Streaming Analytics with Apache Flink. Stephan
|
|
|
- Derrick Stevens
- 6 years ago
- Views:
Transcription




1 Streaming Analytics with Apache Flink Stephan
2 Apache Flink Stack Libraries DataStream API Stream Processing DataSet API Batch Processing Runtime Distributed Streaming Data Flow Streaming and batch as first class citizens. 2
3 Today Libraries DataStream API Stream Processing DataSet API Batch Processing Runtime Distributed Streaming Data Flow Streaming and batch as first class citizens. 3
4 Streaming is the next programming paradigm for data applications, and you need to start thinking in terms of streams. 4
5 Streaming technology is enabling the obvious: continuous processing on data that is continuously produced 5
6 A brief History of Flink January 10 April 14 December 14 March 16 v0.5 v0.6 v0.7 v0.8 v0.9 v0.10 Project Stratosphere (Flink precursor) Flink Project Incubation Top Level Project Release 1.0 6
7 A brief History of Flink The academia gap: Reading/writing papers, teaching, worrying about thesis January 10 April 14 December 14 March 16 v0.5 v0.6 v0.7 v0.8 v0.9 v0.10 Project Stratosphere (Flink precursor) Flink Project Incubation Top Level Project Release 1.0 Realizing this might be interesting to people beyond academia (even more so, actually) 7


8 A Stream Processing Pipeline collect log analyze serve 8
9 Programs and Dataflows val lines: DataStream[String] = env.addsource(new FlinkKafkaConsumer09( )) val events: DataStream[Event] = lines.map((line) => parse(line)) val stats: DataStream[Statistic] = stream.keyby("sensor").timewindow(time.seconds(5)).sum(new MyAggregationFunction()) stats.addsink(new RollingSink(path)) Source Transformation Transformation Sink Source [1] map() [1] keyby()/ window()/ apply() [1] Source [2] map() [2] keyby()/ window()/ apply() [2] Sink [1] Streaming Dataflow 9
10 Why does Flink stream flink? High Throughput Low latency Make more sense of data Well-behaved flow control (back pressure) True Streaming Event Time Works on real-time and historic data Windows & user-defined state Stateful Streaming APIs Libraries Complex Event Processing Exactly-once semantics for fault tolerance Globally consistent savepoints Flexible windows (time, count, session, roll-your own) 10
11 Counting 11

12 Continuous counting A seemingly simple application, but generally an unsolved problem E.g., count visitors, impressions, interactions, clicks, etc Aggregations and OLAP cube operations are generalizations of counting 12
13 Counting in batch architecture Continuous ingestion Periodic (e.g., hourly) files Periodic batch jobs 13
14 Problems with batch architecture High latency Too many moving parts Implicit treatment of time Out of order event handling Implicit batch boundaries 14
15 Counting in λ architecture "Batch layer": what we had before "Stream layer": approximate early results 15
16 Problems with batch and λ Way too many moving parts (and code dup) Implicit treatment of time Out of order event handling Implicit batch boundaries 16
17 Counting in streaming architecture Message queue ensures stream durability and replay Stream processor ensures consistent counting 17
18 Counting in Flink DataStream API Number of visitors in last hour by country DataStream<LogEvent> stream = env.addsource(new FlinkKafkaConsumer(...)) // create stream from Kafka.keyBy("country") // group by country.timewindow(time.minutes(60)) // window of size 1 hour.apply(new CountPerWindowFunction()); // do operations per window 18
,... efficiently on high volume streams,.")
19 Counting hierarchy of needs Based on Maslow's hierarchy of needs... queryable... accurate and repeatable,... fault tolerant (exactly once),... efficiently on high volume streams,... with low latency, Continuous counting 19
20 Counting hierarchy of needs Continuous counting 20
21 Counting hierarchy of needs... with low latency, Continuous counting 21
22 Counting hierarchy of needs... efficiently on high volume streams,... with low latency, Continuous counting 22
23 Counting hierarchy of needs... fault tolerant (exactly once),... efficiently on high volume streams,... with low latency, Continuous counting 23
24 Counting hierarchy of needs... accurate and repeatable,... fault tolerant (exactly once),... efficiently on high volume streams,... with low latency, Continuous counting 24
25 Counting hierarchy of needs queryable... accurate and repeatable,... fault tolerant (exactly once),... efficiently on high volume streams,... with low latency, Continuous counting 25
26 Rest of this talk... queryable... accurate and repeatable,... fault tolerant (exactly once),... efficiently on high volume streams,... with low latency, Continuous counting 26
27 Streaming Analytics by Example 27
28 Time-Windowed Aggregations case class Event(sensor: String, measure: Double) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) stream.keyby("sensor").timewindow(time.seconds(5)).sum("measure") 28
29 Time-Windowed Aggregations case class Event(sensor: String, measure: Double) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) stream.keyby("sensor").timewindow(time.seconds(60), Time.seconds(5)).sum("measure") 29
30 Session-Windowed Aggregations case class Event(sensor: String, measure: Double) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) stream.keyby("sensor").window(eventtimesessionwindows.withgap(time.seconds(60))).max("measure") 30
31 Session-Windowed Aggregations case class Event(sensor: String, measure: Double) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) Flink 1.1 syntax stream.keyby("sensor").window(eventtimesessionwindows.withgap(time.seconds(60))).max("measure") 31
32 Pattern Detection case class Event(producer: String, evttype: Int, msg: String) case class Alert(msg: String) val stream: DataStream[Event] = env.addsource( ) stream.keyby("producer").flatmap(new RichFlatMapFuncion[Event, Alert]() { lazy val state: ValueState[Int] = getruntimecontext.getstate( ) def flatmap(event: Event, out: Collector[Alert]) = { val newstate = state.value() match { case 0 if (event.evttype == 0) => 1 case 1 if (event.evttype == 1) => 0 case x => out.collect(alert(event.msg, x)); 0 } state.update(newstate) } }) 32
33 Pattern Detection case class Event(producer: String, evttype: Int, msg: String) case class Alert(msg: String) val stream: DataStream[Event] = env.addsource( ) stream.keyby("producer").flatmap(new RichFlatMapFuncion[Event, Alert]() { lazy val state: ValueState[Int] = getruntimecontext.getstate( ) def flatmap(event: Event, out: Collector[Alert]) = { val newstate = state.value() match { case 0 if (event.evttype == 0) => 1 case 1 if (event.evttype == 1) => 0 case x => out.collect(alert(event.msg, x)); 0 } state.update(newstate) } }) Embedded key/value state store 33
34 Many more Joining streams (e.g. combine readings from sensor) Detecting Patterns (CEP) Applying (changing) rules or models to events Training and applying online machine learning models 34
35 (It's) About Time 35
36 The biggest change in moving from batch to streaming is handling time explicitly 36
37 Example: Windowing by Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 37
38 Example: Windowing by Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( ) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 38
39 Different Notions of Time Event Producer Message Queue Flink Data Source Flink Window Operator partition 1 partition 2 Event Time Ingestion Time Window Processing Time 39

40 Event Time vs. Processing Time Event Time Episode IV Episode V Episode VI Episode I Episode II Episode III Episode VII Processing Time 40
41 Processing Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(processingtime) val stream: DataStream[Event] = env.addsource( ) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") Window by operator's processing time 41
42 Ingestion Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(ingestiontime) val stream: DataStream[Event] = env.addsource( ) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 42
43 Event Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(eventtime) val stream: DataStream[Event] = env.addsource( ) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 43
44 Event Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(eventtime) val stream: DataStream[Event] = env.addsource( ) val tsstream = stream.assignascendingtimestamps(_.timestamp) tsstream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 44
45 Event Time case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(eventtime) val stream: DataStream[Event] = env.addsource( ) val tsstream = stream.assigntimestampsandwatermarks( new MyTimestampsAndWatermarkGenerator()) tsstream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 45
46 Watermarks Stream (in order) W(20) Watermark W(11) Event timestamp Event Stream (out of order) W(17) W(11) Watermark Event timestamp Event 46
47 Watermarks in Parallel Watermark Event [id timestamp] Q 44 N 39 M 39 Source (1) K 35 W(33) map (1) 29 C 30 B 31 A window (1) 14 Watermark Generation W(17) D 15 Event Time at input streams R 37 O 23 L 22 Source (2) H 20 map (2) 17 G 18 W(17) F 15 E window (2) Event Time at the operator 47
48 Per Kafka Partition Watermarks N 39 L 35 O 97 M Source (1) K 77 W(33) map (1) 29 C 33 B 73 A window (1) 14 Watermark Generation W(17) D 18 Q 23 I 21 T 99 S Source (2) H 94 map (2) 17 G 91 W(17) F 15 E window (2) 48
49 Per Kafka Partition Watermarks val env = StreamExecutionEnvironment.getExecutionEnvironment env.setstreamtimecharacteristic(eventtime) val kafka = new FlinkKafkaConsumer09(topic, schema, props) kafka.assigntimestampsandwatermarks( new MyTimestampsAndWatermarkGenerator()) val stream: DataStream[Event] = env.addsource(kafka) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") 49
50 Matters of State (Fault Tolerance, Reinstatements, etc) 50
51 Back to the Aggregation Example case class Event(id: String, measure: Double, timestamp: Long) val env = StreamExecutionEnvironment.getExecutionEnvironment val stream: DataStream[Event] = env.addsource( new FlinkKafkaConsumer09(topic, schema, properties)) stream.keyby("id").timewindow(time.seconds(15), Time.seconds(5)).sum("measure") Stateful 51
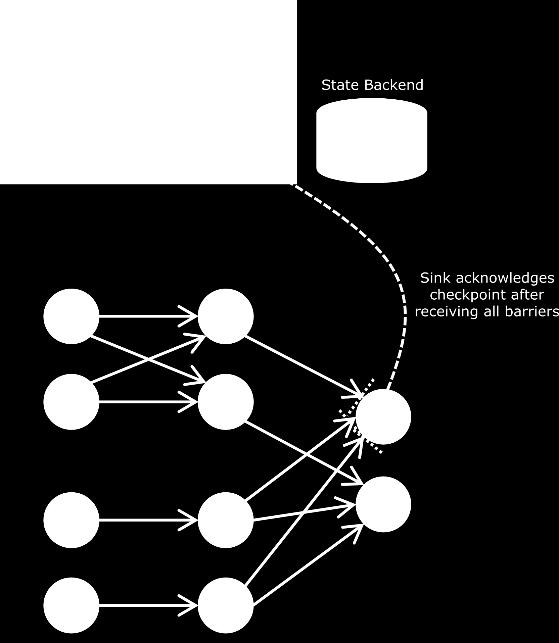
52 Fault Tolerance Prevent data loss (reprocess lost in-flight events) Recover state consistency (exactly-once semantics) Pending windows & user-defined (key/value) state Checkpoint based fault tolerance Periodicaly create checkpoints Recovery: resume from last completed checkpoint Async. Barrier Snapshots (ABS) Algorithm 52
53 Checkpoints newer records data stream older records event State of the dataflow at point Y State of the dataflow at point X 53

54 Checkpoint Barriers Markers, injected into the streams 54
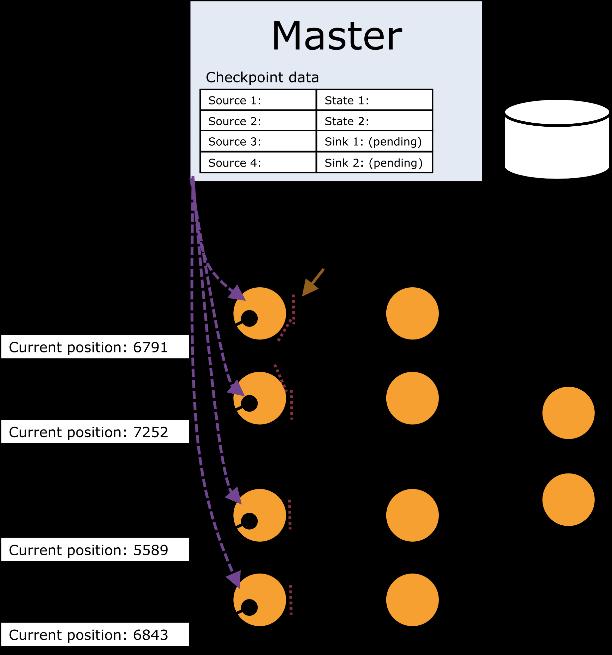
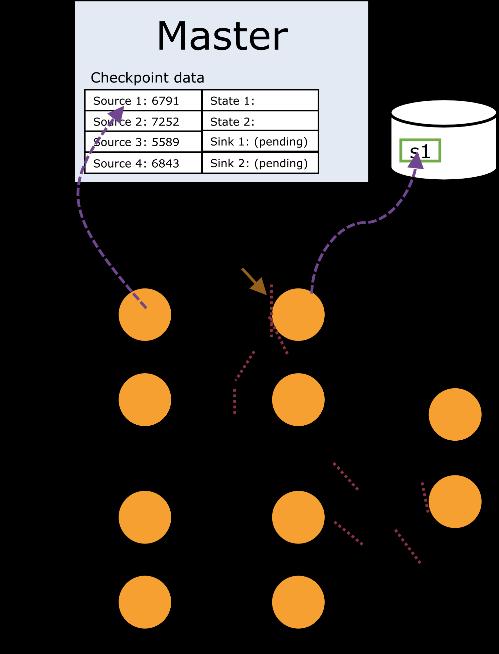
55 Checkpoint Procedure 55
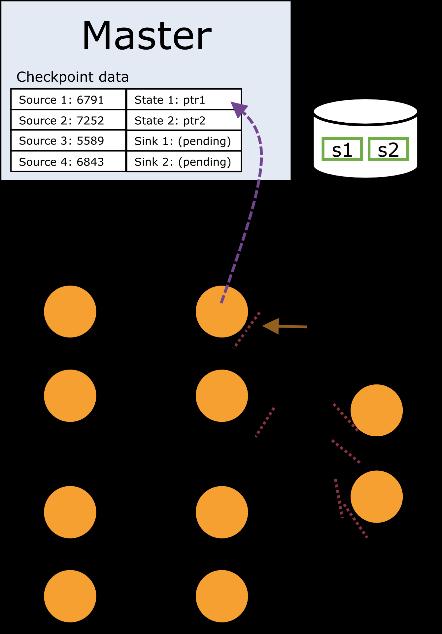
56 Checkpoint Procedure 56
57 Savepoints A "Checkpoint" is a globally consistent point-in-time snapshot of the streaming program (point in stream, state) A "Savepoint" is a user-triggered retained checkpoint Streaming programs can start from a savepoint Savepoint B Savepoint A 57
58 (Re)processing data (in batch) Re-processing data (what-if exploration, to correct bugs, etc.) Usually by running a batch job with a set of old files Tools that map files to times :00 am :00 am :00 am :00pm :00pm :00am :00am Collection of files, by ingestion time To the batch processor 58
59 Unclear Batch Boundaries :00 am :00 am :00 am :00pm :00pm :00am :00am?? What about sessions across batches? To the batch processor 59
60 (Re)processing data (streaming) Draw savepoints at times that you will want to start new jobs from (daily, hourly, ) Reprocess by starting a new job from a savepoint Defines start position in stream (for example Kafka offsets) Initializes pending state (like partial sessions) Run new streaming program from savepoint Savepoint 60
61 Continuous Data Sources partition partition Stream of Kafka Partitions Savepoint Kafka offsets + Operator state WIP (Flink 1.1?) Savepoint File mod timestamp + File position + Operator state :00am :00am :00pm :00pm :00 am :00 am :00 am Stream view over sequence of files 61
62 Upgrading Programs A program starting from a savepoint can differ from the program that created the savepoint Unique operator names match state and operator Mechanism be used to fix bugs in programs, to evolve programs, parameters, libraries, 62
63 State Backends Large state is a collection of key/value pairs State backend defines what data structure holds the state, plus how it is snapshotted Most common choices Main memory snapshots to master Main memory snapshots to dist. filesystem RocksDB snapshots to dist. filesystem 63
64 Complex Event Processing Primer 64
65 Event Types 65
66 Defining Patterns 66
67 Generating Alerts 67
68 Latency and Throughput 68
69 Low Latency and High Throughput Frequently though to be mutually exclusive Event-at-a-time low latency, low throughput Mini batch high latency, high throughput The above is not true! Very little latency has to be sacrificed for very high throughput 69
70 Latency and Throughput 70

71 Latency and Throughput 71
72 The Effect of Buffering Network stack does not always operate in event-at-a-time mode Optional buffering adds some milliseconds latency but increases throughput No effect on application logic 72
73 An Outlook on Things to Come 73
74 Roadmap Dynamic Scaling, Resource Elasticity Stream SQL CEP enhancements Incremental & asynchronous state snapshotting Mesos support More connectors, end-to-end exactly once API enhancements (e.g., joins, slowly changing inputs) Security (data encryption, Kerberos with Kafka) 74
75 I stream*, do you? * beyond Netflix movies 75
76 Why does Flink stream flink? High Throughput Low latency Make more sense of data Well-behaved flow control (back pressure) True Streaming Event Time Works on real-time and historic data Windows & user-defined state Stateful Streaming APIs Libraries Complex Event Processing Exactly-once semantics for fault tolerance Globally consistent savepoints Flexible windows (time, count, session, roll-your own) 76
77 Addendum 77
78 On a technical level Decouple all things Clocks Wall clock time (processing time) Event time (watermarks & punctuations) Consistency clock (logical checkpoint timestamps) Buffering Windows (application logic) Network (throughput tuning) 78
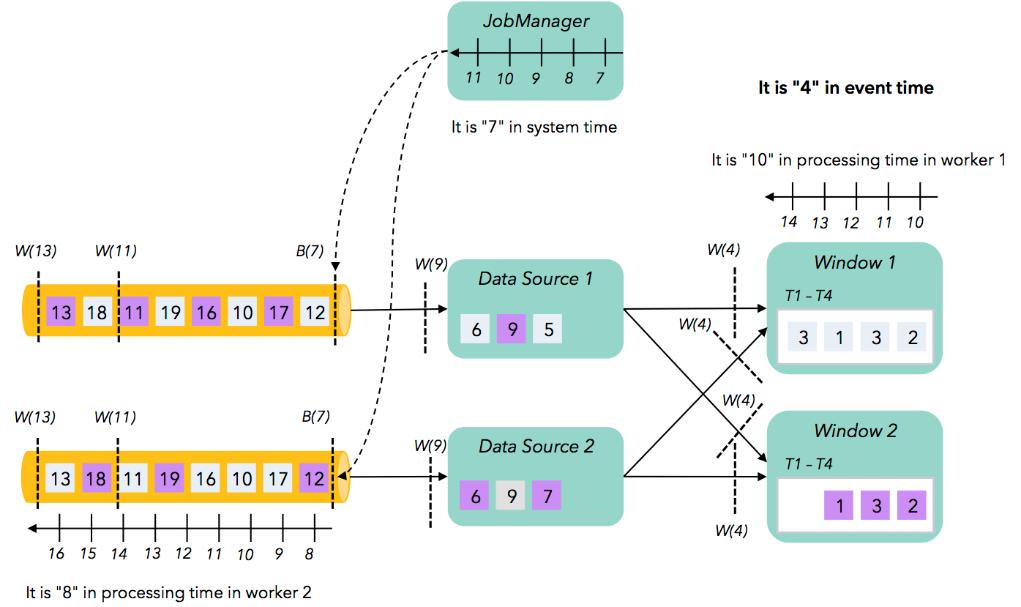
79 Decoupling clocks 79

80 Stream Alignment 80
81 High Availability Checkpoints JobManager Client Apache Zookeeper 1. Take snapshots TaskManagers 81
82 High Availability Checkpoints JobManager Client Apache Zookeeper 1. Take snapshots 2. Persist snapshots 3. Send handles to JM TaskManagers 82
83 High Availability Checkpoints JobManager Client Apache Zookeeper 1. Take snapshots 2. Persist snapshots 3. Send handles to JM 4. Create global checkpoint TaskManagers 83
84 High Availability Checkpoints JobManager Client Apache Zookeeper 1. Take snapshots 2. Persist snapshots 3. Send handles to JM 4. Create global checkpoint 5. Persist global checkpoint TaskManagers 84
85 High Availability Checkpoints JobManager Client Apache Zookeeper 1. Take snapshots 2. Persist snapshots 3. Send handles to JM 4. Create global checkpoint 5. Persist global checkpoint 6. Write handle to ZooKeeper TaskManagers 85
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Power of Snapshots Stateful Stream Processing with Apache Flink
 The Power of Snapshots Stateful Stream Processing with Apache Flink Stephan Ewen QCon San Francisco, 2017 1 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager
The Power of Snapshots Stateful Stream Processing with Apache Flink Stephan Ewen QCon San Francisco, 2017 1 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Apache Flink Streaming Done Right. Till
 Apache Flink Streaming Done Right Till Rohrmann trohrmann@apache.org @stsffap What Is Apache Flink? Apache TLP since December 2014 Parallel streaming data flow runtime Low latency & high throughput Exactly
Apache Flink Streaming Done Right Till Rohrmann trohrmann@apache.org @stsffap What Is Apache Flink? Apache TLP since December 2014 Parallel streaming data flow runtime Low latency & high throughput Exactly
Modern Stream Processing with Apache Flink
 1 Modern Stream Processing with Apache Flink Till Rohrmann GOTO Berlin 2017 2 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager 3 What changes faster? Data
1 Modern Stream Processing with Apache Flink Till Rohrmann GOTO Berlin 2017 2 Original creators of Apache Flink da Platform 2 Open Source Apache Flink + da Application Manager 3 What changes faster? Data
Architecture of Flink's Streaming Runtime. Robert
 Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_
 Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Apache Flink- A System for Batch and Realtime Stream Processing
 Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION
 A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION Konstantin Gregor / konstantin.gregor@tngtech.com ABOUT ME So ware developer for TNG in Munich Client in telecommunication
A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION Konstantin Gregor / konstantin.gregor@tngtech.com ABOUT ME So ware developer for TNG in Munich Client in telecommunication
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Deep Dive into Concepts and Tools for Analyzing Streaming Data
 Deep Dive into Concepts and Tools for Analyzing Streaming Data Dr. Steffen Hausmann Sr. Solutions Architect, Amazon Web Services Data originates in real-time Photo by mountainamoeba https://www.flickr.com/photos/mountainamoeba/2527300028/
Deep Dive into Concepts and Tools for Analyzing Streaming Data Dr. Steffen Hausmann Sr. Solutions Architect, Amazon Web Services Data originates in real-time Photo by mountainamoeba https://www.flickr.com/photos/mountainamoeba/2527300028/
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER
 WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
WHY AND HOW TO LEVERAGE THE POWER AND SIMPLICITY OF SQL ON APACHE FLINK - FABIAN HUESKE, SOFTWARE ENGINEER ABOUT ME Apache Flink PMC member & ASF member Contributing since day 1 at TU Berlin Focusing on
Lecture 21 11/27/2017 Next Lecture: Quiz review & project meetings Streaming & Apache Kafka
 Lecture 21 11/27/2017 Next Lecture: Quiz review & project meetings Streaming & Apache Kafka What problem does Kafka solve? Provides a way to deliver updates about changes in state from one service to another
Lecture 21 11/27/2017 Next Lecture: Quiz review & project meetings Streaming & Apache Kafka What problem does Kafka solve? Provides a way to deliver updates about changes in state from one service to another
Functional Comparison and Performance Evaluation. Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14
 Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Down the event-driven road: Experiences of integrating streaming into analytic data platforms
 Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Using the SDACK Architecture to Build a Big Data Product. Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver
 Apache Big Data NA 2016 Vancouver") Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS
 Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
Personalizing Netflix with Streaming datasets
 Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Using Apache Beam for Batch, Streaming, and Everything in Between. Dan Halperin Apache Beam PMC Senior Software Engineer, Google
 Abstract Apache Beam is a unified programming model capable of expressing a wide variety of both traditional batch and complex streaming use cases. By neatly separating properties of the data from run-time
Abstract Apache Beam is a unified programming model capable of expressing a wide variety of both traditional batch and complex streaming use cases. By neatly separating properties of the data from run-time
data Artisans Streaming Ledger
 data Artisans Streaming Ledger Serializable ACID Transactions on Streaming Data Whitepaper Patent pending in the United States, Europe, and possibly other territories Table of Contents Introduction Streaming
data Artisans Streaming Ledger Serializable ACID Transactions on Streaming Data Whitepaper Patent pending in the United States, Europe, and possibly other territories Table of Contents Introduction Streaming
MEAP Edition Manning Early Access Program Flink in Action Version 2
 MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for
MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for
Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10
 Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Ack per Record Storm* Twitter Heron* Storage
Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Ack per Record Storm* Twitter Heron* Storage
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
Evolution of an Apache Spark Architecture for Processing Game Data
 Evolution of an Apache Spark Architecture for Processing Game Data Nick Afshartous WB Analytics Platform May 17 th 2017 May 17 th, 2017 About Me nafshartous@wbgames.com WB Analytics Core Platform Lead
Evolution of an Apache Spark Architecture for Processing Game Data Nick Afshartous WB Analytics Platform May 17 th 2017 May 17 th, 2017 About Me nafshartous@wbgames.com WB Analytics Core Platform Lead
Streaming Log Analytics with Kafka
 Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Kafka Streams: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
arxiv: v1 [cs.dc] 29 Jun 2015
![arxiv: v1 [cs.dc] 29 Jun 2015](/thumbs/87/95549133.jpg "arxiv: v1 [cs.dc] 29 Jun 2015") Lightweight Asynchronous Snapshots for Distributed Dataflows Paris Carbone 1 Gyula Fóra 2 Stephan Ewen 3 Seif Haridi 1,2 Kostas Tzoumas 3 1 KTH Royal Institute of Technology - {parisc,haridi}@kth.se 2
Lightweight Asynchronous Snapshots for Distributed Dataflows Paris Carbone 1 Gyula Fóra 2 Stephan Ewen 3 Seif Haridi 1,2 Kostas Tzoumas 3 1 KTH Royal Institute of Technology - {parisc,haridi}@kth.se 2
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
@unterstein #bedcon. Operating microservices with Apache Mesos and DC/OS
 @unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
@unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
Deep Dive Amazon Kinesis. Ian Meyers, Principal Solution Architect - Amazon Web Services
 Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Architectural challenges for building a low latency, scalable multi-tenant data warehouse
 Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Distributed ETL. A lightweight, pluggable, and scalable ingestion service for real-time data. Joe Wang
 A lightweight, pluggable, and scalable ingestion service for real-time data ABSTRACT This paper provides the motivation, implementation details, and evaluation of a lightweight distributed extract-transform-load
A lightweight, pluggable, and scalable ingestion service for real-time data ABSTRACT This paper provides the motivation, implementation details, and evaluation of a lightweight distributed extract-transform-load
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Real-time Streaming Applications on AWS Patterns and Use Cases
 Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Dynamically Configured Stream Processing Using Flink & Kafka
 Powering Cloud IT Dynamically Configured Stream Processing Using Flink & Kafka David Hardwick Sean Hester David Brelloch https://github.com/brelloch/flinkforward2017 Multi-SaaS Management What does that
Powering Cloud IT Dynamically Configured Stream Processing Using Flink & Kafka David Hardwick Sean Hester David Brelloch https://github.com/brelloch/flinkforward2017 Multi-SaaS Management What does that
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Introduction to Apache Apex
 Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Introduction to Apache Apex Siyuan Hua @hsy541 PMC Apache Apex, Senior Engineer DataTorrent, Big Data Technology Conference, Beijing, Dec 10 th 2016 Stream Data Processing Data Delivery
Esper EQC. Horizontal Scale-Out for Complex Event Processing
 Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Over the last few years, we have seen a disruption in the data management
 JAYANT SHEKHAR AND AMANDEEP KHURANA Jayant is Principal Solutions Architect at Cloudera working with various large and small companies in various Verticals on their big data and data science use cases,
JAYANT SHEKHAR AND AMANDEEP KHURANA Jayant is Principal Solutions Architect at Cloudera working with various large and small companies in various Verticals on their big data and data science use cases,
Big Data Integration Patterns. Michael Häusler Jun 12, 2017
 Big Data Integration Patterns Michael Häusler Jun 12, 2017 ResearchGate is built for scientists. The social network gives scientists new tools to connect, collaborate, and keep up with the research that
Big Data Integration Patterns Michael Häusler Jun 12, 2017 ResearchGate is built for scientists. The social network gives scientists new tools to connect, collaborate, and keep up with the research that
Building Durable Real-time Data Pipeline
 Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Big Data. Introduction. What is Big Data? Volume, Variety, Velocity, Veracity Subjective? Beyond capability of typical commodity machines
 Agenda Introduction to Big Data, Stream Processing and Machine Learning Apache SAMOA and the Apex Runner Apache Apex and relevant concepts Challenges and Case Study Conclusion with Key Takeaways Big Data
Agenda Introduction to Big Data, Stream Processing and Machine Learning Apache SAMOA and the Apex Runner Apache Apex and relevant concepts Challenges and Case Study Conclusion with Key Takeaways Big Data
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Drizzle: Fast and Adaptable Stream Processing at Scale
 Drizzle: Fast and Adaptable Stream Processing at Scale Shivaram Venkataraman * UC Berkeley Michael Armbrust Databricks Aurojit Panda UC Berkeley Ali Ghodsi Databricks, UC Berkeley Kay Ousterhout UC Berkeley
Drizzle: Fast and Adaptable Stream Processing at Scale Shivaram Venkataraman * UC Berkeley Michael Armbrust Databricks Aurojit Panda UC Berkeley Ali Ghodsi Databricks, UC Berkeley Kay Ousterhout UC Berkeley
Fast and Easy Stream Processing with Hazelcast Jet. Gokhan Oner Hazelcast
 Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Fast and Easy Stream Processing with Hazelcast Jet Gokhan Oner Hazelcast Stream Processing Why should I bother? What is stream processing? Data Processing: Massage the data when moving from place to place.
Naiad (Timely Dataflow) & Streaming Systems
 & Streaming Systems") Naiad (Timely Dataflow) & Streaming Systems CS 848: Models and Applications of Distributed Data Systems Mon, Nov 7th 2016 Amine Mhedhbi What is Timely Dataflow?! What is its significance? Dataflow?! Dataflow?!
Naiad (Timely Dataflow) & Streaming Systems CS 848: Models and Applications of Distributed Data Systems Mon, Nov 7th 2016 Amine Mhedhbi What is Timely Dataflow?! What is its significance? Dataflow?! Dataflow?!
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Time Series Storage with Apache Kudu (incubating)
") Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Implementing the speed layer in a lambda architecture
 Implementing the speed layer in a lambda architecture IT4BI MSc Thesis Student: ERICA BERTUGLI Advisor: FERRAN GALÍ RENIU (TROVIT) Supervisor: OSCAR ROMERO MORAL Master on Information Technologies for
Implementing the speed layer in a lambda architecture IT4BI MSc Thesis Student: ERICA BERTUGLI Advisor: FERRAN GALÍ RENIU (TROVIT) Supervisor: OSCAR ROMERO MORAL Master on Information Technologies for
TOWARDS PORTABILITY AND BEYOND. Maximilian maximilianmichels.com DATA PROCESSING WITH APACHE BEAM
 TOWARDS PORTABILITY AND BEYOND Maximilian Michels mxm@apache.org DATA PROCESSING WITH APACHE BEAM @stadtlegende maximilianmichels.com !2 BEAM VISION Write Pipeline Execute SDKs Runners Backends !3 THE
TOWARDS PORTABILITY AND BEYOND Maximilian Michels mxm@apache.org DATA PROCESSING WITH APACHE BEAM @stadtlegende maximilianmichels.com !2 BEAM VISION Write Pipeline Execute SDKs Runners Backends !3 THE
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Redis as a Reliable Work Queue. Percona University
 Redis as a Reliable Work Queue Percona University 2015-02-12 Introduction Tom DeWire Principal Software Engineer Bronto Software Chris Thunes Senior Software Engineer Bronto Software Introduction Introduction
Redis as a Reliable Work Queue Percona University 2015-02-12 Introduction Tom DeWire Principal Software Engineer Bronto Software Chris Thunes Senior Software Engineer Bronto Software Introduction Introduction
COMPARATIVE EVALUATION OF BIG DATA FRAMEWORKS ON BATCH PROCESSING
 Volume 119 No. 16 2018, 937-948 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ COMPARATIVE EVALUATION OF BIG DATA FRAMEWORKS ON BATCH PROCESSING K.Anusha
Volume 119 No. 16 2018, 937-948 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ COMPARATIVE EVALUATION OF BIG DATA FRAMEWORKS ON BATCH PROCESSING K.Anusha
Scalable Streaming Analytics
 Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE
 DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka. Materna GmbH
 Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka Wer ist Frank Pientka? Dipl.-Informatiker (TH Karlsruhe) Verheiratet, 2 Töchter Principal Software Architect in Dortmund Fast
Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka Wer ist Frank Pientka? Dipl.-Informatiker (TH Karlsruhe) Verheiratet, 2 Töchter Principal Software Architect in Dortmund Fast
Extending Flink s Streaming APIs
 Extending Flink s Streaming APIs Kostas Kloudas @KLOUBEN_K Flink Forward San Francisco April 11, 2017 1 Original creators of Apache Flink Providers of the da Platform, a supported Flink distribution 2
Extending Flink s Streaming APIs Kostas Kloudas @KLOUBEN_K Flink Forward San Francisco April 11, 2017 1 Original creators of Apache Flink Providers of the da Platform, a supported Flink distribution 2
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes
 Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
Apache Ignite and Apache Spark Where Fast Data Meets the IoT
 Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Distributed Data Analytics Stream Processing
 G-3.1.09, Campus III Hasso Plattner Institut Types of Systems Services (online systems) Accept requests and send responses Performance measure: response time and availability Expected runtime: milliseconds
G-3.1.09, Campus III Hasso Plattner Institut Types of Systems Services (online systems) Accept requests and send responses Performance measure: response time and availability Expected runtime: milliseconds
Data Access 3. Managing Apache Hive. Date of Publish:
 3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
Apache Spark Tutorial
 Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
/ Cloud Computing. Recitation 15 December 6 th 2016
 15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
Introduction to Kafka (and why you care)
") Introduction to Kafka (and why you care) Richard Nikula VP, Product Development and Support Nastel Technologies, Inc. 2 Introduction Richard Nikula VP of Product Development and Support Involved in MQ
Introduction to Kafka (and why you care) Richard Nikula VP, Product Development and Support Nastel Technologies, Inc. 2 Introduction Richard Nikula VP of Product Development and Support Involved in MQ
WHITEPAPER. The Lambda Architecture Simplified
 WHITEPAPER The Lambda Architecture Simplified DATE: April 2016 A Brief History of the Lambda Architecture The surest sign you have invented something worthwhile is when several other people invent it too.
WHITEPAPER The Lambda Architecture Simplified DATE: April 2016 A Brief History of the Lambda Architecture The surest sign you have invented something worthwhile is when several other people invent it too.
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's
 Building Agile and Resilient Schema Transformations using Apache Kafka and ESB's Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's Ricardo Ferreira
Building Agile and Resilient Schema Transformations using Apache Kafka and ESB's Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's Ricardo Ferreira
Microservices Lessons Learned From a Startup Perspective
 Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
Container 2.0. Container: check! But what about persistent data, big data or fast data?!
 @unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
@unterstein @joerg_schad @dcos @jaxdevops Container 2.0 Container: check! But what about persistent data, big data or fast data?! 1 Jörg Schad Distributed Systems Engineer @joerg_schad Johannes Unterstein
Outline. INF3190:Distributed Systems - Examples. Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles
 INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
INF3190:Distributed Systems - Examples Thomas Plagemann & Roman Vitenberg Outline Last week: Definitions Transparencies Challenges&pitfalls Architecturalstyles Today: Examples Googel File System (Thomas)
BIG DATA. Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management. Author: Sandesh Deshmane
 BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM
 Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
An Introduction to The Beam Model
 An Introduction to The Beam Model Apache Beam (incubating) Slides by Tyler Akidau & Frances Perry, April 2016 Agenda 1 Infinite, Out-of-order Data Sets 2 The Evolution of the Beam Model 3 What, Where,
An Introduction to The Beam Model Apache Beam (incubating) Slides by Tyler Akidau & Frances Perry, April 2016 Agenda 1 Infinite, Out-of-order Data Sets 2 The Evolution of the Beam Model 3 What, Where,
S-Store: Streaming Meets Transaction Processing
 S-Store: Streaming Meets Transaction Processing H-Store is an experimental database management system (DBMS) designed for online transaction processing applications Manasa Vallamkondu Motivation Reducing
S-Store: Streaming Meets Transaction Processing H-Store is an experimental database management system (DBMS) designed for online transaction processing applications Manasa Vallamkondu Motivation Reducing
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
CS 398 ACC Streaming. Prof. Robert J. Brunner. Ben Congdon Tyler Kim
 CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
Cloudline Autonomous Driving Solutions. Accelerating insights through a new generation of Data and Analytics October, 2018
 Cloudline Autonomous Driving Solutions Accelerating insights through a new generation of Data and Analytics October, 2018 HPE big data analytics solutions power the data-driven enterprise Secure, workload-optimized
Cloudline Autonomous Driving Solutions Accelerating insights through a new generation of Data and Analytics October, 2018 HPE big data analytics solutions power the data-driven enterprise Secure, workload-optimized
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Data pipelines with PostgreSQL & Kafka
 Data pipelines with PostgreSQL & Kafka Oskari Saarenmaa PostgresConf US 2018 - Jersey City Agenda 1. Introduction 2. Data pipelines, old and new 3. Apache Kafka 4. Sample data pipeline with Kafka & PostgreSQL
Data pipelines with PostgreSQL & Kafka Oskari Saarenmaa PostgresConf US 2018 - Jersey City Agenda 1. Introduction 2. Data pipelines, old and new 3. Apache Kafka 4. Sample data pipeline with Kafka & PostgreSQL
Introduction to Apache Beam
 Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
Apache Flink. Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides
 Apache Flink Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides What is Apache Flink Massive parallel data flow engine with unified batch-and streamprocessing CEP
Apache Flink Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides What is Apache Flink Massive parallel data flow engine with unified batch-and streamprocessing CEP
MillWheel:Fault Tolerant Stream Processing at Internet Scale. By FAN Junbo
 MillWheel:Fault Tolerant Stream Processing at Internet Scale By FAN Junbo Introduction MillWheel is a low latency data processing framework designed by Google at Internet scale. Motived by Google Zeitgeist
MillWheel:Fault Tolerant Stream Processing at Internet Scale By FAN Junbo Introduction MillWheel is a low latency data processing framework designed by Google at Internet scale. Motived by Google Zeitgeist
Event Streams using Apache Kafka
 Event Streams using Apache Kafka And how it relates to IBM MQ Andrew Schofield Chief Architect, Event Streams STSM, IBM Messaging, Hursley Park Event-driven systems deliver more engaging customer experiences
Event Streams using Apache Kafka And how it relates to IBM MQ Andrew Schofield Chief Architect, Event Streams STSM, IBM Messaging, Hursley Park Event-driven systems deliver more engaging customer experiences
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum