CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
|
|
|
- Sara Bryant
- 5 years ago
- Views:
Transcription
1 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
2 Last time in Lecture 11 Register renaming removes WAR, WAW hazards In-order fetch/decode, out-of-order execute, in-order commit gives high performance and precise exceptions Need to rapidly recover on branch mispredictions Unified physical register file machines remove data values from ROB All values only read and written during execution Only register tags held in ROB 2
3 Question of the Day How many in-order cores do you think take up the same area as an out-of-order core? 3
4 Reminder Out-of-Order In-Order PC Fetch Decode & Rename Reorder Buffer Commit In-Order Physical Reg. File Branch Unit Execute ALU MEM Store Buffer D$ 4
5 Separate Pending Instruction Window from ROB The instruction window holds instructions that have been decoded and renamed but not issued into execution. Has register tags and presence bits, and pointer to ROB entry. Reorder buffer used to hold exception information for commit. use ex Ptr 2 next to commit Ptr 1 next available Instructions that committed are not in the instruction window any more op p1 PR1 p2 PR2 PRdROB# Done? Rd LPRd PC Except? ROB is usually several times larger than instruction window why? 5
6 Reorder Buffer Holds Active Instructions (Decoded but not Committed) ld x1, (x3) add x3, x1, x2 sub x6, x7, x9 add x3, x3, x6 ld x6, (x1) add x6, x6, x3 sd x6, (x1) ld x6, (x1) (Older instructions) (Newer instructions) Commit Execute Fetch ld x1, (x3) add x3, x1, x2 sub x6, x7, x9 add x3, x3, x6 ld x6, (x1) add x6, x6, x3 sd x6, (x1) ld x6, (x1) Cycle t Cycle t + 1 6
7 Issue Timing i1 Add R1,R1,#1 Issue 1 Execute 1 i2 Sub R1,R1,#1 Issue 2 Execute 2 How can we issue earlier? Using knowledge of execution latency (bypass) i1 Add R1,R1,#1 Issue 1 Execute 1 i2 Sub R1,R1,#1 Issue 2 Execute 2 What makes this schedule fail? If execution latency wasn t as expected
8 Issue Queue with latency prediction Inst# use exec op p1 lat1 src1 p2 lat2 src2 dest ptr 2 next to commit BEQZ Speculative Instructions ptr 1 next available Issue Queue (Reorder buffer) Fixed latency: latency included in queue entry ( bypassed ) Predicted latency: latency included in queue entry (speculated) Variable latency: wait for completion signal (stall)
9 Improving Instruction Fetch Performance of speculative out-of-order machines often limited by instruction fetch bandwidth speculative execution can fetch 2-3x more instructions than are committed mispredict penalties dominated by time to refill instruction window taken branches are particularly troublesome
10 Increasing Taken Branch Bandwidth (Alpha I-Cache) PC Generation Branch Prediction Instruction Decode Validity Checks PC Line Predict Way Predict Cached Instructions Tag Way 0 Tag Way 1 4 insts fast fetch path Fold 2-way tags and BTB into predicted next block Take tag checks, inst. decode, branch predict out of loop Raw RAM speed on critical loop (1 cycle at ~1 GHz) 2-bit hysteresis counter per block prevents overtraining =? =? Hit/Miss/Way
11 Tournament Branch Predictor (Alpha 21264) Local history table (1,024x10b) Local prediction (1,024x3b) Global Prediction (4,096x2b) PC Choice Prediction (4,096x2b) Prediction Global History (12b) Choice predictor learns whether best to use local or global branch history in predicting next branch (best in each case) Global history is speculatively updated but restored on mispredict Claim % success on range of applications
12 Taken Branch Limit Integer codes have a taken branch every 6-9 instructions To avoid fetch bottleneck, must execute multiple taken branches per cycle when increasing performance This implies: predicting multiple branches per cycle fetching multiple non-contiguous blocks per cycle
13 Branch Address Cache (Yeh, Marr, Patt) Entry PC Valid predicted target #1 len predicted target #2 k PC = match valid target#1 len#1 target#2 Extend BTB to return multiple branch predictions per cycle
14 Fetching Multiple Basic Blocks Requires either multiported cache: expensive interleaving: bank conflicts will occur Merging multiple blocks to feed to decoders adds latency increasing mispredict penalty and reducing branch throughput
15 Trace Cache Key Idea: Pack multiple non-contiguous basic blocks into one contiguous trace cache line BR BR BR BR BR BR Single fetch brings in multiple basic blocks Trace cache indexed by start address and next n branch predictions Used in Intel Pentium-4 processor to hold decoded uops
16 Write Ports Superscalar Register Renaming During decode, instructions allocated new physical destination register Source operands renamed to physical register with newest value Execution unit only sees physical register numbers Inst 1 Op Dest Src1 Src2 Op Dest Src1 Src2 Inst 2 Update Mapping Read Addresses Rename Table Read Data Register Free List Issue multiple instructions per cycle Op PDest PSrc1 PSrc2 Op PDest PSrc1 PSrc2 Does this work? 16
17 Write Ports Superscalar Register Renaming Inst 1 Op Dest Src1 Src2 Op Dest Src1 Src2 Inst 2 Update Mapping Must check for RAW hazards between instructions issuing in same cycle. Can be done in parallel with rename Op lookup. PDest Read Addresses Rename Table Read Data PSrc1 PSrc2 Op =? PDest =? PSrc1 PSrc2 Register Free List MIPS R10K renames 4 serially-raw-dependent insts/cycle 17
18 Speculative Loads / Stores Just like register updates, stores should not modify the memory until after the instruction is committed - A speculative store buffer is a structure introduced to hold speculative store data. 18
19 Speculative Store Buffer V S V S V S V S V S V S Tags Store Address Tag Tag Tag Tag Tag Tag Speculative Store Buffer Store Commit Path Data Data Data Data Data Data L1 Data Cache Store Data Data Just like register updates, stores should not modify the memory until after the instruction is committed. A speculative store buffer is a structure introduced to hold speculative store data. During decode, store buffer slot allocated in program order Stores split into store address and store data micro-operations Store address execute writes tag Store data execute writes data Store commits when oldest instruction and both address and data available: clear speculative bit and eventually move data to cache On store abort: clear valid bit 19
20 Load bypass from speculative store buffer Speculative Store Buffer Load Address L1 Data Cache V V V V V V S S S S S S Tag Tag Tag Tag Tag Tag Data Data Data Data Data Data Tags Data Load Data If data in both store buffer and cache, which should we use? Speculative store buffer If same address in store buffer twice, which should we use? Youngest store older than load 20
21 Memory Dependencies sd x1, (x2) ld x3, (x4) When can we execute the load? 21
22 In-Order Memory Queue Execute all loads and stores in program order => Load and store cannot leave ROB for execution until all previous loads and stores have completed execution Can still execute loads and stores speculatively, and out-oforder with respect to other instructions Need a structure to handle memory ordering 22
23 Conservative O-o-O Load Execution sd x1, (x2) ld x3, (x4) Can execute load before store, if addresses known and x4!= x2 Each load address compared with addresses of all previous uncommitted stores can use partial conservative check i.e., bottom 12 bits of address, to save hardware Don t execute load if any previous store address not known (MIPS R10K, 16-entry address queue) 23
24 Address Speculation Guess that x4!= x2 sd x1, (x2) ld x3, (x4) Execute load before store address known Need to hold all completed but uncommitted load/store addresses in program order If subsequently find x4==x2, squash load and all following instructions => Large penalty for inaccurate address speculation 24
25 Memory Dependence Prediction (Alpha 21264) sd x1, (x2) ld x3, (x4) Guess that x4!= x2 and execute load before store If later find x4==x2, squash load and all following instructions, but mark load instruction as store-wait Subsequent executions of the same load instruction will wait for all previous stores to complete Periodically clear store-wait bits 25
26 Datapath: Branch Prediction and Speculative Execution Branch Prediction kill kill Branch Resolution kill kill PC Fetch Decode & Rename Reorder Buffer Commit Reg. File Branch Unit Execute ALU MEM Store Buffer 26 D$
27 Instruction Flow in Unified Physical Register File Pipeline Fetch Get instruction bits from current guess at PC, place in fetch buffer Update PC using sequential address or branch predictor (BTB) Decode/Rename Take instruction from fetch buffer Allocate resources to execute instruction: Destination physical register, if instruction writes a register Entry in reorder buffer to provide in-order commit Entry in issue window to wait for execution Entry in memory buffer, if load or store Decode will stall if resources not available Rename source and destination registers Check source registers for readiness Insert instruction into issue window+reorder buffer+memory buffer 27
28 Memory Instructions Split store instruction into two pieces during decode: Address calculation, store-address Data movement, store-data Allocate space in program order in memory buffers during decode Store instructions: Store-address calculates address and places in store buffer Store-data copies store value into store buffer Store-address and store-data execute independently out of issue window Stores only commit to data cache at commit point Load instructions: Load address calculation executes from window Load with completed effective address searches memory buffer Load instruction may have to wait in memory buffer for earlier store ops to resolve 28
29 Issue Stage Writebacks from completion phase wakeup some instructions by causing their source operands to become ready in issue window In more speculative machines, might wake up waiting loads in memory buffer Need to select some instructions for issue Arbiter picks a subset of ready instructions for execution Example policies: random, lower-first, oldest-first, critical-first Instructions read out from issue window and sent to execution 29
30 Execute Stage Read operands from physical register file and/or bypass network from other functional units Execute on functional unit Write result value to physical register file (or store buffer if store) Produce exception status, write to reorder buffer Free slot in instruction window 30
31 Commit Stage Read completed instructions in-order from reorder buffer (may need to wait for next oldest instruction to complete) If exception raised flush pipeline, jump to exception handler Otherwise, release resources: Free physical register used by last writer to same architectural register Free reorder buffer slot Free memory reorder buffer slot 31
32 Question of the Day How many in-order cores do you think take up the same area as an out-of-order core? 32

33 How Many In-Order In The Same Area? 33
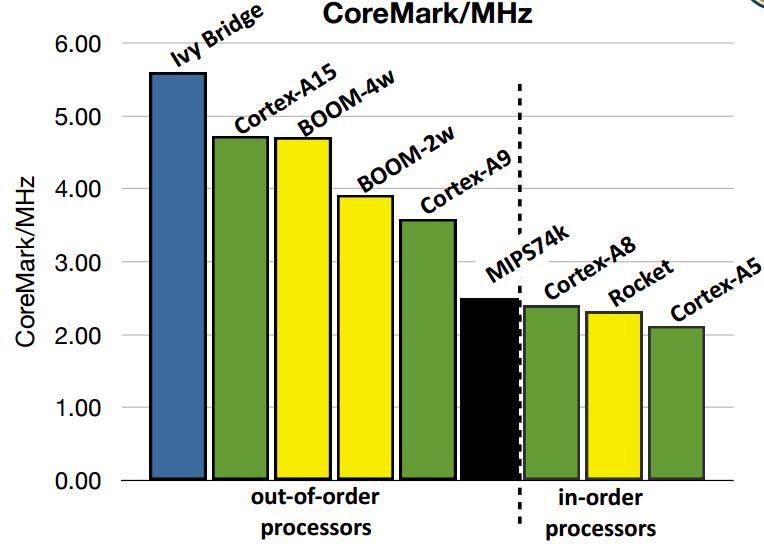
34 Performance? 34
35 Acknowledgements These slides contain material developed and copyright by: Arvind (MIT) Krste Asanovic (MIT/UCB) Joel Emer (Intel/MIT) James Hoe (CMU) John Kubiatowicz (UCB) David Patterson (UCB) MIT material derived from course UCB material derived from course CS252 35
Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars Krste Asanovic Electrical Engineering and Computer
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars Krste Asanovic Electrical Engineering and Computer
CS252 Spring 2017 Graduate Computer Architecture. Lecture 8: Advanced Out-of-Order Superscalar Designs Part II
 CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
 1 cycle per instruction I
1 cycle per instruction I CS 152, Spring 2011 Section 8
 CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152 Computer Architecture and Engineering. Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming
 CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at
CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 9 Instruction-Level Parallelism Part 2
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 9 Instruction-Level Parallelism Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 9 Instruction-Level Parallelism Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
CS 152 Computer Architecture and Engineering. Lecture 13 - Out-of-Order Issue and Register Renaming
 CS 152 Computer Architecture and Engineering Lecture 13 - Out-of-Order Issue and Register Renaming Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://wwweecsberkeleyedu/~krste
CS 152 Computer Architecture and Engineering Lecture 13 - Out-of-Order Issue and Register Renaming Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://wwweecsberkeleyedu/~krste
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 15 Very Long Instruction Word Machines
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 15 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I. Lecture 14 Very Long Instruction Word Machines
 ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 14 Very Long Instruction Word Machines Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
Lecture 13 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering. Lecture 13 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 13 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
Branch Prediction & Speculative Execution. Branch Penalties in Modern Pipelines
 6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
EE 660: Computer Architecture Superscalar Techniques
 EE 660: Computer Architecture Superscalar Techniques Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David entzlaff Agenda Speculation and Branches
EE 660: Computer Architecture Superscalar Techniques Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David entzlaff Agenda Speculation and Branches
Out of Order Processing
 Out of Order Processing Manu Awasthi July 3 rd 2018 Computer Architecture Summer School 2018 Slide deck acknowledgements : Rajeev Balasubramonian (University of Utah), Computer Architecture: A Quantitative
Out of Order Processing Manu Awasthi July 3 rd 2018 Computer Architecture Summer School 2018 Slide deck acknowledgements : Rajeev Balasubramonian (University of Utah), Computer Architecture: A Quantitative
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25
 CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 16: Core Design. Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue
 Lecture 16: Core Design Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue 1 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction
Lecture 16: Core Design Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue 1 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction
Announcements. ECE4750/CS4420 Computer Architecture L11: Speculative Execution I. Edward Suh Computer Systems Laboratory
 ECE4750/CS4420 Computer Architecture L11: Speculative Execution I Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab3 due today 2 1 Overview Branch penalties limit performance
ECE4750/CS4420 Computer Architecture L11: Speculative Execution I Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab3 due today 2 1 Overview Branch penalties limit performance
ECE 252 / CPS 220 Advanced Computer Architecture I. Lecture 8 Instruction-Level Parallelism Part 1
 ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 8 Instruction-Level Parallelism Part 1 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 8 Instruction-Level Parallelism Part 1 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
 ece4750-t11-ooo-execution-notes.txt ========================================================================== ece4750-l12-ooo-execution-notes.txt ==========================================================================
ece4750-t11-ooo-execution-notes.txt ========================================================================== ece4750-l12-ooo-execution-notes.txt ==========================================================================
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CS 152 Computer Architecture and Engineering. Lecture 16 - VLIW Machines and Statically Scheduled ILP
 CS 152 Computer Architecture and Engineering Lecture 16 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16 - VLIW Machines and Statically Scheduled ILP Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
C 1. Last time. CSE 490/590 Computer Architecture. Complex Pipelining I. Complex Pipelining: Motivation. Floating-Point Unit (FPU) Floating-Point ISA
 Floating-Point ISA") CSE 490/590 Computer Architecture Complex Pipelining I Steve Ko Computer Sciences and Engineering University at Buffalo Last time Virtual address caches Virtually-indexed, physically-tagged cache design
CSE 490/590 Computer Architecture Complex Pipelining I Steve Ko Computer Sciences and Engineering University at Buffalo Last time Virtual address caches Virtually-indexed, physically-tagged cache design
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques,
 Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques, ARM Cortex-A53, and Intel Core i7 CSCE 513 Computer Architecture Department of Computer Science and Engineering Yonghong
Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques, ARM Cortex-A53, and Intel Core i7 CSCE 513 Computer Architecture Department of Computer Science and Engineering Yonghong
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Lecture 11: Out-of-order Processors. Topics: more ooo design details, timing, load-store queue
 Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 6 Pipelining Part 1
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 6 Pipelining Part 1 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 6 Pipelining Part 1 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW
: Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW") Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
CS 152 Computer Architecture and Engineering. Lecture 5 - Pipelining II (Branches, Exceptions)
") CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
CS252 Graduate Computer Architecture Lecture 8. Review: Scoreboard (CDC 6600) Explicit Renaming Precise Interrupts February 13 th, 2010
 Explicit Renaming Precise Interrupts February 13 th, 2010") CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
CS252 Graduate Computer Architecture Midterm 1 Solutions
 CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
CS 152, Spring 2012 Section 8
 CS 152, Spring 2012 Section 8 Christopher Celio University of California, Berkeley Agenda More Out- of- Order Intel Core 2 Duo (Penryn) Vs. NVidia GTX 280 Intel Core 2 Duo (Penryn) dual- core 2007+ 45nm
CS 152, Spring 2012 Section 8 Christopher Celio University of California, Berkeley Agenda More Out- of- Order Intel Core 2 Duo (Penryn) Vs. NVidia GTX 280 Intel Core 2 Duo (Penryn) dual- core 2007+ 45nm
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Superscalar Processors
 Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Lecture 4 - Pipelining
 CS 152 Computer Architecture and Engineering Lecture 4 - Pipelining John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 4 - Pipelining John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Lecture 4 Pipelining Part II
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 4 Pipelining Part II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 4 Pipelining Part II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
Announcements. EE382A Lecture 6: Register Renaming. Lecture 6 Outline. Dynamic Branch Prediction Using History. 1. Branch Prediction (epilog)
") Announcements EE382A Lecture 6: Register Renaming Project proposal due on Wed 10/14 2-3 pages submitted through email List the group members Describe the topic including why it is important and your thesis
Announcements EE382A Lecture 6: Register Renaming Project proposal due on Wed 10/14 2-3 pages submitted through email List the group members Describe the topic including why it is important and your thesis
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Lecture 9 - Virtual Memory
 CS 152 Computer Architecture and Engineering Lecture 9 - Virtual Memory Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
CS 152 Computer Architecture and Engineering Lecture 9 - Virtual Memory Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
ECE/CS 552: Introduction to Superscalar Processors
 ECE/CS 552: Introduction to Superscalar Processors Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Limitations of Scalar Pipelines
ECE/CS 552: Introduction to Superscalar Processors Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Limitations of Scalar Pipelines
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
Advanced Computer Architecture
 Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Lecture: Out-of-order Processors
 Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Hardware-based Speculation
 Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Computer Architecture ELEC3441
 Computer Architecture ELEC3441 RISC vs CISC Iron Law CPUTime = # of instruction program # of cycle instruction cycle Lecture 5 Pipelining Dr. Hayden Kwok-Hay So Department of Electrical and Electronic
Computer Architecture ELEC3441 RISC vs CISC Iron Law CPUTime = # of instruction program # of cycle instruction cycle Lecture 5 Pipelining Dr. Hayden Kwok-Hay So Department of Electrical and Electronic
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Complex Pipelining: Out-of-order Execution & Register Renaming. Multiple Function Units
 6823, L14--1 Complex Pipelining: Out-of-order Execution & Register Renaming Laboratory for Computer Science MIT http://wwwcsglcsmitedu/6823 Multiple Function Units 6823, L14--2 ALU Mem IF ID Issue WB Fadd
6823, L14--1 Complex Pipelining: Out-of-order Execution & Register Renaming Laboratory for Computer Science MIT http://wwwcsglcsmitedu/6823 Multiple Function Units 6823, L14--2 ALU Mem IF ID Issue WB Fadd
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
Complex Pipelines and Branch Prediction
 Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Page 1. Recall from Pipelining Review. Lecture 15: Instruction Level Parallelism and Dynamic Execution
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
Motivation. Banked Register File for SMT Processors. Distributed Architecture. Centralized Architecture
 Motivation Banked Register File for SMT Processors Jessica H. Tseng and Krste Asanović MIT Computer Science and Artificial Intelligence Laboratory, Cambridge, MA 02139, USA BARC2004 Increasing demand on
Motivation Banked Register File for SMT Processors Jessica H. Tseng and Krste Asanović MIT Computer Science and Artificial Intelligence Laboratory, Cambridge, MA 02139, USA BARC2004 Increasing demand on
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Portland State University ECE 587/687. The Microarchitecture of Superscalar Processors
 Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
ECE 552: Introduction To Computer Architecture 1. Scalar upper bound on throughput. Instructor: Mikko H Lipasti. University of Wisconsin-Madison
 ECE/CS 552: Introduction to Superscalar Processors Instructor: Mikko H Lipasti Fall 2010 University of Wisconsin-Madison Lecture notes partially based on notes by John P. Shen Limitations of Scalar Pipelines
ECE/CS 552: Introduction to Superscalar Processors Instructor: Mikko H Lipasti Fall 2010 University of Wisconsin-Madison Lecture notes partially based on notes by John P. Shen Limitations of Scalar Pipelines
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Superscalar Processor
 Superscalar Processor Design Superscalar Architecture Virendra Singh Indian Institute of Science Bangalore virendra@computer.orgorg Lecture 20 SE-273: Processor Design Superscalar Pipelines IF ID RD ALU
Superscalar Processor Design Superscalar Architecture Virendra Singh Indian Institute of Science Bangalore virendra@computer.orgorg Lecture 20 SE-273: Processor Design Superscalar Pipelines IF ID RD ALU
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
ECE 505 Computer Architecture
 ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS252 Spring 2017 Graduate Computer Architecture. Lecture 14: Multithreading Part 2 Synchronization 1
 CS252 Spring 2017 Graduate Computer Architecture Lecture 14: Multithreading Part 2 Synchronization 1 Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture
CS252 Spring 2017 Graduate Computer Architecture Lecture 14: Multithreading Part 2 Synchronization 1 Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CS252 Graduate Computer Architecture Spring 2014 Lecture 6: Modern Out- of- Order Processors
 CS252 Graduate Comuter Architecture Sring 2014 Lecture 6: Modern Out- of- Order Processors Krste Asanovic krste@eecs.berkeley.edu htt://inst.eecs.berkeley.edu/~cs252/s14 CS252, Sring 2014, Lecture 6 Last
CS252 Graduate Comuter Architecture Sring 2014 Lecture 6: Modern Out- of- Order Processors Krste Asanovic krste@eecs.berkeley.edu htt://inst.eecs.berkeley.edu/~cs252/s14 CS252, Sring 2014, Lecture 6 Last
Lecture 19: Instruction Level Parallelism
 Lecture 19: Instruction Level Parallelism Administrative: Homework #5 due Homework #6 handed out today Last Time: DRAM organization and implementation Today Static and Dynamic ILP Instruction windows Register
Lecture 19: Instruction Level Parallelism Administrative: Homework #5 due Homework #6 handed out today Last Time: DRAM organization and implementation Today Static and Dynamic ILP Instruction windows Register
Case Study IBM PowerPC 620
 Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
Computer Architecture and Engineering CS152 Quiz #3 March 22nd, 2012 Professor Krste Asanović
 Computer Architecture and Engineering CS52 Quiz #3 March 22nd, 202 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 0 Pages Notes: Not all questions are
Computer Architecture and Engineering CS52 Quiz #3 March 22nd, 202 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 0 Pages Notes: Not all questions are
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
CS 152 Computer Architecture and Engineering. Lecture 11 - Virtual Memory and Caches
 CS 152 Computer Architecture and Engineering Lecture 11 - Virtual Memory and Caches Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 11 - Virtual Memory and Caches Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste