CBAM: Convolutional Block Attention Module
|
|
|
- Mitchell Bishop
- 5 years ago
- Views:
Transcription
1 CBAM: Convolutional Block Attention Module Sanghyun Woo *1, Jongchan Park* 2, Joon-Young Lee 3, and In So Kweon 1 1 Korea Advanced Institute of Science and Technology, Daejeon, Korea {shwoo93, iskweon77}@kaist.ac.kr 2 Lunit Inc., Seoul, Korea jcpark@lunit.io 3 Adobe Research, San Jose, CA, USA jolee@adobe.com Abstract. We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS COCO detection, and VOC 2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available. Keywords: Object recognition, attention mechanism, gated convolution 1 Introduction Convolutional neural networks (CNNs) have significantly pushed the performance of vision tasks [1,2,3] based on their rich representation power. To enhance performance of CNNs, recent researches have mainly investigated three important factors of networks: depth, width, and cardinality. From the LeNet architecture [4] to Residual-style Networks [5,6,7,8] so far, the network has become deeper for rich representation. VGGNet [9] shows that stacking blocks with the same shape gives fair results. Following the same spirit, ResNet [5] stacks the same topology of residual blocks along with skip connection to build an extremely deep architecture. GoogLeNet [10] shows that width is another important factor to improve the performance of a model. Zagoruyko and Komodakis [6] propose to increase the width of a network based on the ResNet architecture. They have shown that a 28-layer ResNet with increased *Both authors have equally contributed. The work was done while the author was at KAIST.
2 2 Woo, Park, Lee, Kweon width can outperform an extremely deep ResNet with 1001 layers on the CI- FAR benchmarks. Xception [11] and ResNeXt [7] come up with to increase the cardinality of a network. They empirically show that cardinality not only saves the total number of parameters but also results in stronger representation power than the other two factors: depth and width. Apart from these factors, we investigate a different aspect of the architecture design, attention. The significance of attention has been studied extensively in the previous literature [12,13,14,15,16,17]. Attention not only tells where to focus, it also improves the representation of interests. Our goal is to increase representation power by using attention mechanism: focusing on important features and suppressing unnecessary ones. In this paper, we propose a new network module, named Convolutional Block Attention Module. Since convolution operations extract informative features by blending cross-channel and spatial information together, we adopt our module to emphasize meaningful features along those two principal dimensions: channel and spatial axes. To achieve this, we sequentially apply channel and spatial attention modules (as shown in Fig. 1), so that each of the branches can learn what and where to attend in the channel and spatial axes respectively. As a result, our module efficiently helps the information flow within the network by learning which information to emphasize or suppress. In the ImageNet-1K dataset, we obtain accuracy improvement from various baseline networks by plugging our tiny module, revealing the efficacy of CBAM. We visualize trained models using the grad-cam [18] and observe that CBAMenhanced networks focus on target objects more properly than their baseline networks. We then conduct user study to quantitatively evaluate improvements in interpretability of models. We show that better performance and better interpretability are possible at the same time by using CBAM. Taking this into account, we conjecture that the performance boost comes from accurate attention and noise reduction of irrelevant clutters. Finally, we validate performance improvement of object detection on the MS COCO and the VOC 2007 datasets, demonstrating a wide applicability of CBAM. Since we have carefully designed our module to be light-weight, the overhead of parameters and computation is negligible in most cases. Contribution. Our main contribution is three-fold. 1. We propose a simple yet effective attention module (CBAM) that can be widely applied to boost representation power of CNNs. 2. We validate the effectiveness of our attention module through extensive ablation studies. 3. We verify that performance of various networks is greatly improved on the multiple benchmarks (ImageNet-1K, MS COCO, and VOC 2007) by plugging our light-weight module.
3 Convolutional Block Attention Module 3 Convolutional Block Attention Module Input Feature Channel Attention Module Spatial Attention Module Refined Feature Fig. 1: The overview of CBAM. The module has two sequential sub-modules: channel and spatial. The intermediate feature map is adaptively refined through our module (CBAM) at every convolutional block of deep networks. 2 Related Work Network engineering. Network engineering has been one of the most important vision research, because well-designed networks ensure remarkable performance improvement in various applications. A wide range of architectures has been proposed since the successful implementation of a large-scale CNN [19]. An intuitive and simple way of extension is to increase the depth of neural networks [9]. Szegedy et al. [10] introduce a deep Inception network using a multi-branch architecture where each branch is customized carefully. While a naive increase in depth comes to saturation due to the difficulty of gradient propagation, ResNet [5] proposes a simple identity skip-connection to ease the optimization issues of deep networks. Based on the ResNet architecture, various models such as WideResNet [6], Inception-ResNet [8], and ResNeXt [7] have been developed. WideResNet [6] proposes a residual network with a larger number of convolutional filters and reduced depth. PyramidNet [20] is a strict generalization of WideResNet where the width of the network gradually increases. ResNeXt [7] suggests to use grouped convolutions and shows that increasing the cardinality leads to better classification accuracy. More recently, Huang et al. [21] propose a new architecture, DenseNet. It iteratively concatenates the input features with the output features, enabling each convolution block to receive raw information from all the previous blocks. While most of recent network engineering methods mainly target on three factors depth [19,9,10,5], width [10,22,6,8], and cardinality [7,11], we focus on the other aspect, attention, one of the curious facets of a human visual system. Attention mechanism. It is well known that attention plays an important role in human perception [23,24,25]. One important property of a human visual system is that one does not attempt to process a whole scene at once. Instead, humans exploit a sequence of partial glimpses and selectively focus on salient parts in order to capture visual structure better [26]. Recently, there have been several attempts [27,28] to incorporate attention processing to improve the performance of CNNs in large-scale classification tasks.
4 4 Woo, Park, Lee, Kweon Wang et al. [27] propose Residual Attention Network which uses an encoderdecoder style attention module. By refining the feature maps, the network not only performs well but is also robust to noisy inputs. Instead of directly computing the 3d attention map, we decompose the process that learns channel attention and spatial attention separately. The separate attention generation process for 3D feature map has much less computational and parameter overhead, and therefore can be used as a plug-and-play module for pre-existing base CNN architectures. More close to our work, Hu et al. [28] introduce a compact module to exploit the inter-channel relationship. In their Squeeze-and-Excitation module, they use global average-pooled features to compute channel-wise attention. However, we show that those are suboptimal features in order to infer fine channel attention, and we suggest to use max-pooled features as well. They also miss the spatial attention, which plays an important role in deciding where to focus as shown in [29]. In our CBAM, we exploit both spatial and channel-wise attention based on an efficient architecture and empirically verify that exploiting both is superior to using only the channel-wise attention as [28]. Moreover, we empirically show that our module is effective in detection tasks (MS-COCO and VOC). Especially, we achieve state-of-the-art performance just by placing our module on top of the existing one-shot detector [30] in the VOC2007 test set. Concurrently, BAM [31] takes a similar approach, decomposing 3D attention map inference into channel and spatial. They place BAM module at every bottleneck of the network while we plug at every convolutional block. 3 Convolutional Block Attention Module Given an intermediate feature map F R C H W as input, CBAM sequentially infers a 1D channel attention map M c R C 1 1 and a 2D spatial attention map M s R 1 H W as illustrated in Fig. 1. The overall attention process can be summarized as: F = M c (F) F, F = M s (F ) F, where denotes element-wise multiplication. During multiplication, the attention values are broadcasted (copied) accordingly: channel attention values are broadcasted along the spatial dimension, and vice versa. F is the final refined output. Fig. 2 depicts the computation process of each attention map. The following describes the details of each attention module. (1) Channel attention module. We produce a channel attention map by exploiting the inter-channel relationship of features. As each channel of a feature map is considered as a feature detector [32], channel attention focuses on what is meaningful given an input image. To compute the channel attention efficiently, we squeeze the spatial dimension of the input feature map. For aggregating spatial information, average-pooling has been commonly adopted so far. Zhou et al.
5 Convolutional Block Attention Module 5 MaxPool Channel Attention Module Input feature F AvgPool Shared MLP Channel Attention M C Spatial Attention Module conv layer Channel-refined feature F [MaxPool, AvgPool] Spatial Attention M S Fig. 2: Diagram of each attention sub-module. As illustrated, the channel sub-module utilizes both max-pooling outputs and average-pooling outputs with a shared network; the spatial sub-module utilizes similar two outputs that are pooled along the channel axis and forward them to a convolution layer. [33] suggest to use it to learn the extent of the target object effectively and Hu et al. [28] adopt it in their attention module to compute spatial statistics. Beyond the previous works, we argue that max-pooling gathers another important clue about distinctive object features to infer finer channel-wise attention. Thus, we use both average-pooled and max-pooled features simultaneously. We empirically confirmed that exploiting both features greatly improves representation power of networks rather than using each independently (see Sec. 4.1), showing the effectiveness of our design choice. We describe the detailed operation below. We first aggregate spatial information of a feature map by using both averagepooling and max-pooling operations, generating two different spatial context descriptors:f c avg andf c max, which denote average-pooled features and max-pooled features respectively. Both descriptors are then forwarded to a shared network to produce our channel attention map M c R C 1 1. The shared network is composed of multi-layer perceptron (MLP) with one hidden layer. To reduce parameter overhead, the hidden activation size is set to R C/r 1 1, where r is the reduction ratio. After the shared network is applied to each descriptor, we merge the output feature vectors using element-wise summation. In short, the channel attention is computed as: M c (F) = σ(mlp(avgpool(f))+mlp(maxpool(f))) = σ(w 1 (W 0 (F c avg))+w 1 (W 0 (F c max))), (2) where σ denotes the sigmoid function, W 0 R C/r C, and W 1 R C C/r. Note that the MLP weights, W 0 and W 1, are shared for both inputs and the ReLU activation function is followed by W 0.
6 6 Woo, Park, Lee, Kweon Spatial attention module. We generate a spatial attention map by utilizing the inter-spatial relationship of features. Different from the channel attention, the spatial attention focuses on where is an informative part, which is complementary to the channel attention. To compute the spatial attention, we first apply average-pooling and max-pooling operations along the channel axis and concatenate them to generate an efficient feature descriptor. Applying pooling operations along the channel axis is shown to be effective in highlighting informative regions [34]. On the concatenated feature descriptor, we apply a convolution layer to generate a spatial attention map M s (F) R H W which encodes where to emphasize or suppress. We describe the detailed operation below. We aggregate channel information of a feature map by using two pooling operations, generating two 2D maps: F s avg R 1 H W and F s max R 1 H W. Each denotes average-pooled features and max-pooled features across the channel. Those are then concatenated and convolved by a standard convolution layer, producing our 2D spatial attention map. In short, the spatial attention is computed as: M s (F) = σ(f 7 7 ([AvgPool(F);MaxPool(F)])) = σ(f 7 7 ([F s avg;f s max])), (3) where σ denotes the sigmoid function and f 7 7 represents a convolution operation with the filter size of 7 7. Arrangement of attention modules. Given an input image, two attention modules, channel and spatial, compute complementary attention, focusing on what and where respectively. Considering this, two modules can be placed in a parallel or sequential manner. We found that the sequential arrangement gives a better result than a parallel arrangement. For the arrangement of the sequential process, our experimental result shows that the channel-first order is slightly better than the spatial-first. We will discuss experimental results on network engineering in Sec Experiments We evaluate CBAM on the standard benchmarks: ImageNet-1K for image classification; MS COCO and VOC 2007 for object detection. In order to perform better apple-to-apple comparisons, we reproduced all the evaluated networks [5,6,7,35,28] in the PyTorch framework [36] and report our reproduced results in the whole experiments. To thoroughly evaluate the effectiveness of our final module, we first perform extensive ablation experiments. Then, we verify that CBAM outperforms all the baselines without bells and whistles, demonstrating the general applicability of CBAM across different architectures as well as different tasks. One can seamlessly integrate CBAM in any CNN architectures and jointly train the combined CBAM-enhanced networks. Fig. 3 shows a diagram of CBAM integrated with a ResBlock in ResNet [5] as an example.
7 Convolutional Block Attention Module 7 Channel attention Spatial attention Previous conv blocks conv F M C F M S F Next conv blocks ResBlock + CBAM Fig. 3: CBAM integrated with a ResBlock in ResNet[5]. This figure shows the exact position of our module when integrated within a ResBlock. We apply CBAM on the convolution outputs in each block. 4.1 Ablation studies In this subsection, we empirically show the effectiveness of our design choice. For this ablation study, we use the ImageNet-1K dataset and adopt ResNet-50 [5] as the base architecture. The ImageNet-1K classification dataset [1] consists of 1.2 million images for training and 50,000 for validation with 1,000 object classes. We adopt the same data augmentation scheme with [5,37] for training and apply a single-crop evaluation with the size of at test time. The learning rate starts from 0.1 and drops every 30 epochs. We train the networks for 90 epochs. Following [5,37,38], we report classification errors on the validation set. Our module design process is split into three parts. We first search for the effective approach to computing the channel attention, then the spatial attention. Finally, we consider how to combine both channel and spatial attention modules. We explain the details of each experiment below. Channel attention. We experimentally verify that using both average-pooled and max-pooled features enables finer attention inference. We compare 3 variants of channel attention: average pooling, max pooling, and joint use of both poolings. Note that the channel attention module with an average pooling is the same as the SE [28] module. Also, when using both poolings, we use a shared MLP for attention inference to save parameters, as both of aggregated channel features lie in the same semantic embedding space. We only use channel attention modules in this experiment and we fix the reduction ratio to 16. Description Parameters GFLOPs Top-1 Error(%) Top-5 Error(%) ResNet50 (baseline) 25.56M ResNet50 + AvgPool (SE [28]) 25.92M ResNet50 + MaxPool 25.92M ResNet50 + AvgPool & MaxPool 25.92M Table 1: Comparison of different channel attention methods. We observe that using our proposed method outperforms recently suggested Squeeze and Excitation method [28].
8 8 Woo, Park, Lee, Kweon Description Param. GFLOPs Top-1 Error(%) Top-5 Error(%) ResNet50 + channel (SE [28]) 28.09M ResNet50 + channel 28.09M ResNet50 + channel + spatial (1x1 conv, k=3) 28.10M ResNet50 + channel + spatial (1x1 conv, k=7) 28.10M ResNet50 + channel + spatial (avg&max, k=3) 28.09M ResNet50 + channel + spatial (avg&max, k=7) 28.09M Table 2: Comparison of different spatial attention methods. Using the proposed channel-pooling (i.e. average- and max-pooling along the channel axis) along with the large kernel size of 7 for the following convolution operation performs best. Description Top-1 Error(%) Top-5 Error(%) ResNet50 + channel (SE [28]) ResNet50 + channel + spatial ResNet50 + spatial + channel ResNet50 + channel & spatial in parallel Table 3: Combining methods of channel and spatial attention. Using both attention is critical while the best-combining strategy (i.e. sequential, channelfirst) further improves the accuracy. Experimental results with various pooling methods are shown in Table 1. We observe that max-pooled features are as meaningful as average-pooled features, comparing the accuracy improvement from the baseline. In the work of SE [28], however, they only exploit the average-pooled features, missing the importance of max-pooled features. We argue that max-pooled features which encode the degree of the most salient part can compensate the average-pooled features which encode global statistics softly. Thus, we suggest to use both features simultaneously and apply a shared network to those features. The outputs of a shared network are then merged by element-wise summation. We empirically show that our channel attention method is an effective way to push performance further from SE [28] without additional learnable parameters. As a brief conclusion, we use both average- and max-pooled features in our channel attention module with the reduction ratio of 16 in the following experiments. Spatial attention. Given the channel-wise refined features, we explore an effective method to compute the spatial attention. The design philosophy is symmetric with the channel attention branch. To generate a 2D spatial attention map, we first compute a 2D descriptor that encodes channel information at each pixel over all spatial locations. We then apply one convolution layer to the 2D descriptor, obtaining the raw attention map. The final attention map is normalized by the sigmoid function. We compare two methods of generating the 2D descriptor: channel pooling using average- and max-pooling across the channel axis and standard 1 1 con-
9 Convolutional Block Attention Module 9 volution reducing the channel dimension into 1. In addition, we investigate the effect of a kernel size at the following convolution layer: kernel sizes of 3 and 7. In the experiment, we place the spatial attention module after the previously designed channel attention module, as the final goal is to use both modules together. Table 2 shows the experimental results. We can observe that the channel pooling produces better accuracy, indicating that explicitly modeled pooling leads to finer attention inference rather than learnable weighted channel pooling (implemented as 1 1 convolution). In the comparison of different convolution kernel sizes, we find that adopting a larger kernel size generates better accuracy in both cases. It implies that a broad view (i.e. large receptive field) is needed for deciding spatially important regions. Considering this, we adopt the channelpooling method and the convolution layer with a large kernel size to compute spatial attention. In a brief conclusion, we use the average- and max-pooled features across the channel axis with a convolution kernel size of 7 as our spatial attention module. Arrangement of the channel and spatial attention. In this experiment, we compare three different ways of arranging the channel and spatial attention submodules: sequential channel-spatial, sequential spatial-channel, and parallel use of both attention modules. As each module has different functions, the order may affect the overall performance. For example, from a spatial viewpoint, the channel attention is globally applied, while the spatial attention works locally. Also, it is natural to think that we may combine two attention outputs to build a 3D attention map. In the case, both attentions can be applied in parallel, then the outputs of the two attention modules are added and normalized with the sigmoid function. Table 3 summarizes the experimental results on different attention arranging methods. From the results, we can find that generating an attention map sequentially infers a finer attention map than doing in parallel. In addition, the channel-first order performs slightly better than the spatial-first order. Note that all the arranging methods outperform using only the channel attention independently, showing that utilizing both attentions is crucial while the best-arranging strategy further pushes performance. 4.2 Image Classification on ImageNet-1K We perform ImageNet-1K classification experiments to rigorously evaluate our module. We follow the same protocol as specified in Sec. 4.1 and evaluate our module in various network architectures including ResNet [5], WideResNet [6], and ResNext [7]. Table 4 summarizes the experimental results. The networks with CBAM outperform all the baselines significantly, demonstrating that the CBAM can generalize well on various models in the large-scale dataset. Moreover, the models with CBAM improve the accuracy upon the one of the strongest method SE [28]
10 10 Woo, Park, Lee, Kweon Architecture Param. GFLOPs Top-1 Error (%) Top-5 Error (%) ResNet18 [5] 11.69M ResNet18 [5] + SE [28] 11.78M ResNet18 [5] + CBAM 11.78M ResNet34 [5] 21.80M ResNet34 [5] + SE [28] 21.96M ResNet34 [5] + CBAM 21.96M ResNet50 [5] 25.56M ResNet50 [5] + SE [28] 28.09M ResNet50 [5] + CBAM 28.09M ResNet101 [5] 44.55M ResNet101 [5] + SE [28] 49.33M ResNet101 [5] + CBAM 49.33M WideResNet18 [6] (widen=1.5) 25.88M WideResNet18 [6] (widen=1.5) + SE [28] 26.07M WideResNet18 [6] (widen=1.5) + CBAM 26.08M WideResNet18 [6] (widen=2.0) 45.62M WideResNet18 [6] (widen=2.0) + SE [28] 45.97M WideResNet18 [6] (widen=2.0) + CBAM 45.97M ResNeXt50 [7] (32x4d) 25.03M ResNeXt50 [7] (32x4d) + SE [28] 27.56M ResNeXt50 [7] (32x4d) + CBAM 27.56M ResNeXt101 [7] (32x4d) 44.18M ResNeXt101 [7] (32x4d) + SE [28] 48.96M ResNeXt101 [7] (32x4d) + CBAM 48.96M * all results are reproduced in the PyTorch framework. Table 4: Classification results on ImageNet-1K. Single-crop validation errors are reported. which is the winning approach of the ILSVRC 2017 classification task. It implies that our proposed approach is powerful, showing the efficacy of new pooling method that generates richer descriptor and spatial attention that complements the channel attention effectively. We also find that the overall overhead of CBAM is quite small in terms of both parameters and computation. This motivates us to apply our proposed module CBAM to the light-weight network, MobileNet [35]. Table 5 summarizes the experimental results that we conducted based on the MobileNet architecture. We have placed CBAM to two models, basic and capacity-reduced model(i.e. adjusting width multiplier(α) to 0.7). We observe similar phenomenon as shown in Table 4. CBAM not only boosts the accuracy of baselines significantly but also favorably improves the performance of SE [28]. This shows the great potential of CBAM for applications on low-end devices. 4.3 Network Visualization with Grad-CAM [18] For the qualitative analysis, we apply the Grad-CAM [18] to different networks using images from the ImageNet validation set. Grad-CAM is a recently proposed visualization method which uses gradients in order to calculate the importance of the spatial locations in convolutional layers. As the gradients are calculated
![Convolutional Block Attention Module 11 Architecture Parameters GFLOPs Top-1 Error (%) Top-5 Error (%) MobileNet [35] α = 0.7 2.30M 0.283 34.86 13.69 MobileNet [35] α = 0.7 + SE [28] 2.71M 0.283 32.](/docs-images/88/114802349/images/11-0.jpg "50 12.49 MobileNet [35] α = 0.7 + CBAM 2.71M 0.289 31.51 11.48 MobileNet [35] 4.23M 0.569 31.39 11.51 MobileNet [35] + SE [28] 5.07M 0.570 29.97 10.63 MobileNet [35] + CBAM 5.07M 0.576 29.01 9.")
11 Convolutional Block Attention Module 11 Architecture Parameters GFLOPs Top-1 Error (%) Top-5 Error (%) MobileNet [35] α = M MobileNet [35] α = SE [28] 2.71M MobileNet [35] α = CBAM 2.71M MobileNet [35] 4.23M MobileNet [35] + SE [28] 5.07M MobileNet [35] + CBAM 5.07M * all results are reproduced in the PyTorch framework. Table 5: Classification results on ImageNet-1K using the light-weight network, MobileNet [35]. Single-crop validation errors are reported. with respect to a unique class, Grad-CAM result shows attended regions clearly. By observing the regions that network has considered as important for predicting a class, we attempt to look at how this network is making good use of features. We compare the visualization results of CBAM-integrated network (ResNet50 + CBAM) with baseline (ResNet50) and SE-integrated network (ResNet50 + SE). Fig. 4 illustrate the visualization results. The softmax scores for a target class are also shown in the figure. In Fig. 4, we can clearly see that the Grad-CAM masks of the CBAMintegrated network cover the target object regions better than other methods. That is, the CBAM-integrated network learns well to exploit information in target object regions and aggregate features from them. Note that target class scores also increase accordingly. Survey choice Votes Seems equal 295 Baseline better 288 CBAM better 667 Fig.5: Example of question image for the user study. Table 6: Results of user study. 4.4 Quantitative evaluation of improved interpretability Following the Sec.5.1 in Grad-CAM paper, we conduct a user study based on Grad-CAM visualizations. We randomly selected 50 images which are correctly classified with both methods(i.e.baseline and CBAM) from ImageNet validation set. The user study is conducted on the Google Forms platform. For each question, randomly shuffled visualizations are shown to the respondents. For the visualizations, regions of the image with Grad-CAM values of 0.6 or greater are shown. In practice, respondents were given full input image, ground-truth label, and two image regions from each methods(see Fig 5). The comparison criterion is Given class label, which region seems more class-discriminative?. The respondents can choose that either one is better, or both are similar. There are 50












































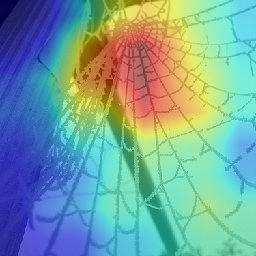












12 12 Woo, Park, Lee, Kweon Tailed frog Toilet tissue Loudspeaker Spider web American egret Tank Seawall Space heater Input image ResNet50 P= P= P= P= P= P= P= P= ResNet50 + SE P= P= P= P= P= P= P= P= ResNet50 + CBAM P = P = P = P = P = P = P = P = Croquet ball Eel Hammerhead Eskimo dog Snow leopard Boat paddle Daddy longlegs School bus Input image ResNet50 P= P= P= P= P= P= P= P= ResNet50 + SE P= P= P= P= P= P= P= P= ResNet50 + CBAM P = P = P = P = P = P = P = P = Fig. 4: Grad-CAM [18] visualization results. We compare the visualization results of CBAM-integrated network (ResNet50 + CBAM) with baseline (ResNet50) and SE-integrated network (ResNet50 + SE). The grad-cam visualization is calculated for the last convolutional outputs. The ground-truth label is shown on the top of each input image and P denotes the softmax score of each network for the ground-truth class.
13 Convolutional Block Attention Module 13 question sets of images and 25 respondents, resulting in a total of 1250 votes. The results are shown in the Table 6. We can clearly see that CBAM outperforms baseline, showing the improved interpretability. 4.5 MS COCO Object Detection We conduct object detection on the Microsoft COCO dataset [3]. This dataset involves 80k training images ( 2014 train ) and 40k validation images ( 2014 val ). The average map over different IoU thresholds from 0.5 to 0.95 is used for evaluation. According to [39,40], we trained our model using all the training images as well as a subset of validation images, holding out 5,000 examples for validation. Our training code is based on [41] and we train the network for 490K iterations for fast performance validation. We adopt Faster-RCNN [42] as our detection method and ImageNet pre-trained ResNet50 and ResNet101 [5] as our baseline networks. Here we are interested in performance improvement by plugging CBAM to the baseline networks. Since we use the same detection method in all the models, the gains can only be attributed to the enhanced representation power, given by our module CBAM. As shown in the Table 7, we observe significant improvements from the baseline, demonstrating generalization performance of CBAM on other recognition tasks. 4.6 VOC 2007 Object Detection We further perform experiments on the PASCAL VOC 2007 test set. In this experiment, we apply CBAM to the detectors, while the previous experiments (Table 7) apply our module to the base networks. We adopt the StairNet [30] framework, which is one of the strongest multi-scale method based on the SSD [40]. For the experiment, we reproduce SSD and StairNet in our PyTorch platform in order to estimate performance improvement of CBAM accurately and achieve 77.8% and 78.9% map@.5 respectively, which are higher than the original accuracy reported in the original papers. We then place SE [28] and CBAM right before every classifier, refining the final features which are composed of up-sampled global features and corresponding local features before the prediction, enforcing model to adaptively select only the meaningful features. We train all the models on the union set of VOC 2007 trainval and VOC 2012 trainval ( ), and evaluate on the VOC 2007 test set. The total number of training epochs is 250. We use a weight decay of and a momentum of 0.9. In all the experiments, the size of the input image is fixed to 300 for the simplicity. The experimental results are summarized in Table 8. We can clearly see that CBAM improves the accuracy of all strong baselines with two backbone networks. Note that accuracy improvement of CBAM comes with a negligible parameter overhead, indicating that enhancement is not due to a naive capacityincrement but because of our effective feature refinement. In addition, the result using the light-weight backbone network [35] again shows that CBAM can be an interesting method to low-end devices.
14 14 Woo, Park, Lee, Kweon Backbone Detector ResNet50 [5] Faster-RCNN [42] ResNet50 [5] + CBAM Faster-RCNN [42] ResNet101 [5] Faster-RCNN [42] ResNet101 [5] + CBAM Faster-RCNN [42] * all results are reproduced in the PyTorch framework. Table 7: Object detection map(%) on the MS COCO validation set. We adopt the Faster R-CNN [42] detection framework and apply our module to the base networks. CBAM boosts map@[.5,.95] by 0.9 for both baseline networks. Backbone Detector map@.5 Parameters (M) VGG16 [9] SSD [40] VGG16 [9] StairNet [30] VGG16 [9] StairNet [30] + SE [28] VGG16 [9] StairNet [30] + CBAM MobileNet [35] SSD [40] MobileNet [35] StairNet [30] MobileNet [35] StairNet [30] + SE [28] MobileNet [35] StairNet [30] + CBAM * all results are reproduced in the PyTorch framework. Table 8: Object detection map(%) on the VOC 2007 test set. We adopt the StairNet [30] detection framework and apply SE and CBAM to the detectors. CBAM favorably improves all the strong baselines with negligible additional parameters. 5 Conclusion We have presented the convolutional block attention module (CBAM), a new approach to improve representation power of CNN networks. We apply attentionbased feature refinement with two distinctive modules, channel and spatial, and achieve considerable performance improvement while keeping the overhead small. For the channel attention, we suggest to use the max-pooled features along with the average-pooled features, leading to produce finer attention than SE [28]. We further push the performance by exploiting the spatial attention. Our final module (CBAM) learns what and where to emphasize or suppress and refines intermediate features effectively. To verify its efficacy, we conducted extensive experiments with various state-of-the-art models and confirmed that CBAM outperforms all the baselines on three different benchmark datasets: ImageNet- 1K, MS COCO, and VOC In addition, we visualize how the module exactly infers given an input image. Interestingly, we observed that our module induces the network to focus on target object properly. We hope CBAM become an important component of various network architectures. Acknowledgement This work was supported by the Technology Innovation Program (No ), funded by the Ministry of Trade, Industry & Energy (MI, Korea).
15 Convolutional Block Attention Module 15 References 1. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2009) 1, 7 2. Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images 1 3. Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Proc. of European Conf. on Computer Vision (ECCV). (2014) 1, LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE 86(11) (1998) He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2016) 1, 3, 6, 7, 9, 10, 13, Zagoruyko, S., Komodakis, N.: Wide residual networks. arxiv preprint arxiv: (2016) 1, 3, 6, 9, Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. arxiv preprint arxiv: (2016) 1, 2, 3, 6, 9, Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proc. of Association for the Advancement of Artificial Intelligence (AAAI). (2017) 1, 3 9. Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arxiv preprint arxiv: (2014) 1, 3, Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2015) 1, Chollet, F.: Xception: Deep learning with depthwise separable convolutions. arxiv preprint arxiv: (2016) 2, Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention." advances in neural information processing systems. In: Proc. of Neural Information Processing Systems (NIPS). (2014) Ba, J., Mnih, V., Kavukcuoglu, K.: Multiple object recognition with visual attention. (2014) Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. (2014) Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. (2015) Gregor, K., Danihelka, I., Graves, A., Rezende, D.J., Wierstra, D.: Draw: A recurrent neural network for image generation. (2015) Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Proc. of Neural Information Processing Systems (NIPS). (2015) Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Gradcam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2017) , 10, Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Proc. of Neural Information Processing Systems (NIPS). (2012) 3
16 16 Woo, Park, Lee, Kweon 20. Han, D., Kim, J., Kim, J.: Deep pyramidal residual networks. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2017) Huang, G., Liu, Z., Weinberger, K.Q., van der Maaten, L.: Densely connected convolutional networks. arxiv preprint arxiv: (2016) Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2016) Itti, L., Koch, C., Niebur, E.: A model of saliency-based visual attention for rapid scene analysis. In: IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI). (1998) Rensink, R.A.: The dynamic representation of scenes. In: Visual cognition (2000) Corbetta, M., Shulman, G.L.: Control of goal-directed and stimulus-driven attention in the brain. In: Nature reviews neuroscience 3.3. (2002) Larochelle, H., Hinton, G.E.: Learning to combine foveal glimpses with a thirdorder boltzmann machine. In: Proc. of Neural Information Processing Systems (NIPS). (2010) Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X., Tang, X.: Residual attention network for image classification. arxiv preprint arxiv: (2017) 3, Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. arxiv preprint arxiv: (2017) 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Chua, T.S.: Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2017) Sanghyun, W., Soonmin, H., So, K.I.: Stairnet: Top-down semantic aggregation for accurate one shot detection. In: Proc. of Winter Conference on Applications of Computer Vision (WACV). (2018) 4, 13, Park, J., Woo, S., Lee, J.Y., Kweon, I.S.: Bam: Bottleneck attention module. In: Proc. of British Machine Vision Conference (BMVC). (2018) Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: Proc. of European Conf. on Computer Vision (ECCV). (2014) Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on, IEEE (2016) Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In: ICLR. (2017) Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arxiv preprint arxiv: (2017) 6, 10, 11, 13, : Pytorch. Accessed: He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: Proc. of European Conf. on Computer Vision (ECCV). (2016) Huang, G., Sun, Y., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In: Proc. of European Conf. on Computer Vision (ECCV). (2016) Bell, S., Lawrence Zitnick, C., Bala, K., Girshick, R.: Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In: Proc. of Computer Vision and Pattern Recognition (CVPR). (2016) 13
17 Convolutional Block Attention Module Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: Proc. of European Conf. on Computer Vision (ECCV). (2016) 13, Chen, X., Gupta, A.: An implementation of faster rcnn with study for region sampling. arxiv preprint arxiv: (2017) Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Proc. of Neural Information Processing Systems (NIPS). (2015) 13, 14
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Learning Deep Representations for Visual Recognition
 Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior
 CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior Xiang Zhang, Nishant Vishwamitra, Hongxin Hu, Feng Luo School of Computing Clemson University xzhang7@clemson.edu Abstract We
CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior Xiang Zhang, Nishant Vishwamitra, Hongxin Hu, Feng Luo School of Computing Clemson University xzhang7@clemson.edu Abstract We
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance Ryo Takahashi, Takashi Matsubara, Member, IEEE, and Kuniaki
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance Ryo Takahashi, Takashi Matsubara, Member, IEEE, and Kuniaki
arxiv: v1 [cs.cv] 30 Jul 2018
![arxiv: v1 [cs.cv] 30 Jul 2018](/thumbs/90/104442893.jpg "arxiv: v1 [cs.cv] 30 Jul 2018") arxiv:1807.11164v1 [cs.cv] 30 Jul 2018 ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design Ningning Ma 1,2 Xiangyu Zhang 1 Hai-Tao Zheng 2 Jian Sun 1 1 Megvii Inc (Face++) 2 Tsinghua
arxiv:1807.11164v1 [cs.cv] 30 Jul 2018 ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design Ningning Ma 1,2 Xiangyu Zhang 1 Hai-Tao Zheng 2 Jian Sun 1 1 Megvii Inc (Face++) 2 Tsinghua
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Image Captioning with Object Detection and Localization
 Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
 ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design Ningning Ma 1,2[0000 0003 4628 8831], Xiangyu Zhang 1[0000 0003 2138 4608], Hai-Tao Zheng 2[0000 0001 5128 5649], and Jian Sun
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design Ningning Ma 1,2[0000 0003 4628 8831], Xiangyu Zhang 1[0000 0003 2138 4608], Hai-Tao Zheng 2[0000 0001 5128 5649], and Jian Sun
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
 Ventral-Dorsal Neural Networks: Object Detection via Selective Attention Mohammad K. Ebrahimpour UC Merced mebrahimpour@ucmerced.edu Jiayun Li UCLA jiayunli@ucla.edu Yen-Yun Yu Ancestry.com yyu@ancestry.com
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention Mohammad K. Ebrahimpour UC Merced mebrahimpour@ucmerced.edu Jiayun Li UCLA jiayunli@ucla.edu Yen-Yun Yu Ancestry.com yyu@ancestry.com
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Parallel Feature Pyramid Network for Object Detection
 Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
Learning Deep Features for Visual Recognition
 7x7 conv, 64, /2, pool/2 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 128, /2 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv,
7x7 conv, 64, /2, pool/2 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 128, /2 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv,
Fei-Fei Li & Justin Johnson & Serena Yeung
 Lecture 9-1 Administrative A2 due Wed May 2 Midterm: In-class Tue May 8. Covers material through Lecture 10 (Thu May 3). Sample midterm released on piazza. Midterm review session: Fri May 4 discussion
Lecture 9-1 Administrative A2 due Wed May 2 Midterm: In-class Tue May 8. Covers material through Lecture 10 (Thu May 3). Sample midterm released on piazza. Midterm review session: Fri May 4 discussion
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Progressive Neural Architecture Search
 Progressive Neural Architecture Search Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy 09/10/2018 @ECCV 1 Outline Introduction
Progressive Neural Architecture Search Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy 09/10/2018 @ECCV 1 Outline Introduction
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
arxiv: v2 [cs.cv] 19 Apr 2018
![arxiv: v2 [cs.cv] 19 Apr 2018](/thumbs/83/87325597.jpg "arxiv: v2 [cs.cv] 19 Apr 2018") arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
Deep Residual Learning
 Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Smart Parking System using Deep Learning. Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins
 Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
arxiv: v1 [cs.cv] 11 Apr 2018
![arxiv: v1 [cs.cv] 11 Apr 2018](/thumbs/89/99253021.jpg "arxiv: v1 [cs.cv] 11 Apr 2018") arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
 FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
Mind the regularized GAP, for human action classification and semi-supervised localization based on visual saliency.
 Mind the regularized GAP, for human action classification and semi-supervised localization based on visual saliency. Marc Moreaux123, Natalia Lyubova1, Isabelle Ferrane 2 and Frederic Lerasle3 1 Softbank
Mind the regularized GAP, for human action classification and semi-supervised localization based on visual saliency. Marc Moreaux123, Natalia Lyubova1, Isabelle Ferrane 2 and Frederic Lerasle3 1 Softbank
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Gated Bi-directional CNN for Object Detection
 Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
arxiv: v2 [cs.cv] 30 Oct 2018
![arxiv: v2 [cs.cv] 30 Oct 2018](/thumbs/94/118508906.jpg "arxiv: v2 [cs.cv] 30 Oct 2018") Adversarial Noise Layer: Regularize Neural Network By Adding Noise Zhonghui You, Jinmian Ye, Kunming Li, Zenglin Xu, Ping Wang School of Electronics Engineering and Computer Science, Peking University
Adversarial Noise Layer: Regularize Neural Network By Adding Noise Zhonghui You, Jinmian Ye, Kunming Li, Zenglin Xu, Ping Wang School of Electronics Engineering and Computer Science, Peking University
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Pelee: A Real-Time Object Detection System on Mobile Devices
 Pelee: A Real-Time Object Detection System on Mobile Devices Robert J. Wang, Xiang Li, Charles X. Ling Department of Computer Science University of Western Ontario London, Ontario, Canada, N6A 3K7 {jwan563,lxiang2,charles.ling}@uwo.ca
Pelee: A Real-Time Object Detection System on Mobile Devices Robert J. Wang, Xiang Li, Charles X. Ling Department of Computer Science University of Western Ontario London, Ontario, Canada, N6A 3K7 {jwan563,lxiang2,charles.ling}@uwo.ca
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Real-time convolutional networks for sonar image classification in low-power embedded systems
 Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Pedestrian Detection based on Deep Fusion Network using Feature Correlation
 Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
arxiv: v2 [cs.cv] 2 Apr 2018
![arxiv: v2 [cs.cv] 2 Apr 2018](/thumbs/91/106374014.jpg "arxiv: v2 [cs.cv] 2 Apr 2018") Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
Introduction to Neural Networks
 Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
CNNS FROM THE BASICS TO RECENT ADVANCES. Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague
 CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset
 Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
A MultiPath Network for Object Detection
 ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
 BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks
 AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks Yao Lu 1, Guangming Lu 1, Yuanrong Xu 1, Bob Zhang 2 1 Shenzhen Graduate School, Harbin Institute of Technology, China 2 Department of
AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks Yao Lu 1, Guangming Lu 1, Yuanrong Xu 1, Bob Zhang 2 1 Shenzhen Graduate School, Harbin Institute of Technology, China 2 Department of
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
arxiv: v3 [cs.cv] 17 May 2018
![arxiv: v3 [cs.cv] 17 May 2018](/thumbs/79/79331767.jpg "arxiv: v3 [cs.cv] 17 May 2018") FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Tiny ImageNet Visual Recognition Challenge
 Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser SUPPLEMENTARY MATERIALS
 Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser SUPPLEMENTARY MATERIALS Fangzhou Liao, Ming Liang, Yinpeng Dong, Tianyu Pang, Xiaolin Hu, Jun Zhu Department of Computer
Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser SUPPLEMENTARY MATERIALS Fangzhou Liao, Ming Liang, Yinpeng Dong, Tianyu Pang, Xiaolin Hu, Jun Zhu Department of Computer
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
arxiv: v1 [cs.cv] 19 Mar 2018
![arxiv: v1 [cs.cv] 19 Mar 2018](/thumbs/78/77646221.jpg "arxiv: v1 [cs.cv] 19 Mar 2018") arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Instance-aware Semantic Segmentation via Multi-task Network Cascades
 Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
WHILE increasingly deeper networks are proposed in the
 LDS-Inspired Residual Networks Anastasios Dimou, Dimitrios Ataloglou, Kosmas Dimitropoulos, Member, IEEE, Federico Alvarez, Member, IEEE, and Petros Daras, Senior Member, IEEE Abstract Residual Networks
LDS-Inspired Residual Networks Anastasios Dimou, Dimitrios Ataloglou, Kosmas Dimitropoulos, Member, IEEE, Federico Alvarez, Member, IEEE, and Petros Daras, Senior Member, IEEE Abstract Residual Networks
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
arxiv: v2 [cs.cv] 10 Oct 2018
![arxiv: v2 [cs.cv] 10 Oct 2018](/thumbs/92/109817158.jpg "arxiv: v2 [cs.cv] 10 Oct 2018") Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
Net: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving Qijie Zhao 1, Tao Sheng 1, Yongtao Wang 1, Feng Ni 1, Ling Cai 2 1 Institute of Computer Science and Technology, Peking
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications
 Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,