Middleware
 Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 11 - Data Replication Middleware Motivation Replication: controlled
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 11 - Data Replication Middleware Motivation Replication: controlled
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE. Presented by Byungjin Jun
 DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
Dynamo: Amazon s Highly Available Key-value Store
 Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
SQL, NoSQL, MongoDB. CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden
 Fall 2016 Gregory Kesden") SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
Datacenter replication solution with quasardb
 Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
CS848 Paper Presentation Building a Database on S3. Brantner, Florescu, Graf, Kossmann, Kraska SIGMOD 2008
 CS848 Paper Presentation Building a Database on S3 Brantner, Florescu, Graf, Kossmann, Kraska SIGMOD 2008 Presented by David R. Cheriton School of Computer Science University of Waterloo 15 March 2010
CS848 Paper Presentation Building a Database on S3 Brantner, Florescu, Graf, Kossmann, Kraska SIGMOD 2008 Presented by David R. Cheriton School of Computer Science University of Waterloo 15 March 2010
Distributed Database Management System UNIT-2. Concurrency Control. Transaction ACID rules. MCA 325, Distributed DBMS And Object Oriented Databases
 Distributed Database Management System UNIT-2 Bharati Vidyapeeth s Institute of Computer Applications and Management, New Delhi-63,By Shivendra Goel. U2.1 Concurrency Control Concurrency control is a method
Distributed Database Management System UNIT-2 Bharati Vidyapeeth s Institute of Computer Applications and Management, New Delhi-63,By Shivendra Goel. U2.1 Concurrency Control Concurrency control is a method
Cluster-Level Google How we use Colossus to improve storage efficiency
 Cluster-Level Storage @ Google How we use Colossus to improve storage efficiency Denis Serenyi Senior Staff Software Engineer dserenyi@google.com November 13, 2017 Keynote at the 2nd Joint International
Cluster-Level Storage @ Google How we use Colossus to improve storage efficiency Denis Serenyi Senior Staff Software Engineer dserenyi@google.com November 13, 2017 Keynote at the 2nd Joint International
PushyDB. Jeff Chan, Kenny Lam, Nils Molina, Oliver Song {jeffchan, kennylam, molina,
 PushyDB Jeff Chan, Kenny Lam, Nils Molina, Oliver Song {jeffchan, kennylam, molina, osong}@mit.edu https://github.com/jeffchan/6.824 1. Abstract PushyDB provides a more fully featured database that exposes
PushyDB Jeff Chan, Kenny Lam, Nils Molina, Oliver Song {jeffchan, kennylam, molina, osong}@mit.edu https://github.com/jeffchan/6.824 1. Abstract PushyDB provides a more fully featured database that exposes