Storm. Distributed and fault-tolerant realtime computation. Nathan Marz Twitter
|
|
|
- Aleesha York
- 5 years ago
- Views:
Transcription

1 Storm Distributed and fault-tolerant realtime computation Nathan Marz Twitter
2 Basic info Open sourced September 19th Implementation is 15,000 lines of code Used by over 25 companies >2700 watchers on Github (most watched JVM project) Very active mailing list >2300 messages >670 members


3 Before Storm Queues Workers
4 Example (simplified)
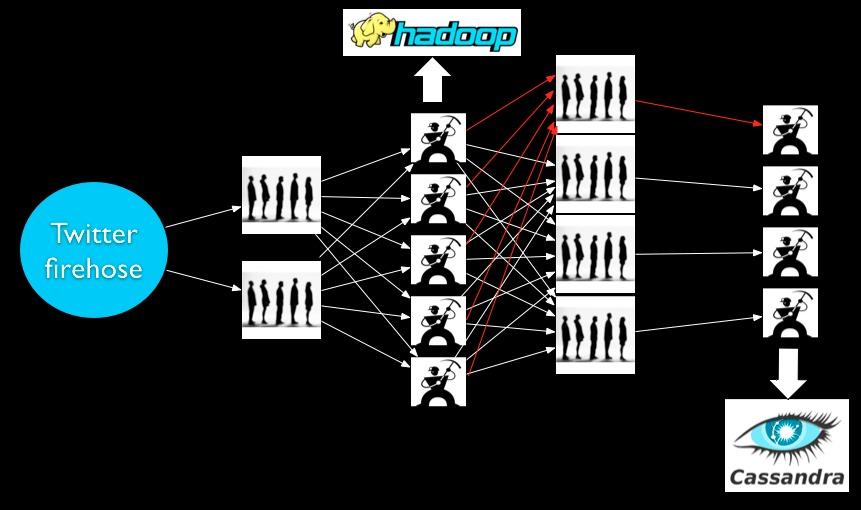
5 Example Workers schemify tweets and append to Hadoop
6 Example Workers update statistics on URLs by incrementing counters in Cassandra
7 Example Use mod/hashing to make sure same URL always goes to same worker
8 Scaling Deploy Reconfigure/redeploy
9 Problems Scaling is painful Poor fault-tolerance Coding is tedious
10 What we want Guaranteed data processing Horizontal scalability Fault-tolerance No intermediate message brokers! Higher level abstraction than message passing Just works
11 Storm Guaranteed data processing Horizontal scalability Fault-tolerance No intermediate message brokers! Higher level abstraction than message passing Just works



12 Use cases Stream processing Distributed RPC Continuous computation
13 Storm Cluster
14 Storm Cluster Master node (similar to Hadoop JobTracker)
15 Storm Cluster Used for cluster coordination
16 Storm Cluster Run worker processes
17 Starting a topology
18 Killing a topology
19 Concepts Streams Spouts Bolts Topologies
20 Streams Tuple Tuple Tuple Tuple Tuple Tuple Tuple Unbounded sequence of tuples
21 Spouts Source of streams
22 Spout examples Read from Kestrel queue Read from Twitter streaming API
23 Bolts Processes input streams and produces new streams
24 Bolts Functions Filters Aggregation Joins Talk to databases
25 Topology Network of spouts and bolts
26 Tasks Spouts and bolts execute as many tasks across the cluster
27 Task execution Tasks are spread across the cluster
28 Task execution Tasks are spread across the cluster

29 Stream grouping When a tuple is emitted, which task does it go to?
30 Stream grouping Shuffle grouping: pick a random task Fields grouping: mod hashing on a subset of tuple fields All grouping: send to all tasks Global grouping: pick task with lowest id
31 Topology shuffle [ id1, id2 ] shuffle [ url ] shuffle all
32 Streaming word count TopologyBuilder is used to construct topologies in Java
33 Streaming word count Define a spout in the topology with parallelism of 5 tasks
34 Streaming word count Split sentences into words with parallelism of 8 tasks
35 Streaming word count Consumer decides what data it receives and how it gets grouped Split sentences into words with parallelism of 8 tasks
36 Streaming word count Create a word count stream
37 Streaming word count splitsentence.py
38 Streaming word count
39 Streaming word count Submitting topology to a cluster
40 Streaming word count Running topology in local mode
41 Demo
42 Distributed RPC Data flow for Distributed RPC
43 DRPC Example Computing reach of a URL on the fly
44 Reach Reach is the number of unique people exposed to a URL on Twitter
45 Computing reach Tweeter Follower Follower Distinct follower URL Tweeter Follower Follower Distinct follower Count Reach Tweeter Follower Follower Distinct follower
46 Reach topology

47 Reach topology
48 Reach topology
49 Reach topology Keep set of followers for each request id in memory
50 Reach topology Update followers set when receive a new follower
51 Reach topology Emit partial count after receiving all followers for a request id

52 Demo
53 Guaranteeing message processing Tuple tree
54 Guaranteeing message processing A spout tuple is not fully processed until all tuples in the tree have been completed
55 Guaranteeing message processing If the tuple tree is not completed within a specified timeout, the spout tuple is replayed
56 Guaranteeing message processing Reliability API
57 Guaranteeing message processing Anchoring creates a new edge in the tuple tree
58 Guaranteeing message processing Marks a single node in the tree as complete
59 Guaranteeing message processing Storm tracks tuple trees for you in an extremely efficient way
60 Transactional topologies How do you do idempotent counting with an at least once delivery guarantee?
61 Transactional topologies Won t you overcount?
62 Transactional topologies Transactional topologies solve this problem
63 Transactional topologies Built completely on top of Storm s primitives of streams, spouts, and bolts
64 Transactional topologies Enables fault-tolerant, exactly-once messaging semantics
65 Transactional topologies Batch 1 Batch 2 Batch 3 Process small batches of tuples
66 Transactional topologies Batch 1 Batch 2 Batch 3 If a batch fails, replay the whole batch
67 Transactional topologies Batch 1 Batch 2 Batch 3 Once a batch is completed, commit the batch
68 Transactional topologies Batch 1 Batch 2 Batch 3 Bolts can optionally be committers
69 Transactional topologies Commit 1 Commit 1 Commit 2 Commit 3 Commit 4 Commit 4 Commits are ordered. If there s a failure during commit, the whole batch + commit is retried
70 Example
71 Example New instance of this object for every transaction attempt
72 Example Aggregate the count for this batch
73 Example Only update database if transaction ids differ
74 Example This enables idempotency since commits are ordered
75 Example (Credit goes to Kafka devs for this trick)
76 Transactional topologies Multiple batches can be processed in parallel, but commits are guaranteed to be ordered
77 Transactional topologies Requires a more sophisticated source queue than Kestrel or RabbitMQ storm-contrib has a transactional spout implementation for Kafka
78 Storm UI
79 Storm on EC2 One-click deploy tool
80 Starter code Example topologies
81 Documentation
82 Ecosystem Scala, JRuby, and Clojure DSL s Kestrel, Redis, AMQP, JMS, and other spout adapters Multilang adapters Cassandra, MongoDB integration
83 Questions?
84 Future work State spout Storm on Mesos Swapping Auto-scaling Higher level abstractions
85 Implementation KafkaTransactionalSpout
86 Implementation all all all
87 Implementation all all TransactionalSpout is a subtopology consisting of a spout and a bolt all
88 Implementation all all The spout consists of one task that coordinates the transactions all
89 Implementation all all all The bolt emits the batches of tuples
90 Implementation all all The coordinator emits a batch stream and a commit stream all
91 Implementation all all all Batch stream
92 Implementation all all all Commit stream
93 Implementation all all Coordinator reuses tuple tree framework to detect success or failure of batches or commits and replays appropriately all
Storm. Distributed and fault-tolerant realtime computation. Nathan Marz Twitter
 Storm Distributed and fault-tolerant realtime computation Nathan Marz Twitter Storm at Twitter Twitter Web Analytics Before Storm Queues Workers Example (simplified) Example Workers schemify tweets and
Storm Distributed and fault-tolerant realtime computation Nathan Marz Twitter Storm at Twitter Twitter Web Analytics Before Storm Queues Workers Example (simplified) Example Workers schemify tweets and
Before proceeding with this tutorial, you must have a good understanding of Core Java and any of the Linux flavors.
 About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
Apache Storm. Hortonworks Inc Page 1
 Apache Storm Page 1 What is Storm? Real time stream processing framework Scalable Up to 1 million tuples per second per node Fault Tolerant Tasks reassigned on failure Guaranteed Processing At least once
Apache Storm Page 1 What is Storm? Real time stream processing framework Scalable Up to 1 million tuples per second per node Fault Tolerant Tasks reassigned on failure Guaranteed Processing At least once
Tutorial: Apache Storm
 Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
Streaming & Apache Storm
 Streaming & Apache Storm Recommended Text: Storm Applied Sean T. Allen, Matthew Jankowski, Peter Pathirana Manning 2010 VMware Inc. All rights reserved Big Data! Volume! Velocity Data flowing into the
Streaming & Apache Storm Recommended Text: Storm Applied Sean T. Allen, Matthew Jankowski, Peter Pathirana Manning 2010 VMware Inc. All rights reserved Big Data! Volume! Velocity Data flowing into the
Data Analytics with HPC. Data Streaming
 Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Data Analytics with HPC Data Streaming Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Scalable Streaming Analytics
 Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
Scalable Streaming Analytics KARTHIK RAMASAMY @karthikz TALK OUTLINE BEGIN I! II ( III b Overview Storm Overview Storm Internals IV Z V K Heron Operational Experiences END WHAT IS ANALYTICS? according
10/24/2017 Sangmi Lee Pallickara Week 10- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 10-A-1 CS535 BIG DATA FAQs Term project proposal Feedback for the most of submissions are available PA2 has been posted (11/6) PART 2. SCALABLE FRAMEWORKS FOR REAL-TIME
CS535 Big Data - Fall 2017 Week 10-A-1 CS535 BIG DATA FAQs Term project proposal Feedback for the most of submissions are available PA2 has been posted (11/6) PART 2. SCALABLE FRAMEWORKS FOR REAL-TIME
REAL-TIME ANALYTICS WITH APACHE STORM
 REAL-TIME ANALYTICS WITH APACHE STORM Mevlut Demir PhD Student IN TODAY S TALK 1- Problem Formulation 2- A Real-Time Framework and Its Components with an existing applications 3- Proposed Framework 4-
REAL-TIME ANALYTICS WITH APACHE STORM Mevlut Demir PhD Student IN TODAY S TALK 1- Problem Formulation 2- A Real-Time Framework and Its Components with an existing applications 3- Proposed Framework 4-
STORM AND LOW-LATENCY PROCESSING.
 STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
8/24/2017 Week 1-B Instructor: Sangmi Lee Pallickara
 Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
Week 1-B-0 Week 1-B-1 CS535 BIG DATA FAQs Slides are available on the course web Wait list Term project topics PART 0. INTRODUCTION 2. DATA PROCESSING PARADIGMS FOR BIG DATA Sangmi Lee Pallickara Computer
Over the last few years, we have seen a disruption in the data management
 JAYANT SHEKHAR AND AMANDEEP KHURANA Jayant is Principal Solutions Architect at Cloudera working with various large and small companies in various Verticals on their big data and data science use cases,
JAYANT SHEKHAR AND AMANDEEP KHURANA Jayant is Principal Solutions Architect at Cloudera working with various large and small companies in various Verticals on their big data and data science use cases,
Flying Faster with Heron
 Flying Faster with Heron KARTHIK RAMASAMY @KARTHIKZ #TwitterHeron TALK OUTLINE BEGIN I! II ( III b OVERVIEW MOTIVATION HERON IV Z OPERATIONAL EXPERIENCES V K HERON PERFORMANCE END [! OVERVIEW TWITTER IS
Flying Faster with Heron KARTHIK RAMASAMY @KARTHIKZ #TwitterHeron TALK OUTLINE BEGIN I! II ( III b OVERVIEW MOTIVATION HERON IV Z OPERATIONAL EXPERIENCES V K HERON PERFORMANCE END [! OVERVIEW TWITTER IS
Twitter Heron: Stream Processing at Scale
 Twitter Heron: Stream Processing at Scale Saiyam Kohli December 8th, 2016 CIS 611 Research Paper Presentation -Sun Sunnie Chung TWITTER IS A REAL TIME ABSTRACT We process billions of events on Twitter
Twitter Heron: Stream Processing at Scale Saiyam Kohli December 8th, 2016 CIS 611 Research Paper Presentation -Sun Sunnie Chung TWITTER IS A REAL TIME ABSTRACT We process billions of events on Twitter
Functional Comparison and Performance Evaluation. Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14
 Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Real-time Calculating Over Self-Health Data Using Storm Jiangyong Cai1, a, Zhengping Jin2, b
 4th International Conference on Mechatronics, Materials, Chemistry and Computer Engineering (ICMMCCE 2015) Real-time Calculating Over Self-Health Data Using Storm Jiangyong Cai1, a, Zhengping Jin2, b 1
4th International Conference on Mechatronics, Materials, Chemistry and Computer Engineering (ICMMCCE 2015) Real-time Calculating Over Self-Health Data Using Storm Jiangyong Cai1, a, Zhengping Jin2, b 1
Apache Storm. A framework for Parallel Data Stream Processing
 Apache Storm A framework for Parallel Data Stream Processing Storm Storm is a distributed real- ;me computa;on pla
Apache Storm A framework for Parallel Data Stream Processing Storm Storm is a distributed real- ;me computa;on pla
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
10/26/2017 Sangmi Lee Pallickara Week 10- B. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 10-A-1 CS535 BIG DATA FAQs Term project proposal Feedback for the most of submissions are available PA2 has been posted (11/6) PART 2. SCALABLE FRAMEWORKS FOR REAL-TIME
CS535 Big Data - Fall 2017 Week 10-A-1 CS535 BIG DATA FAQs Term project proposal Feedback for the most of submissions are available PA2 has been posted (11/6) PART 2. SCALABLE FRAMEWORKS FOR REAL-TIME
Kafka Streams: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION
 A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION Konstantin Gregor / konstantin.gregor@tngtech.com ABOUT ME So ware developer for TNG in Munich Client in telecommunication
A BIG DATA STREAMING RECIPE WHAT TO CONSIDER WHEN BUILDING A REAL TIME BIG DATA APPLICATION Konstantin Gregor / konstantin.gregor@tngtech.com ABOUT ME So ware developer for TNG in Munich Client in telecommunication
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Apache Storm: Hands-on Session A.A. 2016/17
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Storm: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Storm: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Data streams and low latency processing DATA STREAM BASICS What is a data stream? Large data volume, likely structured, arriving at a very high rate Potentially
Big Data Infrastructures & Technologies Data streams and low latency processing DATA STREAM BASICS What is a data stream? Large data volume, likely structured, arriving at a very high rate Potentially
Indirect Communication
 Indirect Communication Vladimir Vlassov and Johan Montelius KTH ROYAL INSTITUTE OF TECHNOLOGY Time and Space In direct communication sender and receivers exist in the same time and know of each other.
Indirect Communication Vladimir Vlassov and Johan Montelius KTH ROYAL INSTITUTE OF TECHNOLOGY Time and Space In direct communication sender and receivers exist in the same time and know of each other.
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
FROM LEGACY, TO BATCH, TO NEAR REAL-TIME. Marc Sturlese, Dani Solà
 FROM LEGACY, TO BATCH, TO NEAR REAL-TIME Marc Sturlese, Dani Solà WHO ARE WE? Marc Sturlese - @sturlese Backend engineer, focused on R&D Interests: search, scalability Dani Solà - @dani_sola Backend engineer
FROM LEGACY, TO BATCH, TO NEAR REAL-TIME Marc Sturlese, Dani Solà WHO ARE WE? Marc Sturlese - @sturlese Backend engineer, focused on R&D Interests: search, scalability Dani Solà - @dani_sola Backend engineer
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Typhoon: An SDN Enhanced Real-Time Big Data Streaming Framework
 Typhoon: An SDN Enhanced Real-Time Big Data Streaming Framework Junguk Cho, Hyunseok Chang, Sarit Mukherjee, T.V. Lakshman, and Jacobus Van der Merwe 1 Big Data Era Big data analysis is increasingly common
Typhoon: An SDN Enhanced Real-Time Big Data Streaming Framework Junguk Cho, Hyunseok Chang, Sarit Mukherjee, T.V. Lakshman, and Jacobus Van der Merwe 1 Big Data Era Big data analysis is increasingly common
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10
 Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Ack per Record Storm* Twitter Heron* Storage
Functional Comparison and Performance Evaluation 毛玮王华峰张天伦 2016/9/10 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Ack per Record Storm* Twitter Heron* Storage
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
Time and Space. Indirect communication. Time and space uncoupling. indirect communication
 Time and Space Indirect communication Johan Montelius In direct communication sender and receivers exist in the same time and know of each other. KTH In indirect communication we relax these requirements.
Time and Space Indirect communication Johan Montelius In direct communication sender and receivers exist in the same time and know of each other. KTH In indirect communication we relax these requirements.
An Efficient Execution Scheme for Designated Event-based Stream Processing
 DEIM Forum 2014 D3-2 An Efficient Execution Scheme for Designated Event-based Stream Processing Yan Wang and Hiroyuki Kitagawa Graduate School of Systems and Information Engineering, University of Tsukuba
DEIM Forum 2014 D3-2 An Efficient Execution Scheme for Designated Event-based Stream Processing Yan Wang and Hiroyuki Kitagawa Graduate School of Systems and Information Engineering, University of Tsukuba
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Introduction to Apache Beam
 Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
Self Regulating Stream Processing in Heron
 Self Regulating Stream Processing in Heron Huijun Wu 2017.12 Huijun Wu Twitter, Inc. Infrastructure, Data Platform, Real-Time Compute Heron Overview Recent Improvements Self Regulating Challenges Dhalion
Self Regulating Stream Processing in Heron Huijun Wu 2017.12 Huijun Wu Twitter, Inc. Infrastructure, Data Platform, Real-Time Compute Heron Overview Recent Improvements Self Regulating Challenges Dhalion
Introduction to Apache Kafka
 Introduction to Apache Kafka Chris Curtin Head of Technical Research Atlanta Java Users Group March 2013 About Me 20+ years in technology Head of Technical Research at Silverpop (12 + years at Silverpop)
Introduction to Apache Kafka Chris Curtin Head of Technical Research Atlanta Java Users Group March 2013 About Me 20+ years in technology Head of Technical Research at Silverpop (12 + years at Silverpop)
Storm Crawler. Low latency scalable web crawling on Apache Storm. Julien Nioche digitalpebble. Berlin Buzzwords 01/06/2015
 Storm Crawler Low latency scalable web crawling on Apache Storm Julien Nioche julien@digitalpebble.com digitalpebble Berlin Buzzwords 01/06/2015 About myself DigitalPebble Ltd, Bristol (UK) Specialised
Storm Crawler Low latency scalable web crawling on Apache Storm Julien Nioche julien@digitalpebble.com digitalpebble Berlin Buzzwords 01/06/2015 About myself DigitalPebble Ltd, Bristol (UK) Specialised
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
BIG DATA. Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management. Author: Sandesh Deshmane
 BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
Strategies for real-time event processing
 SAMPLE CHAPTER Strategies for real-time event processing Sean T. Allen Matthew Jankowski Peter Pathirana FOREWORD BY Andrew Montalenti MANNING Storm Applied by Sean T. Allen Matthew Jankowski Peter Pathirana
SAMPLE CHAPTER Strategies for real-time event processing Sean T. Allen Matthew Jankowski Peter Pathirana FOREWORD BY Andrew Montalenti MANNING Storm Applied by Sean T. Allen Matthew Jankowski Peter Pathirana
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
CS 398 ACC Streaming. Prof. Robert J. Brunner. Ben Congdon Tyler Kim
 CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
CS 398 ACC Streaming Prof. Robert J. Brunner Ben Congdon Tyler Kim MP3 How s it going? Final Autograder run: - Tonight ~9pm - Tomorrow ~3pm Due tomorrow at 11:59 pm. Latest Commit to the repo at the time
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Deep Dive Amazon Kinesis. Ian Meyers, Principal Solution Architect - Amazon Web Services
 Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Deep Dive Amazon Kinesis Ian Meyers, Principal Solution Architect - Amazon Web Services Analytics Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
Distributed systems for stream processing
 Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
Distributed systems for stream processing Apache Kafka and Spark Structured Streaming Alena Hall Alena Hall Large-scale data processing Distributed Systems Functional Programming Data Science & Machine
Architecture of Flink's Streaming Runtime. Robert
 Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
StormCrawler. Low Latency Web Crawling on Apache Storm.
 StormCrawler Low Latency Web Crawling on Apache Storm Julien Nioche julien@digitalpebble.com @digitalpebble @stormcrawlerapi 1 About myself DigitalPebble Ltd, Bristol (UK) Text Engineering Web Crawling
StormCrawler Low Latency Web Crawling on Apache Storm Julien Nioche julien@digitalpebble.com @digitalpebble @stormcrawlerapi 1 About myself DigitalPebble Ltd, Bristol (UK) Text Engineering Web Crawling
Big Data Applications with Spring XD
 Big Data Applications with Spring XD Thomas Darimont, Software Engineer, Pivotal Inc. @thomasdarimont Unless otherwise indicated, these slides are 2013-2015 Pivotal Software, Inc. and licensed under a
Big Data Applications with Spring XD Thomas Darimont, Software Engineer, Pivotal Inc. @thomasdarimont Unless otherwise indicated, these slides are 2013-2015 Pivotal Software, Inc. and licensed under a
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 9: Real-Time Data Analytics (1/2) March 27, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 9: Real-Time Data Analytics (1/2) March 27, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
25/05/2018. Spark Streaming is a framework for large scale stream processing
 25/5/18 Spark Streaming is a framework for large scale stream processing Scales to s of nodes Can achieve second scale latencies Provides a simple batch-like API for implementing complex algorithm Can
25/5/18 Spark Streaming is a framework for large scale stream processing Scales to s of nodes Can achieve second scale latencies Provides a simple batch-like API for implementing complex algorithm Can
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Installing and Configuring Apache Storm
 3 Installing and Configuring Apache Storm Date of Publish: 2018-08-30 http://docs.hortonworks.com Contents Installing Apache Storm... 3...7 Configuring Storm for Supervision...8 Configuring Storm Resource
3 Installing and Configuring Apache Storm Date of Publish: 2018-08-30 http://docs.hortonworks.com Contents Installing Apache Storm... 3...7 Configuring Storm for Supervision...8 Configuring Storm Resource
TSAR A TimeSeries AggregatoR. Anirudh Todi TSAR
 TSAR A TimeSeries AggregatoR Anirudh Todi Twitter @anirudhtodi TSAR What is TSAR? What is TSAR? TSAR is a framework and service infrastructure for specifying, deploying and operating timeseries aggregation
TSAR A TimeSeries AggregatoR Anirudh Todi Twitter @anirudhtodi TSAR What is TSAR? What is TSAR? TSAR is a framework and service infrastructure for specifying, deploying and operating timeseries aggregation
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM
 Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Real-time Data Stream Processing Challenges and Perspectives
 www.ijcsi.org https://doi.org/10.20943/01201705.612 6 Real-time Data Stream Processing Challenges and Perspectives OUNACER Soumaya 1, TALHAOUI Mohamed Amine 2, ARDCHIR Soufiane 3, DAIF Abderrahmane 4 and
www.ijcsi.org https://doi.org/10.20943/01201705.612 6 Real-time Data Stream Processing Challenges and Perspectives OUNACER Soumaya 1, TALHAOUI Mohamed Amine 2, ARDCHIR Soufiane 3, DAIF Abderrahmane 4 and
Large-Scale Data Engineering. Data streams and low latency processing
 Large-Scale Data Engineering Data streams and low latency processing DATA STREAM BASICS What is a data stream? Large data volume, likely structured, arriving at a very high rate Potentially high enough
Large-Scale Data Engineering Data streams and low latency processing DATA STREAM BASICS What is a data stream? Large data volume, likely structured, arriving at a very high rate Potentially high enough
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Distributed CI: Scaling Jenkins on Mesos and Marathon. Roger Ignazio Puppet Labs, Inc. MesosCon 2015 Seattle, WA
 Distributed CI: Scaling Jenkins on Mesos and Marathon Roger Ignazio Puppet Labs, Inc. MesosCon 2015 Seattle, WA About Me Roger Ignazio QE Automation Engineer Puppet Labs, Inc. @rogerignazio Mesos In Action
Distributed CI: Scaling Jenkins on Mesos and Marathon Roger Ignazio Puppet Labs, Inc. MesosCon 2015 Seattle, WA About Me Roger Ignazio QE Automation Engineer Puppet Labs, Inc. @rogerignazio Mesos In Action
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Deploying Applications on DC/OS
 Mesosphere Datacenter Operating System Deploying Applications on DC/OS Keith McClellan - Technical Lead, Federal Programs keith.mcclellan@mesosphere.com V6 THE FUTURE IS ALREADY HERE IT S JUST NOT EVENLY
Mesosphere Datacenter Operating System Deploying Applications on DC/OS Keith McClellan - Technical Lead, Federal Programs keith.mcclellan@mesosphere.com V6 THE FUTURE IS ALREADY HERE IT S JUST NOT EVENLY
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Shen PingCAP 2017
 Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
Shen Li @ PingCAP About me Shen Li ( 申砾 ) Tech Lead of TiDB, VP of Engineering Netease / 360 / PingCAP Infrastructure software engineer WHY DO WE NEED A NEW DATABASE? Brief History Standalone RDBMS NoSQL
Introduc)on to Apache Ka1a. Jun Rao Co- founder of Confluent
on to Apache Ka1a. Jun Rao Co- founder of Confluent") Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
The Emergence of the Datacenter Developer. Tobi Knaup, Co-Founder & CTO at
 The Emergence of the Datacenter Developer Tobi Knaup, Co-Founder & CTO at Mesosphere @superguenter A Brief History of Operating Systems 2 1950 s Mainframes Punchcards No operating systems Time Sharing
The Emergence of the Datacenter Developer Tobi Knaup, Co-Founder & CTO at Mesosphere @superguenter A Brief History of Operating Systems 2 1950 s Mainframes Punchcards No operating systems Time Sharing
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
A New Architecture for Real Time Data Stream Processing
 A New Architecture for Real Time Data Stream Processing Soumaya Ounacer, Mohamed Amine TALHAOUI, Soufiane Ardchir, Abderrahmane Daif and Mohamed Azouazi Laboratoire Mathématiques Informatique et Traitement
A New Architecture for Real Time Data Stream Processing Soumaya Ounacer, Mohamed Amine TALHAOUI, Soufiane Ardchir, Abderrahmane Daif and Mohamed Azouazi Laboratoire Mathématiques Informatique et Traitement
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Exploring the scalability of RPC with oslo.messaging
 Exploring the scalability of RPC with oslo.messaging Rpc client Rpc server Request Rpc client Rpc server Worker Response Worker Messaging infrastructure Rpc client Rpc server Worker Request-response Each
Exploring the scalability of RPC with oslo.messaging Rpc client Rpc server Request Rpc client Rpc server Worker Response Worker Messaging infrastructure Rpc client Rpc server Worker Request-response Each
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
IEMS 5722 Mobile Network Programming and Distributed Server Architecture
 Department of Information Engineering, CUHK MScIE 2 nd Semester, 2016/17 IEMS 5722 Mobile Network Programming and Distributed Server Architecture Lecture 9 Asynchronous Tasks & Message Queues Lecturer:
Department of Information Engineering, CUHK MScIE 2 nd Semester, 2016/17 IEMS 5722 Mobile Network Programming and Distributed Server Architecture Lecture 9 Asynchronous Tasks & Message Queues Lecturer:
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
A Distributed Engine for Processing Triple Streams
 A Distributed Engine for Processing Triple Streams Master Thesis Dec 11, 2012 Thomas Hunziker of Zurich, Switzerland Student-ID: 07-704-844 thomas.hunziker.87@gmail.com Advisor: Lorenz Fischer Prof. Abraham
A Distributed Engine for Processing Triple Streams Master Thesis Dec 11, 2012 Thomas Hunziker of Zurich, Switzerland Student-ID: 07-704-844 thomas.hunziker.87@gmail.com Advisor: Lorenz Fischer Prof. Abraham
Building loosely coupled and scalable systems using Event-Driven Architecture. Jonas Bonér Patrik Nordwall Andreas Källberg
 Building loosely coupled and scalable systems using Event-Driven Architecture Jonas Bonér Patrik Nordwall Andreas Källberg Why is EDA Important for Scalability? What building blocks does EDA consists of?
Building loosely coupled and scalable systems using Event-Driven Architecture Jonas Bonér Patrik Nordwall Andreas Källberg Why is EDA Important for Scalability? What building blocks does EDA consists of?
Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka. Materna GmbH
 Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka Wer ist Frank Pientka? Dipl.-Informatiker (TH Karlsruhe) Verheiratet, 2 Töchter Principal Software Architect in Dortmund Fast
Let the data flow! Data Streaming & Messaging with Apache Kafka Frank Pientka Wer ist Frank Pientka? Dipl.-Informatiker (TH Karlsruhe) Verheiratet, 2 Töchter Principal Software Architect in Dortmund Fast
A STORM ARCHITECTURE FOR FUSING IOT DATA
 NATIONAL AND KAPODISTRIAN UNIVERSITY OF ATHENS SCHOOL OF SCIENCE DEPARTMENT OF INFORMATICS AND TELECOMMUNICATION A STORM ARCHITECTURE FOR FUSING IOT DATA A framework on top of Storm s streaming processing
NATIONAL AND KAPODISTRIAN UNIVERSITY OF ATHENS SCHOOL OF SCIENCE DEPARTMENT OF INFORMATICS AND TELECOMMUNICATION A STORM ARCHITECTURE FOR FUSING IOT DATA A framework on top of Storm s streaming processing