sqoop Easy, parallel database import/export Aaron Kimball Cloudera Inc. June 8, 2010
|
|
|
- Lilian Logan
- 5 years ago
- Views:
Transcription
1
2 sqoop Easy, parallel database import/export Aaron Kimball Cloudera Inc. June 8, 2010

3 Your database Holds a lot of really valuable data! Many structured tables of several hundred GB Provides fast access for OLTP applications Update / delete records Add individual records Complex transactions But
4 You can only go so far Can t store very large datasets (1 TB+) Poor support for complex datatypes / large objects Schema evolution is hard Analytic queries better suited to a batch-oriented system
5 Hadoop and MapReduce A batch processing system for very large datasets Handles complex / unstructured data gracefully Can perform deep queries and large ETL tasks in parallel Automatic fault tolerance but poor at interactive access
6 Sqoop is a suite of tools that connect Hadoop and database systems. Import tables from databases into HDFS for deep analysis Replicate database schemas in Hive s metastore Export MapReduce results back to a database for presentation to end-users
7 In this talk How Sqoop works Working with imported data Parallelism and performance Sqoop 1.0 Release

8 The problem Structured data in traditional databases cannot be easily combined with complex data stored in HDFS Where s the bridge?
9 Sqoop = SQL-to-Hadoop Easy import of data from many databases to HDFS Generates code for use in MapReduce applications Integrates with Hive mysql sqoop! Hadoop Custom MapReduce programs reinterpret data...via auto-generated datatype definitions
10 Example data pipeline
11 Key features of Sqoop JDBC-based implementation Works with many popular database vendors Auto-generation of tedious user-side code Write MapReduce applications to work with your data, faster Integration with Hive Allows you to stay in a SQL-based environment Extensible backend Database-specific code paths for better performance
12 Example input mysql> use corp; Database changed mysql> describe employees; Field Type Null Key Default Extra id int(11) NO PRI NULL auto_increment firstname varchar(32) YES NULL lastname varchar(32) YES NULL jobtitle varchar(64) YES NULL start_date date YES NULL dept_id int(11) YES NULL
13 Loading into HDFS $ sqoop import \ --connect jdbc:mysql://db.foo.com/corp \ --table employees Imports employees table into HDFS directory Data imported as text or SequenceFiles Optionally compress and split data during import Generates employees.java for your use
14 Example output $ hadoop fs cat employees/part ,Aaron,Kimball,engineer, ,3 1,John,Doe,manager, ,6 Files can be used as input to MapReduce processing
15 Auto-generated class public class employees { public Integer get_id(); public String get_firstname(); public String get_lastname(); public String get_jobtitle(); public java.sql.date get_start_date(); public Integer get_dept_id(); // parse() methods that understand text // and serialization methods for Hadoop }

16 Hive integration Imports table definition into Hive after data is imported to HDFS
17 Export back to a database mysql> CREATE TABLE ads_results ( id INT NOT NULL PRIMARY KEY, page VARCHAR(256), score DOUBLE); $ sqoop export \ --connect jdbc:mysql://db.foo.com/corp \ --table ads_results --export-dir results Exports results dir into ads_results table
18 Additional options Multiple data representations supported TextFile ubiquitous; easy import into Hive SequenceFile for binary data; better compression support, higher performance Supports local and remote Hadoop clusters, databases Can select a subset of columns, specify a WHERE clause Controls for delimiters and quote characters: --fields-terminated-by, --lines-terminated-by, --optionally-enclosed-by, etc. Also supports delimiter conversion (--input-fields-terminated-by, etc.)
19 Under the hood JDBC Allows Java applications to submit SQL queries to databases Provides metadata about databases (column names, types, etc.) Hadoop Allows input from arbitrary sources via different InputFormats Provides multiple JDBC-based InputFormats to read from databases Can write to arbitrary sinks via OutputFormats Sqoop includes a high-performance database export OutputFormat
20 InputFormat woes DBInputFormat allows database records to be used as mapper inputs The trouble with using DBInputFormat directly is: Connecting an entire Hadoop cluster to a database is a performance nightmare Databases have lower read bandwidth than HDFS; for repeated analyses, much better to make a copy in HDFS first Users must write a class that describes a record from each table they want to import or work with (a DBWritable )
21 DBWritable example 1. class MyRecord implements Writable, DBWritable { 2. long msg_id; 3. String msg; 4. public void readfields(resultset resultset) 5. throws SQLException { 6. this.msg_id = resultset.getlong(1); 7. this.msg = resultset.getstring(2); 8. } 9. public void readfields(datainput in) throws 10. IOException { 11. this.msg_id = in.readlong(); 12. this.msg = in.readutf(); 13. } 14. }
22 DBWritable example 1. class MyRecord implements Writable, DBWritable { 2. long msg_id; 3. String msg; 4. public void readfields(resultset resultset) 5. throws SQLException { 6. this.msg_id = resultset.getlong(1); 7. this.msg = resultset.getstring(2); 8. } 9. public void readfields(datainput in) throws 10. IOException { 11. this.msg_id = in.readlong(); 12. this.msg = in.readutf(); 13. } 14. }
23 A direct type mapping JDBC Type Java Type CHAR String VARCHAR String LONGVARCHAR String NUMERIC java.math.bigdecimal DECIMAL java.math.bigdecimal BIT boolean TINYINT byte SMALLINT short INTEGER int BIGINT long REAL float FLOAT double DOUBLE double BINARY byte[] VARBINARY byte[] LONGVARBINARY byte[] DATE java.sql.date TIME java.sql.time TIMESTAMP java.sql.timestamp
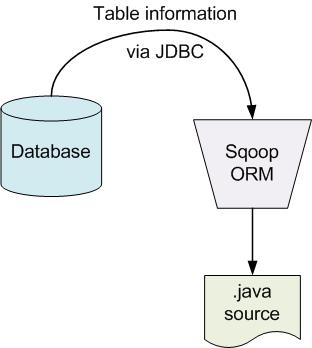
24 Class auto-generation
25 Working with Sqoop Basic workflow: Import initial table with Sqoop Use auto-generated table class in MapReduce analyses Or write Hive queries over imported tables Perform periodic re-imports to ingest new data Use Sqoop to export results back to databases for online access Table classes can parse records from delimited files in HDFS
26 Processing records in MapReduce 1. void map(longwritable k, Text v, Context c) { 2. MyRecord r = new MyRecord(); 3. r.parse(v); // auto-generated text parser 4. process(r.get_msg()); // your logic here }
27 Import parallelism Sqoop uses indexed columns to divide a table into ranges Based on min/max values of the primary key Allows databases to use index range scans Several worker tasks import a subset of the table each MapReduce is used to manage worker tasks Provides fault tolerance Workers write to separate HDFS nodes; wide write bandwidth

28 Parallel exports Results from MapReduce processing stored in delimited text files Sqoop can parse these files, and insert the results in a database table
29 Direct-mode imports and exports MySQL provides mysqldump for high-performance table output Sqoop special-cases jdbc:mysql:// for faster loading With MapReduce, think distributed mk-parallel-dump Similar mechanism used for PostgreSQL Avoids JDBC overhead On the other side mysqlimport provides really fast Sqoop exports Writers stream data into mysqlimport via named FIFOs
30 Recent Developments April 2010: Sqoop moves to github May 2010: Preparing for 1.0 release Higher-performance pipelined export process Improved support for storage of large data (CLOBs, BLOBs) Refactored API, improved documentation Better platform compatibility: Will work with to-be-released Apache Hadoop 0.21 Will work with Cloudera s Distribution for Hadoop 3 June 2010: Planned release (in time for Hadoop Summit) Plenty of bugs to fix and features to add see me if you want to help!
31 Conclusions Most database import/export tasks are turning the crank Sqoop can automate a lot of this Allows more efficient use of existing data sources in concert with new, complex data Available as part of Cloudera s Distribution for Hadoop The pitch: The code: github.com/cloudera/sqoop aaron@cloudera.com
32 (c) 2008 Cloudera, Inc. or its licensors. "Cloudera" is a registered trademark of Cloudera, Inc.. All rights reserved. 1.0
sqoop Automatic database import Aaron Kimball Cloudera Inc. June 18, 2009
 sqoop Automatic database import Aaron Kimball Cloudera Inc. June 18, 2009 The problem Structured data already captured in databases should be used with unstructured data in Hadoop Tedious glue code necessary
sqoop Automatic database import Aaron Kimball Cloudera Inc. June 18, 2009 The problem Structured data already captured in databases should be used with unstructured data in Hadoop Tedious glue code necessary
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Data Access 3. Migrating data. Date of Publish:
 3 Migrating data Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents Data migration to Apache Hive... 3 Moving data from databases to Apache Hive...3 Create a Sqoop import command...4 Import
3 Migrating data Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents Data migration to Apache Hive... 3 Moving data from databases to Apache Hive...3 Create a Sqoop import command...4 Import
Table of Contents. 7. sqoop-import Purpose 7.2. Syntax
 Sqoop User Guide (v1.4.2) Sqoop User Guide (v1.4.2) Table of Contents 1. Introduction 2. Supported Releases 3. Sqoop Releases 4. Prerequisites 5. Basic Usage 6. Sqoop Tools 6.1. Using Command Aliases 6.2.
Sqoop User Guide (v1.4.2) Sqoop User Guide (v1.4.2) Table of Contents 1. Introduction 2. Supported Releases 3. Sqoop Releases 4. Prerequisites 5. Basic Usage 6. Sqoop Tools 6.1. Using Command Aliases 6.2.
Hortonworks Data Platform
 Hortonworks Data Platform Teradata Connector User Guide (April 3, 2017) docs.hortonworks.com Hortonworks Data Platform: Teradata Connector User Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Hortonworks Data Platform Teradata Connector User Guide (April 3, 2017) docs.hortonworks.com Hortonworks Data Platform: Teradata Connector User Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Using IBM-Informix datatypes with IDS 10 and web application server Keshava Murthy, IBM Informix Development
 IBM GLOBAL SERVICES Using IBM-Informix datatypes with IDS 10 and web application server Keshava Murthy, IBM Informix Development Sept. 12-16, 2005 Orlando, FL 1 Agenda JDBC Datatypes IDS 10 Datatypes Java
IBM GLOBAL SERVICES Using IBM-Informix datatypes with IDS 10 and web application server Keshava Murthy, IBM Informix Development Sept. 12-16, 2005 Orlando, FL 1 Agenda JDBC Datatypes IDS 10 Datatypes Java
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Database Access with JDBC. Dr. Jens Bennedsen, Aarhus University, School of Engineering Aarhus, Denmark
 Database Access with JDBC Dr. Jens Bennedsen, Aarhus University, School of Engineering Aarhus, Denmark jbb@ase.au.dk Overview Overview of JDBC technology JDBC drivers Seven basic steps in using JDBC Retrieving
Database Access with JDBC Dr. Jens Bennedsen, Aarhus University, School of Engineering Aarhus, Denmark jbb@ase.au.dk Overview Overview of JDBC technology JDBC drivers Seven basic steps in using JDBC Retrieving
Apache Hive. CMSC 491 Hadoop-Based Distributed Compu<ng Spring 2016 Adam Shook
 Apache Hive CMSC 491 Hadoop-Based Distributed Compu
Apache Hive CMSC 491 Hadoop-Based Distributed Compu
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
Introduction to SQL on GRAHAM ED ARMSTRONG SHARCNET AUGUST 2018
 Introduction to SQL on GRAHAM ED ARMSTRONG SHARCNET AUGUST 2018 Background Information 2 Background Information What is a (Relational) Database 3 Dynamic collection of information. Organized into tables,
Introduction to SQL on GRAHAM ED ARMSTRONG SHARCNET AUGUST 2018 Background Information 2 Background Information What is a (Relational) Database 3 Dynamic collection of information. Organized into tables,
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
This is a brief tutorial that explains how to make use of Sqoop in Hadoop ecosystem.
 About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Complex stories about Sqooping PostgreSQL data
 Presentation slide for Sqoop User Meetup (Strata + Hadoop World NYC 2013) Complex stories about Sqooping PostgreSQL data 10/28/2013 NTT DATA Corporation Masatake Iwasaki Introduction 2 About Me Masatake
Presentation slide for Sqoop User Meetup (Strata + Hadoop World NYC 2013) Complex stories about Sqooping PostgreSQL data 10/28/2013 NTT DATA Corporation Masatake Iwasaki Introduction 2 About Me Masatake
Powered by Teradata Connector for Hadoop
 Powered by Teradata Connector for Hadoop docs.hortonworks.com -D -Dteradata.db.input.file.format=rcfile !and!teradata!database!14.10 -D -D -D -D com.teradata.db.input.num.mappers --num-mappers -D com.teradata.db.input.job.type
Powered by Teradata Connector for Hadoop docs.hortonworks.com -D -Dteradata.db.input.file.format=rcfile !and!teradata!database!14.10 -D -D -D -D com.teradata.db.input.num.mappers --num-mappers -D com.teradata.db.input.job.type
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Sqoop In Action. Lecturer:Alex Wang QQ: QQ Communication Group:
 Sqoop In Action Lecturer:Alex Wang QQ:532500648 QQ Communication Group:286081824 Aganda Setup the sqoop environment Import data Incremental import Free-Form Query Import Export data Sqoop and Hive Apache
Sqoop In Action Lecturer:Alex Wang QQ:532500648 QQ Communication Group:286081824 Aganda Setup the sqoop environment Import data Incremental import Free-Form Query Import Export data Sqoop and Hive Apache
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Data Access 3. Managing Apache Hive. Date of Publish:
 3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
Big Data XML Parsing in Pentaho Data Integration (PDI)
") Big Data XML Parsing in Pentaho Data Integration (PDI) Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Terms You Should Know... 1 Selecting
Big Data XML Parsing in Pentaho Data Integration (PDI) Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Terms You Should Know... 1 Selecting
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
COSC 6339 Big Data Analytics. Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout. Edgar Gabriel Fall Pig
 COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
DOWNLOAD PDF MICROSOFT SQL SERVER HADOOP CONNECTOR USER GUIDE
 Chapter 1 : Apache Hadoop Hive Cloud Integration for ODBC, JDBC, Java SE and OData Installation Instructions for the Microsoft SQL Server Connector for Apache Hadoop (SQL Server-Hadoop Connector) Note:By
Chapter 1 : Apache Hadoop Hive Cloud Integration for ODBC, JDBC, Java SE and OData Installation Instructions for the Microsoft SQL Server Connector for Apache Hadoop (SQL Server-Hadoop Connector) Note:By
Lily 2.4 What s New Product Release Notes
 Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
Hortonworks HDPCD. Hortonworks Data Platform Certified Developer. Download Full Version :
 Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Informatica PowerExchange for Microsoft Azure Blob Storage 10.2 HotFix 1. User Guide
 Informatica PowerExchange for Microsoft Azure Blob Storage 10.2 HotFix 1 User Guide Informatica PowerExchange for Microsoft Azure Blob Storage User Guide 10.2 HotFix 1 July 2018 Copyright Informatica LLC
Informatica PowerExchange for Microsoft Azure Blob Storage 10.2 HotFix 1 User Guide Informatica PowerExchange for Microsoft Azure Blob Storage User Guide 10.2 HotFix 1 July 2018 Copyright Informatica LLC
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication
 MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication Continuent Quick Introduction History Products 2004 2009 2014
MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication Continuent Quick Introduction History Products 2004 2009 2014
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench
 CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Overview. Database Application Development. SQL in Application Code. SQL in Application Code (cont.)
") Overview Database Application Development Chapter 6 Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures Database Management Systems 3ed
Overview Database Application Development Chapter 6 Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures Database Management Systems 3ed
Database Application Development
 Database Application Development Chapter 6 Database Management Systems 3ed 1 Overview Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures
Database Application Development Chapter 6 Database Management Systems 3ed 1 Overview Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures
Database Application Development
 Database Application Development Chapter 6 Database Management Systems 3ed 1 Overview Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures
Database Application Development Chapter 6 Database Management Systems 3ed 1 Overview Concepts covered in this lecture: SQL in application code Embedded SQL Cursors Dynamic SQL JDBC SQLJ Stored procedures
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Hadoop File Formats and Data Ingestion. Prasanth Kothuri, CERN
 Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 4/7/2016 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 4/7/2016 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
iway iway Big Data Integrator New Features Bulletin and Release Notes Version DN
 iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.1 DN3502232.0517 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,
iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.1 DN3502232.0517 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,
ORC Files. Owen O June Page 1. Hortonworks Inc. 2012
 ORC Files Owen O Malley owen@hortonworks.com @owen_omalley owen@hortonworks.com June 2013 Page 1 Who Am I? First committer added to Hadoop in 2006 First VP of Hadoop at Apache Was architect of MapReduce
ORC Files Owen O Malley owen@hortonworks.com @owen_omalley owen@hortonworks.com June 2013 Page 1 Who Am I? First committer added to Hadoop in 2006 First VP of Hadoop at Apache Was architect of MapReduce
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk
 Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
International Journal of Advance Engineering and Research Development. A study based on Cloudera's distribution of Hadoop technologies for big data"
 Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Hacking PostgreSQL Internals to Solve Data Access Problems
 Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
ColdFusion Summit 2016
 ColdFusion Summit 2016 Building Better SQL Server Databases Who is this guy? Eric Cobb - Started in IT in 1999 as a "webmaster - Developer for 14 years - Microsoft Certified Solutions Expert (MCSE) - Data
ColdFusion Summit 2016 Building Better SQL Server Databases Who is this guy? Eric Cobb - Started in IT in 1999 as a "webmaster - Developer for 14 years - Microsoft Certified Solutions Expert (MCSE) - Data
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 5/2/2018 Legal Notices Warranty The only warranties for Micro Focus products and services are set forth in the express warranty
HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 5/2/2018 Legal Notices Warranty The only warranties for Micro Focus products and services are set forth in the express warranty
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Informatica Cloud Spring Data Integration Hub Connector Guide
 Informatica Cloud Spring 2017 Data Integration Hub Connector Guide Informatica Cloud Data Integration Hub Connector Guide Spring 2017 December 2017 Copyright Informatica LLC 1993, 2017 This software and
Informatica Cloud Spring 2017 Data Integration Hub Connector Guide Informatica Cloud Data Integration Hub Connector Guide Spring 2017 December 2017 Copyright Informatica LLC 1993, 2017 This software and
Department of Computer Science University of Cyprus. EPL342 Databases. Lab 1. Introduction to SQL Server Panayiotis Andreou
 Department of Computer Science University of Cyprus EPL342 Databases Lab 1 Introduction to SQL Server 2008 Panayiotis Andreou http://www.cs.ucy.ac.cy/courses/epl342 1-1 Before We Begin Start the SQL Server
Department of Computer Science University of Cyprus EPL342 Databases Lab 1 Introduction to SQL Server 2008 Panayiotis Andreou http://www.cs.ucy.ac.cy/courses/epl342 1-1 Before We Begin Start the SQL Server
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Processing big data with modern applications: Hadoop as DWH backend at Pro7. Dr. Kathrin Spreyer Big data engineer
 Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
This lab will introduce you to MySQL. Begin by logging into the class web server via SSH Secure Shell Client
 Lab 2.0 - MySQL CISC3140, Fall 2011 DUE: Oct. 6th (Part 1 only) Part 1 1. Getting started This lab will introduce you to MySQL. Begin by logging into the class web server via SSH Secure Shell Client host
Lab 2.0 - MySQL CISC3140, Fall 2011 DUE: Oct. 6th (Part 1 only) Part 1 1. Getting started This lab will introduce you to MySQL. Begin by logging into the class web server via SSH Secure Shell Client host
Local MapReduce debugging
 Local MapReduce debugging Tools, tips, and tricks Aaron Kimball Cloudera Inc. July 21, 2009 urce: Wikipedia Japanese rock garden Common sense debugging tips Build incrementally Build compositionally Use
Local MapReduce debugging Tools, tips, and tricks Aaron Kimball Cloudera Inc. July 21, 2009 urce: Wikipedia Japanese rock garden Common sense debugging tips Build incrementally Build compositionally Use
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Integrating with Apache Hadoop
 HPE Vertica Analytic Database Software Version: 7.2.x Document Release Date: 10/10/2017 Legal Notices Warranty The only warranties for Hewlett Packard Enterprise products and services are set forth in
HPE Vertica Analytic Database Software Version: 7.2.x Document Release Date: 10/10/2017 Legal Notices Warranty The only warranties for Hewlett Packard Enterprise products and services are set forth in
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Achieve Data Democratization with effective Data Integration Saurabh K. Gupta
 Achieve Data Democratization with effective Data Integration Saurabh K. Gupta Manager, Data & Analytics, GE www.amazon.com/author/saurabhgupta @saurabhkg Disclaimer: This report has been prepared by the
Achieve Data Democratization with effective Data Integration Saurabh K. Gupta Manager, Data & Analytics, GE www.amazon.com/author/saurabhgupta @saurabhkg Disclaimer: This report has been prepared by the
HIVE INTERVIEW QUESTIONS
 HIVE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hive/hive_interview_questions.htm Copyright tutorialspoint.com Dear readers, these Hive Interview Questions have been designed specially to get you
HIVE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hive/hive_interview_questions.htm Copyright tutorialspoint.com Dear readers, these Hive Interview Questions have been designed specially to get you
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
IBM Big SQL Partner Application Verification Quick Guide
 IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hortonworks Certified Developer (HDPCD Exam) Training Program
 Training Program") Hortonworks Certified Developer (HDPCD Exam) Training Program Having this badge on your resume can be your chance of standing out from the crowd. The HDP Certified Developer (HDPCD) exam is designed for
Hortonworks Certified Developer (HDPCD Exam) Training Program Having this badge on your resume can be your chance of standing out from the crowd. The HDP Certified Developer (HDPCD) exam is designed for
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Because databases are not easily accessible by Hadoop, Apache Sqoop was created to efficiently transfer bulk data between Hadoop and external
 Because databases are not easily accessible by Hadoop, Apache Sqoop was created to efficiently transfer bulk data between Hadoop and external structured datastores. The popularity of Sqoop in enterprise
Because databases are not easily accessible by Hadoop, Apache Sqoop was created to efficiently transfer bulk data between Hadoop and external structured datastores. The popularity of Sqoop in enterprise
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
iway Big Data Integrator New Features Bulletin and Release Notes
 iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.2 DN3502232.0717 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo, iway,
iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.2 DN3502232.0717 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo, iway,
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera