Tutorial on Machine Learning. Impact of dataset composition on models performance. G. Marcou, N. Weill, D. Horvath, D. Rognan, A.
|
|
|
- Mariah Hall
- 6 years ago
- Views:
Transcription
1 Part 1. Tutorial on Machine Learning. Impact of dataset composition on models performance G. Marcou, N. Weill, D. Horvath, D. Rognan, A. Varnek 1 Introduction Predictive performance of QSAR model depends not only on the way how this model has been built and validated (descriptors, machine-learning method, variable selection procedure, scrambling, cross-validation, etc.) but also on similarity between the compounds of training and test sets. Indeed, a training set containing a limited number of compounds is never representative with respect to infinite chemical space. As a consequence, the learning of a chemical or biological property is often biased, i.e. reflect the training set composition. In order to assess predictive performance of the model, the bias between training and test sets could be analyzed using applicability domain or any other related approach. In this tutorial, classifications models build on a training set for antibiotic activities are applied to one related and one unrelated external test sets. Difference between predictive performances of the models applied on related and unrelated sets is interpreted comparing descriptors distribution in all three sets (data profiling). All calculations will be performed using open source software Weka (data mining) 1 and R (graphical representation of the data) 2. Description of data preprocessing (with ChemAxon) and descriptors generation (with OpenEye, MOE and ISIDA) is given in APPENDIXES 1 and 2. Some explanations on Weka graphical interface are given in APPENDIX Software R R is an open source environment for statistical computing and graphics 2.To run R, on Linux type R; on Windows click on the R icon. In order to facilitate use of R, it is recommended to copy the tutorial files the directory C:\WORKDIR. If the application is not run from this working directory, in the R command line area, enter the command: setwd('<name of your working directory>') Weka The Weka software is a graphical user interface (GUI) to a Java library dedicated to data mining 1. A large part of the data mining algorithm is accessible through this interface. It is recommended to use the latest developer version (3.5.7). The library is developed by the Waikato university (New Zealand). The Weka is a native bird of New Zealand, in danger of extinction. 1
2 Run Weka. Since Weka default memory allocation is insufficient to work with these tutorial datasets, some setting parameters should be modified. Linux: Open a terminal and type: java -Xmx512m -jar weka.jar There might be incompatibilities between the java runtime environment (JRE) on some Linux distributions. To avoid this, it is recommended to create a file in the user s home directory called LookAndFeel.props, containing the line: Theme=javax.swing.plaf.metal.MetalLookAndFeel Windows: Modify the file RunWeka in the installation directory of Weka (root privilege required). Change the line: maxheap=128m by: maxheap=512m Then launch Weka by clicking on the window s Start button then in Program/Weka 3.5.7, click on Weka Datasets Two datasets are used in this tutorial. The first one, stored in the directory Cherkasov, was published in reference 5. It contains a set of antibacterials (521 cmpds) and decoys (2158 cmpds). The latter were selected from drugs of different therapeutic classes and for which no antibacterial activity is known. This set will be further split into a training set and a related test set. The second is the external unrelated test set, stored in the directory CN. These data were extracted from the experimental screening of the Chimiothèque Nationale 4 for the antibacterial activity on S. Aureus. 2 Model building 2.1 Descriptors Three sets of desriptors are used: trivial descriptors: 8 descriptors inspired by Shoishet et al. 5 : (the molecular weight, the number of heteroatoms, the number of cycles, the number of rotatable bonds, the number of rigid bonds, the number of hydrogen bonds acceptors, the number of hydrogen bonds donors, the 2D polar surface area); MOE 2D descriptors (optionally); ISIDA / SMF descriptors 8 : paths of 2 to 5 atoms in the molecular graph represented by 2
3 the element type (optionally). 2.2 Data files Here, we provide some information about files both stored in the Cherkasov and CN directories and which are supposed to be created in course of the tutorial. The Cherkasov directory contains the following files: Cherkasov.sdf: the same file in SDF format. The activity flag is stored in the SDF field: > <Antibio>; Chekasov_std.sdf: the same file in SDF format, standardized with Chemaxon s tools. config.xml: a configuration file for Chemaxon s standardizer 6 ; PassAll.txt: a configuration file for OpenEye s Filter 7 ; CherkasovDB.mdb: the MOE database for this dataset; Cherkasov_MOEDsc.csv: the 2D descriptors calculated by MOE; Cherkasov_SMF.arff: the ISIDA/SMF fragment descriptors; Cherkasov_SMF.hdr: file identifying each ISIDA/SMF 8 fragment index to a string description of the fragment; Cherkasov_MOEDsc_80p.arff: MOE descriptors of the training set, a subset of 80% of the original dataset; Cherkasov_MOEDsc_20p.arff: MOE descriptors of the related test set, the remaining 20% of the original dataset; Cherkasov_trivial_80p.arff: simple descriptors of the training set, a subset of 80% of the original dataset; Cherkasov_trivial_20p.arff: simple descriptors of the related test set, the remaining 20% of the original dataset; trivial.tbl: output properties table of OpenEye s filter manipulations; trivial.csv: the same cleaned data to keep only the column used in this tutorial. trivial.arff: the same processed data in ARFF fromat. Content of the directory CN: CN.sdf: raw dataset file containing the flag for antibacterial activity (0 not active, 1 active) in an SDF field (> <Antibio>); CN_std.sdf: standardised file; CN_trivial.arff: trivial descriptors file (ARFF format) CN_MOEDsc.arff: MOE 2D descriptors file (ARFF format) CN_SMF.arff: ISIDA/SMF descriptors file in ARFF format. CN_SMF.hdr: file identifying each ISIDA/SMF fragment descriptors index to a string describing it. 2.3 Obtaining and validation of the models Typically, in QSAR studies an initial parent dataset is split into training and test sets. The models are build on the training set followed by their validation on the test set. 3
4 2.3.1 Extracting the training and theexternal related test set from the Cherkasov dataset. Instructions 1. Open Weka; 2. In the tool bar, click on Application then on Explorer; Transformation Numeric To Nominal ; 3. in the Explorer window, click on Open file and select Cherkasov /trivial.csv; 4. select the attribute name then click on Remove; 5. click on Choose, then Filter/unsupervised/attribute/NumericToNominal; 6. click on the text zone set to NumericToNominal; 7. in the pop-up window, set the parameter attributeindices to last then click on OK; 8. click on Apply; Split of the parent set into training and test sets 9. click on Save and name the new dataset as trivial.arff; 10. click on Choose; 11. select the unsupervised, instance, then RemoveFolds method; 12. click on the text zone set to RemoveFolds; 13. set fold to 1, numfolds to 5 and seed to 1; 14. click on OK; 15. click on Apply; 16. click on Save and name the new dataset as Cherkasov_trivial_20p.arff; 17. click on the text zone set to RemoveFolds; 18. set inverselection to True; 19. click on OK; 20. click on Apply; 21. click on Save and name the new dataset as Cherkasov_trivial_80p.arff; It is important to keep the same integer value (different from 0) for the seed of the random number generator and to keep it different from 0. This will unsure that the fold separation is always the same. If the seed were 0, the parent dataset would not be shuffled and therefore, resulting training and test sets would not be representative Build and analyze a Bayesian model 1. in the Explorer window, click on Open file and select Cherkasov_trivial_80p.arff; 2. select the tab Classify; 3. click on Choose, classifiers / Bayes / NaiveBayes; 4. click on the Cross-validation radio button and set the parameter to 5 folds; 5. click on Start 6. see results on the screenshot below 4
5 Results can be analyzed by right clicking on the corresponding line in the Result list window. In the contextual menu that opens, one can access to some useful options: Visualize Threshold Curve (Receiver Operator Curves) Visualize Cost Curve Visualize Margin Curve Save Model Load Model Re-evaluate External validation on the related test set 1. select the tab Classify; 2. click on Choose, classifiers / Bayes / NaiveBayes; 3. click on the button Set and select the file Cherkasov_trivial_20p.arff; 4. click on Start 5. see results on the screenshot below 5

6 2.4 External validations on unrelated test set The CN dataset, which is highly diverse and completely unrelated to the previous ones, is used here as support for a real virtual screening exercise, challenging the model to predict the antibiotics therein. Since this set never served to influence the model buildup in any way, it is irrelevant that experimental screening actually preceded virtual screening in this example. Save the model 1. righ click on the last line of the Result list; 2. in the contextual menu, choose Save model and save the model as trivial.model. Apply the model 1. click on Load model; 2. select the file trivial.model; 3. click on the button Set and select the file CN/trivial.arff; 4. righ click on the last line of the Result list; 5. in the contextual menu, choose Re-evaluate model on current test set. 6. see results on the screenshot below 6
7 Exercises (optional) 1. Repeat the same steps with ISIDA fragmental descriptors or MOE descriptors; 2. repeat these steps using the decision tree J4.8; 3. repeat these steps using the decision tree J4.8 and the ISIDA descriptors or MOE descriptors. It is remarkable that more sophisticated descriptors and data mining methods will not change the situation. 3 Detection of the bias: profiling of data sets. The file trivial.arff in the Cherkasov directory will be examined. The file will be imported into Weka: 1. activate the preproces tab in Weka; 2. click on Open file and choose the file trivial.csv. The distributions can be displayed as histograms (tab preprocess the button visualise all) or displayed as correlograms (tab visualise). The graphical capacities of Weka are very limited. Other softwares are better suited for graphical display of dataset properties. Here we use R. To start, use the command to set the working directory to the root directory of the tutorial. For instance, Windows users that followed the recommendations in the introduction shall type: 7

8 setwd('c:/workdir/tutorialmarcouweill/') Then execute the R RBoxplot.R script: source('rboxplot.r') This will create a function to plot box plots of the data. Use the function to plot the profile of the training, related and unrelated test sets respectively: plotprofile(``cherkasov/trivial_80p.csv'',''inactive'',''active' ') X11() plotprofile(``cherkasov/trivial_20p.csv'',''inactive'',''active' ') X11() plotprofile(``cn/trivial.csv'',''inactive'',''active'') On the screenshots below one can easily find similarity of descriptors profiles for training and related test sets, whereas that for unrelated test set looks rather different. It should be noted that in related sets (belonging to Cherkasov s data 3 ]) descriptors well separate actives and inactives, whereas in unrelated test set (Chimiothèque Nationale 4 ) no distinct separation is observed. Training set 8


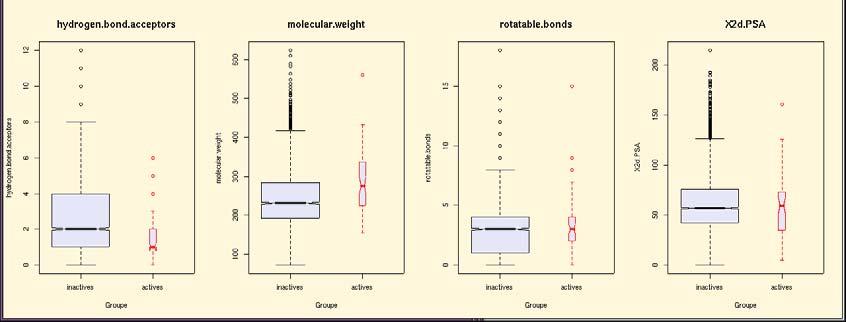
9 related test set unrelated test set 9
10 4 Conclusion Descriptors profiling allowed us to interpret predictive performance of the models with respect to the bias between training and test set. However, this solution is too coarse and doesn t characterize sufficiently the datasets. Applicability domains approaches are more relevant tools to treat the problem of datasets bias. Specifically, for classification problems, the two levels of bias should be outlined the representation of limited subsets of actives. This yields the false impression that only the visited chemical space zones may harbor actives, whereas radically different chemotypes are nevertheless carriers of an activity, but cannot be learned on hand of the training set underrepresented decoys, i.e. inactives in the immediate neighborhood of actives. This lets the user of the biased model believe that any structure in the neighborhood of an active is supposed to be an active, although in reality many small structural changes applied to an active may cause an activity loss. Even if most of small structural changes do not cause an activity loss (so that the similarity principle holds), the number of those who do, may still lead to an enormous set of near-identical inactives. 5. Further readings A special issue of the Journal of Computer-Aided Molecular Design is dedicated to bias in drug design: J. Comp.-Aid. Mol. Design, Volume 22, Number 3-4, March 2008 References [1] Ian H. Witten and Eibe Frank. Data Mining: Practical machine learning tools and techniques, 2nd Edition. Morgan Kaufmann, San Francisco, [2] R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, ISBN [3] A. Cherkasov. Can bacterial-metabolite-likeness model improve odds of in silico antibiotic discovery? J. Chem. Inf. Model., 46: , [4] Chimiothèque Nationale, Chimiotheque-nationale.enscm.fr, [5] Huang N., Shoichet B. K., Irwin J. J., Benchmarking Sets for Molecular Docking. Journal of Medicinal Chemistry, 49(23): , [6] ChemAxon. Standardize , version [7] OpenEye Scientific Software Inc., Santa Fe, MA, USA. Filter. version 2.0. [8] ISIDA project. 10
11 Appendix 1. Data preprocessing Software used OpenEye s Filter: a software for fast chemical library filtering and analysis; Chemaxon s Standardizer: a software for custom chemical library cleaning; CCG s MOE: a general purpose bio/chemoinformatics environment; OpenEye and Chemaxon offer licenses for free to academics, under reasonable conditions. CCG offers MOE licenses for a very affordable price to academics. The use of commercial products is for the purpose of example. Nothing presented here is an exclusive feature of these programs and similar manipulations can be realized using concurrent products. Data Standardization It is not difficult to define some general rules for data standardization. Nonetheless, particular attention should be paid to: correctness of Lewis representations; aromaticity; presence of multiple chemical species; salts and counter-ions; tautomers; protonation; standardizations of key chemical functions; stereochemistry; conformers; ChemAxon Standardizer is used to clean 2D structures. Standardize 1. Open Standardizer; 2. load the file Cherkasov.sdf (AddFile), click on Next; 3. click on Open Configuration, load the file Config.xml; 4. take a look at the standardization rules (Click on a rule, then on MarvinSketch to edit the rule); 5. click on Next; 6. select an output file: Cherkasov_std.sdf -save it in SDF format-; 7. click on Next then on Finish; 8. consider the results. 11
