More Access to Data Managed by Hadoop
|
|
|
- Leonard Bryan
- 6 years ago
- Views:
Transcription

1 How to Train Your Elephant 2 More Access to Data Managed by Hadoop Clif Kranish 1 Topics Introduction What is Hadoop Apache Hive Arrays, Maps and Structs Apache Drill Apache HBase Apache Phoenix Adapter summary Kerberos 2 1


2 Introduction What is Hadoop? 3 What is Hadoop? Software framework for storing and processing big data in a distributed fashion Based on research at Google Originally developed at Yahoo Open source software distributed by ASF Now a collection of many projects Runs primarily on Linux Also available on Windows Server
3 What is Hadoop? Relational databases or Hadoop Traditional data sources transactional applications Stable well defined schemas Centrally managed by DBA Flat structures Social media, clickstreams, logs, sensor data Evolving flexible schemas Managed within applications Semi structured or nested 5 Traditional Hadoop HDFS and MapReduce Hadoop Distributed File System Inexpensive runs on large clusters of commodity hardware expands by adding nodes Redundant data is replicated on at least three nodes Resilient fault tolerant, keeps running even if one node goes down Flexible store any kind of data, in its original format Unified Storage, Metadata, Security Appears as a single file store Map Reduce Programming paradigm for distributed processing Requires programming, usually Java 6 3
4 Apache Hadoop Architecture Hive Pig Other Zookeeper Coordination 7 Apache Hadoop2 Architecture MR Hive Pig Other Zookeeper Coordination Y A R N Cluster Manager Distributed Processing Hadoop Distributed File System 8 4


5 Hadoop Distributions Big 3 Vendors and the Rest Founded 2008 Commercial license Cloudera Management Suite / Impala Founded Improved reliability, high availability Free version lacks some proprietary features MapR-FS / MapR-DB / MapR Control System / Drill Founded % Apache Open Source Ambari / Yarn / Tez Cloud services Database Vendors Others 9 HDFS is a File System File Formats Faster Throughput With Compression and Columnar File Format Compression C Access Description Text RCFile SequenceFile Avro None, LZO, gzip, bzip2, Snappy None Snappy, Gzip, Deflate, bzip2 None, Snappy, gzip, deflate, bzip2 N Any Simple flat files Can be structured as CSV Y Any Record Columnar File By Facebook for use with Hive N Any Binary key/value pairs ZLIB, Snappy Y Hive Optimized Row Columnar By Hortonworks for use with Hive None, Snappy, gzip, deflate, bzip2 N Any Schema-oriented binary data Snappy, Gzip Y Impala Columnar file format By Cloudera for use with Impala 10 5

6 SQL on Hadoop Apache JDBC Drivers for Hadoop Technology Usage Support IBI Adapter Batch oriented / ETL High latency/throughput Hortonworks All distributions Originated at Facebook Hive Incubating BI and Analytics Runs in memory Low latency/throughput Cloudera MapR, Amazon, ORACLE Hive BI and Anaytics Runs in memory Multiple sources MapR Can be installed anywhere Drill Analytics Machine learning Pivotal Greenplum Incubating 11 Apache Hive Provides data summarization, query, and analysis for Hadoop 12 6
7 What is Hive? Data Warehouse layer on top of Hadoop Adds structure to unstructured data in HDFS Allows use of Hive Query Language to access Provides a JDBC Driver Hive Tables are Data Files stored in HDFS Schema (metadata) stored in an RDBMS 13 Comma Delimited File Create, Load and Select ID,Age,Education,Marital,Gender,Occupation,Income 51397,21,College,Single,Male,Student, ,24,Professional,Single,Male,Student, ,45,College,Single,Male,Student, ,28,Bachelor,Single,Male,Student, CREATE TABLE newcusts ( id STRING, age INT, education STRING, marital STRING, gender STRING, occupation STRING, income DECIMAL(8,2) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE TBLPROPERTIES("skip.header.line.count"="1") ; LOAD DATA LOCAL INPATH 'newcusts.csv' OVERWRITE INTO TABLE newcusts; SELECT * FROM newcusts ; 14 7
 Create")

8 HUE (Hadoop User Experience) Create table, load and query 15 HUE - Query Results 16 8





9 Hive Configure Adapter Create Synonym 17 Synonym and Sample Data newcusts 18 9
10 Hive complex data types Arrays, Structs and Maps 19 Text File with Complex Types Array, Map and Struct John Doe# #Mary Smith,Todd Jones#Federal Taxes=.2,State Taxes=.05,Insurance=.1#1 Michigan Ave.,Chicago,IL,60600 Mary Smith# #Bill King#Federal Taxes=.2,State Taxes=.05,Insurance=.1#100 Ontario St.,Chicago,IL,60601 Todd Jones# ##Federal Taxes=.15,State Taxes=.03,Insurance=.1#200 Chicago Ave.,Oak Park,IL,60700 Bill King# ##Federal Taxes=.15,State Taxes=.03,Insurance=.1#300 Obscure Dr.,Obscuria,IL,60100 CREATE TABLE employees ( name STRING, salary FLOAT, subordinates ARRAY<STRING>, deductions MAP<STRING, FLOAT>, address STRUCT<street:STRING, city:string, state:string, zip:int>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '#' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY '=' LINES TERMINATED BY '\n' STORED AS TEXTFILE ; LOAD DATA LOCAL INPATH 'employees.dat' OVERWRITE INTO TABLE employees; 20 10


11 HUE Query Editor Create, Load and Select 21 Query Results Showing Hive Complex Datatypes Array, Map and Struct Maps and Structs look the same in results from Hive query Maps get names from data Structs gets names from Metadata 22 11






12 Create Synonym 23 Sample Data 24 12



13 Synonym Editor 25 Synonym Editor - Array Transpose Multiple values to columns Hive Array 26 13




14 Synonym Editor - Array New segment added 27 Synonym with Array New segment with new field name 28 14



15 Synonym with Map or Struct Transpose Multiple values to columns Hive Structure 29 Synonym with Hive Map Deductions 30 15

16 Synonym with Hive Struct Address 31 Apache Drill Schema Free SQL For Hadoop, NoSQL and Cloud 32 16
 and Web client 33 Drill Web UI with JSON (self describing) source Automatically generates schema 34")
17 Apache Drill Originally developed at MapR Now open source Storage Plugins for Files, HDFS, Hive, HBase, MongoDB Distributed, columnar execution engine Runs in memory Supplies JDBC Driver Command line (sqlline) and Web client 33 Drill Web UI with JSON (self describing) source Automatically generates schema 34 17



18 File Plug in Comma delimited file select * from `dfs`.`tmp`.`newcusts.csv` 35 File Plug in Comma Delimited File select columns[0] as id, columns[1] 36 18





19 Hive Plugin Uses Hive metadata select * from `hive`.`default`.`newcusts` offset 1 37 Create Synonym for Drill Using Hive Metadata 38 19


20 Synonym newcusts Drill using Hive Plugin 39 HBase When you need random, real-time read/write access 40 20
21 HBase NoSQL Database for Hadoop Based on Google Big Table storage architecture Column oriented Timestamped For very large tables with billions of rows, millions of columns For sparse data each row may use only a few of the columns Provides random read/write access by row key only No joins Essentially Schemaless (row key and column families) Schemas maintained by JDBC driver for SQL Access 41 SQL to NoSQL JDBC Drivers and Adapters Technology Metadata creation Metadata create external table Hive create view Drill create table Phoenix 42 21
22 Hbase Shell Create Table and Column Families $ hbase shell HBase Shell; enter 'help<return>' for list of supported commands. Type "exit<return>" to leave the HBase Shell Version , r58355eb3c88bded74f382d81cdd36174d68ad0fd, Wed Sep :56:38 UTC 2015 hbase(main):001:0> create 'customers', 0 row(s) in seconds => Hbase::Table - customers 'address', 'loyalty', 'personal' hbase(main):002:0> exit Column Families Table Name 43 HBase Shell Put data a cell at a time hbase(main):002:0> put 'customers', ' 10001', 'address:state', 'va' 0 row(s) in seconds hbase(main):003:0> put 'customers', ' 10001', 'loyalty:agg_rev', '197' 0 row(s) in seconds hbase(main):004:0> put 'customers', ' 10001', 'loyalty:membership', 'silver' 0 row(s) in seconds hbase(main):005:0> put 'customers', ' 10001', 'personal:age', '15-20' 0 row(s) in seconds hbase(main):006:0> put 'customers', ' 10001', 'personal:gender', 'FEMALE' 0 row(s) in seconds hbase(main):007:0> put 'customers', ' 10001', 'personal:name', 'Corrine Mecham' 0 row(s) in seconds hbase(main):008:0> put 'customers', ' 10005', 'address:state', 'in' 0 row(s) in seconds hbase(main):009:0> put 'customers', ' 10005', 'loyalty:agg_rev', '230' 0 row(s) in seconds Values Table Name Column Family:Column Qualifier Row Key 44 22
23 Hbase Shell Scan hbase(main):020:0> scan 'customers', {LIMIT=>3} ROW COLUMN+CELL column=address:state, timestamp= , value=va column=loyalty:agg_rev, timestamp= , value= column=loyalty:membership, timestamp= , value=silver column=personal:age, timestamp= , value= column=personal:gender, timestamp= , value=female column=personal:name, timestamp= , value=corrine Mecham column=address:state, timestamp= , value=in column=loyalty:agg_rev, timestamp= , value= column=loyalty:membership, timestamp= , value=silver column=personal:age, timestamp= , value= column=personal:gender, timestamp= , value=male column=personal:name, timestamp= , value=brittany Park column=address:state, timestamp= , value=ca column=loyalty:agg_rev, timestamp= , value= column=loyalty:membership, timestamp= , value=silver column=personal:age, timestamp= , value= column=personal:gender, timestamp= , value=male column=personal:name, timestamp= , value=rose Lokey 3 row(s) in seconds hbase(main):021:0> 45 HBase to Hive create external table map column names create external table customers ( key varchar(5), address_state varchar(4), loyalty_agg_rev varchar(8), loyalty_mebership varchar(8), personal_age varchar(8), personal_gender varchar(8), personal_name varchar(32) ) STORED BY 'org.apache.hadoop.hive.hbase.hbasestoragehandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,address:state,loyalty:agg_rev,loyalty:membership,personal:age,personal:gender, personal:name') TBLPROPERTIES ('hbase.table.name' = 'customers') ; 46 23


24 HUE Hive Query select * from customers 47 HBase / Hive Table Customers Synonym 48 24


25 Hbase / Hive Table Customers Sample Data 49 HBase / Drill select * from `hbase`.`customers` 50 25
 as id, convert_from(`customers`.`address`.`state`,'utf8') as state, convert_from(`customers`.`personal`.`age`,'utf8') as age, convert_from(`customers`.`personal`.`name`,'utf8') as name, convert_from(`customers`.")
26 HBase / Drill select * from `hbase`.`customers` 51 Drill into HBase Must convert each value create view `dfs`.views.customers as select convert_from(`customers`.`row_key`,'utf8') as id, convert_from(`customers`.`address`.`state`,'utf8') as state, convert_from(`customers`.`personal`.`age`,'utf8') as age, convert_from(`customers`.`personal`.`name`,'utf8') as name, convert_from(`customers`.`personal`.`gender`,'utf8') as gender, convert_from(`customers`.`loyalty`.`agg_rev`,'utf8') as agg_rev, convert_from(`customers`.`loyalty`.`membership`,'utf8') as membership from `hbase`.`customers` ; 52 26

27 Drill into HBase using a View select * from dfs.views.customers 53 Drill into HBase using View Synonym 54 27


28 Drill into HBase Sample Data 55 Apache Phoenix for HBase Puts the SQL back in NoSQL 56 28
29 Apache Phoenix SQL for HBase Relational database layer on top of Hbase Real-time engine Low latency queries high performance SQL query compiled into HBase scans Metadata stored in HBase Use CREATE TABLE to create a new table or map to an existing HBase table 57 Phoenix Create Table create table customers ("id" varchar(5) primary key, "address"."state" varchar(2), "personal"."age" varchar(6), "personal"."name" varchar(24), "personal"."gender" varchar(6), "loyalty"."agg_rev" integer, "loyalty"."membership" varchar(6) ) ; 58 29

30 Phoenix sqlline command line tool select * from customers limit Synonym for Phoenix Table Column Family Column Name 60 30




