Spatial Latent Dirichlet Allocation
|
|
|
- Audrey Dawson
- 5 years ago
- Views:
Transcription
1 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA Abstract In recent years, the language model Latent Dirichlet Allocation (LDA), which clusters co-occurring words into topics, has been widely appled in the computer vision field. However, many of these applications have difficulty with modeling the spatial and temporal structure among visual words, since LDA assumes that a document is a bag-of-words. It is also critical to properly design words and documents when using a language model to solve vision problems. In this paper, we propose a topic model Spatial Latent Dirichlet Allocation (SLDA), which better encodes spatial structure among visual words that are essential for solving many vision problems. The spatial information is not encoded in the value of visual words but in the design of documents. Instead of knowing the partition of words into documents a priori, the word-document assignment becomes a random hidden variable in SLDA. There is a generative procedure, where knowledge of spatial structure can be flexibly added as a prior, grouping visual words which are close in space into the same document. We use SLDA to discover objects from a collection of images, and show it achieves better performance than LDA. 1 Introduction Latent Dirichlet Allocation (LDA) [1] is a language model which clusters co-occurring words into topics. In recent years, LDA has been widely used to solve computer vision problems. For example, LDA was used to discover objects from a collection of images [2, 3] and to classify images into different scene categories [4]. [5] employed LDA to classify human actions. In visual surveillance, LDA was used to model atomic activities and interactions happening in a crowded and busy scene [6]. In these applications, LDA clustered low-level visual words (which were image patches, spatial and temporal interest points or moving pixels) into topics with semantic meanings (which corresponded to objects, parts of objects, human actions or atomic activities) utilizing their co-occurrence information. Even with these promising achievements, however, directly borrowing a language model to solve vision problems has some difficulties. First, LDA assumes that a document is a bag of words, such that spatial and temporal structure among visual words, which are meaningless in a language model but important in many computer vision problems, are ignored. Second, users need to define the meaning of documents in vision problems. The design of documents often implies some assumptions on vision problems. For example, in order to cluster image patches, which are treated as words, into classes of objects, researchers treated images as documents [2]. This assumes that if two types of patches are from the same object class, they often appear in the same images. This assumption is reasonable, but not strong enough. As an example shown in Figure 1, even though the sky is far from the vehicles, if they often exist in the same images in the data set, they would be clustered into the same topic by LDA. Furthermore, since in this image most of the patches are sky and building, a patch on a vehicle is likely to be labeled as building or sky as well. These problems 1

2 Figure 1: There will be some problems (see text) if the whole image is treated as one document when using LDA to discover classes of objects. could be solved if the document of a patch, such as the yellow patch in Figure 1, only includes other patches falling within its neighborhood, marked by the red dashed window in Figure 1, instead of the whole image. So a better assumption is that if two types of image patches are from the same object class, they are not only often in the same images but also close in space. We expect to utilize spatial information in a flexible way when designing documents for solving vision problems. In this paper, we propose a Spatial Latent Dirichlet Allocation (SLDA) model which encodes the spatial structure among visual words. It clusters visual words (e.g. an eye patch and a nose patch), which often occur in the same images and are close in space, into one topic (e.g. face). This is a more proper assumption for solving many vision problems when images often contain several objects. It is also easy for SLDA to model activities and human actions by encoding temporal information. However the spatial or temporal information is not encoded in the value of visual words, but in the design of documents. LDA and its extensions, such as the author-topic model [7], the dynamic topic model [8], and the correlated topic model [9], all assume that the partition of words into documents is known a priori. A key difference of SLDA is that the word-document assignment becomes a hidden random variable. There is a generative procedure to assign words to documents. When visual words are close in space or time, they have a high probability to be grouped into the same document. Some approaches such as [10] could also capture the spatial structure among visual words. This approach assumed that the spatial distribution of an object class could be modeled as Gaussian and needed to know the number of objects in the image. However, usually we do not know the number of objects in the images. It is also hard to model the spatial distributions of many objects, such sky, trees, grass, crowds of pedestrians, or a flock of cows. In our model, there are no such assumptions. Objects could be anywhere in the image and in arbitrary shape. The spatial information is encoded when generating documents but not in the models of object classes. As an example application, we use the SLDA model to discover objects from a collection of images. As shown in Figure 2, there are different classes of objects, such as cows, cars, faces, grasses, sky, bicycles, etc., in the image set. And an image usually contains several objects of different classes. The goal is to segment objects from images, and at the same time, to label these segments as different object classes in an unsupervised way. This integrates object segmentation and recognition. In our approach images are divided into local patches. A local descriptor is computed for each image patch and quantized into a visual word. Using topic models, the visual words are clustered into topics which correspond to object classes. Thus an image patch can be labeled as one of the object classes. Our work is related to [2] which used LDA to cluster image patches. As shown in Figure 2, SLDA achieves much better performance than LDA. We will compare more results of LDA and SLDA in the experimental section. 2 Computation of Visual Words To obtain the local descriptors, images are convolved with the filter bank proposed in [11], which is a combination of 3 Gaussians, 4 Laplacian of Gaussians, and 4 first order derivatives of Gaussians, and was shown to have good performance for object categorization. Instead of only computing visual words at interest points as in [2], we divide an image into local patches on a grid and densely sample a local descriptor for each patch. A codebook of size W is created by clustering all the local descriptors in the image set using -means. Each local patch is quantized into a visual word 2
, the goal is to segment images into")





 in the corpus.")







3 Figure 2: Given a collection of images as shown in the first row (which are selected from MSRC image dataset [11]), the goal is to segment images into objects and cluster these objects into different classes. The second row uses manual segmentation and labeling as ground truth. The third row is the LDA result and the fourth row is the SLDA result. Under the same labeling approach, image patches marked in the same color are in one object cluster, but the meaning of colors changes across different labeling methods. according to the codebook. In the next step, these visual words (image patches) will be further clustered into classes of objects. We will compare two clustering methods, LDA and SLDA. 3 LDA When LDA is used to solve our problem, we treat local patches of images as words and the whole image as a document. The graphical model of LDA is shown in Figure 3 (a). There are M documents (images) in the corpus. Each document j has N j words (image patches). w ji is the observed value of word i in document j. All the words in document j will be clustered into topics (classes of objects). Each topic k is modeled as a multinomial distribution over the codebook. α and β are Dirichlet prior hyperparameters. φ k, π j, and z ji are hidden variables to be inferred. The generative process of LDA is described as following: 1. For a topic k, a multinomial parameter φ k is sampled from Dirichlet prior φ k Dir(β). 2. For a document j, a multinomial parameter π j over the topics is sampled from Dirichlet prior π j Dir(α). 3. For a word i in document j, a topic label z ji is sampled from discrete distribution z ji Discrete(π j ). 4. The value w ji of word i in document j is sampled from the discrete distribution of topic z ji, w ji Discrete(φ zji ). z ji can be sampled through a Gibbs sampling procedure which integrates out π j and φ k [12]. p(z ji = k z ji, w, α, β) n (k) ji,w ji + β wji n (j) ji,k ) W w=1 (n + α k (k) ji,w + β ) (1) w k =1 (n (j) ji,k + α k where n (k) ji,w is the number of words in the corpus with value w assigned to topic k excluding word i in document j, and n (j) ji,k is the number of words in document j assigned to topic k excluding word i in document j. See more details in [12]. Eq 1 is the product of two ratios: the probability 3
4 Figure 3: Graphical model of LDA (a) and SLDA (b). See text for details. of word w ji under topic k and the probability of topic k in document j. So LDA clusters the visual words often co-occurring in the same images into one object class. As shown by some examples in Figure 2 (see more results in the experimental section), there are two problems in using LDA for object segmentation and recognition. The segmentation result is noisy since spatial information is not considered. The patches in the same image are likely to have the same labels. Since the whole image is treated as one document, if one object class, e.g. car in Figure 2, is dominant in the image, the second ratio in Eq 1 will lead to a large bias towards the car class, and thus the patches of street are also likely to be labeled as car. This problem could be solved if a local patch only considers its neighboring patches as being in the same document. 4 SLDA We assume that if visual words are from the same object class, they not only often co-occur in the same images but also are close in space. So we try to group image patches which are close in space into the same documents. One straightforward way is to divide the image into regions as shown in Figure 4 (a). Each region is treated as a document instead of the whole image. However, since these regions are not overlapped, some patches, such as A (red patch) and B (cyan patch) in Figure 4 (a), even though very close in space, are assigned to different documents. In Figure 4 (a), patch A on the cow is likely to be labeled as grass, since most other patches in its document are grass. To solve this problem, we may put many overlapped regions, each of which is a document, on the images as shown in Figure 4 (b). If a patch is inside a region, it could belong to that document. Any two patches whose distance is smaller than the region size could belong to the same document if the regions are placed densely enough. We use the word could because each local patch is covered by several regions, so we have to decide to which document it belongs. Different from the LDA model, in which the word-document relationship is known a priori, we need a generative procedure assigning words to documents. If two patches are closer in space, they have a higher probability to be assigned to the same document since there are more regions covering both of them. Actually we can go even further. As shown in Figure 4 (c), each document can be represented by a point (marked by magenta circle) in the image, assuming its region covers the whole image. If an image patch is close to a document, it has a high probability to be assigned to that document. The graphical model is shown in Figure 3 (b). In SLDA, there are M documents and N words in the corpus. A hidden variable d i indicates to which document word i is assigned. For each document j there is a hyperparameter c d j = ( g d j, xd j, yd j ) known a priori. g d j is the index of the image where document j is placed and ( x d j, yd j ) is the location of the document. For a word i, in addition to the 4
: densely put overlapped regions over images.")
5 Figure 4: There are several ways to add spatial information among image patches when designing documents. (a): Divide the image into regions without overlapping. Each region, marked by a dashed window, corresponds to a document. Image patches inside the region are assigned to the corresponding document. (b): densely put overlapped regions over images. One image patch is covered by multiple regions. (c): Each document is associated with a point (marked in magenta color). These points are densely placed over the image. If a image patch is close to a document, it has a high probability to be assigned to that document. observed word value w i, its location (x i, y i ) and image index g i are also observed and stored in variable c i = (g i, x i, y i ). The generative procedure of SLDA is described as follows. 1. For a topic k, a multinomial parameter φ k is sampled from Dirichlet prior φ k Dir(β). 2. For a document j, a multinomial parameter π j over the topics is sampled from Dirichlet prior π j Dir(α). 3. For a word (image patch) i, a random variable d i is sampled from prior p(d i η) indicating to which document word i is assigned. We choose p(d i η) as a uniform prior. 4. The image index and location of word i is sampled from distribution p(c i c d d i, σ). We may choose this as a Gaussian kernel. { ( ) x d 2 ( ) di x i + y d 2 } di y i p((g i, x i, y i ) ( g d d i, x d d i, y d d i ), σ) δg d di (g i ) exp p(c i c d d i, σ) = 0 if the word and the document are not in the same image. 5. The topic label z i of word i is sampled from the discrete distribution of document d i, z i Discrete(π di ). 6. The value w i of word i is sampled from the discrete distribution of topic z i, w i Discrete(φ zi ). σ Gibbs Sampling z i and d i can be sampled through a Gibbs sampling procedure integrating out φ k and π j. In SLDA the conditional distribution of z i given d i is the same as in LDA. p(z i = k d i = j, d i, z i, w, α, β) n (k) i,w i + β wi n (j) i,k ) W w=1 (n + α k (k) i,w + β ) (2) w k =1 (n (j) i,k + α k where n (k) i,w is the number of words in the corpus with value w assigned to topic k excluding word i, and n (j) i,k is the number of words in document j assigned to topic k excluding word i. This is easy to understand since if the word-document assignment is fixed, SLDA is the same as LDA. In addition, we also need to sample d i from the conditional distribution given z i. p ( d i = j z i = k, z i, d i, c i, {c d j }, α, β, η, σ) p ( d i = j, z i = k, z i d i, c i, {c d j }, α, β, η, σ) p (d i = j η) p ( c i c d j, σ ) p (z i = k, z i d i = j, d i, α) 5
6 p (z i = k, z i d i = j, d i, α) is obtained by integrating out π j. p (z i = k, z i d i = j, d i, α) = = M p(π j α)p(z j π ji )dπ j j =1 M j =1 ( ) Γ k =1 α k k =1 Γ (α k ) ) k =1 (n Γ (j ) k + α k ( ) Γ k =1 n(j k + ). k =1 α k We choose p (d i = j η) as a uniform prior and p ( c i c d j, σ) as a Gaussian kernel. Thus the conditional distribution of d i is p ( d i = j z i = k, z i, d i, c i, {c d j }, α, β, η, σ) δ g d j (g i ) e ( x d j x i) 2 +(y j d y i) 2 n (j) σ 2 i,k + α k ) (3) k =1 (n (j) i,k + α k Word i is likely to be assigned to document j if they are in the same image, close in space and word i has the same topic label as other words in document j. In real applications, we only care about the distribution of z i while d j can be marginalized by simply ignoring its samples. From Eq 2 and 3, we observed that a word tends to have the same topic label as other words in its document and words closer in space are more likely to be assigned to the same documents. So essentially under SLDA a word tends to be labeled as the same topic as other words close to it. This satisfies our assumption that visual words from the same object class are closer in space. Since we densely place many documents over one image, during Gibbs sampling some documents are only assigned a few words and the distributions cannot be well estimated. To solve this problem we replicate each image patch to get many particles. These particles have the same word value and location but can be assigned to different documents and have different labels. Thus each document will have enough samples of words to estimate the distributions. 4.2 Discussion SLDA is a flexible model intended to encode spatial structure among image patches and design documents. If there is only one document placed over one image, SLDA simply reduces to LDA. If p(c i c d j ) is an uniform distribution inside a local region, SLDA implements the scheme described in Figure 4 (b). If these local regions are not overlapped, it is the case of Figure 4 (a). There are also some other ways to add spatial information by choosing different spatial prior p(c i c d j ). In SLDA, the spatial information is used when designing documents. However the object class model φ k, simply a multinomial distribution over the codebook, has no spatial structure. So the objects of a class could be in any shape and anywhere in the images, as long as they smoothly distribute in space. By simply adding a time stamp to c i and c d j, it is easy for SLDA to encode temporal structure among visual words. So SLDA also can be applied to human action and activity analysis. 5 Experiments We test LDA and SLDA on the MSRC image dataset [11] with 240 images. Our codebook size is 200 and the topic number is 15. In Figure 2, we show some examples of results using LDA and SLDA. Colors are used indicate different topics. The results of LDA are noisy and within one image most of the patches are labeled as one topic. SLDA achieves much better results than LDA. The results are smoother and objects are well segmented. The detection rate and false alarm rate of four classes, cows, cars, faces, and bicycles are shown in Table 1. They are counted in pixels. The MSRC images were manually segmented [11] and the segments were labeled as different object classes as shown in Figure 2. We use the manual segmentation and labeling as ground truth. The two models are also tested on a tiger video sequence with 252 frames. We treat all the frames in the sequence as an image collection and ignore their temporal order. Figure 5 shows their results on two sampled frames. We have a supplementary video material showing the results of the whole sequence. Using LDA, usually there are one or two dominant topics distributed like noise in a 6


 0.5576 0.3963 0.5862 0.5285 SLDA(FA) 0.0334 0.2437 0.3714 0.4217 frame. Topics change as the video background changes.")



![Latent dirichlet allocation. Journal of Machine Learning Research, 3:993 1022, 2003. [2] J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman, and W. T.](/docs-images/96/126749917/images/7-6.jpg "Freeman. Discovering object categories in image collections. In Proc. ICCV, 2005. [3] B. C. Russell, A. A. Efros, J. Sivic, W. T. Freeman, and A. Zisserman.")
![Using multiple segmentations to discover objects and their extent in image collections. In Proc. CVPR, 2006. [4] L. Fei-Fei and P. Perona.](/docs-images/96/126749917/images/7-7.jpg "A bayesian hierarchical model for learning natural scene categories. In Proc. CVPR, 2005. [5] J. C. Niebles, H. Wang, and L. Fei-Fei.")
7 Figure 5: Discovering objects from a video sequence. The first column shows two fames in the video sequence. In the second column, we label the patches in the two frames as different topics using LDA. The thrid column plots the topic labels using SLDA. The red color indicates the topic of tigers. In the fourth column, we segment tigers out by choosing all the patches of the topic marked by red color. Please see the result of the whole video sequence in our supplementary video. Table 1: Detection(D) rate and False Alarm (FA) rate of LDA and SLDA on MSRC cows cars faces bicycles LDA(D) SLDA(D) LDA(FA) SLDA(FA) frame. Topics change as the video background changes. LDA cannot segment out any objects. SLDA clusters image patches into tigers, rock, water, and grass. If we choose the topic of tiger, as shown in the last row of Figure 5, all the tigers in the video can be segmented out. 6 Conclusion We propose a novel Spatial Latent Dirichlet Allocation model which clusters co-occurring and spatially neighboring visual words into the same topic. Instead of knowing word-document assignment a priori, SLDA has a generative procedure partitioning visual words which are close in space into the same documents. It is also easy to extend SLDA to including temporal information. References [1] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation. Journal of Machine Learning Research, 3: , [2] J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman, and W. T. Freeman. Discovering object categories in image collections. In Proc. ICCV, [3] B. C. Russell, A. A. Efros, J. Sivic, W. T. Freeman, and A. Zisserman. Using multiple segmentations to discover objects and their extent in image collections. In Proc. CVPR, [4] L. Fei-Fei and P. Perona. A bayesian hierarchical model for learning natural scene categories. In Proc. CVPR, [5] J. C. Niebles, H. Wang, and L. Fei-Fei. Unsupervised learning of human action categories using spatialtemporal words. In Proc. BMVC, [6] X. Wang, X. Ma, and E. Grimson. Unsupervised activity perception by hierarchical bayesian models. In Proc. CVPR, [7] M. Rosen-Zvi, T. Griffiths, M. Steyvers, and P. Smyth. The author-topic model for authors and documents. In Proc. of Uncertainty in Artificial Intelligence, [8] D. Blei and J. Lafferty. Dynamic topic models. In Proc. ICML,
")













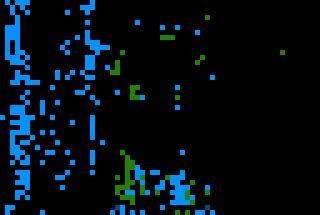
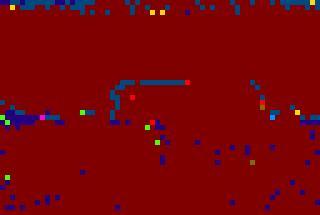


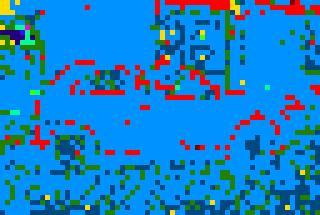
















8 (a) (b) (c) Figure 6: Examples of experimetnal results on MSRC image data set. (a): original images; (b): LDA results; (c) SLDA results. [9] D. Blei and J. Lafferty. Correlated topic models. In Proc. NIPS, [10] E. B. Sudderth, A. Torralba, W. T. Freeman, and A. S. Willsky. Learning hierarchical models of scenes, objects, and parts. In Proc. ICCV, [11] J. Winn, A. Criminisi, and T. Minka. Object categorization by learned universal visual dictionary. In Proc. ICCV, [12] T. Griffiths and M. Steyvers. Finding scientific topics. In Proc. of the National Academy of Sciences,
Probabilistic Generative Models for Machine Vision
 Probabilistic Generative Models for Machine Vision bacciu@di.unipi.it Dipartimento di Informatica Università di Pisa Corso di Intelligenza Artificiale Prof. Alessandro Sperduti Università degli Studi di
Probabilistic Generative Models for Machine Vision bacciu@di.unipi.it Dipartimento di Informatica Università di Pisa Corso di Intelligenza Artificiale Prof. Alessandro Sperduti Università degli Studi di
A Shape Aware Model for semi-supervised Learning of Objects and its Context
 A Shape Aware Model for semi-supervised Learning of Objects and its Context Abhinav Gupta 1, Jianbo Shi 2 and Larry S. Davis 1 1 Dept. of Computer Science, Univ. of Maryland, College Park 2 Dept. of Computer
A Shape Aware Model for semi-supervised Learning of Objects and its Context Abhinav Gupta 1, Jianbo Shi 2 and Larry S. Davis 1 1 Dept. of Computer Science, Univ. of Maryland, College Park 2 Dept. of Computer
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Using Multiple Segmentations to Discover Objects and their Extent in Image Collections
 Using Multiple Segmentations to Discover Objects and their Extent in Image Collections Bryan C. Russell 1 Alexei A. Efros 2 Josef Sivic 3 William T. Freeman 1 Andrew Zisserman 3 1 CS and AI Laboratory
Using Multiple Segmentations to Discover Objects and their Extent in Image Collections Bryan C. Russell 1 Alexei A. Efros 2 Josef Sivic 3 William T. Freeman 1 Andrew Zisserman 3 1 CS and AI Laboratory
Unsupervised Learning of Categorical Segments in Image Collections
 IEEE TRANSACTION ON PATTERN ANALYSIS & MACHINE INTELLIGENCE, VOL. X, NO. X, SEPT XXXX 1 Unsupervised Learning of Categorical Segments in Image Collections Marco Andreetto, Lihi Zelnik-Manor, Pietro Perona,
IEEE TRANSACTION ON PATTERN ANALYSIS & MACHINE INTELLIGENCE, VOL. X, NO. X, SEPT XXXX 1 Unsupervised Learning of Categorical Segments in Image Collections Marco Andreetto, Lihi Zelnik-Manor, Pietro Perona,
Nonparametric Bayesian Texture Learning and Synthesis
 Appears in Advances in Neural Information Processing Systems (NIPS) 2009. Nonparametric Bayesian Texture Learning and Synthesis Long (Leo) Zhu 1 Yuanhao Chen 2 William Freeman 1 Antonio Torralba 1 1 CSAIL,
Appears in Advances in Neural Information Processing Systems (NIPS) 2009. Nonparametric Bayesian Texture Learning and Synthesis Long (Leo) Zhu 1 Yuanhao Chen 2 William Freeman 1 Antonio Torralba 1 1 CSAIL,
Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model
 Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model Xiaogang Wang 1 Keng Teck Ma 2 Gee-Wah Ng 2 W. Eric L. Grimson 1 1 CS and AI Lab, MIT, 77 Massachusetts Ave., Cambridge,
Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model Xiaogang Wang 1 Keng Teck Ma 2 Gee-Wah Ng 2 W. Eric L. Grimson 1 1 CS and AI Lab, MIT, 77 Massachusetts Ave., Cambridge,
Efficient Kernels for Identifying Unbounded-Order Spatial Features
 Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Integrating Image Clustering and Codebook Learning
 Integrating Image Clustering and Codebook Learning Pengtao Xie and Eric Xing {pengtaox,epxing}@cs.cmu.edu School of Computer Science, Carnegie Mellon University 5000 Forbes Ave, Pittsburgh, PA 15213 Abstract
Integrating Image Clustering and Codebook Learning Pengtao Xie and Eric Xing {pengtaox,epxing}@cs.cmu.edu School of Computer Science, Carnegie Mellon University 5000 Forbes Ave, Pittsburgh, PA 15213 Abstract
Geometric LDA: A Generative Model for Particular Object Discovery
 Geometric LDA: A Generative Model for Particular Object Discovery James Philbin 1 Josef Sivic 2 Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering Science, University of Oxford 2 INRIA,
Geometric LDA: A Generative Model for Particular Object Discovery James Philbin 1 Josef Sivic 2 Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering Science, University of Oxford 2 INRIA,
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition
 Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Comparing Local Feature Descriptors in plsa-based Image Models
 Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
CRFs for Image Classification
 CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
HIGH spatial resolution Earth Observation (EO) images
 images") JOURNAL OF L A TEX CLASS FILES, VOL. 6, NO., JANUARY 7 A Comparative Study of Bag-of-Words and Bag-of-Topics Models of EO Image Patches Reza Bahmanyar, Shiyong Cui, and Mihai Datcu, Fellow, IEEE Abstract
JOURNAL OF L A TEX CLASS FILES, VOL. 6, NO., JANUARY 7 A Comparative Study of Bag-of-Words and Bag-of-Topics Models of EO Image Patches Reza Bahmanyar, Shiyong Cui, and Mihai Datcu, Fellow, IEEE Abstract
Continuous Visual Vocabulary Models for plsa-based Scene Recognition
 Continuous Visual Vocabulary Models for plsa-based Scene Recognition Eva Hörster Multimedia Computing Lab University of Augsburg Augsburg, Germany hoerster@informatik.uniaugsburg.de Rainer Lienhart Multimedia
Continuous Visual Vocabulary Models for plsa-based Scene Recognition Eva Hörster Multimedia Computing Lab University of Augsburg Augsburg, Germany hoerster@informatik.uniaugsburg.de Rainer Lienhart Multimedia
Artistic ideation based on computer vision methods
 Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Unsupervised Discovery of Object Classes from Range Data using Latent Dirichlet Allocation
 Robotics: Science and Systems 2009 Seattle, WA, USA, June 28 - July 1, 2009 Unsupervised Discovery of Obect Classes from Range Data using Latent Dirichlet Allocation Felix Endres Christian Plagemann Cyrill
Robotics: Science and Systems 2009 Seattle, WA, USA, June 28 - July 1, 2009 Unsupervised Discovery of Obect Classes from Range Data using Latent Dirichlet Allocation Felix Endres Christian Plagemann Cyrill
Author name(s) Book title. Monograph. October 25, Springer
 Book title. Monograph. October 25, Springer") Author name(s) Book title Monograph October 25, 2010 Springer Contents Part I Part Title 1 Semantic Object Segmentation... 3 1.1 Introduction..... 3 1.2 Local Visual Cues..... 7 1.2.1 Filter-banks and
Author name(s) Book title Monograph October 25, 2010 Springer Contents Part I Part Title 1 Semantic Object Segmentation... 3 1.1 Introduction..... 3 1.2 Local Visual Cues..... 7 1.2.1 Filter-banks and
Scalable Object Classification using Range Images
 Scalable Object Classification using Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems University of Southern California 1 What is a Range Image? Depth measurement
Scalable Object Classification using Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems University of Southern California 1 What is a Range Image? Depth measurement
Visual Object Recognition
 Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Partitioning Algorithms for Improving Efficiency of Topic Modeling Parallelization
 Partitioning Algorithms for Improving Efficiency of Topic Modeling Parallelization Hung Nghiep Tran University of Information Technology VNU-HCMC Vietnam Email: nghiepth@uit.edu.vn Atsuhiro Takasu National
Partitioning Algorithms for Improving Efficiency of Topic Modeling Parallelization Hung Nghiep Tran University of Information Technology VNU-HCMC Vietnam Email: nghiepth@uit.edu.vn Atsuhiro Takasu National
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Towards Total Scene Understanding: Classification, Annotation and Segmentation in an Automatic Framework
 Towards Total Scene Understanding: Classification, Annotation and Segmentation in an Automatic Framework Li-Jia Li Dept. of Computer Science Princeton University, USA jial@princeton.edu Richard Socher
Towards Total Scene Understanding: Classification, Annotation and Segmentation in an Automatic Framework Li-Jia Li Dept. of Computer Science Princeton University, USA jial@princeton.edu Richard Socher
A bipartite graph model for associating images and text
 A bipartite graph model for associating images and text S H Srinivasan Technology Research Group Yahoo, Bangalore, India. shs@yahoo-inc.com Malcolm Slaney Yahoo Research Lab Yahoo, Sunnyvale, USA. malcolm@ieee.org
A bipartite graph model for associating images and text S H Srinivasan Technology Research Group Yahoo, Bangalore, India. shs@yahoo-inc.com Malcolm Slaney Yahoo Research Lab Yahoo, Sunnyvale, USA. malcolm@ieee.org
Semantic Image Retrieval Using Correspondence Topic Model with Background Distribution
 Semantic Image Retrieval Using Correspondence Topic Model with Background Distribution Nguyen Anh Tu Department of Computer Engineering Kyung Hee University, Korea Email: tunguyen@oslab.khu.ac.kr Jinsung
Semantic Image Retrieval Using Correspondence Topic Model with Background Distribution Nguyen Anh Tu Department of Computer Engineering Kyung Hee University, Korea Email: tunguyen@oslab.khu.ac.kr Jinsung
Recognition with Bag-ofWords. (Borrowing heavily from Tutorial Slides by Li Fei-fei)
") Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Characterizing Layouts of Outdoor Scenes Using Spatial Topic Processes
 Characterizing Layouts of Outdoor Scenes Using Spatial Topic Processes Dahua Lin TTI Chicago dhlin@ttic.edu Jianxiong iao Princeton University xj@princeton.edu Abstract In this paper, we develop a generative
Characterizing Layouts of Outdoor Scenes Using Spatial Topic Processes Dahua Lin TTI Chicago dhlin@ttic.edu Jianxiong iao Princeton University xj@princeton.edu Abstract In this paper, we develop a generative
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Computer Vision. Exercise Session 10 Image Categorization
 Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Semantic Segmentation. Zhongang Qi
 Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
Learning Better Image Representations Using Flobject Analysis
 Learning Better Image Representations Using Flobject Analysis Patrick S. Li, Inmar E. Givoni, Brendan J. Frey University of Toronto {pli,inmar,frey}@psi.utoronto.ca Abstract (a) (b) Unsupervised learning
Learning Better Image Representations Using Flobject Analysis Patrick S. Li, Inmar E. Givoni, Brendan J. Frey University of Toronto {pli,inmar,frey}@psi.utoronto.ca Abstract (a) (b) Unsupervised learning
Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words
 DOI 10.1007/s11263-007-0122-4 Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words Juan Carlos Niebles Hongcheng Wang Li Fei-Fei Received: 16 March 2007 / Accepted: 26 December
DOI 10.1007/s11263-007-0122-4 Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words Juan Carlos Niebles Hongcheng Wang Li Fei-Fei Received: 16 March 2007 / Accepted: 26 December
Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover
 Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover Devi Parikh and Tsuhan Chen Carnegie Mellon University {dparikh,tsuhan}@cmu.edu Abstract. Given a collection of
Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover Devi Parikh and Tsuhan Chen Carnegie Mellon University {dparikh,tsuhan}@cmu.edu Abstract. Given a collection of
Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison*
 Tracking Trends: Incorporating Term Volume into Temporal Topic Models Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison* Dept. of Computer Science and Engineering, Lehigh University, Bethlehem, PA,
Tracking Trends: Incorporating Term Volume into Temporal Topic Models Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison* Dept. of Computer Science and Engineering, Lehigh University, Bethlehem, PA,
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Determining Patch Saliency Using Low-Level Context
 Determining Patch Saliency Using Low-Level Context Devi Parikh 1, C. Lawrence Zitnick 2, and Tsuhan Chen 1 1 Carnegie Mellon University, Pittsburgh, PA, USA 2 Microsoft Research, Redmond, WA, USA Abstract.
Determining Patch Saliency Using Low-Level Context Devi Parikh 1, C. Lawrence Zitnick 2, and Tsuhan Chen 1 1 Carnegie Mellon University, Pittsburgh, PA, USA 2 Microsoft Research, Redmond, WA, USA Abstract.
Automatic Learning Image Objects via Incremental Model
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 14, Issue 3 (Sep. - Oct. 2013), PP 70-78 Automatic Learning Image Objects via Incremental Model L. Ramadevi 1,
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 14, Issue 3 (Sep. - Oct. 2013), PP 70-78 Automatic Learning Image Objects via Incremental Model L. Ramadevi 1,
Frequency analysis, pyramids, texture analysis, applications (face detection, category recognition)
") Frequency analysis, pyramids, texture analysis, applications (face detection, category recognition) Outline Measuring frequencies in images: Definitions, properties Sampling issues Relation with Gaussian
Frequency analysis, pyramids, texture analysis, applications (face detection, category recognition) Outline Measuring frequencies in images: Definitions, properties Sampling issues Relation with Gaussian
Texton Clustering for Local Classification using Scene-Context Scale
 Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Hierarchical Multiclass Object Classification
 Hierarchical Multiclass Object Classification Fereshte Khani Massachusetts Institute of Technology fereshte@mit.edu Anurag Mukkara Massachusetts Institute of Technology anurag m@mit.edu Abstract Humans
Hierarchical Multiclass Object Classification Fereshte Khani Massachusetts Institute of Technology fereshte@mit.edu Anurag Mukkara Massachusetts Institute of Technology anurag m@mit.edu Abstract Humans
A Novel LDA and HMM-based technique for Emotion Recognition from Facial Expressions
 A Novel LDA and HMM-based technique for Emotion Recognition from Facial Expressions Akhil Bansal, Santanu Chaudhary, Sumantra Dutta Roy Indian Institute of Technology, Delhi, India akhil.engg86@gmail.com,
A Novel LDA and HMM-based technique for Emotion Recognition from Facial Expressions Akhil Bansal, Santanu Chaudhary, Sumantra Dutta Roy Indian Institute of Technology, Delhi, India akhil.engg86@gmail.com,
Using Maximum Entropy for Automatic Image Annotation
 Using Maximum Entropy for Automatic Image Annotation Jiwoon Jeon and R. Manmatha Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst Amherst, MA-01003.
Using Maximum Entropy for Automatic Image Annotation Jiwoon Jeon and R. Manmatha Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst Amherst, MA-01003.
Interactive Construction of Visual Concepts for Image Annotation and Retrieval
 for Image Annotation and Retrieval Hugo Jair Escalante Universidad Autónoma de Nuevo León, Graduate Program in Systems Engineering, San Nicolás de los Garza, NL 66450, México hugo.jair@gmail.com, J. Antonio
for Image Annotation and Retrieval Hugo Jair Escalante Universidad Autónoma de Nuevo León, Graduate Program in Systems Engineering, San Nicolás de los Garza, NL 66450, México hugo.jair@gmail.com, J. Antonio
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Unsupervised Learning of Visual Taxonomies
 Unsupervised Learning of Visual Taxonomies Evgeniy Bart Caltech Pasadena, CA 91125 bart@caltech.edu Ian Porteous UC Irvine Irvine, CA 92697 iporteou@ics.uci.edu Pietro Perona Caltech Pasadena, CA 91125
Unsupervised Learning of Visual Taxonomies Evgeniy Bart Caltech Pasadena, CA 91125 bart@caltech.edu Ian Porteous UC Irvine Irvine, CA 92697 iporteou@ics.uci.edu Pietro Perona Caltech Pasadena, CA 91125
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Using the Forest to See the Trees: Context-based Object Recognition
 Using the Forest to See the Trees: Context-based Object Recognition Bill Freeman Joint work with Antonio Torralba and Kevin Murphy Computer Science and Artificial Intelligence Laboratory MIT A computer
Using the Forest to See the Trees: Context-based Object Recognition Bill Freeman Joint work with Antonio Torralba and Kevin Murphy Computer Science and Artificial Intelligence Laboratory MIT A computer
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Real-Time Anomaly Detection and Localization in Crowded Scenes
 Real-Time Anomaly Detection and Localization in Crowded Scenes Mohammad Sabokrou 1, Mahmood Fathy 2, Mojtaba Hoseini 1, Reinhard Klette 3 1 Malek Ashtar University of Technology, Tehran, Iran 2 Iran University
Real-Time Anomaly Detection and Localization in Crowded Scenes Mohammad Sabokrou 1, Mahmood Fathy 2, Mojtaba Hoseini 1, Reinhard Klette 3 1 Malek Ashtar University of Technology, Tehran, Iran 2 Iran University
Feature Selection using Constellation Models
 Feature Selection using Constellation Models Heydar Maboudi Afkham, Carl Herik Ek and Stefan Calsson Computer Vision and Active Perception Lab. Royal Institute of Technology (KTH) Stockholm, Sweden {heydarma,chek,stefanc}@csc.kth.se
Feature Selection using Constellation Models Heydar Maboudi Afkham, Carl Herik Ek and Stefan Calsson Computer Vision and Active Perception Lab. Royal Institute of Technology (KTH) Stockholm, Sweden {heydarma,chek,stefanc}@csc.kth.se
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Parallelism for LDA Yang Ruan, Changsi An
 Parallelism for LDA Yang Ruan, Changsi An (yangruan@indiana.edu, anch@indiana.edu) 1. Overview As parallelism is very important for large scale of data, we want to use different technology to parallelize
Parallelism for LDA Yang Ruan, Changsi An (yangruan@indiana.edu, anch@indiana.edu) 1. Overview As parallelism is very important for large scale of data, we want to use different technology to parallelize
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Improving Performance of Topic Models by Variable Grouping
 Improving Performance of Topic Models by Variable Grouping Evgeniy Bart Palo Alto Research Center Palo Alto, CA 94394 bart@parc.com Abstract Topic models have a wide range of applications, including modeling
Improving Performance of Topic Models by Variable Grouping Evgeniy Bart Palo Alto Research Center Palo Alto, CA 94394 bart@parc.com Abstract Topic models have a wide range of applications, including modeling
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University
 Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
A Markov Clustering Topic Model for Mining Behaviour in Video
 A Markov Clustering Topic Model for Mining Behaviour in Video Timothy Hospedales, Shaogang Gong and Tao Xiang School of Electronic Engineering and Computer Science Queen Mary University of London, London
A Markov Clustering Topic Model for Mining Behaviour in Video Timothy Hospedales, Shaogang Gong and Tao Xiang School of Electronic Engineering and Computer Science Queen Mary University of London, London
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Unsupervised Learning: Kmeans, GMM, EM Readings: Barber 20.1-20.3 Stefan Lee Virginia Tech Tasks Supervised Learning x Classification y Discrete x Regression
ECE 5424: Introduction to Machine Learning Topics: Unsupervised Learning: Kmeans, GMM, EM Readings: Barber 20.1-20.3 Stefan Lee Virginia Tech Tasks Supervised Learning x Classification y Discrete x Regression
Multi-Class Video Co-Segmentation with a Generative Multi-Video Model
 2013 IEEE Conference on Computer Vision and Pattern Recognition Multi-Class Video Co-Segmentation with a Generative Multi-Video Model Wei-Chen Chiu Mario Fritz Max Planck Institute for Informatics, Saarbrücken,
2013 IEEE Conference on Computer Vision and Pattern Recognition Multi-Class Video Co-Segmentation with a Generative Multi-Video Model Wei-Chen Chiu Mario Fritz Max Planck Institute for Informatics, Saarbrücken,
OBJECT CATEGORIZATION
 OBJECT CATEGORIZATION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it Slides: Ing. Lamberto Ballan November 18th, 2009 What is an Object? Merriam-Webster Definition: Something material that may be
OBJECT CATEGORIZATION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it Slides: Ing. Lamberto Ballan November 18th, 2009 What is an Object? Merriam-Webster Definition: Something material that may be
Factorizing Appearance Using Epitomic Flobject Analysis
 Factorizing Appearance Using Epitomic Flobect Analysis Patrick S. Li University of California, Berkeley patrickli.2001@gmail.com Brendan J. Frey University of Toronto frey@psi.utoronto.ca Abstract Image
Factorizing Appearance Using Epitomic Flobect Analysis Patrick S. Li University of California, Berkeley patrickli.2001@gmail.com Brendan J. Frey University of Toronto frey@psi.utoronto.ca Abstract Image
Spatial-Temporal correlatons for unsupervised action classification
 Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Combining Appearance and Structure from Motion Features for Road Scene Understanding
 STURGESS et al.: COMBINING APPEARANCE AND SFM FEATURES 1 Combining Appearance and Structure from Motion Features for Road Scene Understanding Paul Sturgess paul.sturgess@brookes.ac.uk Karteek Alahari karteek.alahari@brookes.ac.uk
STURGESS et al.: COMBINING APPEARANCE AND SFM FEATURES 1 Combining Appearance and Structure from Motion Features for Road Scene Understanding Paul Sturgess paul.sturgess@brookes.ac.uk Karteek Alahari karteek.alahari@brookes.ac.uk
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Integrating co-occurrence and spatial contexts on patch-based scene segmentation
 Integrating co-occurrence and spatial contexts on patch-based scene segmentation Florent Monay, Pedro Quelhas, Jean-Marc Odobez, Daniel Gatica-Perez IDIAP Research Institute, Martigny, Switzerland Ecole
Integrating co-occurrence and spatial contexts on patch-based scene segmentation Florent Monay, Pedro Quelhas, Jean-Marc Odobez, Daniel Gatica-Perez IDIAP Research Institute, Martigny, Switzerland Ecole
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Unusual Activity Analysis using Video Epitomes and plsa
 Unusual Activity Analysis using Video Epitomes and plsa Ayesha Choudhary 1 Manish Pal 1 Subhashis Banerjee 1 Santanu Chaudhury 2 1 Dept. of Computer Science and Engineering, 2 Dept. of Electrical Engineering
Unusual Activity Analysis using Video Epitomes and plsa Ayesha Choudhary 1 Manish Pal 1 Subhashis Banerjee 1 Santanu Chaudhury 2 1 Dept. of Computer Science and Engineering, 2 Dept. of Electrical Engineering
Pattern recognition (3)
") Pattern recognition (3) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier Building
Pattern recognition (3) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier Building
Sparse Coding and Dictionary Learning for Image Analysis
 Sparse Coding and Dictionary Learning for Image Analysis Part IV: Recent Advances in Computer Vision and New Models Francis Bach, Julien Mairal, Jean Ponce and Guillermo Sapiro CVPR 10 tutorial, San Francisco,
Sparse Coding and Dictionary Learning for Image Analysis Part IV: Recent Advances in Computer Vision and New Models Francis Bach, Julien Mairal, Jean Ponce and Guillermo Sapiro CVPR 10 tutorial, San Francisco,
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Scalable Object Classification in Range Images
 Scalable Object Classification in Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems USC Viterbi School of Engineering University of Southern California Los Angeles,
Scalable Object Classification in Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems USC Viterbi School of Engineering University of Southern California Los Angeles,
Discovering Primitive Action Categories by Leveraging Relevant Visual Context
 Discovering Primitive Action Categories by Leveraging Relevant Visual Context Kris M. Kitani, Takahiro Okabe, Yoichi Sato The University of Tokyo Institute of Industrial Science Tokyo 158-8505, Japan {kitani,
Discovering Primitive Action Categories by Leveraging Relevant Visual Context Kris M. Kitani, Takahiro Okabe, Yoichi Sato The University of Tokyo Institute of Industrial Science Tokyo 158-8505, Japan {kitani,
Contextual priming for artificial visual perception
 Contextual priming for artificial visual perception Hervé Guillaume 1, Nathalie Denquive 1, Philippe Tarroux 1,2 1 LIMSI-CNRS BP 133 F-91403 Orsay cedex France 2 ENS 45 rue d Ulm F-75230 Paris cedex 05
Contextual priming for artificial visual perception Hervé Guillaume 1, Nathalie Denquive 1, Philippe Tarroux 1,2 1 LIMSI-CNRS BP 133 F-91403 Orsay cedex France 2 ENS 45 rue d Ulm F-75230 Paris cedex 05
Unsupervised Learning of Visual Taxonomies
 Unsupervised Learning of Visual Taxonomies Evgeniy Bart Caltech Pasadena, CA 91125 bart@caltech.edu Ian Porteous UC Irvine Irvine, CA 92697 iporteou@ics.uci.edu Pietro Perona Caltech Pasadena, CA 91125
Unsupervised Learning of Visual Taxonomies Evgeniy Bart Caltech Pasadena, CA 91125 bart@caltech.edu Ian Porteous UC Irvine Irvine, CA 92697 iporteou@ics.uci.edu Pietro Perona Caltech Pasadena, CA 91125
Random Field Topic Model for Semantic Region Analysis in Crowded Scenes from Tracklets
 Random Field Topic Model for Semantic Region Analysis in Crowded Scenes from Tracklets Bolei Zhou, Xiaogang Wang 2,3, and Xiaoou Tang,3 Department of Information Engineering, The Chinese University of
Random Field Topic Model for Semantic Region Analysis in Crowded Scenes from Tracklets Bolei Zhou, Xiaogang Wang 2,3, and Xiaoou Tang,3 Department of Information Engineering, The Chinese University of
One-Shot Learning with a Hierarchical Nonparametric Bayesian Model
 One-Shot Learning with a Hierarchical Nonparametric Bayesian Model R. Salakhutdinov, J. Tenenbaum and A. Torralba MIT Technical Report, 2010 Presented by Esther Salazar Duke University June 10, 2011 E.
One-Shot Learning with a Hierarchical Nonparametric Bayesian Model R. Salakhutdinov, J. Tenenbaum and A. Torralba MIT Technical Report, 2010 Presented by Esther Salazar Duke University June 10, 2011 E.
arxiv: v1 [cs.cv] 21 Nov 2015 Abstract
![arxiv: v1 [cs.cv] 21 Nov 2015 Abstract](/thumbs/83/87982198.jpg "arxiv: v1 [cs.cv] 21 Nov 2015 Abstract") Real-Time Anomaly Detection and Localization in Crowded Scenes Mohammad Sabokrou 1, Mahmood Fathy 2, Mojtaba Hoseini 1, Reinhard Klette 3 1 Malek Ashtar University of Technology, Tehran, Iran 2 Iran University
Real-Time Anomaly Detection and Localization in Crowded Scenes Mohammad Sabokrou 1, Mahmood Fathy 2, Mojtaba Hoseini 1, Reinhard Klette 3 1 Malek Ashtar University of Technology, Tehran, Iran 2 Iran University
Using Geometric Blur for Point Correspondence
 1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
Class 9 Action Recognition
 Class 9 Action Recognition Liangliang Cao, April 4, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual Recognition
Class 9 Action Recognition Liangliang Cao, April 4, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual Recognition
A Probabilistic Model for Recursive Factorized Image Features
 A Probabilistic Model for Recursive Factorized Image Features Sergey Karayev 1 Mario Fritz 1,2 Sanja Fidler 1,3 Trevor Darrell 1 1 UC Berkeley and ICSI Berkeley, CA 2 MPI Informatics Saarbrücken, Germany
A Probabilistic Model for Recursive Factorized Image Features Sergey Karayev 1 Mario Fritz 1,2 Sanja Fidler 1,3 Trevor Darrell 1 1 UC Berkeley and ICSI Berkeley, CA 2 MPI Informatics Saarbrücken, Germany
Visual words. Map high-dimensional descriptors to tokens/words by quantizing the feature space.
 Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
Text Document Clustering Using DPM with Concept and Feature Analysis
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Probabilistic Latent Sequential Motifs: Discovering temporal activity patterns in video scenes
 VARADARAJAN, EMONET, ODOBEZ: PROBABILISTIC LATENT SEQUENTIAL MOTIFS 1 Probabilistic Latent Sequential Motifs: Discovering temporal activity patterns in video scenes Jagannadan Varadarajan 12 varadarajan.jagannadan@idiap.ch
VARADARAJAN, EMONET, ODOBEZ: PROBABILISTIC LATENT SEQUENTIAL MOTIFS 1 Probabilistic Latent Sequential Motifs: Discovering temporal activity patterns in video scenes Jagannadan Varadarajan 12 varadarajan.jagannadan@idiap.ch
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling
 Learning a Dictionary of Shape Epitomes with Applications to Image Labeling Liang-Chieh Chen 1, George Papandreou 2, and Alan L. Yuille 1,2 Departments of Computer Science 1 and Statistics 2, UCLA lcchen@cs.ucla.edu,
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling Liang-Chieh Chen 1, George Papandreou 2, and Alan L. Yuille 1,2 Departments of Computer Science 1 and Statistics 2, UCLA lcchen@cs.ucla.edu,
Discriminative Object Class Models of Appearance and Shape by Correlatons
 Discriminative Object Class Models of Appearance and Shape by Correlatons S. Savarese, J. Winn, A. Criminisi University of Illinois at Urbana-Champaign Microsoft Research Ltd., Cambridge, CB3 0FB, United
Discriminative Object Class Models of Appearance and Shape by Correlatons S. Savarese, J. Winn, A. Criminisi University of Illinois at Urbana-Champaign Microsoft Research Ltd., Cambridge, CB3 0FB, United
Learning Compact Visual Attributes for Large-scale Image Classification
 Learning Compact Visual Attributes for Large-scale Image Classification Yu Su and Frédéric Jurie GREYC CNRS UMR 6072, University of Caen Basse-Normandie, Caen, France {yu.su,frederic.jurie}@unicaen.fr
Learning Compact Visual Attributes for Large-scale Image Classification Yu Su and Frédéric Jurie GREYC CNRS UMR 6072, University of Caen Basse-Normandie, Caen, France {yu.su,frederic.jurie}@unicaen.fr
arxiv: v1 [cs.cv] 7 Aug 2017
![arxiv: v1 [cs.cv] 7 Aug 2017](/thumbs/81/83599070.jpg "arxiv: v1 [cs.cv] 7 Aug 2017") LEARNING TO SEGMENT ON TINY DATASETS: A NEW SHAPE MODEL Maxime Tremblay, André Zaccarin Computer Vision and Systems Laboratory, Université Laval Quebec City (QC), Canada arxiv:1708.02165v1 [cs.cv] 7 Aug
LEARNING TO SEGMENT ON TINY DATASETS: A NEW SHAPE MODEL Maxime Tremblay, André Zaccarin Computer Vision and Systems Laboratory, Université Laval Quebec City (QC), Canada arxiv:1708.02165v1 [cs.cv] 7 Aug
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology
 Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
Latent Topic Model Based on Gaussian-LDA for Audio Retrieval
 Latent Topic Model Based on Gaussian-LDA for Audio Retrieval Pengfei Hu, Wenju Liu, Wei Jiang, and Zhanlei Yang National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy
Latent Topic Model Based on Gaussian-LDA for Audio Retrieval Pengfei Hu, Wenju Liu, Wei Jiang, and Zhanlei Yang National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy
Kernel Codebooks for Scene Categorization
 Kernel Codebooks for Scene Categorization Jan C. van Gemert, Jan-Mark Geusebroek, Cor J. Veenman, and Arnold W.M. Smeulders Intelligent Systems Lab Amsterdam (ISLA), University of Amsterdam, Kruislaan
Kernel Codebooks for Scene Categorization Jan C. van Gemert, Jan-Mark Geusebroek, Cor J. Veenman, and Arnold W.M. Smeulders Intelligent Systems Lab Amsterdam (ISLA), University of Amsterdam, Kruislaan
Object Classification for Video Surveillance
 Object Classification for Video Surveillance Rogerio Feris IBM TJ Watson Research Center rsferis@us.ibm.com http://rogerioferis.com 1 Outline Part I: Object Classification in Far-field Video Part II: Large
Object Classification for Video Surveillance Rogerio Feris IBM TJ Watson Research Center rsferis@us.ibm.com http://rogerioferis.com 1 Outline Part I: Object Classification in Far-field Video Part II: Large
Multiple cosegmentation
 Armand Joulin, Francis Bach and Jean Ponce. INRIA -Ecole Normale Supérieure April 25, 2012 Segmentation Introduction Segmentation Supervised and weakly-supervised segmentation Cosegmentation Segmentation
Armand Joulin, Francis Bach and Jean Ponce. INRIA -Ecole Normale Supérieure April 25, 2012 Segmentation Introduction Segmentation Supervised and weakly-supervised segmentation Cosegmentation Segmentation
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Detecting Multiple Symmetries with Extended SIFT
 1 Detecting Multiple Symmetries with Extended SIFT 2 3 Anonymous ACCV submission Paper ID 388 4 5 6 7 8 9 10 11 12 13 14 15 16 Abstract. This paper describes an effective method for detecting multiple
1 Detecting Multiple Symmetries with Extended SIFT 2 3 Anonymous ACCV submission Paper ID 388 4 5 6 7 8 9 10 11 12 13 14 15 16 Abstract. This paper describes an effective method for detecting multiple
The SIFT (Scale Invariant Feature
 The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical