Modern Stream Processing with Apache Flink
|
|
|
- Baldwin Rice
- 5 years ago
- Views:
Transcription

1 1
2 Modern Stream Processing with Apache Flink Till Rohrmann GOTO Berlin



3 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager 3
4 What changes faster? Data or Query? Data changes slowly compared to fast changing queries ad-hoc queries, data exploration, ML training and (hyper) parameter tuning Batch Processing Use Case Data changes fast application logic is long-lived continuous applications, data pipelines, standing queries, anomaly detection, ML evaluation, Stream Processing Use Case 4
5 Batch Processing 5
6 Stream Processing 6

7 Apache Flink in a Nutshell 7
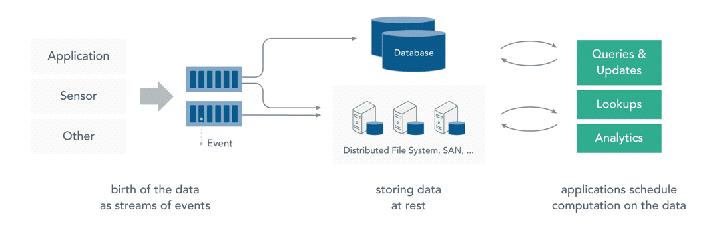
8 Apache Flink in a Nutshell Stateful computations over streams real-time and historic fast, scalable, fault tolerant, in-memory, event time, large state, exactly-once Queries Application Applications Devices etc. Streams Historic Data Database Stream File / Object Storage 8
9 The Core Building Blocks Event Streams State (Event) Time Snapshots real-time and hindsight complex business logic consistency with out-of-order data and late data forking / versioning / time-travel 9
10 Powerful Abstractions Layered abstractions to navigate simple to complex use cases High-level Analytics API Stream- & Batch Data Processing Stream SQL / Tables (dynamic tables) DataStream API (streams, windows) val stats = stream.keyby("sensor").timewindow(time.seconds(5)).sum((a, b) -> a.add(b)) Stateful Event- Driven Applications Process Function (events, state, time) def processelement(event: MyEvent, ctx: Context, out: Collector[Result]) = { // work with event and state (event, state.value) match { } out.collect( ) // emit events state.update( ) // modify state // schedule a timer callback ctx.timerservice.registereventtimetimer(event.timestamp + 500) } 10
11 Hardened at scale Athena X Streaming SQL Platform Service Streaming Platform as a Service 100s jobs, 1000s nodes, TBs state metrics, analytics, real time ML Streaming SQL as a platform Fraud detection Streaming Analytics Platform 11
12 Distributed application infrastructure 12
13 Good old centralized architecture Application Application Application Application $$$ The big mean central database The grumpy DBA 13
14 Modern distributed app. architecture Application Application Sensor Application APIs Application The limit to what you can do is how sophisticated can you compute over the stream! Boils down to: How well do you handle state and time 14


15 A Flink-favored approach 15
16 Event Sourcing + Memory Image event / command periodically snapshot the memory event log persists events (temporarily) main memory update local variables/structures Process 16
17 Event Sourcing + Memory Image Recovery: Restore snapshot and replay events since snapshot event log persists events (temporarily) Process 17
18 Distributed Memory Image Distributed application, many memory images. Snapshots are all consistent together. 18
19 Stateful Event & Stream Processing Scalable embedded state Access at memory speed & scales with parallel operators 19
20 Compute, State, and Storage Classic tiered architecture compute layer Streaming architecture compute + application state database layer application state + backup stream storage and snapshot storage (backup) 20
21 Performance Classic tiered architecture Streaming architecture synchronous reads/writes across tier boundary all modifications are local asynchronous writes of large blobs 21
22 Consistency Classic tiered architecture Streaming architecture exactly once per state =1 =1 distributed transactions at scale typically at-most / at-least once 22
23 Scaling a Service Classic tiered architecture Streaming architecture provision compute provision compute and state together separately provision additional database capacity 23
24 Rolling out a new Service Classic tiered architecture Streaming architecture provision compute and state together provision a new database (or add capacity to an existing one) simply occupies some additional backup space 24
25 What users built on checkpoints Upgrades and Rollbacks Cross Datacenter Failover State Archiving Application Migration Spot Instance Region Chasing A/B testing 25
26 What is the next wave of stream processing applications? 26

27 What changes faster? Data or Query? Data changes slowly compared to fast changing queries ad-hoc queries, data exploration, ML training and tuning Batch Processing Use Case Data changes fast application logic is long-lived continuous applications, data pipelines, standing queries, anomaly detection, ML evaluation, Stream Processing Use Case 27
28 Analytics & Business Logic Source events analytics metrics Business Logic Stream Stream Processor Database Application 28
29 Blending Analytics & Business Logic Source events Stream Streaming Application Stream Processor RPCs (Actor) Messages 29

30 AthenaX by Uber 30
31 Can one build an entire sophisticated web application (say a social network) on a stream processor? (Yes, we can! ) 31
")

32 @ Social network implemented using event sourcing and CQRS (Command Query Responsibility Segregation) on Kafka/Flink/Elasticsearch/Redis More: 32
33 The next wave of stream processing applications is all types of stateful applications that react to data and time! 33
34 Stateful stream applications Continuous applications versioning, upgrading, rollback, duplicating, migrating, 34
35 The da Platform Architecture Real-time Analytics Anomaly- & Fraud Detection Real-time Data Integration Reactive Microservices (and more) Streams from Kafka, Kinesis, S3, HDFS, Databases,... da Application Manager Application lifecycle management da Platform 2 Apache Flink Stateful stream processing Logging Metrics CI/CD Kubernetes Container platform 35
36 Versioned Applications, not Jobs/Jars Stream Processing Application New Application Version 3 Version 3a upgrade upgrade Version 2 Version 1 fork / duplicate Version 2a Code and Application Snapshot 36
37 Deployments, not Flink Clusters Threat Metrics App. Testing Fraud Detection App. Application Testing Activity Monitor Application Testing / QA Kubernetes Cluster Production Kubernetes Cluster 37
38 Hooks for CI/CD pipelines stateful upgrade trigger CI upgrade API da Application Manager Application Version 12 push update CI Service Kubernetes Cluster 38

39 @dataartisans 39
40 We are hiring! data-artisans.com/careers 40
41 41
The Power of Snapshots Stateful Stream Processing with Apache Flink
 The Power of Snapshots Stateful Stream Processing with Apache Flink Stephan Ewen QCon San Francisco, 2017 1 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager
The Power of Snapshots Stateful Stream Processing with Apache Flink Stephan Ewen QCon San Francisco, 2017 1 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER
 WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
Streaming Analytics with Apache Flink. Stephan
 Streaming Analytics with Apache Flink Stephan Ewen @stephanewen Apache Flink Stack Libraries DataStream API Stream Processing DataSet API Batch Processing Runtime Distributed Streaming Data Flow Streaming
Streaming Analytics with Apache Flink Stephan Ewen @stephanewen Apache Flink Stack Libraries DataStream API Stream Processing DataSet API Batch Processing Runtime Distributed Streaming Data Flow Streaming
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
Container 2.0. Container: check! But what about persistent data, big data or fast data?!
 @unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
@unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_
 Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
@unterstein #bedcon. Operating microservices with Apache Mesos and DC/OS
 @unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
@unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
Using the SDACK Architecture to Build a Big Data Product. Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver
 Apache Big Data NA 2016 Vancouver") Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Real-time Streaming Applications on AWS Patterns and Use Cases
 Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Personalizing Netflix with Streaming datasets
 Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Reactive Microservices Architecture on AWS
 Reactive Microservices Architecture on AWS Sascha Möllering Solutions Architect, @sascha242, Amazon Web Services Germany GmbH Why are we here today? https://secure.flickr.com/photos/mgifford/4525333972
Reactive Microservices Architecture on AWS Sascha Möllering Solutions Architect, @sascha242, Amazon Web Services Germany GmbH Why are we here today? https://secure.flickr.com/photos/mgifford/4525333972
Advanced Continuous Delivery Strategies for Containerized Applications Using DC/OS
 Advanced Continuous Delivery Strategies for Containerized Applications Using DC/OS ContainerCon @ Open Source Summit North America 2017 Elizabeth K. Joseph @pleia2 1 Elizabeth K. Joseph, Developer Advocate
Advanced Continuous Delivery Strategies for Containerized Applications Using DC/OS ContainerCon @ Open Source Summit North America 2017 Elizabeth K. Joseph @pleia2 1 Elizabeth K. Joseph, Developer Advocate
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
Cloud Analytics and Business Intelligence on AWS
 Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Qualys Cloud Platform
 18 QUALYS SECURITY CONFERENCE 2018 Qualys Cloud Platform Looking Under the Hood: What Makes Our Cloud Platform so Scalable and Powerful Dilip Bachwani Vice President, Engineering, Qualys, Inc. Cloud Platform
18 QUALYS SECURITY CONFERENCE 2018 Qualys Cloud Platform Looking Under the Hood: What Makes Our Cloud Platform so Scalable and Powerful Dilip Bachwani Vice President, Engineering, Qualys, Inc. Cloud Platform
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
How Microsoft Built MySQL, PostgreSQL and MariaDB for the Cloud. Santa Clara, California April 23th 25th, 2018
 How Microsoft Built MySQL, PostgreSQL and MariaDB for the Cloud Santa Clara, California April 23th 25th, 2018 Azure Data Service Architecture Share Cluster with SQL DB Azure Infrastructure Services Azure
How Microsoft Built MySQL, PostgreSQL and MariaDB for the Cloud Santa Clara, California April 23th 25th, 2018 Azure Data Service Architecture Share Cluster with SQL DB Azure Infrastructure Services Azure
Spark and Flink running scalable in Kubernetes Frank Conrad
 Spark and Flink running scalable in Kubernetes Frank Conrad Architect @ apomaya.com scalable efficient low latency processing 1 motivation, use case run (external, unknown trust) customer spark / flink
Spark and Flink running scalable in Kubernetes Frank Conrad Architect @ apomaya.com scalable efficient low latency processing 1 motivation, use case run (external, unknown trust) customer spark / flink
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS
 Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
Apache Flink Streaming Done Right. Till
 Apache Flink Streaming Done Right Till Rohrmann trohrmann@apache.org @stsffap What Is Apache Flink? Apache TLP since December 2014 Parallel streaming data flow runtime Low latency & high throughput Exactly
Apache Flink Streaming Done Right Till Rohrmann trohrmann@apache.org @stsffap What Is Apache Flink? Apache TLP since December 2014 Parallel streaming data flow runtime Low latency & high throughput Exactly
Deploying Applications on DC/OS
 Mesosphere Datacenter Operating System Deploying Applications on DC/OS Keith McClellan - Technical Lead, Federal Programs keith.mcclellan@mesosphere.com V6 THE FUTURE IS ALREADY HERE IT S JUST NOT EVENLY
Mesosphere Datacenter Operating System Deploying Applications on DC/OS Keith McClellan - Technical Lead, Federal Programs keith.mcclellan@mesosphere.com V6 THE FUTURE IS ALREADY HERE IT S JUST NOT EVENLY
Deep Dive into Concepts and Tools for Analyzing Streaming Data
 Deep Dive into Concepts and Tools for Analyzing Streaming Data Dr. Steffen Hausmann Sr. Solutions Architect, Amazon Web Services Data originates in real-time Photo by mountainamoeba https://www.flickr.com/photos/mountainamoeba/2527300028/
Deep Dive into Concepts and Tools for Analyzing Streaming Data Dr. Steffen Hausmann Sr. Solutions Architect, Amazon Web Services Data originates in real-time Photo by mountainamoeba https://www.flickr.com/photos/mountainamoeba/2527300028/
WHITEPAPER. MemSQL Enterprise Feature List
 WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
Deep Dive Amazon Kinesis. Ian Meyers, Principal Solution Architect - Amazon Web Services
 Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Architecting Microsoft Azure Solutions (proposed exam 535)
") Architecting Microsoft Azure Solutions (proposed exam 535) IMPORTANT: Significant changes are in progress for exam 534 and its content. As a result, we are retiring this exam on December 31, 2017, and
Architecting Microsoft Azure Solutions (proposed exam 535) IMPORTANT: Significant changes are in progress for exam 534 and its content. As a result, we are retiring this exam on December 31, 2017, and
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE
 DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
70-532: Developing Microsoft Azure Solutions
 70-532: Developing Microsoft Azure Solutions Exam Design Target Audience Candidates of this exam are experienced in designing, programming, implementing, automating, and monitoring Microsoft Azure solutions.
70-532: Developing Microsoft Azure Solutions Exam Design Target Audience Candidates of this exam are experienced in designing, programming, implementing, automating, and monitoring Microsoft Azure solutions.
Sunil Shah SECURE, FLEXIBLE CONTINUOUS DELIVERY PIPELINES WITH GITLAB AND DC/OS Mesosphere, Inc. All Rights Reserved.
 Sunil Shah SECURE, FLEXIBLE CONTINUOUS DELIVERY PIPELINES WITH GITLAB AND DC/OS 1 Introduction MOBILE, SOCIAL & CLOUD ARE RAISING CUSTOMER EXPECTATIONS We need a way to deliver software so fast that our
Sunil Shah SECURE, FLEXIBLE CONTINUOUS DELIVERY PIPELINES WITH GITLAB AND DC/OS 1 Introduction MOBILE, SOCIAL & CLOUD ARE RAISING CUSTOMER EXPECTATIONS We need a way to deliver software so fast that our
Windows Azure Services - At Different Levels
 Windows Azure Windows Azure Services - At Different Levels SaaS eg : MS Office 365 Paas eg : Azure SQL Database, Azure websites, Azure Content Delivery Network (CDN), Azure BizTalk Services, and Azure
Windows Azure Windows Azure Services - At Different Levels SaaS eg : MS Office 365 Paas eg : Azure SQL Database, Azure websites, Azure Content Delivery Network (CDN), Azure BizTalk Services, and Azure
OpenShift Roadmap Enterprise Kubernetes for Developers. Clayton Coleman, Architect, OpenShift
 OpenShift Roadmap Enterprise Kubernetes for Developers Clayton Coleman, Architect, OpenShift What Is OpenShift? Application-centric Platform INFRASTRUCTURE APPLICATIONS Use containers for efficiency Hide
OpenShift Roadmap Enterprise Kubernetes for Developers Clayton Coleman, Architect, OpenShift What Is OpenShift? Application-centric Platform INFRASTRUCTURE APPLICATIONS Use containers for efficiency Hide
IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow
 1 IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow Kafka-Native End-to-End IoT Data Integration and Processing Kai Waehner - Technology Evangelist kontakt@kai-waehner.de - LinkedIn Twitter :
1 IoT Sensor Analytics with Apache Kafka, KSQL and TensorFlow Kafka-Native End-to-End IoT Data Integration and Processing Kai Waehner - Technology Evangelist kontakt@kai-waehner.de - LinkedIn Twitter :
Esper EQC. Horizontal Scale-Out for Complex Event Processing
 Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Developing Microsoft Azure Solutions (70-532) Syllabus
 Syllabus") Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Architecture of Flink's Streaming Runtime. Robert
 Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
MarkLogic Technology Briefing
 MarkLogic Technology Briefing Edd Patterson CTO/VP Systems Engineering, Americas Slide 1 Agenda Introductions About MarkLogic MarkLogic Server Deep Dive Slide 2 MarkLogic Overview Company Highlights Headquartered
MarkLogic Technology Briefing Edd Patterson CTO/VP Systems Engineering, Americas Slide 1 Agenda Introductions About MarkLogic MarkLogic Server Deep Dive Slide 2 MarkLogic Overview Company Highlights Headquartered
Redesigning Apache Flink s Distributed Architecture. Till
 Redesigning Apache Flink s Distributed Architecture Till Rohrmann trohrmann@apache.org @stsffap 2 1001 Deployment Scenarios Many different deployment scenarios Yarn Mesos Docker/Kubernetes Standalone Etc.
Redesigning Apache Flink s Distributed Architecture Till Rohrmann trohrmann@apache.org @stsffap 2 1001 Deployment Scenarios Many different deployment scenarios Yarn Mesos Docker/Kubernetes Standalone Etc.
Building a Data-Friendly Platform for a Data- Driven Future
 Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Managing IoT and Time Series Data with Amazon ElastiCache for Redis
 Managing IoT and Time Series Data with ElastiCache for Redis Darin Briskman, ElastiCache Developer Outreach Michael Labib, Specialist Solutions Architect 2016, Web Services, Inc. or its Affiliates. All
Managing IoT and Time Series Data with ElastiCache for Redis Darin Briskman, ElastiCache Developer Outreach Michael Labib, Specialist Solutions Architect 2016, Web Services, Inc. or its Affiliates. All
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Exam : Implementing Microsoft Azure Infrastructure Solutions
 Exam 70-533: Implementing Microsoft Azure Infrastructure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Design and Implement Azure App Service
Exam 70-533: Implementing Microsoft Azure Infrastructure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Design and Implement Azure App Service
Big Data on AWS. Big Data Agility and Performance Delivered in the Cloud. 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
 Big Data on AWS Big Data Agility and Performance Delivered in the Cloud 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Big Data Technologies and techniques for working productively
Big Data on AWS Big Data Agility and Performance Delivered in the Cloud 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Big Data Technologies and techniques for working productively
Containers or Serverless? Mike Gillespie Solutions Architect, AWS Solutions Architecture
 Containers or Serverless? Mike Gillespie Solutions Architect, AWS Solutions Architecture A Typical Application with Microservices Client Webapp Webapp Webapp Greeting Greeting Greeting Name Name Name Microservice
Containers or Serverless? Mike Gillespie Solutions Architect, AWS Solutions Architecture A Typical Application with Microservices Client Webapp Webapp Webapp Greeting Greeting Greeting Name Name Name Microservice
Apache Ignite and Apache Spark Where Fast Data Meets the IoT
 Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Migration. 22 AUG 2017 VMware Validated Design 4.1 VMware Validated Design for Software-Defined Data Center 4.1
 22 AUG 2017 VMware Validated Design 4.1 VMware Validated Design for Software-Defined Data Center 4.1 You can find the most up-to-date technical documentation on the VMware Web site at: https://docs.vmware.com/
22 AUG 2017 VMware Validated Design 4.1 VMware Validated Design for Software-Defined Data Center 4.1 You can find the most up-to-date technical documentation on the VMware Web site at: https://docs.vmware.com/
How can you implement this through a script that a scheduling daemon runs daily on the application servers?
 You ve been tasked with implementing an automated data backup solution for your application servers that run on Amazon EC2 with Amazon EBS volumes. You want to use a distributed data store for your backups
You ve been tasked with implementing an automated data backup solution for your application servers that run on Amazon EC2 with Amazon EBS volumes. You want to use a distributed data store for your backups
Streaming data Model is opposite Queries are usually fixed and data are flows through the system.
 1 2 3 Main difference is: Static Data Model (For related database or Hadoop) Data is stored, and we just send some query. Streaming data Model is opposite Queries are usually fixed and data are flows through
1 2 3 Main difference is: Static Data Model (For related database or Hadoop) Data is stored, and we just send some query. Streaming data Model is opposite Queries are usually fixed and data are flows through
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Focus On: Oracle Database 11g Release 2
 Focus On: Oracle Database 11g Release 2 Focus on: Oracle Database 11g Release 2 Oracle s most recent database version, Oracle Database 11g Release 2 [11g R2] is focused on cost saving, high availability
Focus On: Oracle Database 11g Release 2 Focus on: Oracle Database 11g Release 2 Oracle s most recent database version, Oracle Database 11g Release 2 [11g R2] is focused on cost saving, high availability
Extending Flink s Streaming APIs
 Extending Flink s Streaming APIs Kostas Kloudas @KLOUBEN_K Flink Forward San Francisco April 11, 2017 1 Original creators of Apache Flink Providers of the da Platform, a supported Flink distribution 2
Extending Flink s Streaming APIs Kostas Kloudas @KLOUBEN_K Flink Forward San Francisco April 11, 2017 1 Original creators of Apache Flink Providers of the da Platform, a supported Flink distribution 2
Course Outline: Designing, Optimizing, and Maintaining a Database Administrative Solution for Microsoft SQL Server 2008
 Course Outline: Designing, Optimizing, and Maintaining a Database Administrative Solution for Microsoft SQL Learning Method: Instructor-led Classroom Learning Duration: 5.00 Day(s)/ 40hrs Overview: This
Course Outline: Designing, Optimizing, and Maintaining a Database Administrative Solution for Microsoft SQL Learning Method: Instructor-led Classroom Learning Duration: 5.00 Day(s)/ 40hrs Overview: This
Data Protection Modernization: Meeting the Challenges of a Changing IT Landscape
 Data Protection Modernization: Meeting the Challenges of a Changing IT Landscape Tom Clark IBM Distinguished Engineer, Chief Architect Software 1 Data growth is continuing to explode Sensors & Devices
Data Protection Modernization: Meeting the Challenges of a Changing IT Landscape Tom Clark IBM Distinguished Engineer, Chief Architect Software 1 Data growth is continuing to explode Sensors & Devices
Backup strategies for Stateful Containers in OpenShift Using Gluster based Container-Native Storage
 Backup strategies for Stateful Containers in OpenShift Using Gluster based Container-Native Storage Niels de Vos Senior Software Engineer Red Hat Storage Critical features for both Dev and Ops Self-Service
Backup strategies for Stateful Containers in OpenShift Using Gluster based Container-Native Storage Niels de Vos Senior Software Engineer Red Hat Storage Critical features for both Dev and Ops Self-Service
Microsoft Azure Course Content
 Cloud Computing Trainings @ STUCORNER & SHARPENCLOUD Microsoft Azure Course Content Lesson 1: Introduction to Azure 1. Overview of On-premise infrastructure 2. Transition from On-premise to datacenter
Cloud Computing Trainings @ STUCORNER & SHARPENCLOUD Microsoft Azure Course Content Lesson 1: Introduction to Azure 1. Overview of On-premise infrastructure 2. Transition from On-premise to datacenter
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Microsoft SQL Server
 Microsoft SQL Server Abstract This white paper outlines the best practices for Microsoft SQL Server Failover Cluster Instance data protection with Cohesity DataPlatform. December 2017 Table of Contents
Microsoft SQL Server Abstract This white paper outlines the best practices for Microsoft SQL Server Failover Cluster Instance data protection with Cohesity DataPlatform. December 2017 Table of Contents
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
data Artisans Streaming Ledger
 data Artisans Streaming Ledger Serializable ACID Transactions on Streaming Data Whitepaper Patent pending in the United States, Europe, and possibly other territories Table of Contents Introduction Streaming
data Artisans Streaming Ledger Serializable ACID Transactions on Streaming Data Whitepaper Patent pending in the United States, Europe, and possibly other territories Table of Contents Introduction Streaming
Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio
 CASE STUDY Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio Xueyan Li, Lei Xu, and Xiaoxu Lv Software Engineers at Qunar At Qunar, we have been running Alluxio in production for over
CASE STUDY Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio Xueyan Li, Lei Xu, and Xiaoxu Lv Software Engineers at Qunar At Qunar, we have been running Alluxio in production for over
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
70-532: Developing Microsoft Azure Solutions
 70-532: Developing Microsoft Azure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Create and Manage Azure Resource Manager Virtual Machines
70-532: Developing Microsoft Azure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Create and Manage Azure Resource Manager Virtual Machines
Using DC/OS for Continuous Delivery
 Using DC/OS for Continuous Delivery DevPulseCon 2017 Elizabeth K. Joseph, @pleia2 Mesosphere 1 Elizabeth K. Joseph, Developer Advocate, Mesosphere 15+ years working in open source communities 10+ years
Using DC/OS for Continuous Delivery DevPulseCon 2017 Elizabeth K. Joseph, @pleia2 Mesosphere 1 Elizabeth K. Joseph, Developer Advocate, Mesosphere 15+ years working in open source communities 10+ years
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Introduction to Apache Apex
 Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
AWS Lambda: Event-driven Code in the Cloud
 AWS Lambda: Event-driven Code in the Cloud Dean Bryen, Solutions Architect AWS Andrew Wheat, Senior Software Engineer - BBC April 15, 2015 London, UK 2015, Amazon Web Services, Inc. or its affiliates.
AWS Lambda: Event-driven Code in the Cloud Dean Bryen, Solutions Architect AWS Andrew Wheat, Senior Software Engineer - BBC April 15, 2015 London, UK 2015, Amazon Web Services, Inc. or its affiliates.
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK
 IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
Nevin Dong 董乃文 Principle Technical Evangelist Microsoft Cooperation
 Nevin Dong 董乃文 Principle Technical Evangelist Microsoft Cooperation Microservices Autonomous API Gateway Events Service Discovery Circuit Breakers Commands Aggregates Bounded Context Event Bus Domain Events
Nevin Dong 董乃文 Principle Technical Evangelist Microsoft Cooperation Microservices Autonomous API Gateway Events Service Discovery Circuit Breakers Commands Aggregates Bounded Context Event Bus Domain Events
Cisco Cloud Strategy. Uwe Müller. Leader PreSales Cloud & Datacenter Germany
 Cisco Cloud Strategy Uwe Müller Leader PreSales Cloud & Datacenter Germany 277X Data created by IoE devices v. end-user 30M New devices connected every week 180B Mobile apps downloaded in 2015 78% Workloads
Cisco Cloud Strategy Uwe Müller Leader PreSales Cloud & Datacenter Germany 277X Data created by IoE devices v. end-user 30M New devices connected every week 180B Mobile apps downloaded in 2015 78% Workloads
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Developing Microsoft Azure Solutions (70-532) Syllabus
 Syllabus") Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Down the event-driven road: Experiences of integrating streaming into analytic data platforms
 Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Event Streams using Apache Kafka
 Event Streams using Apache Kafka And how it relates to IBM MQ Andrew Schofield Chief Architect, Event Streams STSM, IBM Messaging, Hursley Park Event-driven systems deliver more engaging customer experiences
Event Streams using Apache Kafka And how it relates to IBM MQ Andrew Schofield Chief Architect, Event Streams STSM, IBM Messaging, Hursley Park Event-driven systems deliver more engaging customer experiences
Best practices for OpenShift high-availability deployment field experience
 Best practices for OpenShift high-availability deployment field experience Orgad Kimchi, Red Hat, Christina Wong, NuoDB, Ariff Kassam, NuoDB Traditional disaster recovery means maintaining underutilized
Best practices for OpenShift high-availability deployment field experience Orgad Kimchi, Red Hat, Christina Wong, NuoDB, Ariff Kassam, NuoDB Traditional disaster recovery means maintaining underutilized
Continuous Integration and Delivery with Spinnaker
 White Paper Continuous Integration and Delivery with Spinnaker The field of software functional testing is undergoing a major transformation. What used to be an onerous manual process took a big step forward
White Paper Continuous Integration and Delivery with Spinnaker The field of software functional testing is undergoing a major transformation. What used to be an onerous manual process took a big step forward
An Information Asset Hub. How to Effectively Share Your Data
 An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
AWS Serverless Architecture Think Big
 MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
VOLTDB + HP VERTICA. page
 VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
Distributed Data on Distributed Infrastructure. Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere
 Distributed Data on Distributed Infrastructure Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere Kunal Kusoorkar Director Solutions Engineering, ArangoDB @neunhoef Jörg Schad Claudius
Distributed Data on Distributed Infrastructure Claudius Weinberger & Kunal Kusoorkar, ArangoDB Jörg Schad, Mesosphere Kunal Kusoorkar Director Solutions Engineering, ArangoDB @neunhoef Jörg Schad Claudius
Oracle 12c Dataguard Administration (32 Hours)
") Oracle 12c Dataguard Administration (32 Hours) Course Topics Introduction to Oracle Data Guard What Is Oracle Data Guard? Types of Standby Databases Types of Data Guard Services Role Transitions: Switchover
Oracle 12c Dataguard Administration (32 Hours) Course Topics Introduction to Oracle Data Guard What Is Oracle Data Guard? Types of Standby Databases Types of Data Guard Services Role Transitions: Switchover
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
MEAP Edition Manning Early Access Program Flink in Action Version 2
 MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for
MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for
HYBRID TRANSACTION/ANALYTICAL PROCESSING COLIN MACNAUGHTON
 HYBRID TRANSACTION/ANALYTICAL PROCESSING COLIN MACNAUGHTON WHO IS NEEVE RESEARCH? Headquartered in Silicon Valley Creators of the X Platform - Memory Oriented Application Platform Passionate about high
HYBRID TRANSACTION/ANALYTICAL PROCESSING COLIN MACNAUGHTON WHO IS NEEVE RESEARCH? Headquartered in Silicon Valley Creators of the X Platform - Memory Oriented Application Platform Passionate about high