INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
|
|
|
- Aubrey Alice Bradley
- 5 years ago
- Views:
Transcription
1 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from IR 7: Scores in a Complete Search System Paul Ginsparg Cornell University, Ithaca, NY 17 Sep / 56
2 Discussion 3, week of 22 Sep For this class, read and be prepared to discuss the following: K. Sparck Jones, A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation 28, 11-21, ser/idfpapers/ksj orig.pdf Letter by Stephen Robertson and reply by Karen Sparck Jones, Journal of Documentation 28, , ser/idfpapers/letters.pdf The first paper introduced the term weighting scheme known as inverse document frequency (IDF). Some of the terminology used in this paper will be introduced in the lectures. The letter describes a slightly different way of expressing IDF, which has become the standard form. (Stephen Robertson has mounted these papers on his Web site with permission from the publisher.) 2/ 56
3 Overview 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 3/ 56
4 Outline 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 4/ 56
5 Heaps law log10 M Vocabulary size M as a function of collection size T (number of tokens) for Reuters-RCV1. For these data, the dashed line log 10 M = 0.49 log 10 T is the best least squares fit. Thus, M = T 0.49 and k = and b = M = kt b = 44T log10 T 5/ 56
6 s law Zipf s law: the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, which occurs twice as often as the fourth most frequent word, etc. Brown Corpus: the : 7% of all word occurrences (69,971 of >1M). of : 3.5% of words (36,411) and : 2.9% (28,852) Only 135 vocabulary items account for half the Brown Corpus. The Brown University Standard Corpus of Present-Day American English is a carefully compiled selection of current American English, totaling about a million words drawn from a wide variety of sources... for many years among the most-cited resources in the field. 6/ 56
7 Model collection: The Reuters collection symbol statistic value N documents 800,000 L avg. # word tokens per document 200 M word types 400,000 avg. # bytes per word token (incl. spaces/punct.) 6 avg. # bytes per word token (without spaces/punct.) 4.5 avg. # bytes per word type 7.5 T non-positional postings 100,000,000 1Gb of text sent over Reuters newswire 20 Aug Aug 97 7/ 56
8 Zipf s law for Reuters log10 cf log10 rank 8/ 56
9 Dictionary as a string...syst i lesyzyget icsyzygial syzygyszaibelyi teszecinszono... freq bytes postings ptr. term ptr bytes... 3 bytes 9/ 56
10 Variable byte (VB) code Dedicate 1 bit (high bit) to be a continuation bit c. If the gap G fits within 7 bits, binary-encode it in the 7 available bits and set c = 1. Else: set c = 0, encode high-order 7 bits and then use one or more additional bytes to encode the lower order bits using the same algorithm. 10/ 56
11 Gamma codes for gap encoding Represent a gap G as a pair of length and offset. Offset is the gap in binary, with the leading bit chopped off. For example Length is the length of offset. For 13 (offset 101), this is 3. Encode length in unary code: Gamma code of 13 is the concatenation of length and offset: / 56
12 Compression of Reuters data structure size in MB dictionary, fixed-width 11.2 dictionary, term pointers into string 7.6, with blocking, k = 4 7.1, with blocking & front coding 5.9 collection (text, xml markup etc) collection (text) T/D incidence matrix 40,000.0 postings, uncompressed (32-bit words) postings, uncompressed (20 bits) postings, variable byte encoded postings, γ encoded / 56
13 Outline 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 13/ 56
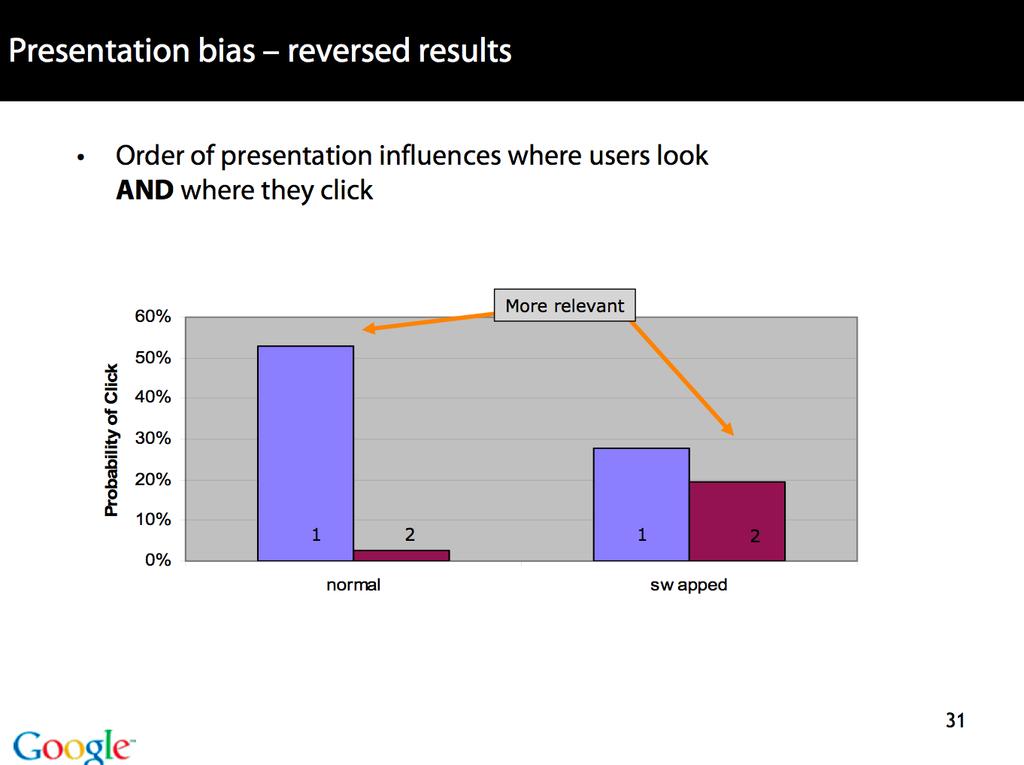
