Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
|
|
|
- Beverly Webb
- 6 years ago
- Views:
Transcription
1 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1
2 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing Query Multimedia documents Crawler 2
3 Indexing by similarity Indexing by terms 3


4 Indexing by similarity Indexing by terms 4
5 Text based inverted file index docid weight multimedia pos 2,56,890 1,89,456 4,5,6 Terms dictionary search engines index crawler ranking inverted-file docid weight pos 64,75 4,543,234 23,545 docid... weight pos... Posting lists 5


6 Index construction How to compute the dictionary? How to compute the posting lists? How to index billions of documents? 6
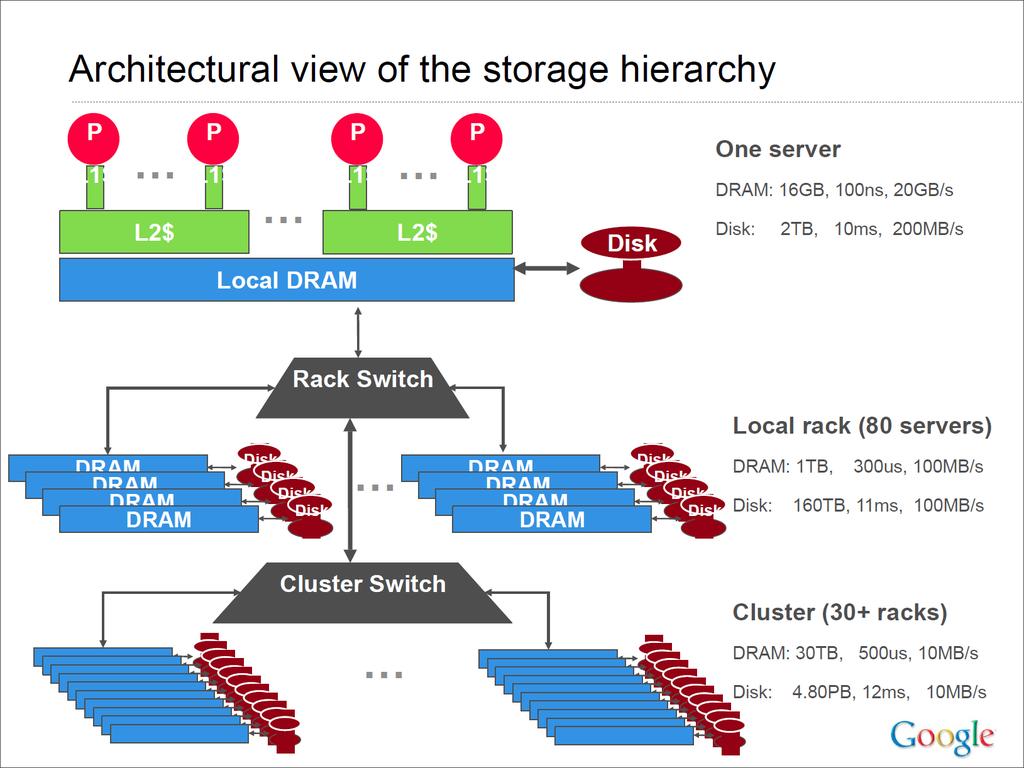
7 10

8 Some numbers 11
9 Text based inverted file index docid weight multimedia pos 2,56,890 1,89,456 4,5,6 Terms dictionary search engines index crawler ranking inverted-file docid weight pos 64,75 4,543,234 23,545 docid... weight pos... 12
10 Sort-based index construction Sec. 4.2 As we build the index, we parse docs one at a time. The final postings for any term are incomplete until the end. At 12 bytes per non-positional postings entry (term, doc, freq), demands a lot of space for large collections. T = 100,000,000 in the case of RCV1 So we can do this in memory now, but typical collections are much larger. E.g. the New York Times provides an index of >150 years of newswire Thus: We need to store intermediate results on disk. 13
11 Use the same algorithm for disk? Sec. 4.2 Can we use the same index construction algorithm for larger collections, but by using disk instead of memory? No: Sorting T = 100,000,000 records on disk is too slow too many disk seeks. => We need an external sorting algorithm. 14
12 BSBI: Blocked sort-based Indexing Sec byte (4+4+4) records (term, doc, freq). These are generated as we parse docs. Must now sort 100M such 12-byte records by term. Define a Block ~ 10M such records Can easily fit a couple into memory. Will have 10 such blocks to start with. Basic idea of algorithm: Compute postings dictionary Accumulate postings for each block, sort, write to disk. Then merge the blocks into one long sorted order. 15
13 Sec
14 Sorting 10 blocks of 10M records Sec. 4.2 First, read each block and sort within: Quicksort takes 2N ln N expected steps In our case 2 x (10M ln 10M) steps 10 times this estimate gives us 10 sorted runs of 10M records each. Done straightforwardly, need 2 copies of data on disk But can optimize this 17
15 BSBI: Blocked sort-based Indexing Sec. 4.2 Notes: 4: Parse and accumulate all termid-docid pairs 5: Collect all termid-docid with the same termid into the same postings list 7: Opens all blocks and keep a small reading buffer for each block. Merge into the final file. (Avoid seeks, read/write sequentially) 18
16 How to merge the sorted runs? Sec. 4.2 Can do binary merges, with a merge tree of log 2 10 = 4 layers. During each layer, read into memory runs in blocks of 10M, merge, write back Merged run. Runs being merged. Disk 4 19

17 Dictionary The size of document collections exposes many poor software designs The distributed scale also exposes such design flaws The choice of the data-structures has great impact on overall system performance To hash or not to hash? The small look-up table of the Shakespeare collection is so small that it fits in the CPU cache. What about wildcard queries? 20
18 Lookup table construction strategies Insight: 90% of terms occur only 1 time Insert at the back Insert terms at the back of the chain as they occur in the collection, i.e., frequent terms occur first, hence they will be at the front of the chain Move to the front: Move to the front of the chain the last acessed term. 21

19 Indexing time dictionary The bulk of the dictionary s lookup load stems from a rather small set of very frequent terms. In a hashtable, those terms should be at the front of the chains 22
20 Remaining problem with sort-based algorithm Our assumption was: we can keep the dictionary in memory. We need the dictionary (which grows dynamically) in order to implement a term to termid mapping. Actually, we could work with term,docid postings instead of termid,docid postings but then intermediate files become very large. (We would end up with a scalable, but very slow index construction method.) 23
21 SPIMI: Single-pass in-memory indexing Key idea 1: Generate separate dictionaries for each block no need to maintain term-termid mapping across blocks. Key idea 2: Don t sort. Accumulate postings in postings lists as they occur. With these two ideas we can generate a complete inverted index for each block. These separate indexes can then be merged into one big index. 24
22 SPIMI-Invert Sec
23 Experimental comparison The index construction is mainly influenced by the available memory Each part of the indexing process is affected differently Parsing Index inversion Indexes merging For web-scale indexing must use a distributed computing cluster How do we exploit such a pool of machines? 26
24 Distributed document parsing Sec. 4.4 Maintain a master machine directing the indexing job. Break up indexing into sets of parallel tasks: Parsers Inverters Break the input document collection into splits Each split is a subset of documents (corresponding to blocks in BSBI/SPIMI) Master machine assigns each task to an idle machine from a pool. 27
25 Parallel tasks Sec. 4.4 Parsers Master assigns a split to an idle parser machine Parser reads a document at a time and emits (term, doc) pairs Parser writes pairs into j partitions Each partition is for a range of terms first letters (e.g., a-f, g-p, q-z) here j = 3. Now to complete the index inversion Inverters An inverter collects all (term,doc) pairs (= postings) for one term-partition. Sorts and writes to postings lists 28
26 Data flow Sec. 4.4 assign Master assign Postings Parser a-f g-p q-z Inverter a-f Parser a-f g-p q-z Inverter g-p splits Parser a-f g-p q-z Inverter q-z Map phase Segment files Reduce phase 29
27 MapReduce Sec. 4.4 The index construction algorithm we just described is an instance of MapReduce. MapReduce (Dean and Ghemawat 2004) is a robust and conceptually simple framework for distributed computing without having to write code for the distribution part. They describe the Google indexing system (ca. 2002) as consisting of a number of phases, each implemented in MapReduce. 30
 Estimate: Google installs 100,000 servers each quarter.")
28 Google data centers Sec. 4.4 Google data centers mainly contain commodity machines. Data centers are distributed around the world. Estimate: a total of 1 million servers, 3 million processors/cores (Gartner 2007) Estimate: Google installs 100,000 servers each quarter. Based on expenditures of million dollars per year This would be 10% of the computing capacity of the world!?! 31
29 32
30 Dynamic indexing Sec. 4.5 Up to now, we have assumed that collections are static. They rarely are: Documents come in over time and need to be inserted. Documents are deleted and modified. This means that the dictionary and postings lists have to be modified: Postings updates for terms already in dictionary New terms added to dictionary 33
31 Simplest approach Sec. 4.5 Maintain big main index New docs go into small auxiliary index Search across both, merge results Deletions Invalidation bit-vector for deleted docs Filter docs output on a search result by this invalidation bit-vector Periodically, re-index into one main index 34
32 Issues with main and auxiliary indexes Sec. 4.5 Problem of frequent merges you touch stuff a lot Poor performance during merge Actually: Merging of the auxiliary index into the main index is efficient if we keep a separate file for each postings list. Merge is the same as a simple append. But then we would need a lot of files inefficient for O/S. Assumption for the rest of the lecture: The index is one big file. In reality: Use a scheme somewhere in between (e.g., split very large postings lists, collect postings lists of length 1 in one file etc.) 35
33 Logarithmic merge Sec. 4.5 Maintain a series of indexes, each twice as large as the previous one. Keep smallest (Z 0 ) in memory Larger ones (I 0, I 1, ) on disk If Z 0 gets too big (> n), write to disk as I 0 or merge with I 0 (if I 0 already exists) as Z 1 Either write merge Z 1 to disk as I 1 (if no I 1 ) Or merge with I 1 to form Z 2 etc. 36
34 Sec
35 Logarithmic merge Sec. 4.5 Auxiliary and main index: index construction time is O(T 2 ) as each posting is touched in each merge. Logarithmic merge: Each posting is merged O(log T) times, so complexity is O(T log T) So logarithmic merge is much more efficient for index construction But query processing now requires the merging of O(log T) indexes Whereas it is O(1) if you just have a main and auxiliary index 38
36 Further issues with multiple indexes Sec. 4.5 Collection-wide statistics are hard to maintain E.g., when we spoke of spell-correction: which of several corrected alternatives do we present to the user? We said, pick the one with the most hits How do we maintain the top ones with multiple indexes and invalidation bit vectors? One possibility: ignore everything but the main index for such ordering Will see more such statistics used in results ranking 39
37 Dynamic indexing at search engines All the large search engines now do dynamic indexing Their indices have frequent incremental changes News items, blogs, new topical web pages Sarah Palin, Sec. 4.5 But (sometimes/typically) they also periodically reconstruct the index from scratch Query processing is then switched to the new index, and the old index is then deleted 40
 Chapter 4")

38 Summary Indexing Dictionary data structures Scalable indexing (BSBI, SPIMI) Chapter 4 Distributed document parsing Dynamic indexing Chapter 4 (dictionary data structures) 41
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
3-2. Index construction. Most slides were adapted from Stanford CS 276 course and University of Munich IR course.
 3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
index construct Overview Overview Recap How to construct index? Introduction Index construction Introduction to Recap
 to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to. CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan. Lecture 4: Index Construction
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures
Index Construction 1
 Index Construction 1 October, 2009 1 Vorlage: Folien von M. Schütze 1 von 43 Index Construction Hardware basics Many design decisions in information retrieval are based on hardware constraints. We begin
Index Construction 1 October, 2009 1 Vorlage: Folien von M. Schütze 1 von 43 Index Construction Hardware basics Many design decisions in information retrieval are based on hardware constraints. We begin
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Introduction to Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Hamid Rastegari Lecture 4: Index Construction Plan Last lecture: Dictionary data structures
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Hamid Rastegari Lecture 4: Index Construction Plan Last lecture: Dictionary data structures
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
CSCI 5417 Information Retrieval Systems Jim Martin!
 CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 4 9/1/2011 Today Finish up spelling correction Realistic indexing Block merge Single-pass in memory Distributed indexing Next HW details 1 Query
CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 4 9/1/2011 Today Finish up spelling correction Realistic indexing Block merge Single-pass in memory Distributed indexing Next HW details 1 Query
Introduc)on to. CS60092: Informa0on Retrieval
on to. CS60092: Informa0on Retrieval") Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Index Construction. Slides by Manning, Raghavan, Schutze
 Introduction to Information Retrieval ΕΠΛ660 Ανάκτηση Πληροφοριών και Μηχανές Αναζήτησης ης Index Construction ti Introduction to Information Retrieval Plan Last lecture: Dictionary data structures Tolerant
Introduction to Information Retrieval ΕΠΛ660 Ανάκτηση Πληροφοριών και Μηχανές Αναζήτησης ης Index Construction ti Introduction to Information Retrieval Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval
 Introduction to CS3245 Lecture 5: Index Construction 5 CS3245 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize
Introduction to CS3245 Lecture 5: Index Construction 5 CS3245 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Information Retrieval
 Introduction to CS3245 Lecture 5: Index Construction 5 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize on abandon
Introduction to CS3245 Lecture 5: Index Construction 5 Last Time Dictionary data structures Tolerant retrieval Wildcards Spelling correction Soundex a-hu hy-m n-z $m mace madden mo among amortize on abandon
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 4: Index Construc*on Plan Last lecture: Dic*onary data structures Tolerant retrieval
Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 4: Index Construc*on Plan Last lecture: Dic*onary data structures Tolerant retrieval
Information Retrieval and Organisation
 Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Information Retrieval and Organisation Dell Zhang Birkbeck, University of London 2015/16 IR Chapter 04 Index Construction Hardware In this chapter we will look at how to construct an inverted index Many
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze, Christina Lioma Institute for Natural Language Processing, University of Stuttgart 2010-05-04
Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze, Christina Lioma Institute for Natural Language Processing, University of Stuttgart 2010-05-04
INDEX CONSTRUCTION 1
 1 INDEX CONSTRUCTION PLAN Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden This time: mo among amortize Index construction on
1 INDEX CONSTRUCTION PLAN Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden This time: mo among amortize Index construction on
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 Schütze:
Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 Schütze:
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 1/54 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 4: Index Construction Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-16 1/54 Overview
CSE 7/5337: Information Retrieval and Web Search Index construction (IIR 4)
") CSE 7/5337: Information Retrieval and Web Search Index construction (IIR 4) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for Natural
CSE 7/5337: Information Retrieval and Web Search Index construction (IIR 4) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for Natural
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 4: Index construction Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 4: Index construction Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Document Representation : Quiz
 Document Representation : Quiz Q1. In-memory Index construction faces following problems:. (A) Scaling problem (B) The optimal use of Hardware resources for scaling (C) Easily keep entire data into main
Document Representation : Quiz Q1. In-memory Index construction faces following problems:. (A) Scaling problem (B) The optimal use of Hardware resources for scaling (C) Easily keep entire data into main
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling
 EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
Lecture 3 Index Construction and Compression. Many thanks to Prabhakar Raghavan for sharing most content from the following slides
 Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Administrative. Distributed indexing. Index Compression! What I did last summer lunch talks today. Master. Tasks
 Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Index Construction Introduction to Information Retrieval INF 141 Donald J. Patterson
 Index Construction Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Index Construction Overview Introduction Hardware
Index Construction Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Index Construction Overview Introduction Hardware
Index Construction Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Index Construction Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Index Construction Overview Introduction
Index Construction Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Index Construction Overview Introduction
Index construc-on. Friday, 8 April 16 1
 Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.3 Single-pass
Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.3 Single-pass
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Building an Inverted Index
 Building an Inverted Index Algorithms Memory-based Disk-based (Sort-Inversion) Sorting Merging (2-way; multi-way) 2 Memory-based Inverted Index Phase I (parse and read) For each document Identify distinct
Building an Inverted Index Algorithms Memory-based Disk-based (Sort-Inversion) Sorting Merging (2-way; multi-way) 2 Memory-based Inverted Index Phase I (parse and read) For each document Identify distinct
Reuters collection example (approximate # s)
") BSBI Reuters collection example (approximate # s) 800,000 documents from the Reuters news feed 200 terms per document 400,000 unique terms number of postings 100,000,000 BSBI Reuters collection example
BSBI Reuters collection example (approximate # s) 800,000 documents from the Reuters news feed 200 terms per document 400,000 unique terms number of postings 100,000,000 BSBI Reuters collection example
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
MapReduce: Simplified Data Processing on Large Clusters. By Stephen Cardina
 MapReduce: Simplified Data Processing on Large Clusters By Stephen Cardina The Problem You have a large amount of raw data, such as a database or a web log, and you need to get some sort of derived data
MapReduce: Simplified Data Processing on Large Clusters By Stephen Cardina The Problem You have a large amount of raw data, such as a database or a web log, and you need to get some sort of derived data
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
PS2 out today. Lab 2 out today. Lab 1 due today - how was it?
 6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
Information Retrieval. Danushka Bollegala
 Information Retrieval Danushka Bollegala Anatomy of a Search Engine Document Indexing Query Processing Search Index Results Ranking 2 Document Processing Format detection Plain text, PDF, PPT, Text extraction
Information Retrieval Danushka Bollegala Anatomy of a Search Engine Document Indexing Query Processing Search Index Results Ranking 2 Document Processing Format detection Plain text, PDF, PPT, Text extraction
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Memory Management. Dr. Yingwu Zhu
 Memory Management Dr. Yingwu Zhu Big picture Main memory is a resource A process/thread is being executing, the instructions & data must be in memory Assumption: Main memory is infinite Allocation of memory
Memory Management Dr. Yingwu Zhu Big picture Main memory is a resource A process/thread is being executing, the instructions & data must be in memory Assumption: Main memory is infinite Allocation of memory
Advanced Database Systems
 Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
16 Sharing Main Memory Segmentation and Paging
 Operating Systems 64 16 Sharing Main Memory Segmentation and Paging Readings for this topic: Anderson/Dahlin Chapter 8 9; Siberschatz/Galvin Chapter 8 9 Simple uniprogramming with a single segment per
Operating Systems 64 16 Sharing Main Memory Segmentation and Paging Readings for this topic: Anderson/Dahlin Chapter 8 9; Siberschatz/Galvin Chapter 8 9 Simple uniprogramming with a single segment per
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Review: Memory, Disks, & Files. File Organizations and Indexing. Today: File Storage. Alternative File Organizations. Cost Model for Analysis
 File Organizations and Indexing Review: Memory, Disks, & Files Lecture 4 R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co.,
File Organizations and Indexing Review: Memory, Disks, & Files Lecture 4 R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co.,
Organização e Recuperação da Informação
 GSI024 Organização e Recuperação da Informação Contrução do índice Ilmério Reis da Silva ilmerio@facom.ufu.br www.facom.ufu.br/~ilmerio/ori UFU/FACOM - 2011/1 Arquivo 3 Construção do índice Observação
GSI024 Organização e Recuperação da Informação Contrução do índice Ilmério Reis da Silva ilmerio@facom.ufu.br www.facom.ufu.br/~ilmerio/ori UFU/FACOM - 2011/1 Arquivo 3 Construção do índice Observação
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part V Lecture 15, March 15, 2015 Mohammad Hammoud Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+ Tree) and Hash-based (i.e., Extendible
Database Applications (15-415) DBMS Internals- Part V Lecture 15, March 15, 2015 Mohammad Hammoud Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+ Tree) and Hash-based (i.e., Extendible
Web Information Retrieval. Lecture 4 Dictionaries, Index Compression
 Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
DATA STRUCTURES AND ALGORITHMS
 DATA STRUCTURES AND ALGORITHMS Sorting algorithms External sorting, Search Summary of the previous lecture Fast sorting algorithms Quick sort Heap sort Radix sort Running time of these algorithms in average
DATA STRUCTURES AND ALGORITHMS Sorting algorithms External sorting, Search Summary of the previous lecture Fast sorting algorithms Quick sort Heap sort Radix sort Running time of these algorithms in average
Realtime Search with Lucene. Michael
 Realtime Search with Lucene Michael Busch @michibusch michael@twitter.com buschmi@apache.org 1 Realtime Search with Lucene Agenda Introduction - Near-realtime Search (NRT) - Searching DocumentsWriter s
Realtime Search with Lucene Michael Busch @michibusch michael@twitter.com buschmi@apache.org 1 Realtime Search with Lucene Agenda Introduction - Near-realtime Search (NRT) - Searching DocumentsWriter s
MapReduce. Cloud Computing COMP / ECPE 293A
 Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
Distributed Systems. 18. MapReduce. Paul Krzyzanowski. Rutgers University. Fall 2015
 Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Advance Indexing. Limock July 3, 2014
 Advance Indexing Limock July 3, 2014 1 Papers 1) Gurajada, Sairam : "On-line index maintenance using horizontal partitioning." Proceedings of the 18th ACM conference on Information and knowledge management.
Advance Indexing Limock July 3, 2014 1 Papers 1) Gurajada, Sairam : "On-line index maintenance using horizontal partitioning." Proceedings of the 18th ACM conference on Information and knowledge management.
Java How to Program, 9/e. Copyright by Pearson Education, Inc. All Rights Reserved.
 Java How to Program, 9/e Copyright 1992-2012 by Pearson Education, Inc. All Rights Reserved. Searching data involves determining whether a value (referred to as the search key) is present in the data
Java How to Program, 9/e Copyright 1992-2012 by Pearson Education, Inc. All Rights Reserved. Searching data involves determining whether a value (referred to as the search key) is present in the data
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Index construc-on. Friday, 8 April 16 1
 Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.1 Index
Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.1 Index
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
1 o Semestre 2007/2008
 Efficient Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 6 7 Outline 1 2 3 4 5 6 7 Text es An index is a mechanism to locate a given term in
Efficient Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 6 7 Outline 1 2 3 4 5 6 7 Text es An index is a mechanism to locate a given term in
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Indexing. CS6200: Information Retrieval. Index Construction. Slides by: Jesse Anderton
 Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Managing the Database
 Slide 1 Managing the Database Objectives of the Lecture : To consider the roles of the Database Administrator. To consider the involvmentof the DBMS in the storage and handling of physical data. To appreciate
Slide 1 Managing the Database Objectives of the Lecture : To consider the roles of the Database Administrator. To consider the involvmentof the DBMS in the storage and handling of physical data. To appreciate
Chapter 9 Memory Management
 Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Query Answering Using Inverted Indexes
 Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
EXTERNAL SORTING. Sorting
 EXTERNAL SORTING 1 Sorting A classic problem in computer science! Data requested in sorted order (sorted output) e.g., find students in increasing grade point average (gpa) order SELECT A, B, C FROM R
EXTERNAL SORTING 1 Sorting A classic problem in computer science! Data requested in sorted order (sorted output) e.g., find students in increasing grade point average (gpa) order SELECT A, B, C FROM R
Survey on MapReduce Scheduling Algorithms
 Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
Recap: lecture 2 CS276A Information Retrieval
 Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
CS /5/18. Paul Krzyzanowski 1. Credit. Distributed Systems 18. MapReduce. Simplest environment for parallel processing. Background.
 Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
Information Retrieval. Lecture 2 - Building an index
 Information Retrieval Lecture 2 - Building an index Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 40 Overview Introduction Introduction Boolean
Information Retrieval Lecture 2 - Building an index Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 40 Overview Introduction Introduction Boolean