China Big Data and HPC Initiatives Overview. Xuanhua Shi
|
|
|
- Derrick Cain
- 5 years ago
- Views:
Transcription
1 China Big Data and HPC Initiatives Overview Xuanhua Shi Services Computing Technology and System Laboratory Big Data Technology and System Laboratory Cluster and Grid Computing Laboratory Huazhong University of Science and Technology, Wuhan, China
2 Outline n In-Memory Computing n New Funding by MOST n HPC Initiatives ( ) n Big Data Initiatives ( )


3 In-Memory Computing: Lifting the Burden of Big Data Aberdeen Group 3
4 In-memory Database Traditional Computing in-memory Computing Database of Record Database of Record App. Data Application Code App. Data Application Code Persistency Recovery Post-processing Backup App. Data Application Code App. Data Application Code Main Memory (DRAM) Main Memory (DRAM) ØTraditional systems exchange data pages between memory and disk when computing with big data : Expensive IO cost Ø Speed of Disk: ms Speed of Memory: ns Ø In-Memory Computing: CPU reads data from memory and provides realtime data processing.
5 Downsides of DRAM Refresh Energy consumption: Each refresh consumes energy Performance degradation: DRAM bank unavailable while refreshed QoS/predictability impact: (Long) pause times during refresh Refresh rate limits DRAM capacity scaling


6 Emerging Non-volatile Memory (NVM) Technologies 6/17/16
7 Storage Class Memory SCM is a new class of data storage and memory devices SCM blurs the distinction between MEMORY (= fast, expensive, volatile ) and STORAGE (= slow, cheap, non-volatile) Characteristics of SCM Solid state, no moving parts Short access times (~ DRAM like, within an order-of-magnitude) Low cost per bit (DISK like, within an order-of-magnitude) Non-volatile ( ~ 10 years)

8 Reconstruction of Virtual Memory Architecture: Break the I/O Bottleneck 8


9 New In-Memory Computing Architecture Build DRAM + SCM hybrid hierarchical/parallel memory structure Memory Channel I/O Channel Disk Memory Channel Data I/O Channel New In-memory Computing Architecture The new in-memory computing architecture supports the shift from computing-centric to combination of computing and data 9

10 Challenges of Hybrid Memory Systems How should SCM-based (main) memory be organized? Partitioning Should DRAM be a cache or main memory, or configurable? What fraction? How many controllers?
11 Challenges of Hybrid Memory Systems Data allocation/movement (energy, performance, lifetime) Who manages allocation/movement? What are good control algorithms? How do we prevent degradation of service due to wearout? Design of cache hierarchy, memory controllers, OS Mitigate PCM shortcomings, exploit PCM advantages Persistent data can be randomly and synchronously addressed Huge non-volatile address spaces, memory-mapped DB, persistent objects Should SCM be used like I/O or like memory or in a totally new way?
12 Challenges of Hybrid Memory Systems Software Architecture Should one make SCM visible to applications software? If visible, in which form? New APIs, libraries, memory models, new I/O devices,... Databases, Business Intelligence and Streams are first impacted Data-intensive HPC - predictable execution time of complex business analytics - streaming search
13 Challenges of Enabling and Exploiting NVM Enabling NVM and hybrid memory How to tolerate errors? How to enable secure operation? How to tolerate performance and power shortcomings? How to minimize cost? Exploiting emerging technologies How to exploit non-volatility? How to minimize energy consumption? How to exploit NVM on chip?
14 Technology and System of In-Memory Computing for Big Data Processing Hybrid Memory Architecture for In-Memory Computing System System Software for In-Memory Computing System Parallel Processing for In-Memory Computing System Data Management for In-Memory Computing System 14
15 Technology and System of In-Memory Computing for Big Data Processing Project Overview Total budget: 170M RMB Period: January 2015 December 2017 Participants Inspur Huawei Sugon Shanghai Jiaotong University Huazhong University of Science and Technology Chongqing University National University of Defense Technology Huadong Normal University Jiangnan Computing Institute 15