14 Why is ranking so important? Two lectures ago: Problems with unranked retrieval Users want to look at a few results not thousands. It s very hard to write queries that produce a few results. Even for expert searchers Ranking is important because it effectively reduces a large set of results to a very small one. Next: More data on users only look at a few results Actually, in the vast majority of cases they only look at 1, 2, or 3 results. 14/ 56
15 Empirical investigation of the effect of ranking How can we measure how important ranking is? Observe what searchers do when they are searching in a controlled setting Videotape them Ask them to think aloud Interview them Eye-track them Time them Record and count their clicks The following slides are from Dan Russell s JCDL talk 2007 Dan Russell is the Über Tech Lead for Search Quality & User Happiness at Google. 15/ 56
16 Interview video So... Did you notice the FTD official site? To be honest I didn t even look at that. At first I saw from $20 and $20 is what I was looking for. To be honest, 1800-flowers is what I m familiar with and why I went there next even though I kind of assumed they wouldn t have $20 flowers. And you knew they were expensive? I knew they were expensive but I thought hey, maybe they ve got some flowers for under $20 here... But you didn t notice the FTD? No I didn t, actually... that s really funny. 16/ 56

17
18 Local work Granka, L., Joachims, T., and Gay, G. (2004) Eye-Tracking Analysis of User Behavior in WWW Search Proceedings of the 28th Annual ACM Conference on Research and Development in Information and Retrieval (SIGIR 04) etal 04a.pdf 18/ 56

19
20
21
22
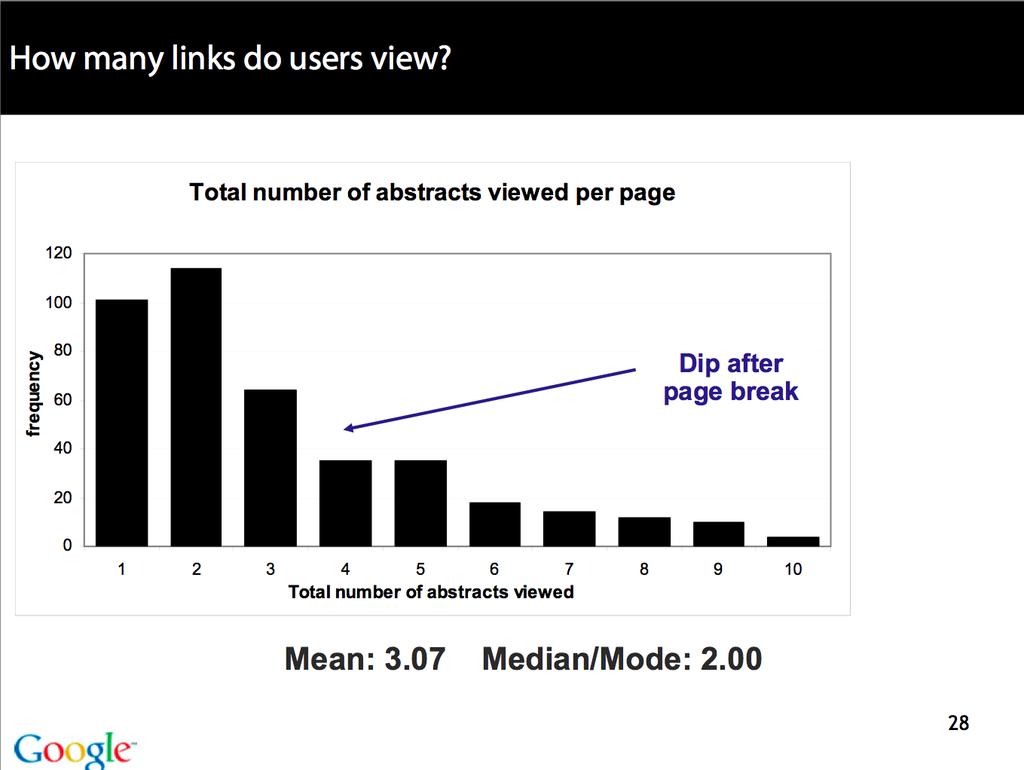
23 Importance of ranking: Summary Viewing abstracts: Users are a lot more likely to read the abstracts of the top-ranked pages (1, 2, 3, 4) than the abstracts of the lower ranked pages (7, 8, 9, 10). Clicking: Distribution is even more skewed for clicking In 1 out of 2 cases, users click on the top-ranked page. Even if the top-ranked page is not relevant, 30% of users will click on it. Getting the ranking right is very important. Getting the top-ranked page right is most important. 23/ 56
24 Outline 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 24/ 56
25 A problem for cosine normalization Query q: anti-doping rules Beijing 2008 olympics Compare three documents d 1 : a short document on anti-doping rules at 2008 Olympics d 2 : a long document that consists of a copy of d 1 and 5 other news stories, all on topics different from Olympics/anti-doping d 3 : a short document on anti-doping rules at the 2004 Athens Olympics What ranking do we expect in the vector space model? d 2 is likely to be ranked below d but d 2 is more relevant than d 3. What can we do about this? 25/ 56
26 Pivot normalization Cosine normalization produces weights that are too large for short documents and too small for long documents (on average). Adjust cosine normalization by linear adjustment: turning the average normalization on the pivot Effect: Similarities of short documents with query decrease; similarities of long documents with query increase. This removes the unfair advantage that short documents have. 26/ 56
27 Predicted and true probability of relevance source: Lillian Lee 27/ 56
28 Pivot normalization source: Lillian Lee 28/ 56
29 Outline 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 29/ 56
30 Now we also need term frequencies in the index Brutus 1,2 7,3 83,1 87,2... Caesar 1,1 5,1 13,1 17,1... Calpurnia 7,1 8,2 40,1 97,3 term frequencies We also need positions. Not shown here. 30/ 56
31 Term frequencies in the inverted index In each posting, store tf t,d in addition to docid d As an integer frequency, not as a (log-)weighted real number......because real numbers are difficult to compress. Unary code is effective for encoding term frequencies. Why? Overall, additional space requirements are small: much less than a byte per posting. 31/ 56
32 How do we compute the top k in ranking? In many applications, we don t need a complete ranking. We just need the top k for a small k (e.g., k = 100). If we don t need a complete ranking, is there an efficient way of computing just the top k? Naive: Compute scores for all N documents Sort Return the top k What s bad about this? Alternative? 32/ 56
33 Use min heap for selecting top k out of N Use a binary min heap A binary min heap is a binary tree in which each node s value is less than the values of its children. Takes O(N log k) operations to construct (where N is the number of documents)......then read off k winners in O(k log k) steps Essentially linear in N for small k and large N. 33/ 56
34 Binary min heap / 56
35 Selecting top k scoring documents in O(N log k) Goal: Keep the top k documents seen so far Use a binary min heap To process a new document d with score s : Get current minimum h m of heap (O(1)) If s h m skip to next document If s > h m heap-delete-root (O(log k)) Heap-add d /s (O(log k)) 35/ 56
36 Even more efficient computation of top k? Ranking has time complexity O(N) where N is the number of documents. Optimizations reduce the constant factor, but they are still O(N) and < N < 10 11! Are there sublinear algorithms? Ideas? What we re doing in effect: solving the k-nearest neighbor (knn) problem for the query vector (= query point). There are no general solutions to this problem that are sublinear. We will revisit when we do knn classification 36/ 56
37 Even more efficient computation of top k Idea 1: Reorder postings lists Instead of ordering according to docid order according to some measure of expected relevance. Idea 2: Heuristics to prune the search space Not guaranteed to be correct but fails rarely. In practice, close to constant time. For this, we ll need the concepts of document-at-a-time processing and term-at-a-time processing. 37/ 56
38 Non-docID ordering of postings lists So far: postings lists have been ordered according to docid. Alternative: a query-independent measure of goodness of a page. Example: PageRank g(d) of page d, a measure of how many good pages hyperlink to d Order documents in postings lists according to PageRank: g(d 1 ) > g(d 2 ) > g(d 3 ) >... Define composite score of a document: net-score(q,d) = g(d) + cos(q,d) This scheme supports early termination: We do not have to process postings lists in their entirety to find top k. 38/ 56
39 Non-docID ordering of postings lists (2) Order documents in postings lists according to PageRank: g(d 1 ) > g(d 2 ) > g(d 3 ) >... Define composite score of a document: net-score(q,d) = g(d) + cos(q,d) Suppose: (i) g [0, 1]; (ii) g(d) < 0.1 for the document d we re currently processing; (iii) smallest top k score we ve found so far is 1.2 Then all subsequent scores will be < 1.1. So we ve already found the top k and can stop processing the remainder of postings lists. Questions? 39/ 56
40 Cluster pruning Cluster docs in preprocessing step Pick N leaders For non-leaders, find nearest leader (expect N / leader) For query q, find closest leader L ( N computations) Rank L and followers or generalize: b 1 closest leaders, and then b 2 leaders closest to query 40/ 56
41 Document-at-a-time processing Both docid-ordering and PageRank-ordering impose a consistent ordering on documents in postings lists. Computing cosines in this scheme is document-at-a-time. We complete computation of the query-document similarity score of document d i before starting to compute the query-document similarity score of d i+1. Alternative: term-at-a-time processing 41/ 56
42 Weight-sorted postings lists Idea: don t process postings that contribute little to final score Order documents in inverted list according to weight Simplest case: normalized tf-idf weight (rarely done: hard to compress) Documents in the top k are likely to occur early in these ordered lists. Early termination while processing inverted lists is unlikely to change the top k. But: We no longer have a consistent ordering of documents in postings lists. We no longer can employ document-at-a-time processing. 42/ 56
43 Term-at-a-time processing Simplest case: completely process the postings list of the first query term Create an accumulator for each docid you encounter Then completely process the postings list of the second query term...and so forth 43/ 56
44 Term-at-a-time processing CosineScore(q) 1 float Scores[N] = 0 2 float Length[N] 3 for each query term t 4 do calculate w t,q and fetch postings list for t 5 for each pair(d,tf t,d ) in postings list 6 do Scores[d]+ = w t,d w t,q 7 Read the array Length 8 for each d 9 do Scores[d] = Scores[d]/Length[d] 10 return Top k components of Scores[] The elements of the array Scores are called accumulators. 44/ 56
45 Computing cosine scores For the web (20 billion documents), an array of accumulators A in memory is infeasible. Thus: Only create accumulators for docs occurring in postings lists This is equivalent to: Do not create accumulators for docs with zero scores (i.e., docs that do not contain any of the query terms) 45/ 56
46 Accumulators Brutus 1,2 7,3 83,1 87,2... Caesar 1,1 5,1 13,1 17,1... Calpurnia 7,1 8,2 40,1 97,3 For query: [Brutus Caesar]: Only need accumulators for 1, 5, 7, 13, 17, 83, 87 Don t need accumulators for 8, 40, 85 46/ 56
47 Removing bottlenecks Use heap / priority queue as discussed earlier Can further limit to docs with non-zero cosines on rare (high idf) words Or enforce conjunctive search (a la Google): non-zero cosines on all words in query Example: just one accumulator for [Brutus Caesar] in the example above......because only d 1 contains both words. 47/ 56
48 Outline 1 Recap 2 Why rank? 3 More on cosine 4 Implementation 5 The complete search system 48/ 56
49 Tiered indexes Basic idea: Create several tiers of indexes, corresponding to importance of indexing terms During query processing, start with highest-tier index If highest-tier index returns at least k (e.g., k = 100) results: stop and return results to user If we ve only found < k hits: repeat for next index in tier cascade Example: two-tier system Tier 1: Index of all titles Tier 2: Index of the rest of documents Pages containing the search words in the title are better hits than pages containing the search words in the body of the text. 49/ 56
50 Tiered index auto Doc2 Tier 1 best car Doc1 Doc3 insurance Doc2 Doc3 auto Tier 2 best Doc1 Doc3 car insurance auto Doc1 Tier 3 best car Doc2 insurance 50/ 56
51 Tiered indexes The use of tiered indexes is believed to be one of the reasons that Google search quality was significantly higher initially (2000/01) than that of competitors. (along with PageRank, use of anchor text and proximity constraints) 51/ 56
52 Exercise Design criteria for tiered system Each tier should be an order of magnitude smaller than the next tier. The top 100 hits for most queries should be in tier 1, the top 100 hits for most of the remaining queries in tier 2 etc. We need a simple test for can I stop at this tier or do I have to go to the next one? There is no advantage to tiering if we have to hit most tiers for most queries anyway. Question 1: Consider a two-tier system where the first tier indexes titles and the second tier everything. What are potential problems with this type of tiering? Question 2: Can you think of a better way of setting up a multitier system? Which zones of a document should be indexed in the different tiers (title, body of document, others?)? What criterion do you want to use for including a document in tier 1? 52/ 56
53 Complete search system 53/ 56
54 Components we have introduced thus far Document preprocessing (linguistic and otherwise) Positional indexes Tiered indexes Spelling correction k-gram indexes for wildcard queries and spelling correction Query processing Document scoring Term-at-a-time processing 54/ 56
55 Components we haven t covered yet Document cache: we need this for generating snippets (= dynamic summaries) Zone indexes: They separate the indexes for different zones: the body of the document, all highlighted text in the document, anchor text, text in metadata fields etc Machine-learned ranking functions Proximity ranking (e.g., rank documents in which the query terms occur in the same local window higher than documents in which the query terms occur far from each other) Query parser 55/ 56
56 Vector space retrieval: Complications How do we combine phrase retrieval with vector space retrieval? We do not want to compute document frequency / idf for every possible phrase. Why? How do we combine Boolean retrieval with vector space retrieval? For example: + -constraints and - -constraints Postfiltering is simple, but can be very inefficient no easy answer. How do we combine wild cards with vector space retrieval? Again, no easy answer 56/ 56
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Administrative. Distributed indexing. Index Compression! What I did last summer lunch talks today. Master. Tasks
 Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Index Compression. David Kauchak cs160 Fall 2009 adapted from:
 Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
ΕΠΛ660. Ανάκτηση µε το µοντέλο διανυσµατικού χώρου
 Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Web Information Retrieval. Lecture 4 Dictionaries, Index Compression
 Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 06 Scoring, Term Weighting and the Vector Space Model 1 Recap of lecture 5 Collection and vocabulary statistics: Heaps and Zipf s laws Dictionary
Information Retrieval Suan Lee - Information Retrieval - 06 Scoring, Term Weighting and the Vector Space Model 1 Recap of lecture 5 Collection and vocabulary statistics: Heaps and Zipf s laws Dictionary
Recap: lecture 2 CS276A Information Retrieval
 Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Introduction to Information Retrieval
 Introduction Inverted index Processing Boolean queries Course overview Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural
Introduction Inverted index Processing Boolean queries Course overview Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural
CS60092: Informa0on Retrieval
 Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Last lecture index construc)on Sort- based indexing Naïve in- memory inversion Blocked Sort- Based Indexing Merge sort is effec)ve for
Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Last lecture index construc)on Sort- based indexing Naïve in- memory inversion Blocked Sort- Based Indexing Merge sort is effec)ve for
Course work. Today. Last lecture index construc)on. Why compression (in general)? Why compression for inverted indexes?
on. Why compression (in general)? Why compression for inverted indexes?") Course work Introduc)on to Informa(on Retrieval Problem set 1 due Thursday Programming exercise 1 will be handed out today CS276: Informa)on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan
Course work Introduc)on to Informa(on Retrieval Problem set 1 due Thursday Programming exercise 1 will be handed out today CS276: Informa)on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan
FRONT CODING. Front-coding: 8automat*a1 e2 ic3 ion. Extra length beyond automat. Encodes automat. Begins to resemble general string compression.
 Sec. 5.2 FRONT CODING Front-coding: Sorted words commonly have long common prefix store differences only (for last k-1 in a block of k) 8automata8automate9automatic10automation 8automat*a1 e2 ic3 ion Encodes
Sec. 5.2 FRONT CODING Front-coding: Sorted words commonly have long common prefix store differences only (for last k-1 in a block of k) 8automata8automate9automatic10automation 8automat*a1 e2 ic3 ion Encodes
Query Answering Using Inverted Indexes
 Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Introduction to Information Retrieval
 Boolean model and Inverted index Processing Boolean queries Why ranked retrieval? Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute
Boolean model and Inverted index Processing Boolean queries Why ranked retrieval? Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute
3-2. Index construction. Most slides were adapted from Stanford CS 276 course and University of Munich IR course.
 3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
Information Retrieval. Lecture 5 - The vector space model. Introduction. Overview. Term weighting. Wintersemester 2007
 Information Retrieval Lecture 5 - The vector space model Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 28 Introduction Boolean model: all documents
Information Retrieval Lecture 5 - The vector space model Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 28 Introduction Boolean model: all documents
Informa(on Retrieval
 Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 8: A complete search system Scoring and results assembly 8 Ch. 6 Last Time: @- idf weighdng The @- idf weight of a term is the product
Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 8: A complete search system Scoring and results assembly 8 Ch. 6 Last Time: @- idf weighdng The @- idf weight of a term is the product
Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency
 Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency Ralf Moeller Hamburg Univ. of Technology Acknowledgement Slides taken from presentation material for the following
Multimedia Information Extraction and Retrieval Term Frequency Inverse Document Frequency Ralf Moeller Hamburg Univ. of Technology Acknowledgement Slides taken from presentation material for the following
Information Retrieval. Lecture 3 - Index compression. Introduction. Overview. Characterization of an index. Wintersemester 2007
 Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Informa(on Retrieval
 Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 7: Scoring, Term Weigh9ng and the Vector Space Model 7 Last Time: Index Compression Collec9on and vocabulary sta9s9cs: Heaps and
Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 7: Scoring, Term Weigh9ng and the Vector Space Model 7 Last Time: Index Compression Collec9on and vocabulary sta9s9cs: Heaps and
Digital Libraries: Language Technologies
 Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
INDEX CONSTRUCTION 1
 1 INDEX CONSTRUCTION PLAN Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden This time: mo among amortize Index construction on
1 INDEX CONSTRUCTION PLAN Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden This time: mo among amortize Index construction on
Information Retrieval
 Information Retrieval Natural Language Processing: Lecture 12 30.11.2017 Kairit Sirts Homework 4 things that seemed to work Bidirectional LSTM instead of unidirectional Change LSTM activation to sigmoid
Information Retrieval Natural Language Processing: Lecture 12 30.11.2017 Kairit Sirts Homework 4 things that seemed to work Bidirectional LSTM instead of unidirectional Change LSTM activation to sigmoid
CSCI 5417 Information Retrieval Systems Jim Martin!
 CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 4 9/1/2011 Today Finish up spelling correction Realistic indexing Block merge Single-pass in memory Distributed indexing Next HW details 1 Query
CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 4 9/1/2011 Today Finish up spelling correction Realistic indexing Block merge Single-pass in memory Distributed indexing Next HW details 1 Query
Introduction to. CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan. Lecture 4: Index Construction
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures
Information Retrieval
 Introduction to CS3245 Lecture 5: Index Construction 5 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize on abandon
Introduction to CS3245 Lecture 5: Index Construction 5 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize on abandon
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
Information Retrieval and Text Mining
 Information Retrieval and Text Mining http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze & Wiltrud Kessler Institute for Natural Language Processing, University of Stuttgart 2012-10-16
Information Retrieval and Text Mining http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze & Wiltrud Kessler Institute for Natural Language Processing, University of Stuttgart 2012-10-16
Introduction to Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Hamid Rastegari Lecture 4: Index Construction Plan Last lecture: Dictionary data structures
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Hamid Rastegari Lecture 4: Index Construction Plan Last lecture: Dictionary data structures
Lecture 5: Information Retrieval using the Vector Space Model
 Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Information Retrieval
 Introduction to CS3245 Lecture 5: Index Construction 5 CS3245 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize
Introduction to CS3245 Lecture 5: Index Construction 5 CS3245 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 1: Boolean Retrieval Paul Ginsparg Cornell University, Ithaca, NY 27 Aug
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 1: Boolean Retrieval Paul Ginsparg Cornell University, Ithaca, NY 27 Aug
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
COMP6237 Data Mining Searching and Ranking
 COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Vector Space Scoring Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Spamming indices This was invented
Vector Space Scoring Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Spamming indices This was invented
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling
 EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
CS347. Lecture 2 April 9, Prabhakar Raghavan
 CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Information Retrieval
 Introduction to Information Retrieval Boolean retrieval Basic assumptions of Information Retrieval Collection: Fixed set of documents Goal: Retrieve documents with information that is relevant to the user
Introduction to Information Retrieval Boolean retrieval Basic assumptions of Information Retrieval Collection: Fixed set of documents Goal: Retrieve documents with information that is relevant to the user
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries
 Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Information Retrieval
 Introduction to Information Retrieval Information Retrieval and Web Search Lecture 1: Introduction and Boolean retrieval Outline ❶ Course details ❷ Information retrieval ❸ Boolean retrieval 2 Course details
Introduction to Information Retrieval Information Retrieval and Web Search Lecture 1: Introduction and Boolean retrieval Outline ❶ Course details ❷ Information retrieval ❸ Boolean retrieval 2 Course details
Today s topics CS347. Inverted index storage. Inverted index storage. Processing Boolean queries. Lecture 2 April 9, 2001 Prabhakar Raghavan
 Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
CSE 7/5337: Information Retrieval and Web Search Introduction and Boolean Retrieval (IIR 1)
") CSE 7/5337: Information Retrieval and Web Search Introduction and Boolean Retrieval (IIR 1) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze
CSE 7/5337: Information Retrieval and Web Search Introduction and Boolean Retrieval (IIR 1) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze
Information Retrieval CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Index Construction. Slides by Manning, Raghavan, Schutze
 Introduction to Information Retrieval ΕΠΛ660 Ανάκτηση Πληροφοριών και Μηχανές Αναζήτησης ης Index Construction ti Introduction to Information Retrieval Plan Last lecture: Dictionary data structures Tolerant
Introduction to Information Retrieval ΕΠΛ660 Ανάκτηση Πληροφοριών και Μηχανές Αναζήτησης ης Index Construction ti Introduction to Information Retrieval Plan Last lecture: Dictionary data structures Tolerant
Index Construction 1
 Index Construction 1 October, 2009 1 Vorlage: Folien von M. Schütze 1 von 43 Index Construction Hardware basics Many design decisions in information retrieval are based on hardware constraints. We begin
Index Construction 1 October, 2009 1 Vorlage: Folien von M. Schütze 1 von 43 Index Construction Hardware basics Many design decisions in information retrieval are based on hardware constraints. We begin
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
This lecture: IIR Sections Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring
 This lecture: IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring 1 Ch. 6 Ranked retrieval Thus far, our queries have all
This lecture: IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring 1 Ch. 6 Ranked retrieval Thus far, our queries have all
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze, Christina Lioma Institute for Natural Language Processing, University of Stuttgart 2010-05-04
Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze, Christina Lioma Institute for Natural Language Processing, University of Stuttgart 2010-05-04
Lecture 3 Index Construction and Compression. Many thanks to Prabhakar Raghavan for sharing most content from the following slides
 Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-05-03 1/ 36 Take-away
Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-05-03 1/ 36 Take-away
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
Part 2: Boolean Retrieval Francesco Ricci
 Part 2: Boolean Retrieval Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content p Term document matrix p Information
Part 2: Boolean Retrieval Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content p Term document matrix p Information
Models for Document & Query Representation. Ziawasch Abedjan
 Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Boolean Model. Hongning Wang
 Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
index construct Overview Overview Recap How to construct index? Introduction Index construction Introduction to Recap
 to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-09 Schütze: Boolean
Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-09 Schütze: Boolean
CS6200 Information Retrieval. David Smith College of Computer and Information Science Northeastern University
 CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 2: Boolean retrieval 2 Blanks on slides, you may want to fill in Last Time: Ngram Language Models Unigram LM: Bag of words Ngram
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 2: Boolean retrieval 2 Blanks on slides, you may want to fill in Last Time: Ngram Language Models Unigram LM: Bag of words Ngram
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Introduc)on to. CS60092: Informa0on Retrieval
on to. CS60092: Informa0on Retrieval") Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 01 Boolean Retrieval Example IR Problem Let s look at a simple IR problem Suppose you own a copy of Shakespeare
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2016/17 IR Chapter 01 Boolean Retrieval Example IR Problem Let s look at a simple IR problem Suppose you own a copy of Shakespeare
Boolean Retrieval. Manning, Raghavan and Schütze, Chapter 1. Daniël de Kok
 Boolean Retrieval Manning, Raghavan and Schütze, Chapter 1 Daniël de Kok Boolean query model Pose a query as a boolean query: Terms Operations: AND, OR, NOT Example: Brutus AND Caesar AND NOT Calpuria
Boolean Retrieval Manning, Raghavan and Schütze, Chapter 1 Daniël de Kok Boolean query model Pose a query as a boolean query: Terms Operations: AND, OR, NOT Example: Brutus AND Caesar AND NOT Calpuria
V.2 Index Compression
 V.2 Index Compression Heap s law (empirically observed and postulated): Size of the vocabulary (distinct terms) in a corpus E[ distinct terms in corpus] n with total number of term occurrences n, and constants,
V.2 Index Compression Heap s law (empirically observed and postulated): Size of the vocabulary (distinct terms) in a corpus E[ distinct terms in corpus] n with total number of term occurrences n, and constants,
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Fall CS646: Information Retrieval. Lecture 2 - Introduction to Search Result Ranking. Jiepu Jiang University of Massachusetts Amherst 2016/09/12
 Fall 2016 CS646: Information Retrieval Lecture 2 - Introduction to Search Result Ranking Jiepu Jiang University of Massachusetts Amherst 2016/09/12 More course information Programming Prerequisites Proficiency
Fall 2016 CS646: Information Retrieval Lecture 2 - Introduction to Search Result Ranking Jiepu Jiang University of Massachusetts Amherst 2016/09/12 More course information Programming Prerequisites Proficiency
Informa(on Retrieval
 Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 7: Scoring, Term Weigh9ng and the Vector Space Model 7 Last Time: Index Construc9on Sort- based indexing Blocked Sort- Based Indexing
Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 7: Scoring, Term Weigh9ng and the Vector Space Model 7 Last Time: Index Construc9on Sort- based indexing Blocked Sort- Based Indexing
Indexing. CS6200: Information Retrieval. Index Construction. Slides by: Jesse Anderton
 Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Outline of the course
 Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Information Retrieval
 Introduction to Information Retrieval Lecture 6-: Scoring, Term Weighting Outline Why ranked retrieval? Term frequency tf-idf weighting 2 Ranked retrieval Thus far, our queries have all been Boolean. Documents
Introduction to Information Retrieval Lecture 6-: Scoring, Term Weighting Outline Why ranked retrieval? Term frequency tf-idf weighting 2 Ranked retrieval Thus far, our queries have all been Boolean. Documents
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology
 Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2013 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2013 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 8: Evaluation & Result Summaries Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-05-07
Introduction to Information Retrieval http://informationretrieval.org IIR 8: Evaluation & Result Summaries Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-05-07
Recap of the previous lecture. This lecture. A naïve dictionary. Introduction to Information Retrieval. Dictionary data structures Tolerant retrieval
 Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
60-538: Information Retrieval
 60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 Schütze:
Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 Schütze:
Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology
 Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan lectures
Boolean retrieval & basics of indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan lectures
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December ISSN Web Search Engine
 International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
Information Retrieval
 Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval 1 Outline Dictionaries Wildcard queries skip Edit distance skip Spelling correction skip Soundex 2 Inverted index Our
Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval 1 Outline Dictionaries Wildcard queries skip Edit distance skip Spelling correction skip Soundex 2 Inverted index Our
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
More on indexing CE-324: Modern Information Retrieval Sharif University of Technology
 More on indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Plan
More on indexing CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Plan
boolean queries Inverted index query processing Query optimization boolean model September 9, / 39
 boolean model September 9, 2014 1 / 39 Outline 1 boolean queries 2 3 4 2 / 39 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
boolean model September 9, 2014 1 / 39 Outline 1 boolean queries 2 3 4 2 / 39 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
Efficiency vs. Effectiveness in Terabyte-Scale IR
 Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
CS105 Introduction to Information Retrieval
 CS105 Introduction to Information Retrieval Lecture: Yang Mu UMass Boston Slides are modified from: http://www.stanford.edu/class/cs276/ Information Retrieval Information Retrieval (IR) is finding material
CS105 Introduction to Information Retrieval Lecture: Yang Mu UMass Boston Slides are modified from: http://www.stanford.edu/class/cs276/ Information Retrieval Information Retrieval (IR) is finding material
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2008.04.22 Schütze: Boolean
Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2008.04.22 Schütze: Boolean