What Dataminers Want
|
|
|
- Derick Alexander
- 6 years ago
- Views:
Transcription

1 New URL: DSC 2001 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria K. Hornik & F. Leisch (eds.) ISSN X What Dataminers Want Martin Theus Abstract Dataming is obviously a buzzword, which does not really describe an academic discipline, but more a field of application of the established disciplines statistics and computer science. Both disciplines do not really cover what dataminers need and lack a certain part. This paper trys to illustrate what the traditional disciplines miss and why new pseudo disciplines like Knowledge Discovery in Databases (KDD) arise. Several aspects of statistical computing like data management and graphical interrogations are investigated in the light of the daily business of a dataminer. Finally the question comes up, whether research in statistical computing focuses on these topics, which might influence commercial software development into the right direction. 1 The Curse of Flat Files Statistics, especially mathematical statistics, grew up about 100 years ago. In those days datasets obviously were very small, because any processing of these data was done manually. The era of mathematical statistics just ended, when statistical computing arose. Still electronic storage was very expensive and dataset sizes were very limited. Since statistics is traditionally a topic owned by math and not by computer since, the primary focus of statistics is on the underlying mathematical theory and less on the computing skills. This is certainly the right balance. Nevertheless when designing and writing statistical software, a profound knowledge of computer science is necessary. So far, statistical software is usually good a reading, respectively import flat ASCII files. Computational statistics unfortunately ignored the presence of data sitting in databases for too long a time. In the VIAG Interkom, P.O. Box: München, martin@theusrus.de
2 Proceedings of DSC early 90s, the number of huge databases grew more and more. This data was mostly collected electronically or entered at distributed locations. Governmental agencies, big retailers or online traders now face huge databases, which were hard to analyze beyond simple summaries. At this point computer scientists took advantage of this lack of database knowledge of statisticians and invented a discipline called KDD (Knowledge Discovery in Databases). But is KDD a concurrent discipline to statistics? Since KDD is about gathering data, sampling data, experimental design, analyzing data, modeling, discovery, visualization, forecasting and classification it lives in the statistics domain. Mainly a lack of apropriate tools brought computer scientists into play. As Daryl Pregibon [4] put it: KDD = Statistics at Scale and Speed. The Datamining Process Although there are several all-in-one datamining tools on the market, the typical Datamining Process (of a statistician) often is performed in four steps as illustrated in figure 1. Define Query SELECT age, wage, gender, product_id, FROM FCT_ALL_CUSTOMERS WHERE contract_length = 24 AND Export Data Convert Data Import Data? Redefine Query * * * * * * * * Analyze Data Computer Science Domain Statistics Domain Figure 1: The usual datamining process 1. Define the SQL query, which gets all(?) the data out of the database we want to analyze. 2. Export the data to a flat file 3. (Optionally convert the flat file to a format the data analysis tool is inclined to import) 4. Import the data into the data analysis tool 5. Analyze the data in your preferred tool.
3 Proceedings of DSC At the end of this process we might find out that we did not get all relevant data out of the database, so we are forced to redo the whole process. This is also true if the underlying data changes in the database and we need to update the results. Is ODBC/JDBC all that bad? Obviously interfaces like ODBC/JDBC are not really fast. Nevertheless, these interfaces are universal and enable to connect to a variety of data sources. Although industrial strength software must use native database interface to transfer huge amounts very quickly, research software can facilitate the more universal interfaces (ODBC/JDBC) in order to start taking advantage of direct database connections. Then ther would no longer be the need to use flat files as a temporary storage/exchange method. Interactivity vs. Databases Exploratory Data Analysis (EDA) is an interactive process by its nature. Thus software supporting EDA must help enabling this interactive process. When working with data inside databases the usual interaction is to wait. To be able to achieve fast response times from databases, one must take a lot of care of setting up indexes and optimize queries carefully. But this is an operation which must take place inside the database and is hard to generalize to arbitrary datasets. Nevertheless, if the size of the datasets gets too big, one cannot handle it outside a database. Many graphical representations of data like e.g. Boxplots, Barcharts and Mosaicplots or even Scatterplots can be drawn with only a summary of the underlying data. These summaries usually can be collected easily by database queries. Another crucial point when directly working on databases is to store additional information like group attributes (selected, color, etc.) inside the database. The back propagation of this information (e.g. color all male customers under 30 with high wages in red) from a graphical front-end into the database is usually a bottleneck. 2 Interactive Statistical Graphics Interactive Statistical Graphics is no new technique. It comes to a renaissance with datamining, since most of the classical mathematical statistical techniques deteriorate when working with too big datasets. Although even graphical displays might be no longer sensible with bigger datasets (the number of outliers to plot in a boxplot grows linearly with the sample size, which obviouly makes no sense) graphical representations of data are often the only means to get an understanding of the data. Interactive Statistical graphics can be characterized as follows:










































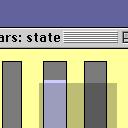








4 Proceedings of DSC PRIM-9 Tukey et al SPLOM Becker et al DataDesk Vellemann 1991 XGobi Buja et al MANET Unwin et al Mondrian Theus Figure 2: A brief history of interactive statistical graphics systems
5 Proceedings of DSC what it is what it not is about graphical user interfaces about direct manipulation of statistical/graphical objects about linking analyses & graphs about exploring data pro Exploratory Data Analysis about interactive computing about manipulation of code about static about presenting results contra mathematical statistics Figure 2 shows a brief history of several interactive statistical graphics systems. Most of them are research software, only Data Desk is commercial software and has industrial strength. All recently build systems proof, that datasets with up to a million observations still can be handled with interactive graphical methods. Unfortunately commercial software like SAS-Insight or SPSS-Clementine (which directly connects to a database) deteriorate above data records and thus are not really usable for datamining purposes. 3 Selections for Drill Down Determine and selecting subsets of data is a basic datamining task. Obviously graphical methods support this task more easily than standard SQL-queries. Evolution of Selection Techniques The way how data are selected in interactive statistical graphics software is maybe the best way to show the evolving research results. 1. The standard way of selecting data is to select data and by doing so replacing any other selection that might have been present. There is no way of refining a selection or selecting over different plots and/or variables. This standard selection technique is implemented e.g. in XGobi [1]. 2. A more advanced way to handle selections is to allow to combine the current selection with a new selection with boolean functions like and, or, Xor, not. This allows the analyst to refine a selection step by step to drill down to a very specific subset of the data. DataDesk [6] implements this selection technique. 3. When dealing with a whole sequence of selections, it is often desirable to change a selection at an earlier stage, without having to redefine all preceding and successive selection steps. By storing the sequence of selections it is possible to make changes to any step in the sequence. Selection Sequences have been first implemented in MANET [5]. 4. Although a selection is always performed on the computer screen in the first place, i.e. in terms of screen coordinates, the data selection must be stored in terms of data coordinates. The approach used by Mondrian [3] keeps a list of any selection associated with a dataset. For each entry in the list the

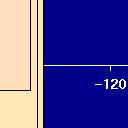
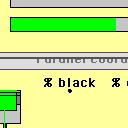
6 Proceedings of DSC selection area in screen coordinates and data coordinates, selection step, the corresponding plot window and the selection mode (i.e. and, or, not etc.) is stored. The currently selected subset of the data can then be determined by processing all elements of the list, no matter which kind of modification to the list the reason for an update of the selection subset was. Selection Rectangles Allowing multiple selections in a single window as well as across different windows makes a visual guide to the performed selections indispensable. Figure 3: Selection Rectangles in Mondrian. Mondrian introduces Selection Rectangles. Figure 3 gives an example of a scatterplot containing two selection rectangles. Selection rectangles indicate the area which was selected. An existing selection rectangle can be used as a brush by simply dragging the selection rectangle The eight handles at the rectangle allow for a flexible resizing of the rectangles or a slicing (i.e. the systematical enlargement or reduction of a selection along one dimension). The selection mode can be maintained via a pop-up menu. The deletion of a selection can be performed via this pop-up, too. The last selection which was performed can be deleted by simply pressing the backspace key. Only the last selection is plotted in black. Selections performed at an earlier stage are plotted in a lighter gray to make them less dominant in the plot. Since selections are stored in terms of the data coordinates they are invariant to any alterations of a plot. Typical scenarios are things like interactive reordering of the axes in parallel coordinate plot, flipping the axes in a scatterplot or zooming a view. These operations automatically update the selection rectangles. The new

7 Proceedings of DSC Figure 4: The Zoom Operation in the window does not affect the selected data, but the Selection Rectangle. screen coordinates of the selection rectangles are calculated from the data coordinates. Figure 4 shows how a selection rectangle reacts on a zoom inside a map. The ability of handling more than one selection in one window is indispensable when dealing with parallel coordinates. 3.1 Translating Graphical Selections into SQL Using a graphical front-end to query databases makes it necessary that graphical queries can be translated into SQL-queries. This task is actually relatively easy, since every selection can directly be translated into restricting where-clauses. The Plot Formal description a) mathematical definition: U = { e i a < x i < b c < y i < d, e i E } v d c b) relational algebra: Π E (σ a < xi < b c < yi < d (E)) c) SQL SELECT weight, MPG FROM CARS_DATA WHERE weight between a and b and MPG between c and d v a b Figure 5: Translating graphical selections into SQL. different selection modes like and, or, xor or not are used to combine these parts in the where-clause. Figure 5 shows the trivial example of a selection in a scatterplot.
8 Proceedings of DSC Translations get more complex when selecting in highdimensional rotation plots. Since the performance of SQL-databases varies very much depending on the actual where-clause supplied, an optimizer might be needed to get a decent response-time from the system. 4 Working with Categorical Data The major proportion of data in databases are categorical. A popular method to deal with categorical data is to condition a dependent, mostly continuous, variable upon the different categories of the influencing variables. But these plots, known as Trellis Displays, can not really deal with categorical data itself, and are very limited when the number of categories is greater than 10 which is very likely in huge databases. To deal with categorical data datamining tool must implement interactive barcharts and mosaic plots. Both plots are not very revealing in a static setting, but are very insightful in an interactive environment providing linked highlighting and interactive reordering of variables and categories. Especially when the number of categories gets high, efficient sorting mechanisms are very useful. Housing Factors Housing Type Satisfaction Influence Contact App. Atr. Terr. Tower low low high low medium low high high low high low low high medium medium low high high low high low low high high medium low high high low high Table 1: The Housing Factors Data: Cross-classification of 1681 tenants

9 Proceedings of DSC The Housing Factors Example The Housing Factors example shall underline why interactivity is a key-feature for a graphical exploration of categorical data. The data is taken from Cox & Snell s [2] investigation. The interaction presented are implemented in Manet and Mondrian. Data on the housing situation of 1681 tenants has been classified according to: Housing Type Apartments, Atrium House, Terraced House, Tower Block Influence on the housing situation low, medium high Contact to other tenants low, high Satisfaction with the housing situation low, medium, high The data is distributed over all 72 cells, i.e. there are no empty cells with no observations. Table 1 lists the complete data set. Figure 6: The Housing Factors Data in the default view.



10 Proceedings of DSC Figure 6 shows the default barcharts and mosaic plots for the four variables. The cases with high satisfaction are selected, to mark the most interesting response. Obviously the order of at least two of the variables make no sense, and the mosaic plot does not reveal any systematic pattern, worthwhile to fit a model for. The necessary steps to make the plots more insightful comprise: Sort the categories of Housing Type according to the relative amount of high satisfaction cases (via the plot option pop-up). The plot has been switched to the Spineplot view, to make the sorting more obvious. Sort Influence and Satisfaction to: low, medium, high (via alt-click and drag): Reorder the variables in the mosaic plot such that the plot is conditioned upon the Housing Type and as a variable with many categories at the deepest stage. The order is then: Housing Type, Contact, Influence. The reordering is done with the four arrow keys. Certainly it is much harder to read the plots without the interactive queries. But in contrast to the default views, the reordered plots now reveal a clear pattern along with some deviations, which can now be investigated more closely using statistical models as well as the suitable meta-information.
11 Proceedings of DSC Summary This paper tried to show what statistical computing still needs to face the challenges of datamining. The ability to handle data located in databases is a very important feature which many statistical software tools still lack. Working on data in databases with interactive tools seems to be much harder as on data in private memory of the application itself. Only if statistical software works on databases as seamless as on flat files, the domain of Knowledge Discovery in Databases (KDD) can be gained back from computer scientists. In the light of massive datasets interactive graphical methods seem to be a good choice to analyze the structure of data, especially of data which are mostly categorical. Relatively simple operations like sorting, joining or splitting categories and reordering of variables in Barcharts and Mosaic Plots are very helpful. Selection techniques well known from interactive statistical graphics can easily be used as a graphical selection front-end for data which is located in databases. In my subjective view What Dataminers Want is a seamless integration of interactive statistical graphics with advanced selection techniques directly working on data in databases. References [1] A. Buja, D. Cook, and D. F. Swayne. Interactive high-dimensional data visualization. Journal of Computational and Graphical Statistics, pages 78 99, [2] D. R. Cox and E. J. Snell. Applied Statistics Principles and Examples. Chapman & Hall, London, [3] Mondrian [4] Daryl Pregibon. 2001: A statistical odyssey. KDD Conference 99, [5] M. Theus, H. Hofmann, and Wilhelm A. Selection sequences interactive analysis of massive data sets. In Proceedings of the 29th Symposium on the Interface: Computing Science and Statistics, [6] Paul F. Velleman. DataDesk Version 6.0 Statistics Guide. Data Description Inc. Ithaka, NY, 1997.
Interactive Graphics for Statistics
 Interactive Graphics for Statistics Principles & Examples martin.theus@math.uni-augsburg.de 2 Graphics in Statistics: Diagnostics vs. Analysis Continuous Data 2 Graphics in Statistics: Diagnostics vs.
Interactive Graphics for Statistics Principles & Examples martin.theus@math.uni-augsburg.de 2 Graphics in Statistics: Diagnostics vs. Analysis Continuous Data 2 Graphics in Statistics: Diagnostics vs.
