Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
|
|
|
- Iris Griffith
- 5 years ago
- Views:
Transcription
1 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, , blog, e-book,... Query: paradigm bag of words Relevant?!? 1
2 Two main difficulties The Web: Extracting significant data is difficult!! Size: more than tens of billions of pages Language and encodings: hundreds Distributed authorship: SPAM, format-less, Dynamic: in one year 35% survive, 20% untouched The User: Matching user needs is difficult!! Query composition: short (2.5 terms avg) and imprecise Query results: 85% users look at just one result-page Several needs: Informational, Navigational, Transactional Evolution of Search Engines First generation -- use only on-page, web-text data Word frequency and language AltaVista, Excite, Lycos, etc Second generation -- use off-page, web-graph data Link (or connectivity) analysis Anchor-text (How people refer to a page) 1998: Google Third generation -- answer the need behind the query Focus on user need, rather than on query Integrate multiple data-sources Click-through data Google, Yahoo, MSN, ASK, Fourth generation Information Supply [Andrei Broder, VP emerging search tech, Yahoo! Research] 2
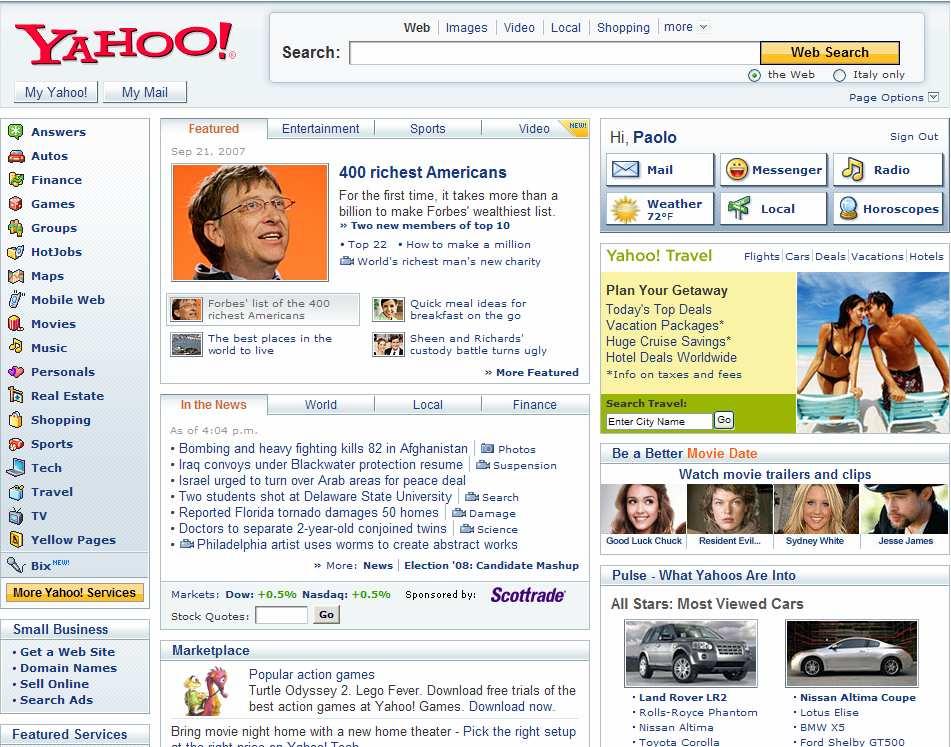
3 3
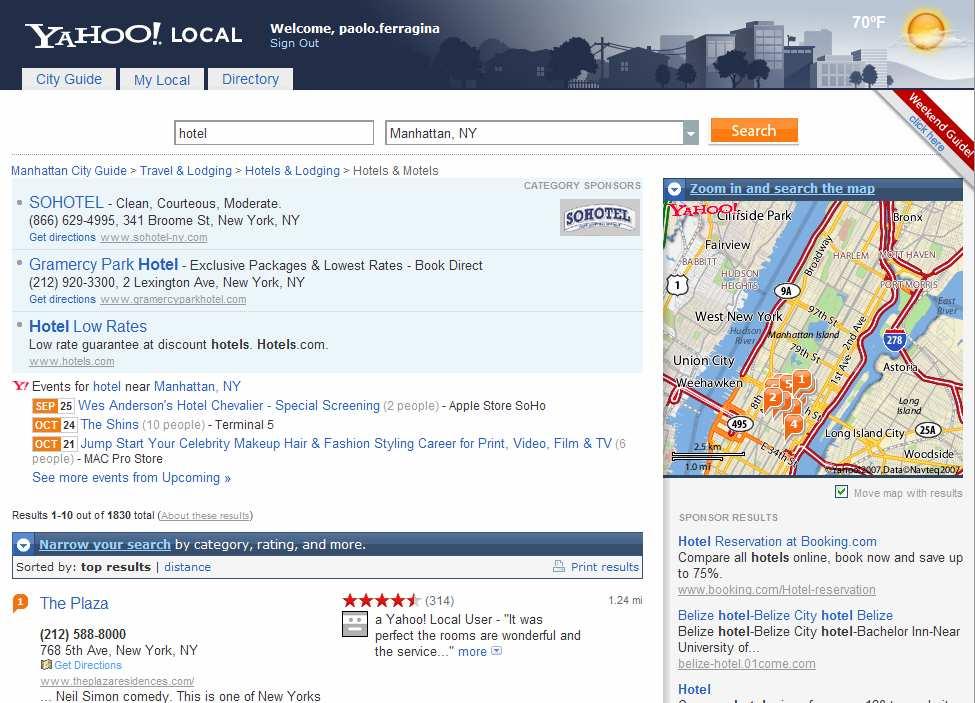
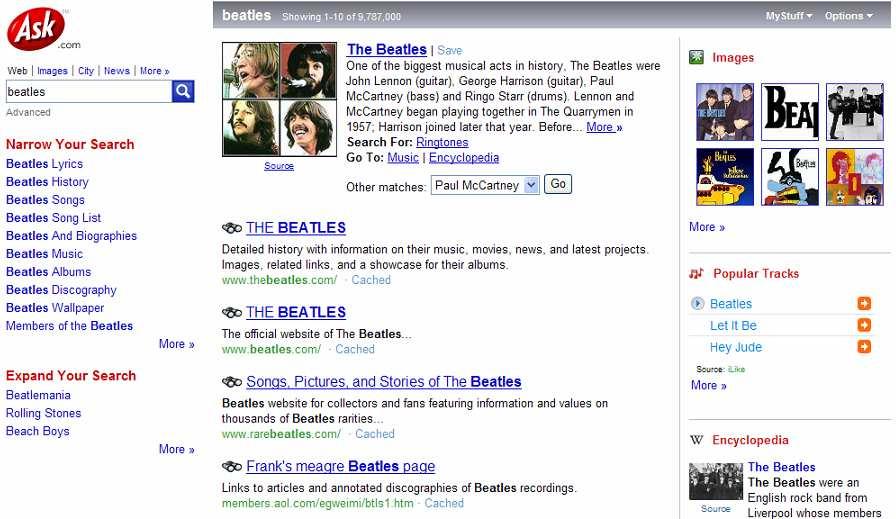
4 4

5 This is a search engine!!! Algoritmi per IR The structure of a Search Engine 5

6 The structure? Page archive Crawler Query Page Analizer Indexer Query resolver Ranker Control text auxiliary Structure 6
7 Information Retrieval Crawling Spidering 24h, 7days walking over a Graph What about the Graph? BowTie Direct graph G = (N, E) N changes (insert, delete) >> 50 * 10 9 nodes E changes (insert, delete) > 10 links per node 10*50*10 9 = 500* entries in adj matrix 7
8 Crawling Issues How to crawl? Quality: Best pages first Efficiency: Avoid duplication (or near duplication) Etiquette: Robots.txt, Server load concerns (Minimize load) How much to crawl? How much to index? Coverage: How big is the Web? How much do we cover? Relative Coverage: How much do competitors have? How often to crawl? Freshness: How much has changed? How to parallelize the process Crawler cycle of life PQ Link Extractor Crawler Manager PR AR Downloaders Link Extractor: while(<page Repository is not empty>){ <take a page p (check if it is new)> <extract links contained in p within href> <extract links contained in javascript> <extract.. <insert these links into the Priority Queue> } Downloaders: while(<assigned Repository is not empty>){ <extract url u> <download page(u)> <send page(u) to the Page Repository> <store page(u) in a proper archive, possibly compressed> } Crawler Manager: while(<priority Queue is not empty>){ <extract some URL u having the highest priority> foreach u extracted { if ( (u Already Seen Page ) ( u Already Seen Page && <u s version on the Web is more recent> ) ) { <resolve u wrt DNS> <send u to the Assigned Repository> } } } 8
9 Page selection Given a page P, define how good P is. Several metrics: BFS, DFS, Random Popularity driven (PageRank, full vs partial) Topic driven or focused crawling Combined BFS BFS-order discovers the highest quality pages during the early stages of the crawl 328 millions of URL in the testbed [Najork 01] 9
10 This page is a new one? Check if file has been parsed or downloaded before after 20 mil pages, we have seen over 200 million URLs each URL is at least 100 bytes on average Overall we have about 20Gb of URLS Options: compress URLs in main memory, or use disk Bloom Filter (Archive) Disk access with caching (Mercator, Altavista) Parallel Crawlers Web is too big to be crawled by a single crawler, work should be divided avoiding duplication Dynamic assignment Central coordinator dynamically assigns URLs to crawlers Links are given to Central coordinator Static assignment Web is statically partitioned and assigned to crawlers Crawler only crawls its part of the web 10
11 Two problems Load balancing the #URLs assigned to downloaders: Static schemes based on hosts may fail Dynamic relocation schemes may be complicated Let D be the number of downloaders. hash(url) maps an URL to {0,...,D-1}. Dowloader x fetches the URLs U s.t. hash(u) = x Managing the fault-tolerance: What about the death of downloaders? D D-1, new hash!!! What about new downloaders? D D+1, new hash!!! A nice technique: Consistent Hashing A tool for: Spidering Web Cache P2P Routers Load Balance Distributed FS Item and servers mapped to unit circle Item K assigned to first server N such that ID(N) ID(K) What if a downloader goes down? What if a new downloader appears? Each server gets replicated log S times [monotone] adding a new server moves points between one old to the new, only. [balance] Prob item goes to a server is O(1)/S [load] any server gets (I/S) log S items w.h.p [scale] you can copy each server more times... 11
12 Examples: Open Source Nutch, also used by WikiSearch Hentrix, used by Archive.org Consisten Hashing Amazon s Dynamo 12
Collection Building on the Web. Basic Algorithm
 Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
An Overview of Search Engine. Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia
 An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
Crawling the Web. Web Crawling. Main Issues I. Type of crawl
 Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Plan for today. CS276B Text Retrieval and Mining Winter Evolution of search engines. Connectivity analysis
 CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
Performance Analysis for Crawling
 Scalable Servers and Load Balancing Kai Shen Online Applications online applications Applications accessible to online users through. Examples Online keyword search engine: Google. Web email: Gmail. News:
Scalable Servers and Load Balancing Kai Shen Online Applications online applications Applications accessible to online users through. Examples Online keyword search engine: Google. Web email: Gmail. News:
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
SEARCH ENGINE INSIDE OUT
 SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
Crawling CE-324: Modern Information Retrieval Sharif University of Technology
 Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
CS 572: Information Retrieval
 CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
EECS 395/495 Lecture 5: Web Crawlers. Doug Downey
 EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Today s lecture. Information Retrieval. Basic crawler operation. Crawling picture. What any crawler must do. Simple picture complications
 Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
Web Crawling. Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India
 Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Today s lecture. Basic crawler operation. Crawling picture. What any crawler must do. Simple picture complications
 Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning and Pandu Nayak Crawling and Duplicates 2 Sec. 20.2
Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning and Pandu Nayak Crawling and Duplicates 2 Sec. 20.2
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Chapter 2: Literature Review
 Chapter 2: Literature Review 2.1 Introduction Literature review provides knowledge, understanding and familiarity of the research field undertaken. It is a critical study of related reviews from various
Chapter 2: Literature Review 2.1 Introduction Literature review provides knowledge, understanding and familiarity of the research field undertaken. It is a critical study of related reviews from various
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Information Retrieval. Lecture 9 - Web search basics
 Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
1. Introduction. 2. Salient features of the design. * The manuscript is still under progress 1
 A Scalable, Distributed Web-Crawler* Ankit Jain, Abhishek Singh, Ling Liu Technical Report GIT-CC-03-08 College of Computing Atlanta,Georgia {ankit,abhi,lingliu}@cc.gatech.edu In this paper we present
A Scalable, Distributed Web-Crawler* Ankit Jain, Abhishek Singh, Ling Liu Technical Report GIT-CC-03-08 College of Computing Atlanta,Georgia {ankit,abhi,lingliu}@cc.gatech.edu In this paper we present
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
BUbiNG. Massive Crawling for the Masses. Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna
 BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
Information retrieval
 Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Web Crawling. Advanced methods of Information Retrieval. Gerhard Gossen Gerhard Gossen Web Crawling / 57
 Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Web search engines. Prepare a keyword index for corpus Respond to keyword queries with a ranked list of documents.
 Web search engines Rooted in Information Retrieval (IR) systems Prepare a keyword index for corpus Respond to keyword queries with a ranked list of documents. ARCHIE Earliest application of rudimentary
Web search engines Rooted in Information Retrieval (IR) systems Prepare a keyword index for corpus Respond to keyword queries with a ranked list of documents. ARCHIE Earliest application of rudimentary
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Information Retrieval II
 Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
THE HISTORY & EVOLUTION OF SEARCH
 THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Definition. Spider = robot = crawler. Crawlers are computer programs that roam the Web with the goal of automating specific tasks related to the Web.
 Web Crawlers Definition Spider = robot = crawler Crawlers are computer programs that roam the Web with the goal of automating specific tasks related to the Web. What is the Web? (another view) pages containing
Web Crawlers Definition Spider = robot = crawler Crawlers are computer programs that roam the Web with the goal of automating specific tasks related to the Web. What is the Web? (another view) pages containing
A Survey on Web Information Retrieval Technologies
 A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
Search Quality. Jan Pedersen 10 September 2007
 Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
US Patent 6,658,423. William Pugh
 US Patent 6,658,423 William Pugh Detecting duplicate and near - duplicate files Worked on this problem at Google in summer of 2000 I have no information whether this is currently being used I know that
US Patent 6,658,423 William Pugh Detecting duplicate and near - duplicate files Worked on this problem at Google in summer of 2000 I have no information whether this is currently being used I know that
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Design of Alta Vista. Course Overview. Google System Anatomy
 CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
Anatomy of a search engine. Design criteria of a search engine Architecture Data structures
 Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM
 CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
Text Technologies for Data Science INFR11145 Web Search Walid Magdy Lecture Objectives
 Text Technologies for Data Science INFR11145 Web Search (2) Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Basics of Web search Brief History of web search SEOs Web Crawling (intro)
Text Technologies for Data Science INFR11145 Web Search (2) Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Basics of Web search Brief History of web search SEOs Web Crawling (intro)
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
CS 345A Data Mining Lecture 1. Introduction to Web Mining
 CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
Web Search Basics. Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University
 Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
Around the Web in Six Weeks: Documenting a Large-Scale Crawl
 Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
5 Choosing keywords Initially choosing keywords Frequent and rare keywords Evaluating the competition rates of search
 Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Information Retrieval. Lecture 4: Search engines and linkage algorithms
 Information Retrieval Lecture 4: Search engines and linkage algorithms Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk Today 2
Information Retrieval Lecture 4: Search engines and linkage algorithms Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk Today 2
PROJECT REPORT (Final Year Project ) Project Supervisor Mrs. Shikha Mehta
 Project Supervisor Mrs. Shikha Mehta") PROJECT REPORT (Final Year Project 2007-2008) Hybrid Search Engine Project Supervisor Mrs. Shikha Mehta INTRODUCTION Definition: Search Engines A search engine is an information retrieval system designed
PROJECT REPORT (Final Year Project 2007-2008) Hybrid Search Engine Project Supervisor Mrs. Shikha Mehta INTRODUCTION Definition: Search Engines A search engine is an information retrieval system designed
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
OnCrawl Metrics. What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for.
 1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December ISSN Web Search Engine
 International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
Keywords: web crawler, parallel, migration, web database
 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Design of a Parallel Migrating Web Crawler Abhinna Agarwal, Durgesh
ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Design of a Parallel Migrating Web Crawler Abhinna Agarwal, Durgesh
YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION
 San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
Parallel Crawlers. Junghoo Cho University of California, Los Angeles. Hector Garcia-Molina Stanford University.
 Parallel Crawlers Junghoo Cho University of California, Los Angeles cho@cs.ucla.edu Hector Garcia-Molina Stanford University cho@cs.stanford.edu ABSTRACT In this paper we study how we can design an effective
Parallel Crawlers Junghoo Cho University of California, Los Angeles cho@cs.ucla.edu Hector Garcia-Molina Stanford University cho@cs.stanford.edu ABSTRACT In this paper we study how we can design an effective
AN OVERVIEW OF SEARCHING AND DISCOVERING WEB BASED INFORMATION RESOURCES
 Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Beyond Ten Blue Links Seven Challenges
 Beyond Ten Blue Links Seven Challenges Ricardo Baeza-Yates VP of Yahoo! Research for EMEA & LatAm Barcelona, Spain Thanks to Andrei Broder, Yoelle Maarek & Prabhakar Raghavan Agenda Past and Present Wisdom
Beyond Ten Blue Links Seven Challenges Ricardo Baeza-Yates VP of Yahoo! Research for EMEA & LatAm Barcelona, Spain Thanks to Andrei Broder, Yoelle Maarek & Prabhakar Raghavan Agenda Past and Present Wisdom
A Taxonomy of Web Search
 A Taxonomy of Web Search by Andrei Broder 1 Overview Ø Motivation Ø Classic model for IR Ø Web-specific Needs Ø Taxonomy of Web Search Ø Evaluation Ø Evolution of Search Engines Ø Conclusions 2 1 Motivation
A Taxonomy of Web Search by Andrei Broder 1 Overview Ø Motivation Ø Classic model for IR Ø Web-specific Needs Ø Taxonomy of Web Search Ø Evaluation Ø Evolution of Search Engines Ø Conclusions 2 1 Motivation
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Informa(on Retrieval
 Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 12: Crawling and Link Analysis 2 1 Ch. 11-12 Last Time Chapter 11 1. ProbabilisCc Approach to Retrieval / Basic Probability Theory
Introduc)on to Informa)on Retrieval CS3245 Informa(on Retrieval Lecture 12: Crawling and Link Analysis 2 1 Ch. 11-12 Last Time Chapter 11 1. ProbabilisCc Approach to Retrieval / Basic Probability Theory
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Today CSCI Coda. Naming: Volumes. Coda GFS PAST. Instructor: Abhishek Chandra. Main Goals: Volume is a subtree in the naming space
 Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Today CSCI 5105 Coda GFS PAST Instructor: Abhishek Chandra 2 Coda Main Goals: Availability: Work in the presence of disconnection Scalability: Support large number of users Successor of Andrew File System
Crawling - part II. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling - part II CS6200: Information Retrieval Slides by: Jesse Anderton Coverage Good coverage is obtained by carefully selecting seed URLs and using a good page selection policy to decide what to crawl
Crawling - part II CS6200: Information Retrieval Slides by: Jesse Anderton Coverage Good coverage is obtained by carefully selecting seed URLs and using a good page selection policy to decide what to crawl
Data Centers. Tom Anderson
 Data Centers Tom Anderson Transport Clarification RPC messages can be arbitrary size Ex: ok to send a tree or a hash table Can require more than one packet sent/received We assume messages can be dropped,
Data Centers Tom Anderson Transport Clarification RPC messages can be arbitrary size Ex: ok to send a tree or a hash table Can require more than one packet sent/received We assume messages can be dropped,
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Web Crawling. Contents
 Foundations and Trends R in Information Retrieval Vol. 4, No. 3 (2010) 175 246 c 2010 C. Olston and M. Najork DOI: 10.1561/1500000017 Web Crawling By Christopher Olston and Marc Najork Contents 1 Introduction
Foundations and Trends R in Information Retrieval Vol. 4, No. 3 (2010) 175 246 c 2010 C. Olston and M. Najork DOI: 10.1561/1500000017 Web Crawling By Christopher Olston and Marc Najork Contents 1 Introduction
Crawling and Mining Web Sources
 Crawling and Mining Web Sources Flávio Martins (fnm@fct.unl.pt) Web Search 1 Sources of data Desktop search / Enterprise search Local files Networked drives (e.g., NFS/SAMBA shares) Web search All published
Crawling and Mining Web Sources Flávio Martins (fnm@fct.unl.pt) Web Search 1 Sources of data Desktop search / Enterprise search Local files Networked drives (e.g., NFS/SAMBA shares) Web search All published
CS290N Summary Tao Yang
 CS290N Summary 2015 Tao Yang Text books [CMS] Bruce Croft, Donald Metzler, Trevor Strohman, Search Engines: Information Retrieval in Practice, Publisher: Addison-Wesley, 2010. Book website. [MRS] Christopher
CS290N Summary 2015 Tao Yang Text books [CMS] Bruce Croft, Donald Metzler, Trevor Strohman, Search Engines: Information Retrieval in Practice, Publisher: Addison-Wesley, 2010. Book website. [MRS] Christopher
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Yioop Full Historical Indexing In Cache Navigation. Akshat Kukreti
 Yioop Full Historical Indexing In Cache Navigation Akshat Kukreti Agenda Introduction History Feature Cache Page Validation Feature Conclusion Demo Introduction Project goals History feature for enabling
Yioop Full Historical Indexing In Cache Navigation Akshat Kukreti Agenda Introduction History Feature Cache Page Validation Feature Conclusion Demo Introduction Project goals History feature for enabling
Google Search Appliance
 Google Search Appliance Administering Crawl Google Search Appliance software version 7.0 September 2012 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com September 2012 Copyright
Google Search Appliance Administering Crawl Google Search Appliance software version 7.0 September 2012 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com September 2012 Copyright
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 12: Conclusion. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 12: Conclusion Aidan Hogan aidhog@gmail.com FULL-CIRCLE The value of data Twitter architecture Google architecture Generalise concepts to Working
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 12: Conclusion Aidan Hogan aidhog@gmail.com FULL-CIRCLE The value of data Twitter architecture Google architecture Generalise concepts to Working
Sharding & CDNs. CS 475, Spring 2018 Concurrent & Distributed Systems
 Sharding & CDNs CS 475, Spring 2018 Concurrent & Distributed Systems Review: Distributed File Systems Challenges: Heterogeneity (different kinds of computers with different kinds of network links) Scale
Sharding & CDNs CS 475, Spring 2018 Concurrent & Distributed Systems Review: Distributed File Systems Challenges: Heterogeneity (different kinds of computers with different kinds of network links) Scale
index construct Overview Overview Recap How to construct index? Introduction Index construction Introduction to Recap
 to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
FILTERING OF URLS USING WEBCRAWLER
 FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
Remote Procedure Call. Tom Anderson
 Remote Procedure Call Tom Anderson Why Are Distributed Systems Hard? Asynchrony Different nodes run at different speeds Messages can be unpredictably, arbitrarily delayed Failures (partial and ambiguous)
Remote Procedure Call Tom Anderson Why Are Distributed Systems Hard? Asynchrony Different nodes run at different speeds Messages can be unpredictably, arbitrarily delayed Failures (partial and ambiguous)
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA
 CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
Dremel: Interactice Analysis of Web-Scale Datasets
 Dremel: Interactice Analysis of Web-Scale Datasets By Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Alex Zahdeh 1 / 32 Overview
Dremel: Interactice Analysis of Web-Scale Datasets By Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Alex Zahdeh 1 / 32 Overview
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 6: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
Crawling. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,