GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
|
|
|
- Baldric Bennett
- 6 years ago
- Views:
Transcription

1 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA


2 ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2






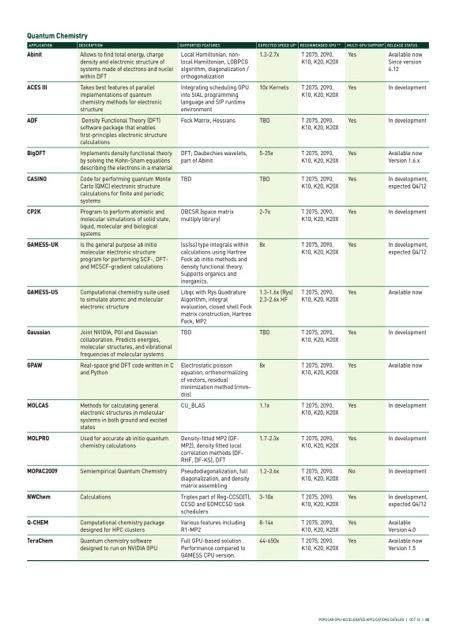
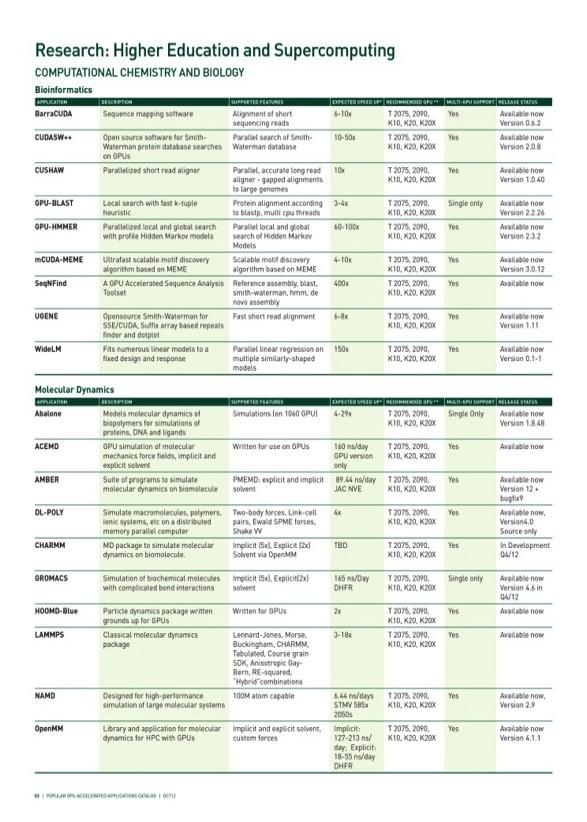
3 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles simulation of combustion for new high-efficiency, lowemission engines. Predictive calculations for thermonuclear and core-collapse supernovae, allowing confirmation of theoretical models. Comprehensive Earth System Model at 1km scale, enabling modeling of cloud convection and ocean eddies. Coupled simulation of entire cells at molecular, genetic, chemical and biological levels. 3

4 EXAFLOP EXPECTATIONS 1 EF First Exaflop Computer 1 PF Titan 8.2 MW 1 TF 1 GF CM5 ~200 KW Growing size, cost and power
5 Power for CPU-only Exaflop Supercomputer = Power for the Bay Area, CA (San Francisco + San Jose) HPC s Biggest Challenge: Power 5





6 MOORE S LAW IS ONLY PART OF THE STORY 2013: 7B transistors 2010: 3B transistors 2007: 580M transistors 2004: 275M transistors 2001: 42M transistors 1997: 7.5M transistors 1993: 3M transistors 6

7 ROBERT DENNARD, IBM! 1968: invented DRAM! 1974: postulated all key figures of merit of MOSFETs improve provided geometric dimensions, voltages, and doping concentrations are consistently scaled to maintain the same electric field. 7
8 CLASSIC DENNARD SCALING 2.8x chip capability in same power 3 2,5 1.4x faster transistors 0.7x capacitance Chip Power 2 2x more transistors 0.7x voltage 1, ,5 2 2,5 3 Chip Capability 8
9 POST DENNARD SCALING 2x chip capability at 1.4x power 1.4x chip capability at same power 3 Transistors are no faster Static leakage limits reduction in V th => V dd stays constant 2,5 Chip Power 2 2x more transistors 0.7x capacitance 1,5 0.7x voltage 1 1 1,5 2 2,5 3 Chip Capability 9
10 THE HIGH COST OF DATA MOVEMENT Fetching operands costs more than computing on them 64-bit DP 20 pj 26 pj 256 pj 256-bit access 8 kb SRAM 50 pj 256 bits 16 nj DRAM Rd/Wr 500 pj Efficient off-chip link 1 nj 20mm 28nm IC Relative cost grows with each generation Wire delay (ps/mm) not improving 10


")

11 1) Stop making it worse... SO, WHAT TO DO? Multicore CPUs But still only a tiny fraction of CPU power spent on flops 2) Unwind all that complexity we threw at single thread performance 11

12 HPC IS GOING HYBRID x86 CPU Fast single threads (serial work) PCIe Sandy Bridge 32nm 690 pj/flop GPU Extreme power-efficiency (throughput work) Kepler 28nm 132 pj/flop! Do most work by cores optimized for extreme energy efficiency! Still need a few cores optimized for fast serial work PCIe Xeon (AMD Fusion too) Intel MIC 12
13 EXPLOSIVE GROWTH OF GPU COMPUTING 150K CUDA Downloads 1.5M CUDA Downloads 1 Supercomputer 52 Supercomputers 60 Universities 560 Universities 4,000 Academic Papers 22,500 Academic Papers

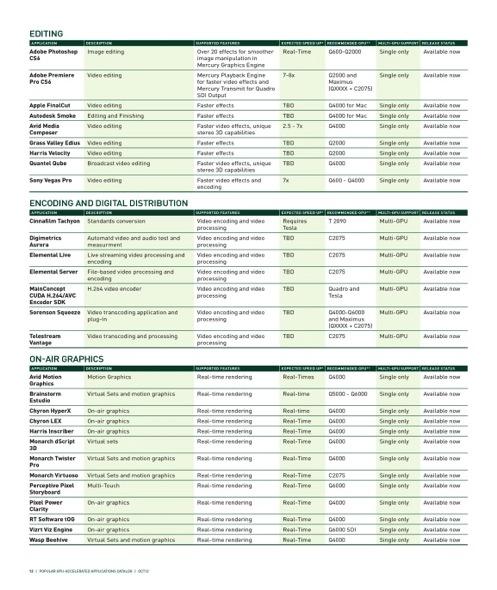
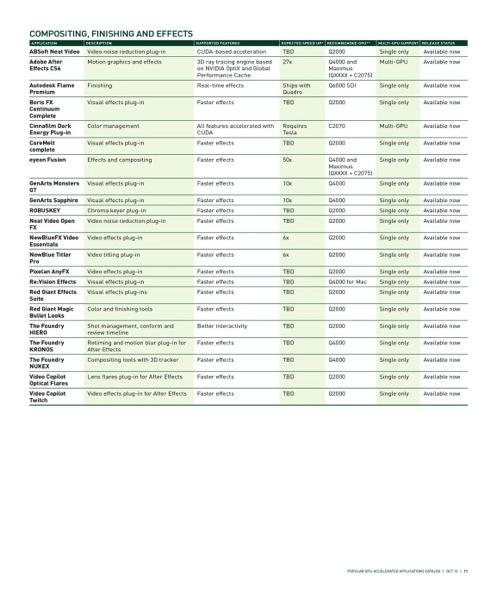
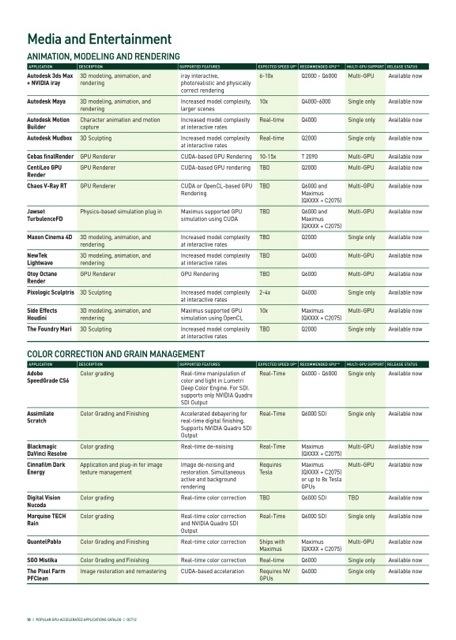
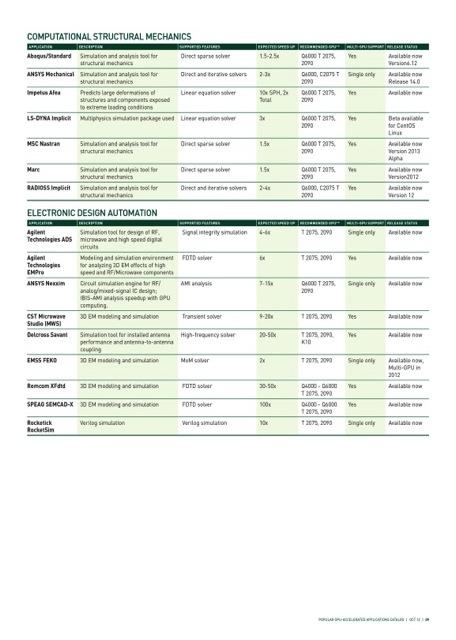
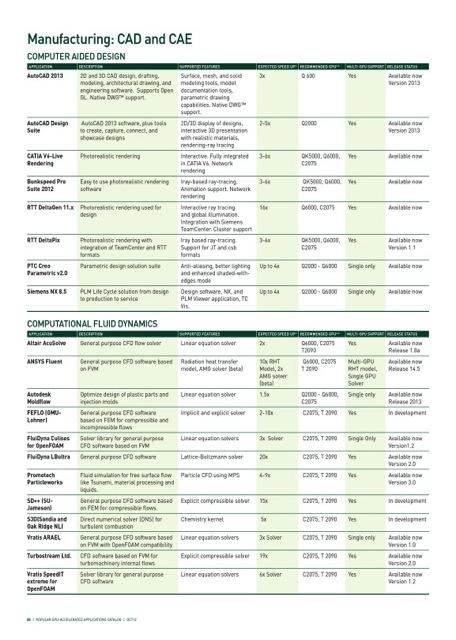
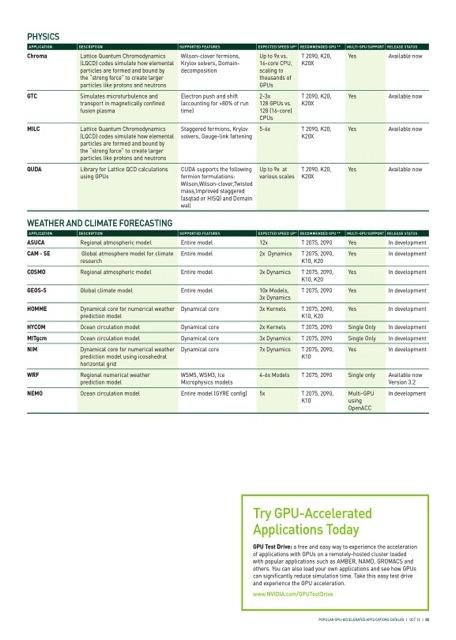

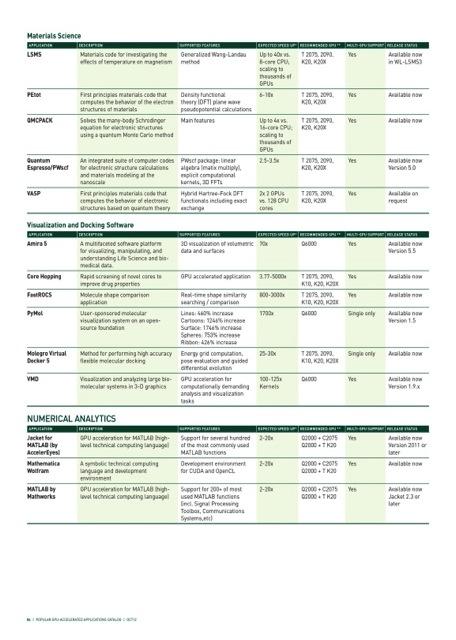



14 Hundreds of GPU-Accelerated Applications 14

15 BREAKTHROUGH EFFICIENCY June 2014 Green 500 list, Tesla powers 15 of the most energyefficient supercomputers First sweep since IBM BlueGene Tsubame-KFC: 4.3 GFLOPS / Watt 15



16 OVERARCHING GOALS FOR TESLA Power Efficiency Ease of Programming And Portability Application Space Coverage 16




17 GK110 GPU KEPLER THE WORLD S FASTEST, MOST EFFICIENT HPC ACCELERATOR SMX Hyper-Q Dynamic Parallelism (power efficiency) (programmability and application coverage) 17



18 TESLA K80 WORLD S FASTEST ACCELERATOR FOR DATA ANALYTICS AND SCIENTIFIC COMPUTING Dual-GPU Accelerator for Max Throughput 2x Faster 2.9 TF 4992 Cores 480 GB/s 25x 20x 15x Deep Learning: Caffe Double the Memory Designed for Big Data Apps 24GB K40 12GB Maximum Performance Dynamically Maximize Perf for Every Application 10x 5x 0x CPU Tesla K40 Tesla K80 Oil & HPC Gas Viz Data Analytics Caffe Benchmark: AlexNet training throughput based on 20 iterations, CPU: 2.70GHz. 64GB System Memory, CentOS
19 PERFORMANCE LEAD CONTINUES TO GROW Peak Double Precision FLOPS Peak Memory Bandwidth GFLOPS GB/s K K K K M1060 K20 M2090 Sandy Bridge Westmere Haswell Ivy Bridge M1060 K20 M2090 Sandy Bridge Westmere Haswell Ivy Bridge NVIDIA GPU x86 CPU NVIDIA GPU x86 CPU 19

20 TESLA K80: 10X FASTER ON REAL-WORLD APPS 15x 10x K80 CPU 5x 0x Benchmarks Molecular Dynamics Quantum Chemistry CPU: 12 cores, 2.70GHz. 64GB System Memory, CentOS 6.2 GPU: Single Tesla K80, Boost enabled Physics 20

21 WHAT DOES THE FUTURE HOLD? 21
22 FAST PACED CUDA GPU ROADMAP Pascal Unified Memory 3D Memory NVLink 16 SGEMM / W Normalized Kepler Dynamic Parallelism Maxwell DX Tesla CUDA Fermi FP
! 3x Larger Capacity!")
23 PASCAL GPU FEATURES NVLINK AND STACKED MEMORY NVLINK! GPU high speed interconnect! GB/s 3D Stacked Memory! 4x Higher Bandwidth (~1 TB/s)! 3x Larger Capacity! 4x More Energy Efficient per bit 23

24 KEPLER GPU PASCAL GPU NVLink NVLINK HIGH-SPEED GPU INTERCONNECT POWER CPU NVLink PCIe PCIe X86, ARM64, POWER CPU 2014 X86, ARM64, POWER CPU



25 3D MEMORY Memory Bandwidth D Chip-on-Wafer integration Many X bandwidth 2.5X capacity 4X energy efficiency



26 PASCAL NVLink 3D Memory Module 5 to 12X PCIe to 4X memory BW & size 1/3 size of PCIe card GPU Chip Power Regulation Memory Stacks 26








27 PARALLELISM IN MAINSTREAM LANGUAGES! Enable more programmers to write parallel software! Give programmers the choice of language to use! GPU support in key languages C 27
, f); // explicitly sequential loop std::for_each(std::seq, vec.begin(), vec.end(), f); // permitting parallel execution std::for_each(std::par, vec.")

28 C++ PARALLEL ALGORITHMS LIBRARY std::vector<int> vec =... // previous standard sequential loop std::for_each(vec.begin(), vec.end(), f); // explicitly sequential loop std::for_each(std::seq, vec.begin(), vec.end(), f); // permitting parallel execution std::for_each(std::par, vec.begin(), vec.end(), f); Complete set of parallel primitives: for_each, sort, reduce, scan, etc. ISO C++ committee voted unanimously to accept as official tech. specification working draft N3960 Technical Specification Working Draft: Prototype: 28



29 LINUX GCC COMPILER TO SUPPORT GPU Open Source Free to all Linux users Most Widely Used HPC Compiler Incorporating OpenACC into GCC is an excellent example of open source and open standards working together to make accelerated computing broadly accessible to all Linux developers. Oscar Hernandez Oak Ridge National Laboratories 29


![jit( void(float32[:], float32, float32[:],](/docs-images/75/72929979/images/30-5.jpg "float32[:]) ) def saxpy(out, a, x, y): i =")
![cuda.grid(1) out[i] = a * x[i] + y[i] #](/docs-images/75/72929979/images/30-6.jpg "Launch saxpy kernel saxpy[griddim,")
30 NUMBA PYTHON COMPILER Free and open source compiler for array-oriented Python NEW numba.cuda module integrates CUDA directly into void(float32[:], float32, float32[:], float32[:]) ) def saxpy(out, a, x, y): i = cuda.grid(1) out[i] = a * x[i] + y[i] # Launch saxpy kernel saxpy[griddim, blockdim](out, a, x, y) 30
![COMPILE JAVA FOR GPUS Approach: apply a closure to a set of arrays // vector addition float[] X = {1.0, 2.](/docs-images/75/72929979/images/31-2.jpg "0, 3.0, 4.0, }; float[] Y = {9.0, 8.1, 7.2, 6.3, }; float[] Z = {0.0, 0.0, 0.0, 0.0, }; jog.")
 { return x + y; } } ); 14 12 10 8 6 4 2 0 Java Black-Scholes Options Pricing Speedup Speedup vs.")

31 COMPILE JAVA FOR GPUS Approach: apply a closure to a set of arrays // vector addition float[] X = {1.0, 2.0, 3.0, 4.0, }; float[] Y = {9.0, 8.1, 7.2, 6.3, }; float[] Z = {0.0, 0.0, 0.0, 0.0, }; jog.foreach(x, Y, Z, new jogcontext(), new jogclosureret<jogcontext>() { public float execute(float x, float y) { return x + y; } } ); Java Black-Scholes Options Pricing Speedup Speedup vs. Sequential Java Millions of Options Learn More: S4939: Vinod Grover: Accelerating JAVA on GPUs Wednesday, 17:30-17:55 Room LL20C foreach iterations parallelized over GPU threads 31
32 ! Power is the constraint THE FUTURE OF HPC IS GREEN! Vast majority of work must be done by cores designed for efficiency! GPU computing has a sustainable model! Aligned with technology trends, supported by consumer markets! Future evolution will focus on:! Integration (CPU, network, memory)! Increased generality efficient on any code with high parallelism! This is simply how computers will be built 32
33
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA
 EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
NVIDIA S VISION FOR EXASCALE. Cyril Zeller, Director, Developer Technology
 NVIDIA S VISION FOR EXASCALE Cyril Zeller, Director, Developer Technology EXASCALE COMPUTING An industry target of 1 ExaFlops within 20 MW by 2020 1 ExaFlops: a necessity to advance science and technology
NVIDIA S VISION FOR EXASCALE Cyril Zeller, Director, Developer Technology EXASCALE COMPUTING An industry target of 1 ExaFlops within 20 MW by 2020 1 ExaFlops: a necessity to advance science and technology
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Efficiency and Programmability: Enablers for ExaScale. Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford
, EE&CS, Stanford") Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
THE PATH TO EXASCALE COMPUTING. Bill Dally Chief Scientist and Senior Vice President of Research
 THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
The Visual Computing Company
 The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
TESLA ACCELERATED COMPUTING. Mike Wang Solutions Architect NVIDIA Australia & NZ
 TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
HPC Cineca Infrastructure: State of the art and towards the exascale
 HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY. Peter Messmer
 NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
The Future of High- Performance Computing
 Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Stan Posey, NVIDIA, Santa Clara, CA, USA
 Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
LECTURE ON PASCAL GPU ARCHITECTURE. Jiri Kraus, November 14 th 2016
 LECTURE ON PASCAL GPU ARCHITECTURE Jiri Kraus, November 14 th 2016 ACCELERATED COMPUTING CPU Optimized for Serial Tasks GPU Accelerator Optimized for Parallel Tasks 2 ACCELERATED COMPUTING CPU Optimized
LECTURE ON PASCAL GPU ARCHITECTURE Jiri Kraus, November 14 th 2016 ACCELERATED COMPUTING CPU Optimized for Serial Tasks GPU Accelerator Optimized for Parallel Tasks 2 ACCELERATED COMPUTING CPU Optimized
The Future of High Performance Computing
 The Future of High Performance Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Comparing Two Large-Scale Systems Oakridge Titan Google Data Center 2 Monolithic supercomputer
The Future of High Performance Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Comparing Two Large-Scale Systems Oakridge Titan Google Data Center 2 Monolithic supercomputer
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
The Future of GPU Computing
 The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
NVIDIA Tesla P100. Whitepaper. The Most Advanced Datacenter Accelerator Ever Built. Featuring Pascal GP100, the World s Fastest GPU
 Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World s Fastest GPU NVIDIA Tesla P100 WP-08019-001_v01.2 1 Table of Contents Introduction...
Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World s Fastest GPU NVIDIA Tesla P100 WP-08019-001_v01.2 1 Table of Contents Introduction...
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
GPU Computing. Axel Koehler Sr. Solution Architect HPC
 GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
HIGH-PERFORMANCE COMPUTING
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Microprocessor Trends and Implications for the Future
 Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
HPC Architectures past,present and emerging trends
 HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory