PROJECT REPORT (Final Year Project ) Project Supervisor Mrs. Shikha Mehta
|
|
|
- Leo Warren
- 5 years ago
- Views:
Transcription
1 PROJECT REPORT (Final Year Project ) Hybrid Search Engine Project Supervisor Mrs. Shikha Mehta
2 INTRODUCTION Definition: Search Engines A search engine is an information retrieval system designed to help find information stored on a computer system, such as on the World Wide Web, inside a corporate or proprietary network, or in a personal computer. Examples: Various search engines are available on the internet e.g. Google, Alta Vista, Ask.com, Yahoo, Lycos, Alltheweb, Myspace, etc. The popularity of search engines can be estimated by the fact that approximately 112 * 10 6 searches are made in a single day from one search engine alone.
3 How do Search Engines work? There are differences in the ways various search engines work, but they all perform three basic tasks: They search the Internet -- or select pieces of the web -- based on important words. [CRAWLER] They keep an index of the words they find, and where they find them. [INDEXER] They allow users to look for words or combinations of words found in that index. [SEARCHER] www CRAWLER INDEXER SEARCHER Local Store (W3 copy) End Users
4 PROBLEM STATEMENT On the basis of recent studies made on the structure and dynamics of the web itself, it has been analyzed that the web is still growing at a high pace, and the dynamics of the web is shifting. More and more dynamic and real-time information is made available on the web. Our aim is to design a search engine that meets the challenges of web growth and update dynamics.
5 How is our Search Engine Hybrid? FAST Crawler Features included in our search engine: Freshness algorithm Heterogeneous Crawlers Heterogeneous Updation mechanism COBWeb Features included in our search engine: Distributed Architecture Inclusion of Importance Number Content based signatures for Page seen problem HITS Link based indexing HYBRID SEARCH ENGINE PAGE RANK Source based indexing focusing on quality of source. DOMINOS Features included in our search engine: Inclusion of a new module namely, Local Cache which stores the URLs recently visited. Mercator Features included in our search engine: Content seen test using fingerprinting Checkpointing URL saving Checksum technique
6 Our Proposed Design
7 Data Flow Initial links Crawler Module Links fetched ContentSeen Tester Non redundant links Compressor Compressed files Keyword Matcher Decompressed stream DeCompressor Data stream Database Matching Links Indexer Ordered Links USER

8 Snapshots Crawler INPUT Initial set of URL s taken for the sample :


9 OUTPUT As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. URLs from the frontier are recursively visited according to a set of policies.
10 HTML Parser Programming Language C# Input After the crawler crawls the web and store the pages in the repository, we need to extract the useful information from the web page like title, no. of forward links etc. of all the web pages. Output The extracted information is then stored in the database.
11 Output
12 Programming Language C# Compressor-Decompressor Input After the crawler crawls the web, this module compress the pages and store them in the repository. We need to decompress all the web pages to search a keyword. Output The compressed pages are stored in the database.
13 Output
14 Content Seen Tester Programming Language C# Input The content seen tester generates a bit sequence of all the web pages using MD5 algorithm. Output The bit sequence of every web page is stored in the database.
15 Output
16 Indexer Sorts the results found on the basis of a rank distribution algorithm. Programming Language C# Input The links between all the web pages are fetched from the database. Output The rank of each web page is stored in the database.
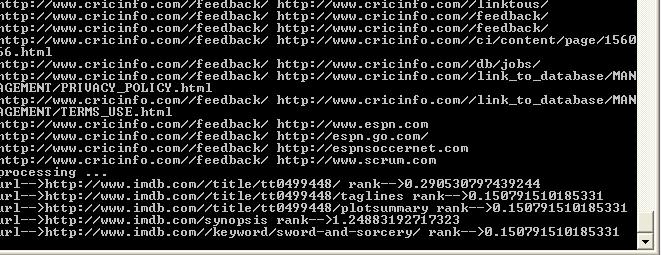
17 Output
18 Refresher Updates the local database with fresh copies of web pages. Programming Language C# Input The cached pages from the database. Output The refreshed pages are stored in the repository.
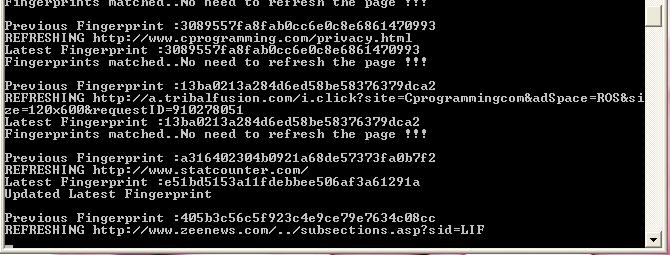
19 Output
20 Programming Language ASP.NET Input User Interface The user enters a keyword or multiple keywords. Output The results are fetched to the user.
21 Output
22 Thank You!! Presented By: ANKUSH GULATI Project Id: B103 ANKIT KALRA Project Id: B119
A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index.
 A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index. The major search engines on the Web all have such a program,
A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index. The major search engines on the Web all have such a program,
Anatomy of a search engine. Design criteria of a search engine Architecture Data structures
 Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Search Engine Techniques: A Review
 Search Engine Techniques: A Review 53 Shivanshu Rastogi Email: rshivanshu1145@gmail.com Zubair Iqbal Email: zubairiqbal17@gmail.com Prabal Bhatnagar Email: prabal_bhatnagar@yahoo.com ABSTRACT The World
Search Engine Techniques: A Review 53 Shivanshu Rastogi Email: rshivanshu1145@gmail.com Zubair Iqbal Email: zubairiqbal17@gmail.com Prabal Bhatnagar Email: prabal_bhatnagar@yahoo.com ABSTRACT The World
CHAPTER 4 PROPOSED ARCHITECTURE FOR INCREMENTAL PARALLEL WEBCRAWLER
 CHAPTER 4 PROPOSED ARCHITECTURE FOR INCREMENTAL PARALLEL WEBCRAWLER 4.1 INTRODUCTION In 1994, the World Wide Web Worm (WWWW), one of the first web search engines had an index of 110,000 web pages [2] but
CHAPTER 4 PROPOSED ARCHITECTURE FOR INCREMENTAL PARALLEL WEBCRAWLER 4.1 INTRODUCTION In 1994, the World Wide Web Worm (WWWW), one of the first web search engines had an index of 110,000 web pages [2] but
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
How to Get Your Website Listed on Major Search Engines
 Contents Introduction 1 Submitting via Global Forms 1 Preparing to Submit 2 Submitting to the Top 3 Search Engines 3 Paid Listings 4 Understanding META Tags 5 Adding META Tags to Your Web Site 5 Introduction
Contents Introduction 1 Submitting via Global Forms 1 Preparing to Submit 2 Submitting to the Top 3 Search Engines 3 Paid Listings 4 Understanding META Tags 5 Adding META Tags to Your Web Site 5 Introduction
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
LIST OF ACRONYMS & ABBREVIATIONS
 LIST OF ACRONYMS & ABBREVIATIONS ARPA CBFSE CBR CS CSE FiPRA GUI HITS HTML HTTP HyPRA NoRPRA ODP PR RBSE RS SE TF-IDF UI URI URL W3 W3C WePRA WP WWW Alpha Page Rank Algorithm Context based Focused Search
LIST OF ACRONYMS & ABBREVIATIONS ARPA CBFSE CBR CS CSE FiPRA GUI HITS HTML HTTP HyPRA NoRPRA ODP PR RBSE RS SE TF-IDF UI URI URL W3 W3C WePRA WP WWW Alpha Page Rank Algorithm Context based Focused Search
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Searching the Web for Information
 Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
Search Xin Liu Searching the Web for Information How a Search Engine Works Basic parts: 1. Crawler: Visits sites on the Internet, discovering Web pages 2. Indexer: building an index to the Web's content
Directory Search Engines Searching the Yahoo Directory
 Searching on the WWW Directory Oriented Search Engines Often looking for some specific information WWW has a growing collection of Search Engines to aid in locating information The Search Engines return
Searching on the WWW Directory Oriented Search Engines Often looking for some specific information WWW has a growing collection of Search Engines to aid in locating information The Search Engines return
An Overview of Search Engine. Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia
 An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Search Quality. Jan Pedersen 10 September 2007
 Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
Search Quality Jan Pedersen 10 September 2007 Outline The Search Landscape A Framework for Quality RCFP Search Engine Architecture Detailed Issues 2 Search Landscape 2007 Source: Search Engine Watch: US
Web Search Basics. Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University
 Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
Web Search Basics Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Searching in All the Right Places. How Is Information Organized? Chapter 5: Searching for Truth: Locating Information on the WWW
 Chapter 5: Searching for Truth: Locating Information on the WWW Fluency with Information Technology Third Edition by Lawrence Snyder Searching in All the Right Places The Obvious and Familiar To find tax
Chapter 5: Searching for Truth: Locating Information on the WWW Fluency with Information Technology Third Edition by Lawrence Snyder Searching in All the Right Places The Obvious and Familiar To find tax
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
A Novel Interface to a Web Crawler using VB.NET Technology
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 6 (Nov. - Dec. 2013), PP 59-63 A Novel Interface to a Web Crawler using VB.NET Technology Deepak Kumar
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 6 (Nov. - Dec. 2013), PP 59-63 A Novel Interface to a Web Crawler using VB.NET Technology Deepak Kumar
FILTERING OF URLS USING WEBCRAWLER
 FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
Collection Building on the Web. Basic Algorithm
 Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Content Based Smart Crawler For Efficiently Harvesting Deep Web Interface
 Content Based Smart Crawler For Efficiently Harvesting Deep Web Interface Prof. T.P.Aher(ME), Ms.Rupal R.Boob, Ms.Saburi V.Dhole, Ms.Dipika B.Avhad, Ms.Suvarna S.Burkul 1 Assistant Professor, Computer
Content Based Smart Crawler For Efficiently Harvesting Deep Web Interface Prof. T.P.Aher(ME), Ms.Rupal R.Boob, Ms.Saburi V.Dhole, Ms.Dipika B.Avhad, Ms.Suvarna S.Burkul 1 Assistant Professor, Computer
Web Search Basics. Berlin Chen Department t of Computer Science & Information Engineering National Taiwan Normal University
 Web Search Basics Berlin Chen Department t of Computer Science & Information Engineering i National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze,
Web Search Basics Berlin Chen Department t of Computer Science & Information Engineering i National Taiwan Normal University References: 1. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze,
CSE 3. How Is Information Organized? Searching in All the Right Places. Design of Hierarchies
 CSE 3 Comics Updates Shortcut(s)/Tip(s) of the Day Web Proxy Server PrimoPDF How Computers Work Ch 30 Chapter 5: Searching for Truth: Locating Information on the WWW Fluency with Information Technology
CSE 3 Comics Updates Shortcut(s)/Tip(s) of the Day Web Proxy Server PrimoPDF How Computers Work Ch 30 Chapter 5: Searching for Truth: Locating Information on the WWW Fluency with Information Technology
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Crawling CE-324: Modern Information Retrieval Sharif University of Technology
 Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
EECS 395/495 Lecture 5: Web Crawlers. Doug Downey
 EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES
 SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
How to Crawl the Web. Hector Garcia-Molina Stanford University. Joint work with Junghoo Cho
 How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Around the Web in Six Weeks: Documenting a Large-Scale Crawl
 Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Ontology Based Searching For Optimization Used As Advance Technology in Web Crawlers
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 6, Ver. II (Nov.- Dec. 2017), PP 68-75 www.iosrjournals.org Ontology Based Searching For Optimization
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 6, Ver. II (Nov.- Dec. 2017), PP 68-75 www.iosrjournals.org Ontology Based Searching For Optimization
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Design of Alta Vista. Course Overview. Google System Anatomy
 CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
Crawling the Web. Web Crawling. Main Issues I. Type of crawl
 Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Software Requirement Specification Version 1.0.0
 Software Requirement Specification Version 1.0.0 Project Title :BATSS - Search Engine for Animation Team Title :BATSS Team Guide (KreSIT) and College : Vijyalakshmi,V.J.T.I.,Mumbai Group Members : Basesh
Software Requirement Specification Version 1.0.0 Project Title :BATSS - Search Engine for Animation Team Title :BATSS Team Guide (KreSIT) and College : Vijyalakshmi,V.J.T.I.,Mumbai Group Members : Basesh
Search Like a Pro. How Search Engines Work. Comparison Search Engine. Comparison Search Engine. How Search Engines Work
 Search Like a Pro Nancy Warren AkLA Conference 2010 How Search Engines Work http://computer.howstuffworks.com/search-engine1.htm Google How Search Engines Crawl a Web Site Yahoo Comparison Search Engine
Search Like a Pro Nancy Warren AkLA Conference 2010 How Search Engines Work http://computer.howstuffworks.com/search-engine1.htm Google How Search Engines Crawl a Web Site Yahoo Comparison Search Engine
Web Crawling. Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India
 Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Searching. Outline. Copyright 2006 Haim Levkowitz. Copyright 2006 Haim Levkowitz
 Searching 1 Outline Goals and Objectives Topic Headlines Introduction Directories Open Directory Project Search Engines Metasearch Engines Search techniques Intelligent Agents Invisible Web Summary 2 1
Searching 1 Outline Goals and Objectives Topic Headlines Introduction Directories Open Directory Project Search Engines Metasearch Engines Search techniques Intelligent Agents Invisible Web Summary 2 1
Information Retrieval Issues on the World Wide Web
 Information Retrieval Issues on the World Wide Web Ashraf Ali 1 Department of Computer Science, Singhania University Pacheri Bari, Rajasthan aali1979@rediffmail.com Dr. Israr Ahmad 2 Department of Computer
Information Retrieval Issues on the World Wide Web Ashraf Ali 1 Department of Computer Science, Singhania University Pacheri Bari, Rajasthan aali1979@rediffmail.com Dr. Israr Ahmad 2 Department of Computer
SEARCH ENGINE INSIDE OUT
 SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
5 Choosing keywords Initially choosing keywords Frequent and rare keywords Evaluating the competition rates of search
 Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Deep Web Crawling and Mining for Building Advanced Search Application
 Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
Keywords: web crawler, parallel, migration, web database
 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Design of a Parallel Migrating Web Crawler Abhinna Agarwal, Durgesh
ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Design of a Parallel Migrating Web Crawler Abhinna Agarwal, Durgesh
Competitive Intelligence and Web Mining:
 Competitive Intelligence and Web Mining: Domain Specific Web Spiders American University in Cairo (AUC) CSCE 590: Seminar1 Report Dr. Ahmed Rafea 2 P age Khalid Magdy Salama 3 P age Table of Contents Introduction
Competitive Intelligence and Web Mining: Domain Specific Web Spiders American University in Cairo (AUC) CSCE 590: Seminar1 Report Dr. Ahmed Rafea 2 P age Khalid Magdy Salama 3 P age Table of Contents Introduction
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Web Analysis in 4 Easy Steps. Rosaria Silipo, Bernd Wiswedel and Tobias Kötter
 Web Analysis in 4 Easy Steps Rosaria Silipo, Bernd Wiswedel and Tobias Kötter KNIME Forum Analysis KNIME Forum Analysis Steps: 1. Get data into KNIME 2. Extract simple statistics (how many posts, response
Web Analysis in 4 Easy Steps Rosaria Silipo, Bernd Wiswedel and Tobias Kötter KNIME Forum Analysis KNIME Forum Analysis Steps: 1. Get data into KNIME 2. Extract simple statistics (how many posts, response
Web Page Load Reduction using Page Change Detection
 Web Page Load Reduction using Page Change Detection Naresh Kumar * Assistant Professor, MSIT, Janakpuri, New Delhi, India. Abstract:-World Wide Web is the assortment of hyper-linked documents in hypertext
Web Page Load Reduction using Page Change Detection Naresh Kumar * Assistant Professor, MSIT, Janakpuri, New Delhi, India. Abstract:-World Wide Web is the assortment of hyper-linked documents in hypertext
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
THE HISTORY & EVOLUTION OF SEARCH
 THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
[Banjare*, 4.(6): June, 2015] ISSN: (I2OR), Publication Impact Factor: (ISRA), Journal Impact Factor: 2.114
![[Banjare*, 4.(6): June, 2015] ISSN: (I2OR), Publication Impact Factor: (ISRA), Journal Impact Factor: 2.114](/thumbs/77/75512611.jpg "[Banjare*, 4.(6): June, 2015] ISSN: (I2OR), Publication Impact Factor: (ISRA), Journal Impact Factor: 2.114") IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY THE CONCEPTION OF INTEGRATING MUTITHREDED CRAWLER WITH PAGE RANK TECHNIQUE :A SURVEY Ms. Amrita Banjare*, Mr. Rohit Miri * Dr.
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY THE CONCEPTION OF INTEGRATING MUTITHREDED CRAWLER WITH PAGE RANK TECHNIQUE :A SURVEY Ms. Amrita Banjare*, Mr. Rohit Miri * Dr.
A Heuristic Based AGE Algorithm For Search Engine
 A Heuristic Based AGE Algorithm For Search Engine Harshita Bhardwaj1 Computer Science and Information Technology Deptt. Krishna Institute of Management and Technology, Moradabad, Uttar Pradesh, India Gaurav
A Heuristic Based AGE Algorithm For Search Engine Harshita Bhardwaj1 Computer Science and Information Technology Deptt. Krishna Institute of Management and Technology, Moradabad, Uttar Pradesh, India Gaurav
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Review: Searching the Web [Arasu 2001]
![Review: Searching the Web [Arasu 2001]](/thumbs/81/82666657.jpg "Review: Searching the Web [Arasu 2001]") Review: Searching the Web [Arasu 2001] Gareth Cronin University of Auckland gareth@cronin.co.nz The authors of Searching the Web present an overview of the state of current technologies employed in the
Review: Searching the Web [Arasu 2001] Gareth Cronin University of Auckland gareth@cronin.co.nz The authors of Searching the Web present an overview of the state of current technologies employed in the
CS 572: Information Retrieval
 CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
Why is Search Engine Optimisation (SEO) important?
 important?") Why is Search Engine Optimisation (SEO) important? With literally billions of searches conducted every month search engines have essentially become our gateway to the internet. Unfortunately getting yourself
Why is Search Engine Optimisation (SEO) important? With literally billions of searches conducted every month search engines have essentially become our gateway to the internet. Unfortunately getting yourself
INTRODUCTION. Chapter GENERAL
 Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
Chapter 1 INTRODUCTION 1.1 GENERAL The World Wide Web (WWW) [1] is a system of interlinked hypertext documents accessed via the Internet. It is an interactive world of shared information through which
This tutorial has been prepared for beginners to help them understand the simple but effective SEO characteristics.
 About the Tutorial Search Engine Optimization (SEO) is the activity of optimizing web pages or whole sites in order to make them search engine friendly, thus getting higher positions in search results.
About the Tutorial Search Engine Optimization (SEO) is the activity of optimizing web pages or whole sites in order to make them search engine friendly, thus getting higher positions in search results.
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Optimized Searching Algorithm Based On Page Ranking: (OSA PR)
") Volume 2, No. 5, Sept-Oct 2011 International Journal of Advanced Research in Computer Science RESEARCH PAPER Available Online at www.ijarcs.info ISSN No. 0976-5697 Optimized Searching Algorithm Based On
Volume 2, No. 5, Sept-Oct 2011 International Journal of Advanced Research in Computer Science RESEARCH PAPER Available Online at www.ijarcs.info ISSN No. 0976-5697 Optimized Searching Algorithm Based On
EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING
 Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
Learn SEO Copywriting
 This is video 1.1 in the online course: Learn SEO Copywriting Module 1: An introduction to SEO copywriting What we ll cover in this session What is SEO? What is SEO copywriting? How does Google work Factors
This is video 1.1 in the online course: Learn SEO Copywriting Module 1: An introduction to SEO copywriting What we ll cover in this session What is SEO? What is SEO copywriting? How does Google work Factors
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule
 Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Objective Explain concepts used to create websites.
 Objective 106.01 Explain concepts used to create websites. WEB DESIGN o The different areas of web design include: Web graphic design User interface design Authoring (including standardized code and proprietary
Objective 106.01 Explain concepts used to create websites. WEB DESIGN o The different areas of web design include: Web graphic design User interface design Authoring (including standardized code and proprietary
An Efficient Method for Deep Web Crawler based on Accuracy
 An Efficient Method for Deep Web Crawler based on Accuracy Pranali Zade 1, Dr. S.W Mohod 2 Master of Technology, Dept. of Computer Science and Engg, Bapurao Deshmukh College of Engg,Wardha 1 pranalizade1234@gmail.com
An Efficient Method for Deep Web Crawler based on Accuracy Pranali Zade 1, Dr. S.W Mohod 2 Master of Technology, Dept. of Computer Science and Engg, Bapurao Deshmukh College of Engg,Wardha 1 pranalizade1234@gmail.com
CHAPTER 2 WEB INFORMATION RETRIEVAL: A REVIEW
 CHAPTER 2 WEB INFORMATION RETRIEVAL: A REVIEW 2.1 THE INTERNET The Internet [29] is often described as a network of networks because all the smaller networks are linked together into the one giant network
CHAPTER 2 WEB INFORMATION RETRIEVAL: A REVIEW 2.1 THE INTERNET The Internet [29] is often described as a network of networks because all the smaller networks are linked together into the one giant network
A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS Satwinder Kaur 1 & Alisha Gupta 2 1 Research Scholar (M.tech
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS Satwinder Kaur 1 & Alisha Gupta 2 1 Research Scholar (M.tech
Module 1: Internet Basics for Web Development (II)
") INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
5. search engine marketing
 5. search engine marketing What s inside: A look at the industry known as search and the different types of search results: organic results and paid results. We lay the foundation with key terms and concepts
5. search engine marketing What s inside: A look at the industry known as search and the different types of search results: organic results and paid results. We lay the foundation with key terms and concepts
An Adaptive Approach in Web Search Algorithm
 International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 4, Number 15 (2014), pp. 1575-1581 International Research Publications House http://www. irphouse.com An Adaptive Approach
International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 4, Number 15 (2014), pp. 1575-1581 International Research Publications House http://www. irphouse.com An Adaptive Approach
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
EVALUATING SEARCH EFFECTIVENESS OF SOME SELECTED SEARCH ENGINES
 DOI: https://dx.doi.org/10.4314/gjpas.v23i1.14 GLOBAL JOURNAL OF PURE AND APPLIED SCIENCES VOL. 23, 2017: 139-149 139 COPYRIGHT BACHUDO SCIENCE CO. LTD PRINTED IN NIGERIA ISSN 1118-0579 www.globaljournalseries.com,
DOI: https://dx.doi.org/10.4314/gjpas.v23i1.14 GLOBAL JOURNAL OF PURE AND APPLIED SCIENCES VOL. 23, 2017: 139-149 139 COPYRIGHT BACHUDO SCIENCE CO. LTD PRINTED IN NIGERIA ISSN 1118-0579 www.globaljournalseries.com,
Crawling. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Web Applications: Internet Search and Digital Preservation
 CS 312 Internet Concepts Web Applications: Internet Search and Digital Preservation Dr. Michele Weigle Department of Computer Science Old Dominion University mweigle@cs.odu.edu http://www.cs.odu.edu/~mweigle/cs312-f11/
CS 312 Internet Concepts Web Applications: Internet Search and Digital Preservation Dr. Michele Weigle Department of Computer Science Old Dominion University mweigle@cs.odu.edu http://www.cs.odu.edu/~mweigle/cs312-f11/
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Indexing Web pages. Web Search: Indexing Web Pages. Indexing the link structure. checkpoint URL s. Connectivity Server: Node table
 Indexing Web pages Web Search: Indexing Web Pages CPS 296.1 Topics in Database Systems Indexing the link structure AltaVista Connectivity Server case study Bharat et al., The Fast Access to Linkage Information
Indexing Web pages Web Search: Indexing Web Pages CPS 296.1 Topics in Database Systems Indexing the link structure AltaVista Connectivity Server case study Bharat et al., The Fast Access to Linkage Information
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA
 CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
deseo: Combating Search-Result Poisoning Yu USF
 deseo: Combating Search-Result Poisoning Yu Jin @MSCS USF Your Google is not SAFE! SEO Poisoning - A new way to spread malware! Why choose SE? 22.4% of Google searches in the top 100 results > 50% for
deseo: Combating Search-Result Poisoning Yu Jin @MSCS USF Your Google is not SAFE! SEO Poisoning - A new way to spread malware! Why choose SE? 22.4% of Google searches in the top 100 results > 50% for
Information Retrieval. Lecture 9 - Web search basics
 Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
An Approach To Web Content Mining
 An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
Search Engines and Web Dynamics
 Search Engines and Web Dynamics Knut Magne Risvik Fast Search & Transfer ASA Knut.Risvik@fast.no Rolf Michelsen Fast Search & Transfer ASA Rolf.Michelsen@fast.no Abstract In this paper we study several
Search Engines and Web Dynamics Knut Magne Risvik Fast Search & Transfer ASA Knut.Risvik@fast.no Rolf Michelsen Fast Search & Transfer ASA Rolf.Michelsen@fast.no Abstract In this paper we study several
3 Media Web. Understanding SEO WHITEPAPER
 3 Media Web WHITEPAPER WHITEPAPER In business, it s important to be in the right place at the right time. Online business is no different, but with Google searching more than 30 trillion web pages, 100
3 Media Web WHITEPAPER WHITEPAPER In business, it s important to be in the right place at the right time. Online business is no different, but with Google searching more than 30 trillion web pages, 100
WebSite Grade For : 97/100 (December 06, 2007)
") 1 of 5 12/6/2007 1:41 PM WebSite Grade For www.hubspot.com : 97/100 (December 06, 2007) A website grade of 97 for www.hubspot.com means that of the thousands of websites that have previously been submitted
1 of 5 12/6/2007 1:41 PM WebSite Grade For www.hubspot.com : 97/100 (December 06, 2007) A website grade of 97 for www.hubspot.com means that of the thousands of websites that have previously been submitted
Search Engine Architecture. Hongning Wang
 Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine
Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine