arxiv: v3 [cs.cv] 23 Aug 2016
|
|
|
- Victor Singleton
- 5 years ago
- Views:
Transcription


![[5], play an essential role in improving the state-of-the-art. Despite their effectiveness on still images, those frameworks are not specifically designed for object detection from videos.](/docs-images/93/114513288/images/1-3.jpg "Temporal and contextual information of videos are not fully investigated and utilized.")


![1 I NTRODUCTION F In the last two years, the performance of object detection has been significantly improved with the success of novel deep convolutional neural networks (CNN) [1], [2], [6], [7] and](/docs-images/93/114513288/images/1-6.jpg "object detection frameworks [3], [4], [5], [8].")
![The stateof-the-art frameworks for object detection such as R-CNN [3] and its successors [4], [5] extract deep convolutional features from region proposals and classify the proposals into different](/docs-images/93/114513288/images/1-7.jpg "classes. DeepID-Net [8] improved R-CNN by introducing box pre-training, cascade on region proposals, deformation layers and context representations.")



 Detection Confidences Video (b) Detected Classes Turtle Turtle Fig. 1. Limitations of still-image detectors on videos.")
 Still-image detectors may generate false positives solely based the information on single frames, while these false positives can be distinguished considering the context information of the whole")
1 1 T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos arxiv: v3 [cs.cv] 23 Aug 2016 Kai Kang, Hongsheng Li, Junjie Yan, Xingyu Zeng, Bin Yang, Tong Xiao, Cong Zhang, Zhe Wang, Ruohui Wang, Xiaogang Wang, and Wanli Ouyang Abstract The state-of-the-art performance for object detection has been significantly improved over the past two years. Besides the introduction of powerful deep neural networks such as GoogleNet [1] and VGG [2], novel object detection frameworks such as R-CNN [3] and its successors, Fast R-CNN [4] and Faster R-CNN [5], play an essential role in improving the state-of-the-art. Despite their effectiveness on still images, those frameworks are not specifically designed for object detection from videos. Temporal and contextual information of videos are not fully investigated and utilized. In this work, we propose a deep learning framework that incorporates temporal and contextual information from tubelets obtained in videos, which dramatically improves the baseline performance of existing still-image detection frameworks when they are applied to videos. It is called T-CNN, i.e. tubelets with convolutional neueral networks. The proposed framework won the recently introduced object-detection-from-video (VID) task with provided data in the ImageNet Large-Scale Visual Recognition Challenge 2015 (ILSVRC2015). Code is publicly available at 1 I NTRODUCTION F In the last two years, the performance of object detection has been significantly improved with the success of novel deep convolutional neural networks (CNN) [1], [2], [6], [7] and object detection frameworks [3], [4], [5], [8]. The stateof-the-art frameworks for object detection such as R-CNN [3] and its successors [4], [5] extract deep convolutional features from region proposals and classify the proposals into different classes. DeepID-Net [8] improved R-CNN by introducing box pre-training, cascade on region proposals, deformation layers and context representations. Recently, ImageNet introduces a new challenge for object detection from videos (VID), which brings object detection into the video domain. In this challenge, an object detection system is required to automatically annotate every object in 30 classes with its bounding box and class label in each frame of the videos, while test videos have no extra information pre-assigned, such as user tags. VID has a broad range of applications on video analysis. Despite their effectiveness on still images, these stillimage object detection frameworks are not specifically designed for videos. One key element of videos is temporal information, because locations and appearances of objects in videos should be temporally consistent, i.e. the detection results should not have dramatic changes over time in terms of both bounding box locations and detection confi Kai Kang and Hongsheng Li share co-first authorship. Wanli Ouyang is the corresponding author. wlouyang@ee.cuhk.edu.hk Kai Kang, Hongsheng Li, Xingyu Zeng, Tong Xiao, Cong Zhang, Zhe Wang, Ruohui Wang, Xiaogang Wang, and Wanli Ouyang are with The Chinese University of Hong Kong. Junjie Yan and Bin Yang are with the SenseTime Group Limited. Video (a) Detection Confidences Video (b) Detected Classes Turtle Turtle Fig. 1. Limitations of still-image detectors on videos. (a) Detections from still-image detectors contain large temporal fluctuations, because they do not incorporate temporal consistency and constraints. (b) Still-image detectors may generate false positives solely based the information on single frames, while these false positives can be distinguished considering the context information of the whole video. dences. However, if still-image object detection frameworks are directly applied to videos, the detection confidences of an object show dramatic changes between adjacent frames and large long-term temporal variations, as shown by an example in Fig. 1 (a). One intuition to improve temporal consistency is to propagate detection results to neighbor frames to reduce sudden changes of detection results. If an object exists in a certain frame, the adjacent frames are likely to contain the same object at neighboring locations with similar confidence. In other words, detection results can be propagated to adjacent frames according to motion information so as to reduce missed detections. The resulted duplicate boxes can be easily removed by non-maximum suppression (NMS). Another intuition to improve temporal consistency is to impose long-term constraints on the detection results. As shown in Fig. 1 (a), the detection scores of a sequence of bounding boxes of an object have large fluctuations over time. These box sequences, or tubelets, can be generated by tracking and spatio-temporal object proposal algorithms [9]. A tubelet can be treated as a unit to apply the longterm constraint. Low detection confidence on some positive bounding boxes may result from moving blur, bad poses, or lack of enough training samples under particular poses. Therefore, if most bounding boxes of a tubelet have high confidence detection scores, the low confidence scores at certain frames should be increased to enforce its long-term consistency. Besides temporal information, contextual information is also a key element of videos compared with still images. Although image context information has been investigated [8] and incorporated into still-image detection frameworks, a video, as a collection of hundreds of images, has much richer contextual information. As shown in Fig. 1 (b), a small amount of frames in a video may have high confidence false positives on some background objects. Contextual information within a single frame is sometimes not enough to distinguish these false positives. However, considering the majority of high-confidence detection results within a video clip, the false positives can be treated as outliers and then their detection confidences can be suppressed. The contribution of this works is three-folded. 1) We propose a deep learning framework that extends popular stillimage detection frameworks (R-CNN and Faster R-CNN) to solve the problem of general object detection in videos
2 2 by incorporating temporal and contextual information from tubelets. It is called T-CNN, i.e. tubelets with convolution neural network. 2) Temporal information is effectively incorporated into the proposed detection framework by locally propagating detection results across adjacent frames as well as globally revising detection confidences along tubelets generated from tracking algorithms. 3) Contextual information is utilized to suppress detection scores of lowconfidence classes based on all detection results within a video clip. This framework is responsible for winning the VID task with provided data and achieving the second place with external data in ImageNet Large-Scale Visual Recognition Challenge 2015 (ILSVRC2015). Code is available at 2 RELATED WORK Object detection from still images. State-of-the-art methods for detecting objects of general classes are mainly based on deep CNNs [1], [3], [4], [5], [8], [10], [11], [12], [13], [14], [15], [16], [17]. Girshick et al. [3] proposed a multi-stage pipeline called Regions with Convolutional Neural Networks (R- CNN) for training deep CNN to classify region proposals for object detection. It decomposed the detection problem into several stages including bounding-box proposal, CNN pre-training, CNN fine-tuning, SVM training, and bounding box regression. Such framework showed good performance and was widely adopted in other works. Szegedy et al. [1] proposed the GoogLeNet with a 22-layer structure and inception modules to replace the CNN in the R-CNN, which won the ILSVRC 2014 object detection task. Ouyang et al. [8] proposed a deformation constrained pooling layer and a box pre-training strategy, which achieved an accuracy of 50.3% on the ILSVRC 2014 test set. To accelerate the training of the R-CNN pipeline, Fast R-CNN [4] was proposed, where each image patch was no longer wrapped to a fixed size before being fed into CNN. Instead, the corresponding features were cropped from the output feature maps of the last convolutional layer. In the Faster R-CNN pipeline [5], the region proposals were generated by a Region Proposal Network (RPN), and the overall framework can thus be trained in an end-to-end manner. All these pipelines were for object detection from still images. When they are directly applied to videos in a frame-by-frame manner, they might miss some positive samples because objects might not be of their best poses at certain frames of videos. Object localization in videos. There have also been works on object localization and co-localization [18], [19], [20], [21]. Although such a task seems to be similar, the VID task we focus on is actually much more challenging. There are crucial differences between the two problems. 1) Goal: The (co)locolization problem assumes that each video contains only one known (weakly supervised setting) or unknown (unsupervised setting) class and only requires localizing one of the objects in each test frame. In VID, however, each video frame contains unknown numbers of objects instances and classes. The VID task is closer to real-world applications. 2) Metrics: Localization metric (CorLoc [22]) is usually used for evaluation in (co)locolization, while mean average precision (mean AP) is used for evaluation on the VID task. With the above differences, we think that the VID task is more difficult and closer to real-world scenarios. The previous works on object (co)localization in videos cannot be directly applied to VID. Image classification. The performance of image classification has been significantly improved during the past few years thanks to the large scale datasets [23] and novel deep neural networks [1], [2], [6], [24]. The models for object detection are commonly pre-trained on the ImageNet 1000-class classification task. Batch normalization layer was proposed in [7] to reduce the statistical variations among mini batches and accelerate the training process. Simonyan et al. proposed a 19-layer neural network with very small 3 3 convolution kernels in [2], which was proved effective in other related tasks such as detection [4], [5], action recognition [25], and semantic segmentation [26]. Visual tracking. Object tracking has been studied for decades [27], [28], [29]. Recently, deep CNNs have been used for object tracking and achieved impressive tracking accuracy. Wang et al. [30] proposed to create an object-specific tracker by online selecting the most influential features from an ImageNet pre-trained CNN, which outperforms state-ofthe-art trackers by a large margin. Nam et al. [31] trained a multi-domain CNN for learning generic representations for tracking objects. When tracking a new target, a new network is created by combining the shared layers in the pre-trained CNN with a new binary classification layer, which is online updated. Tracking is apparently different from VID, since it assumes the initial localization of an object in the first frame and it does not require predicting class labels. 3 METHODS In this section, we first introduce the VID task setting (Section 3.1) and our overall framework (Section 3.2). Then each major component will be introduced in more details. Section 3.3 describes the settings of our still-image detectors. Section 3.4 introduces how to utilize multi-context information to suppress false positive detections and utilize motion information to reduce false negatives. Global tubelet rescoring is introduced in Section VID task setting The ImageNet object detection from video (VID) task is similar to the object detection task (DET) in still images. It contains 30 classes to be detected, which are a subset of 200 classes of the DET task. All classes are fully labeled in all the frames of each video clip. For each video clip, algorithms need to produce a set of annotations (f i, c i, s i, b i ) of frame index f i, class label c i, confidence score s i and bounding box b i. The evaluation protocol for the VID task is the same as the DET task, i.e. we use the conventional mean average precision (mean AP) on all classes as the evaluation metric. 3.2 Framework overview The proposed framework is shown in Fig. 2. It consists of four main components: 1) still-image detection, 2) multicontext suppression and motion-guided propagation, 3) temporal tubelet re-scoring, and 4) model combination. Still-image object detection. Our still-image object detectors adopt the DeepID-Net [8] and CRAFT [32] frameworks
3 3 Still-image Detection Multi-context Suppression and Motion-guided Propagation Model Combination Object Proposal Multi-context Suppression Motion-guided Propagation Proposal Combination Proposal Scoring Score Average Highconfidence Tracking Spatial Maxpooling Temporal Re-scoring Non-Maximum Suppression Tubelet Re-scoring Fig. 2. Our proposed T-CNN framework. The framework mainly consists of four components. 1) The still-image object detection component generates object region proposals in all the frames in a video clip and assigns each region proposal an initial detection score. 2) The multi-context suppression incorporates context information to suppress false positives and motion-guided propagation component utilizes motion information to propagate detection results to adjacent frames to reduce false negatives. 3) The tubelet re-scoring components utilizes tracking to obtain long bounding box sequences to enforce long-term temporal consistency of their detection scores. 4) The model combination component combines different groups of proposals and different models to generate the final results. and are trained with both ImageNet detection (DET) and video (VID) training datasets in ILSVRC DeepID-Net [8] is an extension of R-CNN [3] and CRAFT is an extension of Faster R-CNN [5]. Both of the two frameworks contain the steps of object region proposal and region proposal scoring. The major difference is that in CRAFT (also Faster R-CNN), the proposal generation and classification are combined into a single end-to-end network. Still-image object detectors are applied to individual frames. The results from the two stillimage object detection frameworks are treated separately for the remaining components in the proposed T-CNN framework. Multi-context suppression. This process first sorts all stillimage detection scores within a video in descending orders. The classes with highly ranked detection scores are treated as high-confidence classes and the rest as low-confidence ones. The detection scores of low-confidence classes are suppressed to reduce false positives. Motion-guided Propagation. In still-image object detection, some objects may be missed in certain frames while detected in adjacent frames. Motion-guided propagation uses motion information such as optical flows to locally propagate detection results to adjacent frames to reduce false negatives. Temporal tubelet re-scoring. Starting from high-confidence detections by still-image detectors, we first run tracking algorithms to obtain sequences of bounding boxes, which we call tubelets. Tubelets are then classified into positive and negative samples according to the statistics of their detection scores. Positive scores are mapped to a higher range while negative ones to a lower range, thus increasing the score margins. Model combination. For each of the two groups of proposals from DeepID-Net and CRAFT, their detection results from both tubelet re-scoring and the motion-guided propagation are each min-max mapped to [0, 1] and combined by an NMS process with an IOU overlap 0.5 to obtain the final results. 3.3 Still-image object detectors Our still-image object detectors are adopted from DeepID- Net [8] and CRAFT [32]. The two detectors have different region proposal methods, pre-trained models and training strategies DeepID-Net Object region proposals. For DeepID-Net, the object region proposals are obtained by selective search (SS) [33] and Edge Boxes (EB) [34] with a cascaded selection process that eliminates easy false positive boxes using an ImageNet pretrained AlexNet [24] model. All proposal boxes are then labeled with 200 ImageNet detection class scores by the pre-trained AlexNet. The boxes whose maximum prediction scores of all 200 classes are lower than a threshold are regarded as easy negative samples and are eliminated. The process removes around 94% of all proposal boxes while obtains a recall around 90%.
 For the provided data track, one can use data and annotations from all ILSVRC 2015 datasets including classification and localization (CLS), DET, VID")
 [7] using the CLS 1000-class data, while for the")





 stream to generated object proposals and the Fast-RCNN stream which further assigns a class (including")




 and motionguided propagation (MGP) Multi-context suppression (MCS).")

.")




4 4 Pre-trained models. ILSVRC 2015 has two tracks for each task. 1) For the provided data track, one can use data and annotations from all ILSVRC 2015 datasets including classification and localization (CLS), DET, VID and Places2. 2) For the external data track, one can use additional data and annotations. For the provided data track, we pretrained VGG [2] and GoogLeNet [1] with batch normalization (BN) [7] using the CLS 1000-class data, while for the external data track, we used the ImageNet 3000-class data. Pre-training is done at the object-level annotation as in [8] instead of image-level annotation in R-CNN [3]. Model finetuning and SVM training. Since the classes in VID are a subset of DET classes, the DET pretained networks and SVM can be directly applied to the VID task, with correct class index mapping. However, due to the mismatch of the DET and VID data distributions and the unique statistics in videos, the DET-trained models may not be optimal for the VID task. Therefore, we finetuned the networks and re-trained the 30 SVMs with combination of DET and VID data. Different combination configurations are investigated and a 2 : 1 DET to VID data ratio achieves the best performance (see Section 4.2). Score average. Multiple CNN and SVM models are trained separately for the DeepID-Net framework, their results are averaged to generate the detection scores. Such score averaging process is conducted in a greedy searching manner. The best single model is first chosen. Then for each of the remaining models, its detection scores are averaged with those of the chosen model, and the model with best performance is chosen as the second chosen model. The process repeats until no significant improvement is observed CRAFT CRAFT is an extension of Faster R-CNN. It contains the Region Proposal Network (RPN) stream to generated object proposals and the Fast-RCNN stream which further assigns a class (including background) score to each proposal. Object region proposals. In this framework, we use the enhanced version of Faster-RCNN by cascade RPN and cascade Fast-RCNN. In our cascaded version of RPN, the proposals generated by the RPN are further fed into a object/background Fast-RCNN. We find that it leads to a 93% recall rate with about 100 proposals per image. In our cascade version of the Fast-RCNN, we further use a classwise softmax loss as the cascaded step. It is utilized for hard negative mining and leads to about 2% improvement in mean AP. Pretrained models. Similar to the DeepID-Net setting, the pretrained models are the VGG and GoogLeNet with batch normalization. We only use the VGG in the RPN step and use both models in the later Fast-RCNN classification step. Score average. The same greedy searching is conducted for model averaging as the DeepID-Net framework. 3.4 Multi-context suppression (MCS) and motionguided propagation (MGP) Multi-context suppression (MCS). One limitation of directly applying still-image object detectors to videos is that Monkey, Domestic cat Others Car Others Domestic cat Others Bicycle Others Fig. 3. Multi-context suppression. For each video, the classes with top detection confidences are regarded as the high-confidence classes (green arrows) and others are regarded as low-confidence ones (red arrows). The detection scores of high-confidence classes are kept the same, while those of low-confidence ones are decreased to suppress false positives. they ignore the context information within a video clip. The detection results in each frame of a video should be strongly correlated and we can use such property to suppress false positive detections. We observed that although video snippets in the VID dataset may contain arbitrary number of classes, statistically each video usually contains only a few classes and co-existing classes have correlations. Statistics of all detections within a video can therefore help distinguish false positives. For example in Fig. 3, in some frames from a video clip, some false positive detections have very large detection scores. Only using the context information within these frames cannot distinguish them from the positive samples. However, considering the detection results on other frames, we can easily determine that the majority of high-confidence detections are other classes and these positive detections are outliers. For each frame, we have about a few hundred region proposals, each of which has detection scores of 30 classes. For each video clip, we rank all detection scores on all boxes in a descending order. The classes of detection scores beyond a threshold are regarded as high-confidence classes and the rest as low-confidence classes. The detection scores of the high-confidence classes are kept the same, while those of the low-confidence classes are suppressed by subtracting a certain value. The threshold and subtracted value are greedily searched on the validation set. Motion-guided propagation (MGP). The multi-context suppression process can significantly reduce false positive detections, but cannot recover false negatives. The false negatives are typically caused by several reasons. 1) There are no region proposals covering enough areas of the objects; 2) Due to bad pose or motion blur of an object, its detection scores are low. These false negatives can be recovered by adding more detections from adjacent frames, because the adjacent frames are highly correlated, the detection results should also have high correlations both in spatial locations and detection scores. For example, if an object is still or moves at a low speed, it should appear at similar locations in adjacent frames. This inspires us to propagate boxes and their scores of each frame to its adjacent frame to augment detections and reduce false negatives. We propose a motion-guided approach to propagate
5 5 (a) Before Propagation (b) After Propagation t=t-1 t=t t=t+1 Fig. 4. Motion-guided propagation. Before the propagation, some frames may contain false negatives (e.g. some airplanes are missing in (a)). Motion-guided propagation is to propagate detections to adjacent frames (e.g. from t = T to t = T 1 and t = T + 1) according to the mean optical flow vector of each detection bounding box. After propagation, fewer false negatives exist in (b). Count Top-k Negative tubelets Positive tubelets Fig. 5. Tubelet classification. Tubelets obtained from tracking can be classified into positive and negative samples using statistics (e.g. topk, mean, median) of the detection scores on the tubelets. Based on the statistics on the training set, a 1-D Bayesian classifier is trained to classify the tubelets for re-scoring. detection bounding boxes according to the motion information. For each region proposal, we calculate the mean optical flow vector within the bounding box of the region proposal and propagate the box coordinate with same detection score to adjacent frames according the mean flow vectors. An illustration example is shown in Fig Tubelet re-scoring MGP generates short dense tubelets at every detection by our still-image detectors. It significantly reduces false negatives but only incorporates short-term temporal constraints and consistency to the final detection results. To enforce long-term temporal consistency of the results, we also need tubelets that span long periods of time. Therefore, we use tracking algorithms to generate long tubelets and associate still-image object detections around tubelets. As shown in Fig. 2, the tubelet re-scoring includes three sub-steps: 1) high confidence tracking, 2) spatial maxpooling, and 3) tubelet classification. High-confidence tracking. For each object class in a video clip, we track high-confidence detection proposals bidirectionally over the temporal dimensions. The tracker we choose is from [30], which in our experiments shows robust performance to different object poses and scale changes. The starting bounding boxes of tracking are called anchors, which are determined as the most confident detections. Starting from an anchor, we track biredictionally to obtain a complete tubelet. As the tracking is conducted along the temporal dimension, the tracked box may drift to background or other objects, or may not adapt to the scale and pose changes of the target object. Therefore, we stop the tracking early when the tracking confidence is below a threshold (probability of 0.1 in our experiments) to reduce false positive tubelets. After obtaining a tubelet, a new anchor is selected from the remaining detections to start a new track. Usually, high-confidence detections tend to cluster both spatially and temporally, and therefore directly tracking the next most confident detection tends to result in tubelets with large mutual overlaps on the same object. To reduce the redundancy and cover as many objects as possible, we perform a suppression process similar to NMS. Detections that have overlaps with the existing tracks beyond a certain threshold (IOU, i.e. Intersection of Union, 0.3 in our experiment) will not be chosen as new anchors. The tracking-suppression process performs iteratively until confidence values of all remaining detections are lower than a threshold. For each video clip, such tracking process is performed for each of the 30 VID classes. Spatial max-pooling. After tracking, for each class, we have tubelets with high-confidence anchors. A naive approach is to classify each bounding box on the tubelets using stillimage object detectors. Since the boxes from tracked tubelets and those from still-image object detectors have different statistics, when a still-image object detector is applied to a bounding box obtained from tracking, the detection score many not be accurate. In addition, the tracked box locations may not be optimal due to the tracking failures. Therefore, the still-image detection scores on the tracked tubelets may not be reliable. However, the detections spatially close to the tubelets can provide helpful information. The spatial max-pooling process is to replace tubelet box proposals with detections of higher confidence by the still-image object detector. For each tubelet box, we first obtain the detections from still-image object detectors that have overlaps with the box beyond a threshold (IOU 0.5 in our setting). Then only the detection with the maximum detection score is kept and used to replace the tracked bounding box. This process is to simulate the conventional NMS process in object detection. If the tubelet box is indeed a positive box but with low detection score, this process can raise its detection score. The higher the overlap threshold, the more trust on the tubelet box. In an extreme case when IOU = 1 is chosen as the threshold, we fully rely on the tubelet boxes while their surrounding boxes from still-image object detectors are not considered. Tubelet classification and rescoring. High-confidence tracking and spatial max-pooling generate long sparse tubelets that become candidates for temporal rescoring. The main idea of temporal rescoring is to classify tubelets into positive and negative samples and map the detection scores into different ranges to increase the score margins. Since the input only contains the original detection scores, the features for tubelet classification should also be simple. We tried different statistics of tubelet detection scores such as mean, median and top-k (i.e. the kth largest detection score from a tubelet). A Bayesian classifier is
6 6 TABLE 1 Performances of the still-image object detector DeepID-Net single model by using different finetuning data configurations on the initial validation set. The baseline DeepID-Net of only using the DET training data has the mean AP DET:VID Ratio 1:0 3:1 2:1 1:1 1:3 Mean AP / % TABLE 2 Performances of the still-image object detector CRAFT single model by using different finetuning data configurations on the final validation set. DET:VID Ratio 0:1 2:1 Mean AP / % trained to classify the tubelets based on the statistics as shown in Fig. 5, and in our experiment, the top-k feature works best. After classification, the detection scores of positive samples are min-max mapped to [0.5, 1], while negatives to [0, 0.5]. Thus, the tubelet detection scores are globally changed so that the margin between positive and negative tubelets is increased. 4 EXPERIMENTS 4.1 Dataset 1) The training set contains 3862 fully-annotated video snippets ranging from 6 frames to 5492 frames per snippet. 2) The validation set contains 555 fully-annotated video snippets ranging from 11 frames to 2898 frame per snippet. 3) The test set contains 937 snippets and the ground truth annotation are not publicly released. Since the official test server is primarily used for competition and has usage limitations, we primarily report the performances on the validation set as a common convention for object detection tasks. In the end, test results from topranked teams participated in ILSVRC 2015 are reported. 4.2 Parameter Settings Data configuration. We investigated the ratio of training data combination from the DET and VID training sets, and its influence on the still-image object detector DeepID-Net. The best data configuration is then used for both DeepID- Net and CRAFT. Because the VID training set has many more fully annotated frames than the DET training set, we kept all the DET images and sampled the training frames in VID for different combination ratios in order to training the still-image object detectors. We investigated several training data configurations by finetuning a GoogLeNet with BN layers. From the Table 1 and 2, we can see that the ratio of 2 : 1 between DET and VID data has the best performance on the still-image detector DeepID-Net and CRAFT single models, therefore, we finetuned all of our models using this data configuration. In addition to model finetuning, we also investigated the data configurations for training the SVMs in DeepID-Net. The performances are shown in Table 3, which show that using positive and negative samples from both DET and VID data leads to the best performance. TABLE 3 Performances of different data configurations on the validation set for training SVMs in DeepID-Net. Baseline (the first column) only uses DET positive and negative samples and the result is a mean AP of DET Positive VID Positive DET Negative VID Negative mean AP / % TABLE 4 Performances on the validation set by different temporal window sizes of MGP. Temporal window size Methods 1 (baseline) Duplicate Motion-guided Because of the redundancy among video frames, we also sampled the video frames by a factor of 2 during testing and applied the still-image detectors to the remaining frames. The MCS, MGP and re-scoring steps in Section 3.4 and 3.5 are then conducted. The detection boxes on the unsampled frames are generated by interpolation and MGP. We did not observe significant performance differences with frame sampling on the validation set. To conclude, we sampled VID frames to half the amount of DET images and combined the samples to finetune the CNN models in both DeepID-Net and CRAFT. Positive and negative samples from both DET and VID images are used to train SVMs in DeepID-Net. Hyperparameter settings. For motion-guided propagations, as described in Section 3.4, Table 4 shows the performances of different propagation window sizes. Compared to directly duplicating boxes to adjacent frames without changing their locations according to optical flow vectors, MGP has better performances with the same propagation durations, which proves that MGP generates detections with more accurate locations. 7 frames (3 frames forward and 3 backward) are empirically set as the window size. In multi-context suppression, classes in the top of all the bounding boxes in a video are regarded as highconfidence classes and the detection scores for both frameworks are subtracted by 0.4. Those hyperparameters are greedily searched in the validation set. Network configurations. The models in DeepID-Net and CRAFT are mainly based on GoogLeNet with batchnormalization layers and VGG models. The techniques of multi-scale [35] and multi-region [13] are used to further increase the number of models for score averaging in the stillimage object detection shown in Fig. 2. The performance of a baseline DeepID-Net trained on ImageNet DET task can be increased from 49.8 to 70.7 with all the above-mentioned techniques (data configuration for finetuning, multi-scale, multi-region, score average, etc.). 4.3 Results Qualitative results. Some qualitative results of our proposed framework are shown in Fig. 6. From the figure, we
7 7 TABLE 5 Performances of individual components, frameworks and our overall system. Data Model Still-image MCS+MGP Model Rank in Test Set +Rescoring Combination ILSVRC2015 #win Provided CRAFT [32] DeepID-net [8] #1 28/30 Additional CRAFT [32] DeepID-net [8] #2 11/30 TABLE 6 Performaces of our submitted models on the validation set. Method Provided Additional airplane antelope bear bicycle bird bus car cattle Method Provided /30 Additional /30 lizard monkey motorcycle rabbit r panda sheep snake squirrel dog tiger d cat train turtle elephant fox watercraft g panda whale hamster zebra horse mean AP lion #win can see the following characteristics of our proposed framework. 1) The bounding boxes are very tight to the objects, which results from the high-quality bonding box proposals combined from Selective Search, Edge Boxes and Regionproposal Networks. 2) The detections are consistent across adjacent frames without obvious false negatives thanks to the motion-guided propagation and tracking. 3) There are no obvious false positives even though the scenes may be complex (e.g. cases in the third row), because the multicontext information is used to suppress their scores. Quantitative results The component analysis of our framework on both provided-data and additional-data tracks are shown in Table 5. The results are obtained from the validation set. From the table, we can see that the still-image object detectors obtain about 65 70% mean AP. Adding temporal and contextual information through MCS, MGP and tubelet re-scoring significantly improves the results by up to 6.7 percents. The final model combination process further improves the performance. Overall, our framework ranks 1st on the provided-data track in ILSVRC2015 winning 28 classes out of 30 and 2nd on the additonal-data track winning 11 classes. The detailed AP lists of the submitted models on the validation set are shown in Table 6. The final results of our team and other top-ranked teams on the test data are shown in Table 7. 5 CONCLUSION In this work, we propose a deep learning framework that incorporates temporal and contextual information into object detection in videos. This framework achieved the state of the art performance on the ImageNet object detection from video task and won the corresponding VID challenge with provided data in ILSVRC2015. The component analysis is investigated and discussed in details. Code is publicly available. The VID task is still new and under-explored. Our proposed framework is based on the popular still-image object detection frameworks and adds important components TABLE 7 Performance comparison with other teams on ILSVRC2015 VID test set with provided data (sorted by mean AP, the best model is chosen for each team). Rank Team name mean AP #win 1 CUVideo (Ours) ITLab VID - Inha UIUC-IFP [36] Trimps-Soushen HKUST HiVision RUC BDAI specifically designed for videos. We believe that the knowledge of these components can be further incorporated in to end-to-end systems and is our future research direction. REFERENCES [1] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, Going deeper with convolutions, CVPR, [2] K. Simonyan and A. Zisserman, Very deep convolutional networks for large-scale image recognition, Int l Conf. Learning Representations, [3] R. Girshick, J. Donahue, T. Darrell, and J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR, [4] R. Girshick, Fast r-cnn, ICCV, [5] S. Ren, K. He, R. Girshick, and J. Sun, Faster r-cnn: Towards realtime object detection with region proposal networks, NIPS, [6] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, arxiv preprint arxiv: , [7] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, arxiv preprint arxiv: , [8] W. Ouyang, X. Wang, X. Zeng, S. Qiu, P. Luo, Y. Tian, H. Li, S. Yang, Z. Wang, C.-C. Loy et al., DeepID-net: Deformable deep convolutional neural networks for object detection, CVPR, [9] D. Oneata, J. Revaud, J. Verbeek, and C. Schmid, Spatio-temporal Object Detection Proposals, ECCV, 2014.
8 [10] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. Le- Cun, Overfeat: Integrated recognition, localization and detection using convolutional networks, arxiv preprint arxiv: , [11] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, Scalable object detection using deep neural networks, [12] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, You only look once: Unified, real-time object detection, arxiv preprint arxiv: , [13] S. Gidaris and N. Komodakis, Object detection via a multi-region and semantic segmentation-aware cnn model, in ICCV, [14] R. Girshick, F. Iandola, T. Darrell, and J. Malik, Deformable part models are convolutional neural networks, in CVPR, [15] D. Mrowca, M. Rohrbach, J. Hoffman, R. Hu, K. Saenko, and T. Darrell, Spatial semantic regularisation for large scale object detection, in ICCV, [16] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick, Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks, arxiv preprint arxiv: , [17] J. Yan, Y. Yu, X. Zhu, Z. Lei, and S. Z. Li, Object detection by labeling superpixels, in CVPR, [18] A. Prest, C. Leistner, J. Civera, C. Schmid, and V. Ferrari, Learning object class detectors from weakly annotated video, CVPR, [19] A. Papazoglou and V. Ferrari, Fast Object Segmentation in Unconstrained Video, ICCV, [20] A. Joulin, K. Tang, and L. Fei-Fei, Efficient Image and Video Colocalization with Frank-Wolfe Algorithm, ECCV, [21] S. Kwak, M. Cho, I. Laptev, J. Ponce, and C. Schmid, Unsupervised Object Discovery and Tracking in Video Collections, ICCV, [22] T. Deselaers, B. Alexe, and V. Ferrari, Localizing Objects While Learning Their Appearance, ECCV, [23] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, Imagenet: A large-scale hierarchical image database, CVPR, [24] A. Krizhevsky, I. Sutskever, and G. E. Hinton, Imagenet classification with deep convolutional neural networks, NIPS, [25] K. Simonyan and A. Zisserman, Two-Stream Convolutional Networks for Action Recognition in Videos, in Conference on Neural Information Processing Systems, [26] J. Long, E. Shelhamer, and T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp [27] H. Possegger, T. Mauthner, P. M. Roth, and H. Bischof, Occlusion geodesics for online multi-object tracking, CVPR, [28] Y. Li, J. Zhu, and S. C. Hoi, Reliable patch trackers: Robust visual tracking by exploiting reliable patches, CVPR, [29] Z. Hong, Z. Chen, C. Wang, X. Mei, D. Prokhorov, and D. Tao, Multi-store tracker (muster): a cognitive psychology inspired approach to object tracking, CVPR, [30] L. Wang, W. Ouyang, X. Wang, and H. Lu, Visual tracking with fully convolutional networks, ICCV, [31] H. Nam and B. Han, Learning multi-domain convolutional neural networks for visual tracking, arxiv: , [32] B. Yang, J. Yan, Z. Lei, and S. Z. Li, Craft objects from images, CVPR, [33] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders, Selective search for object recognition, IJCV, [34] C. L. Zitnick and P. Dollar, Edge Boxes: Locating Object Proposals from Edges, ECCV, [35] X. Zeng, W. Ouyang, and X. Wang, Window-object relationship guided representation learning for generic object detections, arxiv preprint arxiv: , [36] W. Han, P. Khorrami, T. L. Paine, P. Ramachandran, M. Babaeizadeh, H. Shi, J. Li, S. Yan, and T. S. Huang, Seq-nms for video object detection, arxiv preprint arxiv: ,
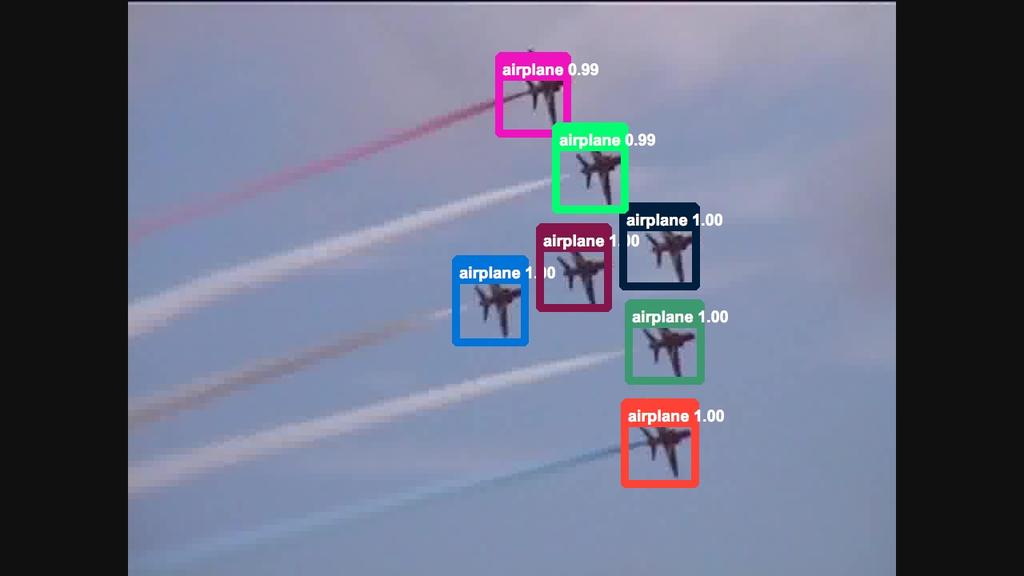


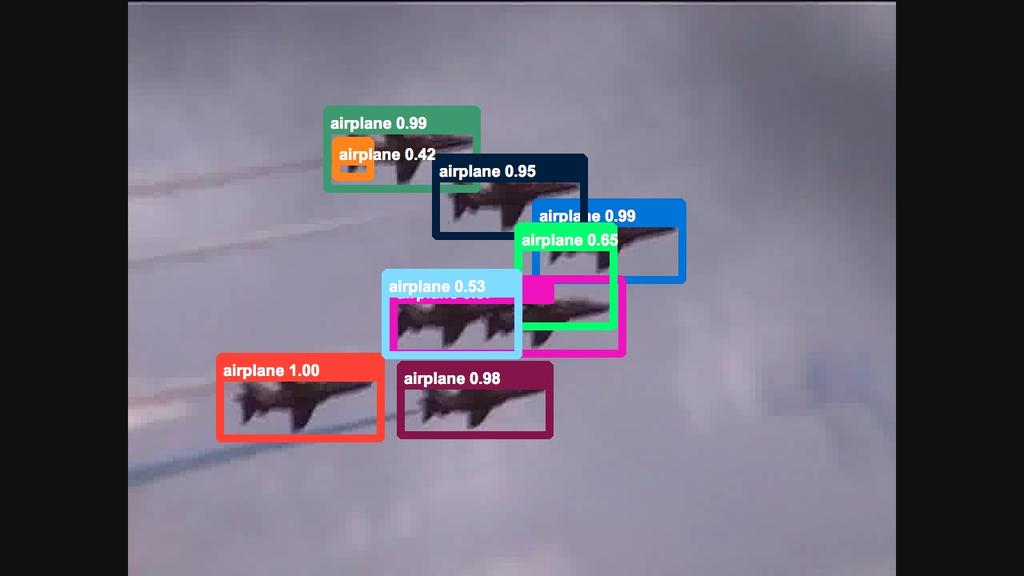










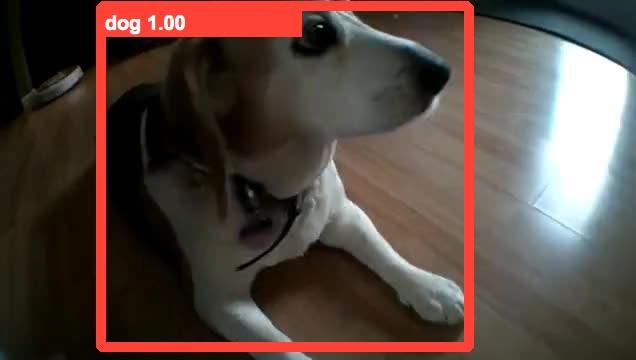



















9 9 Fig. 6. Qualitative results. The bounding boxes are tight to objects because of the combination of different region proposals. The detection results are consistent across adjacent frames thanks to motion-guided propagation and tracking. The false positives are much eliminated by multi-context suppression. (Different colors are used to mark bounding boxes in the same frame and do not represent tracking results)
arxiv: v1 [cs.cv] 14 Apr 2016
![arxiv: v1 [cs.cv] 14 Apr 2016](/thumbs/81/84437665.jpg "arxiv: v1 [cs.cv] 14 Apr 2016") Object Detection from Video Tubelets with Convolutional Neural Networks Kai Kang Wanli Ouyang Hongsheng Li Xiaogang Wang Department of Electronic Engineering, The Chinese University of Hong Kong {kkang,wlouyang,hsli,xgwang}@ee.cuhk.edu.hk
Object Detection from Video Tubelets with Convolutional Neural Networks Kai Kang Wanli Ouyang Hongsheng Li Xiaogang Wang Department of Electronic Engineering, The Chinese University of Hong Kong {kkang,wlouyang,hsli,xgwang}@ee.cuhk.edu.hk
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Gated Bi-directional CNN for Object Detection
 Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v2 [cs.cv] 10 Apr 2017
![arxiv: v2 [cs.cv] 10 Apr 2017](/thumbs/75/72708236.jpg "arxiv: v2 [cs.cv] 10 Apr 2017") Object Detection in Videos with Tubelet Proposal Networks Kai Kang1,2 Hongsheng Li2,? Tong Xiao1,2 Wanli Ouyang2,5 Junjie Yan3 Xihui Liu4 Xiaogang Wang2,? 1 2 Shenzhen Key Lab of Comp. Vis. & Pat. Rec.,
Object Detection in Videos with Tubelet Proposal Networks Kai Kang1,2 Hongsheng Li2,? Tong Xiao1,2 Wanli Ouyang2,5 Junjie Yan3 Xihui Liu4 Xiaogang Wang2,? 1 2 Shenzhen Key Lab of Comp. Vis. & Pat. Rec.,
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection
 MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL
 PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
arxiv: v2 [cs.cv] 24 Jul 2018
![arxiv: v2 [cs.cv] 24 Jul 2018](/thumbs/94/120067817.jpg "arxiv: v2 [cs.cv] 24 Jul 2018") arxiv:1803.05549v2 [cs.cv] 24 Jul 2018 Object Detection in Video with Spatiotemporal Sampling Networks Gedas Bertasius 1, Lorenzo Torresani 2, and Jianbo Shi 1 1 University of Pennsylvania, 2 Dartmouth
arxiv:1803.05549v2 [cs.cv] 24 Jul 2018 Object Detection in Video with Spatiotemporal Sampling Networks Gedas Bertasius 1, Lorenzo Torresani 2, and Jianbo Shi 1 1 University of Pennsylvania, 2 Dartmouth
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Chained Cascade Network for Object Detection
 Chained Cascade Network for Object Detection Wanli Ouyang 1,2, Kun Wang 1, Xin Zhu 1, Xiaogang Wang 1 1. The Chinese University of Hong Kong 2. The University of Sydney {wlouyang, kwang, xzhu, xgwang}@ee.cuhk.edu.hk
Chained Cascade Network for Object Detection Wanli Ouyang 1,2, Kun Wang 1, Xin Zhu 1, Xiaogang Wang 1 1. The Chinese University of Hong Kong 2. The University of Sydney {wlouyang, kwang, xzhu, xgwang}@ee.cuhk.edu.hk
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
arxiv: v1 [cs.cv] 4 Jun 2015
![arxiv: v1 [cs.cv] 4 Jun 2015](/thumbs/92/109659580.jpg "arxiv: v1 [cs.cv] 4 Jun 2015") Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Supplementary Material: Unconstrained Salient Object Detection via Proposal Subset Optimization
 Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Project 3 Q&A. Jonathan Krause
 Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
FCHD: A fast and accurate head detector
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
arxiv: v1 [cs.cv] 9 Dec 2015
![arxiv: v1 [cs.cv] 9 Dec 2015](/thumbs/96/127505663.jpg "arxiv: v1 [cs.cv] 9 Dec 2015") Window-Object Relationship Guided Representation Learning for Generic Object Detections Xingyu ZENG Wanli OUYANG Xiaogang WANG The Chinese University of Hong Kong {xyzeng,wlouyang,xgwang}@ee.cuhk.edu.hk
Window-Object Relationship Guided Representation Learning for Generic Object Detections Xingyu ZENG Wanli OUYANG Xiaogang WANG The Chinese University of Hong Kong {xyzeng,wlouyang,xgwang}@ee.cuhk.edu.hk
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Industrial Technology Research Institute, Hsinchu, Taiwan, R.O.C ǂ
 Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
arxiv: v1 [cs.cv] 19 Oct 2016
![arxiv: v1 [cs.cv] 19 Oct 2016](/thumbs/76/73604965.jpg "arxiv: v1 [cs.cv] 19 Oct 2016") arxiv:1610.06136v1 [cs.cv] 19 Oct 2016 POI: Multiple Object Tracking with High Performance Detection and Appearance Feature Fengwei Yu 1,3 Wenbo Li 2,3 Quanquan Li 3 Yu Liu 3 Xiaohua Shi 1 Junjie Yan 3
arxiv:1610.06136v1 [cs.cv] 19 Oct 2016 POI: Multiple Object Tracking with High Performance Detection and Appearance Feature Fengwei Yu 1,3 Wenbo Li 2,3 Quanquan Li 3 Yu Liu 3 Xiaohua Shi 1 Junjie Yan 3
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Crafting GBD-Net for Object Detection
 MANUSCRIPT 1 Crafting GBD-Net for Object Detection Xingyu Zeng*,Wanli Ouyang*,Junjie Yan, Hongsheng Li,Tong Xiao, Kun Wang, Yu Liu, Yucong Zhou, Bin Yang, Zhe Wang,Hui Zhou, Xiaogang Wang, To handle these
MANUSCRIPT 1 Crafting GBD-Net for Object Detection Xingyu Zeng*,Wanli Ouyang*,Junjie Yan, Hongsheng Li,Tong Xiao, Kun Wang, Yu Liu, Yucong Zhou, Bin Yang, Zhe Wang,Hui Zhou, Xiaogang Wang, To handle these
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Deep Learning for Object detection & localization
 Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/98911750.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Vehicle classification using ResNets, localisation and spatially-weighted pooling Rohan Watkins, Nick Pears, Suresh Manandhar Department of Computer Science, University of York, York, UK arxiv:1810.10329v1
Vehicle classification using ResNets, localisation and spatially-weighted pooling Rohan Watkins, Nick Pears, Suresh Manandhar Department of Computer Science, University of York, York, UK arxiv:1810.10329v1
arxiv: v1 [cs.cv] 12 Apr 2016
![arxiv: v1 [cs.cv] 12 Apr 2016](/thumbs/72/67523347.jpg "arxiv: v1 [cs.cv] 12 Apr 2016") CRAFT Objects from Images Bin Yang 1 Junjie Yan 2 Zhen Lei 1 Stan Z. Li 1 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences 2 Tsinghua University arxiv:1604.03239v1
CRAFT Objects from Images Bin Yang 1 Junjie Yan 2 Zhen Lei 1 Stan Z. Li 1 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences 2 Tsinghua University arxiv:1604.03239v1
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS 1674: Intro to Computer Vision. Object Recognition. Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018
 CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
A MultiPath Network for Object Detection
 ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Object Detection. TA : Young-geun Kim. Biostatistics Lab., Seoul National University. March-June, 2018
 Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Optimizing Object Detection:
 Lecture 10: Optimizing Object Detection: A Case Study of R-CNN, Fast R-CNN, and Faster R-CNN Visual Computing Systems Today s task: object detection Image classification: what is the object in this image?
Lecture 10: Optimizing Object Detection: A Case Study of R-CNN, Fast R-CNN, and Faster R-CNN Visual Computing Systems Today s task: object detection Image classification: what is the object in this image?
Detect to Track and Track to Detect
 Detect to Track and Track to Detect Christoph Feichtenhofer Graz University of Technology feichtenhofer@tugraz.at Axel Pinz Graz University of Technology axel.pinz@tugraz.at Andrew Zisserman University
Detect to Track and Track to Detect Christoph Feichtenhofer Graz University of Technology feichtenhofer@tugraz.at Axel Pinz Graz University of Technology axel.pinz@tugraz.at Andrew Zisserman University
Automatic Detection of Multiple Organs Using Convolutional Neural Networks
 Automatic Detection of Multiple Organs Using Convolutional Neural Networks Elizabeth Cole University of Massachusetts Amherst Amherst, MA ekcole@umass.edu Sarfaraz Hussein University of Central Florida
Automatic Detection of Multiple Organs Using Convolutional Neural Networks Elizabeth Cole University of Massachusetts Amherst Amherst, MA ekcole@umass.edu Sarfaraz Hussein University of Central Florida
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
arxiv: v1 [cs.cv] 31 Mar 2017
![arxiv: v1 [cs.cv] 31 Mar 2017](/thumbs/80/81467687.jpg "arxiv: v1 [cs.cv] 31 Mar 2017") End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
Object Detection and Its Implementation on Android Devices
 Object Detection and Its Implementation on Android Devices Zhongjie Li Stanford University 450 Serra Mall, Stanford, CA 94305 jay2015@stanford.edu Rao Zhang Stanford University 450 Serra Mall, Stanford,
Object Detection and Its Implementation on Android Devices Zhongjie Li Stanford University 450 Serra Mall, Stanford, CA 94305 jay2015@stanford.edu Rao Zhang Stanford University 450 Serra Mall, Stanford,
Mimicking Very Efficient Network for Object Detection
 Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
A Novel Representation and Pipeline for Object Detection
 A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
OBJECT DETECTION HYUNG IL KOO
 OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL
 LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
Adaptive Object Detection Using Adjacency and Zoom Prediction
 Adaptive Object Detection Using Adjacency and Zoom Prediction Yongxi Lu University of California, San Diego yol7@ucsd.edu Tara Javidi University of California, San Diego tjavidi@ucsd.edu Svetlana Lazebnik
Adaptive Object Detection Using Adjacency and Zoom Prediction Yongxi Lu University of California, San Diego yol7@ucsd.edu Tara Javidi University of California, San Diego tjavidi@ucsd.edu Svetlana Lazebnik
Weakly Supervised Learning of Part Selection Model with Spatial Constraints for Fine-Grained Image Classification
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Weakly Supervised Learning of Part Selection Model with Spatial Constraints for Fine-Grained Image Classification Xiangteng
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Weakly Supervised Learning of Part Selection Model with Spatial Constraints for Fine-Grained Image Classification Xiangteng
Supervised Learning of Classifiers
 Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1