16 Technology and System of In-Memory Computing for Big Data Processing Project Mission Hybrid NVM-based high reliable, massive storage, and low power in-memory computing system, the capacity of NVM in each node should be in TB level, supporting zero bootup System software and simulation platform for inmemory computing system Parallel processing system for in-memory computing system In-memory database for hybrid memory architecture to support decision making and other data management applications 16
17 System Architecture
18 Full System Simulator Applications Core Core Core Core Latency-Aware Shared Cache Data Migration Service Channel Redirect Mapping PCM Libs OS Migrator DRAM Software Level Migration Libs Hardware Level Migration Strategies Designed Based On: MARSSX86+ NVMain More flexible (supports NVMain DRAMSim HybridSim as main memory simulator) Simulate memory system precisely, easy to configure
19 Pros and Cons of DDPS User Program UDT UDF Distributed Data Process System Platform with memory management Stage1 StageN Produce data objects with different lifetime Apply Memory Y allocate N GC Benefit from the high-level objectoriented language The automatic memory management of platform effect the performance seriously



20 Deca: Exploiting Raw Data of In-Memory Data Objects in Distributed Data-Parallel Systems l Completely decomposing inmemory data objects to eliminate the references invocation and reduce frequent garbage collection in JVM l A system to automatic converse the user codes, decompose data objects and manage in-memory raw data l Speedup from 22.7x to 41.6x, compare with Apache Spark






")







21 Hadoop Engine: IO-intensive Map Task 1.I/O operations input split Hdfs collect Map buffer 2.I/O operations Local Disk Jvm sortandspill Merge-Sort (Combine) I/O wait file0 file1 file2 final merged file 3.I/O operations Shuffle NetWork final output 7.I/O operations Reduce Task 6.I/O operations Reduce file0 file1 file2 Merge 5.I/O operations Pull Sort Jvm 4.I/O operations 16/6/17 21



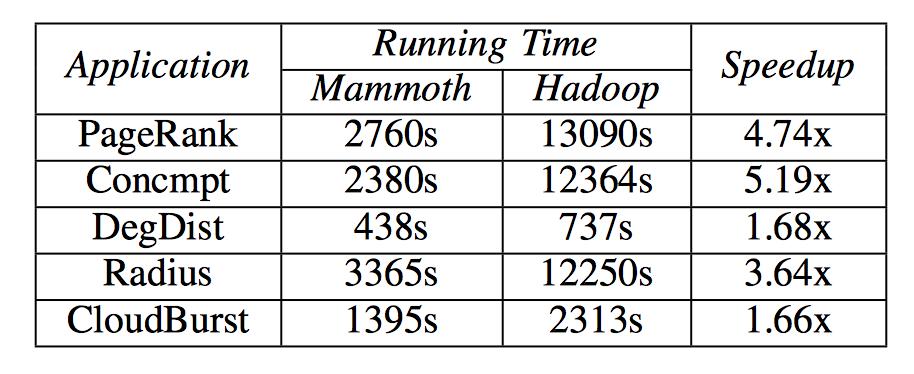

22 Mammoth: Memory-Centric MapReduce System A novel rule-based heuristic to prioritize memory allocation and revocation mechanism A multi-threaded execution engine, which realize global memory management Compatible with Hadoop Sources available at Github and ASF IEEE Computer Spotlight Execution Engine 10 22


23 Landscape of Disk-Based and In-Memory Data Management Systems (2014) 23
24 Outline n In-Memory Computing n New Funding by MOST n HPC Initiatives ( ) n Big Data Initiatives ( )
25 HPC Initiatives ( ) Two 100PFlops Supercomputer One is located Wuxi, another is located in Guangzhou E-scale architecture E-scale processors High-speed network HPC software stack Co-design: Aircraft design and Weather forecasting Some typical applications 25