31 Synonym for Phoenix Table Map to Column Name 61 Access to Phoenix Tables Sample Data 62 31

32 Adapters Summary 63 Access to Data Managed By Hadoop WebFOCUS Reporting Server / DataMigrator Server File Adapters Hive Adapter Drill Adapter Phoenix NFS Gateway JDBC Metadata Hive Impala Drill Phoenix Hive Metadata / HCatalog Drill Views Phoenix Metadata RCFile SequenceFile 64 32
![DataMigrator Extended Bulk Load Loads in Parallel Automatically Generates Data Files Creates data file(s) Uses [S]FTP to copy to remote server if](/docs-images/76/74129492/images/33-2.jpg "required Copies to HDFS Automatically Generates Metadata Apache Hive/Impala Metadata Synonym immediately usable by WebFOCUS 65 Kerberos Securing Hadoop")
33 DataMigrator Extended Bulk Load Loads in Parallel Automatically Generates Data Files Creates data file(s) Uses [S]FTP to copy to remote server if required Copies to HDFS Automatically Generates Metadata Apache Hive/Impala Metadata Synonym immediately usable by WebFOCUS 65 Kerberos Securing Hadoop 66 33
34 Kerberos Security Deployment Server Wide Get Kerberos ticket Start Server Add connection for everyone All users use same ticket Per User Start Server with Security on Create profile for each user Add connection for users Each user uses their own ticket 67 Kerberos Server wide security /home/gdc$ kinit gc00001 Password for /home/gdc$ klist Ticket cache: FILE:/tmp/krb5cc_278 Default principal: Valid starting Expires Service principal 02/26/16 16:05:53 02/27/16 02:05:58 renew until 03/04/16 16:05:53 /home/gdc$ beeline Beeline>!connect Connecting to Enter username for...: Enter password for...: Connected to: Apache Hive jdbc:hive2://sandbox:10000/default> select id, current_user() from newcusts limit 1; id _c gc row selected (0.158 seconds) 0: jdbc:hive2://sandbox:10000/default>!quit /home/gdc$ edastart start 02/26/ :51: Starting Workspace Manager in /ibi/srv77/dm 02/26/ :51: Logging startup progress and errors in /ibi/srv77/dm/edaprint.log 68 34



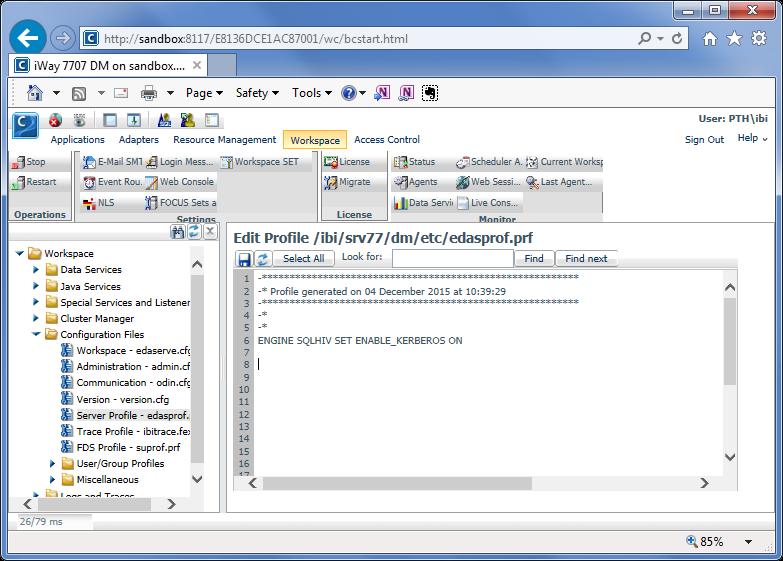
35 Kerberos Server wide security settings Add principal to URL -Djavax.security.auth.useSubjectCredsOnly=false 69 Kerberos Per User Security Settings Security on (PTH, LDAP, DBMS, Custom or OPSYS) Enable Kerberos for Hive Adapter ENGINE SQLHIV SET ENABLE_KERBEROS ON 70 35





36 Kerberos Connect to Hive with credentials from user profiles Register each user to create a profile Add a connection to their profile jdbc:hive2://sandbox:10000/default;principal=hive/sandbox@ibi.com;auth=kerberos;kerberosauthtype=fromsubject 71 Socialize to Win! Daily Prizes Awarded! Tweet and tag #IBSummit during the event! in your #IBSummit pics! Check our Summit Facebook & LinkedIn pages for updates, photos, and announcements 36
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Integration of Apache Hive
 Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 Agenda Overview of Hive and HBase Hive + HBase Features and Improvements Future of Hive and HBase Q&A Page
Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 Agenda Overview of Hive and HBase Hive + HBase Features and Improvements Future of Hive and HBase Q&A Page
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack. Chief Architect RainStor
 Mark Cusack. Chief Architect RainStor") Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
HBase Installation and Configuration
 Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Install and configure Hive Manage data using Hive HBase Installation and Configuration 1. Download HBase
Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Install and configure Hive Manage data using Hive HBase Installation and Configuration 1. Download HBase
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
COSC 6339 Big Data Analytics. NoSQL (II) HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables
 HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables") COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Apache Hive. CMSC 491 Hadoop-Based Distributed Compu<ng Spring 2016 Adam Shook
 Apache Hive CMSC 491 Hadoop-Based Distributed Compu
Apache Hive CMSC 491 Hadoop-Based Distributed Compu
Understanding NoSQL Database Implementations
 Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Aims. Background. This exercise aims to get you to:
 Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
Aims This exercise aims to get you to: Import data into HBase using bulk load Read MapReduce input from HBase and write MapReduce output to HBase Manage data using Hive Manage data using Pig Background
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Hortonworks Data Platform
 Hortonworks Data Platform Teradata Connector User Guide (April 3, 2017) docs.hortonworks.com Hortonworks Data Platform: Teradata Connector User Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Hortonworks Data Platform Teradata Connector User Guide (April 3, 2017) docs.hortonworks.com Hortonworks Data Platform: Teradata Connector User Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Copyright 2015 EMC Corporation. All rights reserved. A long time ago
 1 A long time ago AP REDUCE HDFS IN A BLINK OF AN EYE Crunch Mahout YARN MLib PivotalR Hadoop UI Hue Coordination and workflow management Zookeeper Pig Hive MapReduce Tez Giraph Phoenix SolrCloud Flink
1 A long time ago AP REDUCE HDFS IN A BLINK OF AN EYE Crunch Mahout YARN MLib PivotalR Hadoop UI Hue Coordination and workflow management Zookeeper Pig Hive MapReduce Tez Giraph Phoenix SolrCloud Flink
Apache Drill. Interactive Analysis of Large-Scale Datasets. Tomer Shiran
 Apache Drill Interactive Analysis of Large-Scale Datasets Tomer Shiran Latency Matters Ad-hoc analysis with interactive tools Real-time dashboards Event/trend detection Network intrusions Fraud Failures
Apache Drill Interactive Analysis of Large-Scale Datasets Tomer Shiran Latency Matters Ad-hoc analysis with interactive tools Real-time dashboards Event/trend detection Network intrusions Fraud Failures
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Informatica Cloud Spring Hadoop Connector Guide
 Informatica Cloud Spring 2017 Hadoop Connector Guide Informatica Cloud Hadoop Connector Guide Spring 2017 December 2017 Copyright Informatica LLC 2015, 2017 This software and documentation are provided
Informatica Cloud Spring 2017 Hadoop Connector Guide Informatica Cloud Hadoop Connector Guide Spring 2017 December 2017 Copyright Informatica LLC 2015, 2017 This software and documentation are provided
Integrating with Apache Hadoop
 HPE Vertica Analytic Database Software Version: 7.2.x Document Release Date: 10/10/2017 Legal Notices Warranty The only warranties for Hewlett Packard Enterprise products and services are set forth in
HPE Vertica Analytic Database Software Version: 7.2.x Document Release Date: 10/10/2017 Legal Notices Warranty The only warranties for Hewlett Packard Enterprise products and services are set forth in
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Juxtaposition of Apache Tez and Hadoop MapReduce on Hadoop Cluster - Applying Compression Algorithms
 , pp.289-295 http://dx.doi.org/10.14257/astl.2017.147.40 Juxtaposition of Apache Tez and Hadoop MapReduce on Hadoop Cluster - Applying Compression Algorithms Dr. E. Laxmi Lydia 1 Associate Professor, Department
, pp.289-295 http://dx.doi.org/10.14257/astl.2017.147.40 Juxtaposition of Apache Tez and Hadoop MapReduce on Hadoop Cluster - Applying Compression Algorithms Dr. E. Laxmi Lydia 1 Associate Professor, Department
New Technologies for Data Management
 New Technologies for Data Management Chaitan Baru 2 2 Why new technologies? Big Data Characteristics: Volume, Velocity, Variety Began as a Volume problem E.g. Web crawls 1 spb-100 spb in a single cluster
New Technologies for Data Management Chaitan Baru 2 2 Why new technologies? Big Data Characteristics: Volume, Velocity, Variety Began as a Volume problem E.g. Web crawls 1 spb-100 spb in a single cluster
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
SAS Data Loader 2.4 for Hadoop: User s Guide
 SAS Data Loader 2.4 for Hadoop: User s Guide SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2016. SAS Data Loader 2.4 for Hadoop: User s Guide. Cary,
SAS Data Loader 2.4 for Hadoop: User s Guide SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2016. SAS Data Loader 2.4 for Hadoop: User s Guide. Cary,
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Processing Unstructured Data. Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd.
 Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
IBM Big SQL Partner Application Verification Quick Guide
 IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Data Access 3. Starting Apache Hive. Date of Publish:
 3 Starting Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents Start a Hive shell locally...3 Start Hive as an authorized user... 4 Run a Hive command... 4... 5 Start a Hive shell
3 Starting Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents Start a Hive shell locally...3 Start Hive as an authorized user... 4 Run a Hive command... 4... 5 Start a Hive shell
International Journal of Advance Engineering and Research Development. A study based on Cloudera's distribution of Hadoop technologies for big data"
 Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (
 MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (") HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Enterprise Data Catalog Fixed Limitations ( Update 1)
") Informatica LLC Enterprise Data Catalog 10.2.1 Update 1 Release Notes September 2018 Copyright Informatica LLC 2015, 2018 Contents Enterprise Data Catalog Fixed Limitations (10.2.1 Update 1)... 1 Enterprise
Informatica LLC Enterprise Data Catalog 10.2.1 Update 1 Release Notes September 2018 Copyright Informatica LLC 2015, 2018 Contents Enterprise Data Catalog Fixed Limitations (10.2.1 Update 1)... 1 Enterprise
Cloudera Impala User Guide
 Cloudera Impala User Guide Important Notice (c) 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in
Cloudera Impala User Guide Important Notice (c) 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in
New Approaches to Big Data Processing and Analytics
 New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
HBase... And Lewis Carroll! Twi:er,
 HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
How to Run the Big Data Management Utility Update for 10.1
 How to Run the Big Data Management Utility Update for 10.1 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
How to Run the Big Data Management Utility Update for 10.1 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics
 Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
BIG DATA Standardisation - Data Lake Ingestion
 BIG DATA Standardisation - Data Lake Ingestion Data Warehousing & Big Data Summer School 3 rd Edition Oana Vasile & Razvan Stoian 21.06.2017 Data & Analytics Data Sourcing and Transformation Content Big
BIG DATA Standardisation - Data Lake Ingestion Data Warehousing & Big Data Summer School 3 rd Edition Oana Vasile & Razvan Stoian 21.06.2017 Data & Analytics Data Sourcing and Transformation Content Big
Department of Computer Engineering 1, 2, 3, 4,5
 Components for writing Parquet Format Files Manas Rathi 1, Pratik Jagtap 2, Pranali Jain 3, Anisha Jain 4, Prof. Subhash Tatale 5 1, 2, 3, 4,5 Department of Computer Engineering 1, 2, 3, 4,5 Vishwakarma
Components for writing Parquet Format Files Manas Rathi 1, Pratik Jagtap 2, Pranali Jain 3, Anisha Jain 4, Prof. Subhash Tatale 5 1, 2, 3, 4,5 Department of Computer Engineering 1, 2, 3, 4,5 Vishwakarma
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Modern ETL Tools for Cloud and Big Data. Ken Beutler, Principal Product Manager, Progress Michael Rainey, Technical Advisor, Gluent Inc.
 Modern ETL Tools for Cloud and Big Data Ken Beutler, Principal Product Manager, Progress Michael Rainey, Technical Advisor, Gluent Inc. Agenda Landscape Cloud ETL Tools Big Data ETL Tools Best Practices
Modern ETL Tools for Cloud and Big Data Ken Beutler, Principal Product Manager, Progress Michael Rainey, Technical Advisor, Gluent Inc. Agenda Landscape Cloud ETL Tools Big Data ETL Tools Best Practices
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Sources. P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley
 Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
1z0-449.exam. Number: 1z0-449 Passing Score: 800 Time Limit: 120 min File Version: Oracle. 1z0-449
 1z0-449.exam Number: 1z0-449 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Oracle 1z0-449 Oracle Big Data 2017 Implementation Essentials Version 1.0 Exam A QUESTION 1 The NoSQL KVStore experiences
1z0-449.exam Number: 1z0-449 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Oracle 1z0-449 Oracle Big Data 2017 Implementation Essentials Version 1.0 Exam A QUESTION 1 The NoSQL KVStore experiences
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to