CORA COmmon Reference Architecture
|
|
|
- Nathan Dennis
- 5 years ago
- Views:
Transcription
1 CORA COmmon Reference Architecture Monica Scannapieco Istat Carlo Vaccari Università di Camerino Antonino Virgillito Istat
2 Outline Introduction (90 mins) CORE Design (60 mins) CORE Architectural Components (90 mins) Illustration of CORE Platform (135 mins) Case studies (90 mins) CORE Follow-up (60 mins)
3 Introduction
4 CORE Generalities Principal Outcome: Environment for the definition and execution of standard statistical processes Definition of a process in terms of available services Execution of the composed workflow
5 CORE Generalities Plug and play approach to process execution Process View Service Repository
6 CORE Generalities Plug and play approach to process execution Process View Service Repository Data View
7 Why CORE? START Allocation (MAUSS R) Estimation (ReGenesees) Selection (SAS Script) STOP
8 Why CORE? START Allocation (MAUSS R) Estimation (ReGenesees) Selection (SAS Script) STOP
9 Why CORE? START Technological Heterogeneity Different technologies Different formats Allocation (MAUSS R) Estimation (ReGenesees) Selection (SAS Script) STOP
10 Why CORE? START Technological Heterogeneity Data Allocation Heterogeneity (MAUSS R) Different technologies Different formats Different names for variables Variables as combinations of other variables... Estimation (ReGenesees) Selection (SAS Script) STOP
11 Why CORE? Technological heterogeneity can be solved by solutions available on the market CORE permits to solve both technological and data heterogeneity in a single environment
12 CORE Vision 1. Abstract services: well-defined, technology-independent functionalities implemented by different IT tools; 2. Statistical process: workflow defined in terms of available services; 3. Data model: standardization of the semantics/format of services data, i.e. definition of the domain entities involved as input/output between services.
13 CORE Vision 1. Abstract services: well-defined, technologyindependent functionalities implemented by IT tools Allocation (MAUSS R) Estimation (ReGenesees) Selection (SAS Script)
14 CORE Vision 3. Data model: standardization of the semantics/format of services data 3.1 Domain descriptor (DD) Allocation (MAUSS R) DD <schema name="demo_dd"> <entity name="sampleplan"> <property name="var"/> <property name="size"/>... </entity> </schema> Selection (SAS Script) 3.2 Mapping to/from DD

15 CORE Design Tasks - 1 Design of services Definition of integration APIs (IAPIs) Data conversion from/to CORA model to/from tool specific format Graphical front ends for designing schemas and mappings
16 CORE Design Tasks - 2 Design of processes How to define and execute processes within CORE Modelling language Execution Visual interfaces design Design of a service repository
17 CORE Design Tasks - 3 Design of exchanged data Definition of data models and formats (plain XML/XSD, SDMX ) to be used for data exchanges Definition of metadata necessary for process execution SDMX Relationships
18 CORE Design
19 CORE Design: Services Abstract services: specify a well-defined functionality in a technology-independent way An abstract service can be implemented by one or more concrete services, i.e. IT tools Examples: sample allocation, record linkage, estimates and errors computation, etc.
20 CORE Design: Services GSBPM classification Documentation purpose Provided that a CORE service can be linked to IT tools, GSBPM tagging enables the performance of a search e.g. retrieving all the IT tools implementing the 5.4 Impute subprocess of GSBPM proposal
21 CORE Design: Services Service inputs and outputs Specified by logical names Characterized with respect to their role in data exchange Non-CORE: if they are not provided by/to other services of the process, but are only local to a specific service CORE: they are passed by/to other services and hence they do need to undergo CORE transformations
22 CORE Design: Data and Metadata They are specified as service inputs and outputs Logical names link them to previously specified services Non-CORE data only need the file system path where they can be retrieved
23 CORE Design: CORE Data The specification of CORE data is provided by 3 elements: Domain descriptor CORE data model Mapping model
24 Domain Descriptor: Model Entity Like entities in Entity Relationships Entity properties Like attributes in Entity Relationships Very simple (meta-)model
25 Domain Descriptor: Example <schema name="demo_domain_descriptor"> <entity name="sampleplan"> <property name="stratification_var"/> <property name="stratum_sample_size"/> <property name="stratum_population_size"/> </entity> <entity name="enterprise"> <property name="identifier"/> <property name="stratification_var"/> <property name="weight"/> <property name="sampling_fraction"/> <property name="enterprise_flag"/> <property name="employees_num"/> <property name="value_added"/> <property name="area"/> </entity> </schema>
26 Domain Descriptor Role Role of the Domain Descriptor (DD): from service-to-service data mapping to service-toglobal data mapping
27 CORE Data Model: Role Specified once and valid for all processes Extensible, i.e. core tag, data set kind, column kind can be modified Adds more semantics to data Example of usage: mapping to other models
28 CORE Data Model Rectangular data set CORE tag: Data set level (mandatory) Column level (optional) Rows level (optional) Data set kind Column kind
29 CORE Data Model Role Specified once and valid for all processes Extensible, i.e. core tag, data set kind, column kind can be modified Adds more semantics to data Example of usage: mapping to other models
30 Mapping Model Rectangular data assumption Mapping is intended to be specified with respect to Domain Descriptor Columns are to be mapped to properties of an entity It contains the specification of how CORE data model concepts are associated to data

31 CORE Logical Architecture
32 CORE GUIs Process design Ad-hoc customization of an existing tool (Oryx) Service data flow Service design Set of interfaces for the definition of services and related data flow Data design Set of interfaces for the specification of domain descriptors and mapping files
33 Use Case Specification CORE (Principal) Users 33
34 Use Case Specification: Tool Management 34
35 Use Case Specification: Service Management Statistical User Service Management «uses» Add Service «uses» «uses» Show Tools' List «uses» Modify Service «uses» «uses» Delete Service SelectTool Show Services' List «uses» Select Service 35
36 Use Case Specification: Process 36
37 Process design: Oryx Oryx is an academic open source framework for graphical process modeling Based on web technology Extensible via a plugin mechanism and new stencil sets Supports BPMN and other process modeling languages Programming language Javascript and Java, internal data format based on RDF
38 Stencil Set Set of graphical objects and rules that specify how to relate those graphical objects to others Additional properties that can later be used by other applications or Oryx extensions (e.g. setting element colors and visibility) Can be used to build process models
39 The CORE Stencil Set Graphical representation of CORE processes Easy-to-use editor (desktop feeling) Easy-to-extend source (JSON) Defined from BPMN Guarantees complete BPMN compliance

40 Integration APIs Purpose: wrapping a tool by a CORE service Translates inputs and outputs of the tool in a completely transparent and automatic way
41 Repository Processes and their instances Services with their GSBPM and CORE classifications Tools and their runtime features Data with their logical classification within CORE processes
42 Database design: Overview 42
43 Database Design: Principal Entities Service & Tool 43
44 Database Design: Principal Entities Service & Process service -id -name -GSBPMtag -coretag -version -namespace 0..* 0..* process -id -name -definition 44
45 Database Design: Principal Entities Operational Data 45
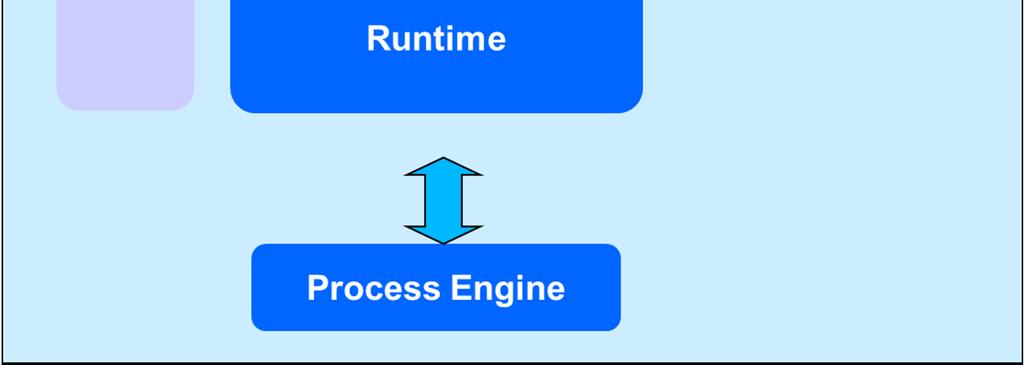
46 Process Engine Official statistics processes can be viewed from two perspectives: Functional: they are data-oriented, reflecting a common feature of scientific workflows Organizational: they are workflow-oriented, have the complexity of real production lines, with the need for harmonizing the work of different actors
47 Process Engine Hence our process engine has two layers WF ENGINE DATA FLOW CONTROL SYSTEM Complex control flows Syncronizing constructs, cycles, conditions, etc. E.g.: Interactive multi-user editing imputation Simple control flows Sequence of tasks is composed by connecting the output of one task to the input of another Data intensive operations
48 Worflow Engine Selection Process CORE workpackage (WP$) led by INSEE Business Process Management (BPM) platforms: Bonita ( Activiti ( ActiveVOS (

49 Worflow Engine Selection Process
50 SDMX Relationships Both propose an information model CORE information model takes explicitly process dimension into account Data dimension spanning over the whole statistical process SDMX information model focused on data exchange (though processes are also considered)
51 SDMX Relationships CORE information model Deals with both microdata and macrodata SDMX information model Mainly deals with macrodata
52 SDMX Relationships 1. Can we use SDMX for micro and macro data exchanges in a CORE process? Need for mapping of information models 2. What about metadata? CORE: Data and metadata managed at the same way SDMX: distinction between structural metadata and reference metadata. Possibility of having domain knowledge codified through concepts
53 SDMX Relationships Choices and steps: Conversion from CORE XML to CSV in order to use SDMX conversion tools Starting from the CORE file structure it was created a SDMX DSD (Data Structure Definition) SDMX data format : cross-sectional Once prepared the DSD, we proceeded to convert the CORE file using the SDMX Converter tool
54 SDMX Relationships CORE-to-SDMX Conversion Proof-of-Concept Setting: Italian Time-Use Survey Data Structure Wizard and the SDMX Converter Compute Estimates and Sampling Errors (as the aggregated data dissemination phase) Choices and steps: Conversion from CORE XML to CSV in order to use SDMX conversion tools Starting from the CORE file structure it was created a SDMX DSD (Data Structure Definition)
55 SDMX Relationships The experiment has shown the feasibility of the conversion to SDMX format of a data file obtained as a CORE output Not automated conversion: Manual mapping of the CORE output s fields to the dimensions and attributes of the SDMX DSD SDMX does not manage more than measure, it was necessary the verticalization of the CORE output file in order to convert it to the SDMX cross sectional
56 Architecture Deployment Web-based architectured centered on a centralized component CORE Environment Different CORE deployments can co-exist Intra- or Inter- organization Services can be remotely executed Support is needed in the form of a distibuted component for tool execution and data transfer
57 Types of service runtime Batch Tool executed by a command line call Can be automated Interactive User interact with the tool through a tool-provided GUI Cannot be automated Web service No tool procedure distributed on a web service actived by a programming language call Can be automated
58 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Process Engine Integration APIs Runtime agent Run on the machine on which the tool is deployed. Is responsible for: -Preparing the input -Gathering the output -Activating the tool Web service runtime Runtime Remote activation Web service client Web container
59 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine The process engine signals a service must be executed Integration APIs Runtime Remote activation Web service client
60 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs Runtime Remote activation Web service client Service definition is extracted from the repository, as well as the required datasets and the corresponding mappings
61 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs Runtime Remote activation Web service client Datasets are converted according to the mapping
62 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs Runtime Remote activation Web service client Converted datasets are transferred to the remote runtime
63 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs The tool is activated by the runtime agent Runtime Remote activation Web service client
64 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine The output datasets are gathered and sent back to the CORE environment Integration APIs Runtime Remote activation Web service client
65 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs Runtime Remote activation Web service client Datasets are converted back to CORE format according to the mapping
66 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs Runtime Remote activation Converted datasets are stored in the repository Web service client
67 CORE Technical Architecture CORE Environment Batch-Interactive runtime Runtime GUI Definition Repository Runtime agent Process Engine Integration APIs The process continues its execution Runtime Remote activation Web service client
68 Scenario 1 Remote execution command line/gui Physical layers: CORE env, Service AGENT
69 Scenario 2 Remote execution web service Physical layers: CORE env, Service
70 CORE Scenario
71 Why a Process Scenario? Helps to clarify ideas and to asses their feasibility Forces to make newly proposed solutions concrete Can/will be used as empirical test-bed during the whole implementation cycle of the CORE environment 71
72 How did we build the Scenario? Rationale for our Scenario: Naturality: involves typical processing steps performed by NSIs for sample surveys Minimality: very easy workflow (no conditionals, nor cycles), can be run without a Workflow Engine Appropriateness: incorporates as much heterogeneity as possible: heterogeneity is precisely what CORE must be able to get rid of 72
73 Spreading Heterogeneity over the Scenario The Scenario incorporates both: Data Heterogeneity Via data exchanged by CORE services belonging to the scenario process Technological Heterogeneity Via IT tools implementing scenario sub-processes 73
74 Data Heterogeneity The Scenario entails different levels of data heterogeneity: Format Heterogeneity: CSV files, relational DB tables, SDMX XML files involved Statistical Heterogeneity: both Micro and Aggregated Data involved Model Heterogeneity: some data refer to ordinary real-world concepts (e.g. enterprise, individual, ), some other to concepts arising from the statistical domain (e.g. stratum, variance, sampling weight, ) 74
75 Technological Heterogeneity The Scenario requires to wrap inside CORE-compliant services very different IT tools: simple SQL statements executed on a relational DB batch jobs based on SAS or R scripts full-fledged R-based systems requiring a human-computer interaction through a GUI layer 75
76 The Scenario at a glance ALLOCATION STAR T Compute Strata Statistics Allocate the Sample Collect Survey Data Check and Correct Survey Data Calibrate Survey Data Compute Estimates and Sampling Errors Store Estimates and Sampling Errors ESTIMATION Select the Sample Convert to SDMX STOP 76
77 Sample Allocation Subprocess ALLOCATION START Compute Strata Statistics Allocate the Sample Overall Goal: determine the minimum number of units to be sampled inside each stratum, when lower bounds are imposed on the expected level of precision of the estimates the survey has to deliver Two statistical services are needed: Compute Strata Statistics Allocate the Sample 77
78 Compute Strata Statistics Service ALLOCATION START Compute Strata Statistics Allocate the Sample Goal: compute, for each stratum, the population mean and standard deviation of a set of auxiliary variables IT tool: a simple SQL aggregated query with a group-by clause NSIs usually maintain their sampling frame(s) as Relational DB tables Integration API: must support Relational/CORE transformations CORA tag: Statistics 78
79 Allocate the Sample Service ALLOCATION START Compute Strata Statistics Allocate the Sample Goal: solve a constrained optimization problem to find and return the optimal sample allocation across strata IT tool: Istat MAUSS-R system implemented in R and Java, can be run either in batch mode or interactively via a GUI Integration API: must support CSV/CORE transformations MAUSS handles I/O via CSV files CORA tag: Statistics 79
80 Sample Selection Subprocess Select the Sample Goal: draw a stratified random sample of units from the sampling frame, according to the previously computed optimal allocation IT tool: a simple SAS script to be executed in batch mode Integration API: CSV/CORE transformation SAS datasets have proprietary, closed format we ll not support direct SAS/CORE conversions CORA tag: Population output stores the identifiers of the units to be later surveyed + basic information needed to contact them 80
81 Estimation Subprocess Calibrate Survey Data Compute Estimates and Sampling Errors ESTIMATION Overall Goal: compute the estimates the survey must deliver, and asses their precision as well Two statistical services are needed: Calibrate Survey Data Compute Estimates and Sampling Errors 81
82 Calibrate Survey Data Service Calibrate Survey Data Compute Estimates and Sampling Errors ESTIMATION Goal: provide a new set of weights (the calibrated weights ) to be used for estimation purposes IT tool: Istat ReGenesees system implemented in R, can be run either in batch mode or interactively via a GUI Integration API: can use both CSV/CORE and Relational/CORE transformations CORA tag: Variable 82
83 Estimates and Errors Service Calibrate Survey Data Compute Estimates and Sampling Errors ESTIMATION Goal: use the calibrated weights to compute the estimates the survey has to provide (typically for different subpopulations of interest) along with the corresponding confidence intervals IT tool: Istat ReGenesees system Integration API: can use both CSV/CORE and Relational/CORE transformations CORA tag: Statistic 83
84 Store Estimates Subprocess Store Estimates and Sampling Errors Goal: persistently store the previously computed survey estimates in a relational DB e.g. in order to subsequently feed a data warehouse for online publication IT tool: a set of SQL statements Integration API: Relational/CORE transformation again CORA tag: Statistics 84
85 Convert to SDMX Service Convert to SDMX STOP Goal: retrieve the aggregated data from the relational DB and directly convert them in SDMX XML format e.g. to later send them to IT tool:??? Integration API: must support SDMX/CORE transformations CORA tag: Statistics 85
86 Scenario Open Issues Besides I/O data, CORE must be able to handle service behaviour parameters. How? e.g. to analyze a complex survey, ReGenesees needs a lot of sampling design metadata, namely information about strata, stages, clusters identifiers, sampling weights, calibration models, and so on Enabling the CORE environment to support interactive services execution is still a challanging problem we plan to exploit MAUSS-R and/or ReGenesees to test the technical feasibility of any forthcoming solution How to implement a SDMX/CORE converter? 86
87 Demo Scenario Involves 3 typical processing steps performed by NSIs for sample surveys: Sample Allocation Sample Selection Estimation It has been used as empirical test-bed during the whole implementation cycle of the CORE environment 87
88 Rationale for the Scenario Minimality: very easy workflow (no conditionals, nor cycles), can be run without a Workflow Engine Appropriateness: addresses heterogeneity issues heterogeneity is precisely what CORE must be able to get rid of 88
89 Spreading Heterogeneity over the Scenario The Scenario incorporates both: Data Heterogeneity: Via data exchanged by CORE services belonging to the scenario process Technological Heterogeneity: Via IT tools implementing scenario services A batch job based on a SAS script Two full-fledged R-based systems 89
90 The Scenario at a glance START ESTIMATION ALLOCATION MAUSS- R SELECTION ReGenesees System SAS SCRIPT STOP 90
91 Sample Allocation Service ALLOCATION START MAUSS- R Overall Goal: determine the minimum number of units to be sampled inside each stratum, when lower bounds are imposed on the expected level of precision of the estimates the survey has to deliver IT tool: Istat MAUSS-R system implemented in R and Java CORA tag: Statistics 91
92 Sample Selection Service SELECTION SAS SCRIPT Goal: draw a stratified random sample of units from the sampling frame, according to the previously computed optimal allocation IT tool: a simple SAS script to be executed in batch mode CORA tag: Population 92
93 Estimates and Errors Service ESTIMATION ReGenesees System STOP Goal: compute the estimates the survey has to provide (typically for different subpopulations of interest) along with the corresponding confidence intervals IT tool: Istat ReGenesees System R-based CORA tag: Statistics 93
94 CORE Follow up
95 CORE in Istat CORE is an Action of the Istat strategic plan Stat2015 Period Objective: Usage of CORE platform in production scenarios of Istat Plan for 2013: Implementation of engineering activities Usage of CORE to support sharing of generalized software functionalities currently studying how to Usage of CORE in dissemination flow of the corporate architecture in conjunction with an ETL tool (Kettle) currently studying how to
96 Development of CORE Services for ESS: Issues CORE is strictly related to the Shared Services technical cross-cutting issue of the ESS VIP (Vision Infrastructure Project) Programme Period Role: Supporting standardisation of the communication protocol among standard statistical services
97 Issue 1: Relationship between CORE and SOA Hints for answering issue 1: CORE adopts a SOA design approach CORE services can be deployed as Web Services CORE do imply / include SOA technologies SOA technologies does not imply / include CORE
98 Issue 2: Relationship between CORE and GSIM Hints for answering issue 2: CORE did not have the purpose of defining yet another information model CORE takes into account the need for an information model Introduced only for demonstration purposes Hence from a design perspective CORE is open to adopt a full-fledged information model like GSIM CORE Model slot/core Domain Descriptor slot
99 Issue 3: Relationship between CORE and DDI/SDMX Hints for answering issue 3: DDI/SDMX provides logical information models GSIM serves a documentation purpose DDI/SDMX serve (mainly) a representation purpose CORE could be integrated with DDI/SDMX by: Mapping rectangular datasets representation of CORE data to such models Mapping in principle feasible as CORE model less expressive
100 Issue 4: CORE Deployment Issues in the ESS SOA supporting platform Hints for answering issue 4: Need for designing a CORE deployment for the ESS Service repositories Data exchanges Security issues Performance issues...
Description of CORE Implementation in Java
 Partner s name: Istat WP number and name: WP6 Implementation library for generic interface and production chain for Java Deliverable number and name: 6.1 Description of Implementation in Java Description
Partner s name: Istat WP number and name: WP6 Implementation library for generic interface and production chain for Java Deliverable number and name: 6.1 Description of Implementation in Java Description
3.4 Data-Centric workflow
 3.4 Data-Centric workflow One of the most important activities in a S-DWH environment is represented by data integration of different and heterogeneous sources. The process of extract, transform, and load
3.4 Data-Centric workflow One of the most important activities in a S-DWH environment is represented by data integration of different and heterogeneous sources. The process of extract, transform, and load
On the Design and Implementation of a Generalized Process for Business Statistics
 On the Design and Implementation of a Generalized Process for Business Statistics M. Bruno, D. Infante, G. Ruocco, M. Scannapieco 1. INTRODUCTION Since the second half of 2014, Istat has been involved
On the Design and Implementation of a Generalized Process for Business Statistics M. Bruno, D. Infante, G. Ruocco, M. Scannapieco 1. INTRODUCTION Since the second half of 2014, Istat has been involved
Linked open data at Insee. Franck Cotton Guillaume Mordant
 Linked open data at Insee Franck Cotton franck.cotton@insee.fr Guillaume Mordant guillaume.mordant@insee.fr Linked open data at Insee Agenda A long story How is data published? Why publish Linked Open
Linked open data at Insee Franck Cotton franck.cotton@insee.fr Guillaume Mordant guillaume.mordant@insee.fr Linked open data at Insee Agenda A long story How is data published? Why publish Linked Open
ESSnet. COmmon Reference Environment. WP number and name: WP1 Project Management. Deliverable number and name: 1.1 Preliminary Report
 Partner s name: Istat WP number and name: WP1 Project Management Deliverable number and name: 1.1 Preliminary Report Preliminary Report Partner in charge Istat Version 1.0 Date 11/04/2011 Version Changes
Partner s name: Istat WP number and name: WP1 Project Management Deliverable number and name: 1.1 Preliminary Report Preliminary Report Partner in charge Istat Version 1.0 Date 11/04/2011 Version Changes
A new international standard for data validation and processing
 A new international standard for data validation and processing Marco Pellegrino (marco.pellegrino@ec.europa.eu) 1 Keywords: Data validation, transformation, open standards, SDMX, GSIM 1. INTRODUCTION
A new international standard for data validation and processing Marco Pellegrino (marco.pellegrino@ec.europa.eu) 1 Keywords: Data validation, transformation, open standards, SDMX, GSIM 1. INTRODUCTION
A STRATEGY ON STRUCTURAL METADATA MANAGEMENT BASED ON SDMX AND THE GSIM MODELS
 Distr. GENERAL 25 April 2013 WP.4 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS EUROPEAN COMMISSION STATISTICAL OFFICE OF THE EUROPEAN UNION (EUROSTAT)
Distr. GENERAL 25 April 2013 WP.4 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS EUROPEAN COMMISSION STATISTICAL OFFICE OF THE EUROPEAN UNION (EUROSTAT)
Fusion Registry 9 SDMX Data and Metadata Management System
 Registry 9 Data and Management System Registry 9 is a complete and fully integrated statistical data and metadata management system using. Whether you require a metadata repository supporting a highperformance
Registry 9 Data and Management System Registry 9 is a complete and fully integrated statistical data and metadata management system using. Whether you require a metadata repository supporting a highperformance
Information Infrastructure: Foundations for ABS Transformation. Stuart Girvan, Australian Bureau of Statistics MSIS Paris, April 2013.
 Information Infrastructure: Foundations for ABS Transformation Stuart Girvan, Australian Bureau of Statistics MSIS Paris, April 2013 Outline ABS 2017 Transformation Vision and Information Infrastructure
Information Infrastructure: Foundations for ABS Transformation Stuart Girvan, Australian Bureau of Statistics MSIS Paris, April 2013 Outline ABS 2017 Transformation Vision and Information Infrastructure
Business Architecture concepts and components: BA shared infrastructures, capability modeling and guiding principles
 Business Architecture concepts and components: BA shared infrastructures, capability modeling and guiding principles Giulio Barcaroli Directorate for Methodology and Statistical Process Design Istat ESTP
Business Architecture concepts and components: BA shared infrastructures, capability modeling and guiding principles Giulio Barcaroli Directorate for Methodology and Statistical Process Design Istat ESTP
CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING
 in partnership with Overall handbook to set up a S-DWH CoE: Deliverable: 4.6 Version: 3.1 Date: 3 November 2017 CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING Handbook to set up a S-DWH 1 version 2.1 / 4
in partnership with Overall handbook to set up a S-DWH CoE: Deliverable: 4.6 Version: 3.1 Date: 3 November 2017 CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING Handbook to set up a S-DWH 1 version 2.1 / 4
IMPLEMENTING STATISTICAL DOMAIN DATABASES IN POLAND. OPPORTUNITIES AND THREATS. Central Statistical Office in Poland
 IMPLEMENTING STATISTICAL DOMAIN DATABASES IN POLAND. OPPORTUNITIES AND THREATS. Central Statistical Office in Poland Agenda 2 Background Current state The goal of the SDD Architecture Technologies Data
IMPLEMENTING STATISTICAL DOMAIN DATABASES IN POLAND. OPPORTUNITIES AND THREATS. Central Statistical Office in Poland Agenda 2 Background Current state The goal of the SDD Architecture Technologies Data
SDMX GLOBAL CONFERENCE
 SDMX GLOBAL CONFERENCE PARIS 2009 EUROSTAT SDMX REGISTRY (Francesco Rizzo, Bengt-Åke Lindblad - Eurostat) 1. Introduction The SDMX initiative (Statistical Data and Metadata exchange) is aimed at developing
SDMX GLOBAL CONFERENCE PARIS 2009 EUROSTAT SDMX REGISTRY (Francesco Rizzo, Bengt-Åke Lindblad - Eurostat) 1. Introduction The SDMX initiative (Statistical Data and Metadata exchange) is aimed at developing
ESS Shared SERVices project Background, Status, Roadmap. Modernisation Workshop 16/17 March Bucharest
 ESS Shared SERVices project Background, Status, Roadmap Modernisation Workshop 16/17 March Bucharest Table of contents 1. Background of the project 2. Objectives & Deliverables 3. Timeline 4. Phase 1 5.
ESS Shared SERVices project Background, Status, Roadmap Modernisation Workshop 16/17 March Bucharest Table of contents 1. Background of the project 2. Objectives & Deliverables 3. Timeline 4. Phase 1 5.
CORA Technical Annex. ESSnet. WP3: Definition of the Layered Architecture. 3.2 Technical Annex. Statistics Netherlands
 Statistics Netherlands WP3: Definition of the Layered Architecture 3.2 Technical Annex Technical Annex Partner in charge Statistics Netherlands Version.0 Date 2/0/200 2/0/200.0 of 6 Version Changes Date
Statistics Netherlands WP3: Definition of the Layered Architecture 3.2 Technical Annex Technical Annex Partner in charge Statistics Netherlands Version.0 Date 2/0/200 2/0/200.0 of 6 Version Changes Date
Publishing the 15 th Italian Population and Housing Census in Linked Open Data
 Publishing the 15 th Italian Population and Housing Census in Linked Open Data Raffaella Aracri, Stefano De Francisci, Andrea Pagano, Monica Scannapieco, Laura Tosco, Luca Valentino Istat Istituto Nazionale
Publishing the 15 th Italian Population and Housing Census in Linked Open Data Raffaella Aracri, Stefano De Francisci, Andrea Pagano, Monica Scannapieco, Laura Tosco, Luca Valentino Istat Istituto Nazionale
1 Dulcian, Inc., 2001 All rights reserved. Oracle9i Data Warehouse Review. Agenda
 Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
1Z0-560 Oracle Unified Business Process Management Suite 11g Essentials
 1Z0-560 Oracle Unified Business Process Management Suite 11g Essentials Number: 1Z0-560 Passing Score: 650 Time Limit: 120 min File Version: 1.0 http://www.gratisexam.com/ 1Z0-560: Oracle Unified Business
1Z0-560 Oracle Unified Business Process Management Suite 11g Essentials Number: 1Z0-560 Passing Score: 650 Time Limit: 120 min File Version: 1.0 http://www.gratisexam.com/ 1Z0-560: Oracle Unified Business
SDMX self-learning package No. 3 Student book. SDMX-ML Messages
 No. 3 Student book SDMX-ML Messages Produced by Eurostat, Directorate B: Statistical Methodologies and Tools Unit B-5: Statistical Information Technologies Last update of content February 2010 Version
No. 3 Student book SDMX-ML Messages Produced by Eurostat, Directorate B: Statistical Methodologies and Tools Unit B-5: Statistical Information Technologies Last update of content February 2010 Version
Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data
 Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data June 2006 Note: This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality,
Oracle Warehouse Builder 10g Release 2 Integrating Packaged Applications Data June 2006 Note: This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality,
Designing your BI Architecture
 IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
Tools to Develop New Linux Applications
 Tools to Develop New Linux Applications IBM Software Development Platform Tools for every member of the Development Team Supports best practices in Software Development Analyst Architect Developer Tester
Tools to Develop New Linux Applications IBM Software Development Platform Tools for every member of the Development Team Supports best practices in Software Development Analyst Architect Developer Tester
SAS offers technology to facilitate working with CDISC standards : the metadata perspective.
 SAS offers technology to facilitate working with CDISC standards : the metadata perspective. Mark Lambrecht, PhD Principal Consultant, Life Sciences SAS Agenda SAS actively supports CDISC standards Tools
SAS offers technology to facilitate working with CDISC standards : the metadata perspective. Mark Lambrecht, PhD Principal Consultant, Life Sciences SAS Agenda SAS actively supports CDISC standards Tools
Call: SAS BI Course Content:35-40hours
 SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
A corporate approach to processing microdata in Eurostat
 A corporate approach to processing microdata in Eurostat Pál JANCSÓK and Christine WIRTZ Eurostat Unit B4 1 Agenda Introduction Generic SAS Tool (GSAST) architecture Microdata processing Architecture Metadata
A corporate approach to processing microdata in Eurostat Pál JANCSÓK and Christine WIRTZ Eurostat Unit B4 1 Agenda Introduction Generic SAS Tool (GSAST) architecture Microdata processing Architecture Metadata
A metadata-driven process for handling statistical data end-to-end
 A metadata-driven process for handling statistical data end-to-end Denis GROFILS Seconded National Expert Methodology and corporate architecture Content Context Approach Benefits Enablers Challenges Conclusions
A metadata-driven process for handling statistical data end-to-end Denis GROFILS Seconded National Expert Methodology and corporate architecture Content Context Approach Benefits Enablers Challenges Conclusions
Red Hat JBoss Data Virtualization 6.3 Glossary Guide
 Red Hat JBoss Data Virtualization 6.3 Glossary Guide David Sage Nidhi Chaudhary Red Hat JBoss Data Virtualization 6.3 Glossary Guide David Sage dlesage@redhat.com Nidhi Chaudhary nchaudha@redhat.com Legal
Red Hat JBoss Data Virtualization 6.3 Glossary Guide David Sage Nidhi Chaudhary Red Hat JBoss Data Virtualization 6.3 Glossary Guide David Sage dlesage@redhat.com Nidhi Chaudhary nchaudha@redhat.com Legal
METADATA MANAGEMENT AND STATISTICAL BUSINESS PROCESS AT STATISTICS ESTONIA
 Distr. GENERAL 06 May 2013 WP.13 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS EUROPEAN COMMISSION STATISTICAL OFFICE OF THE EUROPEAN UNION (EUROSTAT)
Distr. GENERAL 06 May 2013 WP.13 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS EUROPEAN COMMISSION STATISTICAL OFFICE OF THE EUROPEAN UNION (EUROSTAT)
Research Data Repository Interoperability Primer
 Research Data Repository Interoperability Primer The Research Data Repository Interoperability Working Group will establish standards for interoperability between different research data repository platforms
Research Data Repository Interoperability Primer The Research Data Repository Interoperability Working Group will establish standards for interoperability between different research data repository platforms
Enterprise Architecture Layers
 Enterprise Architecture Layers Monica Scannapieco ESTP Training Course Enterprise Architecture and the different EA layers, application to the ESS context Advanced course Rome, 11 14 October 2016 THE CONTRACTOR
Enterprise Architecture Layers Monica Scannapieco ESTP Training Course Enterprise Architecture and the different EA layers, application to the ESS context Advanced course Rome, 11 14 October 2016 THE CONTRACTOR
SDMX self-learning package No. 7 Student book. SDMX Architecture Using the Pull Method for Data Sharing
 No. 7 Student book SDMX Architecture Using the Pull Method for Data Sharing Produced by Eurostat, Directorate B: Statistical Methodologies and Tools Unit B-5: Statistical Information Technologies Last
No. 7 Student book SDMX Architecture Using the Pull Method for Data Sharing Produced by Eurostat, Directorate B: Statistical Methodologies and Tools Unit B-5: Statistical Information Technologies Last
Active Endpoints. ActiveVOS Platform Architecture Active Endpoints
 Active Endpoints ActiveVOS Platform Architecture ActiveVOS Unique process automation platforms to develop, integrate, and deploy business process applications quickly User Experience Easy to learn, use
Active Endpoints ActiveVOS Platform Architecture ActiveVOS Unique process automation platforms to develop, integrate, and deploy business process applications quickly User Experience Easy to learn, use
OLAP Introduction and Overview
 1 CHAPTER 1 OLAP Introduction and Overview What Is OLAP? 1 Data Storage and Access 1 Benefits of OLAP 2 What Is a Cube? 2 Understanding the Cube Structure 3 What Is SAS OLAP Server? 3 About Cube Metadata
1 CHAPTER 1 OLAP Introduction and Overview What Is OLAP? 1 Data Storage and Access 1 Benefits of OLAP 2 What Is a Cube? 2 Understanding the Cube Structure 3 What Is SAS OLAP Server? 3 About Cube Metadata
Oracle Warehouse Builder 10g Runtime Environment, an Update. An Oracle White Paper February 2004
 Oracle Warehouse Builder 10g Runtime Environment, an Update An Oracle White Paper February 2004 Runtime Environment, an Update Executive Overview... 3 Introduction... 3 Runtime in warehouse builder 9.0.3...
Oracle Warehouse Builder 10g Runtime Environment, an Update An Oracle White Paper February 2004 Runtime Environment, an Update Executive Overview... 3 Introduction... 3 Runtime in warehouse builder 9.0.3...
Contents. Microsoft is a registered trademark of Microsoft Corporation. TRAVERSE is a registered trademark of Open Systems Holdings Corp.
 TPLWPT Contents Summary... 1 General Information... 1 Technology... 2 Server Technology... 2 Business Layer... 4 Client Technology... 4 Structure... 4 Ultra-Thin Client Considerations... 7 Internet and
TPLWPT Contents Summary... 1 General Information... 1 Technology... 2 Server Technology... 2 Business Layer... 4 Client Technology... 4 Structure... 4 Ultra-Thin Client Considerations... 7 Internet and
OpenBudgets.eu: Fighting Corruption with Fiscal Transparency. Project Number: Start Date of Project: Duration: 30 months
 OpenBudgets.eu: Fighting Corruption with Fiscal Transparency Project Number: 645833 Start Date of Project: 01.05.2015 Duration: 30 months Deliverable 4.1 Specification of services' Interfaces Dissemination
OpenBudgets.eu: Fighting Corruption with Fiscal Transparency Project Number: 645833 Start Date of Project: 01.05.2015 Duration: 30 months Deliverable 4.1 Specification of services' Interfaces Dissemination
ESPRIT Project N Work Package H User Access. Survey
 ESPRIT Project N. 25 338 Work Package H User Access Survey ID: User Access V. 1.0 Date: 28.11.97 Author(s): A. Sinderman/ E. Triep, Status: Fast e.v. Reviewer(s): Distribution: Change History Document
ESPRIT Project N. 25 338 Work Package H User Access Survey ID: User Access V. 1.0 Date: 28.11.97 Author(s): A. Sinderman/ E. Triep, Status: Fast e.v. Reviewer(s): Distribution: Change History Document
ECLIPSE PERSISTENCE PLATFORM (ECLIPSELINK) FAQ
 FAQ") ECLIPSE PERSISTENCE PLATFORM (ECLIPSELINK) FAQ 1. What is Oracle proposing in EclipseLink, the Eclipse Persistence Platform Project? Oracle is proposing the creation of the Eclipse Persistence Platform
ECLIPSE PERSISTENCE PLATFORM (ECLIPSELINK) FAQ 1. What is Oracle proposing in EclipseLink, the Eclipse Persistence Platform Project? Oracle is proposing the creation of the Eclipse Persistence Platform
Teiid Designer User Guide 7.5.0
 Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
UCT Application Development Lifecycle. UCT Business Applications
 UCT Business Applications Page i Table of Contents Planning Phase... 1 Analysis Phase... 2 Design Phase... 3 Implementation Phase... 4 Software Development... 4 Product Testing... 5 Product Implementation...
UCT Business Applications Page i Table of Contents Planning Phase... 1 Analysis Phase... 2 Design Phase... 3 Implementation Phase... 4 Software Development... 4 Product Testing... 5 Product Implementation...
Extending the Scope of Custom Transformations
 Paper 3306-2015 Extending the Scope of Custom Transformations Emre G. SARICICEK, The University of North Carolina at Chapel Hill. ABSTRACT Building and maintaining a data warehouse can require complex
Paper 3306-2015 Extending the Scope of Custom Transformations Emre G. SARICICEK, The University of North Carolina at Chapel Hill. ABSTRACT Building and maintaining a data warehouse can require complex
to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse
 An End-to to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse Presented at ODTUG 2003 Dan Vlamis dvlamis@vlamis.com Vlamis Software Solutions, Inc. (816) 781-2880 http://www.vlamis.com
An End-to to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse Presented at ODTUG 2003 Dan Vlamis dvlamis@vlamis.com Vlamis Software Solutions, Inc. (816) 781-2880 http://www.vlamis.com
Minsoo Ryu. College of Information and Communications Hanyang University.
 Software Reuse and Component-Based Software Engineering Minsoo Ryu College of Information and Communications Hanyang University msryu@hanyang.ac.kr Software Reuse Contents Components CBSE (Component-Based
Software Reuse and Component-Based Software Engineering Minsoo Ryu College of Information and Communications Hanyang University msryu@hanyang.ac.kr Software Reuse Contents Components CBSE (Component-Based
D2.5 Data mediation. Project: ROADIDEA
 D2.5 Data mediation Project: ROADIDEA 215455 Document Number and Title: D2.5 Data mediation How to convert data with different formats Work-Package: WP2 Deliverable Type: Report Contractual Date of Delivery:
D2.5 Data mediation Project: ROADIDEA 215455 Document Number and Title: D2.5 Data mediation How to convert data with different formats Work-Package: WP2 Deliverable Type: Report Contractual Date of Delivery:
DEV-33: Get to Know Your Data Open Source Data Integration, Business Intelligence and more Marian Edu
 DEV-33: Get to Know Your Data Open Source, Business Intelligence and more IT Consultant Agenda Take Ownership of Your Data. Data Discovery Reporting Analysis 2 DEV-33: Get to Know Your Data Data Discovery
DEV-33: Get to Know Your Data Open Source, Business Intelligence and more IT Consultant Agenda Take Ownership of Your Data. Data Discovery Reporting Analysis 2 DEV-33: Get to Know Your Data Data Discovery
Teiid Designer User Guide 7.7.0
 Teiid Designer User Guide 1 7.7.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Teiid Designer User Guide 1 7.7.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Sampling Error Estimation SORS practice
 Sampling Error Estimation SORS practice Rudi Seljak, Petra Blažič Statistical Office of the Republic of Slovenia 1. Introduction Assessment of the quality in the official statistics has faced significant
Sampling Error Estimation SORS practice Rudi Seljak, Petra Blažič Statistical Office of the Republic of Slovenia 1. Introduction Assessment of the quality in the official statistics has faced significant
Federated XDMoD Requirements
 Federated XDMoD Requirements Date Version Person Change 2016-04-08 1.0 draft XMS Team Initial version Summary Definitions Assumptions Data Collection Local XDMoD Installation Module Support Data Federation
Federated XDMoD Requirements Date Version Person Change 2016-04-08 1.0 draft XMS Team Initial version Summary Definitions Assumptions Data Collection Local XDMoD Installation Module Support Data Federation
A standardized approach to editing: Statistics Finland s metadata-driven editing and imputation service
 Working Paper. UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS Work Session on Statistical Data Editing (Neuchâtel, Switzerland, 18-20 September 2018) A standardized
Working Paper. UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS Work Session on Statistical Data Editing (Neuchâtel, Switzerland, 18-20 September 2018) A standardized
Business microdata dissemination at Istat
 Business microdata dissemination at Istat Daniela Ichim Luisa Franconi ichim@istat.it franconi@istat.it Outline - Released products - Microdata dissemination - Business microdata dissemination - Documentation
Business microdata dissemination at Istat Daniela Ichim Luisa Franconi ichim@istat.it franconi@istat.it Outline - Released products - Microdata dissemination - Business microdata dissemination - Documentation
ActiveVOS Technologies
 ActiveVOS Technologies ActiveVOS Technologies ActiveVOS provides a revolutionary way to build, run, manage, and maintain your business applications ActiveVOS is a modern SOA stack designed from the top
ActiveVOS Technologies ActiveVOS Technologies ActiveVOS provides a revolutionary way to build, run, manage, and maintain your business applications ActiveVOS is a modern SOA stack designed from the top
Optimizing Testing Performance With Data Validation Option
 Optimizing Testing Performance With Data Validation Option 1993-2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
Optimizing Testing Performance With Data Validation Option 1993-2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
ThinProway A Java client to a SAS application. A successful story. Exactly what you need?
 ThinProway A Java client to a SAS application. A successful story. Exactly what you need? Author: Riccardo Proni TXT Ingegneria Informatica Abstract ThinProway is a software solution dedicated to the manufacturing
ThinProway A Java client to a SAS application. A successful story. Exactly what you need? Author: Riccardo Proni TXT Ingegneria Informatica Abstract ThinProway is a software solution dedicated to the manufacturing
An Oracle White Paper October Release Notes - V Oracle Utilities Application Framework
 An Oracle White Paper October 2012 Release Notes - V4.2.0.0.0 Oracle Utilities Application Framework Introduction... 2 Disclaimer... 2 Deprecation of Functionality... 2 New or Changed Features... 4 Native
An Oracle White Paper October 2012 Release Notes - V4.2.0.0.0 Oracle Utilities Application Framework Introduction... 2 Disclaimer... 2 Deprecation of Functionality... 2 New or Changed Features... 4 Native
Sunday, May 1,
 1 Governing Services, Data, Rules, Processes and more Randall Hauch Project Lead, ModeShape Kurt Stam Project Lead, Guvnor @rhauch @modeshape @guvtalk 2 Scenario 1 Build business processes using existing
1 Governing Services, Data, Rules, Processes and more Randall Hauch Project Lead, ModeShape Kurt Stam Project Lead, Guvnor @rhauch @modeshape @guvtalk 2 Scenario 1 Build business processes using existing
Copy Data From One Schema To Another In Sql Developer
 Copy Data From One Schema To Another In Sql Developer The easiest way to copy an entire Oracle table (structure, contents, indexes, to copy a table from one schema to another, or from one database to another,.
Copy Data From One Schema To Another In Sql Developer The easiest way to copy an entire Oracle table (structure, contents, indexes, to copy a table from one schema to another, or from one database to another,.
The CASPAR Finding Aids
 ABSTRACT The CASPAR Finding Aids Henri Avancini, Carlo Meghini, Loredana Versienti CNR-ISTI Area dell Ricerca di Pisa, Via G. Moruzzi 1, 56124 Pisa, Italy EMail: Full.Name@isti.cnr.it CASPAR is a EU co-funded
ABSTRACT The CASPAR Finding Aids Henri Avancini, Carlo Meghini, Loredana Versienti CNR-ISTI Area dell Ricerca di Pisa, Via G. Moruzzi 1, 56124 Pisa, Italy EMail: Full.Name@isti.cnr.it CASPAR is a EU co-funded
Optimizer Challenges in a Multi-Tenant World
 Optimizer Challenges in a Multi-Tenant World Pat Selinger pselinger@salesforce.come Classic Query Optimizer Concepts & Assumptions Relational Model Cost = X * CPU + Y * I/O Cardinality Selectivity Clustering
Optimizer Challenges in a Multi-Tenant World Pat Selinger pselinger@salesforce.come Classic Query Optimizer Concepts & Assumptions Relational Model Cost = X * CPU + Y * I/O Cardinality Selectivity Clustering
Data integration made easy with Talend Open Studio for Data Integration. Dimitar Zahariev BI / DI Consultant
 Data integration made easy with Talend Open Studio for Data Integration Dimitar Zahariev BI / DI Consultant dimitar@zahariev.pro @shekeriev Disclaimer Please keep in mind that: 2 I m not related in any
Data integration made easy with Talend Open Studio for Data Integration Dimitar Zahariev BI / DI Consultant dimitar@zahariev.pro @shekeriev Disclaimer Please keep in mind that: 2 I m not related in any
Lupin: from Web Services to Web-based Problem Solving Environments
 Lupin: from Web Services to Web-based Problem Solving Environments K. Li, M. Sakai, Y. Morizane, M. Kono, and M.-T.Noda Dept. of Computer Science, Ehime University Abstract The research of powerful Problem
Lupin: from Web Services to Web-based Problem Solving Environments K. Li, M. Sakai, Y. Morizane, M. Kono, and M.-T.Noda Dept. of Computer Science, Ehime University Abstract The research of powerful Problem
Predicting impact of changes in application on SLAs: ETL application performance model
 Predicting impact of changes in application on SLAs: ETL application performance model Dr. Abhijit S. Ranjekar Infosys Abstract Service Level Agreements (SLAs) are an integral part of application performance.
Predicting impact of changes in application on SLAs: ETL application performance model Dr. Abhijit S. Ranjekar Infosys Abstract Service Level Agreements (SLAs) are an integral part of application performance.
WHY WE NEED AN XML STANDARD FOR REPRESENTING BUSINESS RULES. Introduction. Production rules. Christian de Sainte Marie ILOG
 WHY WE NEED AN XML STANDARD FOR REPRESENTING BUSINESS RULES Christian de Sainte Marie ILOG Introduction We are interested in the topic of communicating policy decisions to other parties, and, more generally,
WHY WE NEED AN XML STANDARD FOR REPRESENTING BUSINESS RULES Christian de Sainte Marie ILOG Introduction We are interested in the topic of communicating policy decisions to other parties, and, more generally,
Enterprise Data Catalog for Microsoft Azure Tutorial
 Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Metadata and classification system development in Bosnia and Herzegovina
 >> Metadata and classification system development in Bosnia and Herzegovina 23. april 2012 Mogens Grosen Nielsen Statistics Denmark Outline of introduction to metadata project in Bosnia and Hercegovina
>> Metadata and classification system development in Bosnia and Herzegovina 23. april 2012 Mogens Grosen Nielsen Statistics Denmark Outline of introduction to metadata project in Bosnia and Hercegovina
An Approach to Evaluate and Enhance the Retrieval of Web Services Based on Semantic Information
 An Approach to Evaluate and Enhance the Retrieval of Web Services Based on Semantic Information Stefan Schulte Multimedia Communications Lab (KOM) Technische Universität Darmstadt, Germany schulte@kom.tu-darmstadt.de
An Approach to Evaluate and Enhance the Retrieval of Web Services Based on Semantic Information Stefan Schulte Multimedia Communications Lab (KOM) Technische Universität Darmstadt, Germany schulte@kom.tu-darmstadt.de
Metadata. Frauke Kreuter BLS 2018 University of Maryland (JPSM), University of Mannheim & IAB
, University of Mannheim & IAB") Metadata Frauke Kreuter BLS 2018 University of Maryland (JPSM), University of Mannheim & IAB Metadata? Process data whiskey Spaghetti Metadata Paradata and metadata Paradata capture information about
Metadata Frauke Kreuter BLS 2018 University of Maryland (JPSM), University of Mannheim & IAB Metadata? Process data whiskey Spaghetti Metadata Paradata and metadata Paradata capture information about
New Features in Oracle Data Miner 4.2. The new features in Oracle Data Miner 4.2 include: The new Oracle Data Mining features include:
 Oracle Data Miner Release Notes Release 4.2 E64607-03 March 2017 This document provides late-breaking information and information that is not yet part of the formal documentation. This document contains
Oracle Data Miner Release Notes Release 4.2 E64607-03 March 2017 This document provides late-breaking information and information that is not yet part of the formal documentation. This document contains
Database of historical places, persons, and lemmas
 Database of historical places, persons, and lemmas Natalia Korchagina Outline 1. Introduction 1.1 Swiss Law Sources Foundation as a Digital Humanities project 1.2 Data to be stored 1.3 Final goal: how
Database of historical places, persons, and lemmas Natalia Korchagina Outline 1. Introduction 1.1 Swiss Law Sources Foundation as a Digital Humanities project 1.2 Data to be stored 1.3 Final goal: how
Grid Computing Systems: A Survey and Taxonomy
 Grid Computing Systems: A Survey and Taxonomy Material for this lecture from: A Survey and Taxonomy of Resource Management Systems for Grid Computing Systems, K. Krauter, R. Buyya, M. Maheswaran, CS Technical
Grid Computing Systems: A Survey and Taxonomy Material for this lecture from: A Survey and Taxonomy of Resource Management Systems for Grid Computing Systems, K. Krauter, R. Buyya, M. Maheswaran, CS Technical
Alignment of Business and IT - ArchiMate. Dr. Barbara Re
 Alignment of Business and IT - ArchiMate Dr. Barbara Re What is ArchiMate? ArchiMate is a modelling technique ("language") for describing enterprise architectures. It presents a clear set of concepts within
Alignment of Business and IT - ArchiMate Dr. Barbara Re What is ArchiMate? ArchiMate is a modelling technique ("language") for describing enterprise architectures. It presents a clear set of concepts within
Semantic Web Company. PoolParty - Server. PoolParty - Technical White Paper.
 Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
SDK USE CASES Topic of the Month FusionBanking Loan IQ
 SDK USE CASES Topic of the Month FusionBanking Loan IQ Lorenzo Cerutti SAG Specialist Vishal Chandgude MSDC Principal Consultant January 2018 Finastra WELCOME TO THE FINASTRA TOPIC OF THE MONTH! Format
SDK USE CASES Topic of the Month FusionBanking Loan IQ Lorenzo Cerutti SAG Specialist Vishal Chandgude MSDC Principal Consultant January 2018 Finastra WELCOME TO THE FINASTRA TOPIC OF THE MONTH! Format
Business Process Model Repositories - Framework and Survey
 Business Process Model Repositories - Framework and Survey Zhiqiang Yan, Remco Dijkman, Paul Grefen Eindhoven University of Technology, PO Box 513, 5600 MB Eindhoven, The Netherlands Abstract Large organizations
Business Process Model Repositories - Framework and Survey Zhiqiang Yan, Remco Dijkman, Paul Grefen Eindhoven University of Technology, PO Box 513, 5600 MB Eindhoven, The Netherlands Abstract Large organizations
"Out of the Box" Workflow Simplicity Data Access Using PPDM in a Multi-Vendor Environment
 "Out of the Box" Workflow Simplicity Data Access Using PPDM in a Multi-Vendor Environment W. Brian Boulmay Director, Business Partners Fall 2010 Abstract Proper conversion of unit and coordinate reference
"Out of the Box" Workflow Simplicity Data Access Using PPDM in a Multi-Vendor Environment W. Brian Boulmay Director, Business Partners Fall 2010 Abstract Proper conversion of unit and coordinate reference
Best ETL Design Practices. Helpful coding insights in SAS DI studio. Techniques and implementation using the Key transformations in SAS DI studio.
 SESUG Paper SD-185-2017 Guide to ETL Best Practices in SAS Data Integration Studio Sai S Potluri, Synectics for Management Decisions; Ananth Numburi, Synectics for Management Decisions; ABSTRACT This Paper
SESUG Paper SD-185-2017 Guide to ETL Best Practices in SAS Data Integration Studio Sai S Potluri, Synectics for Management Decisions; Ananth Numburi, Synectics for Management Decisions; ABSTRACT This Paper
Introduction to Federation Server
 Introduction to Federation Server Alex Lee IBM Information Integration Solutions Manager of Technical Presales Asia Pacific 2006 IBM Corporation WebSphere Federation Server Federation overview Tooling
Introduction to Federation Server Alex Lee IBM Information Integration Solutions Manager of Technical Presales Asia Pacific 2006 IBM Corporation WebSphere Federation Server Federation overview Tooling
InfoSphere Warehouse V9.5 Exam.
 IBM 000-719 InfoSphere Warehouse V9.5 Exam TYPE: DEMO http://www.examskey.com/000-719.html Examskey IBM 000-719 exam demo product is here for you to test the quality of the product. This IBM 000-719 demo
IBM 000-719 InfoSphere Warehouse V9.5 Exam TYPE: DEMO http://www.examskey.com/000-719.html Examskey IBM 000-719 exam demo product is here for you to test the quality of the product. This IBM 000-719 demo
Automated Bundling and Other New Features in IBM License Metric Tool 7.5 Questions & Answers
 ILMT Central Team Automated Bundling and Other New Features in IBM License Metric Tool 7.5 Questions & Answers Information These slides were just the deck of the ILMT Central Team Questions&Answers session.
ILMT Central Team Automated Bundling and Other New Features in IBM License Metric Tool 7.5 Questions & Answers Information These slides were just the deck of the ILMT Central Team Questions&Answers session.
ESSnet. Common Reference Architecture. WP number and name: WP2 Requirements collection & State of the art. Questionnaire
 Partner s name: Statistics Norway WP number and name: WP2 Requirements collection & State of the art Deliverable number and name: 2.1 Questionnaire Questionnaire Partner in charge Statistics Norway Version
Partner s name: Statistics Norway WP number and name: WP2 Requirements collection & State of the art Deliverable number and name: 2.1 Questionnaire Questionnaire Partner in charge Statistics Norway Version
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
MCSA SQL SERVER 2012
 MCSA SQL SERVER 2012 1. Course 10774A: Querying Microsoft SQL Server 2012 Course Outline Module 1: Introduction to Microsoft SQL Server 2012 Introducing Microsoft SQL Server 2012 Getting Started with SQL
MCSA SQL SERVER 2012 1. Course 10774A: Querying Microsoft SQL Server 2012 Course Outline Module 1: Introduction to Microsoft SQL Server 2012 Introducing Microsoft SQL Server 2012 Getting Started with SQL
Streamlining Data Compilation and Dissemination at ILO Department of Statistics Lessons Learned and Current Status
 Distr. GENERAL Working Paper 11 April 2013 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE (ECE) CONFERENCE OF EUROPEAN STATISTICIANS ORGANISATION FOR ECONOMIC COOPERATION AND DEVELOPMENT (OECD)
Distr. GENERAL Working Paper 11 April 2013 ENGLISH ONLY UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE (ECE) CONFERENCE OF EUROPEAN STATISTICIANS ORGANISATION FOR ECONOMIC COOPERATION AND DEVELOPMENT (OECD)
1. Analytical queries on the dimensionally modeled database can be significantly simpler to create than on the equivalent nondimensional database.
 1. Creating a data warehouse involves using the functionalities of database management software to implement the data warehouse model as a collection of physically created and mutually connected database
1. Creating a data warehouse involves using the functionalities of database management software to implement the data warehouse model as a collection of physically created and mutually connected database
Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three.
 Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three. A. Too much irrelevant data for the job role B. A static reporting tool C.
Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three. A. Too much irrelevant data for the job role B. A static reporting tool C.
Gamma Data Warehouse Studio
 Gamma Data Warehouse Studio Streamlined Implementation of Data Warehouses Data Marts Data Integration Projects www.gamma-sys.com Data Warehouse Studio Gamma Data Warehouse Studio Feature Highlights Slide
Gamma Data Warehouse Studio Streamlined Implementation of Data Warehouses Data Marts Data Integration Projects www.gamma-sys.com Data Warehouse Studio Gamma Data Warehouse Studio Feature Highlights Slide
Business Architecture concepts and components: BA Process Flow
 Business Architecture concepts and components: BA Process Flow Giulio Barcaroli Directorate for Methodology and Statistical Process Design Istat ESTP Training Course Enterprise Architecture and the different
Business Architecture concepts and components: BA Process Flow Giulio Barcaroli Directorate for Methodology and Statistical Process Design Istat ESTP Training Course Enterprise Architecture and the different
Metadata Based Impact and Lineage Analysis Across Heterogeneous Metadata Sources
 Metadata Based Impact and Lineage Analysis Across Heterogeneous Metadata Sources Presentation at the THE 9TH ANNUAL Wilshire Meta-Data Conference AND THE 17TH ANNUAL DAMA International Symposium by John
Metadata Based Impact and Lineage Analysis Across Heterogeneous Metadata Sources Presentation at the THE 9TH ANNUAL Wilshire Meta-Data Conference AND THE 17TH ANNUAL DAMA International Symposium by John
Oracle 1Z0-640 Exam Questions & Answers
 Oracle 1Z0-640 Exam Questions & Answers Number: 1z0-640 Passing Score: 800 Time Limit: 120 min File Version: 28.8 http://www.gratisexam.com/ Oracle 1Z0-640 Exam Questions & Answers Exam Name: Siebel7.7
Oracle 1Z0-640 Exam Questions & Answers Number: 1z0-640 Passing Score: 800 Time Limit: 120 min File Version: 28.8 http://www.gratisexam.com/ Oracle 1Z0-640 Exam Questions & Answers Exam Name: Siebel7.7
European Conference on Quality and Methodology in Official Statistics (Q2008), 8-11, July, 2008, Rome - Italy
, 8-11, July, 2008, Rome - Italy") European Conference on Quality and Methodology in Official Statistics (Q2008), 8-11, July, 2008, Rome - Italy Metadata Life Cycle Statistics Portugal Isabel Morgado Methodology and Information Systems
European Conference on Quality and Methodology in Official Statistics (Q2008), 8-11, July, 2008, Rome - Italy Metadata Life Cycle Statistics Portugal Isabel Morgado Methodology and Information Systems
Integrated Data Processing System (EAR)
") Integrated Data Processing System (EAR) Session number: 8 Date: June 1 th 2016 Hajnalka Debreceni Hungarian Central Statistical Office Hajnalka.Debreceni@ksh.hu Outline Methodological aspects Hungarian
Integrated Data Processing System (EAR) Session number: 8 Date: June 1 th 2016 Hajnalka Debreceni Hungarian Central Statistical Office Hajnalka.Debreceni@ksh.hu Outline Methodological aspects Hungarian
From business need to implementation Design the right information solution
 From business need to implementation Design the right information solution Davor Gornik (dgornik@us.ibm.com) Product Manager Agenda Relational design Integration design Summary Relational design Data modeling
From business need to implementation Design the right information solution Davor Gornik (dgornik@us.ibm.com) Product Manager Agenda Relational design Integration design Summary Relational design Data modeling
MetaMatrix Enterprise Data Services Platform
 MetaMatrix Enterprise Data Services Platform MetaMatrix Overview Agenda Background What it does Where it fits How it works Demo Q/A 2 Product Review: Problem Data Challenges Difficult to implement new
MetaMatrix Enterprise Data Services Platform MetaMatrix Overview Agenda Background What it does Where it fits How it works Demo Q/A 2 Product Review: Problem Data Challenges Difficult to implement new
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Efficient Object-Relational Mapping for JAVA and J2EE Applications or the impact of J2EE on RDB. Marc Stampfli Oracle Software (Switzerland) Ltd.
 Ltd.") Efficient Object-Relational Mapping for JAVA and J2EE Applications or the impact of J2EE on RDB Marc Stampfli Oracle Software (Switzerland) Ltd. Underestimation According to customers about 20-50% percent
Efficient Object-Relational Mapping for JAVA and J2EE Applications or the impact of J2EE on RDB Marc Stampfli Oracle Software (Switzerland) Ltd. Underestimation According to customers about 20-50% percent
Using the IMS Universal Drivers and QMF to Access Your IMS Data Hands-on Lab
 Using the IMS Universal Drivers and QMF to Access Your IMS Data Hands-on Lab 1 Overview QMF for Workstation is an Eclipse-based, rich client desktop Java application, that uses JDBC to connect to data
Using the IMS Universal Drivers and QMF to Access Your IMS Data Hands-on Lab 1 Overview QMF for Workstation is an Eclipse-based, rich client desktop Java application, that uses JDBC to connect to data
Implicit BPM Business Process Platform for Transparent Workflow Weaving
 Implicit BPM Business Process Platform for Transparent Workflow Weaving Rubén Mondéjar, Pedro García, Carles Pairot, and Enric Brull BPM Round Table Tarragona Contents Context Introduction 01/27 Building
Implicit BPM Business Process Platform for Transparent Workflow Weaving Rubén Mondéjar, Pedro García, Carles Pairot, and Enric Brull BPM Round Table Tarragona Contents Context Introduction 01/27 Building
Business Intelligence Roadmap HDT923 Three Days
 Three Days Prerequisites Students should have experience with any relational database management system as well as experience with data warehouses and star schemas. It would be helpful if students are
Three Days Prerequisites Students should have experience with any relational database management system as well as experience with data warehouses and star schemas. It would be helpful if students are
Data Stage ETL Implementation Best Practices
 Data Stage ETL Implementation Best Practices Copyright (C) SIMCA IJIS Dr. B. L. Desai Bhimappa.desai@capgemini.com ABSTRACT: This paper is the out come of the expertise gained from live implementation
Data Stage ETL Implementation Best Practices Copyright (C) SIMCA IJIS Dr. B. L. Desai Bhimappa.desai@capgemini.com ABSTRACT: This paper is the out come of the expertise gained from live implementation
Accessibility Features in the SAS Intelligence Platform Products
 1 CHAPTER 1 Overview of Common Data Sources Overview 1 Accessibility Features in the SAS Intelligence Platform Products 1 SAS Data Sets 1 Shared Access to SAS Data Sets 2 External Files 3 XML Data 4 Relational
1 CHAPTER 1 Overview of Common Data Sources Overview 1 Accessibility Features in the SAS Intelligence Platform Products 1 SAS Data Sets 1 Shared Access to SAS Data Sets 2 External Files 3 XML Data 4 Relational
Application Discovery and Enterprise Metadata Repository solution Questions PRIEVIEW COPY ONLY 1-1
 Application Discovery and Enterprise Metadata Repository solution Questions 1-1 Table of Contents SECTION 1 ENTERPRISE METADATA ENVIRONMENT...1-1 1.1 TECHNICAL ENVIRONMENT...1-1 1.2 METADATA CAPTURE...1-1
Application Discovery and Enterprise Metadata Repository solution Questions 1-1 Table of Contents SECTION 1 ENTERPRISE METADATA ENVIRONMENT...1-1 1.1 TECHNICAL ENVIRONMENT...1-1 1.2 METADATA CAPTURE...1-1