Projekt 1 Ausarbeitung
 Projekt 1 Ausarbeitung Truong Vinh Phan Support for Interactive Visual Analytics in Various Software Packages Fakultät Technik und Informatik Department Informatik Faculty of Engineering and Computer Science
Projekt 1 Ausarbeitung Truong Vinh Phan Support for Interactive Visual Analytics in Various Software Packages Fakultät Technik und Informatik Department Informatik Faculty of Engineering and Computer Science
Plot and Look! Trust your Data more than your Models
 Titel Author Event, Date Affiliation Plot and Look! Trust your Data more than your Models martin@theusrus.de Telefónica O2 Germany Augsburg University 2 Outline Why use Graphics for Data Analysis? Foundations
Titel Author Event, Date Affiliation Plot and Look! Trust your Data more than your Models martin@theusrus.de Telefónica O2 Germany Augsburg University 2 Outline Why use Graphics for Data Analysis? Foundations
Trellis Displays. Definition. Example. Trellising: Which plot is best? Historical Development. Technical Definition
 Trellis Displays The curse of dimensionality as described by Huber [6] is not restricted to mathematical statistical problems, but can be found in graphicbased data analysis as well. Most plots like histograms
Trellis Displays The curse of dimensionality as described by Huber [6] is not restricted to mathematical statistical problems, but can be found in graphicbased data analysis as well. Most plots like histograms
R Lattice Graphics. Paul Murrell
 New URL: http://www.r-project.org/conferences/dsc-21/ DSC 21 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-21
New URL: http://www.r-project.org/conferences/dsc-21/ DSC 21 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-21
Exploratory model analysis
 Exploratory model analysis with R and GGobi Hadley Wickham 6--8 Introduction Why do we build models? There are two basic reasons: explanation or prediction [Ripley, 4]. Using large ensembles of models
Exploratory model analysis with R and GGobi Hadley Wickham 6--8 Introduction Why do we build models? There are two basic reasons: explanation or prediction [Ripley, 4]. Using large ensembles of models
Examining a Single Variable
 2 Examining a Single Variable This chapter introduces the most important statistical graphics to investigate the structure of a single variable. The plots in this chapter can be best categorized by the
2 Examining a Single Variable This chapter introduces the most important statistical graphics to investigate the structure of a single variable. The plots in this chapter can be best categorized by the
A Virtual Laboratory for Study of Algorithms
 A Virtual Laboratory for Study of Algorithms Thomas E. O'Neil and Scott Kerlin Computer Science Department University of North Dakota Grand Forks, ND 58202-9015 oneil@cs.und.edu Abstract Empirical studies
A Virtual Laboratory for Study of Algorithms Thomas E. O'Neil and Scott Kerlin Computer Science Department University of North Dakota Grand Forks, ND 58202-9015 oneil@cs.und.edu Abstract Empirical studies
SpRay. an R-based visual-analytics platform for large and high-dimensional datasets. J. Heinrich 1 J. Dietzsch 1 D. Bartz 2 K.
 an R-based visual-analytics platform for large and high-dimensional datasets J. Heinrich 1 J. Dietzsch 1 D. Bartz 2 K. Nieselt 1 1 Center for Bioinformatics, University of Tübingen 2 ICCAS/VCM, University
an R-based visual-analytics platform for large and high-dimensional datasets J. Heinrich 1 J. Dietzsch 1 D. Bartz 2 K. Nieselt 1 1 Center for Bioinformatics, University of Tübingen 2 ICCAS/VCM, University
Chapter 1. Introduction
 Chapter 1 Introduction This chapter introduces ViSta, the Visual Statistics system. ViSta is designed for students and teachers in introductory and multivariate statistics, for researchers who have data
Chapter 1 Introduction This chapter introduces ViSta, the Visual Statistics system. ViSta is designed for students and teachers in introductory and multivariate statistics, for researchers who have data
ALTER < 40.5 ALTER < 70.5 GRA < 98.5 FIE < ZZLQ < 4650 ZZLQ < ZZLQ < yes. yes ALTER < 49. yes
 Making Trees Interactive - KLIMT Simon Urbanek su@uni-augsburg.net Antony R. Unwin antony.unwin@math.uni-augsburg.de Department of Computeroriented Statistics and Data Analysis, Augsburg University Interface2001
Making Trees Interactive - KLIMT Simon Urbanek su@uni-augsburg.net Antony R. Unwin antony.unwin@math.uni-augsburg.de Department of Computeroriented Statistics and Data Analysis, Augsburg University Interface2001
JavaStat: A Distributed Statistical Computing Environment
 New URL: http://www.r-project.org/conferences/dsc-2001/ DSC 2001 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-2001
New URL: http://www.r-project.org/conferences/dsc-2001/ DSC 2001 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-2001
Linked Data Views. Introduction. Starting with Scatterplots. By Graham Wills
 Linked Data Views By Graham Wills gwills@research.bell-labs.com Introduction I think of a data view very generally as anything that gives the user a way of looking at data so as to gain insight and understanding.
Linked Data Views By Graham Wills gwills@research.bell-labs.com Introduction I think of a data view very generally as anything that gives the user a way of looking at data so as to gain insight and understanding.
Exploratory Data Analysis EDA
 Exploratory Data Analysis EDA Luc Anselin http://spatial.uchicago.edu 1 from EDA to ESDA dynamic graphics primer on multivariate EDA interpretation and limitations 2 From EDA to ESDA 3 Exploratory Data
Exploratory Data Analysis EDA Luc Anselin http://spatial.uchicago.edu 1 from EDA to ESDA dynamic graphics primer on multivariate EDA interpretation and limitations 2 From EDA to ESDA 3 Exploratory Data
KDD, SEMMA AND CRISP-DM: A PARALLEL OVERVIEW. Ana Azevedo and M.F. Santos
 KDD, SEMMA AND CRISP-DM: A PARALLEL OVERVIEW Ana Azevedo and M.F. Santos ABSTRACT In the last years there has been a huge growth and consolidation of the Data Mining field. Some efforts are being done
KDD, SEMMA AND CRISP-DM: A PARALLEL OVERVIEW Ana Azevedo and M.F. Santos ABSTRACT In the last years there has been a huge growth and consolidation of the Data Mining field. Some efforts are being done
Visualisation of Categorical Data
 Visualisation of Categorical Data Martin Theus Department of Computational Statistics and Data Analysis Institute of Mathematics University of Augsburg 86135 Augsburg GERMANY 1 Summary: Many statistical
Visualisation of Categorical Data Martin Theus Department of Computational Statistics and Data Analysis Institute of Mathematics University of Augsburg 86135 Augsburg GERMANY 1 Summary: Many statistical
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
In the recent past, the World Wide Web has been witnessing an. explosive growth. All the leading web search engines, namely, Google,
 1 1.1 Introduction In the recent past, the World Wide Web has been witnessing an explosive growth. All the leading web search engines, namely, Google, Yahoo, Askjeeves, etc. are vying with each other to
1 1.1 Introduction In the recent past, the World Wide Web has been witnessing an explosive growth. All the leading web search engines, namely, Google, Yahoo, Askjeeves, etc. are vying with each other to
GGobi meets R: an extensible environment for interactive dynamic data visualization
 DSC 2001 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-2001 GGobi meets R: an extensible environment
DSC 2001 Proceedings of the 2nd International Workshop on Distributed Statistical Computing March 15-17, Vienna, Austria http://www.ci.tuwien.ac.at/conferences/dsc-2001 GGobi meets R: an extensible environment
8. MINITAB COMMANDS WEEK-BY-WEEK
 8. MINITAB COMMANDS WEEK-BY-WEEK In this section of the Study Guide, we give brief information about the Minitab commands that are needed to apply the statistical methods in each week s study. They are
8. MINITAB COMMANDS WEEK-BY-WEEK In this section of the Study Guide, we give brief information about the Minitab commands that are needed to apply the statistical methods in each week s study. They are
Biology 345: Biometry Fall 2005 SONOMA STATE UNIVERSITY Lab Exercise 2 Working with data in Excel and exporting to JMP Introduction
 Biology 345: Biometry Fall 2005 SONOMA STATE UNIVERSITY Lab Exercise 2 Working with data in Excel and exporting to JMP Introduction In this exercise, we will learn how to reorganize and reformat a data
Biology 345: Biometry Fall 2005 SONOMA STATE UNIVERSITY Lab Exercise 2 Working with data in Excel and exporting to JMP Introduction In this exercise, we will learn how to reorganize and reformat a data
Data analysis using Microsoft Excel
 Introduction to Statistics Statistics may be defined as the science of collection, organization presentation analysis and interpretation of numerical data from the logical analysis. 1.Collection of Data
Introduction to Statistics Statistics may be defined as the science of collection, organization presentation analysis and interpretation of numerical data from the logical analysis. 1.Collection of Data
CE4031 and CZ4031 Database System Principles
 CE4031 and CZ4031 Database System Principles Academic AY1819 Semester 1 CE/CZ4031 Database System Principles s CE/CZ2001 Algorithms; CZ2007 Introduction to Databases CZ4033 Advanced Data Management (not
CE4031 and CZ4031 Database System Principles Academic AY1819 Semester 1 CE/CZ4031 Database System Principles s CE/CZ2001 Algorithms; CZ2007 Introduction to Databases CZ4033 Advanced Data Management (not
WEB SEARCH, FILTERING, AND TEXT MINING: TECHNOLOGY FOR A NEW ERA OF INFORMATION ACCESS
 1 WEB SEARCH, FILTERING, AND TEXT MINING: TECHNOLOGY FOR A NEW ERA OF INFORMATION ACCESS BRUCE CROFT NSF Center for Intelligent Information Retrieval, Computer Science Department, University of Massachusetts,
1 WEB SEARCH, FILTERING, AND TEXT MINING: TECHNOLOGY FOR A NEW ERA OF INFORMATION ACCESS BRUCE CROFT NSF Center for Intelligent Information Retrieval, Computer Science Department, University of Massachusetts,
Facet: Multiple View Methods
 Facet: Multiple View Methods Large Data Visualization Torsten Möller Overview Combining views Partitioning Coordinating Multiple Side-by-Side Views Encoding Channels Shared Data Shared Navigation Synchronized
Facet: Multiple View Methods Large Data Visualization Torsten Möller Overview Combining views Partitioning Coordinating Multiple Side-by-Side Views Encoding Channels Shared Data Shared Navigation Synchronized
MAXQDA and Chapter 9 Coding Schemes
 MAXQDA and Chapter 9 Coding Schemes Chapter 9 discusses how the structures of coding schemes, alternate groupings are key to moving forward with analysis. The nature and structures of the coding scheme
MAXQDA and Chapter 9 Coding Schemes Chapter 9 discusses how the structures of coding schemes, alternate groupings are key to moving forward with analysis. The nature and structures of the coding scheme
WhatsApp Group Data Analysis with R
 WhatsApp Group Data Analysis with R Sanchita Patil MCA Department Vivekanand Education Society's Institute of Technology Chembur, Mumbai 400074. ABSTRACT The means of communication has changed over time
WhatsApp Group Data Analysis with R Sanchita Patil MCA Department Vivekanand Education Society's Institute of Technology Chembur, Mumbai 400074. ABSTRACT The means of communication has changed over time
1 Topic. Image classification using Knime.
 1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
The first thing we ll need is some numbers. I m going to use the set of times and drug concentration levels in a patient s bloodstream given below.
 Graphing in Excel featuring Excel 2007 1 A spreadsheet can be a powerful tool for analyzing and graphing data, but it works completely differently from the graphing calculator that you re used to. If you
Graphing in Excel featuring Excel 2007 1 A spreadsheet can be a powerful tool for analyzing and graphing data, but it works completely differently from the graphing calculator that you re used to. If you
Data Analyst Nanodegree Syllabus
 Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Data Mining. Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA.
 Data Mining Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA January 13, 2011 Important Note! This presentation was obtained from Dr. Vijay Raghavan
Data Mining Ryan Benton Center for Advanced Computer Studies University of Louisiana at Lafayette Lafayette, La., USA January 13, 2011 Important Note! This presentation was obtained from Dr. Vijay Raghavan
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 01 Databases, Data warehouse Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 01 Databases, Data warehouse Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Warehousing. Ritham Vashisht, Sukhdeep Kaur and Shobti Saini
 Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 3, Number 6 (2013), pp. 669-674 Research India Publications http://www.ripublication.com/aeee.htm Data Warehousing Ritham Vashisht,
Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 3, Number 6 (2013), pp. 669-674 Research India Publications http://www.ripublication.com/aeee.htm Data Warehousing Ritham Vashisht,
3 Graphical Displays of Data
 3 Graphical Displays of Data Reading: SW Chapter 2, Sections 1-6 Summarizing and Displaying Qualitative Data The data below are from a study of thyroid cancer, using NMTR data. The investigators looked
3 Graphical Displays of Data Reading: SW Chapter 2, Sections 1-6 Summarizing and Displaying Qualitative Data The data below are from a study of thyroid cancer, using NMTR data. The investigators looked
Step-by-step data transformation
 Step-by-step data transformation Explanation of what BI4Dynamics does in a process of delivering business intelligence Contents 1. Introduction... 3 Before we start... 3 1 st. STEP: CREATING A STAGING
Step-by-step data transformation Explanation of what BI4Dynamics does in a process of delivering business intelligence Contents 1. Introduction... 3 Before we start... 3 1 st. STEP: CREATING A STAGING
Yunfeng Zhang 1, Huan Wang 2, Jie Zhu 1 1 Computer Science & Engineering Department, North China Institute of Aerospace
 [Type text] [Type text] [Type text] ISSN : 0974-7435 Volume 10 Issue 20 BioTechnology 2014 An Indian Journal FULL PAPER BTAIJ, 10(20), 2014 [12526-12531] Exploration on the data mining system construction
[Type text] [Type text] [Type text] ISSN : 0974-7435 Volume 10 Issue 20 BioTechnology 2014 An Indian Journal FULL PAPER BTAIJ, 10(20), 2014 [12526-12531] Exploration on the data mining system construction
7 Fractions. Number Sense and Numeration Measurement Geometry and Spatial Sense Patterning and Algebra Data Management and Probability
 7 Fractions GRADE 7 FRACTIONS continue to develop proficiency by using fractions in mental strategies and in selecting and justifying use; develop proficiency in adding and subtracting simple fractions;
7 Fractions GRADE 7 FRACTIONS continue to develop proficiency by using fractions in mental strategies and in selecting and justifying use; develop proficiency in adding and subtracting simple fractions;
Flight Systems are Cyber-Physical Systems
 Flight Systems are Cyber-Physical Systems Dr. Christopher Landauer Software Systems Analysis Department The Aerospace Corporation Computer Science Division / Software Engineering Subdivision 08 November
Flight Systems are Cyber-Physical Systems Dr. Christopher Landauer Software Systems Analysis Department The Aerospace Corporation Computer Science Division / Software Engineering Subdivision 08 November
Input part 3: Interaction Techniques
 Input part 3: Interaction Techniques Interaction techniques A method for carrying out a specific interactive task Example: enter a number in a range could use (simulated) slider (simulated) knob type in
Input part 3: Interaction Techniques Interaction techniques A method for carrying out a specific interactive task Example: enter a number in a range could use (simulated) slider (simulated) knob type in
D&B Market Insight Release Notes. July 2016
 D&B Market Insight Release Notes July 2016 Table of Contents User Experience and Performance 3 Mapping.. 4 Visualizations.... 5 User Experience and Performance Speed Improvements Improvements have been
D&B Market Insight Release Notes July 2016 Table of Contents User Experience and Performance 3 Mapping.. 4 Visualizations.... 5 User Experience and Performance Speed Improvements Improvements have been
An Intelligent Clustering Algorithm for High Dimensional and Highly Overlapped Photo-Thermal Infrared Imaging Data
 An Intelligent Clustering Algorithm for High Dimensional and Highly Overlapped Photo-Thermal Infrared Imaging Data Nian Zhang and Lara Thompson Department of Electrical and Computer Engineering, University
An Intelligent Clustering Algorithm for High Dimensional and Highly Overlapped Photo-Thermal Infrared Imaging Data Nian Zhang and Lara Thompson Department of Electrical and Computer Engineering, University
CE4031 and CZ4031 Database System Principles
 CE431 and CZ431 Database System Principles Course CE/CZ431 Course Database System Principles CE/CZ21 Algorithms; CZ27 Introduction to Databases CZ433 Advanced Data Management (not offered currently) Lectures
CE431 and CZ431 Database System Principles Course CE/CZ431 Course Database System Principles CE/CZ21 Algorithms; CZ27 Introduction to Databases CZ433 Advanced Data Management (not offered currently) Lectures
An Evolution of Mathematical Tools
 An Evolution of Mathematical Tools From Conceptualization to Formalization Here's what we do when we build a formal model (or do a computation): 0. Identify a collection of objects/events in the real world.
An Evolution of Mathematical Tools From Conceptualization to Formalization Here's what we do when we build a formal model (or do a computation): 0. Identify a collection of objects/events in the real world.
User Control Mechanisms for Privacy Protection Should Go Hand in Hand with Privacy-Consequence Information: The Case of Smartphone Apps
 User Control Mechanisms for Privacy Protection Should Go Hand in Hand with Privacy-Consequence Information: The Case of Smartphone Apps Position Paper Gökhan Bal, Kai Rannenberg Goethe University Frankfurt
User Control Mechanisms for Privacy Protection Should Go Hand in Hand with Privacy-Consequence Information: The Case of Smartphone Apps Position Paper Gökhan Bal, Kai Rannenberg Goethe University Frankfurt
A Comparative Study of Data Mining Process Models (KDD, CRISP-DM and SEMMA)
") International Journal of Innovation and Scientific Research ISSN 2351-8014 Vol. 12 No. 1 Nov. 2014, pp. 217-222 2014 Innovative Space of Scientific Research Journals http://www.ijisr.issr-journals.org/
International Journal of Innovation and Scientific Research ISSN 2351-8014 Vol. 12 No. 1 Nov. 2014, pp. 217-222 2014 Innovative Space of Scientific Research Journals http://www.ijisr.issr-journals.org/
Data Analyst Nanodegree Syllabus
 Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Leslie Lamport: The Specification Language TLA +
 Leslie Lamport: The Specification Language TLA + This is an addendum to a chapter by Stephan Merz in the book Logics of Specification Languages by Dines Bjørner and Martin C. Henson (Springer, 2008). It
Leslie Lamport: The Specification Language TLA + This is an addendum to a chapter by Stephan Merz in the book Logics of Specification Languages by Dines Bjørner and Martin C. Henson (Springer, 2008). It
Python for Data Analysis. Prof.Sushila Aghav-Palwe Assistant Professor MIT
 Python for Data Analysis Prof.Sushila Aghav-Palwe Assistant Professor MIT Four steps to apply data analytics: 1. Define your Objective What are you trying to achieve? What could the result look like? 2.
Python for Data Analysis Prof.Sushila Aghav-Palwe Assistant Professor MIT Four steps to apply data analytics: 1. Define your Objective What are you trying to achieve? What could the result look like? 2.
Record Linkage using Probabilistic Methods and Data Mining Techniques
 Doi:10.5901/mjss.2017.v8n3p203 Abstract Record Linkage using Probabilistic Methods and Data Mining Techniques Ogerta Elezaj Faculty of Economy, University of Tirana Gloria Tuxhari Faculty of Economy, University
Doi:10.5901/mjss.2017.v8n3p203 Abstract Record Linkage using Probabilistic Methods and Data Mining Techniques Ogerta Elezaj Faculty of Economy, University of Tirana Gloria Tuxhari Faculty of Economy, University
Category Theory in Ontology Research: Concrete Gain from an Abstract Approach
 Category Theory in Ontology Research: Concrete Gain from an Abstract Approach Markus Krötzsch Pascal Hitzler Marc Ehrig York Sure Institute AIFB, University of Karlsruhe, Germany; {mak,hitzler,ehrig,sure}@aifb.uni-karlsruhe.de
Category Theory in Ontology Research: Concrete Gain from an Abstract Approach Markus Krötzsch Pascal Hitzler Marc Ehrig York Sure Institute AIFB, University of Karlsruhe, Germany; {mak,hitzler,ehrig,sure}@aifb.uni-karlsruhe.de
Data Visualisation with SASIINSIGHT Software. Gerhard Held SAS Institute. Summary. Introduction
 Data Visualisation with SASIINSIGHT Software Gerhard Held SAS Institute Summary Recently interactive data analysis packages have become popular. These packages attempt to visualise the structure in multivariate
Data Visualisation with SASIINSIGHT Software Gerhard Held SAS Institute Summary Recently interactive data analysis packages have become popular. These packages attempt to visualise the structure in multivariate
CITS5501 Software Testing and Quality Assurance Formal methods
 CITS5501 Software Testing and Quality Assurance Formal methods Unit coordinator: Arran Stewart May 1, 2018 1 / 49 Sources Pressman, R., Software Engineering: A Practitioner s Approach, McGraw-Hill, 2005
CITS5501 Software Testing and Quality Assurance Formal methods Unit coordinator: Arran Stewart May 1, 2018 1 / 49 Sources Pressman, R., Software Engineering: A Practitioner s Approach, McGraw-Hill, 2005
Chapter 2 Basic Structure of High-Dimensional Spaces
 Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
An Automated System for Data Attribute Anomaly Detection
 Proceedings of Machine Learning Research 77:95 101, 2017 KDD 2017: Workshop on Anomaly Detection in Finance An Automated System for Data Attribute Anomaly Detection David Love Nalin Aggarwal Alexander
Proceedings of Machine Learning Research 77:95 101, 2017 KDD 2017: Workshop on Anomaly Detection in Finance An Automated System for Data Attribute Anomaly Detection David Love Nalin Aggarwal Alexander
Lab #9: ANOVA and TUKEY tests
 Lab #9: ANOVA and TUKEY tests Objectives: 1. Column manipulation in SAS 2. Analysis of variance 3. Tukey test 4. Least Significant Difference test 5. Analysis of variance with PROC GLM 6. Levene test for
Lab #9: ANOVA and TUKEY tests Objectives: 1. Column manipulation in SAS 2. Analysis of variance 3. Tukey test 4. Least Significant Difference test 5. Analysis of variance with PROC GLM 6. Levene test for
A Systems Approach to Dimensional Modeling in Data Marts. Joseph M. Firestone, Ph.D. White Paper No. One. March 12, 1997
 1 of 8 5/24/02 4:43 PM A Systems Approach to Dimensional Modeling in Data Marts By Joseph M. Firestone, Ph.D. White Paper No. One March 12, 1997 OLAP s Purposes And Dimensional Data Modeling Dimensional
1 of 8 5/24/02 4:43 PM A Systems Approach to Dimensional Modeling in Data Marts By Joseph M. Firestone, Ph.D. White Paper No. One March 12, 1997 OLAP s Purposes And Dimensional Data Modeling Dimensional
Big Data Analytics The Data Mining process. Roger Bohn March. 2016
 1 Big Data Analytics The Data Mining process Roger Bohn March. 2016 Office hours HK thursday5 to 6 in the library 3115 If trouble, email or Slack private message. RB Wed. 2 to 3:30 in my office Some material
1 Big Data Analytics The Data Mining process Roger Bohn March. 2016 Office hours HK thursday5 to 6 in the library 3115 If trouble, email or Slack private message. RB Wed. 2 to 3:30 in my office Some material
MetaData for Database Mining
 MetaData for Database Mining John Cleary, Geoffrey Holmes, Sally Jo Cunningham, and Ian H. Witten Department of Computer Science University of Waikato Hamilton, New Zealand. Abstract: At present, a machine
MetaData for Database Mining John Cleary, Geoffrey Holmes, Sally Jo Cunningham, and Ian H. Witten Department of Computer Science University of Waikato Hamilton, New Zealand. Abstract: At present, a machine
Exploring the Structure of Data at Scale. Rudy Agovic, PhD CEO & Chief Data Scientist at Reliancy January 16, 2019
 Exploring the Structure of Data at Scale Rudy Agovic, PhD CEO & Chief Data Scientist at Reliancy January 16, 2019 Outline Why exploration of large datasets matters Challenges in working with large data
Exploring the Structure of Data at Scale Rudy Agovic, PhD CEO & Chief Data Scientist at Reliancy January 16, 2019 Outline Why exploration of large datasets matters Challenges in working with large data
Tips and Guidance for Analyzing Data. Executive Summary
 Tips and Guidance for Analyzing Data Executive Summary This document has information and suggestions about three things: 1) how to quickly do a preliminary analysis of time-series data; 2) key things to
Tips and Guidance for Analyzing Data Executive Summary This document has information and suggestions about three things: 1) how to quickly do a preliminary analysis of time-series data; 2) key things to
CLASSIFICATION FOR SCALING METHODS IN DATA MINING
 CLASSIFICATION FOR SCALING METHODS IN DATA MINING Eric Kyper, College of Business Administration, University of Rhode Island, Kingston, RI 02881 (401) 874-7563, ekyper@mail.uri.edu Lutz Hamel, Department
CLASSIFICATION FOR SCALING METHODS IN DATA MINING Eric Kyper, College of Business Administration, University of Rhode Island, Kingston, RI 02881 (401) 874-7563, ekyper@mail.uri.edu Lutz Hamel, Department
FORMALIZED SOFTWARE DEVELOPMENT IN AN INDUSTRIAL ENVIRONMENT
 FORMALIZED SOFTWARE DEVELOPMENT IN AN INDUSTRIAL ENVIRONMENT Otthein Herzog IBM Germany, Dept. 3100 P.O.Box 80 0880 D-7000 STUTTGART, F. R. G. ABSTRACT tn the IBM Boeblingen Laboratory some software was
FORMALIZED SOFTWARE DEVELOPMENT IN AN INDUSTRIAL ENVIRONMENT Otthein Herzog IBM Germany, Dept. 3100 P.O.Box 80 0880 D-7000 STUTTGART, F. R. G. ABSTRACT tn the IBM Boeblingen Laboratory some software was
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
An Experiment in Visual Clustering Using Star Glyph Displays
 An Experiment in Visual Clustering Using Star Glyph Displays by Hanna Kazhamiaka A Research Paper presented to the University of Waterloo in partial fulfillment of the requirements for the degree of Master
An Experiment in Visual Clustering Using Star Glyph Displays by Hanna Kazhamiaka A Research Paper presented to the University of Waterloo in partial fulfillment of the requirements for the degree of Master
Dashboard 8.0. User Guide
 Dashboard 8.0 User Guide Table of Contents Dashboard User Reference Guide Table of Contents...2 Basic Navigation...3 Content Section...3 Filter Frame...4 Table Types...5 The Drilling Process...6 The Metric
Dashboard 8.0 User Guide Table of Contents Dashboard User Reference Guide Table of Contents...2 Basic Navigation...3 Content Section...3 Filter Frame...4 Table Types...5 The Drilling Process...6 The Metric
Seamless Dynamic Web (and Smart Device!) Reporting with SAS D.J. Penix, Pinnacle Solutions, Indianapolis, IN
 Reporting with SAS D.J. Penix, Pinnacle Solutions, Indianapolis, IN") Paper RIV05 Seamless Dynamic Web (and Smart Device!) Reporting with SAS D.J. Penix, Pinnacle Solutions, Indianapolis, IN ABSTRACT The SAS Business Intelligence platform provides a wide variety of reporting
Paper RIV05 Seamless Dynamic Web (and Smart Device!) Reporting with SAS D.J. Penix, Pinnacle Solutions, Indianapolis, IN ABSTRACT The SAS Business Intelligence platform provides a wide variety of reporting
arxiv:cs/ v1 [cs.dl] 11 Feb 1999
![arxiv:cs/ v1 [cs.dl] 11 Feb 1999](/thumbs/93/114245729.jpg "arxiv:cs/ v1 [cs.dl] 11 Feb 1999") arxiv:cs/9902023v1 [cs.dl] 11 Feb 1999 A New Ranking Principle for Multimedia Information Retrieval Martin Wechsler, Peter Schäuble Eurospider Information Technology AG, Zürich www.eurospider.com Abstract
arxiv:cs/9902023v1 [cs.dl] 11 Feb 1999 A New Ranking Principle for Multimedia Information Retrieval Martin Wechsler, Peter Schäuble Eurospider Information Technology AG, Zürich www.eurospider.com Abstract
JMP 12.1 Quick Reference Windows and Macintosh Keyboard Shortcuts
 Data Table Actions JMP 12.1 Quick Reference and Keyboard s Select the left or right cell. If a blinking cursor is inserted in a cell, move one character left or right through the cell contents. Select
Data Table Actions JMP 12.1 Quick Reference and Keyboard s Select the left or right cell. If a blinking cursor is inserted in a cell, move one character left or right through the cell contents. Select
Formal Methods of Software Design, Eric Hehner, segment 1 page 1 out of 5
 Formal Methods of Software Design, Eric Hehner, segment 1 page 1 out of 5 [talking head] Formal Methods of Software Engineering means the use of mathematics as an aid to writing programs. Before we can
Formal Methods of Software Design, Eric Hehner, segment 1 page 1 out of 5 [talking head] Formal Methods of Software Engineering means the use of mathematics as an aid to writing programs. Before we can
TableLens: A Clear Window for Viewing Multivariate Data Ramana Rao July 11, 2006
 TableLens: A Clear Window for Viewing Multivariate Data Ramana Rao July 11, 2006 Can a few simple operators on a familiar and minimal representation provide much of the power of exploratory data analysis?
TableLens: A Clear Window for Viewing Multivariate Data Ramana Rao July 11, 2006 Can a few simple operators on a familiar and minimal representation provide much of the power of exploratory data analysis?
Establishing Virtual Private Network Bandwidth Requirement at the University of Wisconsin Foundation
 Establishing Virtual Private Network Bandwidth Requirement at the University of Wisconsin Foundation by Joe Madden In conjunction with ECE 39 Introduction to Artificial Neural Networks and Fuzzy Systems
Establishing Virtual Private Network Bandwidth Requirement at the University of Wisconsin Foundation by Joe Madden In conjunction with ECE 39 Introduction to Artificial Neural Networks and Fuzzy Systems
FODAVA Partners Leland Wilkinson (SYSTAT & UIC) Robert Grossman (UIC) Adilson Motter (Northwestern) Anushka Anand, Troy Hernandez (UIC)
 Robert Grossman (UIC) Adilson Motter (Northwestern) Anushka Anand, Troy Hernandez (UIC)") FODAVA Partners Leland Wilkinson (SYSTAT & UIC) Robert Grossman (UIC) Adilson Motter (Northwestern) Anushka Anand, Troy Hernandez (UIC) Visually-Motivated Characterizations of Point Sets Embedded in High-Dimensional
FODAVA Partners Leland Wilkinson (SYSTAT & UIC) Robert Grossman (UIC) Adilson Motter (Northwestern) Anushka Anand, Troy Hernandez (UIC) Visually-Motivated Characterizations of Point Sets Embedded in High-Dimensional
Computational Databases: Inspirations from Statistical Software. Linnea Passing, Technical University of Munich
 Computational Databases: Inspirations from Statistical Software Linnea Passing, linnea.passing@tum.de Technical University of Munich Data Science Meets Databases Data Cleansing Pipelines Fuzzy joins Data
Computational Databases: Inspirations from Statistical Software Linnea Passing, linnea.passing@tum.de Technical University of Munich Data Science Meets Databases Data Cleansing Pipelines Fuzzy joins Data
iplots High Interaction Graphics for R
 New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
Best Practice for Creation and Maintenance of a SAS Infrastructure
 Paper 2501-2015 Best Practice for Creation and Maintenance of a SAS Infrastructure Paul Thomas, ASUP Ltd. ABSTRACT The advantage of using metadata to control and maintain data and access to data on databases,
Paper 2501-2015 Best Practice for Creation and Maintenance of a SAS Infrastructure Paul Thomas, ASUP Ltd. ABSTRACT The advantage of using metadata to control and maintain data and access to data on databases,
Spreadsheet View and Basic Statistics Concepts
 Spreadsheet View and Basic Statistics Concepts GeoGebra 3.2 Workshop Handout 9 Judith and Markus Hohenwarter www.geogebra.org Table of Contents 1. Introduction to GeoGebra s Spreadsheet View 2 2. Record
Spreadsheet View and Basic Statistics Concepts GeoGebra 3.2 Workshop Handout 9 Judith and Markus Hohenwarter www.geogebra.org Table of Contents 1. Introduction to GeoGebra s Spreadsheet View 2 2. Record
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Quality Metrics for Visual Analytics of High-Dimensional Data
 Quality Metrics for Visual Analytics of High-Dimensional Data Daniel A. Keim Data Analysis and Information Visualization Group University of Konstanz, Germany Workshop on Visual Analytics and Information
Quality Metrics for Visual Analytics of High-Dimensional Data Daniel A. Keim Data Analysis and Information Visualization Group University of Konstanz, Germany Workshop on Visual Analytics and Information
LAB 1 INSTRUCTIONS DESCRIBING AND DISPLAYING DATA
 LAB 1 INSTRUCTIONS DESCRIBING AND DISPLAYING DATA This lab will assist you in learning how to summarize and display categorical and quantitative data in StatCrunch. In particular, you will learn how to
LAB 1 INSTRUCTIONS DESCRIBING AND DISPLAYING DATA This lab will assist you in learning how to summarize and display categorical and quantitative data in StatCrunch. In particular, you will learn how to
Vignette: MDS-GUI. Andrew Timm. 1. Introduction. July 24, Multidimensional Scaling
 Vignette: MDS-GUI Andrew Timm Abstract The MDS-GUI is an R based graphical user interface for performing numerous Multidimensional Scaling (MDS) methods. The intention of its design is that it be user
Vignette: MDS-GUI Andrew Timm Abstract The MDS-GUI is an R based graphical user interface for performing numerous Multidimensional Scaling (MDS) methods. The intention of its design is that it be user
DATA MINING AND WAREHOUSING
 DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
3 Graphical Displays of Data
 3 Graphical Displays of Data Reading: SW Chapter 2, Sections 1-6 Summarizing and Displaying Qualitative Data The data below are from a study of thyroid cancer, using NMTR data. The investigators looked
3 Graphical Displays of Data Reading: SW Chapter 2, Sections 1-6 Summarizing and Displaying Qualitative Data The data below are from a study of thyroid cancer, using NMTR data. The investigators looked
Input: Interaction Techniques
 Input: Interaction Techniques Administration Questions about homework? 2 Interaction techniques A method for carrying out a specific interactive task Example: enter a number in a range could use (simulated)
Input: Interaction Techniques Administration Questions about homework? 2 Interaction techniques A method for carrying out a specific interactive task Example: enter a number in a range could use (simulated)
Quality Indicators for Automotive Test Case Specifications
 Quality Indicators for Automotive Test Case Specifications Katharina Juhnke Daimler AG Group Research & MBC Development Email: katharina.juhnke@daimler.com Matthias Tichy Ulm University Institute of Software
Quality Indicators for Automotive Test Case Specifications Katharina Juhnke Daimler AG Group Research & MBC Development Email: katharina.juhnke@daimler.com Matthias Tichy Ulm University Institute of Software
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS
 FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS") AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
THE SWALLOW-TAIL PLOT: A SIMPLE GRAPH FOR VISUALIZING BIVARIATE DATA.
 STATISTICA, anno LXXIV, n. 2, 2014 THE SWALLOW-TAIL PLOT: A SIMPLE GRAPH FOR VISUALIZING BIVARIATE DATA. Maria Adele Milioli Dipartimento di Economia, Università di Parma, Parma, Italia Sergio Zani Dipartimento
STATISTICA, anno LXXIV, n. 2, 2014 THE SWALLOW-TAIL PLOT: A SIMPLE GRAPH FOR VISUALIZING BIVARIATE DATA. Maria Adele Milioli Dipartimento di Economia, Università di Parma, Parma, Italia Sergio Zani Dipartimento
Improving the ROI of Your Data Warehouse
 Improving the ROI of Your Data Warehouse Many organizations are struggling with a straightforward but challenging problem: their data warehouse can t affordably house all of their data and simultaneously
Improving the ROI of Your Data Warehouse Many organizations are struggling with a straightforward but challenging problem: their data warehouse can t affordably house all of their data and simultaneously
Clustering of Data with Mixed Attributes based on Unified Similarity Metric
 Clustering of Data with Mixed Attributes based on Unified Similarity Metric M.Soundaryadevi 1, Dr.L.S.Jayashree 2 Dept of CSE, RVS College of Engineering and Technology, Coimbatore, Tamilnadu, India 1
Clustering of Data with Mixed Attributes based on Unified Similarity Metric M.Soundaryadevi 1, Dr.L.S.Jayashree 2 Dept of CSE, RVS College of Engineering and Technology, Coimbatore, Tamilnadu, India 1
DSS based on Data Warehouse
 DSS based on Data Warehouse C_13 / 19.01.2017 Decision support system is a complex system engineering. At the same time, research DW composition, DW structure and DSS Architecture based on DW, puts forward
DSS based on Data Warehouse C_13 / 19.01.2017 Decision support system is a complex system engineering. At the same time, research DW composition, DW structure and DSS Architecture based on DW, puts forward
Eloqua Insight Intro Analyzer User Guide
 Eloqua Insight Intro Analyzer User Guide Table of Contents About the Course Materials... 4 Introduction to Eloqua Insight for Analyzer Users... 13 Introduction to Eloqua Insight... 13 Eloqua Insight Home
Eloqua Insight Intro Analyzer User Guide Table of Contents About the Course Materials... 4 Introduction to Eloqua Insight for Analyzer Users... 13 Introduction to Eloqua Insight... 13 Eloqua Insight Home
Cornerstone 7. DoE, Six Sigma, and EDA
 Cornerstone 7 DoE, Six Sigma, and EDA Statistics made for engineers Cornerstone data analysis software allows efficient work to design experiments and explore data, analyze dependencies, and find answers
Cornerstone 7 DoE, Six Sigma, and EDA Statistics made for engineers Cornerstone data analysis software allows efficient work to design experiments and explore data, analyze dependencies, and find answers
Introduction to Exploratory Data Analysis
 Introduction to Exploratory Data Analysis Ref: NIST/SEMATECH e-handbook of Statistical Methods http://www.itl.nist.gov/div898/handbook/index.htm The original work in Exploratory Data Analysis (EDA) was
Introduction to Exploratory Data Analysis Ref: NIST/SEMATECH e-handbook of Statistical Methods http://www.itl.nist.gov/div898/handbook/index.htm The original work in Exploratory Data Analysis (EDA) was
Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques
 24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
Depth First Search A B C D E F G A B C 5 D E F 3 2 G 2 3
 Depth First Search A B C D E F G A 4 3 2 B 4 5 4 3 C 5 D 3 4 2 E 2 2 3 F 3 2 G 2 3 Minimum (Weight) Spanning Trees Let G be a graph with weights on the edges. We define the weight of any subgraph of G
Depth First Search A B C D E F G A 4 3 2 B 4 5 4 3 C 5 D 3 4 2 E 2 2 3 F 3 2 G 2 3 Minimum (Weight) Spanning Trees Let G be a graph with weights on the edges. We define the weight of any subgraph of G
An introduction to ggplot: An implementation of the grammar of graphics in R
 An introduction to ggplot: An implementation of the grammar of graphics in R Hadley Wickham 00-0-7 1 Introduction Currently, R has two major systems for plotting data, base graphics and lattice graphics
An introduction to ggplot: An implementation of the grammar of graphics in R Hadley Wickham 00-0-7 1 Introduction Currently, R has two major systems for plotting data, base graphics and lattice graphics
Statistical Good Practice Guidelines. 1. Introduction. Contents. SSC home Using Excel for Statistics - Tips and Warnings
 Statistical Good Practice Guidelines SSC home Using Excel for Statistics - Tips and Warnings On-line version 2 - March 2001 This is one in a series of guides for research and support staff involved in
Statistical Good Practice Guidelines SSC home Using Excel for Statistics - Tips and Warnings On-line version 2 - March 2001 This is one in a series of guides for research and support staff involved in
Lecture 34 SDLC Phases and UML Diagrams
 That Object-Oriented Analysis and Design Prof. Partha Pratim Das Department of Computer Science and Engineering Indian Institute of Technology-Kharagpur Lecture 34 SDLC Phases and UML Diagrams Welcome
That Object-Oriented Analysis and Design Prof. Partha Pratim Das Department of Computer Science and Engineering Indian Institute of Technology-Kharagpur Lecture 34 SDLC Phases and UML Diagrams Welcome
Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016
 LSS: ITNPBD4, 1 November 2016") Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016 Overview Overview (short: we covered most of this in the tutorial) Why infographics and visualisation What s the
Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016 Overview Overview (short: we covered most of this in the tutorial) Why infographics and visualisation What s the
PROCLARITY. Page 1 of 10. Version 1.0 Author. Imogen Dainty Department. IT Date Created 10/06/2016 Review Date 10/06/2018
 PROCLARITY Version 1.0 Author Imogen Dainty Department IT Date Created 10/06/2016 Review Date 10/06/2018 This guide is designed to give you step by step guidance on the core functions of ProClarity Additional
PROCLARITY Version 1.0 Author Imogen Dainty Department IT Date Created 10/06/2016 Review Date 10/06/2018 This guide is designed to give you step by step guidance on the core functions of ProClarity Additional
Data Mining. CS57300 Purdue University. Bruno Ribeiro. February 1st, 2018
 Data Mining CS57300 Purdue University Bruno Ribeiro February 1st, 2018 1 Exploratory Data Analysis & Feature Construction How to explore a dataset Understanding the variables (values, ranges, and empirical
Data Mining CS57300 Purdue University Bruno Ribeiro February 1st, 2018 1 Exploratory Data Analysis & Feature Construction How to explore a dataset Understanding the variables (values, ranges, and empirical