MI-PDB, MIE-PDB: Advanced Database Systems
|
|
|
- Peregrine Smith
- 5 years ago
- Views:
Transcription
1 MI-PDB, MIE-PDB: Advanced Database Systems Lecture 10: MapReduce, Hadoop Lecturer: Martin Svoboda Author: Irena Holubová Faculty of Mathematics and Physics, Charles University in Prague Course NDBI040: Big Data Management and NoSQL Databases
2 Framework A programming model + implementation Developed by Google in 2008 To replace old, centralized index structure Distributed, parallel computing on large data Google: A simple and powerful interface that enables automatic parallelization and distribution of large-scale computations, combined with an implementation of this interface that achieves high performance on large clusters of commodity PCs. Programming model in general: Mental model a programmer has about execution of application Purpose: improve programmer's productivity Evaluation: expressiveness, simplicity, performance
3 Programming Models Parallel programming models Message passing Independent tasks encapsulating local data Tasks interact by exchanging messages Shared memory Tasks share a common address space Tasks interact by reading and writing from/to this space Asynchronously Data parallelization Data are partitioned across tasks Tasks execute a sequence of independent operations
4 Framework Divide-and-conquer paradigm Map breaks down a problem into sub-problems Processes input data to generate a set of intermediate key/value pairs Reduce receives and combines the sub-solutions to solve the problem Processes intermediate values associated with the same intermediate key Many real world tasks can be expressed this way Programmer focuses on map/reduce code Framework cares about data partitioning, scheduling execution across machines, handling machine failures, managing intermachine communication,
5 A Bit More Formally Map Input: a key/value pair Output: a set of intermediate key/value pairs Usually different domain (k 1,v 1 ) list(k 2,v 2 ) Reduce Input: an intermediate key and a set of values for that key Output: a possibly smaller set of values The same domain (k 2,list(v 2 )) (k 2,possibly smaller list(v 2 ))
6 Example: Word Frequency map(string key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(string key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(key, AsString(result));

7 Example: Word Frequency
8 Application Parts Input reader Reads data from stable storage e.g., a distributed file system Divides the input into appropriate size 'splits' Prepares key/value pairs Map function User-specified processing of key/value pairs Partition function Map function output is allocated to a reducer Partition function is given the key (output of Map) and the number of reducers and returns the index of the desired reducer Default is to hash the key and use the hash value modulo the number of reducers
9 Application Parts Compare function Sorts the input for the Reduce function Reduce function User-specified processing of key/values Output writer Writes the output of the Reduce function to stable storage e.g., a distributed file system
10
11 Execution Step 1 1. MapReduce library in the user program splits the input files into M pieces Typically MB per piece Controllable by the user via optional parameter 2. It starts copies of the program on a cluster of machines
12 Execution Step 2 Master = a special copy of the program Workers = other copies that are assigned work by master M Map tasks and R Reduce tasks to assign Master picks idle workers and assigns each one a Map task (or a Reduce task)
13 Execution Step 3 A worker who is assigned a Map task: Reads the contents of the corresponding input split Parses key/value pairs out of the input data Passes each pair to the user-defined Map function Intermediate key/value pairs produced by the Map function are buffered in memory
14 Execution Step 4 Periodically, the buffered pairs are written to local disk Partitioned into R regions by the partitioning function Locations of the buffered pairs on the local disk are passed back to the master It is responsible for forwarding the locations to the Reduce workers
15 Execution Step 5 Reduce worker is notified by the master about data locations It uses remote procedure calls to read the buffered data from local disks of the Map workers When it has read all intermediate data, it sorts it by the intermediate keys Typically many different keys map to the same Reduce task If the amount of intermediate data is too large, an external sort is used
16 Execution Step 6 A Reduce worker iterates over the sorted intermediate data For each intermediate key encountered: It passes the key and the corresponding set of intermediate values to the user's Reduce function The output is appended to a final output file for this Reduce partition
17 Function combine After a map phase, the mapper transmits over the network the entire intermediate data file to the reducer Sometimes this file is highly compressible User can specify function combine Like a reduce function It is run by the mapper before passing the job to the reducer Over local data
18 Counters Can be associated with any action that a mapper or a reducer does In addition to default counters e.g., the number of input and output key/value pairs processed User can watch the counters in real time to see the progress of a job
19 Fault Tolerance A large number of machines process a large number of data fault tolerance is necessary Worker failure Master pings every worker periodically If no response is received in a certain amount of time, master marks the worker as failed All its tasks are reset back to their initial idle state become eligible for scheduling on other workers
20 Fault Tolerance Master failure Strategy A: Master writes periodic checkpoints of the master data structures If it dies, a new copy can be started from the last checkpointed state Strategy B: There is only a single master its failure is unlikely MapReduce computation is simply aborted if the master fails Clients can check for this condition and retry the MapReduce operation if they desire
21 Stragglers Straggler = a machine that takes an unusually long time to complete one of the map/reduce tasks in the computation Example: a machine with a bad disk Solution: When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks A task is marked as completed whenever either the primary or the backup execution completes
22 Task Granularity M pieces of Map phase and R pieces of Reduce phase Ideally both much larger than the number of worker machines How to set them? Master makes O(M + R) scheduling decisions Master keeps O(M * R) status information in memory For each Map/Reduce task: state (idle/in-progress/completed) For each non-idle task: identity of worker machine For each completed Map task: locations and sizes of the R intermediate file regions R is often constrained by users The output of each Reduce task ends up in a separate output file Practical recommendation (Google): Choose M so that each individual task is roughly MB of input data Make R a small multiple of the number of worker machines we expect to use
23 Criticism David DeWitt and Michael Stonebraker MapReduce is a step backwards in database access based on Schema describing data structure Separating schema from the application Advanced query languages 2. MapReduce is a poor implementation Instead of indexes is uses brute force 3. MapReduce is not novel (ideas more than 20 years old and overcome) 4. MapReduce is missing features common in DBMSs Indexes, transactions, integrity constraints, views, 5. MapReduce is incompatible with applications implemented over DBMSs Data mining, business intelligence,
24 Apache Hadoop Open-source software framework Running of applications on large clusters of commodity hardware Multi-terabyte data-sets Thousands of nodes Implements MapReduce Derived from Google's MapReduce and Google File System (GFS) Not open-source
25 Apache Hadoop Modules Hadoop Common Common utilities Support for other Hadoop modules Hadoop Distributed File System (HDFS) Distributed file system High-throughput access to application data Hadoop YARN Framework for job scheduling and cluster resource management Hadoop MapReduce YARN-based system for parallel processing of large data sets

26 HDFS (Hadoop Distributed File System) Basic Features Free and open source High quality Crossplatform Pure Java Has bindings for non-java programming languages Fault-tolerant Highly scalable
27 HDFS Data Characteristics Assumes: Streaming data access Batch processing rather than interactive user access Large data sets and files Write-once / read-many A file once created, written and closed does not need to be changed Or not often This assumption simplifies coherency Optimal applications for this model: MapReduce, webcrawlers,
28 HDFS Fault Tolerance Idea: failure is the norm rather than exception A HDFS instance may consist of thousands of machines Each storing a part of the file system s data Each component has non-trivial probability of failure Assumption: There is always some component that is non-functional. Detection of faults Quick, automatic recovery
29 HDFS NameNode, DataNodes Master/slave architecture HDFS exposes file system namespace File is internally split into one or more blocks Typical block size is 64MB (or 128 MB) NameNode = master server that manages the file system namespace + regulates access to files by clients Opening/closing/renaming files and directories Determines mapping of blocks to DataNodes DataNode = serves read/write requests from clients + performs block creation/deletion and replication upon instructions from NameNode Usually one per node in a cluster Manages storage attached to the node that it runs on
30 HDFS Namespace Hierarchical file system Directories and files Create, remove, move, rename,... NameNode maintains the file system Any meta information changes to the file system are recorded by the NameNode An application can specify the number of replicas of the file needed Replication factor of the file The information is stored in the NameNode
31 HDFS Data Replication HDFS is designed to store very large files across machines in a large cluster Each file is a sequence of blocks All blocks in the file are of the same size Except the last one Block size is configurable per file Blocks are replicated for fault tolerance Number of replicas is configurable per file
32 HDFS How NameNode Works? Stores HDFS namespace Uses a transaction log called EditLog to record every change that occurs to the file system s meta data E.g., creating a new file, change in replication factor of a file,.. EditLog is stored in the NameNode s local file system FsImage entire file system namespace + mapping of blocks to files + file system properties Stored in a file in NameNode s local file system Designed to be compact Loaded in NameNode s memory 4 GB of RAM is sufficient
33 HDFS How DataNode Works? Stores data in files in its local file system Has no knowledge about HDFS file system Stores each block of HDFS data in a separate file Does not create all files in the same directory Local file system might not be support it Uses heuristics to determine optimal number of files per directory
34 Hadoop MapReduce MapReduce requires: Distributed file system Engine that can distribute, coordinate, monitor and gather the results Hadoop: HDFS + JobTracker + TaskTracker JobTracker (master) = scheduler TaskTracker (slave per node) is assigned a Map or Reduce (or other operations) Map or Reduce run on a node so does the TaskTracker Each task is run on its own JVM
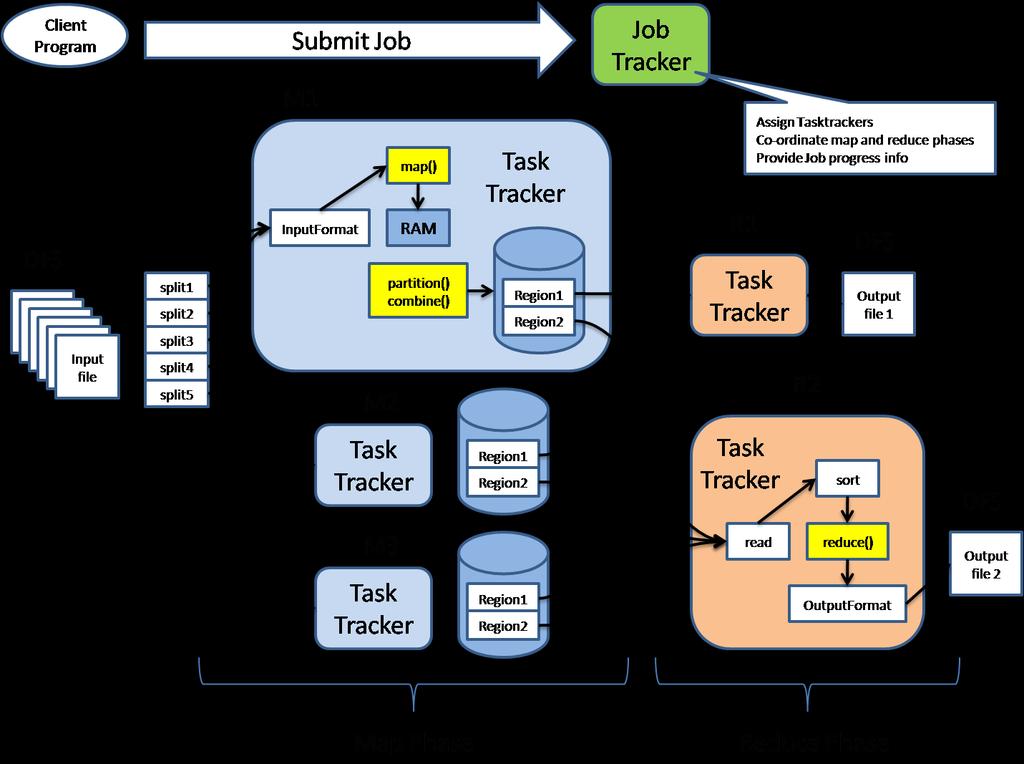
35
36 JobTracker (Master) Like a scheduler: 1. A client application is sent to the JobTracker 2. It talks to the NameNode (= HDFS master) and locates the TaskTracker (Hadoop client) near the data 3. It moves the work to the chosen TaskTracker node
37 TaskTracker (Client) Accepts tasks from JobTracker Map, Reduce, Combine, Input, output paths Has a number of slots for the tasks Execution slots available on the machine (or machines on the same rack) Spawns a separate JVM for execution of a task Indicates the number of available slots through the hearbeat message to the JobTracker A failed task is re-executed by the JobTracker
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
MapReduce, Apache Hadoop
 Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
MapReduce, Apache Hadoop
 NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
MapReduce, Apache Hadoop
 B4M36DS2, BE4M36DS2: Database Systems 2 h p://www.ksi.mff.cuni.cz/~svoboda/courses/171-b4m36ds2/ Lecture 5 MapReduce, Apache Hadoop Mar n Svoboda mar n.svoboda@fel.cvut.cz 30. 10. 2017 Charles University
B4M36DS2, BE4M36DS2: Database Systems 2 h p://www.ksi.mff.cuni.cz/~svoboda/courses/171-b4m36ds2/ Lecture 5 MapReduce, Apache Hadoop Mar n Svoboda mar n.svoboda@fel.cvut.cz 30. 10. 2017 Charles University
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
MapReduce & HyperDex. Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University
 MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Introduction to MapReduce
 Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Batch Processing Systems
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Batch Processing Systems Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid,
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Batch Processing Systems Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid,
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
Survey on MapReduce Scheduling Algorithms
 Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
Survey on MapReduce Scheduling Algorithms Liya Thomas, Mtech Student, Department of CSE, SCTCE,TVM Syama R, Assistant Professor Department of CSE, SCTCE,TVM ABSTRACT MapReduce is a programming model used
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
L5-6:Runtime Platforms Hadoop and HDFS
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/