26 Big Data Initiatives ( ) Big data infrastructure New storage system Data flow based data analyzed stack Domain specific data management system Data-driven software Data analyze applications and Human-like intelligence From data to knowledge Large scale objects recognition 26
27 Thanks!
Gearing Hadoop towards HPC sytems
 Gearing Hadoop towards HPC sytems Xuanhua Shi http://grid.hust.edu.cn/xhshi Huazhong University of Science and Technology HPC Advisory Council China Workshop 2014, Guangzhou 2014/11/5 2 Internet Internet
Gearing Hadoop towards HPC sytems Xuanhua Shi http://grid.hust.edu.cn/xhshi Huazhong University of Science and Technology HPC Advisory Council China Workshop 2014, Guangzhou 2014/11/5 2 Internet Internet
Optimizing Apache Spark with Memory1. July Page 1 of 14
 Optimizing Apache Spark with Memory1 July 2016 Page 1 of 14 Abstract The prevalence of Big Data is driving increasing demand for real -time analysis and insight. Big data processing platforms, like Apache
Optimizing Apache Spark with Memory1 July 2016 Page 1 of 14 Abstract The prevalence of Big Data is driving increasing demand for real -time analysis and insight. Big data processing platforms, like Apache
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Practical Near-Data Processing for In-Memory Analytics Frameworks
 Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
The Role of Database Aware Flash Technologies in Accelerating Mission- Critical Databases
 The Role of Database Aware Flash Technologies in Accelerating Mission- Critical Databases Gurmeet Goindi Principal Product Manager Oracle Flash Memory Summit 2013 Santa Clara, CA 1 Agenda Relational Database
The Role of Database Aware Flash Technologies in Accelerating Mission- Critical Databases Gurmeet Goindi Principal Product Manager Oracle Flash Memory Summit 2013 Santa Clara, CA 1 Agenda Relational Database
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Using Alluxio to Improve the Performance and Consistency of HDFS Clusters
 ARTICLE Using Alluxio to Improve the Performance and Consistency of HDFS Clusters Calvin Jia Software Engineer at Alluxio Learn how Alluxio is used in clusters with co-located compute and storage to improve
ARTICLE Using Alluxio to Improve the Performance and Consistency of HDFS Clusters Calvin Jia Software Engineer at Alluxio Learn how Alluxio is used in clusters with co-located compute and storage to improve
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS
 SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS Samira Khan MEMORY IN TODAY S SYSTEM Processor DRAM Memory Storage DRAM is critical for performance
SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS Samira Khan MEMORY IN TODAY S SYSTEM Processor DRAM Memory Storage DRAM is critical for performance
Innovator, Disruptor or Laggard, Where will your storage applications live? Next generation storage
 Innovator, Disruptor or Laggard, Where will your storage applications live? Next generation storage Bev Crair, Vice President and General Manager, Storage Group Intel The world is changing Information
Innovator, Disruptor or Laggard, Where will your storage applications live? Next generation storage Bev Crair, Vice President and General Manager, Storage Group Intel The world is changing Information
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
PHX: Memory Speed HPC I/O with NVM. Pradeep Fernando Sudarsun Kannan, Ada Gavrilovska, Karsten Schwan
 PHX: Memory Speed HPC I/O with NVM Pradeep Fernando Sudarsun Kannan, Ada Gavrilovska, Karsten Schwan Node Local Persistent I/O? Node local checkpoint/ restart - Recover from transient failures ( node restart)
PHX: Memory Speed HPC I/O with NVM Pradeep Fernando Sudarsun Kannan, Ada Gavrilovska, Karsten Schwan Node Local Persistent I/O? Node local checkpoint/ restart - Recover from transient failures ( node restart)
Efficient Data Mapping and Buffering Techniques for Multi-Level Cell Phase-Change Memories
 Efficient Data Mapping and Buffering Techniques for Multi-Level Cell Phase-Change Memories HanBin Yoon, Justin Meza, Naveen Muralimanohar*, Onur Mutlu, Norm Jouppi* Carnegie Mellon University * Hewlett-Packard
Efficient Data Mapping and Buffering Techniques for Multi-Level Cell Phase-Change Memories HanBin Yoon, Justin Meza, Naveen Muralimanohar*, Onur Mutlu, Norm Jouppi* Carnegie Mellon University * Hewlett-Packard
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Oracle Exadata: Strategy and Roadmap
 Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
IQ for DNA. Interactive Query for Dynamic Network Analytics. Haoyu Song. HUAWEI TECHNOLOGIES Co., Ltd.
 IQ for DNA Interactive Query for Dynamic Network Analytics Haoyu Song www.huawei.com Motivation Service Provider s pain point Lack of real-time and full visibility of networks, so the network monitoring
IQ for DNA Interactive Query for Dynamic Network Analytics Haoyu Song www.huawei.com Motivation Service Provider s pain point Lack of real-time and full visibility of networks, so the network monitoring
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands
 Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands Unleash Your Data Center s Hidden Power September 16, 2014 Molly Rector CMO, EVP Product Management & WW Marketing
Leveraging Software-Defined Storage to Meet Today and Tomorrow s Infrastructure Demands Unleash Your Data Center s Hidden Power September 16, 2014 Molly Rector CMO, EVP Product Management & WW Marketing
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Huge market -- essentially all high performance databases work this way
 11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
SpongeFiles: Mitigating Data Skew in MapReduce Using Distributed Memory. Khaled Elmeleegy Turn Inc.
 SpongeFiles: Mitigating Data Skew in MapReduce Using Distributed Memory Khaled Elmeleegy Turn Inc. kelmeleegy@turn.com Christopher Olston Google Inc. olston@google.com Benjamin Reed Facebook Inc. br33d@fb.com
SpongeFiles: Mitigating Data Skew in MapReduce Using Distributed Memory Khaled Elmeleegy Turn Inc. kelmeleegy@turn.com Christopher Olston Google Inc. olston@google.com Benjamin Reed Facebook Inc. br33d@fb.com
Workload Characterization and Optimization of TPC-H Queries on Apache Spark
 Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Linear Regression Optimization
 Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic
 WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
 Original citation: Shi, Xuanhua, Chen, Ming, He, Ligang, Xie, Xu, Lu, Lu, Jin, Hai, Chen, Yong and Wu, Song. (214) Mammoth : gearing hadoop towards memory-intensive MapReduce applications. IEEE Transactions
Original citation: Shi, Xuanhua, Chen, Ming, He, Ligang, Xie, Xu, Lu, Lu, Jin, Hai, Chen, Yong and Wu, Song. (214) Mammoth : gearing hadoop towards memory-intensive MapReduce applications. IEEE Transactions
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Planning For Persistent Memory In The Data Center. Sarah Jelinek/Intel Corporation
 Planning For Persistent Memory In The Data Center Sarah Jelinek/Intel Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies
Planning For Persistent Memory In The Data Center Sarah Jelinek/Intel Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
IBM Education Assistance for z/os V2R2
 IBM Education Assistance for z/os V2R2 Item: RSM Scalability Element/Component: Real Storage Manager Material current as of May 2015 IBM Presentation Template Full Version Agenda Trademarks Presentation
IBM Education Assistance for z/os V2R2 Item: RSM Scalability Element/Component: Real Storage Manager Material current as of May 2015 IBM Presentation Template Full Version Agenda Trademarks Presentation
: A new version of Supercomputing or life after the end of the Moore s Law
 : A new version of Supercomputing or life after the end of the Moore s Law Dr.-Ing. Alexey Cheptsov SEMAPRO 2015 :: 21.07.2015 :: Dr. Alexey Cheptsov OUTLINE About us Convergence of Supercomputing into
: A new version of Supercomputing or life after the end of the Moore s Law Dr.-Ing. Alexey Cheptsov SEMAPRO 2015 :: 21.07.2015 :: Dr. Alexey Cheptsov OUTLINE About us Convergence of Supercomputing into
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University
 RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University (with Nandu Jayakumar, Diego Ongaro, Mendel Rosenblum, Stephen Rumble, and Ryan Stutsman) DRAM in Storage
RAMCloud: Scalable High-Performance Storage Entirely in DRAM John Ousterhout Stanford University (with Nandu Jayakumar, Diego Ongaro, Mendel Rosenblum, Stephen Rumble, and Ryan Stutsman) DRAM in Storage
NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory
 NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory Dhananjoy Das, Sr. Systems Architect SanDisk Corp. 1 Agenda: Applications are KING! Storage landscape (Flash / NVM)
NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory Dhananjoy Das, Sr. Systems Architect SanDisk Corp. 1 Agenda: Applications are KING! Storage landscape (Flash / NVM)
Staged Memory Scheduling
 Staged Memory Scheduling Rachata Ausavarungnirun, Kevin Chang, Lavanya Subramanian, Gabriel H. Loh*, Onur Mutlu Carnegie Mellon University, *AMD Research June 12 th 2012 Executive Summary Observation:
Staged Memory Scheduling Rachata Ausavarungnirun, Kevin Chang, Lavanya Subramanian, Gabriel H. Loh*, Onur Mutlu Carnegie Mellon University, *AMD Research June 12 th 2012 Executive Summary Observation:
Designing High-Performance Non-Volatile Memory-aware RDMA Communication Protocols for Big Data Processing
 Designing High-Performance Non-Volatile Memory-aware RDMA Communication Protocols for Big Data Processing Talk at Storage Developer Conference SNIA 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu
Designing High-Performance Non-Volatile Memory-aware RDMA Communication Protocols for Big Data Processing Talk at Storage Developer Conference SNIA 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu
Middleware and Flash Translation Layer Co-Design for the Performance Boost of Solid-State Drives
 Middleware and Flash Translation Layer Co-Design for the Performance Boost of Solid-State Drives Chao Sun 1, Asuka Arakawa 1, Ayumi Soga 1, Chihiro Matsui 1 and Ken Takeuchi 1 1 Chuo University Santa Clara,
Middleware and Flash Translation Layer Co-Design for the Performance Boost of Solid-State Drives Chao Sun 1, Asuka Arakawa 1, Ayumi Soga 1, Chihiro Matsui 1 and Ken Takeuchi 1 1 Chuo University Santa Clara,
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Survey Paper on Traditional Hadoop and Pipelined Map Reduce
 International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
Row Buffer Locality Aware Caching Policies for Hybrid Memories. HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu
 Row Buffer Locality Aware Caching Policies for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Executive Summary Different memory technologies have different
Row Buffer Locality Aware Caching Policies for Hybrid Memories HanBin Yoon Justin Meza Rachata Ausavarungnirun Rachael Harding Onur Mutlu Executive Summary Different memory technologies have different
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Strata: A Cross Media File System. Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson
 A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Computer Architecture
 Computer Architecture Lecture 1: Introduction and Basics Dr. Ahmed Sallam Suez Canal University Spring 2016 Based on original slides by Prof. Onur Mutlu I Hope You Are Here for This Programming How does
Computer Architecture Lecture 1: Introduction and Basics Dr. Ahmed Sallam Suez Canal University Spring 2016 Based on original slides by Prof. Onur Mutlu I Hope You Are Here for This Programming How does
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
GridGain and Apache Ignite In-Memory Performance with Durability of Disk
 GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading
 Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading Mario Almeida, Liang Wang*, Jeremy Blackburn, Konstantina Papagiannaki, Jon Crowcroft* Telefonica
Diffusing Your Mobile Apps: Extending In-Network Function Virtualisation to Mobile Function Offloading Mario Almeida, Liang Wang*, Jeremy Blackburn, Konstantina Papagiannaki, Jon Crowcroft* Telefonica
Hybrid Memory Platform
 Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Bringing Data to Life
 Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
PRESENTATION TITLE GOES HERE
 Enterprise Storage PRESENTATION TITLE GOES HERE Leah Schoeb, Member of SNIA Technical Council SNIA EmeraldTM Training SNIA Emerald Power Efficiency Measurement Specification, for use in EPA ENERGY STAR
Enterprise Storage PRESENTATION TITLE GOES HERE Leah Schoeb, Member of SNIA Technical Council SNIA EmeraldTM Training SNIA Emerald Power Efficiency Measurement Specification, for use in EPA ENERGY STAR
Datacenter replication solution with quasardb
 Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Datacenter replication solution with quasardb Technical positioning paper April 2017 Release v1.3 www.quasardb.net Contact: sales@quasardb.net Quasardb A datacenter survival guide quasardb INTRODUCTION
Strategic Briefing Paper Big Data
 Strategic Briefing Paper Big Data The promise of Big Data is improved competitiveness, reduced cost and minimized risk by taking better decisions. This requires affordable solution architectures which
Strategic Briefing Paper Big Data The promise of Big Data is improved competitiveness, reduced cost and minimized risk by taking better decisions. This requires affordable solution architectures which
Enabling Cost-effective Data Processing with Smart SSD
 Enabling Cost-effective Data Processing with Smart SSD Yangwook Kang, UC Santa Cruz Yang-suk Kee, Samsung Semiconductor Ethan L. Miller, UC Santa Cruz Chanik Park, Samsung Electronics Efficient Use of
Enabling Cost-effective Data Processing with Smart SSD Yangwook Kang, UC Santa Cruz Yang-suk Kee, Samsung Semiconductor Ethan L. Miller, UC Santa Cruz Chanik Park, Samsung Electronics Efficient Use of
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Software and Tools for HPE s The Machine Project
 Labs Software and Tools for HPE s The Machine Project Scalable Tools Workshop Aug/1 - Aug/4, 2016 Lake Tahoe Milind Chabbi Traditional Computing Paradigm CPU DRAM CPU DRAM CPU-centric computing 2 CPU-Centric
Labs Software and Tools for HPE s The Machine Project Scalable Tools Workshop Aug/1 - Aug/4, 2016 Lake Tahoe Milind Chabbi Traditional Computing Paradigm CPU DRAM CPU DRAM CPU-centric computing 2 CPU-Centric
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Diagnostics in Testing and Performance Engineering
 Diagnostics in Testing and Performance Engineering This document talks about importance of diagnostics in application testing and performance engineering space. Here are some of the diagnostics best practices
Diagnostics in Testing and Performance Engineering This document talks about importance of diagnostics in application testing and performance engineering space. Here are some of the diagnostics best practices
Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers
 Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers 1 ASPLOS 2016 2-6 th April Amro Awad (NC State University) Pratyusa Manadhata (Hewlett Packard Labs) Yan Solihin (NC
Silent Shredder: Zero-Cost Shredding For Secure Non-Volatile Main Memory Controllers 1 ASPLOS 2016 2-6 th April Amro Awad (NC State University) Pratyusa Manadhata (Hewlett Packard Labs) Yan Solihin (NC
Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators
 WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
STORAGE LATENCY x. RAMAC 350 (600 ms) NAND SSD (60 us)
 NAND SSD (60 us)") 1 STORAGE LATENCY 2 RAMAC 350 (600 ms) 1956 10 5 x NAND SSD (60 us) 2016 COMPUTE LATENCY 3 RAMAC 305 (100 Hz) 1956 10 8 x 1000x CORE I7 (1 GHZ) 2016 NON-VOLATILE MEMORY 1000x faster than NAND 3D XPOINT
1 STORAGE LATENCY 2 RAMAC 350 (600 ms) 1956 10 5 x NAND SSD (60 us) 2016 COMPUTE LATENCY 3 RAMAC 305 (100 Hz) 1956 10 8 x 1000x CORE I7 (1 GHZ) 2016 NON-VOLATILE MEMORY 1000x faster than NAND 3D XPOINT
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Software-Defined Data Infrastructure Essentials
 Software-Defined Data Infrastructure Essentials Cloud, Converged, and Virtual Fundamental Server Storage I/O Tradecraft Greg Schulz Server StorageIO @StorageIO 1 of 13 Contents Preface Who Should Read
Software-Defined Data Infrastructure Essentials Cloud, Converged, and Virtual Fundamental Server Storage I/O Tradecraft Greg Schulz Server StorageIO @StorageIO 1 of 13 Contents Preface Who Should Read
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Improved Solutions for I/O Provisioning and Application Acceleration
 1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Improving DRAM Performance by Parallelizing Refreshes with Accesses
 Improving DRAM Performance by Parallelizing Refreshes with Accesses Kevin Chang Donghyuk Lee, Zeshan Chishti, Alaa Alameldeen, Chris Wilkerson, Yoongu Kim, Onur Mutlu Executive Summary DRAM refresh interferes
Improving DRAM Performance by Parallelizing Refreshes with Accesses Kevin Chang Donghyuk Lee, Zeshan Chishti, Alaa Alameldeen, Chris Wilkerson, Yoongu Kim, Onur Mutlu Executive Summary DRAM refresh interferes
Challenges in Data Stream Processing
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Challenges in Data Stream Processing Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Challenges in Data Stream Processing Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio
 CASE STUDY Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio Xueyan Li, Lei Xu, and Xiaoxu Lv Software Engineers at Qunar At Qunar, we have been running Alluxio in production for over
CASE STUDY Qunar Performs Real-Time Data Analytics up to 300x Faster with Alluxio Xueyan Li, Lei Xu, and Xiaoxu Lv Software Engineers at Qunar At Qunar, we have been running Alluxio in production for over
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
IBM System Storage DCS3700
 IBM System Storage DCS3700 Maximize performance, scalability and storage density at an affordable price Highlights Gain fast, highly dense storage capabilities at an affordable price Deliver simplified
IBM System Storage DCS3700 Maximize performance, scalability and storage density at an affordable price Highlights Gain fast, highly dense storage capabilities at an affordable price Deliver simplified
Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data
 Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data Yunhao Zhang, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong University Stream Query
Sub-millisecond Stateful Stream Querying over Fast-evolving Linked Data Yunhao Zhang, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong University Stream Query
Hierarchy of knowledge BIG DATA 9/7/2017. Architecture
 BIG DATA Architecture Hierarchy of knowledge Data: Element (fact, figure, etc.) which is basic information that can be to be based on decisions, reasoning, research and which is treated by the human or
BIG DATA Architecture Hierarchy of knowledge Data: Element (fact, figure, etc.) which is basic information that can be to be based on decisions, reasoning, research and which is treated by the human or
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
CSCI-GA Database Systems Lecture 8: Physical Schema: Storage
 CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
Reducing DRAM Latency at Low Cost by Exploiting Heterogeneity. Donghyuk Lee Carnegie Mellon University
 Reducing DRAM Latency at Low Cost by Exploiting Heterogeneity Donghyuk Lee Carnegie Mellon University Problem: High DRAM Latency processor stalls: waiting for data main memory high latency Major bottleneck
Reducing DRAM Latency at Low Cost by Exploiting Heterogeneity Donghyuk Lee Carnegie Mellon University Problem: High DRAM Latency processor stalls: waiting for data main memory high latency Major bottleneck