Boosted Multiple Deformable Trees for Parsing Human Poses
|
|
|
- Cecily Howard
- 5 years ago
- Views:
Transcription
1 Boosted Multiple Deformable Trees for Parsing Human Poses Yang Wang and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada Abstract. Tree-structured models have been widely used for human pose estimation, in either 2D or 3D. While such models allow efficient learning and inference, they fail to capture additional dependencies between body parts, other than kinematic constraints. In this paper, we consider the use of multiple tree models, rather than a single tree model for human pose estimation. Our model can alleviate the limitations of a single tree-structured model by combining information provided across different tree models. The parameters of each individual tree model are trained via standard learning algorithms in a single tree-structured model. Different tree models are combined in a discriminative fashion by a boosting procedure. We present experimental results showing the improvement of our model over previous approaches on a very challenging dataset. 1 Introduction Estimating human body poses from still images is arguably one of the most difficult object recognition problems in computer vision. The difficulties of this problem are manifold humans are articulated objects, and can bend and contort their bodies into a wide variety of poses; the parts which make up a human figure are varied in appearance (due to clothing), which makes them difficult to reliably detect; and parts often have small support in the image or are occluded. In order to reliably interpret still images of human figures, it is likely that multiple cues relating different parts of the figure will need to be exploited. Many existing approaches to this problem model the human body as a combination of rigid parts, connected together in some fashion. The typical configuration constraints used are kinematic constraints between adjacent parts, such as torso-upper half-limb connection, or upper-lower half-limb connection (e.g. Fig. 1). This set of constraints has a distinct computational advantage since the constraints form a tree-structured model, inferring the optimal pose of the person using this model is tractable. However, this computational advantage comes at a cost. Simply put, the single tree model does not adequately model the full set of relationships between parts of the body. Relationships between parts not connected in the kinematic tree cannot be directly captured by this model.
2 In this paper, we develop a framework for modeling human figures as a collection of trees. We argue that this framework has the advantage of being able to locally capture constraints between the parts which constitute the model. With a collection of trees, a global set of constraints can be modeled. In our work, these constraints are spatial constraints, but this framework could be extended to other cues (e.g. color consistency, occlusion relationships). We demonstrate that the computational advantages of tree-structured models can be kept, and provide tractable algorithms for learning and inference in these multiple tree models. The rest of this paper is organized as follows. Section 2 reviews previous work. Section 3 gives the details of our approach. Section 4 shows some experimental results. Section 5 concludes this paper and points to some future work. 2 Related Work One of the earliest lines of research related to finding people from images is in the setting of detecting and tracking pedestrians. Starting with the work of Hogg [4], there have been a lot work done in tracking with kinematic models in both 2D and 3D. Forsyth et al. [3] provide a survey of this work. Some of the these approaches are exemplar-based. For example, Toyama & Blake [26] use 2D exemplars for people tracking. Mori & Malik [13] and Sullivan & Carlsson [24] address the pose estimation problems as 2D template matching using pre-stored exemplars upon which joint locations have been marked. In order to deal with the complexity due to variations of pose and clothing, Shakhnarovich et al. [19] adopt a brute-force search, using a variant of locality sensitive hashing for speed. Exemplar-based models are effective when dealing with regular human poses. However, they cannot handle those poses that rarely occur. See Fig. 5 for some examples. There are many approaches which explicitly model the human body as an assembly of parts. Ju et al. [7] introduce a cardboard people model, where body parts are represented by a set of connected planar patches. Felzenszwalb & Huttenlocher [2] develop a tree-structured model called pictorial structure (PS) and applied it to 2D human pose estimation. Lee & Cohen [10] present results on 3D pose estimation from a single image based on proposal maps, using skin and face detection as extra cues to guide the MCMC sampling of 3D models. Ramaman & Forsyth [16] describe a self-starting tracker that tracks people by building an appearance model from a stylized pose detected by a top-down PS method. Sudderth et al. [23] introduce a non-parametric belief propagation method with occlusion reasoning for hand tracking. Sigal & Black [20] use a similar idea for pose estimation. Ren et al. [18] use bottom-up detections of parallel lines as part hypotheses, and combine these hypotheses with various pairwise part constraints via an integer quadratic programming. Hua et al. [5] use bottom-up cues such as skin/face detection to guide a belief propagation inference algorithm. There is also some work on using segmentation as a preprocessing step [12,14,22].
3 Our work is closely related to some recent work on learning discriminative models for localization. Ramanan & Sminchisescu [17] use a variant of conditional random fields (CRF) [8] for training localization models for articulated objects, such as human figures, horses, etc. Ramanan [15] extends their work by iteratively building a region model based on color cues. Our work is also related to boosting on structured outputs. Boosting was originally proposed for classification problems. Recently people have adopted it for various tasks where the outputs have certain structures (e.g., chains, trees, graphs). For example, Torralba et al. [25] use boosted random fields for object detection with contextual information. Truyen et al. [27] use a boosting algorithm on Markov Random Fields for multilevel activity recognition. Another line of research related to our work is on various extensions of tree models in both the computer vision and the machine learning literature. Song et al. [21] detect corner features in video sequences and model them using a decomposable triangulated graph, where the graph structure is found by a greedy search. Ioffe & Forsyth [6] propose a sampling method based on body part candidates found by a rectangle detector. Meila & Jordan [11] propose mixturesof-trees that combine multiple tree models. The parameters of such models are learned by an EM algorithm in either maximum likelihood or Bayesian framework. We would like to point out that although our work seems similar to mixtures-of-trees, there are some important differences. Instead of using the maximum likelihood criterion, our method optimizes a loss function that is directly tied to inference. And our model is learned by an efficient boosting procedure. 3 Our Approach Our method is a combination of tree-structured deformable models for human pose estimation [15,17] and boosting on MRFs [27]. The basic idea is to model a human figure as a weighted combination of several tree-structured deformable models. The parameters of each tree model, and the weights of different trees are learned from training data in a discriminative fashion using boosting. In this section, we first review deformable models for human pose estimation (Sect. 3.1), followed by the learning and inference algorithms in such models (Sect. 3.2). Then we introduce the boosted multiple trees (Sect. 3.3). 3.1 Deformable Model Consider a human body model with K parts, where each part is represented by an oriented rectangle with fixed size. We can construct an undirected graph G = (V, E) to represent the K parts. Each part is represented by a vertex v i V in G, and there exists an undirected edge e ij = (v i, v j ) E between vertices v i and v j if v i and v j has a spatial dependency. Let l i = (x i, y i, θ i ) be a random variable encoding the image position and orientation of the i-th part. We denote
4 the configuration of the K part model as L = (l 1, l 2,..., l K ). Given the model parameters Θ, the conditional probability of L in an image I can be written as: Pr(L I, Θ) exp (i,j) E ψ(l i l j ) + K φ(l i ) (1) ψ(l i l j ) corresponds to a spatial prior on the part geometry, and φ(l i ) models the local image evidence at each part located at l i. Most previous approaches use Gaussian shape priors ψ(l i l j ) N(l i l j ; µ i, Σ i ) [2, 17]. However, since we are dealing with images with a wide range of poses and aspects, Gaussian shape priors seem too rigid. Instead we choose a spatial prior using discrete binning (Fig. 2) similar to the one used in Ramanan [15]: i=1 ψ(l i l j ) = α T i bin(l i l j ) (2) α i is a parameter that favors certain relative spatial and angular bins for part i with respect to its parent j. This spatial prior captures more intricate distributions than a Gaussian prior. For the appearance model φ(l i ), we follow the one used in Ramanan [15]. φ(l i ) corresponds to the local image evidence for a part and is defined as: φ(l i ) = β T i f i (I(l i )) (3) f i (I(l i )) is the part-specific feature vector extracted from the oriented image patch at location l i. We use a binary vector of edges for all parts. β i is a partspecific parameter that favors certain edge patterns for an oriented rectangle patch I(l i ) in image I, where l i defines the location and orientation of the patch. To facilitate tractable learning and inference, G is usually assumed to form a tree T = (V, E T ) [2,15,17]. In particular, most work uses the kinematic tree (see Fig. 1) as the underlying tree model. l10 l6 l2 l1 l3 l7 l4 l5 l8 l9 (a) (b) Fig. 1. Representation of a human body. (a) human body represented as a 10-part model; (b) corresponding kinematic tree structured model.
5 Fig.2. Discrete binning for spatial prior 3.2 Learning and Inference in a Single Tree Model Inference: Given the model parameters Θ = {α i, β i }, parsing an image I of a human body involves computing the posterior distribution over part locations L, i.e., P(L I, Θ). Then the optimal part locations can be found by the maximum a posterior estimation L MAP = argmax L Pr(L I, Θ). We use message-passing to carry out this computation (see [15,17] for details). We first pick a node (e.g., the torso) in the tree model as the root and make a directed graph from the tree structure. Then we pass messages upstream starting from leaf nodes to their parents. The message from part i to part j is: m i (l j ) l j ψ(l i l j )a i (l i ) (4) a i (l i ) φ(l i ) k kids i m k (l i ) (5) φ(l i ) is obtained by convolving the edge image with the filter β i. m i (l j ) can be computed by convolving a i (l i ) with a 3D spatial filter (with coefficient α i ) extending the bins from Fig. 2. a i (l i ) is obtained by multiplying the response image φ(l i ) together with messages from its child nodes m k (l i ). At the root, a i is the true conditional marginal distribution Pr(l i I). Then starting from the root, we pass messages downstream from part j to part i to compute the true conditional marginal of each node: Pr(l i I) a i (l i ) l j ψ(l i l j )Pr(l j I) (6) It can been shown that in a tree structure, the inference is exact, and converges to the true conditional marginal distributions after this message-passing scheme. Similar to previous work [15,17], we normalize each a i to 1 for numerical stability, and keep track of the normalizing constants, which are needed for computing the partition function of the posterior Pr(L I, Θ). Learning Θ ML : If we are given a set of training images I t where part locations L t have been labeled, one way of learning the model parameters Θ = {α i, β i } is to maximize the joint likelihood of the labeled data: Θ ML = max Θ Pr(I t, L t Θ) (7) t
6 = max Pr(L t Θ) Θ t t Pr(I t L t, Θ) (8) Θ ML is also known as the maximum likelihood (ML) estimate of the model parameter Θ. Θ ML can be found by independently fitting the ML estimate of each factor [17]. Learning Θ CL : It has been noticed [17] that the ML estimate is not directly tied to the inference, and a better criterion is to optimize the posterior distribution: Θ CL = max Θ Pr(L t I t, Θ) (9) t Finding Θ CL is equivalent to learning a Conditional Random Field (CRF) [8]. There are standard algorithms to learn Θ CL using gradient ascent methods. 3.3 Boosted Multiple Trees There is a trade-off between representational power and computational complexity amongst different forms of spatial priors. A complete graph captures all the possible spatial dependencies between all the parts, but the learning and inference of such models are intractable. On the other hand, tree-structured models are appealing due to their tractability. However, previous work [9, 21] has shown that tree models fail to capture some additional dependencies between body parts. In order to alleviate the limitation of tree models, various classes of graph structures that allow tractable learning and inference have been studied, e.g., mixture of trees [11], triangulated graph [21], k-fan [1], common-factor model [9]. In this section, we present our algorithm on boosting multiple trees for human pose estimation. Our algorithm is based on AdaBoost.MRF proposed in Truyen et al. [27] with some modifications. The basic idea of this method is to combine multiple tree-structured models. Since each component of the combined model is still a tree, learning and inference will be tractable. At the same time, since we are using several trees, we can capture additional spatial dependencies that are missing from a single tree model. Although our model is similar to mixtures of trees at a first glance, there are some importance differences. Mixtures of trees is trained by the EM algorithm to maximize the likelihood of the training data, while our model is trained by boosting to minimize a loss function directly tied to inference. Given an image I, the problem of pose estimation is to find the best part labeling L that maximize some function F(L, I), i.e. L = arg max L F(L, I). F(L, I) is known as the strong learner in the boosting literature. Given a set of training examples (I i, L i ), i = 1, 2,..., N. F(L, I) is found by minimizing the following loss function: L O = i exp ( F(I i, L) F(I i, L i ) ) (10) L
7 We assume F(L, I) is a linear combination of a set of so-called weak learners, i.e., F(I, L) = t α tf t (L, I). The t-th weak learner f t (L, I) and its corresponding weight α t are found by minimizing the loss function defined in Equation 10, i.e. (f t, α t ) = argmax f,α L O. Since we are interested in finding the distribution p(l I), we can choose the weak learner as f(l, I) = log p(l I). To achieve computational tractability, we assume each weak learner is defined on a tree model. If we can successfully learn a set of tree-based weak learners f t (L, I) and their weights α t, the combination of these weak learners captures more spatial dependencies than a single tree model. At the same, the inference in this model is still tractable, since each component is a tree. Optimizing L O is difficult, Truyen et al. [27] suggest optimizing the following alternative loss function: L H = i exp ( F(L i, I i ) ) (11) It can be shown that L H is an upper bound of the original loss function L O, provided that we can make sure j α j = 1. In Truyen et al. [27], the requirement j α j = 1 is met by scaling down each previous weak learner s weight by a factor of 1 α t as α j α j(1 α t ), for j = 1, 2,..., t 1, so that t 1 j=1 α j + α t = t 1 j=1 α j(1 α t ) + α t = 1, since t 1 j=1 α j = 1. In practice, we find this trick sometimes has the undesirable effect of scaling down previous weak learners to have zero weights. So we use another method by scaling down each weak learner s weight up to t by a factor of 1/(1 + α t ), i.e., α j αj 1+α t for j = 1, 2,..., t. It can be easily shown that we still have t j=1 α j = t 1 α j j=1 1+α t + αt 1+α t = 1, since t 1 j=1 α j = 1. In practice, the algorithm could be very slow, since learning CRF parameters requires gradient ascent on a high dimensional space. To speed up the learning process, we employ several simple tricks. Firstly, we learn Θ CL = {α i, β i } using the kinematic tree structure, and fix the appearance parameters {β i } during the boosting process. The rational behind this is that multiple tree structures should only affect the spatial prior, not the appearance model. Secondly, during each boosting iteration, we learn Θ ML instead of Θ CL. Thirdly, instead of selecting the best tree structure in each iteration, we simply sequentially select a tree from a set of pre-specified tree structures. We also allow re-selecting a tree. 4 Experiments We test our algorithm on the people dataset used in previous work [15,17]. This dataset contains 305 images of people in various interesting poses. First 100 images are used for training, and the remaining 205 images for testing. We manually select three tree structures shown in Fig. 4, although it will be an interesting future work on how to automatically learn the tree structure at each iteration in an efficient way. The results are obtained by running 15 boosting
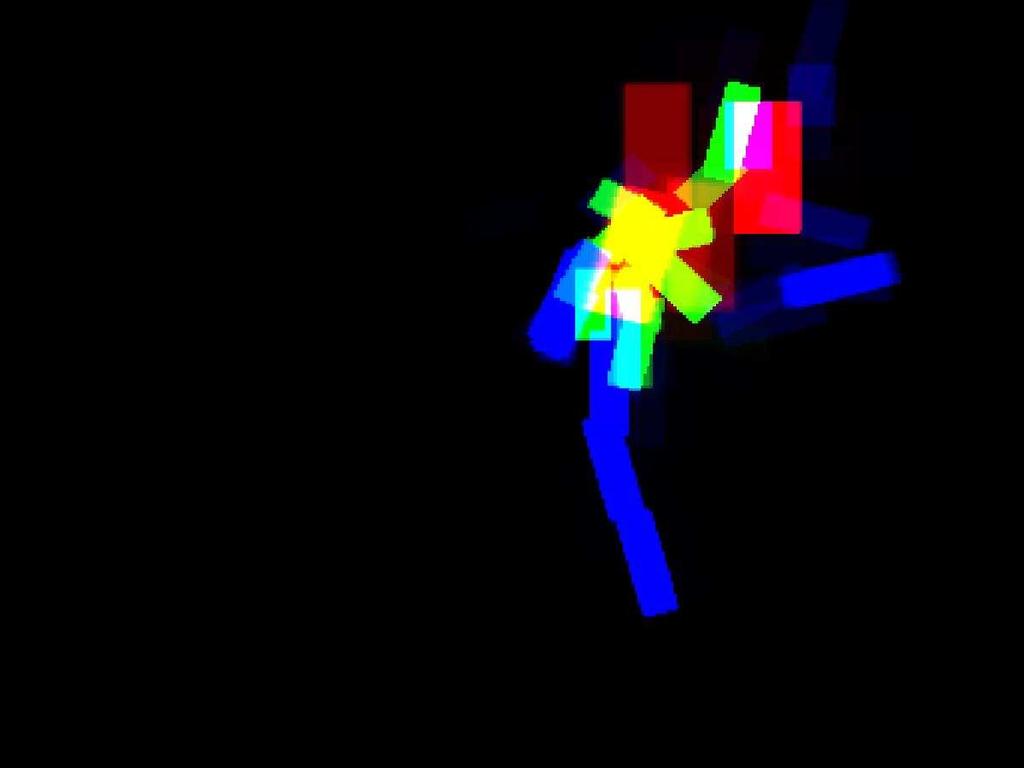
8 Input: i = 1,2,..., D data pairs, graphs {G i = (V i, E i)} Output: set of trees with learned parameters and weights Select a set of spanning trees {τ} Choose the number of boosting iterations T Initialize {w i,0 = 1 }, and α1 = 1 D for each boosting round t = 1,2,..., T Select a spanning tree τ t /* Add a weak learner */ Θ t = arg max Θ Pi wi,t 1 log Prτt (L i, I i Θ) f t = log Pr τt (L I, Θ t) if t > 1 then select the step size 0 < α t < 1 using line searches end if /* Update the strong learner */ F t = 1 1+α t F t 1 + αt 1+α t f t /* Scale down the previous learners weights*/ α j α j 1+α t, for j = 1, 2,..., t /* Re-weight training data*/ w i,t w i,t 1 exp( α tf i,t) end for Output {τ t},{θ t} and {α t}, t = 1,2,..., T Fig.3. Algorithm of boosted multiple trees iterations. We visualize the posterior distribution Pr(L I) on a 2D image using the same technique in Ramanan [15], where the torso is represented as red, upper-limbs as green, and lower-limbs and the head as blue. Some of the parsing results are shown in Fig. 5. We can see that our parsing results are much clearer than the one using the kinematic tree. In many images, the body parts are almost clearly visible from our parsing results. In the parsing results of using the kinematic tree, there are many white pixels, indicating high uncertainty about body parts at those locations. But with multiple trees, most of the white pixels are cleaned up. We can imagine if we sample the part candidates l i according to Pr(l i I; Θ) and use them as the inputs to other pose estimation algorithms (e.g., Ren et al. [18]), the samples generated from our parsing results are more likely to be the true part locations. 5 Conclusion and Future Work We have presented a framework for modeling human figures as a collection of tree-structured models. This framework has the computational advantages of previous tree-structured models used for human pose estimation. At the same
9 l10 l10 l10 l6 l2 l1 l3 l7 l6 l2 l1 l3 l7 l6 l2 l1 l3 l7 l4 l5 l4 l5 l4 l5 l8 l9 l8 l9 l8 l9 Fig.4. Three tree structures used for boosting time, it models a richer set of spatial constraints between body parts. We demonstrate our results on a challenging dataset with substantial pose variations. Human pose estimation is an extremely difficult computer vision problem. The solution of this problem probably requires the symbiosis of various kinds of visual cues. This paper represents our first step in that direction. Our framework nicely solves the problem of modeling spatial dependencies between nonconnected body parts. In the future, we would like to extend our framework to other cues (e.g., color consistency, occlusion relationships). We would also like to combine our framework with the iterative color parsing [15]. Acknowledgement We would like to thank Deva Ramanan for providing source code, the dataset, and many helpful discussions. References 1. Crandell, D., Felzenszwalb, P.F., Huttenlocher, D.P.: Spatial priors for part-based recognition using statistical models. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 1. (2005) Felzenszwalb, P.F., Huttenlocher, D.P.: Pictorial structures for object recognition. International Journal of Computer Vision 61(1) (January 2003) Forsyth, D.A., Arikan, O., Ikemoto, L., O Brien, J., Ramanan, D.: Computational studies of human motion: Part 1, tracking and motion synthesis. Foundations and Trends in Computer Graphics and Vision 1(2/3) (July 2006) Hogg, D.: Model-based vision: a program to see a walking person. Image and Vision Computing 1(1) (1983) Hua, G., Yang, M.H., Wu, Y.: Learning to estimate human pose with data driven belief propagation. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. (2005) Ioffe, S., Forsyth, D.: Finding people by sampling. In: IEEE International Conference on Computer Vision. Volume 2. (1999) Ju, S.X., Black, M.J., Yaccob, Y.: Cardboard people: A parameterized model of articulated image motion. In: International Conference on Automatic Face and Gesture Recognition. (1996) 38 44





























10
 (c)")






















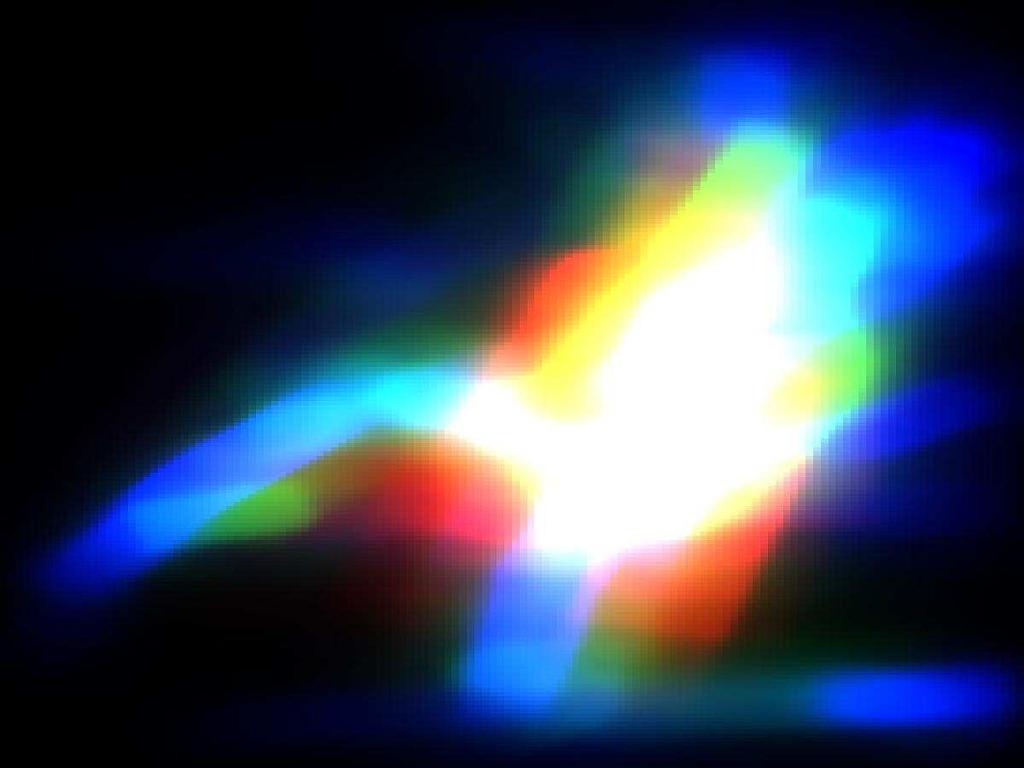
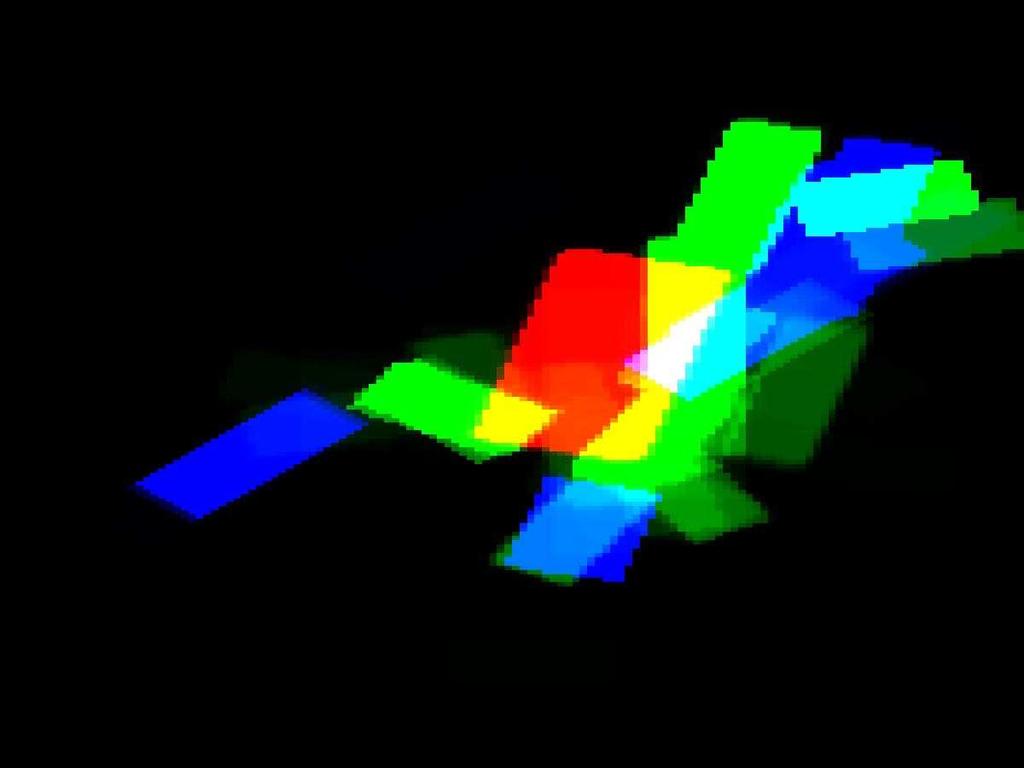






11 (a) (b) (c) (a) (b) (c) Fig. 5. Some results of our algorithm: (a) original images; (b) results of using one kinematic tree; (c) results of using multiple trees.
12 8. Lafferty, J., McCallum, A., Pereira, F.: Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In: International Conference on Machine Learning (ICML). (2001) Lan, X., Huttenlocher, D.P.: Beyond trees: Common-factor models for 2d human pose recovery. In: IEEE International Conference on Computer Vision. Volume 1. (2005) Lee, M.W., Cohen, I.: Proposal maps driven mcmc for estimating human body pose in static images. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. (2004) Meila, M., Jordan, M.I.: Learing with mixtures of trees. Journal of Machine Learning Research 1 (2000) Mori, G.: Guiding model search using segmentation. In: IEEE International Conference on Computer Vision. Volume 2. (2005) Mori, G., Malik, J.: Estimating human body configurations using shape context matching. In: European Conference on Computer Vision. Volume 3. (2002) Mori, G., Ren, X., Efros, A., Malik, J.: Recovering human body configuration: Combining segmentation and recognition. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. (2004) Ramanan, D.: Learning to parse images of articulated bodies. In: Advances in Neural Information Processing Systems. Volume 19. (2007) Ramanan, D., Forsyth, D.A., Zisserman, A.: Strike a pose: Tracking people by finding stylized poses. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 1. (2005) Ramanan, D., Sminchisescu, C.: Training deformable models for localization. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 1. (2006) Ren, X., Berg, A., Malik, J.: Recovering human body configurations using pairwise constraints between parts. In: IEEE International Conference on Computer Vision. Volume 1. (2005) Shakhnarovich, G., Viola, P., Darrell, T.: Fast pose estimation with parameter sensitive hashing. In: IEEE International Conference on Computer Vision. Volume 2. (2003) Sigal, L., Black, M.J.: Measure locally, reason globally: Occlusion-sensitive articulated pose estimation. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. (2006) Song, Y., Goncalves, L., Perona, P.: Unsupervised learning of human motion. IEEE Transaction on Pattern Analysis and Machine Intelligence 25(7) (July 2003) Srinivasan, P., Shi, J.: Bottom-up recognition and parsing of the human body. In: IEEE Conference on Computer Vision and Pattern Recognition. (2007) 23. Sudderth, E.B., Mandel, M.I., Freeman, W.T., Willsky, A.S.: Distributed occlusion reasoning for tracking with nonparametric belief propagation. In: Advances in Neural Information Processing Systems. MIT Press (2004) Sullivan, J., Carlsson, S.: Recognizing and tracking human action. In: European Conference on Computer Vision LNCS Volume 1. (2002) Torralba, A., Murphy, K.P., Freeman, W.T.: Contextual models for object detection using boosted random fields. In: Advances in Neural Information Processing Systems 17. MIT Press (2005) Toyama, K., Blake, A.: Probabilistic exemplar-based tracking in a metric space. In: IEEE International Conference on Computer Vision. Volume 2. (2001) 50 57
13 27. Truyen, T.T., Phung, D.Q., Bui, H.H., Venkatesh, S.: AdaBoost.MRF: Boosted markov random forests and application to multilevel activity recognition. In: IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. (2006)
Learning to parse images of articulated bodies
 Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Object Recognition Using Pictorial Structures. Daniel Huttenlocher Computer Science Department. In This Talk. Object recognition in computer vision
 Object Recognition Using Pictorial Structures Daniel Huttenlocher Computer Science Department Joint work with Pedro Felzenszwalb, MIT AI Lab In This Talk Object recognition in computer vision Brief definition
Object Recognition Using Pictorial Structures Daniel Huttenlocher Computer Science Department Joint work with Pedro Felzenszwalb, MIT AI Lab In This Talk Object recognition in computer vision Brief definition
Human Pose Estimation with Rotated Geometric Blur
 Human Pose Estimation with Rotated Geometric Blur Bo Chen, Nhan Nguyen, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, CANADA {bca11,tnn}@sfu.ca, mori@cs.sfu.ca Abstract
Human Pose Estimation with Rotated Geometric Blur Bo Chen, Nhan Nguyen, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, CANADA {bca11,tnn}@sfu.ca, mori@cs.sfu.ca Abstract
Guiding Model Search Using Segmentation
 Guiding Model Search Using Segmentation Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada V5A S6 mori@cs.sfu.ca Abstract In this paper we show how a segmentation as preprocessing
Guiding Model Search Using Segmentation Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada V5A S6 mori@cs.sfu.ca Abstract In this paper we show how a segmentation as preprocessing
CS 664 Flexible Templates. Daniel Huttenlocher
 CS 664 Flexible Templates Daniel Huttenlocher Flexible Template Matching Pictorial structures Parts connected by springs and appearance models for each part Used for human bodies, faces Fischler&Elschlager,
CS 664 Flexible Templates Daniel Huttenlocher Flexible Template Matching Pictorial structures Parts connected by springs and appearance models for each part Used for human bodies, faces Fischler&Elschlager,
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation
 Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation Leonid Sigal Michael J. Black Department of Computer Science, Brown University, Providence, RI 02912 {ls,black}@cs.brown.edu
Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation Leonid Sigal Michael J. Black Department of Computer Science, Brown University, Providence, RI 02912 {ls,black}@cs.brown.edu
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Computer Vision Group Prof. Daniel Cremers. 4a. Inference in Graphical Models
 Group Prof. Daniel Cremers 4a. Inference in Graphical Models Inference on a Chain (Rep.) The first values of µ α and µ β are: The partition function can be computed at any node: Overall, we have O(NK 2
Group Prof. Daniel Cremers 4a. Inference in Graphical Models Inference on a Chain (Rep.) The first values of µ α and µ β are: The partition function can be computed at any node: Overall, we have O(NK 2
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Global Pose Estimation Using Non-Tree Models
 Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Inferring 3D People from 2D Images
 Inferring 3D People from 2D Images Department of Computer Science Brown University http://www.cs.brown.edu/~black Collaborators Hedvig Sidenbladh, Swedish Defense Research Inst. Leon Sigal, Brown University
Inferring 3D People from 2D Images Department of Computer Science Brown University http://www.cs.brown.edu/~black Collaborators Hedvig Sidenbladh, Swedish Defense Research Inst. Leon Sigal, Brown University
Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking
 Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking Nam-Gyu Cho, Alan Yuille and Seong-Whan Lee Department of Brain and Cognitive Engineering, orea University, orea
Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking Nam-Gyu Cho, Alan Yuille and Seong-Whan Lee Department of Brain and Cognitive Engineering, orea University, orea
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS
 HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
Recovering Human Body Configurations: Combining Segmentation and Recognition
 Recovering Human Body Configurations: Combining Segmentation and Recognition Greg Mori, Xiaofeng Ren, Alexei A. Efros and Jitendra Malik Computer Science Division Robotics Research Group UC Berkeley University
Recovering Human Body Configurations: Combining Segmentation and Recognition Greg Mori, Xiaofeng Ren, Alexei A. Efros and Jitendra Malik Computer Science Division Robotics Research Group UC Berkeley University
Finding people in repeated shots of the same scene
 1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
Learning to Estimate Human Pose with Data Driven Belief Propagation
 Learning to Estimate Human Pose with Data Driven Belief Propagation Gang Hua Ming-Hsuan Yang Ying Wu ECE Department, Northwestern University Honda Research Institute Evanston, IL 60208, U.S.A. Mountain
Learning to Estimate Human Pose with Data Driven Belief Propagation Gang Hua Ming-Hsuan Yang Ying Wu ECE Department, Northwestern University Honda Research Institute Evanston, IL 60208, U.S.A. Mountain
Recognizing Human Actions from Still Images with Latent Poses
 Recognizing Human Actions from Still Images with Latent Poses Weilong Yang, Yang Wang, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada wya16@sfu.ca, ywang12@cs.sfu.ca,
Recognizing Human Actions from Still Images with Latent Poses Weilong Yang, Yang Wang, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada wya16@sfu.ca, ywang12@cs.sfu.ca,
Predicting 3D People from 2D Pictures
 Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
Human Pose Estimation Using Consistent Max-Covering
 Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
A Unified Spatio-Temporal Articulated Model for Tracking
 A Unified Spatio-Temporal Articulated Model for Tracking Xiangyang Lan Daniel P. Huttenlocher {xylan,dph}@cs.cornell.edu Cornell University Ithaca NY 14853 Abstract Tracking articulated objects in image
A Unified Spatio-Temporal Articulated Model for Tracking Xiangyang Lan Daniel P. Huttenlocher {xylan,dph}@cs.cornell.edu Cornell University Ithaca NY 14853 Abstract Tracking articulated objects in image
Recognition Rate. 90 S 90 W 90 R Segment Length T
 Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
18 October, 2013 MVA ENS Cachan. Lecture 6: Introduction to graphical models Iasonas Kokkinos
 Machine Learning for Computer Vision 1 18 October, 2013 MVA ENS Cachan Lecture 6: Introduction to graphical models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Machine Learning for Computer Vision 1 18 October, 2013 MVA ENS Cachan Lecture 6: Introduction to graphical models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
A Hierarchical Compositional System for Rapid Object Detection
 A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model
 Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model Xiaoqin Zhang 1,Changcheng Li 2, Xiaofeng Tong 3,Weiming Hu 1,Steve Maybank 4,Yimin Zhang 3 1 National Laboratory of Pattern
Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model Xiaoqin Zhang 1,Changcheng Li 2, Xiaofeng Tong 3,Weiming Hu 1,Steve Maybank 4,Yimin Zhang 3 1 National Laboratory of Pattern
and we can apply the recursive definition of the cost-to-go function to get
 Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Strike a Pose: Tracking People by Finding Stylized Poses
 Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
On the Sustained Tracking of Human Motion
 On the Sustained Tracking of Human Motion Yaser Ajmal Sheikh Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 yaser@cs.cmu.edu Ankur Datta Robotics Institute Carnegie Mellon University
On the Sustained Tracking of Human Motion Yaser Ajmal Sheikh Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 yaser@cs.cmu.edu Ankur Datta Robotics Institute Carnegie Mellon University
Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation
 JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
Conditional Random Fields for Object Recognition
 Conditional Random Fields for Object Recognition Ariadna Quattoni Michael Collins Trevor Darrell MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139 {ariadna, mcollins, trevor}@csail.mit.edu
Conditional Random Fields for Object Recognition Ariadna Quattoni Michael Collins Trevor Darrell MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139 {ariadna, mcollins, trevor}@csail.mit.edu
Efficient Mean Shift Belief Propagation for Vision Tracking
 Efficient Mean Shift Belief Propagation for Vision Tracking Minwoo Park, Yanxi Liu * and Robert T. Collins Department of Computer Science and Engineering, *Department of Electrical Engineering The Pennsylvania
Efficient Mean Shift Belief Propagation for Vision Tracking Minwoo Park, Yanxi Liu * and Robert T. Collins Department of Computer Science and Engineering, *Department of Electrical Engineering The Pennsylvania
Learning Objects and Parts in Images
 Learning Objects and Parts in Images Chris Williams E H U N I V E R S I T T Y O H F R G E D I N B U School of Informatics, University of Edinburgh, UK Learning multiple objects and parts from images (joint
Learning Objects and Parts in Images Chris Williams E H U N I V E R S I T T Y O H F R G E D I N B U School of Informatics, University of Edinburgh, UK Learning multiple objects and parts from images (joint
Conditional Random Fields and beyond D A N I E L K H A S H A B I C S U I U C,
 Conditional Random Fields and beyond D A N I E L K H A S H A B I C S 5 4 6 U I U C, 2 0 1 3 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative
Conditional Random Fields and beyond D A N I E L K H A S H A B I C S 5 4 6 U I U C, 2 0 1 3 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative
Pictorial Structures for Object Recognition
 Pictorial Structures for Object Recognition Felzenszwalb and Huttenlocher Presented by Stephen Krotosky Pictorial Structures Introduced by Fischler and Elschlager in 1973 Objects are modeled by a collection
Pictorial Structures for Object Recognition Felzenszwalb and Huttenlocher Presented by Stephen Krotosky Pictorial Structures Introduced by Fischler and Elschlager in 1973 Objects are modeled by a collection
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information
 Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
Loopy Belief Propagation
 Loopy Belief Propagation Research Exam Kristin Branson September 29, 2003 Loopy Belief Propagation p.1/73 Problem Formalization Reasoning about any real-world problem requires assumptions about the structure
Loopy Belief Propagation Research Exam Kristin Branson September 29, 2003 Loopy Belief Propagation p.1/73 Problem Formalization Reasoning about any real-world problem requires assumptions about the structure
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Scene Grammars, Factor Graphs, and Belief Propagation
 Scene Grammars, Factor Graphs, and Belief Propagation Pedro Felzenszwalb Brown University Joint work with Jeroen Chua Probabilistic Scene Grammars General purpose framework for image understanding and
Scene Grammars, Factor Graphs, and Belief Propagation Pedro Felzenszwalb Brown University Joint work with Jeroen Chua Probabilistic Scene Grammars General purpose framework for image understanding and
Finding and Tracking People from the Bottom Up
 Finding and Tracking People from the Bottom Up Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 9472 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu
Finding and Tracking People from the Bottom Up Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 9472 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu
CRFs for Image Classification
 CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
Probabilistic Graphical Models
 Overview of Part Two Probabilistic Graphical Models Part Two: Inference and Learning Christopher M. Bishop Exact inference and the junction tree MCMC Variational methods and EM Example General variational
Overview of Part Two Probabilistic Graphical Models Part Two: Inference and Learning Christopher M. Bishop Exact inference and the junction tree MCMC Variational methods and EM Example General variational
Scene Grammars, Factor Graphs, and Belief Propagation
 Scene Grammars, Factor Graphs, and Belief Propagation Pedro Felzenszwalb Brown University Joint work with Jeroen Chua Probabilistic Scene Grammars General purpose framework for image understanding and
Scene Grammars, Factor Graphs, and Belief Propagation Pedro Felzenszwalb Brown University Joint work with Jeroen Chua Probabilistic Scene Grammars General purpose framework for image understanding and
Efficient Extraction of Human Motion Volumes by Tracking
 Efficient Extraction of Human Motion Volumes by Tracking Juan Carlos Niebles Princeton University, USA Universidad del Norte, Colombia jniebles@princeton.edu Bohyung Han Electrical and Computer Engineering
Efficient Extraction of Human Motion Volumes by Tracking Juan Carlos Niebles Princeton University, USA Universidad del Norte, Colombia jniebles@princeton.edu Bohyung Han Electrical and Computer Engineering
Lecture 21 : A Hybrid: Deep Learning and Graphical Models
 10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
2D Articulated Tracking With Dynamic Bayesian Networks
 2D Articulated Tracking With Dynamic Bayesian Networks Chunhua Shen, Anton van den Hengel, Anthony Dick, Michael J. Brooks School of Computer Science, The University of Adelaide, SA 5005, Australia {chhshen,anton,ard,mjb}@cs.adelaide.edu.au
2D Articulated Tracking With Dynamic Bayesian Networks Chunhua Shen, Anton van den Hengel, Anthony Dick, Michael J. Brooks School of Computer Science, The University of Adelaide, SA 5005, Australia {chhshen,anton,ard,mjb}@cs.adelaide.edu.au
Key Developments in Human Pose Estimation for Kinect
 Key Developments in Human Pose Estimation for Kinect Pushmeet Kohli and Jamie Shotton Abstract The last few years have seen a surge in the development of natural user interfaces. These interfaces do not
Key Developments in Human Pose Estimation for Kinect Pushmeet Kohli and Jamie Shotton Abstract The last few years have seen a surge in the development of natural user interfaces. These interfaces do not
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Experts-Shift: Learning Active Spatial Classification Experts for Keyframe-based Video Segmentation
 Experts-Shift: Learning Active Spatial Classification Experts for Keyframe-based Video Segmentation Yibiao Zhao 1,3, Yanbiao Duan 2,3, Xiaohan Nie 2,3, Yaping Huang 1, Siwei Luo 1 1 Beijing Jiaotong University,
Experts-Shift: Learning Active Spatial Classification Experts for Keyframe-based Video Segmentation Yibiao Zhao 1,3, Yanbiao Duan 2,3, Xiaohan Nie 2,3, Yaping Huang 1, Siwei Luo 1 1 Beijing Jiaotong University,
Multiple Pose Context Trees for estimating Human Pose in Object Context
 Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 5 Inference
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 5 Inference
Object recognition (part 1)
") Recognition Object recognition (part 1) CSE P 576 Larry Zitnick (larryz@microsoft.com) The Margaret Thatcher Illusion, by Peter Thompson Readings Szeliski Chapter 14 Recognition What do we mean by object
Recognition Object recognition (part 1) CSE P 576 Larry Zitnick (larryz@microsoft.com) The Margaret Thatcher Illusion, by Peter Thompson Readings Szeliski Chapter 14 Recognition What do we mean by object
D-Separation. b) the arrows meet head-to-head at the node, and neither the node, nor any of its descendants, are in the set C.
 the arrows meet head-to-head at the node, and neither the node, nor any of its descendants, are in the set C.") D-Separation Say: A, B, and C are non-intersecting subsets of nodes in a directed graph. A path from A to B is blocked by C if it contains a node such that either a) the arrows on the path meet either
D-Separation Say: A, B, and C are non-intersecting subsets of nodes in a directed graph. A path from A to B is blocked by C if it contains a node such that either a) the arrows on the path meet either
Graphical Models for Computer Vision
 Graphical Models for Computer Vision Pedro F Felzenszwalb Brown University Joint work with Dan Huttenlocher, Joshua Schwartz, Ross Girshick, David McAllester, Deva Ramanan, Allie Shapiro, John Oberlin
Graphical Models for Computer Vision Pedro F Felzenszwalb Brown University Joint work with Dan Huttenlocher, Joshua Schwartz, Ross Girshick, David McAllester, Deva Ramanan, Allie Shapiro, John Oberlin
A Fast Learning Algorithm for Deep Belief Nets
 A Fast Learning Algorithm for Deep Belief Nets Geoffrey E. Hinton, Simon Osindero Department of Computer Science University of Toronto, Toronto, Canada Yee-Whye Teh Department of Computer Science National
A Fast Learning Algorithm for Deep Belief Nets Geoffrey E. Hinton, Simon Osindero Department of Computer Science University of Toronto, Toronto, Canada Yee-Whye Teh Department of Computer Science National
Learning Diagram Parts with Hidden Random Fields
 Learning Diagram Parts with Hidden Random Fields Martin Szummer Microsoft Research Cambridge, CB 0FB, United Kingdom szummer@microsoft.com Abstract Many diagrams contain compound objects composed of parts.
Learning Diagram Parts with Hidden Random Fields Martin Szummer Microsoft Research Cambridge, CB 0FB, United Kingdom szummer@microsoft.com Abstract Many diagrams contain compound objects composed of parts.
Random projection for non-gaussian mixture models
 Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
A Parts-based Person Detector
 A arts-based erson Detector Benjamin Laxton Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 Abstract This work presents a parts-based person detection
A arts-based erson Detector Benjamin Laxton Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 Abstract This work presents a parts-based person detection
AUTOMATIC OBJECT EXTRACTION IN SINGLE-CONCEPT VIDEOS. Kuo-Chin Lien and Yu-Chiang Frank Wang
 AUTOMATIC OBJECT EXTRACTION IN SINGLE-CONCEPT VIDEOS Kuo-Chin Lien and Yu-Chiang Frank Wang Research Center for Information Technology Innovation, Academia Sinica, Taipei, Taiwan {iker, ycwang}@citi.sinica.edu.tw
AUTOMATIC OBJECT EXTRACTION IN SINGLE-CONCEPT VIDEOS Kuo-Chin Lien and Yu-Chiang Frank Wang Research Center for Information Technology Innovation, Academia Sinica, Taipei, Taiwan {iker, ycwang}@citi.sinica.edu.tw
Undirected Graphical Models. Raul Queiroz Feitosa
 Undirected Graphical Models Raul Queiroz Feitosa Pros and Cons Advantages of UGMs over DGMs UGMs are more natural for some domains (e.g. context-dependent entities) Discriminative UGMs (CRF) are better
Undirected Graphical Models Raul Queiroz Feitosa Pros and Cons Advantages of UGMs over DGMs UGMs are more natural for some domains (e.g. context-dependent entities) Discriminative UGMs (CRF) are better
Located Hidden Random Fields: Learning Discriminative Parts for Object Detection
 Located Hidden Random Fields: Learning Discriminative Parts for Object Detection Ashish Kapoor 1 and John Winn 2 1 MIT Media Laboratory, Cambridge, MA 02139, USA kapoor@media.mit.edu 2 Microsoft Research,
Located Hidden Random Fields: Learning Discriminative Parts for Object Detection Ashish Kapoor 1 and John Winn 2 1 MIT Media Laboratory, Cambridge, MA 02139, USA kapoor@media.mit.edu 2 Microsoft Research,
Markov Random Fields and Gibbs Sampling for Image Denoising
 Markov Random Fields and Gibbs Sampling for Image Denoising Chang Yue Electrical Engineering Stanford University changyue@stanfoed.edu Abstract This project applies Gibbs Sampling based on different Markov
Markov Random Fields and Gibbs Sampling for Image Denoising Chang Yue Electrical Engineering Stanford University changyue@stanfoed.edu Abstract This project applies Gibbs Sampling based on different Markov
Detection of Man-made Structures in Natural Images
 Detection of Man-made Structures in Natural Images Tim Rees December 17, 2004 Abstract Object detection in images is a very active research topic in many disciplines. Probabilistic methods have been applied
Detection of Man-made Structures in Natural Images Tim Rees December 17, 2004 Abstract Object detection in images is a very active research topic in many disciplines. Probabilistic methods have been applied
Computer vision: models, learning and inference. Chapter 10 Graphical Models
 Computer vision: models, learning and inference Chapter 10 Graphical Models Independence Two variables x 1 and x 2 are independent if their joint probability distribution factorizes as Pr(x 1, x 2 )=Pr(x
Computer vision: models, learning and inference Chapter 10 Graphical Models Independence Two variables x 1 and x 2 are independent if their joint probability distribution factorizes as Pr(x 1, x 2 )=Pr(x
Image Segmentation using Gaussian Mixture Models
 Image Segmentation using Gaussian Mixture Models Rahman Farnoosh, Gholamhossein Yari and Behnam Zarpak Department of Applied Mathematics, University of Science and Technology, 16844, Narmak,Tehran, Iran
Image Segmentation using Gaussian Mixture Models Rahman Farnoosh, Gholamhossein Yari and Behnam Zarpak Department of Applied Mathematics, University of Science and Technology, 16844, Narmak,Tehran, Iran
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation
 Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Visual Motion Analysis and Tracking Part II
 Visual Motion Analysis and Tracking Part II David J Fleet and Allan D Jepson CIAR NCAP Summer School July 12-16, 16, 2005 Outline Optical Flow and Tracking: Optical flow estimation (robust, iterative refinement,
Visual Motion Analysis and Tracking Part II David J Fleet and Allan D Jepson CIAR NCAP Summer School July 12-16, 16, 2005 Outline Optical Flow and Tracking: Optical flow estimation (robust, iterative refinement,
Efficient Nonparametric Belief Propagation with Application to Articulated Body Tracking
 Efficient Nonparametric Belief Propagation with Application to Articulated Body Tracking Tony X. Han Huazhong Ning Thomas S. Huang Beckman Institute and ECE Department University of Illinois at Urbana-Champaign
Efficient Nonparametric Belief Propagation with Application to Articulated Body Tracking Tony X. Han Huazhong Ning Thomas S. Huang Beckman Institute and ECE Department University of Illinois at Urbana-Champaign
Beyond Actions: Discriminative Models for Contextual Group Activities
 Beyond Actions: Discriminative Models for Contextual Group Activities Tian Lan School of Computing Science Simon Fraser University tla58@sfu.ca Weilong Yang School of Computing Science Simon Fraser University
Beyond Actions: Discriminative Models for Contextual Group Activities Tian Lan School of Computing Science Simon Fraser University tla58@sfu.ca Weilong Yang School of Computing Science Simon Fraser University
Topological Mapping. Discrete Bayes Filter
 Topological Mapping Discrete Bayes Filter Vision Based Localization Given a image(s) acquired by moving camera determine the robot s location and pose? Towards localization without odometry What can be
Topological Mapping Discrete Bayes Filter Vision Based Localization Given a image(s) acquired by moving camera determine the robot s location and pose? Towards localization without odometry What can be
Object Pose Detection in Range Scan Data
 Object Pose Detection in Range Scan Data Jim Rodgers, Dragomir Anguelov, Hoi-Cheung Pang, Daphne Koller Computer Science Department Stanford University, CA 94305 {jimkr, drago, hcpang, koller}@cs.stanford.edu
Object Pose Detection in Range Scan Data Jim Rodgers, Dragomir Anguelov, Hoi-Cheung Pang, Daphne Koller Computer Science Department Stanford University, CA 94305 {jimkr, drago, hcpang, koller}@cs.stanford.edu
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Skin and Face Detection
 Skin and Face Detection Linda Shapiro EE/CSE 576 1 What s Coming 1. Review of Bakic flesh detector 2. Fleck and Forsyth flesh detector 3. Details of Rowley face detector 4. Review of the basic AdaBoost
Skin and Face Detection Linda Shapiro EE/CSE 576 1 What s Coming 1. Review of Bakic flesh detector 2. Fleck and Forsyth flesh detector 3. Details of Rowley face detector 4. Review of the basic AdaBoost
Hierarchical Part-Based Human Body Pose Estimation
 Hierarchical Part-Based Human Body Pose Estimation R. Navaratnam A. Thayananthan P. H. S. Torr R. Cipolla University of Cambridge Oxford Brookes Univeristy Department of Engineering Cambridge, CB2 1PZ,
Hierarchical Part-Based Human Body Pose Estimation R. Navaratnam A. Thayananthan P. H. S. Torr R. Cipolla University of Cambridge Oxford Brookes Univeristy Department of Engineering Cambridge, CB2 1PZ,
Easy Minimax Estimation with Random Forests for Human Pose Estimation
 Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Tracking as Repeated Figure/Ground Segmentation
 Tracking as Repeated Figure/Ground Segmentation Xiaofeng Ren Toyota Technological Institute at Chicago 1427 E. 60th Street, Chicago, IL 60637 xren@tti-c.org Jitendra Malik Computer Science Division University
Tracking as Repeated Figure/Ground Segmentation Xiaofeng Ren Toyota Technological Institute at Chicago 1427 E. 60th Street, Chicago, IL 60637 xren@tti-c.org Jitendra Malik Computer Science Division University
Virtual Training for Multi-View Object Class Recognition
 Virtual Training for Multi-View Object Class Recognition Han-Pang Chiu Leslie Pack Kaelbling Tomás Lozano-Pérez MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139, USA {chiu,lpk,tlp}@csail.mit.edu
Virtual Training for Multi-View Object Class Recognition Han-Pang Chiu Leslie Pack Kaelbling Tomás Lozano-Pérez MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139, USA {chiu,lpk,tlp}@csail.mit.edu
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University
 Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
ELL 788 Computational Perception & Cognition July November 2015
 ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
Object Category Detection: Sliding Windows
 04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
Part II. C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS
 Part II C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Converting Directed to Undirected Graphs (1) Converting Directed to Undirected Graphs (2) Add extra links between
Part II C. M. Bishop PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Converting Directed to Undirected Graphs (1) Converting Directed to Undirected Graphs (2) Add extra links between
Belief propagation and MRF s
 Belief propagation and MRF s Bill Freeman 6.869 March 7, 2011 1 1 Undirected graphical models A set of nodes joined by undirected edges. The graph makes conditional independencies explicit: If two nodes
Belief propagation and MRF s Bill Freeman 6.869 March 7, 2011 1 1 Undirected graphical models A set of nodes joined by undirected edges. The graph makes conditional independencies explicit: If two nodes
Last week. Multi-Frame Structure from Motion: Multi-View Stereo. Unknown camera viewpoints
 Last week Multi-Frame Structure from Motion: Multi-View Stereo Unknown camera viewpoints Last week PCA Today Recognition Today Recognition Recognition problems What is it? Object detection Who is it? Recognizing
Last week Multi-Frame Structure from Motion: Multi-View Stereo Unknown camera viewpoints Last week PCA Today Recognition Today Recognition Recognition problems What is it? Object detection Who is it? Recognizing
Detecting Coarticulation in Sign Language using Conditional Random Fields
 Detecting Coarticulation in Sign Language using Conditional Random Fields Ruiduo Yang and Sudeep Sarkar Computer Science and Engineering Department University of South Florida 4202 E. Fowler Ave. Tampa,
Detecting Coarticulation in Sign Language using Conditional Random Fields Ruiduo Yang and Sudeep Sarkar Computer Science and Engineering Department University of South Florida 4202 E. Fowler Ave. Tampa,
IMA Preprint Series # 2154
 A GRAPH-BASED FOREGROUND REPRESENTATION AND ITS APPLICATION IN EXAMPLE BASED PEOPLE MATCHING IN VIDEO By Kedar A. Patwardhan Guillermo Sapiro and Vassilios Morellas IMA Preprint Series # 2154 ( January
A GRAPH-BASED FOREGROUND REPRESENTATION AND ITS APPLICATION IN EXAMPLE BASED PEOPLE MATCHING IN VIDEO By Kedar A. Patwardhan Guillermo Sapiro and Vassilios Morellas IMA Preprint Series # 2154 ( January
Articulated Pose Estimation using Discriminative Armlet Classifiers
 Articulated Pose Estimation using Discriminative Armlet Classifiers Georgia Gkioxari 1, Pablo Arbeláez 1, Lubomir Bourdev 2 and Jitendra Malik 1 1 University of California, Berkeley - Berkeley, CA 94720
Articulated Pose Estimation using Discriminative Armlet Classifiers Georgia Gkioxari 1, Pablo Arbeláez 1, Lubomir Bourdev 2 and Jitendra Malik 1 1 University of California, Berkeley - Berkeley, CA 94720
Using Geometric Blur for Point Correspondence
 1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
Better appearance models for pictorial structures
 EICHNER, FERRARI: BETTER APPEARANCE MODELS FOR PICTORIAL STRUCTURES 1 Better appearance models for pictorial structures Marcin Eichner eichner@vision.ee.ethz.ch Vittorio Ferrari ferrari@vision.ee.ethz.ch
EICHNER, FERRARI: BETTER APPEARANCE MODELS FOR PICTORIAL STRUCTURES 1 Better appearance models for pictorial structures Marcin Eichner eichner@vision.ee.ethz.ch Vittorio Ferrari ferrari@vision.ee.ethz.ch
Object Recognition with Deformable Models
 Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Human Context: Modeling human-human interactions for monocular 3D pose estimation
 Human Context: Modeling human-human interactions for monocular 3D pose estimation Mykhaylo Andriluka Leonid Sigal Max Planck Institute for Informatics, Saarbrücken, Germany Disney Research, Pittsburgh,
Human Context: Modeling human-human interactions for monocular 3D pose estimation Mykhaylo Andriluka Leonid Sigal Max Planck Institute for Informatics, Saarbrücken, Germany Disney Research, Pittsburgh,
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based