Tutorial: From chemical structures to outlier analysis. G. Marcou, D. Horvath, A. Varnek
|
|
|
- Beatrice Ball
- 5 years ago
- Views:
Transcription
1 Tutorial: From chemical structures to outlier analysis G. Marcou, D. Horvath, A. Varnek 1
2 Download your materials Download URL (tinyurl to Renater FileSender repository): ahttps://tinyurl.com/y99km3nd Content (<150Mo when unziped) asoftwares ExtCV.exe, xfragmentor.exe, xmodelanalyzerr.exe adatasets Datamining 5-HT2B (a database) Iter0 (tutorial directory) Iter1 (result after the tutorial) Pubmed Relevant articles 2
3 Introduction The IUPHAR 5-HT2B dataset a88 compounds aaffinity values pki, pkd Mostly human atype Agonist Antagonist abibliography PubMed Ids 3



4 5-HT2A Expressed in forebrain cerebral cortex Famous 5-HT2A agonist LSD Implicated in Flower Power 4


5 5-HT2C Expressed in CNS Example 5-HT2C antagonist Methysergide Implicated into: obesity, seizure, psychotic disorder 5



6 5-HT2B, the anti-target Expressed into Liver Kidney Heart Example ligands: PhenFen Benfluorex Drug induced valvular heart disease 6
7 Exercise 1 Goal: acreate a database of 5-HT2B ligand Software: ainstantjchem File aiuphar_5ht2b.sdf Output adirectory 5-HT2B

8 Create a local database

9 Configure local database

10 Load an SDF into the database
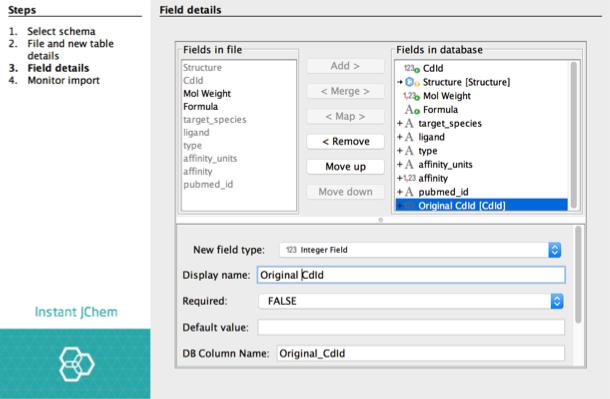
11 SDF field management

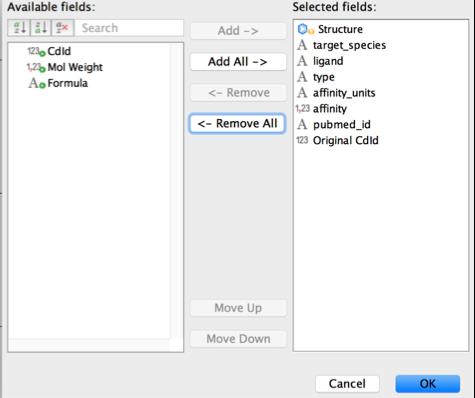
12 Grid view column management

13 Final state of the interface A database of 5-HT2B ligands Access to chemical structures, affinity, type, identifier, bibliographic references Possibility to edit the dataset: structures, instances and values
14 Exercise 2 Goal: aset up an External Cross-Validation procedure Software: aextcrossvalidate axfragmentor File aiuphar_5ht2b.sdf Output adirectories CVIteriFoldj, files train.sdf and test.sdf aisida Substructural Molecular Fragments, files *.hdr, *.svm, *.arff 14

15 Software: ExtCrossValidate 1 Select the IUPHAR_5HT2B.sdf file 2 Choose Cross Validation 3 Set 1 iteration to 1: k=1 and 4 folds: N=4 4 Uncheck the tick-box. Store all train and test sets into a folder named CV 15
16 External Cross-Validation 4- Fold Cross Validation Each compound is used once in a test set. Training and test sets are structural files. Dataset Fold1 Fold2 Fold3 Fold4 CV CV CV CV - trainiter1fold1.sdf - trainiter1fold2.sdf - trainiter1fold3.sdf - trainiter1fold4.sdf - testiter1fold1.sdf - testiter1fold2.sdf - testiter1fold3.sdf - testiter1fold4.sdf Each fold produces a dedicated training and test files in a directory named CV.
17 Software: xfragmentor 17
18 ISIDA fragments Sequences of atoms and bonds containing Nmin > 2 to Nmax < 15 atoms atoms and bonds Augmented atoms (a central atom and his direct neighbours) 18
19 ISIDA Substructural Molecular DataSet Fragments C-C-C-N-C-C C=O N(C)(C)(C) N(CO)(CC)(CC)... C-N-C-C*C Etc. ISIDA FRAGMENTOR the Pattern matrix 19
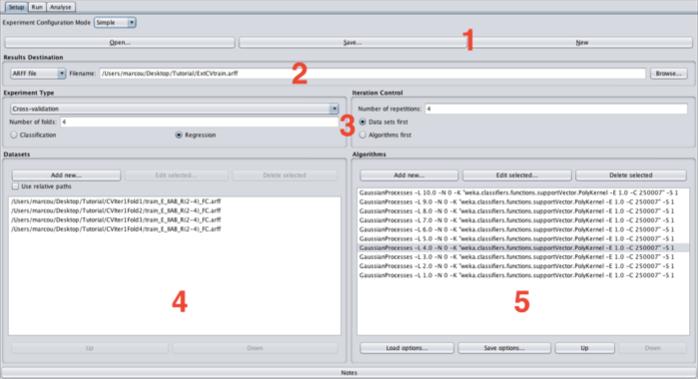
20 Compute training set descriptors Add SDF files (area 1) a IUPHAR_5-HT2B.sdf acv/trainiterifoldj.sdf Add Fragmentations (area 2) aatom count: E aatom centered of length 2 to 4: IIAB(2-4) ause formal charge: FC Save configuration aclick the Save XML button aname the file train_e_iiab_r(2-4)_fc.xml Click the Run button 20
21 Compute test set descriptors Remove all SDF files and add test SDF files (area 1) aremove IUPHAR_5-HT2B.sdf aremove CV/trainIteriFoldj.sdf aadd CV/testIteriFoldj.sdf Check the tickbox Use Predefined Fragments (area 3) aleave Basis name to default value or empty Use the Check button (optional) ayou should receive the message All hear files were found. Save configuration aclick the Save XML button aname the file test_e_iiab_r(2-4)_fc.xml Click the Run button 21

 files in sparse format.")

