Introduction to Search Engine Technology CS , Technion, Winter 2011/12
|
|
|
- Kelley Fowler
- 6 years ago
- Views:
Transcription
 research")
1 Introduction to Search Engine Technology CS , Technion, Winter 2011/12 Ronny Lempel Yahoo! Labs, Haifa What this Course is All About Will try to sample the science that drives Web search engines, highlighting several areas of ongoing world-wide (academic and industrial) research Algorithms, data structures, system issues and theoretical problems Just the tip of the iceberg won t be able to discuss everything This is an introductory lecture - many of the areas will be further elaborated upon during the course 22 October 2011 CS Search Engine Technology 2 1
 Grading: (20 points, after week 2) Problem sheet (25 points, after week 6) Problem sheet + programming assignment tweaking the Lucene")
2 Administration Web page: Reception hour: by prior appointment, before class Teaching Assistant: Naama Kraus (tutorial on Thursday, 9:30) Grading: (20 points, after week 2) Problem sheet (25 points, after week 6) Problem sheet + programming assignment tweaking the Lucene open-source search library (20 points, after week 10) Problem sheet (35 points, after semester) Final assigment Some HW assignments will be in pairs, some will be individual 22 October 2011 CS Search Engine Technology 3 Mission Impossible? Search engines: Crawl and index tens of billions of documents Answer hundreds of millions of queries per day Devote less than 1 second of processing time per query execution Users: Submit very short queries (averaging about 2.6 terms) Expect to receive the most relevant results on the Web In a blink of an eye In terms of 1990 IR research - almost unimaginable! 22 October 2011 CS Search Engine Technology 4 2
3 The Static Web Corpus Bulk 10s of billions of static pages; doubling every 8-24 months Lack of stability Estimates vary widely (half life of page is several months) Lexicon Size 10s-100s of millions of words Heterogeneity Type of documents.. Text, pictures, audio, video, scripts, Quality From junk to the best content on earth Languages 100+ Duplication Syntactic 30%-40% (near) duplicates Semantic?? Complex graph topology 8 links/page in the average; bow-tie structure Spam 100s of millions of pages 22 October 2011 CS Search Engine Technology 5 Web Searchers - Observations Make ill defined queries Short (2.54 terms average, 80% contain less than 3 words) Use imprecise (and often misspelled) terms Unfamiliar with query syntax (80% queries without operator) Wide variance in information needs, expectations, education/knowledge, IP bandwidth, human patience Different modalities (mobile, desktop) = different needs, even with same person Specific behavior 85% look over one result screen only (mostly above the fold ) 78% of queries are not modified Overall, we as users are investing low cognitive effort per query (formulating and looking at results) 22 October 2011 CS Search Engine Technology 6 3
4 Evolution of Search Engines Pre-search: human edited directories High quality, authoritative, reliable But inherently non-scalable and doesn t cater to niches First generation use only on page, text data 1994, the Yahoo! directory Information Retrieval techniques such as TF/IDF, Vector Space model adapted to HTML Scalable, automatic AV, Excite, Lycos, etc But ranking is poor and easy to spam 22 October 2011 CS Search Engine Technology 7 Evolution of Search Engines (2) Second generation - use off-page, web-specific data Link analysis Anchor-text (how authors refer to a page when linking to it) Click-through data (what results people click on) From Made popular by Google and used by everyone now Ranking is much improved, especially for navigational queries But popularity rules and results are very homogenous Spam evolving into a cat-and-mouse game 22 October 2011 CS Search Engine Technology 8 4
5 Evolution of Search Engines (3) Third generation answer the need behind the query, focusing on the need rather than on the keywords Simple context determination Spatial (user location, target location) Query stream (previous queries) Shortcuts via regular expressions Integrate multiple sources of data Maps, videos, images, news First half of decade: Google, Yahoo!, Ask Search assistance tools that help users create good queries and streamline search efforts Spell correction, expand/narrow suggestions, facets From 2006 and on: some of this happens as you type, before the query is actually evaluated (AJAX) 22 October 2011 CS Search Engine Technology 9 Evolution of Search Engines (3.5) More recent efforts (2005 to date): Integration of search and text analysis, e.g. understanding concepts in documents and matching those to queries Named entities, directives/modifiers ( download, reviews etc.) Social search making use of UGC (user-generated content), social networks, etc. Optimizing the experience delivered by the search result page as a whole rather than as a collection of 10 independent links Page real-estate is scarce, need to make every pixel count Emphasis on diversity of results More elaborate personalization Apps 22 October 2011 CS Search Engine Technology 10 5
, 2001 22 October 2011 CS236621 Search Engine Technology 11 Weeks 1-2: Introduction to")
6 Anatomy of a Search Engine Image taken from Searching the Web, Arasu et al., TOIT 1(1), October 2011 CS Search Engine Technology 11 Weeks 1-2: Introduction to Information Retrieval 6
7 Classic Information Retrieval Given a query, the system retrieves a set B of documents Every retrieved document is either relevant or irrelevant to the query Quality metrics: Recall : (A B) / A Precision : (A B) / B 22 October 2011 CS Search Engine Technology 13 Recall and Precision on the Web Relevance of document to queries is not binary there are many shades of gray Broad-topic queries: abundance problem Precision is the dominating factor: users mostly satisfied with a few good results (a few authoritative pages) Narrow-topic queries: Find a needle in an enormous haystack Recall demands engines cover significant portions of the Web Common measure: precision@10 Nowadays larger emphasis on diversity 22 October 2011 CS Search Engine Technology 14 7
8 The Boolean Model Simple model based on set theory Queries are specified as Boolean expressions. indexing units are words Boolean Operator: OR, AND, NOT Example: q = java AND compilers AND ( unix OR linux ) Relevance: A document is considered relevant to the query if it satisfies the query Boolean expression. Pros: Fast (bitmap vector operations) Binary decision (doc is relevant or not) Cons: Binary decision - What about ranking? Who speaks Boolean? 22 October 2011 CS Search Engine Technology 15 Vector Space Model Documents and queries are both represented as vectors in a highdimensional vector space in which each word is a dimension Relevance is measured by similarity, i.e. by the cosine of the angle between doc-vectors and the query-vector j d 2 d 1 q d Sim( q, d) = = q d i i w w iq 2 iq w i id w 2 id α 1 q i 22 October 2011 CS Search Engine Technology 16 8
9 Probabilistic Retrieval Models Attempt to predict the probability that a given document is relevant to a given query: Pr(R d,q) Rank retrieved documents according to this probability of relevance Probability Ranking Principle: if a retrieval system s response to each request is a ranking of the documents in decreasing probability of usefulness to the user then the overall effectiveness of the system to its users will be the best - Stephen E. Robertson, J. Documentation 1977 Rely on accurate estimates of probabilities 22 October 2011 CS Search Engine Technology 17 Classic and Modern IR Issues Polysemy (ambiguity): does Jordan refer to Michael Jordan, the Jordan River, or the Hashemite Kingdom of Jordan? Can we ensure that our SERP * will represent all aspects? Synonymy: elevator/lift, movie/film Do the models hold when queries are very short? Short queries require the addition of proximity considerations (query term hits should be in proximity to each other) how does this fit with the models? Information Retrieval merits a course of its own! * SERP Search Results Page 22 October 2011 CS Search Engine Technology 18 9
10 Weeks 3-6: The Inverted Index The Inverted Index Data Structure An Inverted Index consists of 2 elements: The lexicon (AKA vocabulary, dictionary) The inverted file (AKA postings file) The Lexicon is the set of all indexing units (terms) in a given collection The Inverted file is a set of postings lists a list per term. The list consists of posting elements. The list of term t holds the locations (documents + offsets therein) where t appeared. Additional data (payload) is often encoded per location Many variations and degrees of freedom Supports efficient lookup from word to occurrences Essentially a way of representing and accessing (by row) a huge and very sparse matrix 22 October 2011 CS Search Engine Technology 20 10
11 Inverted Index Example The good 1 2 the bad 3 4 and the ugly Doc #1 As good as it gets, and more Term Doc #2 Doc #3 Lexicon DF The 1 Good 2 Bad 2 And 3 Ugly 2 As 1 It 2 Gets 1 More 2 Is 1 (1; 1,3,6) (1; 2) (2; 2) (1; 4) (3; 5) (1; 5) (2; 6) (3; 4,8) (1; 7) (3; 3) (2; 1,3) (2; 4) (3; 2,6) (2; 5) (2, 7) (3, 9) (3; 1,7) Is it ugly and bad? It is, and more! Basic questions: How to efficiently build an inverted index? How does the inverted index efficiently support the various retrieval models (Boolean, Vector Space, etc.)? How does the inverted index handle complex operators, e.g. phrase queries? 22 October 2011 CS Search Engine Technology 21 Course Will Cover Index representation, and algorithms for batch index build + lexicon representation Evaluation schemes (term/document at a time), early termination and pruning schemes Index compression and pruning Efficient identification of near-duplicate pages Large-scale search engines have huge indices, which are distributed across thousands of machines. How can an index be distributed, and what are the implications on query processing? 22 October 2011 CS Search Engine Technology 22 11
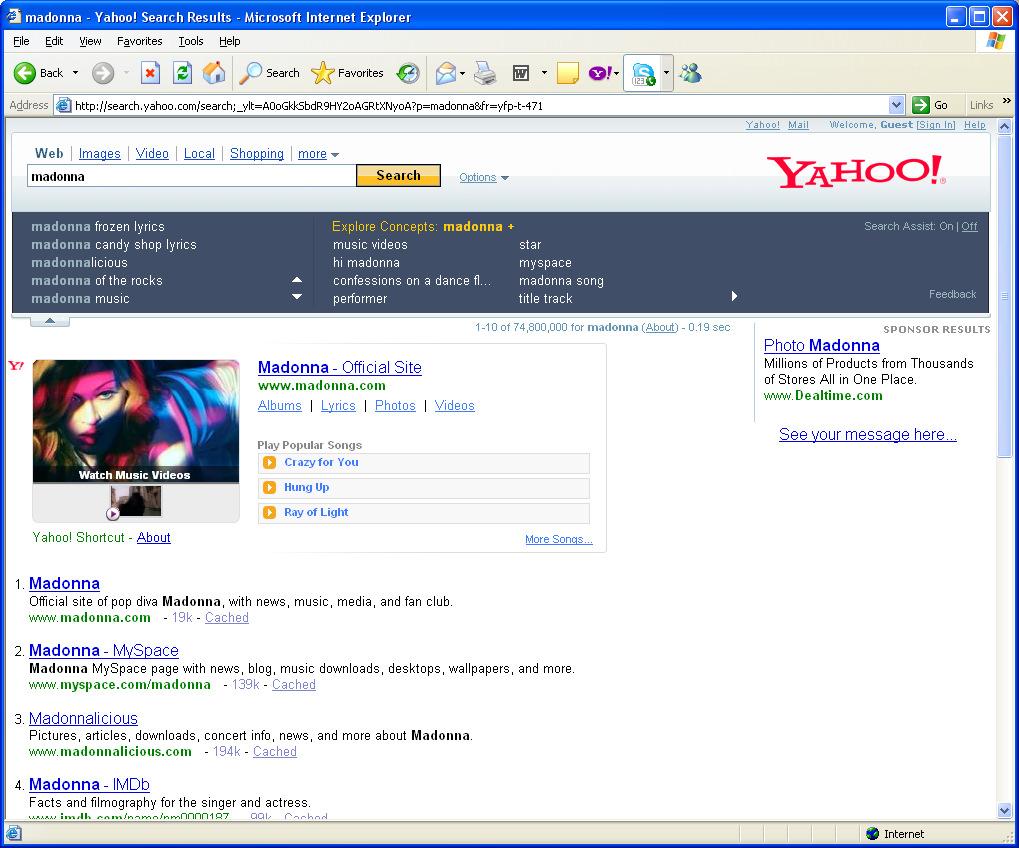
12 Weeks 7-8: Link Structure Analysis The Information Need Behind the Query [Broder, SIGIR Forum 36(2), 2002] Informational I want to learn more about the roman empire Many possible fine results Navigational Find me the home page of el al In principle, a single correct result In practice, correct result may depend on language/locale Transactional I want to buy a digital camera Good results: e-tailors that sell digital cameras 22 October 2011 CS Search Engine Technology 24 12


13 Navigational Queries & Anchor Text Anchor text the highlighted clickable text of a link Physically in page A, but actually describes the content of page B Many times, concisely defines page B Often, better than the text present on page B itself Anchor text is the most important factor in treating navigational queries Case study: the query engine on Microsoft s Live Search Famous pop-culture examples: French Military Victories, miserable failure 22 October 2011 CS Search Engine Technology 25 Case study: the query engine on Microsoft s Live Search The word engine does not appear Anywhere on the page, nor in its source 22 October 2011 CS Search Engine Technology 26 13

14 Link-Structure Analysis Beyond anchor-text: the connectivity patterns between Web pages contain a gold mine of information A link from page a to page b can often be interpreted as: 1. A recommendation, by a s author, of the contents of b. 2. Evidence that pages a,b share some topic of interest. A co-citation of a and b (by a third page c) may also constitute evidence that a,b share some topic of interest a c b 22 October 2011 CS Search Engine Technology 27 Hubs and Authorities Notions proposed by Jon Kleinberg (1998) Two types of quality Web pages that pertain to a given topic hubs: resource lists, containing links to many authorities hubs authorities Authorities: pages containing authoritative content on the topic HITS (Hypertext Induced Topic Search): an algorithm that identifies hubs and authorities, given a topic of interest t Based on the Perron-Frobenius theory of non-negative matrices 22 October 2011 CS Search Engine Technology 28 14


15 Example an Authority for the Query movies 22 October 2011 CS Search Engine Technology 29 Example a Hub for the Query movies 22 October 2011 CS Search Engine Technology 30 15
16 PageRank (Brin & Page, 1998) Named after Google s co-founder, Larry Page A global, query independent importance measure of Web pages A page is considered important if it receives many links from important pages Based on Markov chains and random walks 22 October 2011 CS Search Engine Technology 31 PageRank: Random Surfer Model A random surfer moves from page to page. Upon leaving page p, the surfer chooses one of two actions: 1. Follows an outgoing link of p (chosen uniformly at random), w.p. d 2. Jumps to an arbitrary Web page (chosen uniformly at random), w.p. 1-d The vector of PageRanks is the stationary distribution of this (ergodic) random walk 22 October 2011 CS Search Engine Technology 32 16
17 Link Analysis Algorithms Many variants and refinements of both HITS and PageRank have been proposed Course will cover SALSA & Topic-Sensitive PageRank Other approaches include: Max-flow techniques [Flake et al., SIGKDD 2000] Machine learning and Bayesian techniques Examples of applications: Ranking pages (topic specific/global importance) Categorization, clustering, finding related pages Identifying virtual communities A wealth of literature 22 October 2011 CS Search Engine Technology 33 Stability of Link Analysis IR algorithms should be robust small changes in the input should not dramatically alter the results The Web changes constantly: pages and links are created, deleted and modified? Do the known link-based algorithms produce stable scores/rankings?? Does stability of scores imply stability of rankings? Different research approaches have been applied to these questions, some problems are still unsolved 22 October 2011 CS Search Engine Technology 34 17
18 Size & Dynamics of the Web Billions of pages, tens of millions of sites Hundreds of terabytes (10 14 ) of data Projected growth rate: doubling in size every two years (some estimate rate is much quicker) New pages are added; existing pages are modified and deleted Unstructured information in chaotic disorder Many media types Widely distributed, both geographically and organizationally 22 October 2011 CS Search Engine Technology 35 The Web as a Graph Pages as graph nodes, hyperlinks as edges Sometimes sites are taken as the nodes Some natural questions: 1. Distribution of the number of in-links to a page 2. Distribution of the number of out-links from a page 3. Distribution of the number of pages in a site 4. Connectivity: is it possible to reach most pages from most pages? 5. Are there models that explain how the Web graph evolved to its current shape? 22 October 2011 CS Search Engine Technology 36 18
19 Weeks 9-10: Crawlers and Caches Crawlers - Framework The World Wide Web can be viewed as a directed graph Nodes are web objects, such as html pages, image files, pdf files, forms, etc... Nodes are uniquely identified by URLs Edges are html hyperlinks, pointing from an html page to its embedded objects or to other web objects Edges are uniquely identified by their source and target nodes 22 October 2011 CS Search Engine Technology 38 19
20 Generic Web Crawling Algorithm Given a root set of distinct URLs: Put the root URLs in a queue While queue is not empty: Take the first URL x out of the queue Retrieve the contents of x from the web Do whatever you want with it Mark x as visited If x is an html page, parse it to find hyperlink URLs For each hyperlink URL y within x: If y is not marked visited, put y into queue This is often the computational bottleneck 22 October 2011 CS Search Engine Technology 39 Crawler Design Issues Writing a simple crawler is a fairly easy task one can be written in Java in a few lines of code However, there are many issues that need to be considered when writing a robust Web-scale crawler: Redirections Encrypted and password protected data Politeness - avoiding server load and respecting Robot Exclusion Protocol Script handling Language and encoding issues The challenge of dynamic pages Duplicate pages Crawl prioritization and variable revisit rates to ensure freshness Focused crawling Concurrency and distribution issues And many many more 22 October 2011 CS Search Engine Technology 40 20
21 Query Result Caching Exploits locality of reference in the query streams that are submitted to search engines: Query popularities vary widely, from the extremely popular to the very rare Although a minority, significant number of users still view multiple result pages per query (motivates prefetching) Successful caching and prefetching of results can: Lower the number/cost of query executions Shorten the engine s response time and lower its hardware requirements 22 October 2011 CS Search Engine Technology 41 Query Log Analysis Analysis of queries submitted to AltaVista during September 2001: The queries requested distinct result pages, belonging to distinct query strings 67% of the strings were only requested once; the most popular string was queried times 48% of the result pages were only requested once; the 50 most requested pages account for almost 2% of all requests Qualitative behavior consistent with analyses of query logs of other engines 22 October 2011 CS Search Engine Technology 42 21
22 Result Caching and Prefetching Simple LRU-based caches of query results can achieve cache hit-rates of about 30% (Markatos, 2000) Prefetching deeper result pages, along with more complex caching policies, can achieve hit rates of over 50% What is the cost associated with prefetching additional results? What happens when the index changes? BTW, what about caching of other data in search engines, e.g. postings lists? 22 October 2011 CS Search Engine Technology 43 Weeks 11-14: Users, Advertising and Long-Tail Economics 22

23 Search Assistance Help users complete their online tasks quickly and easily Examples on next slides, from the top 4 search engines, show: Task-oriented mashups Query completion tools Suggestions of related concepts and queries Federation of multiple sources of information Challenges: Which experience to trigger for which query/user? Which data items to trigger given an experience? Lots(!!!) of data mining including usage mining - behind the scenes The bigger picture: which (layout), what (content), where (on the page) and how (to render) 22 October 2011 CS Search Engine Technology October 2011 CS Search Engine Technology 46 23

24 22 October 2011 CS Search Engine Technology October 2011 CS Search Engine Technology 48 24
 Online advertising budgets still lagging in proportion to time spent online, which is growing fast at the expense of old media Seen as a driver to continued growth of")
25 22 October 2011 CS Search Engine Technology 49 The Advertising Market Internet advertising is a $10 10 business that is growing faster than old media advertising (radio, TV, newspapers & magazines, mail, outdoors) Online advertising budgets still lagging in proportion to time spent online, which is growing fast at the expense of old media Seen as a driver to continued growth of online advertising market Traditional advertising: Few, expensive opportunities Targeting en-masse, by immediate context only Difficult to measure effectiveness Internet advertising: Billions of opportunities daily Open to personalization via rich context of impression Effectiveness is measurable: can measure click-through rates as % of impressions, and conversions as % of clicks 22 October 2011 CS Search Engine Technology 50 25


26 Internet Advertising Types: Sponsored Search textual ads served on search results pages, triggered by query terms on which advertisers bid 22 October 2011 CS Search Engine Technology 51 Internet Advertising Types: Contextual Ads (a.k.a. Content Match) textual ads served on third party ( publisher ) pages, triggered by content of page on which advertisers bid 22 October 2011 CS Search Engine Technology 52 26

27 Internet Advertising Types: Display Ads Graphical elements (e.g. banners) of standard sizes, served on publisher pages, mainly targeting audience demographics Guaranteed delivery (GD): advertiser buys a display campaign months in advance, requesting ## impressions to certain demographics in a given time period; ad agency pays fine for under-delivery Non-guaranteed delivery (NGD): advertiser bids in real time for impressions, with no guarantees that ads will be shown 22 October 2011 CS Search Engine Technology 53 Internet Advertising Models 1. Cost per Impression (sometimes called Cost per Mille, i.e impressions) advertiser pays for ad to be shown Main model for display advertising 2. Cost per Click advertiser only pays when ad is clicked by user Main model for sponsored search and content match Sponsored search, 2005: 50% of clicks < $0.25, 80% < $ Cost per Action advertiser only pays when the user s interaction with the ad is followed by some transaction (not necessarily purchase) 22 October 2011 CS Search Engine Technology 54 27
28 Computational Advertising Challenges Conflicting goals: Advertiser: campaign effectiveness maximize ROI Publisher: revenue without jeopardizing image of site User: relevant ads, or at least ads that do not harm the experience Ad agency (search engine): own revenue, while balancing goals of other parties; sometimes ad agency is also the publisher Ad agency challenges: Which ads to trigger per query/page/impression? How to order them? What to charge for them? In general, how to set the rules of the marketplace so as to ensure goals of parties are met (Game Theory/Mechanism Design)? Which guaranteed delivery contracts to accept? How to balance GD with NGD? Helping advertisers choose bid phrases effectively Combating spam and fraud Scale!! 22 October 2011 CS Search Engine Technology 55 The Long Tail How the infinite choice available in e-commerce and the ease of publishing online have redefined the business of media & entertainment Mottos: The biggest money is in the smallest sales Embrace niches 22 October 2011 CS Search Engine Technology 56 28

29 Long Tail Economics and Recommender Systems People cannot intelligently navigate product or media catalogs consisting of millions of items e-inventories of books, songs, movies, albums are practically infinite In particular, niche audiences cannot find niche content Recommender systems, collaborative filtering and social tagging services are key to Long Tail economics Find an item you like, and we ll point you to similar items Pioneered by Amazon; today, used everywhere 22 October 2011 CS Search Engine Technology 57 29
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information retrieval
 Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
SEARCH ENGINE INSIDE OUT
 SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
Link Structure Analysis
 Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
A Survey on Web Information Retrieval Technologies
 A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
CS 345A Data Mining Lecture 1. Introduction to Web Mining
 CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
5 Choosing keywords Initially choosing keywords Frequent and rare keywords Evaluating the competition rates of search
 Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Information Retrieval. Lecture 9 - Web search basics
 Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM
 CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Jargon Buster. Ad Network. Analytics or Web Analytics Tools. Avatar. App (Application) Blog. Banner Ad
 Blog. Banner Ad") D I G I TA L M A R K E T I N G Jargon Buster Ad Network A platform connecting advertisers with publishers who want to host their ads. The advertiser pays the network every time an agreed event takes place,
D I G I TA L M A R K E T I N G Jargon Buster Ad Network A platform connecting advertisers with publishers who want to host their ads. The advertiser pays the network every time an agreed event takes place,
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December ISSN Web Search Engine
 International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
6 WAYS Google s First Page
 6 WAYS TO Google s First Page FREE EBOOK 2 CONTENTS 03 Intro 06 Search Engine Optimization 08 Search Engine Marketing 10 Start a Business Blog 12 Get Listed on Google Maps 15 Create Online Directory Listing
6 WAYS TO Google s First Page FREE EBOOK 2 CONTENTS 03 Intro 06 Search Engine Optimization 08 Search Engine Marketing 10 Start a Business Blog 12 Get Listed on Google Maps 15 Create Online Directory Listing
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Ranking of ads. Sponsored Search
 Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Web Search Ranking. (COSC 488) Nazli Goharian Evaluation of Web Search Engines: High Precision Search
 Nazli Goharian Evaluation of Web Search Engines: High Precision Search") Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Review: Searching the Web [Arasu 2001]
![Review: Searching the Web [Arasu 2001]](/thumbs/81/82666657.jpg "Review: Searching the Web [Arasu 2001]") Review: Searching the Web [Arasu 2001] Gareth Cronin University of Auckland gareth@cronin.co.nz The authors of Searching the Web present an overview of the state of current technologies employed in the
Review: Searching the Web [Arasu 2001] Gareth Cronin University of Auckland gareth@cronin.co.nz The authors of Searching the Web present an overview of the state of current technologies employed in the
Web Search Basics. Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University
 Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
NBA 600: Day 15 Online Search 116 March Daniel Huttenlocher
 NBA 600: Day 15 Online Search 116 March 2004 Daniel Huttenlocher Today s Class Finish up network effects topic from last week Searching, browsing, navigating Reading Beyond Google No longer available on
NBA 600: Day 15 Online Search 116 March 2004 Daniel Huttenlocher Today s Class Finish up network effects topic from last week Searching, browsing, navigating Reading Beyond Google No longer available on
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
SEO. Definitions/Acronyms. Definitions/Acronyms
 Definitions/Acronyms SEO Search Engine Optimization ITS Web Services September 6, 2007 SEO: Search Engine Optimization SEF: Search Engine Friendly SERP: Search Engine Results Page PR (Page Rank): Google
Definitions/Acronyms SEO Search Engine Optimization ITS Web Services September 6, 2007 SEO: Search Engine Optimization SEF: Search Engine Friendly SERP: Search Engine Results Page PR (Page Rank): Google
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
5. search engine marketing
 5. search engine marketing What s inside: A look at the industry known as search and the different types of search results: organic results and paid results. We lay the foundation with key terms and concepts
5. search engine marketing What s inside: A look at the industry known as search and the different types of search results: organic results and paid results. We lay the foundation with key terms and concepts
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
World Wide Web has specific challenges and opportunities
 6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
An Oracle White Paper October Oracle Social Cloud Platform Text Analytics
 An Oracle White Paper October 2012 Oracle Social Cloud Platform Text Analytics Executive Overview Oracle s social cloud text analytics platform is able to process unstructured text-based conversations
An Oracle White Paper October 2012 Oracle Social Cloud Platform Text Analytics Executive Overview Oracle s social cloud text analytics platform is able to process unstructured text-based conversations
CS Search Engine Technology
 CS236620 - Search Engine Technology Ronny Lempel Winter 2008/9 The course consists of 14 2-hour meetings, divided into 4 main parts. It aims to cover both engineering and theoretical aspects of search
CS236620 - Search Engine Technology Ronny Lempel Winter 2008/9 The course consists of 14 2-hour meetings, divided into 4 main parts. It aims to cover both engineering and theoretical aspects of search
Web Crawling. Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India
 Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
seosummit seosummit April 24-26, 2017 Copyright 2017 Rebecca Gill & ithemes
 April 24-26, 2017 CLASSROOM EXERCISE #1 DEFINE YOUR SEO GOALS Template: SEO Goals.doc WHAT DOES SEARCH ENGINE OPTIMIZATION REALLY MEAN? Search engine optimization is often about making SMALL MODIFICATIONS
April 24-26, 2017 CLASSROOM EXERCISE #1 DEFINE YOUR SEO GOALS Template: SEO Goals.doc WHAT DOES SEARCH ENGINE OPTIMIZATION REALLY MEAN? Search engine optimization is often about making SMALL MODIFICATIONS
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
Informa/on Retrieval. Text Search. CISC437/637, Lecture #23 Ben CartereAe. Consider a database consis/ng of long textual informa/on fields
 Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Overture Advertiser Workbook. Chapter 4: Tracking Your Results
 Overture Advertiser Workbook Chapter 4: Tracking Your Results Tracking Your Results TRACKING YOUR RESULTS Tracking the performance of your keywords enables you to effectively analyze your results, adjust
Overture Advertiser Workbook Chapter 4: Tracking Your Results Tracking Your Results TRACKING YOUR RESULTS Tracking the performance of your keywords enables you to effectively analyze your results, adjust
Detecting Spam Web Pages
 Detecting Spam Web Pages Marc Najork Microsoft Research Silicon Valley About me 1989-1993: UIUC (home of NCSA Mosaic) 1993-2001: Digital Equipment/Compaq Started working on web search in 1997 Mercator
Detecting Spam Web Pages Marc Najork Microsoft Research Silicon Valley About me 1989-1993: UIUC (home of NCSA Mosaic) 1993-2001: Digital Equipment/Compaq Started working on web search in 1997 Mercator
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
SEO and Monetizing The Content. Digital 2011 March 30 th Thinking on a different level
 SEO and Monetizing The Content Digital 2011 March 30 th 2011 Getting Found and Making the Most of It 1. Researching target Audience (Keywords) 2. On-Page Optimisation (Content) 3. Titles and Meta Tags
SEO and Monetizing The Content Digital 2011 March 30 th 2011 Getting Found and Making the Most of It 1. Researching target Audience (Keywords) 2. On-Page Optimisation (Content) 3. Titles and Meta Tags
An Overview of Search Engine. Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia
 An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
Advertising Network Affiliate Marketing Algorithm Analytics Auto responder autoresponder Backlinks Blog
 Advertising Network A group of websites where one advertiser controls all or a portion of the ads for all sites. A common example is the Google Search Network, which includes AOL, Amazon,Ask.com (formerly
Advertising Network A group of websites where one advertiser controls all or a portion of the ads for all sites. A common example is the Google Search Network, which includes AOL, Amazon,Ask.com (formerly
Module 1: Internet Basics for Web Development (II)
") INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
An Introduction to Search Engines and Web Navigation
 An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
Empowering People with Knowledge the Next Frontier for Web Search. Wei-Ying Ma Assistant Managing Director Microsoft Research Asia
 Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
THE QUICK AND EASY GUIDE
 THE QUICK AND EASY GUIDE TO BOOSTING YOUR ORGANIC SEO A FEROCIOUS DIGITAL MARKETING AGENCY About Designzillas IS YOUR BUSINESS FEROCIOUS? Our Digital Marketing Agency specializes in custom website design
THE QUICK AND EASY GUIDE TO BOOSTING YOUR ORGANIC SEO A FEROCIOUS DIGITAL MARKETING AGENCY About Designzillas IS YOUR BUSINESS FEROCIOUS? Our Digital Marketing Agency specializes in custom website design
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
The Web: Concepts and Technology. January 15: Course Overview
 The Web: Concepts and Technology January 15: Course Overview 1 Today s Plan Who am I? What is this course about? Logistics Who are you? 2 Meet Your Instructor Instructor: Eugene Agichtein Web: http://www.mathcs.emory.edu/~eugene
The Web: Concepts and Technology January 15: Course Overview 1 Today s Plan Who am I? What is this course about? Logistics Who are you? 2 Meet Your Instructor Instructor: Eugene Agichtein Web: http://www.mathcs.emory.edu/~eugene
SME Developing and managing your online presence. Presented by: Rasheed Girvan Global Directories
 SME Developing and managing your online presence Presented by: Rasheed Girvan Global Directories DIGITAL MEDIA What is Digital Media Any media type in an electronic or digital format for the convenience
SME Developing and managing your online presence Presented by: Rasheed Girvan Global Directories DIGITAL MEDIA What is Digital Media Any media type in an electronic or digital format for the convenience
Information Retrieval
 Introduction to Information Retrieval Information Retrieval and Web Search Lecture 1: Introduction and Boolean retrieval Outline ❶ Course details ❷ Information retrieval ❸ Boolean retrieval 2 Course details
Introduction to Information Retrieval Information Retrieval and Web Search Lecture 1: Introduction and Boolean retrieval Outline ❶ Course details ❷ Information retrieval ❸ Boolean retrieval 2 Course details
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 12: Link Analysis January 28 th, 2016 Wolf-Tilo Balke and Younes Ghammad Institut für Informationssysteme Technische Universität Braunschweig An Overview
Information Retrieval and Web Search Engines Lecture 12: Link Analysis January 28 th, 2016 Wolf-Tilo Balke and Younes Ghammad Institut für Informationssysteme Technische Universität Braunschweig An Overview
THE HISTORY & EVOLUTION OF SEARCH
 THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
WebReach Product Glossary
 WebReach Product Glossary September 2009 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A Active Month Any month in which an account is being actively managed by hibu. Statuses that qualify as active
WebReach Product Glossary September 2009 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A Active Month Any month in which an account is being actively managed by hibu. Statuses that qualify as active
google SEO UpdatE the RiSE Of NOt provided and hummingbird october 2013
 google SEO Update The Rise of Not Provided and Hummingbird October 2013 Lead contributors David Freeman Head of SEO Havas Media UK david.freeman@havasmedia.com Winston Burton VP, Director of SEO Havas
google SEO Update The Rise of Not Provided and Hummingbird October 2013 Lead contributors David Freeman Head of SEO Havas Media UK david.freeman@havasmedia.com Winston Burton VP, Director of SEO Havas
Lecture 5: Information Retrieval using the Vector Space Model
 Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
INTRODUCTION. Chapter GENERAL
 Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
AN OVERVIEW OF SEARCHING AND DISCOVERING WEB BASED INFORMATION RESOURCES
 Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
What Is Voice SEO and Why Should My Site Be Optimized For Voice Search?
 What Is Voice SEO and Why Should My Site Be Optimized For Voice Search? Voice search is a speech recognition technology that allows users to search by saying terms aloud rather than typing them into a
What Is Voice SEO and Why Should My Site Be Optimized For Voice Search? Voice search is a speech recognition technology that allows users to search by saying terms aloud rather than typing them into a
DATA MINING II - 1DL460. Spring 2017
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
SEO WITH SHOPIFY: DOES SHOPIFY HAVE GOOD SEO?
 TABLE OF CONTENTS INTRODUCTION CHAPTER 1: WHAT IS SEO? CHAPTER 2: SEO WITH SHOPIFY: DOES SHOPIFY HAVE GOOD SEO? CHAPTER 3: PRACTICAL USES OF SHOPIFY SEO CHAPTER 4: SEO PLUGINS FOR SHOPIFY CONCLUSION INTRODUCTION
TABLE OF CONTENTS INTRODUCTION CHAPTER 1: WHAT IS SEO? CHAPTER 2: SEO WITH SHOPIFY: DOES SHOPIFY HAVE GOOD SEO? CHAPTER 3: PRACTICAL USES OF SHOPIFY SEO CHAPTER 4: SEO PLUGINS FOR SHOPIFY CONCLUSION INTRODUCTION
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
60-538: Information Retrieval
 60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
60-538: Information Retrieval September 7, 2017 1 / 48 Outline 1 what is IR 2 3 2 / 48 Outline 1 what is IR 2 3 3 / 48 IR not long time ago 4 / 48 5 / 48 now IR is mostly about search engines there are
New Technology Briefing
 New Technology Briefing Kate Burns is Google s managing director of advertising sales UK, responsible for the growth of the company s UK market businesses and expansion. Kate was Google s first international
New Technology Briefing Kate Burns is Google s managing director of advertising sales UK, responsible for the growth of the company s UK market businesses and expansion. Kate was Google s first international
Search Engine Optimization. MBA 563 Week 6
 Search Engine Optimization MBA 563 Week 6 SEARCH ENGINE OPTIMIZATION (SEO) Search engine marketing 2 major methods TWO MAJOR METHODS - OBJECTIVE IS TO BE IN THE TOP FEW SEARCH RESULTS 1. Search engine
Search Engine Optimization MBA 563 Week 6 SEARCH ENGINE OPTIMIZATION (SEO) Search engine marketing 2 major methods TWO MAJOR METHODS - OBJECTIVE IS TO BE IN THE TOP FEW SEARCH RESULTS 1. Search engine
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Information Retrieval II
 Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Web Search Basics. Berlin Chen Department t of Computer Science & Information Engineering National Taiwan Normal University
 Web Search Basics Berlin Chen Department t of Computer Science & Information Engineering i National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze,
Web Search Basics Berlin Chen Department t of Computer Science & Information Engineering i National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze,
Plan for today. CS276B Text Retrieval and Mining Winter Evolution of search engines. Connectivity analysis
 CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines