Statistical Disclosure Control meets Recommender Systems: A practical approach
|
|
|
- Garry Ryan
- 5 years ago
- Views:
Transcription







1 Research Group Statistical Disclosure Control meets Recommender Systems: A practical approach Fran Casino and Agusti Solanas {franciscojose.casino, agusti.solanas}@urv.cat Smart Health Research Group Universitat Rovira i Virgili
2 Background Outline Recommender Systems and Collaborative Filtering Limitations and Countermeasures Statistical Disclosure Control and Privacy-Preserving Collaborative Filtering Evaluation Tools Contributions to Privacy-Preserving Collaborative Filtering Evaluated Methods Experiments and Comparisons Conclusions 2

![directs to appropriate recipients [Resnick et. al.].](/docs-images/80/82194331/images/3-1.jpg "The main advantage of Recommender Systems (RS) is that they help us to deal with/overcome information overload. P.")
3 Recommender Systems Recommender Systems evolve from the Knowledge Discovery in Databases field. In a typical recommender system, people provide opinions/evaluations as inputs, which the system then aggregates and directs to appropriate recipients [Resnick et. al.]. The main advantage of Recommender Systems (RS) is that they help us to deal with/overcome information overload. P. Resnick, H. Varian, Recommender Systems Communications of the ACM 40(3), 56 (1997) 3
4 Collaborative Filtering Collaborative Filtering (CF) is a crowdsourcingbased recommender system which aims to make suggestions on items (books, music, movies or routes) based on preferences of users that have already acquired and/or rated these items. 4



5 CF Philosophy The recommendations provided by CF methods are based on the assumption that similar users will be interested in the same items. Users collaborate in order to obtain more quality recommendations. 5


6 CF Families Collaborative Filtering Memory Model Hybrid 6

7 Limitations & Privacy Bribing Shilling Sparseness CF limitations Synonymy Scalability Privacy Cold start Black sheep 7
8 Collaborative Filtering & Privacy Recommender Systems Collaborative Filtering Privacy-preserving Collaborative Filtering Collaborative Filtering Statistical Disclosure Control 8
9 Statistical Disclosure Control Statistical Disclosure Control (SDC, [Hunderpool et. al.]), seeks to anonymise microdata sets (i.e. datasets consisting of multiple records corresponding to individual respondents) in order to prevent their disclosure. Types of disclosure Identity Disclosure Identification of an entity (person, institution). Attribute Disclosure The intruder finds something new about the target entity. A. Hundepool, et al. Statistical Disclosure Control. Wiley,
10 Data Anonymisation Techniques Overview Top/bottom coding Rounding Sampling Suppression Generalisation Limitation of detail Anatomisation Data swapping Noise addition Microaggregation 10
 consider each cluster all ratings contains asat")
.")
11 Microaggregation Microaggregation is a family of SDC algorithms for datasets used to prevent against reidentification, which works in two stages: In1. thethe caseset of of RS records in a dataset is clustered in such a way that: We i) consider each cluster all ratings contains asat quasi-identifiers. least k records; Therefore, ii) recordswe within anonymise a cluster are allasratings similar as in possible. order to achieve k-anonymity. 2. Records within each cluster are replaced by a representative of the cluster, typically the centroid record (i.e. the average of the cluster). 11



12 Evaluation Tools Evaluation Tools SDC Metrics RS Metrics 12
13 SDC Information Loss The quantity of information which exist in the initial microdata and because of disclosure control methods does not occur in masked microdata [Willemborg et. al.]. Willemborg L., Waal T. Elements of Statistical Disclosure Control. Springer Verlag. 13
14 SDC Disclosure Risk The risk that a given form of disclosure will arise if a masked microdata is released [Chen et. al.]. Value/attribute disclosure Identity disclosure Individual measures - The risk per record or the probability of correctly re-identifying a unit. [Willemborg et. al.] Global measures - The risk for the entire dataset. Number of correct re-identifications according to a linking measure. [Domingo-Ferrer et. al.] Chen G., Keller-McNulty S. Estimation of Deidentification Disclosure Risk in Microdata. Journal of Official Statistics, Vol 14. No. 1, Willemborg L. Waal T. Elements of Statistical Disclosure Control, Springer Verlag. Domingo-Ferrer J. Torra V. Disclosure Risk Assessment in Statistical Microdata Protection Via Advanced Record Linkage Statistics and Computing, vol 13, no 4, pp


15 RS Metrics Prediction Match Slight Match Slight Reversal Reversal Real Value Ratings Range 15
16 Background Outline Recommender Systems and Information Overload Limitations of Collaborative Filtering and Countermeasures Statistical Disclosure Control and Privacy-Preserving Collaborative Filtering Evaluation Tools Contributions to Privacy-Preserving Collaborative Filtering Evaluated Methods Experiments and Comparisons Conclusions 16
17 PPCF Methods Gaussian Noise Addition with zero mean. Maximum Distance to Average Vector (MDAV) [Domingo-Ferrer et. al.] Variable MDAV (V-MDAV) [Solanas et. al.] J. Domingo-Ferrer and J. M. Mateo-Sanz. Practical data-oriented microaggregation for statistical disclosure control, IEEE Transactions on Knowledge and data Engineering, A. Solanas and A. Martínez-Ballesté. V-MDAV : A Multivariate Microaggregation With Variable Group Size. Seventh COMPSTAT Symposium of the IASC,

18 MDAV Fixed-size groups & k-anonymity 18
19 V-MDAV After each iteration, a heuristic evaluates whether to include a new record r to a group: If r is closer to the actual group than to the rest of records, according to its distance and a gain factor. If the actual group size is < 2k-1, because the optimal k-partition is achieved when groups consists of k to 2k-1 records [Domingo- Ferrer et. al.]. The gain factor can be tuned in order to fit the data distribution. Variable-sized Groups & k-anonymity J. Domingo-Ferrer and V. Torra. Ordinal, continuous and heterogenerous k-anonymity through microaggregation. Data Mining and Knowledge Discovery, 11(2): ,
20 Data Preprocessing Matrices are filled and stantardised (z-scores). where x i is the i-th value of item x and µ and σ are the mean and the standard deviation of item x, respectively. Next, the corresponding method is applied. Comparison between methods in terms of data utility and privacy using well-known metrics. 20


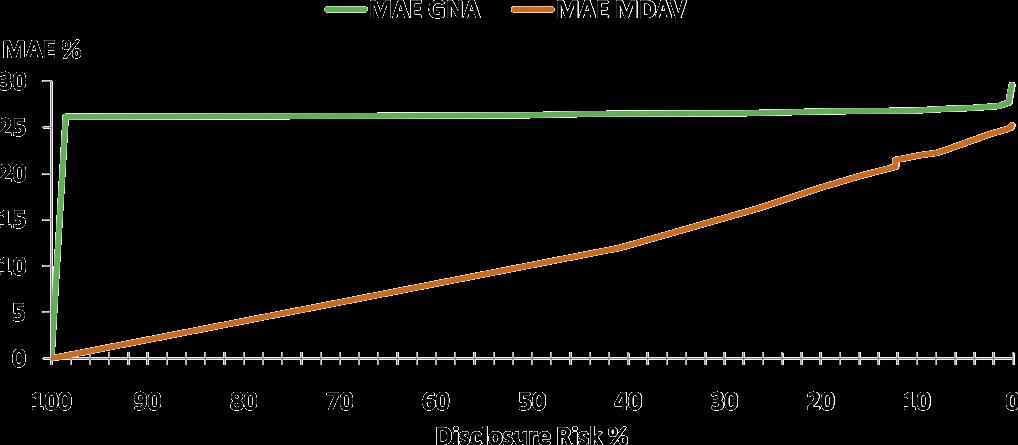
21 GNA & MDAV Movielens 100k Jester 21

22 MDAV & V-MDAV (I) 22

23 MDAV & V-MDAV (II) 23
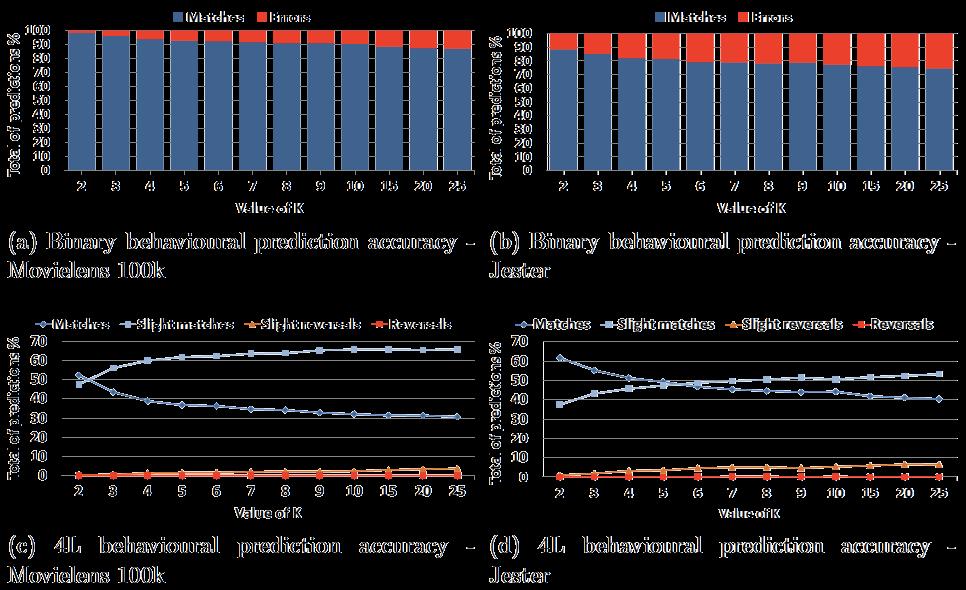
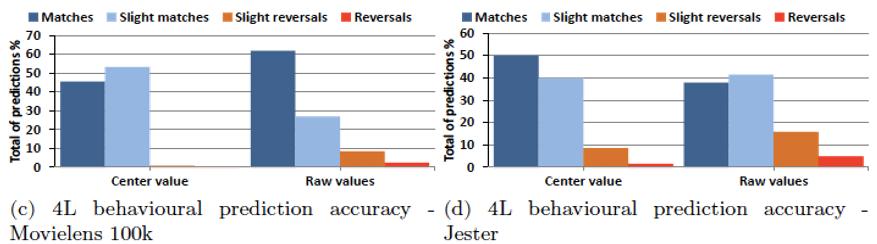
24 Behavioural Precision B/A 24
25 Conclusions - Highlights Despite the great advantages of using CF, we have highlighted its downside regarding users privacy. We have analysed/discussed how V-MDAV obtains better results and provides both more privacy and data usability than wellknown methods such as MDAV and Gaussian noise addition. Both microaggregation-based proposals achieve k-anonymity, which guarantees privacy by design, a feature not offered by GNA. Moreover, for low cardinality values, recommendations were more accurate than these obtained when using data without obfuscation, showing the efficacy of our proposal. The use of behavioural measures allowed us to better analyse data and increase its usability. 25
26 Research Group Statistical Disclosure Control meets Recommender Systems: A practical approach Fran Casino and Agusti Solanas {franciscojose.casino, agusti.solanas}@urv.cat Smart Health Research Group Universitat Rovira i Virgili
Protecting Against Maximum-Knowledge Adversaries in Microdata Release: Analysis of Masking and Synthetic Data Using the Permutation Model
 Protecting Against Maximum-Knowledge Adversaries in Microdata Release: Analysis of Masking and Synthetic Data Using the Permutation Model Josep Domingo-Ferrer and Krishnamurty Muralidhar Universitat Rovira
Protecting Against Maximum-Knowledge Adversaries in Microdata Release: Analysis of Masking and Synthetic Data Using the Permutation Model Josep Domingo-Ferrer and Krishnamurty Muralidhar Universitat Rovira
A COMPARATIVE STUDY ON MICROAGGREGATION TECHNIQUES FOR MICRODATA PROTECTION
 A COMPARATIVE STUDY ON MICROAGGREGATION TECHNIQUES FOR MICRODATA PROTECTION Sarat Kumar Chettri 1, Bonani Paul 2 and Ajoy Krishna Dutta 2 1 Department of Computer Science, Saint Mary s College, Shillong,
A COMPARATIVE STUDY ON MICROAGGREGATION TECHNIQUES FOR MICRODATA PROTECTION Sarat Kumar Chettri 1, Bonani Paul 2 and Ajoy Krishna Dutta 2 1 Department of Computer Science, Saint Mary s College, Shillong,
Disclosure Control by Computer Scientists: An Overview and an Application of Microaggregation to Mobility Data Anonymization
 Int. Statistical Inst.: Proc. 58th World Statistical Congress, 2011, Dublin (Session IPS060) p.1082 Disclosure Control by Computer Scientists: An Overview and an Application of Microaggregation to Mobility
Int. Statistical Inst.: Proc. 58th World Statistical Congress, 2011, Dublin (Session IPS060) p.1082 Disclosure Control by Computer Scientists: An Overview and an Application of Microaggregation to Mobility
Ordinal, Continuous and Heterogeneous k-anonymity Through Microaggregation
 Data Mining and Knowledge Discovery, 11, 195 212, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. DOI: 10.1007/s10618-005-0007-5 Ordinal, Continuous and Heterogeneous
Data Mining and Knowledge Discovery, 11, 195 212, 2005 c 2005 Springer Science + Business Media, Inc. Manufactured in The Netherlands. DOI: 10.1007/s10618-005-0007-5 Ordinal, Continuous and Heterogeneous
Fuzzy methods for database protection
 EUSFLAT-LFA 2011 July 2011 Aix-les-Bains, France Fuzzy methods for database protection Vicenç Torra1 Daniel Abril1 Guillermo Navarro-Arribas2 1 IIIA, Artificial Intelligence Research Institute CSIC, Spanish
EUSFLAT-LFA 2011 July 2011 Aix-les-Bains, France Fuzzy methods for database protection Vicenç Torra1 Daniel Abril1 Guillermo Navarro-Arribas2 1 IIIA, Artificial Intelligence Research Institute CSIC, Spanish
Partition Based Perturbation for Privacy Preserving Distributed Data Mining
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
Survey of Statistical Disclosure Control Technique
 Survey of Statistical Disclosure Control Technique Jony N 1, AnithaM 2, Department of Computer Science and Engineering 1, 2, Adithya Institute of technology, Coimbatore 1, 2 Email: nesajony@gmail.com 1,
Survey of Statistical Disclosure Control Technique Jony N 1, AnithaM 2, Department of Computer Science and Engineering 1, 2, Adithya Institute of technology, Coimbatore 1, 2 Email: nesajony@gmail.com 1,
n-confusion: a generalization of k-anonymity
 n-confusion: a generalization of k-anonymity ABSTRACT Klara Stokes Universitat Rovira i Virgili Dept. of Computer Engineering and Maths UNESCO Chair in Data Privacy Av. Països Catalans 26 43007 Tarragona,
n-confusion: a generalization of k-anonymity ABSTRACT Klara Stokes Universitat Rovira i Virgili Dept. of Computer Engineering and Maths UNESCO Chair in Data Privacy Av. Països Catalans 26 43007 Tarragona,
Anonymization Algorithms - Microaggregation and Clustering
 Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
A Disclosure Avoidance Research Agenda
 A Disclosure Avoidance Research Agenda presented at FCSM research conf. ; Nov. 5, 2013 session E-3; 10:15am: Data Disclosure Issues Paul B. Massell U.S. Census Bureau Center for Disclosure Avoidance Research
A Disclosure Avoidance Research Agenda presented at FCSM research conf. ; Nov. 5, 2013 session E-3; 10:15am: Data Disclosure Issues Paul B. Massell U.S. Census Bureau Center for Disclosure Avoidance Research
Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm
 Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm Majid Hatami Faculty of Electrical and Computer Engineering University of Tabriz,
Improving Results and Performance of Collaborative Filtering-based Recommender Systems using Cuckoo Optimization Algorithm Majid Hatami Faculty of Electrical and Computer Engineering University of Tabriz,
CS573 Data Privacy and Security. Li Xiong
 CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
Privacy-preserving Publication of Trajectories Using Microaggregation
 Privacy-preserving Publication of Trajectories Using Microaggregation Josep Domingo-Ferrer, Michal Sramka, and Rolando Trujillo-Rasúa Universitat Rovira i Virgili UNESCO Chair in Data Privacy Department
Privacy-preserving Publication of Trajectories Using Microaggregation Josep Domingo-Ferrer, Michal Sramka, and Rolando Trujillo-Rasúa Universitat Rovira i Virgili UNESCO Chair in Data Privacy Department
CERIAS Tech Report
 CERIAS Tech Report 25-96 A FRAMEWORK FOR EVALUATING PRIVACY PRESERVING DATA MINING ALGORITHMS by ELISA BERTINO, IGOR NAI FOVINO, LOREDANA PARASILITI PROVENZA Center for Education and Research in Information
CERIAS Tech Report 25-96 A FRAMEWORK FOR EVALUATING PRIVACY PRESERVING DATA MINING ALGORITHMS by ELISA BERTINO, IGOR NAI FOVINO, LOREDANA PARASILITI PROVENZA Center for Education and Research in Information
RESEARCH REPORT SERIES (Statistics # ) Masking and Re-identification Methods for Public-use Microdata: Overview and Research Problems
 Masking and Re-identification Methods for Public-use Microdata: Overview and Research Problems") RESEARCH REPORT SERIES (Statistics #2004-06) Masking and Re-identification Methods for Public-use Microdata: Overview and Research Problems William E. Winkler Statistical Research Division U.S. Bureau
RESEARCH REPORT SERIES (Statistics #2004-06) Masking and Re-identification Methods for Public-use Microdata: Overview and Research Problems William E. Winkler Statistical Research Division U.S. Bureau
An efficient hash-based algorithm for minimal k-anonymity
 An efficient hash-based algorithm for minimal k-anonymity Xiaoxun Sun Min Li Hua Wang Ashley Plank Department of Mathematics & Computing University of Southern Queensland Toowoomba, Queensland 4350, Australia
An efficient hash-based algorithm for minimal k-anonymity Xiaoxun Sun Min Li Hua Wang Ashley Plank Department of Mathematics & Computing University of Southern Queensland Toowoomba, Queensland 4350, Australia
Abstract. Index Terms
 Microaggregation Sorting Framework for 1 K-Anonymity Statistical Disclosure Control in Cloud Computing Md Enamul Kabir 1 Abdun Naser Mahmood 2 Abdul K Mustafa 3 Hua Wang 4 Abstract In cloud computing,
Microaggregation Sorting Framework for 1 K-Anonymity Statistical Disclosure Control in Cloud Computing Md Enamul Kabir 1 Abdun Naser Mahmood 2 Abdul K Mustafa 3 Hua Wang 4 Abstract In cloud computing,
Transforming Data to Satisfy Privacy Constraints
 Transforming Data to Satisfy Privacy Constraints Vijay S. Iyengar IBM Research Division Thomas J. Watson Research Center P.O. Box 218, Yorktown Heights, NY 10598, USA vsi@us.ibm.com ABSTRACT Data on individuals
Transforming Data to Satisfy Privacy Constraints Vijay S. Iyengar IBM Research Division Thomas J. Watson Research Center P.O. Box 218, Yorktown Heights, NY 10598, USA vsi@us.ibm.com ABSTRACT Data on individuals
The Two Dimensions of Data Privacy Measures
 The Two Dimensions of Data Privacy Measures Abstract Orit Levin Page 1 of 9 Javier Salido Corporat e, Extern a l an d Lega l A ffairs, Microsoft This paper describes a practical framework for the first
The Two Dimensions of Data Privacy Measures Abstract Orit Levin Page 1 of 9 Javier Salido Corporat e, Extern a l an d Lega l A ffairs, Microsoft This paper describes a practical framework for the first
A Recommender System Based on Improvised K- Means Clustering Algorithm
 A Recommender System Based on Improvised K- Means Clustering Algorithm Shivani Sharma Department of Computer Science and Applications, Kurukshetra University, Kurukshetra Shivanigaur83@yahoo.com Abstract:
A Recommender System Based on Improvised K- Means Clustering Algorithm Shivani Sharma Department of Computer Science and Applications, Kurukshetra University, Kurukshetra Shivanigaur83@yahoo.com Abstract:
Privacy Preserving Data Sharing in Data Mining Environment
 Privacy Preserving Data Sharing in Data Mining Environment PH.D DISSERTATION BY SUN, XIAOXUN A DISSERTATION SUBMITTED TO THE UNIVERSITY OF SOUTHERN QUEENSLAND IN FULLFILLMENT OF THE REQUIREMENTS FOR THE
Privacy Preserving Data Sharing in Data Mining Environment PH.D DISSERTATION BY SUN, XIAOXUN A DISSERTATION SUBMITTED TO THE UNIVERSITY OF SOUTHERN QUEENSLAND IN FULLFILLMENT OF THE REQUIREMENTS FOR THE
k-anonymization May Be NP-Hard, but Can it Be Practical?
 k-anonymization May Be NP-Hard, but Can it Be Practical? David Wilson RTI International dwilson@rti.org 1 Introduction This paper discusses the application of k-anonymity to a real-world set of microdata
k-anonymization May Be NP-Hard, but Can it Be Practical? David Wilson RTI International dwilson@rti.org 1 Introduction This paper discusses the application of k-anonymity to a real-world set of microdata
Comparative Analysis of Anonymization Techniques
 International Journal of Electronic and Electrical Engineering. ISSN 0974-2174 Volume 7, Number 8 (2014), pp. 773-778 International Research Publication House http://www.irphouse.com Comparative Analysis
International Journal of Electronic and Electrical Engineering. ISSN 0974-2174 Volume 7, Number 8 (2014), pp. 773-778 International Research Publication House http://www.irphouse.com Comparative Analysis
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Review on Techniques of Collaborative Tagging
 Review on Techniques of Collaborative Tagging Ms. Benazeer S. Inamdar 1, Mrs. Gyankamal J. Chhajed 2 1 Student, M. E. Computer Engineering, VPCOE Baramati, Savitribai Phule Pune University, India benazeer.inamdar@gmail.com
Review on Techniques of Collaborative Tagging Ms. Benazeer S. Inamdar 1, Mrs. Gyankamal J. Chhajed 2 1 Student, M. E. Computer Engineering, VPCOE Baramati, Savitribai Phule Pune University, India benazeer.inamdar@gmail.com
ARGUS version 4.0. User s Manual. Statistics Netherlands Project: CASC-project P.O. Box 4000
 µ ARGUS version 4.0 User s Manual Document: 2-D6 Statistics Netherlands Project: CASC-project P.O. Box 4000 Date: November 2004 2270 JM Voorburg BPA no: 768-02-TMO The Netherlands email: ahnl@rnd.vb.cbs.nl
µ ARGUS version 4.0 User s Manual Document: 2-D6 Statistics Netherlands Project: CASC-project P.O. Box 4000 Date: November 2004 2270 JM Voorburg BPA no: 768-02-TMO The Netherlands email: ahnl@rnd.vb.cbs.nl
Collaborative Filtering using Euclidean Distance in Recommendation Engine
 Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Data Management Glossary
 Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
ARGUS version 4.1. User s Manual. Statistics Netherlands Project: CENEX-project P.O. Box 4000
 µ ARGUS version 4.1 User s Manual Statistics Netherlands Project: CENEX-project P.O. Box 4000 Date: February 2007 2270 JM Voorburg BPA no: 768-02-TMO The Netherlands email: ahnl@rnd.vb.cbs.nl Contributors:
µ ARGUS version 4.1 User s Manual Statistics Netherlands Project: CENEX-project P.O. Box 4000 Date: February 2007 2270 JM Voorburg BPA no: 768-02-TMO The Netherlands email: ahnl@rnd.vb.cbs.nl Contributors:
Utility-Preserving Differentially Private Data Releases Via Individual Ranking Microaggregation
 Utility-Preserving Differentially Private Data Releases Via Individual Ranking Microaggregation David Sánchez, Josep Domingo-Ferrer, Sergio Martínez, and Jordi Soria-Comas UNESCO Chair in Data Privacy,
Utility-Preserving Differentially Private Data Releases Via Individual Ranking Microaggregation David Sánchez, Josep Domingo-Ferrer, Sergio Martínez, and Jordi Soria-Comas UNESCO Chair in Data Privacy,
A Survey on Various Techniques of Recommendation System in Web Mining
 A Survey on Various Techniques of Recommendation System in Web Mining 1 Yagnesh G. patel, 2 Vishal P.Patel 1 Department of computer engineering 1 S.P.C.E, Visnagar, India Abstract - Today internet has
A Survey on Various Techniques of Recommendation System in Web Mining 1 Yagnesh G. patel, 2 Vishal P.Patel 1 Department of computer engineering 1 S.P.C.E, Visnagar, India Abstract - Today internet has
Overview. Data-mining. Commercial & Scientific Applications. Ongoing Research Activities. From Research to Technology Transfer
 Data Mining George Karypis Department of Computer Science Digital Technology Center University of Minnesota, Minneapolis, USA. http://www.cs.umn.edu/~karypis karypis@cs.umn.edu Overview Data-mining What
Data Mining George Karypis Department of Computer Science Digital Technology Center University of Minnesota, Minneapolis, USA. http://www.cs.umn.edu/~karypis karypis@cs.umn.edu Overview Data-mining What
Privacy-Preserving. Introduction to. Data Publishing. Concepts and Techniques. Benjamin C. M. Fung, Ke Wang, Chapman & Hall/CRC. S.
 Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Comparative Evaluation of Synthetic Dataset Generation Methods
 Comparative Evaluation of Synthetic Dataset Generation Methods Ashish Dandekar, Remmy A. M. Zen, Stéphane Bressan December 12, 2017 1 / 17 Open Data vs Data Privacy Open Data Helps crowdsourcing the research
Comparative Evaluation of Synthetic Dataset Generation Methods Ashish Dandekar, Remmy A. M. Zen, Stéphane Bressan December 12, 2017 1 / 17 Open Data vs Data Privacy Open Data Helps crowdsourcing the research
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Privacy Preserving Data Mining: An approach to safely share and use sensible medical data
 Privacy Preserving Data Mining: An approach to safely share and use sensible medical data Gerhard Kranner, Viscovery Biomax Symposium, June 24 th, 2016, Munich www.viscovery.net Privacy protection vs knowledge
Privacy Preserving Data Mining: An approach to safely share and use sensible medical data Gerhard Kranner, Viscovery Biomax Symposium, June 24 th, 2016, Munich www.viscovery.net Privacy protection vs knowledge
Record Linkage using Probabilistic Methods and Data Mining Techniques
 Doi:10.5901/mjss.2017.v8n3p203 Abstract Record Linkage using Probabilistic Methods and Data Mining Techniques Ogerta Elezaj Faculty of Economy, University of Tirana Gloria Tuxhari Faculty of Economy, University
Doi:10.5901/mjss.2017.v8n3p203 Abstract Record Linkage using Probabilistic Methods and Data Mining Techniques Ogerta Elezaj Faculty of Economy, University of Tirana Gloria Tuxhari Faculty of Economy, University
Recommendation with Differential Context Weighting
 Recommendation with Differential Context Weighting Yong Zheng Robin Burke Bamshad Mobasher Center for Web Intelligence DePaul University Chicago, IL USA Conference on UMAP June 12, 2013 Overview Introduction
Recommendation with Differential Context Weighting Yong Zheng Robin Burke Bamshad Mobasher Center for Web Intelligence DePaul University Chicago, IL USA Conference on UMAP June 12, 2013 Overview Introduction
Self-Organizing Maps for cyclic and unbounded graphs
 Self-Organizing Maps for cyclic and unbounded graphs M. Hagenbuchner 1, A. Sperduti 2, A.C. Tsoi 3 1- University of Wollongong, Wollongong, Australia. 2- University of Padova, Padova, Italy. 3- Hong Kong
Self-Organizing Maps for cyclic and unbounded graphs M. Hagenbuchner 1, A. Sperduti 2, A.C. Tsoi 3 1- University of Wollongong, Wollongong, Australia. 2- University of Padova, Padova, Italy. 3- Hong Kong
Privacy Preserving Data Publishing for Recommender System
 IT 11 023 Examensarbete 30 hp Maj 2011 Privacy Preserving Data Publishing for Recommender System Xiaoqiang Chen Institutionen för informationsteknologi Department of Information Technology Abstract Privacy
IT 11 023 Examensarbete 30 hp Maj 2011 Privacy Preserving Data Publishing for Recommender System Xiaoqiang Chen Institutionen för informationsteknologi Department of Information Technology Abstract Privacy
Comparison of Recommender System Algorithms focusing on the New-Item and User-Bias Problem
 Comparison of Recommender System Algorithms focusing on the New-Item and User-Bias Problem Stefan Hauger 1, Karen H. L. Tso 2, and Lars Schmidt-Thieme 2 1 Department of Computer Science, University of
Comparison of Recommender System Algorithms focusing on the New-Item and User-Bias Problem Stefan Hauger 1, Karen H. L. Tso 2, and Lars Schmidt-Thieme 2 1 Department of Computer Science, University of
Randomized Response Technique in Data Mining
 Randomized Response Technique in Data Mining Monika Soni Arya College of Engineering and IT, Jaipur(Raj.) 12.monika@gmail.com Vishal Shrivastva Arya College of Engineering and IT, Jaipur(Raj.) vishal500371@yahoo.co.in
Randomized Response Technique in Data Mining Monika Soni Arya College of Engineering and IT, Jaipur(Raj.) 12.monika@gmail.com Vishal Shrivastva Arya College of Engineering and IT, Jaipur(Raj.) vishal500371@yahoo.co.in
Business microdata dissemination at Istat
 Business microdata dissemination at Istat Daniela Ichim Luisa Franconi ichim@istat.it franconi@istat.it Outline - Released products - Microdata dissemination - Business microdata dissemination - Documentation
Business microdata dissemination at Istat Daniela Ichim Luisa Franconi ichim@istat.it franconi@istat.it Outline - Released products - Microdata dissemination - Business microdata dissemination - Documentation
Differential Privacy. Seminar: Robust Data Mining Techniques. Thomas Edlich. July 16, 2017
 Differential Privacy Seminar: Robust Techniques Thomas Edlich Technische Universität München Department of Informatics kdd.in.tum.de July 16, 2017 Outline 1. Introduction 2. Definition and Features of
Differential Privacy Seminar: Robust Techniques Thomas Edlich Technische Universität München Department of Informatics kdd.in.tum.de July 16, 2017 Outline 1. Introduction 2. Definition and Features of
Rotation Perturbation Technique for Privacy Preserving in Data Stream Mining
 218 IJSRSET Volume 4 Issue 8 Print ISSN: 2395-199 Online ISSN : 2394-499 Themed Section : Engineering and Technology Rotation Perturbation Technique for Privacy Preserving in Data Stream Mining Kalyani
218 IJSRSET Volume 4 Issue 8 Print ISSN: 2395-199 Online ISSN : 2394-499 Themed Section : Engineering and Technology Rotation Perturbation Technique for Privacy Preserving in Data Stream Mining Kalyani
Recommendation Algorithms: Collaborative Filtering. CSE 6111 Presentation Advanced Algorithms Fall Presented by: Farzana Yasmeen
 Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
Privacy Preserving Data Mining, Evaluation Methodologies. Igor Nai Fovino and Marcelo Masera
 Privacy Preserving Data Mining, Evaluation Methodologies Igor Nai Fovino and Marcelo Masera EUR 23069 EN - 2008 The Institute for the Protection and Security of the Citizen provides research-based, systemsoriented
Privacy Preserving Data Mining, Evaluation Methodologies Igor Nai Fovino and Marcelo Masera EUR 23069 EN - 2008 The Institute for the Protection and Security of the Citizen provides research-based, systemsoriented
Engineering Privacy by Design Reloaded
 H2020-ICT-15 GA 688722 Engineering Privacy by Design Reloaded Seda Gürses 1, Carmela Troncoso 2, Claudia Diaz 3 1 New York University / Princeton University 2 IMDEA Software Institute 3 KU Leuven Privacy
H2020-ICT-15 GA 688722 Engineering Privacy by Design Reloaded Seda Gürses 1, Carmela Troncoso 2, Claudia Diaz 3 1 New York University / Princeton University 2 IMDEA Software Institute 3 KU Leuven Privacy
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique
 Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Recommender Systems using Graph Theory
 Recommender Systems using Graph Theory Vishal Venkatraman * School of Computing Science and Engineering vishal2010@vit.ac.in Swapnil Vijay School of Computing Science and Engineering swapnil2010@vit.ac.in
Recommender Systems using Graph Theory Vishal Venkatraman * School of Computing Science and Engineering vishal2010@vit.ac.in Swapnil Vijay School of Computing Science and Engineering swapnil2010@vit.ac.in
Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust
 Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust G.Mareeswari 1, V.Anusuya 2 ME, Department of CSE, PSR Engineering College, Sivakasi, Tamilnadu,
Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust G.Mareeswari 1, V.Anusuya 2 ME, Department of CSE, PSR Engineering College, Sivakasi, Tamilnadu,
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING
 A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD. Abstract
 for Movie Recommendations) Drew Hodun SCPD. Abstract") Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD Abstract There are two common main approaches to ML recommender systems, feedback-based systems and content-based systems.
Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD Abstract There are two common main approaches to ML recommender systems, feedback-based systems and content-based systems.
An Efficient Clustering Method for k-anonymization
 An Efficient Clustering Method for -Anonymization Jun-Lin Lin Department of Information Management Yuan Ze University Chung-Li, Taiwan jun@saturn.yzu.edu.tw Meng-Cheng Wei Department of Information Management
An Efficient Clustering Method for -Anonymization Jun-Lin Lin Department of Information Management Yuan Ze University Chung-Li, Taiwan jun@saturn.yzu.edu.tw Meng-Cheng Wei Department of Information Management
Property1 Property2. by Elvir Sabic. Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14
 Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
Towards the Use of Graph Summaries for Privacy Enhancing Release and Querying of Linked Data
 Towards the Use of Graph Summaries for Privacy Enhancing Release and Querying of Linked Data Benjamin Heitmann, Felix Hermsen, and Stefan Decker Informatik 5 Information Systems RWTH Aachen University,
Towards the Use of Graph Summaries for Privacy Enhancing Release and Querying of Linked Data Benjamin Heitmann, Felix Hermsen, and Stefan Decker Informatik 5 Information Systems RWTH Aachen University,
Security Control Methods for Statistical Database
 Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Unsupervised learning on Color Images
 Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
A Survey on: Privacy Preserving Mining Implementation Techniques
 A Survey on: Privacy Preserving Mining Implementation Techniques Mukesh Kumar Dangi P.G. Scholar Computer Science & Engineering, Millennium Institute of Technology Bhopal E-mail-mukeshlncit1987@gmail.com
A Survey on: Privacy Preserving Mining Implementation Techniques Mukesh Kumar Dangi P.G. Scholar Computer Science & Engineering, Millennium Institute of Technology Bhopal E-mail-mukeshlncit1987@gmail.com
Hierarchical and Ensemble Clustering
 Hierarchical and Ensemble Clustering Ke Chen Reading: [7.8-7., EA], [25.5, KPM], [Fred & Jain, 25] COMP24 Machine Learning Outline Introduction Cluster Distance Measures Agglomerative Algorithm Example
Hierarchical and Ensemble Clustering Ke Chen Reading: [7.8-7., EA], [25.5, KPM], [Fred & Jain, 25] COMP24 Machine Learning Outline Introduction Cluster Distance Measures Agglomerative Algorithm Example
Hybrid Recommendation System Using Clustering and Collaborative Filtering
 Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Triangulation-Based Multivariate Microaggregation
 gmail Triangulation-Based Multivariate Microaggregation Juvenal Machín Casañas (jmachinc@uoc.edu) Open University of Catalonia Agustí Solanas Gómez (agusti.solanas@urv.cat) Smart Health Research Group
gmail Triangulation-Based Multivariate Microaggregation Juvenal Machín Casañas (jmachinc@uoc.edu) Open University of Catalonia Agustí Solanas Gómez (agusti.solanas@urv.cat) Smart Health Research Group
Introduction to Data Mining
 Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1 Privacy Preserving Data Mining Privacy concerns about personal data AOL
Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1 Privacy Preserving Data Mining Privacy concerns about personal data AOL
Know your neighbours: Machine Learning on Graphs
 Know your neighbours: Machine Learning on Graphs Andrew Docherty Senior Research Engineer andrew.docherty@data61.csiro.au www.data61.csiro.au 2 Graphs are Everywhere Online Social Networks Transportation
Know your neighbours: Machine Learning on Graphs Andrew Docherty Senior Research Engineer andrew.docherty@data61.csiro.au www.data61.csiro.au 2 Graphs are Everywhere Online Social Networks Transportation
Web Service Recommendation Using Hybrid Approach
 e-issn 2455 1392 Volume 2 Issue 5, May 2016 pp. 648 653 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com Web Service Using Hybrid Approach Priyanshi Barod 1, M.S.Bhamare 2, Ruhi Patankar
e-issn 2455 1392 Volume 2 Issue 5, May 2016 pp. 648 653 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com Web Service Using Hybrid Approach Priyanshi Barod 1, M.S.Bhamare 2, Ruhi Patankar
Data Distortion for Privacy Protection in a Terrorist Analysis System
 Data Distortion for Privacy Protection in a Terrorist Analysis System Shuting Xu, Jun Zhang, Dianwei Han, and Jie Wang Department of Computer Science, University of Kentucky, Lexington KY 40506-0046, USA
Data Distortion for Privacy Protection in a Terrorist Analysis System Shuting Xu, Jun Zhang, Dianwei Han, and Jie Wang Department of Computer Science, University of Kentucky, Lexington KY 40506-0046, USA
Prowess Improvement of Accuracy for Moving Rating Recommendation System
 2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Scienceand Technology Prowess Improvement of Accuracy for Moving Rating Recommendation System P. Damodharan *1,
2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Scienceand Technology Prowess Improvement of Accuracy for Moving Rating Recommendation System P. Damodharan *1,
A Review on Privacy Preserving Data Mining Approaches
 A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
Privacy-Enhanced Collaborative Filtering
 Privacy-Enhanced Collaborative Filtering Shlomo Berkovsky 1, Yaniv Eytani 1, Tsvi Kuflik 2, Francesco Ricci 3 1 Computer Science Department, University of Haifa, Israel {slavax, ieytani}@cs.haifa.ac.il
Privacy-Enhanced Collaborative Filtering Shlomo Berkovsky 1, Yaniv Eytani 1, Tsvi Kuflik 2, Francesco Ricci 3 1 Computer Science Department, University of Haifa, Israel {slavax, ieytani}@cs.haifa.ac.il
k-degree Anonymity And Edge Selection: Improving Data Utility In Large Networks
 Knowledge and Information Systems manuscript No. (will be inserted by the editor) k-degree Anonymity And Edge Selection: Improving Data Utility In Large Networks Jordi Casas-oma Jordi Herrera-Joancomartí
Knowledge and Information Systems manuscript No. (will be inserted by the editor) k-degree Anonymity And Edge Selection: Improving Data Utility In Large Networks Jordi Casas-oma Jordi Herrera-Joancomartí
The Two Dimensions of Data Privacy Measures
 The Two Dimensions of Data Privacy Measures Ms. Orit Levin, Principle Program Manager Corporate, External and Legal Affairs, Microsoft Abstract This paper describes a practical framework that can be used
The Two Dimensions of Data Privacy Measures Ms. Orit Levin, Principle Program Manager Corporate, External and Legal Affairs, Microsoft Abstract This paper describes a practical framework that can be used
Privacy, Security & Ethical Issues
 Privacy, Security & Ethical Issues How do we mine data when we can t even look at it? 2 Individual Privacy Nobody should know more about any entity after the data mining than they did before Approaches:
Privacy, Security & Ethical Issues How do we mine data when we can t even look at it? 2 Individual Privacy Nobody should know more about any entity after the data mining than they did before Approaches:
KEYWORDS: Clustering, RFPCM Algorithm, Ranking Method, Query Redirection Method.
 IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY IMPROVED ROUGH FUZZY POSSIBILISTIC C-MEANS (RFPCM) CLUSTERING ALGORITHM FOR MARKET DATA T.Buvana*, Dr.P.krishnakumari *Research
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY IMPROVED ROUGH FUZZY POSSIBILISTIC C-MEANS (RFPCM) CLUSTERING ALGORITHM FOR MARKET DATA T.Buvana*, Dr.P.krishnakumari *Research
Social Voting Techniques: A Comparison of the Methods Used for Explicit Feedback in Recommendation Systems
 Special Issue on Computer Science and Software Engineering Social Voting Techniques: A Comparison of the Methods Used for Explicit Feedback in Recommendation Systems Edward Rolando Nuñez-Valdez 1, Juan
Special Issue on Computer Science and Software Engineering Social Voting Techniques: A Comparison of the Methods Used for Explicit Feedback in Recommendation Systems Edward Rolando Nuñez-Valdez 1, Juan
Novelty Detection from an Ego- Centric Perspective
 Novelty Detection from an Ego- Centric Perspective Omid Aghazadeh, Josephine Sullivan, and Stefan Carlsson Presented by Randall Smith 1 Outline Introduction Sequence Alignment Appearance Based Cues Geometric
Novelty Detection from an Ego- Centric Perspective Omid Aghazadeh, Josephine Sullivan, and Stefan Carlsson Presented by Randall Smith 1 Outline Introduction Sequence Alignment Appearance Based Cues Geometric
Location Privacy in Location-Based Services: Beyond TTP-based Schemes
 Location Privacy in Location-Based Services: Beyond TTP-based Schemes Agusti Solanas, Josep Domingo-Ferrer, and Antoni Martínez-Ballesté Rovira i Virgili University Department of Computer Engineering and
Location Privacy in Location-Based Services: Beyond TTP-based Schemes Agusti Solanas, Josep Domingo-Ferrer, and Antoni Martínez-Ballesté Rovira i Virgili University Department of Computer Engineering and
Privacy-Preserving Collaborative Filtering using Randomized Perturbation Techniques
 Privacy-Preserving Collaborative Filtering using Randomized Perturbation Techniques Huseyin Polat and Wenliang Du Systems Assurance Institute Department of Electrical Engineering and Computer Science Syracuse
Privacy-Preserving Collaborative Filtering using Randomized Perturbation Techniques Huseyin Polat and Wenliang Du Systems Assurance Institute Department of Electrical Engineering and Computer Science Syracuse
Implementation of Privacy Mechanism using Curve Fitting Method for Data Publishing in Health Care Domain
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 5, May 2014, pg.1105
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 5, May 2014, pg.1105
A new shiny GUI for sdcmicro
 A new shiny GUI for sdcmicro Bernhard Meindl, Alexander Kowarik, Matthias Templ, Matthew Welch, Thijs Benschop Methods Division, Statistics Austria, Vienna, Austria ZHAW - Zurich University of Applied
A new shiny GUI for sdcmicro Bernhard Meindl, Alexander Kowarik, Matthias Templ, Matthew Welch, Thijs Benschop Methods Division, Statistics Austria, Vienna, Austria ZHAW - Zurich University of Applied
Database and Knowledge-Base Systems: Data Mining. Martin Ester
 Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing
 A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing Alexander Smirnov, Andrew Ponomarev St. Petersburg Institute for Informatics and Automation of the Russian Academy
A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing Alexander Smirnov, Andrew Ponomarev St. Petersburg Institute for Informatics and Automation of the Russian Academy
Challenges in Ubiquitous Data Mining
 LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
Artificial Neuron Modelling Based on Wave Shape
 Artificial Neuron Modelling Based on Wave Shape Kieran Greer, Distributed Computing Systems, Belfast, UK. http://distributedcomputingsystems.co.uk Version 1.2 Abstract This paper describes a new model
Artificial Neuron Modelling Based on Wave Shape Kieran Greer, Distributed Computing Systems, Belfast, UK. http://distributedcomputingsystems.co.uk Version 1.2 Abstract This paper describes a new model
Survey Result on Privacy Preserving Techniques in Data Publishing
 Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Co-clustering for differentially private synthetic data generation
 Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
8/3/2017. Contour Assessment for Quality Assurance and Data Mining. Objective. Outline. Tom Purdie, PhD, MCCPM
 Contour Assessment for Quality Assurance and Data Mining Tom Purdie, PhD, MCCPM Objective Understand the state-of-the-art in contour assessment for quality assurance including data mining-based techniques
Contour Assessment for Quality Assurance and Data Mining Tom Purdie, PhD, MCCPM Objective Understand the state-of-the-art in contour assessment for quality assurance including data mining-based techniques
Collaborative Filtering Based on Iterative Principal Component Analysis. Dohyun Kim and Bong-Jin Yum*
 Collaborative Filtering Based on Iterative Principal Component Analysis Dohyun Kim and Bong-Jin Yum Department of Industrial Engineering, Korea Advanced Institute of Science and Technology, 373-1 Gusung-Dong,
Collaborative Filtering Based on Iterative Principal Component Analysis Dohyun Kim and Bong-Jin Yum Department of Industrial Engineering, Korea Advanced Institute of Science and Technology, 373-1 Gusung-Dong,
Towards Traffic Anomaly Detection via Reinforcement Learning and Data Flow
 Towards Traffic Anomaly Detection via Reinforcement Learning and Data Flow Arturo Servin Computer Science, University of York aservin@cs.york.ac.uk Abstract. Protection of computer networks against security
Towards Traffic Anomaly Detection via Reinforcement Learning and Data Flow Arturo Servin Computer Science, University of York aservin@cs.york.ac.uk Abstract. Protection of computer networks against security
Analysis of Dendrogram Tree for Identifying and Visualizing Trends in Multi-attribute Transactional Data
 Analysis of Dendrogram Tree for Identifying and Visualizing Trends in Multi-attribute Transactional Data D.Radha Rani 1, A.Vini Bharati 2, P.Lakshmi Durga Madhuri 3, M.Phaneendra Babu 4, A.Sravani 5 Department
Analysis of Dendrogram Tree for Identifying and Visualizing Trends in Multi-attribute Transactional Data D.Radha Rani 1, A.Vini Bharati 2, P.Lakshmi Durga Madhuri 3, M.Phaneendra Babu 4, A.Sravani 5 Department
arxiv: v4 [cs.ir] 28 Jul 2016
![arxiv: v4 [cs.ir] 28 Jul 2016](/thumbs/77/76321758.jpg "arxiv: v4 [cs.ir] 28 Jul 2016") Review-Based Rating Prediction arxiv:1607.00024v4 [cs.ir] 28 Jul 2016 Tal Hadad Dept. of Information Systems Engineering, Ben-Gurion University E-mail: tah@post.bgu.ac.il Abstract Recommendation systems
Review-Based Rating Prediction arxiv:1607.00024v4 [cs.ir] 28 Jul 2016 Tal Hadad Dept. of Information Systems Engineering, Ben-Gurion University E-mail: tah@post.bgu.ac.il Abstract Recommendation systems
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University
 Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
COLD-START PRODUCT RECOMMENDATION THROUGH SOCIAL NETWORKING SITES USING WEB SERVICE INFORMATION
 COLD-START PRODUCT RECOMMENDATION THROUGH SOCIAL NETWORKING SITES USING WEB SERVICE INFORMATION Z. HIMAJA 1, C.SREEDHAR 2 1 PG Scholar, Dept of CSE, G Pulla Reddy Engineering College, Kurnool (District),
COLD-START PRODUCT RECOMMENDATION THROUGH SOCIAL NETWORKING SITES USING WEB SERVICE INFORMATION Z. HIMAJA 1, C.SREEDHAR 2 1 PG Scholar, Dept of CSE, G Pulla Reddy Engineering College, Kurnool (District),
Chapter 5: Outlier Detection
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 5: Outlier Detection Lecture: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 5: Outlier Detection Lecture: Prof. Dr.
Available online at ScienceDirect. Procedia Technology 17 (2014 )
") Available online at www.sciencedirect.com ScienceDirect Procedia Technology 17 (2014 ) 528 533 Conference on Electronics, Telecommunications and Computers CETC 2013 Social Network and Device Aware Personalized
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 17 (2014 ) 528 533 Conference on Electronics, Telecommunications and Computers CETC 2013 Social Network and Device Aware Personalized
Hotel Recommendation Based on Hybrid Model
 Hotel Recommendation Based on Hybrid Model Jing WANG, Jiajun SUN, Zhendong LIN Abstract: This project develops a hybrid model that combines content-based with collaborative filtering (CF) for hotel recommendation.
Hotel Recommendation Based on Hybrid Model Jing WANG, Jiajun SUN, Zhendong LIN Abstract: This project develops a hybrid model that combines content-based with collaborative filtering (CF) for hotel recommendation.
CS435 Introduction to Big Data Spring 2018 Colorado State University. 3/21/2018 Week 10-B Sangmi Lee Pallickara. FAQs. Collaborative filtering
 W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
Multi-Level Trust Privacy Preserving Data Mining to Enhance Data Security and Prevent Leakage of the Sensitive Data
 Bonfring International Journal of Industrial Engineering and Management Science, Vol. 7, No. 2, May 2017 21 Multi-Level Trust Privacy Preserving Data Mining to Enhance Data Security and Prevent Leakage
Bonfring International Journal of Industrial Engineering and Management Science, Vol. 7, No. 2, May 2017 21 Multi-Level Trust Privacy Preserving Data Mining to Enhance Data Security and Prevent Leakage
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What