12 Appendix 2. Generation of molecular descriptors MOE and ISIDA are used to generate molecular descriptors. In this tutorial, only 2D descriptors are used. MOE 1. Open the file Cherkasov_std.sdf (File, Open, Import SD); 2. in the import window, name the database as CherkasovDB.mdb then click on scan then on OK; 3. in the Database Viewer, click on Compute then on Descriptors; 4. in the QuaSAR-Descriptor window, click on 2D and select all (Shift+Click) then OK; 5. in Database Viewer, right click on the header Antibio then, in the contextual menu, on Move Field and click on the name of the last column; 6. in the main menu, click on File, then on Export. 7. in the Output format menu, select delimited ASCII database then, as delimiter, select Comma and name the output file as Cherkasov_MOEDsc.csv. MOE possess a QSAR module allowing to construct immediately a model. But in the following we work with Weka. ISIDA/Fragmentor On a command line type: Fragmentor -i Cherkasov_std.sdf -o Cherkasov_SMF -t 1 -l 2 -u 5 -s Antibio -f SVM This will generate an SVM file containing for each molecule a line containing its descriptors values. The first column of an SVM file is the value of the property to model. The header file, containing a string describing each descriptor possesses the extension HDR. Simple descriptors Most chemoinformatics tools allow monitoring the distribution of simple descriptors. Simple descriptors must depend only of 2D representation of molecules, have a straightforward interpretation and not depend of the details of the molecule -for instance, they might not be able to distinguish structural isomers. This set of descriptors is often used to define a profile of chemical libraryies. Here are some proposals of simple descriptors: the molecular weight; the number of heteroatoms; the number of cycles; the number of rotatable bonds; the number of rigid bonds; the number of hydrogen bonds acceptors; the number of hydrogen bonds donors; the 2D polar surface area. 12
13 This list is non-exhaustive and is proposed for the tutorial. As stated before it was inspired by the Dataset of Usefull Decoy methodology 5. A model based on these descriptors can yet be of some interest as a filter or pre-screen of a very large chemical database. Simple descriptors can be generated with OpenEye Filter. This software works as a command line for Linux or a command line in DOS terminal for Windows (type cmd in the Run text area in the Windows Start menu). The use of a cygwin terminal for Windows is recommended. The command line: filter -in Cherkasov_std.sdf -out Cherkasov_filter.sdf -filter filter_trivial.txt -table trivial.tbl A file containing the count of all the above mentioned descriptors (and more) is created as trivial.tbl. The columns are tab separated. A version of this file restricted to the sole descriptors above mentioned is provided as trivial.csv. The last column of this file contains the antibacterial activity flag. It is also possible to calculate these descriptors with MOE. 13
14 Appendix 3. Weka at first glance The Weka interface consists first in a main menu bar. These menu concern general manipulations of the interface: close the program, manipulate native data files (ARFF format), visualize graphical results, and provide help... The only menu of interest for us is labeled Application. Through this menu, it is possible to access to 4 separate modes to treat datasets: «Simple CLI» : command line interface. The syntax is almost equivalent to Java code. «Explorer» : Visualization, treatment of datasets. «Experimenter» : Apply a variety of data mining approach to a variety of datasets. «Knowledge Flow» : Graphical elaboration of data pipelining. The concept is similar to Pipeline Pilot. 7.1 Simple CLI The syntax of a command line is close to the Java programming language. This simplifies greatly the development of unitary tests in the course of development of project making use of Java classes of Weka. This tutorial will not provide introduction to Java development nor Weka scripting. 7.2 Knowledge Flow This is a functional graphical representation of a dataset treatment. Datasets, data mining methods, display and results are the nodes of a graph. The edges represent paths that can be followed by the data. This is similar in spirit to Pipeline Pilot and is considered rather as an alternative to the Explorer module (see later). 7.3 Experimenter The goal of this module is to provide a way to process many combinations of data mining approaches on many datasets. Computations are distributed on a grid if available. Datasets and results can be stored and accessed relational database such as MySQL. Methods performances are stored and can be compared on a statistical basis. This module is not meant to build models to be published. It is rather used to identify the most fruitful approaches to a data mining problem. 7.4 Explorer The explorer module will be the one used in this tutorial. It allows accessing to almost all the methods in the software interactively. It can build models and validate them. Visualizations and analysis tools are available. 14
Short instructions on using Weka
 Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
KNIME Enalos+ Molecular Descriptor nodes
 KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
The Explorer. chapter Getting started
 chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
WEKA Explorer User Guide for Version 3-4
 WEKA Explorer User Guide for Version 3-4 Richard Kirkby Eibe Frank July 28, 2010 c 2002-2010 University of Waikato This guide is licensed under the GNU General Public License version 2. More information
WEKA Explorer User Guide for Version 3-4 Richard Kirkby Eibe Frank July 28, 2010 c 2002-2010 University of Waikato This guide is licensed under the GNU General Public License version 2. More information
Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5
 open-source software version 0.1.5") Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5 Version (date) Changes and comments 0.1.0 (02.02.2015) Changes from alpha version: 1. More precise default
Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5 Version (date) Changes and comments 0.1.0 (02.02.2015) Changes from alpha version: 1. More precise default
KNIME Enalos+ Modelling nodes
 KNIME Enalos+ Modelling nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step 2-Building
KNIME Enalos+ Modelling nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step 2-Building
6.034 Design Assignment 2
 6.034 Design Assignment 2 April 5, 2005 Weka Script Due: Friday April 8, in recitation Paper Due: Wednesday April 13, in class Oral reports: Friday April 15, by appointment The goal of this assignment
6.034 Design Assignment 2 April 5, 2005 Weka Script Due: Friday April 8, in recitation Paper Due: Wednesday April 13, in class Oral reports: Friday April 15, by appointment The goal of this assignment
Practical Data Mining COMP-321B. Tutorial 1: Introduction to the WEKA Explorer
 Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
TUBE: Command Line Program Calls
 TUBE: Command Line Program Calls March 15, 2009 Contents 1 Command Line Program Calls 1 2 Program Calls Used in Application Discretization 2 2.1 Drawing Histograms........................ 2 2.2 Discretizing.............................
TUBE: Command Line Program Calls March 15, 2009 Contents 1 Command Line Program Calls 1 2 Program Calls Used in Application Discretization 2 2.1 Drawing Histograms........................ 2 2.2 Discretizing.............................
Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques
 24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
User Guide Written By Yasser EL-Manzalawy
 User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
Using Weka for Classification. Preparing a data file
 Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
AI32 Guide to Weka. Andrew Roberts 1st March 2005
 AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
DATA ANALYSIS WITH WEKA. Author: Nagamani Mutteni Asst.Professor MERI
 DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
LAD-WEKA Tutorial Version 1.0
 LAD-WEKA Tutorial Version 1.0 March 25, 2014 Tibérius O. Bonates tb@ufc.br Federal University of Ceará, Brazil Vaux S. D. Gomes vauxgomes@gmail.com Federal University of the Semi-Arid, Brazil 1 Requirements
LAD-WEKA Tutorial Version 1.0 March 25, 2014 Tibérius O. Bonates tb@ufc.br Federal University of Ceará, Brazil Vaux S. D. Gomes vauxgomes@gmail.com Federal University of the Semi-Arid, Brazil 1 Requirements
COMPARISON OF DIFFERENT CLASSIFICATION TECHNIQUES
 COMPARISON OF DIFFERENT CLASSIFICATION TECHNIQUES USING DIFFERENT DATASETS V. Vaithiyanathan 1, K. Rajeswari 2, Kapil Tajane 3, Rahul Pitale 3 1 Associate Dean Research, CTS Chair Professor, SASTRA University,
COMPARISON OF DIFFERENT CLASSIFICATION TECHNIQUES USING DIFFERENT DATASETS V. Vaithiyanathan 1, K. Rajeswari 2, Kapil Tajane 3, Rahul Pitale 3 1 Associate Dean Research, CTS Chair Professor, SASTRA University,
Attribute Discretization and Selection. Clustering. NIKOLA MILIKIĆ UROŠ KRČADINAC
 Attribute Discretization and Selection Clustering NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com Naive Bayes Features Intended primarily for the work with nominal attributes
Attribute Discretization and Selection Clustering NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com Naive Bayes Features Intended primarily for the work with nominal attributes
Lab Exercise Three Classification with WEKA Explorer
 Lab Exercise Three Classification with WEKA Explorer 1. Fire up WEKA to get the GUI Chooser panel. Select Explorer from the four choices on the right side. 2. We are on Preprocess now. Click the Open file
Lab Exercise Three Classification with WEKA Explorer 1. Fire up WEKA to get the GUI Chooser panel. Select Explorer from the four choices on the right side. 2. We are on Preprocess now. Click the Open file
A chemistry friendly system integrating drug design tools and a consistent visual interface Xin Zhang, Christian Baber
 Cubist Pharmaceuticals The Shape of Cures to Come A chemistry friendly system integrating drug design tools and a consistent visual interface Xin Zhang, Christian Baber Outline Introduction to drug metabolism
Cubist Pharmaceuticals The Shape of Cures to Come A chemistry friendly system integrating drug design tools and a consistent visual interface Xin Zhang, Christian Baber Outline Introduction to drug metabolism
WEKA homepage.
 WEKA homepage http://www.cs.waikato.ac.nz/ml/weka/ Data mining software written in Java (distributed under the GNU Public License). Used for research, education, and applications. Comprehensive set of
WEKA homepage http://www.cs.waikato.ac.nz/ml/weka/ Data mining software written in Java (distributed under the GNU Public License). Used for research, education, and applications. Comprehensive set of
WEKA: Practical Machine Learning Tools and Techniques in Java. Seminar A.I. Tools WS 2006/07 Rossen Dimov
 WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies
 Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies Anthony C. Arvanites Lead Discovery Informatics Company Introduction Founded: 1999 Platform: Combining
Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies Anthony C. Arvanites Lead Discovery Informatics Company Introduction Founded: 1999 Platform: Combining
An Introduction to WEKA Explorer. In part from: Yizhou Sun 2008
 An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
Data Mining. Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka. I. Data sets. I.1. Data sets characteristics and formats
 Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux.
 1 Introduction Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux. The gain chart is an alternative to confusion matrix for the evaluation of a classifier.
1 Introduction Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux. The gain chart is an alternative to confusion matrix for the evaluation of a classifier.
Data Mining With Weka A Short Tutorial
 Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
Luke S. Fisher, Ph.D. Manager, Client Services US Modeling and Simulation Support. July 24 th, 2008
 Workflow Customization with the DS Developer Client Luke S. Fisher, Ph.D. Manager, Client Services US Modeling and Simulation Support July 24 th, 2008 New Science and Customized Workflows for Drug Discovery
Workflow Customization with the DS Developer Client Luke S. Fisher, Ph.D. Manager, Client Services US Modeling and Simulation Support July 24 th, 2008 New Science and Customized Workflows for Drug Discovery
Using Google s PageRank Algorithm to Identify Important Attributes of Genes
 Using Google s PageRank Algorithm to Identify Important Attributes of Genes Golam Morshed Osmani Ph.D. Student in Software Engineering Dept. of Computer Science North Dakota State Univesity Fargo, ND 58105
Using Google s PageRank Algorithm to Identify Important Attributes of Genes Golam Morshed Osmani Ph.D. Student in Software Engineering Dept. of Computer Science North Dakota State Univesity Fargo, ND 58105
Docking with GOLD. Novembre 2009 CCDC. G. Marcou, E. Kellenberger. G. Marcou, E. Kellenberger () Docking with GOLD Novembre / 25
 Docking with GOLD Novembre / 25") Docking with GOLD CCDC G. Marcou, E. Kellenberger Novembre 2009 G. Marcou, E. Kellenberger () Docking with GOLD Novembre 2009 1 / 25 Sommaire 1 GOLD Suite organization 2 GOLD run setting - Wizard 3 GOLD
Docking with GOLD CCDC G. Marcou, E. Kellenberger Novembre 2009 G. Marcou, E. Kellenberger () Docking with GOLD Novembre 2009 1 / 25 Sommaire 1 GOLD Suite organization 2 GOLD run setting - Wizard 3 GOLD
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Practical Data Mining COMP-321B. Tutorial 5: Article Identification
 Practical Data Mining COMP-321B Tutorial 5: Article Identification Shevaun Ryan Mark Hall August 15, 2006 c 2006 University of Waikato 1 Introduction This tutorial will focus on text mining, using text
Practical Data Mining COMP-321B Tutorial 5: Article Identification Shevaun Ryan Mark Hall August 15, 2006 c 2006 University of Waikato 1 Introduction This tutorial will focus on text mining, using text
A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics
 A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics Helmut Berger and Dieter Merkl 2 Faculty of Information Technology, University of Technology, Sydney, NSW, Australia hberger@it.uts.edu.au
A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics Helmut Berger and Dieter Merkl 2 Faculty of Information Technology, University of Technology, Sydney, NSW, Australia hberger@it.uts.edu.au
Data Preparation. UROŠ KRČADINAC URL:
 Data Preparation UROŠ KRČADINAC EMAIL: uros@krcadinac.com URL: http://krcadinac.com Normalization Normalization is the process of rescaling the values to a specific value scale (typically 0-1) Standardization
Data Preparation UROŠ KRČADINAC EMAIL: uros@krcadinac.com URL: http://krcadinac.com Normalization Normalization is the process of rescaling the values to a specific value scale (typically 0-1) Standardization
Outline. Part II Pre-processing Description of pre-processing nodes Build using table editor
 www.inforsense.com Outline Part I Import & Export Import data from different data sources and file types Query from a relational database Export data to different locations Part II Pre-processing Description
www.inforsense.com Outline Part I Import & Export Import data from different data sources and file types Query from a relational database Export data to different locations Part II Pre-processing Description
Data Mining. Introduction. Piotr Paszek. (Piotr Paszek) Data Mining DM KDD 1 / 44
 Data Mining DM KDD 1 / 44") Data Mining Piotr Paszek piotr.paszek@us.edu.pl Introduction (Piotr Paszek) Data Mining DM KDD 1 / 44 Plan of the lecture 1 Data Mining (DM) 2 Knowledge Discovery in Databases (KDD) 3 CRISP-DM 4 DM software
Data Mining Piotr Paszek piotr.paszek@us.edu.pl Introduction (Piotr Paszek) Data Mining DM KDD 1 / 44 Plan of the lecture 1 Data Mining (DM) 2 Knowledge Discovery in Databases (KDD) 3 CRISP-DM 4 DM software
How to Create a Substance Answer Set
 How to Create a Substance Answer Set Select among five search techniques to find substances Substances can be described by multiple names or other characteristics, so SciFinder gives you the flexibility
How to Create a Substance Answer Set Select among five search techniques to find substances Substances can be described by multiple names or other characteristics, so SciFinder gives you the flexibility
Basic Concepts Weka Workbench and its terminology
 Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
WEKA Explorer User Guide for Version 3-5-5
 WEKA Explorer User Guide for Version 3-5-5 Richard Kirkby Eibe Frank Peter Reutemann January 26, 2007 c 2002-2006 University of Waikato Contents 1 Launching WEKA 2 2 The WEKA Explorer 4 2.1 Section Tabs.............................
WEKA Explorer User Guide for Version 3-5-5 Richard Kirkby Eibe Frank Peter Reutemann January 26, 2007 c 2002-2006 University of Waikato Contents 1 Launching WEKA 2 2 The WEKA Explorer 4 2.1 Section Tabs.............................
WEKA KnowledgeFlow Tutorial for Version 3-5-6
 WEKA KnowledgeFlow Tutorial for Version 3-5-6 Mark Hall Peter Reutemann June 1, 2007 c 2007 University of Waikato Contents 1 Introduction 2 2 Features 3 3 Components 4 3.1 DataSources..............................
WEKA KnowledgeFlow Tutorial for Version 3-5-6 Mark Hall Peter Reutemann June 1, 2007 c 2007 University of Waikato Contents 1 Introduction 2 2 Features 3 3 Components 4 3.1 DataSources..............................
Perform the following steps to set up for this project. Start out in your login directory on csit (a.k.a. acad).
.") CSC 458 Data Mining and Predictive Analytics I, Fall 2017 (November 22, 2017) Dr. Dale E. Parson, Assignment 4, Comparing Weka Bayesian, clustering, ZeroR, OneR, and J48 models to predict nominal dissolved
CSC 458 Data Mining and Predictive Analytics I, Fall 2017 (November 22, 2017) Dr. Dale E. Parson, Assignment 4, Comparing Weka Bayesian, clustering, ZeroR, OneR, and J48 models to predict nominal dissolved
COMP s1 - Getting started with the Weka Machine Learning Toolkit
 COMP9417 16s1 - Getting started with the Weka Machine Learning Toolkit Last revision: Thu Mar 16 2016 1 Aims This introduction is the starting point for Assignment 1, which requires the use of the Weka
COMP9417 16s1 - Getting started with the Weka Machine Learning Toolkit Last revision: Thu Mar 16 2016 1 Aims This introduction is the starting point for Assignment 1, which requires the use of the Weka
Weka ( )
") Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
AutoDock Virtual Screening: Raccoon & Fox Tools
 AutoDock Virtual Screening: Raccoon & Fox Tools Stefano Forli Ruth Huey The Scripps Research Institute Molecular Graphics Laboratory 10550 N. Torrey Pines Rd. La Jolla, California 92037-1000 USA 3 December
AutoDock Virtual Screening: Raccoon & Fox Tools Stefano Forli Ruth Huey The Scripps Research Institute Molecular Graphics Laboratory 10550 N. Torrey Pines Rd. La Jolla, California 92037-1000 USA 3 December
New ensemble methods for evolving data streams
 New ensemble methods for evolving data streams A. Bifet, G. Holmes, B. Pfahringer, R. Kirkby, and R. Gavaldà Laboratory for Relational Algorithmics, Complexity and Learning LARCA UPC-Barcelona Tech, Catalonia
New ensemble methods for evolving data streams A. Bifet, G. Holmes, B. Pfahringer, R. Kirkby, and R. Gavaldà Laboratory for Relational Algorithmics, Complexity and Learning LARCA UPC-Barcelona Tech, Catalonia
Data Mining. Lesson 9 Support Vector Machines. MSc in Computer Science University of New York Tirana Assoc. Prof. Dr.
 Data Mining Lesson 9 Support Vector Machines MSc in Computer Science University of New York Tirana Assoc. Prof. Dr. Marenglen Biba Data Mining: Content Introduction to data mining and machine learning
Data Mining Lesson 9 Support Vector Machines MSc in Computer Science University of New York Tirana Assoc. Prof. Dr. Marenglen Biba Data Mining: Content Introduction to data mining and machine learning
Tutorial 2: Analysis of DIA/SWATH data in Skyline
 Tutorial 2: Analysis of DIA/SWATH data in Skyline In this tutorial we will learn how to use Skyline to perform targeted post-acquisition analysis for peptide and inferred protein detection and quantification.
Tutorial 2: Analysis of DIA/SWATH data in Skyline In this tutorial we will learn how to use Skyline to perform targeted post-acquisition analysis for peptide and inferred protein detection and quantification.
Tutorial Case studies
 1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
A Program demonstrating Gini Index Classification
 A Program demonstrating Gini Index Classification Abstract In this document, a small program demonstrating Gini Index Classification is introduced. Users can select specified training data set, build the
A Program demonstrating Gini Index Classification Abstract In this document, a small program demonstrating Gini Index Classification is introduced. Users can select specified training data set, build the
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Data Mining. Practical Machine Learning Tools and Techniques. Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A.
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
Machine Learning Practical NITP Summer Course Pamela K. Douglas UCLA Semel Institute
 Machine Learning Practical NITP Summer Course 2013 Pamela K. Douglas UCLA Semel Institute Email: pamelita@g.ucla.edu Topics Covered Part I: WEKA Basics J Part II: MONK Data Set & Feature Selection (from
Machine Learning Practical NITP Summer Course 2013 Pamela K. Douglas UCLA Semel Institute Email: pamelita@g.ucla.edu Topics Covered Part I: WEKA Basics J Part II: MONK Data Set & Feature Selection (from
Introduction to Hermes
 Introduction to Hermes Version 2.0 November 2017 Hermes v1.9 Table of Contents Introduction... 2 Visualising and Editing the MLL1 fusion protein... 2 Opening Files in Hermes... 3 Setting Style Preferences...
Introduction to Hermes Version 2.0 November 2017 Hermes v1.9 Table of Contents Introduction... 2 Visualising and Editing the MLL1 fusion protein... 2 Opening Files in Hermes... 3 Setting Style Preferences...
Order Preserving Triclustering Algorithm. (Version1.0)
") Order Preserving Triclustering Algorithm User Manual (Version1.0) Alain B. Tchagang alain.tchagang@nrc-cnrc.gc.ca Ziying Liu ziying.liu@nrc-cnrc.gc.ca Sieu Phan sieu.phan@nrc-cnrc.gc.ca Fazel Famili fazel.famili@nrc-cnrc.gc.ca
Order Preserving Triclustering Algorithm User Manual (Version1.0) Alain B. Tchagang alain.tchagang@nrc-cnrc.gc.ca Ziying Liu ziying.liu@nrc-cnrc.gc.ca Sieu Phan sieu.phan@nrc-cnrc.gc.ca Fazel Famili fazel.famili@nrc-cnrc.gc.ca
Tutorial: From chemical structures to outlier analysis. G. Marcou, D. Horvath, A. Varnek
 Tutorial: From chemical structures to outlier analysis G. Marcou, D. Horvath, A. Varnek 1 Download your materials Download URL (tinyurl to Renater FileSender repository): ahttps://tinyurl.com/y99km3nd
Tutorial: From chemical structures to outlier analysis G. Marcou, D. Horvath, A. Varnek 1 Download your materials Download URL (tinyurl to Renater FileSender repository): ahttps://tinyurl.com/y99km3nd
The use of KNIME to support research activity at Lhasa Limited
 The use of KNIME to support research activity at Lhasa Limited Data processing through to proof-of-concept implementations Sam Webb samuel.webb@lhasalimited.org Overview The Lhasa-KNIME timeline Internal
The use of KNIME to support research activity at Lhasa Limited Data processing through to proof-of-concept implementations Sam Webb samuel.webb@lhasalimited.org Overview The Lhasa-KNIME timeline Internal
Scenario Implementation as the R SubtypeDiscovery Package
 Chapter 5 Scenario Implementation as the R SubtypeDiscovery Package To enable reproducibility of our analyses and to abstract from the application domains, we implemented in the R SubtypeDiscovery package
Chapter 5 Scenario Implementation as the R SubtypeDiscovery Package To enable reproducibility of our analyses and to abstract from the application domains, we implemented in the R SubtypeDiscovery package
Version 1.1 October 2017 Teaching Subset v5.39
 1 Visualisations Version 1.1 October 2017 Teaching Subset v5.39 Table of Contents Example 1. Generating Structure Views... 2 Generating a Simple Molecular View... 2 Generating a Packing Diagram... 4 Displaying
1 Visualisations Version 1.1 October 2017 Teaching Subset v5.39 Table of Contents Example 1. Generating Structure Views... 2 Generating a Simple Molecular View... 2 Generating a Packing Diagram... 4 Displaying
Bayesian Learning Networks Approach to Cybercrime Detection
 Bayesian Learning Networks Approach to Cybercrime Detection N S ABOUZAKHAR, A GANI and G MANSON The Centre for Mobile Communications Research (C4MCR), University of Sheffield, Sheffield Regent Court, 211
Bayesian Learning Networks Approach to Cybercrime Detection N S ABOUZAKHAR, A GANI and G MANSON The Centre for Mobile Communications Research (C4MCR), University of Sheffield, Sheffield Regent Court, 211
Data Science with R Decision Trees with Rattle
 Data Science with R Decision Trees with Rattle Graham.Williams@togaware.com 9th June 2014 Visit http://onepager.togaware.com/ for more OnePageR s. In this module we use the weather dataset to explore the
Data Science with R Decision Trees with Rattle Graham.Williams@togaware.com 9th June 2014 Visit http://onepager.togaware.com/ for more OnePageR s. In this module we use the weather dataset to explore the
User Manual Tips and Tricks
 For the latest news and the most up-todate information, please consult the ECHA website. Document history Version Comment Version 1.0 December 2010: for Toolbox version 2.0 Version 1.1 : Amended section
For the latest news and the most up-todate information, please consult the ECHA website. Document history Version Comment Version 1.0 December 2010: for Toolbox version 2.0 Version 1.1 : Amended section
WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA.
. Comparison with a FILTER approach implemented into TANAGRA.") 1 Topic WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA. Feature selection. The feature selection 1 is a crucial aspect of
1 Topic WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA. Feature selection. The feature selection 1 is a crucial aspect of
Using CSD-CrossMiner to Create a Feature Database
 Table of Contents Introduction... 2 CSD-CrossMiner Terminology... 2 Overview of CSD-CrossMiner... 3 Features and Pharmacophore Representation... 4 Building your Own Feature Database... 5 Using CSD-CrossMiner
Table of Contents Introduction... 2 CSD-CrossMiner Terminology... 2 Overview of CSD-CrossMiner... 3 Features and Pharmacophore Representation... 4 Building your Own Feature Database... 5 Using CSD-CrossMiner
Chapter 2 Overview of the Design Methodology
 Chapter 2 Overview of the Design Methodology This chapter presents an overview of the design methodology which is developed in this thesis, by identifying global abstraction levels at which a distributed
Chapter 2 Overview of the Design Methodology This chapter presents an overview of the design methodology which is developed in this thesis, by identifying global abstraction levels at which a distributed
Data Preparation. Nikola Milikić. Jelena Jovanović
 Data Preparation Nikola Milikić nikola.milikic@fon.bg.ac.rs Jelena Jovanović jeljov@fon.bg.ac.rs Normalization Normalization is the process of rescaling the values of an attribute to a specific value range,
Data Preparation Nikola Milikić nikola.milikic@fon.bg.ac.rs Jelena Jovanović jeljov@fon.bg.ac.rs Normalization Normalization is the process of rescaling the values of an attribute to a specific value range,
Application of Data Mining in Manufacturing Industry
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 3, Number 2 (2011), pp. 59-64 International Research Publication House http://www.irphouse.com Application of Data Mining
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 3, Number 2 (2011), pp. 59-64 International Research Publication House http://www.irphouse.com Application of Data Mining
International Journal of Advanced Research in Computer Science and Software Engineering
 Volume 3, Issue 4, April 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Discovering Knowledge
Volume 3, Issue 4, April 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Discovering Knowledge
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Weka VotedPerceptron & Attribute Transformation (1)
") Weka VotedPerceptron & Attribute Transformation (1) Lab6 (in- class): 5 DIC 2016-13:15-15:00 (CHOMSKY) ACKNOWLEDGEMENTS: INFORMATION, EXAMPLES AND TASKS IN THIS LAB COME FROM SEVERAL WEB SOURCES. Learning
Weka VotedPerceptron & Attribute Transformation (1) Lab6 (in- class): 5 DIC 2016-13:15-15:00 (CHOMSKY) ACKNOWLEDGEMENTS: INFORMATION, EXAMPLES AND TASKS IN THIS LAB COME FROM SEVERAL WEB SOURCES. Learning
Type Checking and Type Equality
 Type Checking and Type Equality Type systems are the biggest point of variation across programming languages. Even languages that look similar are often greatly different when it comes to their type systems.
Type Checking and Type Equality Type systems are the biggest point of variation across programming languages. Even languages that look similar are often greatly different when it comes to their type systems.
IJSRD - International Journal for Scientific Research & Development Vol. 4, Issue 05, 2016 ISSN (online):
:") IJSRD - International Journal for Scientific Research & Development Vol. 4, Issue 05, 2016 ISSN (online): 2321-0613 A Study on Handling Missing Values and Noisy Data using WEKA Tool R. Vinodhini 1 A. Rajalakshmi
IJSRD - International Journal for Scientific Research & Development Vol. 4, Issue 05, 2016 ISSN (online): 2321-0613 A Study on Handling Missing Values and Noisy Data using WEKA Tool R. Vinodhini 1 A. Rajalakshmi
SOLOMON: Parentage Analysis 1. Corresponding author: Mark Christie
 SOLOMON: Parentage Analysis 1 Corresponding author: Mark Christie christim@science.oregonstate.edu SOLOMON: Parentage Analysis 2 Table of Contents: Installing SOLOMON on Windows/Linux Pg. 3 Installing
SOLOMON: Parentage Analysis 1 Corresponding author: Mark Christie christim@science.oregonstate.edu SOLOMON: Parentage Analysis 2 Table of Contents: Installing SOLOMON on Windows/Linux Pg. 3 Installing
Lead Discovery 5.2. User Guide. Powered by TIBCO Spotfire
 User Guide Powered by TIBCO Spotfire Last Modified: July 26, 2013 Table of Contents 1. Introduction... 5 2. Loading Data... 6 2.1. Opening an SDFile... 6 2.2. Importing a ChemDraw for Excel File... 6 2.3.
User Guide Powered by TIBCO Spotfire Last Modified: July 26, 2013 Table of Contents 1. Introduction... 5 2. Loading Data... 6 2.1. Opening an SDFile... 6 2.2. Importing a ChemDraw for Excel File... 6 2.3.
Dr. Prof. El-Bahlul Emhemed Fgee Supervisor, Computer Department, Libyan Academy, Libya
 Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Performance
Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Performance
7.4 Tutorial #4: Profiling LC Segments Using the CHAID Option
 7.4 Tutorial #4: Profiling LC Segments Using the CHAID Option DemoData = gss82.sav After an LC model is estimated, it is often desirable to describe (profile) the resulting latent classes in terms of demographic
7.4 Tutorial #4: Profiling LC Segments Using the CHAID Option DemoData = gss82.sav After an LC model is estimated, it is often desirable to describe (profile) the resulting latent classes in terms of demographic
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels
 Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),
IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER
 IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER N. Suresh Kumar, Dr. M. Thangamani 1 Assistant Professor, Sri Ramakrishna Engineering College, Coimbatore, India 2 Assistant
IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER N. Suresh Kumar, Dr. M. Thangamani 1 Assistant Professor, Sri Ramakrishna Engineering College, Coimbatore, India 2 Assistant
CS 223B Computer Vision Problem Set 3
 CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
1 Topic. Image classification using Knime.
 1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
Data Mining. 3.3 Rule-Based Classification. Fall Instructor: Dr. Masoud Yaghini. Rule-Based Classification
 Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
Study on Classifiers using Genetic Algorithm and Class based Rules Generation
 2012 International Conference on Software and Computer Applications (ICSCA 2012) IPCSIT vol. 41 (2012) (2012) IACSIT Press, Singapore Study on Classifiers using Genetic Algorithm and Class based Rules
2012 International Conference on Software and Computer Applications (ICSCA 2012) IPCSIT vol. 41 (2012) (2012) IACSIT Press, Singapore Study on Classifiers using Genetic Algorithm and Class based Rules
Data Mining. Part 1. Introduction. 1.3 Input. Fall Instructor: Dr. Masoud Yaghini. Input
 Data Mining Part 1. Introduction 1.3 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Instances Attributes References Instances Instance: Instances Individual, independent example of the concept to be
Data Mining Part 1. Introduction 1.3 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Instances Attributes References Instances Instance: Instances Individual, independent example of the concept to be
Tanagra: An Evaluation
 Tanagra: An Evaluation Jessica Enright Jonathan Klippenstein November 5th, 2004 1 Introduction to Tanagra Tanagra was written as an aid to education and research on data mining by Ricco Rakotomalala [1].
Tanagra: An Evaluation Jessica Enright Jonathan Klippenstein November 5th, 2004 1 Introduction to Tanagra Tanagra was written as an aid to education and research on data mining by Ricco Rakotomalala [1].
Vector Xpression 3. Speed Tutorial: III. Creating a Script for Automating Normalization of Data
 Vector Xpression 3 Speed Tutorial: III. Creating a Script for Automating Normalization of Data Table of Contents Table of Contents...1 Important: Please Read...1 Opening Data in Raw Data Viewer...2 Creating
Vector Xpression 3 Speed Tutorial: III. Creating a Script for Automating Normalization of Data Table of Contents Table of Contents...1 Important: Please Read...1 Opening Data in Raw Data Viewer...2 Creating
GMDR User Manual. GMDR software Beta 0.9. Updated March 2011
 GMDR User Manual GMDR software Beta 0.9 Updated March 2011 1 As an open source project, the source code of GMDR is published and made available to the public, enabling anyone to copy, modify and redistribute
GMDR User Manual GMDR software Beta 0.9 Updated March 2011 1 As an open source project, the source code of GMDR is published and made available to the public, enabling anyone to copy, modify and redistribute
MetScape User Manual
 MetScape 2.3.2 User Manual A Plugin for Cytoscape National Center for Integrative Biomedical Informatics July 2012 2011 University of Michigan This work is supported by the National Center for Integrative
MetScape 2.3.2 User Manual A Plugin for Cytoscape National Center for Integrative Biomedical Informatics July 2012 2011 University of Michigan This work is supported by the National Center for Integrative
Analyzing Client-Side Interactions to Determine Reading Behavior
 Analyzing Client-Side Interactions to Determine Reading Behavior David Hauger 1 and Lex Van Velsen 2 1 Institute for Information Processing and Microprocessor Technology Johannes Kepler University, Linz,
Analyzing Client-Side Interactions to Determine Reading Behavior David Hauger 1 and Lex Van Velsen 2 1 Institute for Information Processing and Microprocessor Technology Johannes Kepler University, Linz,
Machine Learning Chapter 2. Input
 Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
ReaxysTutorial. Dr. QF Carlos F. Lagos
 ReaxysTutorial Dr. QF Carlos F. Lagos Agenda 1) Reaxys Basics Main Settings Query Menu: Reaction, Substances and Properties, Authors and citations Generate a structure t from a name Commercial Availability
ReaxysTutorial Dr. QF Carlos F. Lagos Agenda 1) Reaxys Basics Main Settings Query Menu: Reaction, Substances and Properties, Authors and citations Generate a structure t from a name Commercial Availability
TIBCO Spotfire Lead Discovery 2.1 User s Manual
 TIBCO Spotfire Lead Discovery 2.1 User s Manual Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE
TIBCO Spotfire Lead Discovery 2.1 User s Manual Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE
University of Florida CISE department Gator Engineering. Data Preprocessing. Dr. Sanjay Ranka
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Chapter 5: Summary and Conclusion CHAPTER 5 SUMMARY AND CONCLUSION. Chapter 1: Introduction
 CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
Using Decision Boundary to Analyze Classifiers
 Using Decision Boundary to Analyze Classifiers Zhiyong Yan Congfu Xu College of Computer Science, Zhejiang University, Hangzhou, China yanzhiyong@zju.edu.cn Abstract In this paper we propose to use decision
Using Decision Boundary to Analyze Classifiers Zhiyong Yan Congfu Xu College of Computer Science, Zhejiang University, Hangzhou, China yanzhiyong@zju.edu.cn Abstract In this paper we propose to use decision
In this exercitation we will try to develop 3-D QSAR models on the molecules reported in a very recent paper, as displayed in the slide.
 1 In this exercitation we will try to develop 3-D QSAR models on the molecules reported in a very recent paper, as displayed in the slide. 2 These are the steps that will be covered in the tutorial 3 Before
1 In this exercitation we will try to develop 3-D QSAR models on the molecules reported in a very recent paper, as displayed in the slide. 2 These are the steps that will be covered in the tutorial 3 Before
Data Preprocessing. Data Preprocessing
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
IMS database application manual
 IMS database application manual The following manual includes standard operation procedures (SOP) for installation and usage of the IMS database application. Chapter 1 8 refer to Windows 7 operating systems
IMS database application manual The following manual includes standard operation procedures (SOP) for installation and usage of the IMS database application. Chapter 1 8 refer to Windows 7 operating systems
1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable!
 Project 1 140313 1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable! network.txt @attribute play {yes, no}!!! @graph! play -> outlook! play -> temperature!
Project 1 140313 1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable! network.txt @attribute play {yes, no}!!! @graph! play -> outlook! play -> temperature!
Jue Wang (Joyce) Department of Computer Science, University of Massachusetts, Boston Feb Outline
 Department of Computer Science, University of Massachusetts, Boston Feb Outline") Learn to Use Weka Jue Wang (Joyce) Department of Computer Science, University of Massachusetts, Boston Feb-09-2010 Outline Introduction of Weka Explorer Filter Classify Cluster Experimenter KnowledgeFlow
Learn to Use Weka Jue Wang (Joyce) Department of Computer Science, University of Massachusetts, Boston Feb-09-2010 Outline Introduction of Weka Explorer Filter Classify Cluster Experimenter KnowledgeFlow
A Comparative Study of Selected Classification Algorithms of Data Mining
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.220
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.220
A Cloud Framework for Big Data Analytics Workflows on Azure
 A Cloud Framework for Big Data Analytics Workflows on Azure Fabrizio MAROZZO a, Domenico TALIA a,b and Paolo TRUNFIO a a DIMES, University of Calabria, Rende (CS), Italy b ICAR-CNR, Rende (CS), Italy Abstract.
A Cloud Framework for Big Data Analytics Workflows on Azure Fabrizio MAROZZO a, Domenico TALIA a,b and Paolo TRUNFIO a a DIMES, University of Calabria, Rende (CS), Italy b ICAR-CNR, Rende (CS), Italy Abstract.