Advanced issues in pipelining
|
|
|
- Derick Banks
- 6 years ago
- Views:
Transcription
1 Advanced issues in pipelining 1
2 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2
3 Handling exceptions 3
4 Exceptions In pipelined execution, one instructions completes in N clock cycles Clock cycle is the minimum granularity for interrupts So, exceptions can interrupt execution of several instructions! We must include capabilities to cancel an instruction while executing! Source of interrupts: Power failure Arithmetic overflow I/O device request OS call Page fault 4
5 Exception source in pipeline Each stage has its sources: IF Page fault on instruction fetch Misaligned memory access Memory-protection violation ID Undefined or illegal opcode EX Arithmetic interrupt MEM Page fault on data fetch Misaligned memory access Memory-protection violation 5
6 Exception handling Complications: Simultaneous exceptions in more than one pipeline stage, e.g., Load with data page fault in MEM stage Add with instruction page fault in IF stage Add fault will happen BEFORE load fault In MIPS, exceptions tend to occur in the EX or MEM stage (e.g., late in the pipe) Requirements: Pipeline must be safely shut down PC must be saved so restart point is known If restart is a branch then it will need to be re-executed Which means the condition code state must not change 6
7 Exception handling (2) MIPS/DLX sequence: When an exception occurs, the pipeline control does: 1. Force trap instruction into pipeline on next IF 2. Squash all instructions that follow (0 s to pipeline registers) Prevent not-completed instructions from changing state! 3. Let all preceding instructions complete if they can 4. Save the restart PC value If delayed branches are used, save BDS+1 PCs 5. OS handle the exception (saves PC of faulting instructions for later restart) 7
8 Precise exceptions (1) Definition: Exceptions are called precise if they leave the machine in a state that is consistent with the sequential execution model Otherwise they are called imprecise (or non-precise) Example: A precedes B B finishes before A and modifies state imprecise 8
9 Precise exceptions (2) Condition for preciseness: 1. All instructions before the faulting instruction have completed (and modified machine state) 2. All instructions after the faulting instruction have not completed (nor modified machine state) 3. The faulting instruction may or may not complete, but is either completed or it has to be started Precise exceptions are not always possible e.g., FP operations Most machines have two operation modes: Precise exceptions (slow, less overlapping) Non-precise exception (fast) 9
10 Handling exceptions: example I IF ID EX MEM WB I+1 I+2 I+3 I+4 I+5 IF ID IF EX ID IF MEM EX ID IF WB MEM EX ID IF WB MEM EX ID WB MEM EX WB MEM WB <- Page fault <- Squash <- Squash <- Squash I+6 IF ID EX MEM WB Interrupt handler 10
11 Handling exceptions: example (2) 11
 ldq or addq xor")
12 Handling exceptions: example (2) ldq or addq xor and 12
 bubble(nop) bubble(nop) xor")
13 Handling exceptions: example (2) stq bubble(nop) bubble(nop) bubble(nop) xor 13
14 Further complications in pipelines Complex Addressing Modes and Instructions Address modes: Autoincrement causes register change during instruction execution Interrupts? Need to restore register state Adds WAR and WAW hazards since writes are no longer the last stage. Memory-Memory Move Instructions Must be able to handle multiple page faults Long-lived instructions: partial state save on interrupt Condition Codes Ex., PSW bits 14
15 Multi-cycle operations 15
16 Multi-cycle Operations It is impractical to require that all operations complete in one clock cycle What about FP operations? Recall that clock cycle is bounded by slowest pipeline stage Doing FP ops in one cycle would mean to use a slow clock Use a modified pipeline: The EX cycle is repeated as many times as needed to complete the operation There may be multiple floating-point functional units. 16
 FP and integer divider If we assume that the execution stages of these functional units are not pipelined Cycling for computation")
17 Multi-cycle Operations (2) Four separate functional units: The main integer unit FP and integer multiplier FP adder (handles FP add, subtract, and conversion) FP and integer divider If we assume that the execution stages of these functional units are not pipelined Cycling for computation 17
18 Multi-Cycle Operations (3) Floating point gives long execution time. It s possible to pipeline the FP execution unit so it can initiate new instructions without waiting full latency. Can also have multiple FP units. Typical values: FP Instruction Latency Add, Subtract 4 Multiply 8 Divide 36 Square root 112 Negate 2 Absolute value 2 FP compare 3 # of stages after EX an Instruction produces a result Initiation interval = time between two successive ops (= latency-1) 18
19 Multi-Cycle Operations (4) To reduce initiation interval, some long operations are pipelined Some may not be pipelined e.g, sometimes division not pipelined Implementation: 19
20 Multi-Cycle Operations (5) Example (independent operations): MULTD IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB ADDD IF ID A1 A2 A3 A4 MEM WB LD IF ID EX MEM WB SD IF ID EX MEM WB 20
21 Multi-Cycle Operations: problems Longer latencies increase the chance of RAW hazards Ex: instruction needing result of an FP ADD must wait 4 cycles Non-pipelined operations increase the chance of structural hazards WAW are now possible (but no WAR) Instructions do not reach WB in order Instruction complete in different order than issued Problems with exceptions Different latencies may require multiple write to registers 21
22 Multi-Cycle Operations: problems Example: RAW stalls LD F4,0(R2) IF ID EX MEM WB MULTD F0,F4,F,6 IF ID stall M1 M2 M3 M4 M5 M6 M7 MEM WB ADDD F2,F0,F8 IF ID stall stall stall stall stall stall stall A1 A2 A3 A4 MEM SD F2,0(R2) IF stall stall stall stall stall stall stall stall stall stall stall MEM Example: multiple writes to register MULTD F0,F4,F,6 IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB IF ID EX MEM WB IF ID EX MEM WB ADDD F2, F2, F6 IF ID A1 A2 A3 A4 MEM WB IF ID EX MEM WB IF ID EX MEM WB LD F8, 0(R2) IF ID EX MEM WB 22
23 Multi-Cycle Operations Performance impact: Average # of stalls for operation type add/sub compare mult div doduc ear hydro2d mdlijdp su2cor 23
24 Pipeline evolution 24
25 Out-of-order execution Superscalar pipelines Superpipelines Outline 25
26 Out-of-order execution Assumptions so far: In-order instruction execution: If an instruction is stalled in the pipeline, later instructions cannot proceed Static scheduling The hardware minimizes the impact of hazards It is up to the compiler to schedule dependent instructions so as to avoid hazards Static = No exploitation of run-time scheduling opportunities Improvements: Out-of-order (OOO) execution Dynamic scheduling Done by the hardware! 26
27 OOO execution In traditional pipelines, a hazards also stalls instructions that are not affected by it Example DIVD $0, $2, $4 ADDD $10, $0, $8 SUBD $12, $8, $4 The SUB is independent of the rest, yet it is stopped (for several cycles) Particularly critical for multi-cycle instructions Why not let SUB complete? Need extra hardware to do this Need to separate: Hazard detection phase Instruction issue phase 27
28 OOO execution (2) Hazard detection and instruction issue done in the ID stage Split ID conceptually into two stages: Issue Decode instructions and check for hazards Read operands Wait until no data hazards, then read operands IF/ID ID/EX Issue Read ops ID 28
29 OOO execution (3) Definitions: Three phases of instruction processing: 1. Instruction issue (or dispatch) 2. Instruction execution: There will be multiple instructions in execution at the same time (thanks to availability of several independent functional units) 3. Instruction commit (or completion) When results are written Typically: Issue: in-order Execution: out-of-order Commit: may be either one 29
30 Dynamic scheduling OOO execution = instruction issue is still in order! WAR hazards now possible! Example: DIVD $0, $2, $4 ADDD $10, $0, $8 SUBD $8, $8, $4 If SUBD is executed first, it will write a new $8 before it is read by ADDD 30
31 OOO execution: organization Result bus Reservation station (a.k.a. issue queues) Buffers where instructions wait for the desired unit Realize the issue phase 31
32 OOO execution: organization (2) Traditional MEM stage has disappeared MEM accesses managed by a proper LOAD/STORE unit EX stage consists of multiple units with different latencies There is a single result bus for transferring results of the various units to register file 32
33 OOO execution schemes Three solutions: Commit-in-order: Instructions are committed according to the architectural order Reorder buffer: Instructions are committed out of order, but they are forced to modify the machine state according to the architectural order History buffer: Instructions are committed out of order, and machine state is modified in any order, but it is always possible to restore a consistent state in case of hazards 33
34 OOO execution: architecture Single result bus requires a bus reservation scheme Implemented through the Result Shift Register (RSR) Position j of RSR is reserved when instruction I (taking j cycles for EX) is issued If taken by an earlier instruction, I is kept waiting in reservation stations for 1 cycle (after that, retry) Contents of RSR shifted at each cycle unit1 unit2 unitn RSR RF 34
35 RSR structure Information contained in the RSR: Identifier of unit to be used Destination register Validity bit (actual reservation or not) PC (for state restoration) Example: 100 multd f12,f8,f10 (10 cycles) 104 addd f18,f14,f16 (2 cycles) 1 Unit Rd V PC 2 Add F Mult F
36 Commit-in-order RSR is reserved so that commit is in the same order as the program Implementation Instruction I when reserving RSR slot j also reserves slots 0,,j-1 that are not yet reserved Done by using some bits in an RSR entry 36
37 Reorder buffer (1) Results are fed to the Reorder buffer (ROB) ROB works as a circular queue Head = instruction that when completed will modify first the state Tail = where issued instructions are inserted Entries contain: Destination register unit1 unit2 unitn RSR ROB RF Instruction result Commit bit (instruction is committed) PC RSR now contains a pointer to position in ROB 37
38 Reorder buffer (2) Completed instructions will leave RSR but not ROB Instructions leave ROB in order! Entries that leave RSR write result in ROB entry! Example: 100 multd f12,f8,f10 (10 cycles) 104 addd f18,f14,f16 (2 cycles) Unit Rd V PC prob Rd Result C PC Add F F12 F head tail 10 Mult F n m RSR m>n ROB 38
39 History buffer (1) Improves ROB Similar to ROB Circular queue Entries contain: Destination register Old value of destination register Commit bit PC RSR contains a pointer to HB unit1 unit2 unitn RSR RF HB 39
40 History buffer (2) Results are written in RF as soon as available If there is no need of restoring the previous state, the (committed) instruction at the top of HB leaves HB Note: Instructions can be issued only if dependencies are solved; if not, they are queued Consequence: state must be restored only because of Interrupts Mispredicted branches 40
41 P6 architecture 41
42 P6 Pipeline 42

43 P6 pipeline 43
44 Advanced architectures 44
45 Getting CPI < 1: Issuing Multiple Instructions/Cycle Two variants: Superscalar: Varying no. instructions/cycle (1 to 8), scheduled by compiler or by HW IBM PowerPC, Sun UltraSparc, DEC Alpha, HP 8000 Very Long Instruction Words (VLIW): Fixed number of instructions (4-16) scheduled by the compiler Put operations into wide templates Instructions Per Clock cycle (IPC) vs. CPI 45

46 VLIW Statically scheduled ILP architecture. Wide instructions specify many independent simple operations Multiple functional units execute all of the operations in an instruction concurrently Instructions directly control the hardware with minimal decoding A powerful compiler is responsible for locating and extracting ILP from the program and for scheduling operations to exploit the available parallel resources VLIW Instruction bits 46
47 EPIC EPIC (Explicitly Parallel Instruction Computing) An ISA philosophy/approach (IA-64 - Itanium) Very closely related to but not the same as VLIW Similarities: Compiler generated wide instructions Static detection of dependencies ILP encoded in the binary (a group) Large number of architected registers Differences: Instructions in a bundle can have dependencies Hardware interlock between dependent instructions Allows dynamic scheduling and functional unit binding Accommodates varying number of functional units and latencies 47
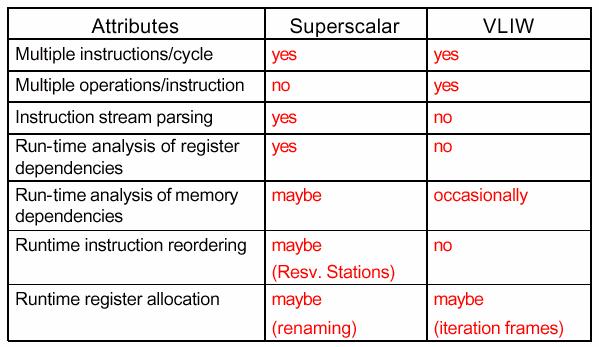
48 Superscalar v. VLIW 48
49 Intel/HP Explicitly Parallel Instruction Computer (EPIC) 3 Instructions in 128 bit groups Field determines if instructions dependent or independent Smaller code size than old VLIW, larger than x86/risc Groups can be linked to show independence > 3 instr 64 integer registers + 64 floating point registers Not separate files per funcitonal unit as in old VLIW Hardware checks dependencies (interlocks => binary compatibility over time) Predicated execution (select 1 out of 64 1-bit flags) => 40% fewer mispredictions? IA-64 : name of instruction set architecture; EPIC is type Merced is name of first implementation (1999/2000?) LIW = EPIC? 49
50 Architectural Trends Simultaneous Multi-Threading (SMT) processors Thread-level parallelism (TLP) as opposed to instruction-level one (ILP) Memory-centric processors (I-RAM) Vector-processor ISA organized around a large amount of on-chip memory (not only caches) Super-speculative processors Superscalar architectures bringing speculation and OOO to the extreme Trace processors Execute pre-fetched sequences of instructions viewed as a trace 50
51 Examples of real pipelines 51

52 UltraSPARC pipeline 52

53 Alpha pipeline 53
54 PentiumPro pipeline 54
55 Summary Interrupts, Instruction Set, FP makes pipelining harder Hardware can improve that 55
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1
![Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1](/thumbs/92/108067849.jpg "Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1") Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
COSC4201. Prof. Mokhtar Aboelaze York University
 COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Computer Systems Architecture I. CSE 560M Lecture 5 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
COMP 4211 Seminar Presentation
 COMP Seminar Presentation Based On: Computer Architecture A Quantitative Approach by Hennessey and Patterson Presenter : Feri Danes Outline Exceptions Handling Floating Points Operations Case Study: MIPS
COMP Seminar Presentation Based On: Computer Architecture A Quantitative Approach by Hennessey and Patterson Presenter : Feri Danes Outline Exceptions Handling Floating Points Operations Case Study: MIPS
There are different characteristics for exceptions. They are as follows:
 e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EEC 581 Computer Architecture. Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW)
") 1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Page 1. Recall from Pipelining Review. Lecture 15: Instruction Level Parallelism and Dynamic Execution
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
Lecture 9: Multiple Issue (Superscalar and VLIW)
") Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Execution/Effective address
 Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
Instruction Level Parallelism
 Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Review: Evaluating Branch Alternatives. Lecture 3: Introduction to Advanced Pipelining. Review: Evaluating Branch Prediction
 Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
EEC 581 Computer Architecture. Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW)
") EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Administrivia. CMSC 411 Computer Systems Architecture Lecture 6. When do MIPS exceptions occur? Review: Exceptions. Answers to HW #1 posted
 Administrivia CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining (cont.) Alan Sussman als@cs.umd.edu as@csu dedu Answers to HW #1 posted password protected, with instructions sent via email
Administrivia CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining (cont.) Alan Sussman als@cs.umd.edu as@csu dedu Answers to HW #1 posted password protected, with instructions sent via email
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 7: Pipelining Contd. More pipelining complications: Interrupts and Exceptions
 Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
09-1 Multicycle Pipeline Operations
 09-1 Multicycle Pipeline Operations 09-1 Material may be added to this set. Material Covered Section 3.7. Long-Latency Operations (Topics) Typical long-latency instructions: floating point Pipelined v.
09-1 Multicycle Pipeline Operations 09-1 Material may be added to this set. Material Covered Section 3.7. Long-Latency Operations (Topics) Typical long-latency instructions: floating point Pipelined v.
CISC 662 Graduate Computer Architecture. Lecture 10 - ILP 3
 CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Hardware-based Speculation
 Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Review: Compiler techniques for parallelism Loop unrolling Ÿ Multiple iterations of loop in software:
 CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
Complications with long instructions. CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. How slow is slow?
 Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Complex Pipelining COE 501. Computer Architecture Prof. Muhamed Mudawar
 Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
The basic structure of a MIPS floating-point unit
 Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 09
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 09
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
EECC551 Review. Dynamic Hardware-Based Speculation
 EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Complex Pipelining: Out-of-order Execution & Register Renaming. Multiple Function Units
 6823, L14--1 Complex Pipelining: Out-of-order Execution & Register Renaming Laboratory for Computer Science MIT http://wwwcsglcsmitedu/6823 Multiple Function Units 6823, L14--2 ALU Mem IF ID Issue WB Fadd
6823, L14--1 Complex Pipelining: Out-of-order Execution & Register Renaming Laboratory for Computer Science MIT http://wwwcsglcsmitedu/6823 Multiple Function Units 6823, L14--2 ALU Mem IF ID Issue WB Fadd
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Website for Students VTU NOTES QUESTION PAPERS NEWS RESULTS
 Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
Lecture 4: Introduction to Advanced Pipelining
 Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles
 CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Lecture 5: VLIW, Software Pipelining, and Limits to ILP. Review: Tomasulo
 Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards