Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
|
|
|
- Aubrey King
- 5 years ago
- Views:
Transcription
1 Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays)
2 A computer vision goal Recognize many different objects under many viewing conditions in unconstrained settings. OFFICE Bookshelf Screen Desk 2

3 Why is this hard? y x 10,000 patches/object/image Plus, we want to do this for ~ 1000 objects 1,000,000 images/day time 3
 Graded Learning for Object Detection - Fleuret, Geman (1999) Robust Real-time Object Detection - Viola, Jones (2001) Feature")
4 The face detection age The representation and matching of pictorial structures Fischler, Elschlager (1973). Face recognition using eigenfaces M. Turk and A. Pentland (1991). Human Face Detection in Visual Scenes - Rowley, Baluja, Kanade (1995) Graded Learning for Object Detection - Fleuret, Geman (1999) Robust Real-time Object Detection - Viola, Jones (2001) Feature Reduction and Hierarchy of Classifiers for Fast Object Detection in Video Images - Heisele, Serre, Mukherjee, Poggio (2001). 4
5 Head in the coffee beans problem Can you find the head in this image? 5

6 Head in the coffee beans problem Can you find the head in this image? 6

7 Context in Recognition Objects usually are surrounded by a scene that can provide context in the form of nearby objects, surfaces, scene category, geometry, etc.


8 Context provides clues for function What is this? Now can you tell?
9 Sometimes context is the major component of recognition What is this?

10 Sometimes context is the major component of recognition What is this? Now can you tell?
11 More Low-Res What are these blobs?

12 More Low-Res The same pixels! (a car)

13 Some symptoms of standard approaches 13
14 Just objects is not enough The detector challenge: by looking at the output of a detector on a random set of images, can you guess which object is it trying to detect? 14
15 What object is detector trying to detect? The detector challenge: by looking at the output of a detector on a random set of images, can you guess which object is it trying to detect? 15

16 1. chair, 2. table, 3. road, 4. road, 5. table, 6. car, 7. keyboard. 16
17 What are the hidden objects?


18 What are the hidden objects? Chance ~ 1/

19 Biederman 1982 Pictures shown for 150 ms. Objects in appropriate context were detected more accurately than objects in an inappropriate context. Scene consistency affects object detection. 19

20 Look-Alikes by Joan Steiner Even in high resolution, we can not shut down contextual processing and it is hard to recognize the true identities of the elements that compose this scene. 20

21 Look-Alikes by Joan Steiner 21
22 The multiple personalities of a blob 22


23 The multiple personalities of a blob 23





24 Recognition with low resolution none not sure bedroom bedroom 12x12 16x16 24x24 32x32 bookcase closet window bed skyscraper poster window poster skyscraper bed man bed leg shoes step ladder Humans can perceive the Gist of the scene (scene category + 4/5 objects) with a resolution of 32x32 pixels. 24 Torralba. Visual Neuroscience. 2009
25 Disambiguation 25
26 Disambiguation 26
27 Disambiguation 27





28 Why is context important? Changes the interpretation of an object (or its function) Context defines what an unexpected event is 28
")
29 Global precedence Forest Before Trees: The Precedence of Global Features in Visual Perception Navon (1977) 29
")




")








30 p(o I) ap(i O) p(o) Object model Context model office Full joint Scene model p(o) = S Pp(Oi S=s) p(s=s) s i street Approx. joint 30
31 Context models object1 object2 object3 Independent model scene object2 object1 object2 object3 object1 object3 Objects are correlated via the scene Dependencies among objects 31
32 Context models object1 object2 object3 Independent model scene object2 object1 object2 object3 object1 object3 Objects are correlated via the scene Dependencies among objects 32
33 Scene recognition without object recognition Scene S g Scene features Murphy, Torralba, Freeman; NIPS Torralba, Murphy, Freeman, CACM
34 Application of object detection for image retrieval Results using the keyboard detector alone

35 The system does not care about the scene, but we do We know there is a keyboard present in this scene even if we cannot see it clearly. We know there is no keyboard present in this scene even if there is one indeed.
 5 0 0 5 10 15 P(N car S = park) 5 N N 0 0 5 10 15 g Scene gist features Murphy, Torralba, Freeman;")
36 An integrated model of Scenes, Objects, and Parts Scene S N car P(N car S = street) P(N car S = park) 5 N N g Scene gist features Murphy, Torralba, Freeman; NIPS Torralba, Murphy, Freeman, CACM
37 Object retrieval: scene features vs. detector Results using the keyboard detector alone Results using both the detector and the global scene features Murphy, Torralba, Freeman; NIPS Torralba, Murphy, Freeman, CACM
38 Context driven object detection Scene S N car P(N car S = street) Z car N g Scene gist features 38

39 The layered structure of scenes Assuming a human observer standing on the ground p(x) p(x 2 x 1 ) In a display with multiple targets present, the location of one target constraints the y coordinate of the remaining targets, but not the x coordinate. Torralba, Oliva, Castelhano, Henderson. 2006

40 Car detection without a car detector 40

41 screens keyboard car pedestrian 41




42 Detecting faces without a face detector Torralba & Sinha, 01; Torralba, 0342
 0 1 5 Z car N 0 0 5 10 15 g Scene gist features Murphy, Torralba, Freeman;")
43 Context driven object detection Scene S N car P(N car S = street) Z car N g Scene gist features Murphy, Torralba, Freeman; NIPS Torralba, Murphy, Freeman, CACM

44 An integrated model of Scenes, Objects, and Parts Scene S N car Z car car F i g d car i x car i M=4 Scene gist features Murphy, Torralba, Freeman; NIPS Torralba, Murphy, Freeman, CACM
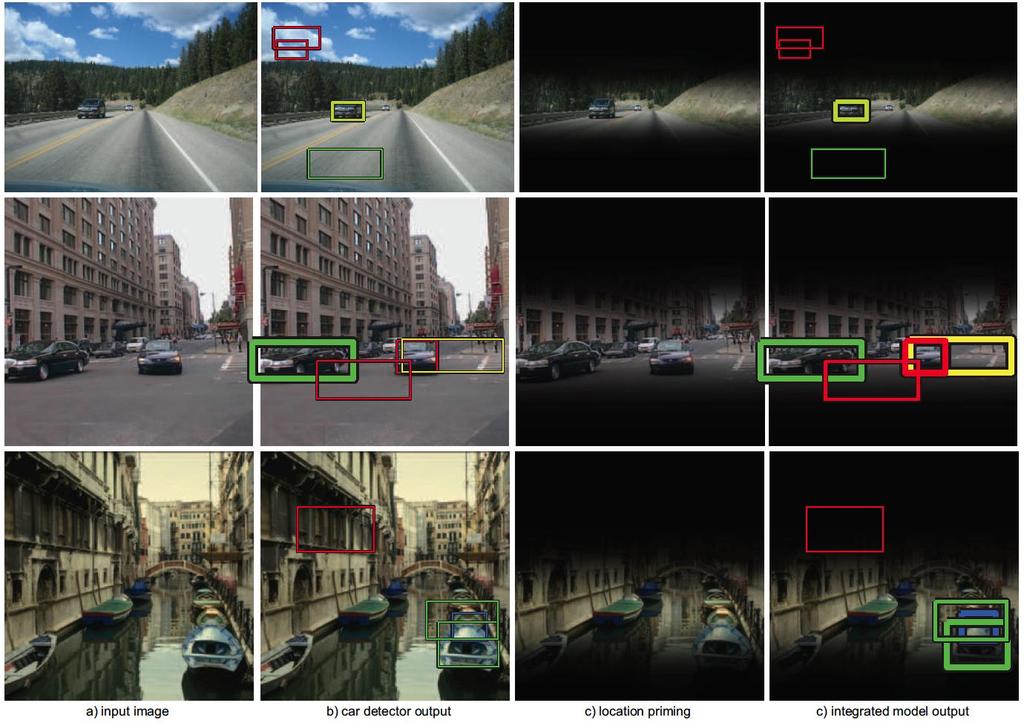
45
46 Failures If the detector fails context can not help 46




47 Failures If the detector fails context can not help If the detector produces a contextually coherent false alarm, context will increase the error. 47


48 A car out of context 48

49 Who needs context anyway? We can recognize objects even out of context Banksy 49
50 Context models object1 object2 object3 Independent model scene object2 object1 object2 object3 object1 object3 Objects are correlated via the scene Dependencies among objects
![Building, cat car, table cow, building road, river 1) Generate candidate objects (run a detector, or segmentation) M possible object labels N regions Label: c k = [1 M] with k = [1 N] Scores: s k =](/docs-images/90/102407859/images/51-1.jpg "vector length M 2) For each candidate, get a list of possible interpretations with their probabilities p(c k = m s k ) 3) Goal: to assign labels c k to each candidate so that they are in contextual")
51 Building, cat car, table cow, building road, river 1) Generate candidate objects (run a detector, or segmentation) M possible object labels N regions Label: c k = [1 M] with k = [1 N] Scores: s k = vector length M 2) For each candidate, get a list of possible interpretations with their probabilities p(c k = m s k ) 3) Goal: to assign labels c k to each candidate so that they are in contextual agreement. We want to optimize the joint probability of all the labels: p(c 1 = m 1,, c N = m N s 1,, s N ) 51 A. Rabinovich, A. Vedaldi, C. Galleguillos, E. Wiewiora and S. Belongie. Objects in Context. ICCV 2007
. A. Rabinovich, A. Vedaldi, C. Galleguillos, E. Wiewiora and S. Belongie. Objects in Context.")
52 F(c i =m i, c j =m j ) = co-ocurrence matrix on training set (count how many times two objects appear together). A. Rabinovich, A. Vedaldi, C. Galleguillos, E. Wiewiora and S. Belongie. Objects in Context. ICCV

53 A. Rabinovich, A. Vedaldi, C. Galleguillos, E. Wiewiora and S. Belongie. Objects in Context. ICCV




54 Spatial layout is especially important 1. Context for recognition

55 Spatial layout is especially important 1. Context for recognition Slide: Derek Hoiem

56 Spatial layout is especially important 1. Context for recognition 2. Scene understanding Slide: Derek Hoiem

 2D to 3D conversion for 3D TV d)")
57 Spatial layout is especially important 1. Context for recognition 2. Scene understanding 3. Many direct applications a) Assisted driving b) Robot navigation/interaction c) 2D to 3D conversion for 3D TV d) Object insertion Slide: Derek Hoiem
58 Spatial Layout: 2D vs. 3D Slide: Derek Hoiem


![Hebert 2005] [He](/docs-images/90/102407859/images/59-3.jpg "Zemel")

59 Context in Image Space [Torralba Murphy Freeman 2004] 59 [Kumar Hebert 2005] [He Zemel Cerreira-Perpiñán 2004] Slide: Derek Hoiem

60 But object relations are in 3D Close Not Close Slide: Derek Hoiem
61 How to represent scene space? Slide: Derek Hoiem

62 Wide variety of possible representations Figs from Hoiem/Savarese Draft

63 Figs from Hoiem/Savarese Draft

64 Figs from Hoiem/Savarese Draft


65 Low detail, Low abstraction Holistic Scene Space: Gist Torralba & Oliva 2002 Oliva & Torralba 2001 Slide: Derek Hoiem


66 High detail, Low abstraction Depth Map Saxena, Chung & Ng 2005, 2007 Slide: Derek Hoiem

67 Medium detail, High abstraction Room as a Box Hedau Hoiem Forsyth 2009 Slide: Derek Hoiem








68 Surface Layout: describe 3D surfaces with geometric classes Sky Non-Planar Porous Vertical Non-Planar Solid Support Planar (Left/Center/Right) Slide: Derek Hoiem

69 Geometry estimation as recognition Region Features Color Texture Perspective Position Surface Geometry Classifier Vertical, Planar Training Data Slide: Derek Hoiem



70 Use a variety of image cues Color, texture, image location Vanishing points, lines Texture gradient Slide: Derek Hoiem
71 Surface Layout Algorithm Input Image Segmentation Features Perspective Color Texture Position Surface Labels Trained Region Classifier Training Data Hoiem Efros Hebert (2007)
72 Input Image Surface Layout Algorithm Multiple Segmentations Features Perspective Color Texture Position Confidence-Weighted Predictions Final Surface Labels Trained Region Classifier Training Data Hoiem Efros Hebert (2007)

73 Surface Description Result Slide: Derek Hoiem



74 Automatic Photo Popup Labeled Image Fit Ground-Vertical Boundary with Line Segments Form Segments into Polylines Cut and Fold Final Pop-up Model [Hoiem Efros Hebert 2005]

75 Automatic Photo Pop-up Slide: Derek Hoiem
 Lee Kanade Hebert (2009) Gupta")
76 What about more organized but complex spaces? Other excellent works include: Saxena Sun Ng (2009) Lee Kanade Hebert (2009) Gupta Efros Hebert (2010) Slide: Derek Hoiem
77 The room as a box Hedau Hoiem Forsyth (2009)





78 Recovering the box layout Surface Label Confidences Vertical VP Left Wall Right Wall Floor Objects Joint Inference Detected Edges + Vanishing Points Most Likely Geometry Hypothesized Boxes


79 Estimate room s physical space from one image Estimated Box Geometry + Object Pixels 3D Reconstruction + Estimated Occupied Volume
80 Detecting 3D bed positions in an image 2D Bed Detection 3D Bed Detection with Scene Geometry Hedau Hoiem Forsyth (2010)






81 Searching for beds in room coordinates Recover Room Coordinates Rectify Features to Room Coordinates Rectified Sliding Windows


82 3D bed detection from an image


83 Reason about 3D room and bed space Joint Inference with Priors Beds close to walls Beds within room Consistent bed/wall size Two objects cannot occupy the same space Hedau Hoiem Forsyth (2010)

84 Depth Estimates from an Image Saxena et al. 2005, 2008

85 Depth from Image: approach 1. Divide image into superpixels 2. Compute features for each superpixel Position, color, texture, shape 3. Predict 3D plane parameters for each superpixel using features 4. Estimate confidence in prediction using features 5. Global inference, incorporating constraints of connected structure, co-planarity, co-linearity Saxena et al. 2008

86 Depth Estimates from an Image Saxena et al. 2005, 2008

87 Depth Estimates from an Image Saxena et al. 2008




88 Depth from Image: Reconstructions Input Novel View Saxena et al. 2008
89 Things to remember Objects should be interpreted in the context of the surrounding scene Many types of context to consider Spatial layout is an important part of scene interpretation, but many open problems How to represent space? How to learn and infer spatial models? Consider trade-offs of detail vs. accuracy and abstraction vs. quantification
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
CS 558: Computer Vision 13 th Set of Notes
 CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
Closing the Loop in Scene Interpretation
 Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Using the Forest to See the Trees: Context-based Object Recognition
 Using the Forest to See the Trees: Context-based Object Recognition Bill Freeman Joint work with Antonio Torralba and Kevin Murphy Computer Science and Artificial Intelligence Laboratory MIT A computer
Using the Forest to See the Trees: Context-based Object Recognition Bill Freeman Joint work with Antonio Torralba and Kevin Murphy Computer Science and Artificial Intelligence Laboratory MIT A computer
Can Similar Scenes help Surface Layout Estimation?
 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
ELL 788 Computational Perception & Cognition July November 2015
 ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
Single-view 3D Reconstruction
 Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Course Administration
 Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
1 Learning Spatial Context: 2 Using Stuff to Find Things
 Learning Spatial Context: 2 Using Stuff to Find Things 2 Geremy Heitz Daphne Koller 3 3 4 Department of Computer Science 4 5 Stanford University 5 6 Stanford, CA 94305 6 7 Abstract. The sliding window
Learning Spatial Context: 2 Using Stuff to Find Things 2 Geremy Heitz Daphne Koller 3 3 4 Department of Computer Science 4 5 Stanford University 5 6 Stanford, CA 94305 6 7 Abstract. The sliding window
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
CS294 43: Recognition in Context. Spring April il14 th, 2009
 CS294 43: Recognition in Context Prof. Trevor Darrell Spring 2009 April il14 th, 2009 Last Lecture Kernel Combination, Segmentation, and Structured Output M. Varma and D. Ray, "Learning the discriminative
CS294 43: Recognition in Context Prof. Trevor Darrell Spring 2009 April il14 th, 2009 Last Lecture Kernel Combination, Segmentation, and Structured Output M. Varma and D. Ray, "Learning the discriminative
Overview of section. Lecture 10 Discriminative models. Discriminative methods. Discriminative vs. generative. Discriminative methods.
 Overview of section Lecture 0 Discriminative models Object detection with classifiers Boosting Gentle boosting Object model Object detection Nearest-Neighbor methods Multiclass object detection Context
Overview of section Lecture 0 Discriminative models Object detection with classifiers Boosting Gentle boosting Object model Object detection Nearest-Neighbor methods Multiclass object detection Context
Texton Clustering for Local Classification using Scene-Context Scale
 Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Visual localization using global visual features and vanishing points
 Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Attributes and More Crowdsourcing
 Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Recovering the Spatial Layout of Cluttered Rooms
 Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Object recognition (part 2)
") Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Context by Region Ancestry
 Context by Region Ancestry Joseph J. Lim, Pablo Arbeláez, Chunhui Gu, and Jitendra Malik University of California, Berkeley - Berkeley, CA 94720 {lim,arbelaez,chunhui,malik}@eecs.berkeley.edu Abstract
Context by Region Ancestry Joseph J. Lim, Pablo Arbeláez, Chunhui Gu, and Jitendra Malik University of California, Berkeley - Berkeley, CA 94720 {lim,arbelaez,chunhui,malik}@eecs.berkeley.edu Abstract
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Decomposing a Scene into Geometric and Semantically Consistent Regions
 Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
Attributes. Computer Vision. James Hays. Many slides from Derek Hoiem
 Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Support surfaces prediction for indoor scene understanding
 2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
Using the forest to see the trees: exploiting context for visual object detection and localization
 Using the forest to see the trees: exploiting context for visual object detection and localization A. Torralba Massachusetts Institute of Technology 32 Vassar Cambridge, USA torralba@csail.mit.edu K. P.
Using the forest to see the trees: exploiting context for visual object detection and localization A. Torralba Massachusetts Institute of Technology 32 Vassar Cambridge, USA torralba@csail.mit.edu K. P.
CS4495/6495 Introduction to Computer Vision. 8C-L1 Classification: Discriminative models
 CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes
 A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes Qixing Huang Stanford University huangqx@stanford.edu Mei Han Google Inc. meihan@google.com Bo Wu Google
A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes Qixing Huang Stanford University huangqx@stanford.edu Mei Han Google Inc. meihan@google.com Bo Wu Google
24 hours of Photo Sharing. installation by Erik Kessels
 24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Single-view 3D reasoning
 Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Single Image Super-resolution. Slides from Libin Geoffrey Sun and James Hays
 Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Does everyone have an override code?
 Does everyone have an override code? Project 1 due Friday 9pm Review of Filtering Filtering in frequency domain Can be faster than filtering in spatial domain (for large filters) Can help understand effect
Does everyone have an override code? Project 1 due Friday 9pm Review of Filtering Filtering in frequency domain Can be faster than filtering in spatial domain (for large filters) Can help understand effect
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould 1 Tianshi Gao 1 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer Science, Stanford University
Region-based Segmentation and Object Detection Stephen Gould 1 Tianshi Gao 1 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer Science, Stanford University
Viewpoint Invariant Features from Single Images Using 3D Geometry
 Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Object Category Detection: Sliding Windows
 04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
Semantic Segmentation of Street-Side Images
 Semantic Segmentation of Street-Side Images Michal Recky 1, Franz Leberl 2 1 Institute for Computer Graphics and Vision Graz University of Technology recky@icg.tugraz.at 2 Institute for Computer Graphics
Semantic Segmentation of Street-Side Images Michal Recky 1, Franz Leberl 2 1 Institute for Computer Graphics and Vision Graz University of Technology recky@icg.tugraz.at 2 Institute for Computer Graphics
Visual words. Map high-dimensional descriptors to tokens/words by quantizing the feature space.
 Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Previously. Window-based models for generic object detection 4/11/2011
 Previously for generic object detection Monday, April 11 UT-Austin Instance recognition Local features: detection and description Local feature matching, scalable indexing Spatial verification Intro to
Previously for generic object detection Monday, April 11 UT-Austin Instance recognition Local features: detection and description Local feature matching, scalable indexing Spatial verification Intro to
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
3D layout propagation to improve object recognition in egocentric videos
 3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
Generic Object-Face detection
 Generic Object-Face detection Jana Kosecka Many slides adapted from P. Viola, K. Grauman, S. Lazebnik and many others Today Window-based generic object detection basic pipeline boosting classifiers face
Generic Object-Face detection Jana Kosecka Many slides adapted from P. Viola, K. Grauman, S. Lazebnik and many others Today Window-based generic object detection basic pipeline boosting classifiers face
Object Recognition and Segmentation in Indoor Scenes from RGB-D Images
 Object Recognition and Segmentation in Indoor Scenes from RGB-D Images Md. Alimoor Reza Department of Computer Science George Mason University mreza@masonlive.gmu.edu Jana Kosecka Department of Computer
Object Recognition and Segmentation in Indoor Scenes from RGB-D Images Md. Alimoor Reza Department of Computer Science George Mason University mreza@masonlive.gmu.edu Jana Kosecka Department of Computer
Context Based Object Categorization: A Critical Survey
 Context Based Object Categorization: A Critical Survey Carolina Galleguillos 1 Serge Belongie 1,2 1 Computer Science and Engineering, University of California, San Diego 2 Electrical Engineering, California
Context Based Object Categorization: A Critical Survey Carolina Galleguillos 1 Serge Belongie 1,2 1 Computer Science and Engineering, University of California, San Diego 2 Electrical Engineering, California
Shadows in the graphics pipeline
 Shadows in the graphics pipeline Steve Marschner Cornell University CS 569 Spring 2008, 19 February There are a number of visual cues that help let the viewer know about the 3D relationships between objects
Shadows in the graphics pipeline Steve Marschner Cornell University CS 569 Spring 2008, 19 February There are a number of visual cues that help let the viewer know about the 3D relationships between objects
Object detection as supervised classification
 Object detection as supervised classification Tues Nov 10 Kristen Grauman UT Austin Today Supervised classification Window-based generic object detection basic pipeline boosting classifiers face detection
Object detection as supervised classification Tues Nov 10 Kristen Grauman UT Austin Today Supervised classification Window-based generic object detection basic pipeline boosting classifiers face detection
Image Analysis. Window-based face detection: The Viola-Jones algorithm. iphoto decides that this is a face. It can be trained to recognize pets!
 Image Analysis 2 Face detection and recognition Window-based face detection: The Viola-Jones algorithm Christophoros Nikou cnikou@cs.uoi.gr Images taken from: D. Forsyth and J. Ponce. Computer Vision:
Image Analysis 2 Face detection and recognition Window-based face detection: The Viola-Jones algorithm Christophoros Nikou cnikou@cs.uoi.gr Images taken from: D. Forsyth and J. Ponce. Computer Vision:
Probabilistic Graphical Models Part III: Example Applications
 Probabilistic Graphical Models Part III: Example Applications Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2014 CS 551, Fall 2014 c 2014, Selim
Probabilistic Graphical Models Part III: Example Applications Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2014 CS 551, Fall 2014 c 2014, Selim
CS 1674: Intro to Computer Vision. Attributes. Prof. Adriana Kovashka University of Pittsburgh November 2, 2016
 CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
CS5670: Intro to Computer Vision
 CS5670: Intro to Computer Vision Noah Snavely Introduction to Recognition mountain tree banner building street lamp people vendor Announcements Final exam, in-class, last day of lecture (5/9/2018, 12:30
CS5670: Intro to Computer Vision Noah Snavely Introduction to Recognition mountain tree banner building street lamp people vendor Announcements Final exam, in-class, last day of lecture (5/9/2018, 12:30
3dRR: Representation and Recognition
 CS331B (3 units) 3dRR: Representation and Recognition Instructor: Silvio Savarese Email: ssilvio@stanford.edu Office: Gates, room: 228 Office hour: by appointment TA: Scott Chung scottc52@gmail.com Class
CS331B (3 units) 3dRR: Representation and Recognition Instructor: Silvio Savarese Email: ssilvio@stanford.edu Office: Gates, room: 228 Office hour: by appointment TA: Scott Chung scottc52@gmail.com Class
Bayes Risk. Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Discriminative vs Generative Models. Loss functions in classifiers
 Discriminative vs Generative Models. Loss functions in classifiers") Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Example: A Classification Problem Categorize
Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Example: A Classification Problem Categorize
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Modeling Image Context using Object Centered Grid
 Modeling Image Context using Object Centered Grid Sobhan Naderi Parizi, Ivan Laptev, Alireza Tavakoli Targhi Computer Vision and Active Perception Laboratory Royal Institute of Technology (KTH) SE-100
Modeling Image Context using Object Centered Grid Sobhan Naderi Parizi, Ivan Laptev, Alireza Tavakoli Targhi Computer Vision and Active Perception Laboratory Royal Institute of Technology (KTH) SE-100
Object Detection System
 A Trainable View-Based Object Detection System Thesis Proposal Henry A. Rowley Thesis Committee: Takeo Kanade, Chair Shumeet Baluja Dean Pomerleau Manuela Veloso Tomaso Poggio, MIT Motivation Object detection
A Trainable View-Based Object Detection System Thesis Proposal Henry A. Rowley Thesis Committee: Takeo Kanade, Chair Shumeet Baluja Dean Pomerleau Manuela Veloso Tomaso Poggio, MIT Motivation Object detection
Understanding Faces. Detection, Recognition, and. Transformation of Faces 12/5/17
 Understanding Faces Detection, Recognition, and 12/5/17 Transformation of Faces Lucas by Chuck Close Chuck Close, self portrait Some slides from Amin Sadeghi, Lana Lazebnik, Silvio Savarese, Fei-Fei Li
Understanding Faces Detection, Recognition, and 12/5/17 Transformation of Faces Lucas by Chuck Close Chuck Close, self portrait Some slides from Amin Sadeghi, Lana Lazebnik, Silvio Savarese, Fei-Fei Li
Object Detection Using Cascaded Classification Models
 Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Classifiers for Recognition Reading: Chapter 22 (skip 22.3)
") Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Slide credits for this chapter: Frank
Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Slide credits for this chapter: Frank
Single-view metrology
 Single-view metrology Magritte, Personal Values, 952 Many slides from S. Seitz, D. Hoiem Camera calibration revisited What if world coordinates of reference 3D points are not known? We can use scene features
Single-view metrology Magritte, Personal Values, 952 Many slides from S. Seitz, D. Hoiem Camera calibration revisited What if world coordinates of reference 3D points are not known? We can use scene features
Unsupervised discovery of category and object models. The task
 Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Context Based Object Categorization: A Critical Survey
 Context Based Object Categorization: A Critical Survey Carolina Galleguillos a Serge Belongie a,b a University of California San Diego, Department of Computer Science and Engineering, La Jolla, CA 92093
Context Based Object Categorization: A Critical Survey Carolina Galleguillos a Serge Belongie a,b a University of California San Diego, Department of Computer Science and Engineering, La Jolla, CA 92093
Today. Introduction to recognition Alignment based approaches 11/4/2008
 Today Introduction to recognition Alignment based approaches Tuesday, Nov 4 Brief recap of visual words Introduction to recognition problem Recognition by alignment, pose clustering Kristen Grauman UT
Today Introduction to recognition Alignment based approaches Tuesday, Nov 4 Brief recap of visual words Introduction to recognition problem Recognition by alignment, pose clustering Kristen Grauman UT
Interpreting 3D Scenes Using Object-level Constraints
 Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels
 SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation
 Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Contextual Classification with Functional Max-Margin Markov Networks
 Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
Recognizing and Learning Object Categories. Li Fei-Fei, Stanford Rob Fergus, NYU Antonio Torralba, MIT
 Recognizing and Learning Object Categories Li Fei-Fei, Stanford Rob Fergus, NYU Antonio Torralba, MIT Outline 2. Single object categories - Bag of words - Part-based - Discriminative - Detecting single
Recognizing and Learning Object Categories Li Fei-Fei, Stanford Rob Fergus, NYU Antonio Torralba, MIT Outline 2. Single object categories - Bag of words - Part-based - Discriminative - Detecting single
From 3D Scene Geometry to Human Workspace
 From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CEng Computational Vision
 CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
Computer Vision: Summary and Discussion
 12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
Face Detection. Raghuraman Gopalan AT&T Labs-Research, Middletown NJ USA
 Face Detection Raghuraman Gopalan AT&T Labs-Research, Middletown NJ USA Book chapter collaborators: William Schwartz (University of Campinas, Brazil), Rama Chellappa and Ankur Srivastava (University of
Face Detection Raghuraman Gopalan AT&T Labs-Research, Middletown NJ USA Book chapter collaborators: William Schwartz (University of Campinas, Brazil), Rama Chellappa and Ankur Srivastava (University of
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
CV as making bank. Intel buys Mobileye! $15 billion. Mobileye:
 CV as making bank Intel buys Mobileye! $15 billion Mobileye: Spin-off from Hebrew University, Israel 450 engineers 15 million cars installed 313 car models June 2016 - Tesla left Mobileye Fatal crash car
CV as making bank Intel buys Mobileye! $15 billion Mobileye: Spin-off from Hebrew University, Israel 450 engineers 15 million cars installed 313 car models June 2016 - Tesla left Mobileye Fatal crash car
Scenes vs. Objects: a Comparative Study of Two Approaches to Context Based Recognition
 Scenes vs. Objects: a Comparative Study of Two Approaches to Context Based Recognition Andrew Rabinovich Google Inc. amrabino@google.com Serge Belongie University of California, San Diego sjb@cs.ucsd.edu
Scenes vs. Objects: a Comparative Study of Two Approaches to Context Based Recognition Andrew Rabinovich Google Inc. amrabino@google.com Serge Belongie University of California, San Diego sjb@cs.ucsd.edu
A Framework for Encoding Object-level Image Priors
 Microsoft Research Technical Report MSR-TR-2011-99 A Framework for Encoding Object-level Image Priors Jenny Yuen 1 C. Lawrence Zitnick 2 Ce Liu 2 Antonio Torralba 1 {jenny, torralba}@csail.mit.edu {larryz,
Microsoft Research Technical Report MSR-TR-2011-99 A Framework for Encoding Object-level Image Priors Jenny Yuen 1 C. Lawrence Zitnick 2 Ce Liu 2 Antonio Torralba 1 {jenny, torralba}@csail.mit.edu {larryz,
Scene Modeling for a Single View
 on to 3D Scene Modeling for a Single View We want real 3D scene walk-throughs: rotation translation Can we do it from a single photograph? Reading: A. Criminisi, I. Reid and A. Zisserman, Single View Metrology
on to 3D Scene Modeling for a Single View We want real 3D scene walk-throughs: rotation translation Can we do it from a single photograph? Reading: A. Criminisi, I. Reid and A. Zisserman, Single View Metrology
Filters (cont.) CS 554 Computer Vision Pinar Duygulu Bilkent University
 CS 554 Computer Vision Pinar Duygulu Bilkent University") Filters (cont.) CS 554 Computer Vision Pinar Duygulu Bilkent University Today s topics Image Formation Image filters in spatial domain Filter is a mathematical operation of a grid of numbers Smoothing,
Filters (cont.) CS 554 Computer Vision Pinar Duygulu Bilkent University Today s topics Image Formation Image filters in spatial domain Filter is a mathematical operation of a grid of numbers Smoothing,
Categorization by Learning and Combining Object Parts
 Categorization by Learning and Combining Object Parts Bernd Heisele yz Thomas Serre y Massimiliano Pontil x Thomas Vetter Λ Tomaso Poggio y y Center for Biological and Computational Learning, M.I.T., Cambridge,
Categorization by Learning and Combining Object Parts Bernd Heisele yz Thomas Serre y Massimiliano Pontil x Thomas Vetter Λ Tomaso Poggio y y Center for Biological and Computational Learning, M.I.T., Cambridge,
Local Image Features
 Local Image Features Computer Vision Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Flashed Face Distortion 2nd Place in the 8th Annual Best
Local Image Features Computer Vision Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Flashed Face Distortion 2nd Place in the 8th Annual Best
Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes
 Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes Kevin Murphy MIT AI lab Cambridge, MA 239 murphyk@ai.mit.edu Antonio Torralba MIT AI lab Cambridge, MA 239 torralba@ai.mit.edu
Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes Kevin Murphy MIT AI lab Cambridge, MA 239 murphyk@ai.mit.edu Antonio Torralba MIT AI lab Cambridge, MA 239 torralba@ai.mit.edu
Unsupervised Patch-based Context from Millions of Images
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Opportunities of Scale
 Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven