Apache Ignite and Apache Spark Where Fast Data Meets the IoT
|
|
|
- Reynard Paul
- 5 years ago
- Views:
Transcription
1 Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC #apacheignite #denismagda
2 Agenda IoT Demands to Software IoT Software Stack Device OS/RTOS Data Collection and Enrichment HTAP Platform Application APIs Demo
3 IoT Demands to Software

4 IoT Demands to Software Real-time ingestion Real-time processing Time-series support Flexible Querying APIs SQL Full-text search Geo-spatial Analytics BI Machine Learning High-availability Simple scalability
5 IoT Software Stack
6 IoT Software Stack Application APIs HTAP Platform Data Collection and Enrichment Device OS / Real-Time OS





7 Apache IoT Software Stack Application APIs HTAP Platform Data Collection and Enrichment Device OS / Real-Time OS
8 Device OS/RTOS



9 Open Source RTOS Cortex M0-M4 MIPS & RISC-V Networking Bluetooth Low Energy Wi-Fi TCP/IP & UPD Apache MyNewt Build & Package Management Secure bootloader and signed images Remote Firmware Upgrade
10 Data Collection and Enrichment

11 Data Collection and Enrichment Spark Streaming Fault-Tolerant Streams Processing Data Collection Sockets Kafka Flume Data Enrichment Spark API Data Storage Apache Ignite
12 HTAP Platform




13 Use Case: Smart Metering and Utilities delivers a comprehensive IOT platform SilverSpring Requirements Migrate to in-memory processing Add scalability & elasticity Use open source technologies SilverSpring Solution SaaS Architecture Multi-Tenancy Advanced Security Strong compute capabilities Co-located in-memory processing Demonstrated best On-demand elasticity & scalability ANSI-99 SQL Support Transactional consistency 50+ Million Meters SilverSpring IoT Platform GridGain Security

14 Apache Ignite In-Memory Data Fabric Supports Applications of various types and languages Open Source Apache 2.0 Simple Java APIs 1 JAR Dependency High Performance & Scale Automatic Fault Tolerance Management/Monitoring Runs on Commodity Hardware Supports existing & new data sources No need to rip & replace
15 Distributed Key-Value Data Store Data Reliability High-Availability Active replicas, automatic failover Data Consistency ACID distributed transactions In-Memory Data Grid


16 In-Memory Data Grid: Partitioning Partitioned Cache Replicated Cache

17 Ignite Data Streamer Fastest Data Injection Automatic data partitioning Stream Receivers Custom logic execution Additional data transformation Stream Adapter Socket Kafka Flink RocketMQ etc. Streaming to Ignite
18 Application APIs
 DDL (CREATE, DROP, etc.)")
19 ANSI-99 SQL Geo-spatial Queries Full-text Search Always Consistent Fault Tolerant Cross-Platform Apache Ignite SQL Grid JDBC and ODBC drivers DML (INSERT, UPDATE, etc.) DDL (CREATE, DROP, etc.)


20 Apache Ignite SQL Grid: Queries Distributed Joins Automatic Group By, Aggregations, Sorting Cross-Cache Joins, Unions, etc. Ad-Hoc SQL Support


21 Apache Ignite Compute Grid Direct API for MapReduce Direct API for ForkJoin Zero Deployment State Checkpoints Load Balancing Automatic Failover


22 IgniteRDD Share RDD across jobs on the host Share RDD across jobs in the application Share RDD globally Faster SQL In-Memory Indexes SQL on top of Shared RDD Spark Shared RDDs

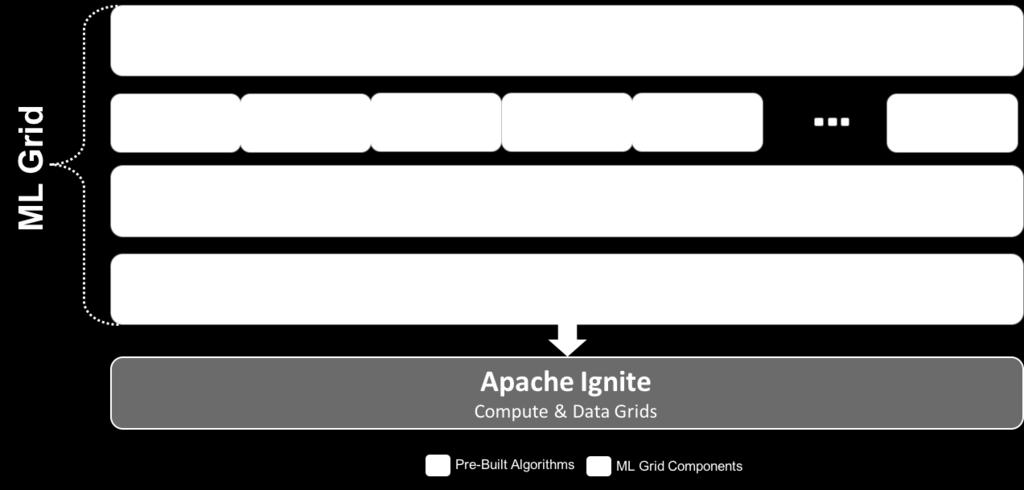
23 Machine Learning Grid
24 Demo
25 Documentation: Resources Apache Ignite: Apache Spark Streaming: Ignite and Spark Integration: Apache MyNewt: Demo Source Code:
26 ANY QUESTIONS? Thank you for joining us. Follow the conversation. #apacheignite #denismagda
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
In-Memory Performance Durability of Disk GridGain Systems, Inc.
 In-Memory Performance Durability of Disk Apache Ignite In-Memory Hammer for Your Data Science Toolkit Denis Magda Ignite PMC Chair GridGain Director of Product Management Agenda Apache Ignite Overview
In-Memory Performance Durability of Disk Apache Ignite In-Memory Hammer for Your Data Science Toolkit Denis Magda Ignite PMC Chair GridGain Director of Product Management Agenda Apache Ignite Overview
In-Memory Computing Essentials
 In-Memory Computing Essentials for Architects and Developers: Part 1 Denis Magda Ignite PMC Chair GridGain Director of Product Management Agenda Apache Ignite Overview Clustering and Deployment Distributed
In-Memory Computing Essentials for Architects and Developers: Part 1 Denis Magda Ignite PMC Chair GridGain Director of Product Management Agenda Apache Ignite Overview Clustering and Deployment Distributed
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016
 Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
Accelerate MySQL for Demanding OLAP and OLTP Use Case with Apache Ignite December 7, 2016 Nikita Ivanov CTO and Co-Founder GridGain Systems Peter Zaitsev CEO and Co-Founder Percona About the Presentation
Agenda. Apache Ignite Project Apache Ignite Data Fabric: Data Grid HPC & Compute Streaming & CEP Hadoop & Spark Integration Use Cases Demo Q & A
 Introduction 2015 The Apache Software Foundation. Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are trademarks of The Apache Software Foundation. Agenda Apache Ignite Project Apache
Introduction 2015 The Apache Software Foundation. Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are trademarks of The Apache Software Foundation. Agenda Apache Ignite Project Apache
2017 GridGain Systems, Inc. In-Memory Performance Durability of Disk
 In-Memory Performance Durability of Disk Ignite the Fire in your SQL App Akmal B. Chaudhri Technology Evangelist GridGain Systems Agenda SQL Capabilities Connectivity Data Definition Language Data Manipulation
In-Memory Performance Durability of Disk Ignite the Fire in your SQL App Akmal B. Chaudhri Technology Evangelist GridGain Systems Agenda SQL Capabilities Connectivity Data Definition Language Data Manipulation
2017 GridGain Systems, Inc. In-Memory Performance Durability of Disk
 In-Memory Performance Durability of Disk Meeting the Challenges of Fast Data in Healthcare with In-Memory Technologies Akmal Chaudhri Technology Evangelist GridGain Agenda Introduction Fast Data in Healthcare
In-Memory Performance Durability of Disk Meeting the Challenges of Fast Data in Healthcare with In-Memory Technologies Akmal Chaudhri Technology Evangelist GridGain Agenda Introduction Fast Data in Healthcare
Take Telecom to the Next Level with In- Memory Computing
 Take Telecom to the Next Level with In- Memory Computing Matt Sarrel Industry Consultant Agenda Introduction What is In-Memory Computing? GridGain / Apache Ignite Overview Survey Results Use Cases and
Take Telecom to the Next Level with In- Memory Computing Matt Sarrel Industry Consultant Agenda Introduction What is In-Memory Computing? GridGain / Apache Ignite Overview Survey Results Use Cases and
GridGain and Apache Ignite In-Memory Performance with Durability of Disk
 GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
Getting Started with Apache Ignite as a Distributed Database
 Getting Started with Apache Ignite as a Distributed Database VALENTIN KULICHENKO Lead Architect GridGain Systems, Inc. 2018 GridGain Systems, Inc. Agenda Apache Ignite as a Distributed Database Connectivity
Getting Started with Apache Ignite as a Distributed Database VALENTIN KULICHENKO Lead Architect GridGain Systems, Inc. 2018 GridGain Systems, Inc. Agenda Apache Ignite as a Distributed Database Connectivity
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
A GridGain Systems In-Memory Computing White Paper
 A GridGain Systems In-Memory Computing White Paper February 2017 Contents Five Limitations of MySQL... 2 Delivering Hot Data... 2 Dealing with Highly Volatile Data... 3 Handling Large Data Volumes... 3
A GridGain Systems In-Memory Computing White Paper February 2017 Contents Five Limitations of MySQL... 2 Delivering Hot Data... 2 Dealing with Highly Volatile Data... 3 Handling Large Data Volumes... 3
Oracle NoSQL Database Enterprise Edition, Version 18.1
 Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Esper EQC. Horizontal Scale-Out for Complex Event Processing
 Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Spatial Analytics Built for Big Data Platforms
 Spatial Analytics Built for Big Platforms Roberto Infante Software Development Manager, Spatial and Graph 1 Copyright 2011, Oracle and/or its affiliates. All rights Global Digital Growth The Internet of
Spatial Analytics Built for Big Platforms Roberto Infante Software Development Manager, Spatial and Graph 1 Copyright 2011, Oracle and/or its affiliates. All rights Global Digital Growth The Internet of
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
IN-MEMORY DATA FABRIC: Real-Time Streaming
 WHITE PAPER IN-MEMORY DATA FABRIC: Real-Time Streaming COPYRIGHT AND TRADEMARK INFORMATION 2014 GridGain Systems. All rights reserved. This document is provided as is. Information and views expressed in
WHITE PAPER IN-MEMORY DATA FABRIC: Real-Time Streaming COPYRIGHT AND TRADEMARK INFORMATION 2014 GridGain Systems. All rights reserved. This document is provided as is. Information and views expressed in
Oracle TimesTen Scaleout: Revolutionizing In-Memory Transaction Processing
 Oracle Scaleout: Revolutionizing In-Memory Transaction Processing Scaleout is a brand new, shared nothing scale-out in-memory database designed for next generation extreme OLTP workloads. Featuring elastic
Oracle Scaleout: Revolutionizing In-Memory Transaction Processing Scaleout is a brand new, shared nothing scale-out in-memory database designed for next generation extreme OLTP workloads. Featuring elastic
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation. Chris Herrera Hashmap
 Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Oracle NoSQL Database Enterprise Edition, Version 18.1
 Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018
 Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018 R E T H I N K I N G Stream Processing with Apache Kafka Kafka the Streaming Data Platform 1.0 Enterprise
Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018 R E T H I N K I N G Stream Processing with Apache Kafka Kafka the Streaming Data Platform 1.0 Enterprise
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
August 23, 2017 Revision 0.3. Building IoT Applications with GridDB
 August 23, 2017 Revision 0.3 Building IoT Applications with GridDB Table of Contents Executive Summary... 2 Introduction... 2 Components of an IoT Application... 2 IoT Models... 3 Edge Computing... 4 Gateway
August 23, 2017 Revision 0.3 Building IoT Applications with GridDB Table of Contents Executive Summary... 2 Introduction... 2 Components of an IoT Application... 2 IoT Models... 3 Edge Computing... 4 Gateway
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
@unterstein #bedcon. Operating microservices with Apache Mesos and DC/OS
 @unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
@unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Python, PySpark and Riak TS. Stephen Etheridge Lead Solution Architect, EMEA
 Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
WHITEPAPER. MemSQL Enterprise Feature List
 WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
Trafodion Enterprise-Class Transactional SQL-on-HBase
 Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
GridGain In- Memory Compu2ng Pla6orm: Empowering Insurance With In- Memory CompuBng
 GridGain In- Memory Compu2ng Pla6orm: Empowering Insurance With In- Memory CompuBng Eric Karpman Independent Consultant E- mail: emkarpman@gmail.com 25 years in Finance MaJ Sarrel Director of Technical
GridGain In- Memory Compu2ng Pla6orm: Empowering Insurance With In- Memory CompuBng Eric Karpman Independent Consultant E- mail: emkarpman@gmail.com 25 years in Finance MaJ Sarrel Director of Technical
IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data. IBM Db2 Event Store
 IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data IBM Db2 Event Store Disclaimer The information contained in this presentation is provided for informational purposes only.
IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data IBM Db2 Event Store Disclaimer The information contained in this presentation is provided for informational purposes only.
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Fast and Easy Stream Processing with Hazelcast Jet. Gokhan Oner Hazelcast
 Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Agenda. AWS Database Services Traditional vs AWS Data services model Amazon RDS Redshift DynamoDB ElastiCache
 Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER
 WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
Oracle TimesTen In-Memory Database 18.1
 Oracle TimesTen In-Memory Database 18.1 Scaleout Functionality, Architecture and Performance Chris Jenkins Senior Director, In-Memory Technology TimesTen Product Management Best In-Memory Databases: For
Oracle TimesTen In-Memory Database 18.1 Scaleout Functionality, Architecture and Performance Chris Jenkins Senior Director, In-Memory Technology TimesTen Product Management Best In-Memory Databases: For
Introduction to Apache Apex
 Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Container 2.0. Container: check! But what about persistent data, big data or fast data?!
 @unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
@unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
Modern Stream Processing with Apache Flink
 1 Modern Stream Processing with Apache Flink Till Rohrmann GOTO Berlin 2017 2 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager 3 What changes faster? Data
1 Modern Stream Processing with Apache Flink Till Rohrmann GOTO Berlin 2017 2 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager 3 What changes faster? Data
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Shen PingCAP 2017
 Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
CrateDB for Time Series. How CrateDB compares to specialized time series data stores
 CrateDB for Time Series How CrateDB compares to specialized time series data stores July 2017 The Time Series Data Workload IoT, digital business, cyber security, and other IT trends are increasing the
CrateDB for Time Series How CrateDB compares to specialized time series data stores July 2017 The Time Series Data Workload IoT, digital business, cyber security, and other IT trends are increasing the
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Down the event-driven road: Experiences of integrating streaming into analytic data platforms
 Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
DURATION : 03 DAYS. same along with BI tools.
 AWS REDSHIFT TRAINING MILDAIN DURATION : 03 DAYS To benefit from this Amazon Redshift Training course from mildain, you will need to have basic IT application development and deployment concepts, and good
AWS REDSHIFT TRAINING MILDAIN DURATION : 03 DAYS To benefit from this Amazon Redshift Training course from mildain, you will need to have basic IT application development and deployment concepts, and good
Cloud Analytics and Business Intelligence on AWS
 Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Ingesting Streaming Data for Analysis in Apache Ignite. Pat Patterson
 Ingesting Streaming Data for Analysis in Apache Ignite Pat Patterson StreamSets pat@streamsets.com @metadaddy Agenda Product Support Use Case Continuous Queries in Apache Ignite Integrating StreamSets
Ingesting Streaming Data for Analysis in Apache Ignite Pat Patterson StreamSets pat@streamsets.com @metadaddy Agenda Product Support Use Case Continuous Queries in Apache Ignite Integrating StreamSets
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Page 1. Oracle9i OLAP. Agenda. Mary Rehus Sales Consultant Patrick Larkin Vice President, Oracle Consulting. Oracle Corporation. Business Intelligence
 Oracle9i OLAP A Scalable Web-Base Business Intelligence Platform Mary Rehus Sales Consultant Patrick Larkin Vice President, Oracle Consulting Agenda Business Intelligence Market Oracle9i OLAP Business
Oracle9i OLAP A Scalable Web-Base Business Intelligence Platform Mary Rehus Sales Consultant Patrick Larkin Vice President, Oracle Consulting Agenda Business Intelligence Market Oracle9i OLAP Business
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Technical Sheet NITRODB Time-Series Database
 Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
New Oracle NoSQL Database APIs that Speed Insertion and Retrieval
 New Oracle NoSQL Database APIs that Speed Insertion and Retrieval O R A C L E W H I T E P A P E R F E B R U A R Y 2 0 1 6 1 NEW ORACLE NoSQL DATABASE APIs that SPEED INSERTION AND RETRIEVAL Introduction
New Oracle NoSQL Database APIs that Speed Insertion and Retrieval O R A C L E W H I T E P A P E R F E B R U A R Y 2 0 1 6 1 NEW ORACLE NoSQL DATABASE APIs that SPEED INSERTION AND RETRIEVAL Introduction
Distributed systems for stream processing
 Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
Hacking PostgreSQL Internals to Solve Data Access Problems
 Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
Microservices Lessons Learned From a Startup Perspective
 Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
SQL Azure. Abhay Parekh Microsoft Corporation
 SQL Azure By Abhay Parekh Microsoft Corporation Leverage this Presented by : - Abhay S. Parekh MSP & MSP Voice Program Representative, Microsoft Corporation. Before i begin Demo Let s understand SQL Azure
SQL Azure By Abhay Parekh Microsoft Corporation Leverage this Presented by : - Abhay S. Parekh MSP & MSP Voice Program Representative, Microsoft Corporation. Before i begin Demo Let s understand SQL Azure
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Understanding the latent value in all content
 Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Streaming Integration and Intelligence For Automating Time Sensitive Events
 Streaming Integration and Intelligence For Automating Time Sensitive Events Ted Fish Director Sales, Midwest ted@striim.com 312-330-4929 Striim Executive Summary Delivering Data for Time Sensitive Processes
Streaming Integration and Intelligence For Automating Time Sensitive Events Ted Fish Director Sales, Midwest ted@striim.com 312-330-4929 Striim Executive Summary Delivering Data for Time Sensitive Processes