 files in sparse format, compatible")
22 Files created by xfragmentor XML: Configuration file. HDR: List of fragments. SVM: Molecular descriptors (attributes)/ Property value (value) files in sparse format. Each molecule correspond to one line, in order of appearance in the SDF file. ARFF: Molecular descriptors (attributes)/ Property value (value) files in sparse format, compatible with the Weka software. Concatenate information from HDR and SVM 22
23 Summary Division of the dataset into 4 sets of training and test structural files Calculation of the ISIDA Substructural Molecular Fragments descriptors aatom Count aatom Centered fragment including from 2 to 4 atoms aatoms and bonds standard annotation aformal Charge 23
24 Exercise 3 Goal: asetup Gaussian Processes models using only the training sets. Software: aweka/experimenter File acv/trainiterifoldj.sdf and CV/train_IteriFoldj_*.arff Output aextcvtrain.arff aextcvtrain.exp 24
25 Introduction to Gaussian Processes Goal: amodel a probability distribution of the property. Y train,y test are random vectors representing properties X train, X test are the molecular descriptors matrices Y train Y test = N 0, K(X train, X train )+1σ 2 K(X train, X test ) K(X test, X train ) K(X test, X test ) Parameters of the method ak(.,.) the kernel. In this tutorial, the linear kernel is used. aσ 2 the noise level. Closely related to the experimental noise on the property. 25
26 Inference of Gaussian Processes Two quantities are inferred for a test set athe mean vector Y test = K(X test, X train ) K(X train, X train )+1σ 2 1 Y train athe covariance 2 σ Y test = K(X test, X test ) K(X test, X train ) K(X train, X train )+1σ 2 1 K(X train, X test ) () Data points ( ) Mean vector ( ) +/- two variances 26
27 Weka/Experimenter 27

28 Weka/Experimenter aclick New. aresults destination: ExtCVtrain.arff a4-fold cross validation repeated 4 times. aexperiment type: Regression aadd the training files to the Datasets aadd the ZeroR method to the Algorithms aadd Gaussian Processes method to the Algorithms 28


29 Setup Gaussian Processes Add Gaussian Processes: no data transformations Noise level in the range [1..10] 29
30 Finalize the experiment Click the button Save asave you setup as ExtCVtrain.exp Click the Run tab, then Start Click the Analyse tab 30

31 Analyze the experiment on training data Click the Experiment button Set the Comparison field to Relative Absolute Error Click the Perform test button 31
32 Summary The optimum noise level is deduced only from the internal cross-validation on training sets. aoptimal value about 4 Different performances on different training sets amust be statistically demonstrated The test sets are fully independent. athe setup of the model building is complete without the help of the test sets 32
33 Exercise 4 Goal: aexternal validation of Gaussian Processes models. Software: aweka/experimenter File acv/trainiterifoldj.sdf and CV/trainIteriFoldj_*.arff acv/testiterifoldj.sdf and CV/testIteriFoldj_*.arff Output aextcvtrain.arff aextcvtrain.exp 33
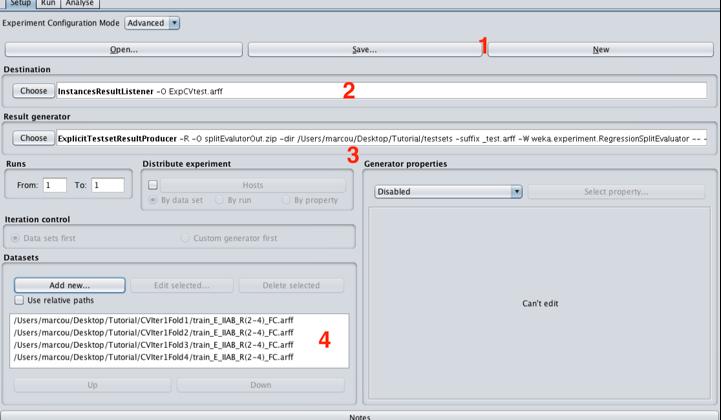
34 Weka/Experimenter Advanced mode

35 Weka/Experimenter Advanced mode Set the Destination to ExpCVtest.arff Set the Runs from 1 to 1 Check or set the Datasets

36 Setup the Results Generator (.*train \.sdf.*) CV test _E_IIAB_R(2-4)_FC.arff Set the value of RelationFind to (.*train \.sdf.*) Set the value of testsetprefix to test Set the value of testsetsuffix to _E_IIAB(2-4)_FC.arff Set the testsetdir to CV Click the RegressionSplitEvaluator
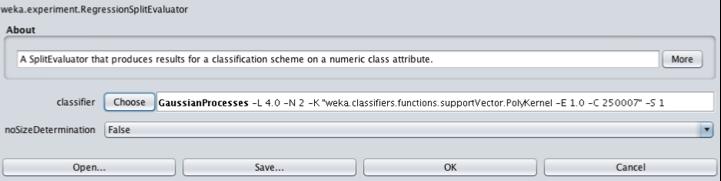
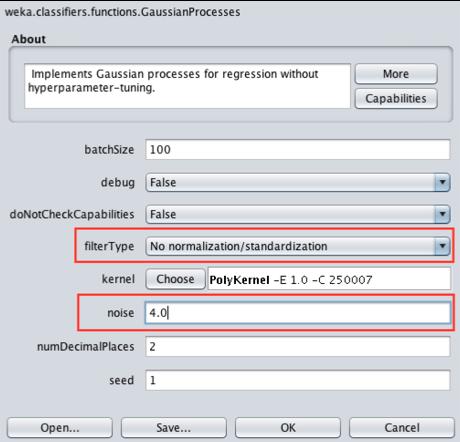
37 RegressionSplitEvaluator: GP with optimum noise level
38 Finalize the experiment Click the button Save asave you setup as ExtCVtrain.exp Click the Run tab, then Start Click the Analyse tab
39 Analyze the experiment on training data Click the Experiment button Set the Comparison field to Relative Absolute Error Click the Perform test button
40 Summary The optimum noise level is deduced only from the internal cross-validation on training sets. aoptimal value about 4 The configuration is used to validate the models on the test sets arelative absolute error about 80% Performances are dependent of the crossvalidation fold aare there outliers?
41 Goal: aoutlier identification Software: aweka/explorer axmodelanalyzerr ainstantjchem Files aarff files Output Exercise 4 alog files of Weka/Explorer anew SDF without an outlier.
42 Weka/Explorer Load the file IUPHAR_5HT2B_E_IIAB_R(2-4)_FC.arff
 Select the Cross-validation option and set the Folds value to 4.")
43 Setup a Gaussian Processes model Setup a Gaussian Processes model with an optimal noise value (for instance 4) Select the Cross-validation option and set the Folds value to 4. Click the Start button 43

44 Weka/Explorer Gaussian Processes Cross-Validation results Experiment summary Description of the model Cross-validation statistics
45 Setup a Gaussian Processes model Setup a Gaussian Processes model if needed Select the Supplied test set option and set the training file as test. This produces fitting results. Click the More options button.

46 Weka/Explorer classifier options Set the Output predictions to CSV. Click OK then click the button Start.

47 Weka/Explorer Gaussian Processes Fitting results Estimation for each instance aweka/explorer does not provide the covariance matrix. Fit performances. aas they are excellent, the outliers become visible aoutliers do not fit.


48 Save Wekaresult buffer Right click on the model s line Save your file as GP_Fit_all.out
49 xmoldelanalyzerr Open the file GP_Fit_all.out and the file IUPHAR_5HT2B.sdf. Click the OK button.
![Outlier detection Example of a single step procedure All points outside the [-3σ, 3σ] range.](/docs-images/88/116328272/images/50-0.jpg "aassumption: data follow a normal distribution.")
50 Outlier detection Example of a single step procedure All points outside the [-3σ, 3σ] range. aassumption: data follow a normal distribution. ahigh impact of outliers on the mean (μ) and standard deviation (σ) values.
51 Interval width and risk in outlier detection [ 3.5σ, 3.5σ ] Risk(%) u (sigma)
52 Interval width and risk in outlier detection [ 3σ,3σ ] Risk(%) u (sigma)
 u (sigma) 0.05 3.5 0.25 3 1.")
53 Interval width and risk in outlier detection [ 2.6σ, 2.6σ ] Risk(%) u (sigma)
 u (sigma) 0.05 3.5 0.25 3 1.00 2.6 5.00 1.")
54 Interval width and risk in outlier detection [ 1.96σ,1.96σ ] Risk(%) u (sigma)
![Interval width and risk in outlier detection [ σ,σ ]](/docs-images/88/116328272/images/55-0.jpg "Risk(%) u (sigma) 0.05 3.5 0.25 3 1.00 2.6 5.00 1.96 32.")
55 Interval width and risk in outlier detection [ σ,σ ] Risk(%) u (sigma)




56 Outlier detection Example of sequential procedure WR Thompson (?) Formulation of the test in 1935 FE Grubbs ES Pearson C Chandra Sekar Domain of validity of the test, 1936 Tables of critical values, 1950 The Grubbs test. acompute decision variables: G 1 = r r 1 s G N = r r N s acompute critical value: G c = N-1 N atake a decision: t 2 N-2+t 2 G 1 > G c r 1, outlier G N > G c r N, outlier t, α/2n fractile of student distribution with N-2 degrees of freedom


57 Outlier, compound 33 amelatonin apubid Outlier identification
58 Goal: aoutlier identification Software: aweka/explorer axmodelanalyzerr ainstantjchem Files aarff files Output Exercise 5 alog files of Weka/Explorer anew SDF without an outlier. 58

59 Remove Melatonin from the training set In InstantJChem software, click the Query button. Set the query field Origninal CdId to «not in list 50» - the Original CdId of Melatonin. Click the Run Query button. Click the export button. Save the exported SDF file as IUPHAR_5HT2B-33.sdf.
60 Fragment the curated dataset In the xfragmentor interface aif needed, click the Read XML button and read the file train_e_iiab_r(2-4)_fc.xml aremove all SDF files aadd the file IUPHA_5-HT2B- 33.sdf aclick the button Run.
61 Load the curated dataset into the Weka/Explorer software Load the file IUPHAR_5HT2B-33_E_IIAB_R(2-4)_FC.arff
62 Re-fit the Gaussian Processes model Setup a Gaussian Processes model if needed Select the Supplied test set option and set the training file as test. This produces fitting results. Click the More options button.
63 Re-evaluate the Gaussian Processes model Setup a Gaussian Processes model with an optimal noise value (for instance 4) Select the Cross-validation option and set the Folds value to 4. Click the Start button
")
64 Gaussian Processes model on currated dataset Fit Cross-validation Performances are (slightly) improved

65 Summary Single step procedure afast and simple afalse estimation of risk in outlier detection: Distribution parameters are distorted by outliers The risk estimation is valid for only one point. athe bigger the dataset is, the greater the chances to interpret a standard instance as outlier (false positive) P(X > a) = p P({x i x i > a} Sample) = Binomial(N, p) 65
66 Summary Sequential procedure afastidious the whole procedure repeats after each identified outlier. adistribution parameters are distorted by the outlier Use robust statistics resampling by the half-means method or by the smallest half-volume method Egon WJ, Morgan SL, Anal. Chem., 1998, 70(11), pages Identify multiple outliers arank instances by outlier likeliness Higher rank to instances that are consistently not fitted in consensus modeling 66
67 Conclusion Outlier detection may depend on data modeling amolecular Descriptors, Machine Learning method, atherefore, a consensus model-based approach may help (pick the outliers that are common to the several distinct models) Use internal and external cross-validation to avoid overfitting. Exploit the fitted values (rather than cross-validated predictions) for outlier detection An outlier not confirmed as anomalous cannot be discarded abut it may help understand the limitations of your model ait might be a discovery! 67

68 Thanks 68

69 Thank you 69
Short instructions on using Weka
 Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
Tutorial on Machine Learning. Impact of dataset composition on models performance. G. Marcou, N. Weill, D. Horvath, D. Rognan, A.
 Part 1. Tutorial on Machine Learning. Impact of dataset composition on models performance G. Marcou, N. Weill, D. Horvath, D. Rognan, A. Varnek 1 Introduction Predictive performance of QSAR model depends
Part 1. Tutorial on Machine Learning. Impact of dataset composition on models performance G. Marcou, N. Weill, D. Horvath, D. Rognan, A. Varnek 1 Introduction Predictive performance of QSAR model depends
Hands on Datamining & Machine Learning with Weka
 Step1: Click the Experimenter button to launch the Weka Experimenter. The Weka Experimenter allows you to design your own experiments of running algorithms on datasets, run the experiments and analyze
Step1: Click the Experimenter button to launch the Weka Experimenter. The Weka Experimenter allows you to design your own experiments of running algorithms on datasets, run the experiments and analyze
Software Documentation of the Potential Support Vector Machine
 Software Documentation of the Potential Support Vector Machine Tilman Knebel and Sepp Hochreiter Department of Electrical Engineering and Computer Science Technische Universität Berlin 10587 Berlin, Germany
Software Documentation of the Potential Support Vector Machine Tilman Knebel and Sepp Hochreiter Department of Electrical Engineering and Computer Science Technische Universität Berlin 10587 Berlin, Germany
Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5
 open-source software version 0.1.5") Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5 Version (date) Changes and comments 0.1.0 (02.02.2015) Changes from alpha version: 1. More precise default
Manual of SPCI (structural and physico-chemical interpretation) open-source software version 0.1.5 Version (date) Changes and comments 0.1.0 (02.02.2015) Changes from alpha version: 1. More precise default
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Introduction to ConQuest
 Introduction to ConQuest Version 1.5 October 2017 CSD v 5.39 Table of Contents Introduction... 2 Overview of ConQuest... 2 Introduction to the Draw Window... 3 ConQuest sketching conventions... 3 Example
Introduction to ConQuest Version 1.5 October 2017 CSD v 5.39 Table of Contents Introduction... 2 Overview of ConQuest... 2 Introduction to the Draw Window... 3 ConQuest sketching conventions... 3 Example
Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies
 Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies Anthony C. Arvanites Lead Discovery Informatics Company Introduction Founded: 1999 Platform: Combining
Rapid Application Development using InforSense Open Workflow and Oracle Chemistry Cartridge Technologies Anthony C. Arvanites Lead Discovery Informatics Company Introduction Founded: 1999 Platform: Combining
DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES
 EXPERIMENTAL WORK PART I CHAPTER 6 DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES The evaluation of models built using statistical in conjunction with various feature subset
EXPERIMENTAL WORK PART I CHAPTER 6 DESIGN AND EVALUATION OF MACHINE LEARNING MODELS WITH STATISTICAL FEATURES The evaluation of models built using statistical in conjunction with various feature subset
Harris: Quantitative Chemical Analysis, Eight Edition CHAPTER 05: QUALITY ASSURANCE AND CALIBRATION METHODS
 Harris: Quantitative Chemical Analysis, Eight Edition CHAPTER 05: QUALITY ASSURANCE AND CALIBRATION METHODS 5-0. International Measurement Evaluation Program Sample: Pb in river water (blind sample) :
Harris: Quantitative Chemical Analysis, Eight Edition CHAPTER 05: QUALITY ASSURANCE AND CALIBRATION METHODS 5-0. International Measurement Evaluation Program Sample: Pb in river water (blind sample) :
KNIME Enalos+ Molecular Descriptor nodes
 KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
Analyzing ICAT Data. Analyzing ICAT Data
 Analyzing ICAT Data Gary Van Domselaar University of Alberta Analyzing ICAT Data ICAT: Isotope Coded Affinity Tag Introduced in 1999 by Ruedi Aebersold as a method for quantitative analysis of complex
Analyzing ICAT Data Gary Van Domselaar University of Alberta Analyzing ICAT Data ICAT: Isotope Coded Affinity Tag Introduced in 1999 by Ruedi Aebersold as a method for quantitative analysis of complex
ChemBioFinder for Office 13.0 User Guide
 User Guide Table of Contents Chapter 1: ChemBioFinder for Office 13.0 1 The user interface (UI) 1 Selecting files to search 2 Searching by chemical structure 3 Searching by multiple properties 4 Browsing
User Guide Table of Contents Chapter 1: ChemBioFinder for Office 13.0 1 The user interface (UI) 1 Selecting files to search 2 Searching by chemical structure 3 Searching by multiple properties 4 Browsing
Using CSD-CrossMiner to Create a Feature Database
 Table of Contents Introduction... 2 CSD-CrossMiner Terminology... 2 Overview of CSD-CrossMiner... 3 Features and Pharmacophore Representation... 4 Building your Own Feature Database... 5 Using CSD-CrossMiner
Table of Contents Introduction... 2 CSD-CrossMiner Terminology... 2 Overview of CSD-CrossMiner... 3 Features and Pharmacophore Representation... 4 Building your Own Feature Database... 5 Using CSD-CrossMiner
The Explorer. chapter Getting started
 chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
STATS PAD USER MANUAL
 STATS PAD USER MANUAL For Version 2.0 Manual Version 2.0 1 Table of Contents Basic Navigation! 3 Settings! 7 Entering Data! 7 Sharing Data! 8 Managing Files! 10 Running Tests! 11 Interpreting Output! 11
STATS PAD USER MANUAL For Version 2.0 Manual Version 2.0 1 Table of Contents Basic Navigation! 3 Settings! 7 Entering Data! 7 Sharing Data! 8 Managing Files! 10 Running Tests! 11 Interpreting Output! 11
AutoDock Virtual Screening: Raccoon & Fox Tools
 AutoDock Virtual Screening: Raccoon & Fox Tools Stefano Forli Ruth Huey The Scripps Research Institute Molecular Graphics Laboratory 10550 N. Torrey Pines Rd. La Jolla, California 92037-1000 USA 3 December
AutoDock Virtual Screening: Raccoon & Fox Tools Stefano Forli Ruth Huey The Scripps Research Institute Molecular Graphics Laboratory 10550 N. Torrey Pines Rd. La Jolla, California 92037-1000 USA 3 December
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Noise-based Feature Perturbation as a Selection Method for Microarray Data
 Noise-based Feature Perturbation as a Selection Method for Microarray Data Li Chen 1, Dmitry B. Goldgof 1, Lawrence O. Hall 1, and Steven A. Eschrich 2 1 Department of Computer Science and Engineering
Noise-based Feature Perturbation as a Selection Method for Microarray Data Li Chen 1, Dmitry B. Goldgof 1, Lawrence O. Hall 1, and Steven A. Eschrich 2 1 Department of Computer Science and Engineering
COMP s1 - Getting started with the Weka Machine Learning Toolkit
 COMP9417 16s1 - Getting started with the Weka Machine Learning Toolkit Last revision: Thu Mar 16 2016 1 Aims This introduction is the starting point for Assignment 1, which requires the use of the Weka
COMP9417 16s1 - Getting started with the Weka Machine Learning Toolkit Last revision: Thu Mar 16 2016 1 Aims This introduction is the starting point for Assignment 1, which requires the use of the Weka
Application of Support Vector Machine In Bioinformatics
 Application of Support Vector Machine In Bioinformatics V. K. Jayaraman Scientific and Engineering Computing Group CDAC, Pune jayaramanv@cdac.in Arun Gupta Computational Biology Group AbhyudayaTech, Indore
Application of Support Vector Machine In Bioinformatics V. K. Jayaraman Scientific and Engineering Computing Group CDAC, Pune jayaramanv@cdac.in Arun Gupta Computational Biology Group AbhyudayaTech, Indore
Classification using Weka (Brain, Computation, and Neural Learning)
") LOGO Classification using Weka (Brain, Computation, and Neural Learning) Jung-Woo Ha Agenda Classification General Concept Terminology Introduction to Weka Classification practice with Weka Problems: Pima
LOGO Classification using Weka (Brain, Computation, and Neural Learning) Jung-Woo Ha Agenda Classification General Concept Terminology Introduction to Weka Classification practice with Weka Problems: Pima
Beilstein (Elsevier/MDL CrossFire Commander 7.1)
") Introduction Beilstein (Elsevier/MDL CrossFire Commander 7.1) Beilstein vs. SciFinder Scholar As two of the most important databases in chemistry, Beilstein and SciFinder Scholar serve different needs.
Introduction Beilstein (Elsevier/MDL CrossFire Commander 7.1) Beilstein vs. SciFinder Scholar As two of the most important databases in chemistry, Beilstein and SciFinder Scholar serve different needs.
Machine Learning for. Artem Lind & Aleskandr Tkachenko
 Machine Learning for Object Recognition Artem Lind & Aleskandr Tkachenko Outline Problem overview Classification demo Examples of learning algorithms Probabilistic modeling Bayes classifier Maximum margin
Machine Learning for Object Recognition Artem Lind & Aleskandr Tkachenko Outline Problem overview Classification demo Examples of learning algorithms Probabilistic modeling Bayes classifier Maximum margin
TIBCO Spotfire Lead Discovery 2.1 User s Manual
 TIBCO Spotfire Lead Discovery 2.1 User s Manual Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE
TIBCO Spotfire Lead Discovery 2.1 User s Manual Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE
Gaussian Processes for Robotics. McGill COMP 765 Oct 24 th, 2017
 Gaussian Processes for Robotics McGill COMP 765 Oct 24 th, 2017 A robot must learn Modeling the environment is sometimes an end goal: Space exploration Disaster recovery Environmental monitoring Other
Gaussian Processes for Robotics McGill COMP 765 Oct 24 th, 2017 A robot must learn Modeling the environment is sometimes an end goal: Space exploration Disaster recovery Environmental monitoring Other
Tutorial 2: Analysis of DIA/SWATH data in Skyline
 Tutorial 2: Analysis of DIA/SWATH data in Skyline In this tutorial we will learn how to use Skyline to perform targeted post-acquisition analysis for peptide and inferred protein detection and quantification.
Tutorial 2: Analysis of DIA/SWATH data in Skyline In this tutorial we will learn how to use Skyline to perform targeted post-acquisition analysis for peptide and inferred protein detection and quantification.
CPSC 340: Machine Learning and Data Mining. Probabilistic Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
Agilent G6825AA METLIN Personal Metabolite Database for MassHunter Workstation
 Agilent G6825AA METLIN Personal Metabolite Database for MassHunter Workstation Quick Start Guide This guide describes how to install and use METLIN Personal Metabolite Database for MassHunter Workstation.
Agilent G6825AA METLIN Personal Metabolite Database for MassHunter Workstation Quick Start Guide This guide describes how to install and use METLIN Personal Metabolite Database for MassHunter Workstation.
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Data Mining. Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka. I. Data sets. I.1. Data sets characteristics and formats
 Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
UNIBALANCE Users Manual. Marcin Macutkiewicz and Roger M. Cooke
 UNIBALANCE Users Manual Marcin Macutkiewicz and Roger M. Cooke Deflt 2006 1 1. Installation The application is delivered in the form of executable installation file. In order to install it you have to
UNIBALANCE Users Manual Marcin Macutkiewicz and Roger M. Cooke Deflt 2006 1 1. Installation The application is delivered in the form of executable installation file. In order to install it you have to
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Skyline High Resolution Metabolomics (Draft)
") Skyline High Resolution Metabolomics (Draft) The Skyline Targeted Proteomics Environment provides informative visual displays of the raw mass spectrometer data you import into your Skyline documents. Originally
Skyline High Resolution Metabolomics (Draft) The Skyline Targeted Proteomics Environment provides informative visual displays of the raw mass spectrometer data you import into your Skyline documents. Originally
Support Vector Machines
 Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
User Guide Written By Yasser EL-Manzalawy
 User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
Final Report: Kaggle Soil Property Prediction Challenge
 Final Report: Kaggle Soil Property Prediction Challenge Saurabh Verma (verma076@umn.edu, (612)598-1893) 1 Project Goal Low cost and rapid analysis of soil samples using infrared spectroscopy provide new
Final Report: Kaggle Soil Property Prediction Challenge Saurabh Verma (verma076@umn.edu, (612)598-1893) 1 Project Goal Low cost and rapid analysis of soil samples using infrared spectroscopy provide new
KNIME Enalos+ Modelling nodes
 KNIME Enalos+ Modelling nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step 2-Building
KNIME Enalos+ Modelling nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step 2-Building
Some questions of consensus building using co-association
 Some questions of consensus building using co-association VITALIY TAYANOV Polish-Japanese High School of Computer Technics Aleja Legionow, 4190, Bytom POLAND vtayanov@yahoo.com Abstract: In this paper
Some questions of consensus building using co-association VITALIY TAYANOV Polish-Japanese High School of Computer Technics Aleja Legionow, 4190, Bytom POLAND vtayanov@yahoo.com Abstract: In this paper
Importing data in a database with levels
 BioNumerics Tutorial: Importing data in a database with levels 1 Aim In this tutorial you will learn how to import data in a BioNumerics database with levels and how to replicate and summarize level-specific
BioNumerics Tutorial: Importing data in a database with levels 1 Aim In this tutorial you will learn how to import data in a BioNumerics database with levels and how to replicate and summarize level-specific
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Unsupervised Discretization using Tree-based Density Estimation
 Unsupervised Discretization using Tree-based Density Estimation Gabi Schmidberger and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {gabi, eibe}@cs.waikato.ac.nz
Unsupervised Discretization using Tree-based Density Estimation Gabi Schmidberger and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {gabi, eibe}@cs.waikato.ac.nz
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp
 CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
Correctly Compute Complex Samples Statistics
 SPSS Complex Samples 15.0 Specifications Correctly Compute Complex Samples Statistics When you conduct sample surveys, use a statistics package dedicated to producing correct estimates for complex sample
SPSS Complex Samples 15.0 Specifications Correctly Compute Complex Samples Statistics When you conduct sample surveys, use a statistics package dedicated to producing correct estimates for complex sample
Agilent G6854AA MassHunter Personal Compound Database
 Agilent G6854AA MassHunter Personal Compound Database Quick Start Guide This guide describes how to install and use MassHunter Personal Compound Database. Where to find more information What is Personal
Agilent G6854AA MassHunter Personal Compound Database Quick Start Guide This guide describes how to install and use MassHunter Personal Compound Database. Where to find more information What is Personal
Assignment 4 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran
 Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran") Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Cover Page. The handle holds various files of this Leiden University dissertation.
 Cover Page The handle http://hdl.handle.net/1887/22055 holds various files of this Leiden University dissertation. Author: Koch, Patrick Title: Efficient tuning in supervised machine learning Issue Date:
Cover Page The handle http://hdl.handle.net/1887/22055 holds various files of this Leiden University dissertation. Author: Koch, Patrick Title: Efficient tuning in supervised machine learning Issue Date:
08 An Introduction to Dense Continuous Robotic Mapping
 NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Supervised classification exercice
 Universitat Politècnica de Catalunya Master in Artificial Intelligence Computational Intelligence Supervised classification exercice Authors: Miquel Perelló Nieto Marc Albert Garcia Gonzalo Date: December
Universitat Politècnica de Catalunya Master in Artificial Intelligence Computational Intelligence Supervised classification exercice Authors: Miquel Perelló Nieto Marc Albert Garcia Gonzalo Date: December
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Artificial Neural Networks (Feedforward Nets)
") Artificial Neural Networks (Feedforward Nets) y w 03-1 w 13 y 1 w 23 y 2 w 01 w 21 w 22 w 02-1 w 11 w 12-1 x 1 x 2 6.034 - Spring 1 Single Perceptron Unit y w 0 w 1 w n w 2 w 3 x 0 =1 x 1 x 2 x 3... x
Artificial Neural Networks (Feedforward Nets) y w 03-1 w 13 y 1 w 23 y 2 w 01 w 21 w 22 w 02-1 w 11 w 12-1 x 1 x 2 6.034 - Spring 1 Single Perceptron Unit y w 0 w 1 w n w 2 w 3 x 0 =1 x 1 x 2 x 3... x
Quick Reference Guide
 Quick Reference Guide Table of Contents Homepage My Settings Generate a Structure from a Name Reactions Query tab Query tab Add further Search Conditions Results General Overview 7 Results Reactions tab
Quick Reference Guide Table of Contents Homepage My Settings Generate a Structure from a Name Reactions Query tab Query tab Add further Search Conditions Results General Overview 7 Results Reactions tab
Data mining with sparse grids
 Data mining with sparse grids Jochen Garcke and Michael Griebel Institut für Angewandte Mathematik Universität Bonn Data mining with sparse grids p.1/40 Overview What is Data mining? Regularization networks
Data mining with sparse grids Jochen Garcke and Michael Griebel Institut für Angewandte Mathematik Universität Bonn Data mining with sparse grids p.1/40 Overview What is Data mining? Regularization networks
Customisable Curation Workflows in Argo
 Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
Customisable Curation Workflows in Argo Rafal Rak*, Riza Batista-Navarro, Andrew Rowley, Jacob Carter and Sophia Ananiadou National Centre for Text Mining, University of Manchester, UK *Corresponding author:
Machine Learning and Bioinformatics 機器學習與生物資訊學
 Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Support Vector Machines + Classification for IR
 Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
static MM_Index snap(mm_index corect, MM_Index ligct, int imatch0, int *moleatoms, i
 GLIDE static MM_Index snap(mm_index corect, MM_Index ligct, int imatch0, int *moleatoms, int *refcoreatoms){int ncoreat = :vector mappings; PhpCoreMapping mapping; for COMMON(glidelig).
GLIDE static MM_Index snap(mm_index corect, MM_Index ligct, int imatch0, int *moleatoms, int *refcoreatoms){int ncoreat = :vector mappings; PhpCoreMapping mapping; for COMMON(glidelig).
Tutorial Case studies
 1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
ChemFinder for Office 17.0 User Guide
 User Guide Table of Contents Chapter 1: ChemFinder for Office 1 The user interface (UI) 1 Selecting files to search 2 Searching by chemical structure 3 Searching by multiple properties 4 Browsing search
User Guide Table of Contents Chapter 1: ChemFinder for Office 1 The user interface (UI) 1 Selecting files to search 2 Searching by chemical structure 3 Searching by multiple properties 4 Browsing search
Robust Regression. Robust Data Mining Techniques By Boonyakorn Jantaranuson
 Robust Regression Robust Data Mining Techniques By Boonyakorn Jantaranuson Outline Introduction OLS and important terminology Least Median of Squares (LMedS) M-estimator Penalized least squares What is
Robust Regression Robust Data Mining Techniques By Boonyakorn Jantaranuson Outline Introduction OLS and important terminology Least Median of Squares (LMedS) M-estimator Penalized least squares What is
SGN (4 cr) Chapter 10
 Chapter 10") SGN-41006 (4 cr) Chapter 10 Feature Selection and Extraction Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 18, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
SGN-41006 (4 cr) Chapter 10 Feature Selection and Extraction Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 18, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
Chap.12 Kernel methods [Book, Chap.7]
![Chap.12 Kernel methods [Book, Chap.7]](/thumbs/83/87786394.jpg "Chap.12 Kernel methods [Book, Chap.7]") Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
AI32 Guide to Weka. Andrew Roberts 1st March 2005
 AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
Analyzing Genomic Data with NOJAH
 Analyzing Genomic Data with NOJAH TAB A) GENOME WIDE ANALYSIS Step 1: Select the example dataset or upload your own. Two example datasets are available. Genome-Wide TCGA-BRCA Expression datasets and CoMMpass
Analyzing Genomic Data with NOJAH TAB A) GENOME WIDE ANALYSIS Step 1: Select the example dataset or upload your own. Two example datasets are available. Genome-Wide TCGA-BRCA Expression datasets and CoMMpass
StatCalc User Manual. Version 9 for Mac and Windows. Copyright 2018, AcaStat Software. All rights Reserved.
 StatCalc User Manual Version 9 for Mac and Windows Copyright 2018, AcaStat Software. All rights Reserved. http://www.acastat.com Table of Contents Introduction... 4 Getting Help... 4 Uninstalling StatCalc...
StatCalc User Manual Version 9 for Mac and Windows Copyright 2018, AcaStat Software. All rights Reserved. http://www.acastat.com Table of Contents Introduction... 4 Getting Help... 4 Uninstalling StatCalc...
EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm
 EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm Group 1: Mina A. Makar Stanford University mamakar@stanford.edu Abstract In this report, we investigate the application of the Scale-Invariant
EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm Group 1: Mina A. Makar Stanford University mamakar@stanford.edu Abstract In this report, we investigate the application of the Scale-Invariant
Deep Tensor: Eliciting New Insights from Graph Data that Express Relationships between People and Things
 Deep Tensor: Eliciting New Insights from Graph Data that Express Relationships between People and Things Koji Maruhashi An important problem in information and communications technology (ICT) is classifying
Deep Tensor: Eliciting New Insights from Graph Data that Express Relationships between People and Things Koji Maruhashi An important problem in information and communications technology (ICT) is classifying
Data Mining Practical Machine Learning Tools and Techniques. Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
3D Object Recognition using Multiclass SVM-KNN
 3D Object Recognition using Multiclass SVM-KNN R. Muralidharan, C. Chandradekar April 29, 2014 Presented by: Tasadduk Chowdhury Problem We address the problem of recognizing 3D objects based on various
3D Object Recognition using Multiclass SVM-KNN R. Muralidharan, C. Chandradekar April 29, 2014 Presented by: Tasadduk Chowdhury Problem We address the problem of recognizing 3D objects based on various
Enterprise Data Catalog for Microsoft Azure Tutorial
 Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Perform the following steps to set up for this project. Start out in your login directory on csit (a.k.a. acad).
.") CSC 458 Data Mining and Predictive Analytics I, Fall 2017 (November 22, 2017) Dr. Dale E. Parson, Assignment 4, Comparing Weka Bayesian, clustering, ZeroR, OneR, and J48 models to predict nominal dissolved
CSC 458 Data Mining and Predictive Analytics I, Fall 2017 (November 22, 2017) Dr. Dale E. Parson, Assignment 4, Comparing Weka Bayesian, clustering, ZeroR, OneR, and J48 models to predict nominal dissolved
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
A Comparative Study of Selected Classification Algorithms of Data Mining
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.220
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.220
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
OECD QSAR Toolbox v.4.1. Example illustrating endpoint vs. endpoint correlation using ToxCast data
 OECD QSAR Toolbox v.4.1 Example illustrating endpoint vs. endpoint correlation using ToxCast data Outlook Background Objectives The exercise Workflow 2 Background This presentation is designed to introduce
OECD QSAR Toolbox v.4.1 Example illustrating endpoint vs. endpoint correlation using ToxCast data Outlook Background Objectives The exercise Workflow 2 Background This presentation is designed to introduce
Subject. Dataset. Copy paste feature of the diagram. Importing the dataset. Copy paste feature into the diagram.
 Subject Copy paste feature into the diagram. When we define the data analysis process into Tanagra, it is possible to copy components (or entire branches of components) towards another location into the
Subject Copy paste feature into the diagram. When we define the data analysis process into Tanagra, it is possible to copy components (or entire branches of components) towards another location into the
Chapters 5-6: Statistical Inference Methods
 Chapters 5-6: Statistical Inference Methods Chapter 5: Estimation (of population parameters) Ex. Based on GSS data, we re 95% confident that the population mean of the variable LONELY (no. of days in past
Chapters 5-6: Statistical Inference Methods Chapter 5: Estimation (of population parameters) Ex. Based on GSS data, we re 95% confident that the population mean of the variable LONELY (no. of days in past
How to Create a Substance Answer Set
 How to Create a Substance Answer Set Select among five search techniques to find substances Substances can be described by multiple names or other characteristics, so SciFinder gives you the flexibility
How to Create a Substance Answer Set Select among five search techniques to find substances Substances can be described by multiple names or other characteristics, so SciFinder gives you the flexibility
REALCOM-IMPUTE: multiple imputation using MLwin. Modified September Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol
 REALCOM-IMPUTE: multiple imputation using MLwin. Modified September 2014 by Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol This description is divided into two sections. In the
REALCOM-IMPUTE: multiple imputation using MLwin. Modified September 2014 by Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol This description is divided into two sections. In the
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Lead Discovery 5.2. User Guide. Powered by TIBCO Spotfire
 User Guide Powered by TIBCO Spotfire Last Modified: July 26, 2013 Table of Contents 1. Introduction... 5 2. Loading Data... 6 2.1. Opening an SDFile... 6 2.2. Importing a ChemDraw for Excel File... 6 2.3.
User Guide Powered by TIBCO Spotfire Last Modified: July 26, 2013 Table of Contents 1. Introduction... 5 2. Loading Data... 6 2.1. Opening an SDFile... 6 2.2. Importing a ChemDraw for Excel File... 6 2.3.
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Introduction The problem of cancer classication has clear implications on cancer treatment. Additionally, the advent of DNA microarrays introduces a w
 MASSACHUSETTS INSTITUTE OF TECHNOLOGY ARTIFICIAL INTELLIGENCE LABORATORY and CENTER FOR BIOLOGICAL AND COMPUTATIONAL LEARNING DEPARTMENT OF BRAIN AND COGNITIVE SCIENCES A.I. Memo No.677 C.B.C.L Paper No.8
MASSACHUSETTS INSTITUTE OF TECHNOLOGY ARTIFICIAL INTELLIGENCE LABORATORY and CENTER FOR BIOLOGICAL AND COMPUTATIONAL LEARNING DEPARTMENT OF BRAIN AND COGNITIVE SCIENCES A.I. Memo No.677 C.B.C.L Paper No.8
Bagging for One-Class Learning
 Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Voxel selection algorithms for fmri
 Voxel selection algorithms for fmri Henryk Blasinski December 14, 2012 1 Introduction Functional Magnetic Resonance Imaging (fmri) is a technique to measure and image the Blood- Oxygen Level Dependent
Voxel selection algorithms for fmri Henryk Blasinski December 14, 2012 1 Introduction Functional Magnetic Resonance Imaging (fmri) is a technique to measure and image the Blood- Oxygen Level Dependent
DATA ANALYSIS WITH WEKA. Author: Nagamani Mutteni Asst.Professor MERI
 DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION. Prateek Verma, Yang-Kai Lin, Li-Fan Yu. Stanford University
 TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
Chapter 5: Outlier Detection
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 5: Outlier Detection Lecture: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 5: Outlier Detection Lecture: Prof. Dr.
INTRODUCTION TO DATA MINING. Daniel Rodríguez, University of Alcalá
 INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
The Power and Sample Size Application
 Chapter 72 The Power and Sample Size Application Contents Overview: PSS Application.................................. 6148 SAS Power and Sample Size............................... 6148 Getting Started:
Chapter 72 The Power and Sample Size Application Contents Overview: PSS Application.................................. 6148 SAS Power and Sample Size............................... 6148 Getting Started:
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D.
 PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
Automated Microarray Classification Based on P-SVM Gene Selection
 Automated Microarray Classification Based on P-SVM Gene Selection Johannes Mohr 1,2,, Sambu Seo 1, and Klaus Obermayer 1 1 Berlin Institute of Technology Department of Electrical Engineering and Computer
Automated Microarray Classification Based on P-SVM Gene Selection Johannes Mohr 1,2,, Sambu Seo 1, and Klaus Obermayer 1 1 Berlin Institute of Technology Department of Electrical Engineering and Computer
Introduction to BEST Viewpoints
 Introduction to BEST Viewpoints This is not all but just one of the documentation files included in BEST Viewpoints. Introduction BEST Viewpoints is a user friendly data manipulation and analysis application
Introduction to BEST Viewpoints This is not all but just one of the documentation files included in BEST Viewpoints. Introduction BEST Viewpoints is a user friendly data manipulation and analysis application