4. Networks. in parallel computers. Advances in Computer Architecture
|
|
|
- Shanon Barrett
- 5 years ago
- Views:
Transcription

1 4. Networks in parallel computers Advances in Computer Architecture
2 System architectures for parallel computers
3 Control organization Single Instruction stream Multiple Data stream (SIMD) All processors execute the same instruction using one control unit and many data paths with control signals broadcast to each datapath from the control unit Conditional execution possible: PE activity can be masked based on condition register Multiple Instruction Stream Multiple data Stream (MIMD) Typically a collection of microprocessors connected by a bus or network: it could be a group of PCs loosely interconnected by the internet or a rack of processors more tightly interconnected with a high speed bus or network

4 SIMD Computer

5 MIMD Computer
6 Memory organization A distributed memory organization partitions the memory between the different processors where each processor owns a bank only one processor can access each bank of memory data is shared between processors by the exchange of messages managed in software or hardware messages are routed to processors based on a processor addressing scheme (e.g. IP) A shared memory organization allows each processor to access any word of data anywhere in memory data is accessed by address regardless of its location shared memory is not exclusive to bus-based multi-processors shared memory can be implemented over packet-addressed networks access times to different locations in memory may not be uniform - NUMA
7 Typical MIMD examples Multi-processor PCs + multi-cores use bus-connected shared memory or central switch for memory channels typically with 2-16 processors they are symmetric and have uniform access to memory (UMA) Symmetric Multi-Processor (SMP) servers use switch/bus-connected shared memory, multiple chips typically processors they also have uniform but slower access to memory Massively Parallel Processors (MPPs) use network connected memory which can be distributed or shared Typically 256 to hundreds of thousands in supercomputers They have non-uniform access to memory if it is shared as accesses are implemented using message passing There may be many orders of magnitude difference between access times to L1 and remote memory
8 Communication architecture There are two ways in which microprocessors may be connected to form parallel computers By shared Bus - giving shared memory multi-processors e.g. MP PCs, SMPs By Network - giving distributed or shared memory e.g. SMPs and MPPs It is common for architectures to use a combination of the two e.g. bus-based SMPs interconnected by a network
 A global synchronisation mechanism is usually implemented on the bus")
9 Symmetric Multi-Processors Processors in an SMP have a symmetric view on the shared memory May be at any level of the memory hierarchy, L1:L2, L2:l3, L3:main Communication is by shared memory reading and writing a given address snoopy protocol for memory coherence between processor caches Synchronisation is usually implemented in software and requires an indivisible operation (e.g. test and set on a memory location) A global synchronisation mechanism is usually implemented on the bus

10 Massively parallel processors
11 Scalability The goal in a parallel computer is to scale processor performance linearly with the number of processors used processor performance is generally scalable but communication and synchronization are not! A bus has a constant performance so it scales very badly adding processors eventually saturates the bandwidth and congestion gives decreasing performance with concurrency The throughput is constant for P processors
12 Scalability A fully connected switch (X-bar) scales throughput with concurrency e.g. for P processors concurrent busses can be established between any of the processors with throughput of O(P) The problem with fully connected switches is that the costs grow very quickly i.e. O(P 2 ) for P processors Theoretically, at best we can get O(P) throughput with O(logP) delay and at a cost of O(PlogP) - e.g. hypercube network
13 Buses
14 Bus architectures In traditional busses, address and data lines may be time-multiplexed When there are more bus-masters, arbitration is required
15 Traditional vs split-transaction
16 Central arbitration flexible + efficient, expensive, not scalable
17 Daisy-chain arbitration higher latencies, less fairness, cheaper
18 Networks for parallel computers
19 Bandwidth and latency Bandwidth of a channel number of bits per second that can be passed over a channel usually defined in terms of the channel width and the channel cycle a w bit channel at f MHz has a bandwidth of f*w Mbps Latency of a channel - serialization latency the time required to pass a message of a given size over a channel a message of m bits in the above channel requires m/ (f*w) secs
20 Network topology Physical topology: how the wires are connected Logical topology: what nodes can be considered as neighbors for the purpose of sending/receiving messages Cost intimately related to topology: more wires, more cost more neighbors, more communication, more performance
21 Example topologies

22 Toroidal topologies By providing wrap around connections on each edge the distance measure is reduced by a factor of 2. Moreover the network also becomes symmetrical. Whereas a mesh suffers from congestion at its centre, a torroidal network has an even distribution of traffic.
23 Link load under uniform random traffic
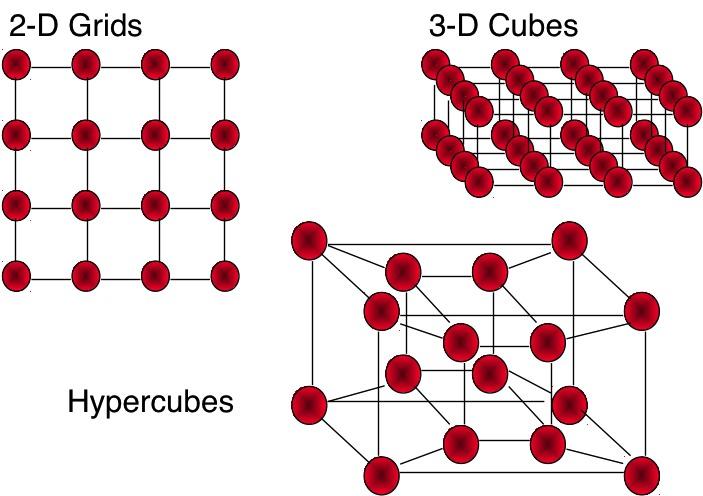
24 Multi-dimensional topologies
25 Metrics related to topology Node degree: number of channels connected to one node 2D Mesh: degree 4, ring: degree 2 Diameter: maximum shortest path between two nodes Ring: N/2, 2D Mesh: 2N 1/2 Bisection width: when the network is cut into two equal halves, the minimum number of channels along the cut This determines the bandwidth from one half to another
26 Topologies and metrics Net Degree Diameter Bisection width Ring 2 N/2 2 Fully conn. 2D mesh Hyper cube N-1 1 (N/2) 2 4 2N 1/2-1 N 1/2 log2n log2n N/2
27 Dimensionality vs. cost As the dimensionality of a network, D, increases so does its degree and the cost of each node As the dimensionality increases the distance measures of diameter and average distance, and hence latency, decrease A compromise normally results... but there are other factors Wire length is an issue - 2-D and 3-D networks can be mapped in 3-D space but a hypercube always has non-local wires that can increase latency and decrease throughput

28 Bisection analysis: mesh is O(n 1/2 )
29 Dynamic vs static networks A static network provides a pre-programmed set of connections messages are addressed to ports & ports connect to different nodes in the network What is the abstraction here? one of permutations of data message are exchanged over fixed topologies which is a low-level and application specific form of programming This is typical of SIMD computers and some low-level DSP devices like the picochip Array
30 Example static network Processor i,j in the grid may only send messages to processors: i,j+1 i,j-1, i+1,j, i-1,j In a planar grid there are exceptions at the boundaries In a cyclic network (torus) there is uniformity or symmetry
31 Dynamic vs. static networks In a dynamic network each message uniquely identifies its destination by means of a header within the message i.e., packet routing the header addresses the node in the network to which the message is to be delivered, and possibly the manner in which it will interpreted there What is the abstraction here? the abstraction here is well understood, one of address spaces an address to a destination provides data or action this can be abstracted and is able to support any programming paradigm

32 Example dynamic network In this example, each node in the network has an address as does each message The processor dynamically computes an address and the nodes in the network route the message to its destination using a number of transfers or hops
33 Indirect networks
34 Direct vs. indirect networks Direct networks are characterized by point-to-point connections between nodes, typically fixed topology Indirect networks allow remote nodes to exchange messages, hopping through intermediate nodes The physical links are shared by multiple point-to-point virtual neighbors A bus is a special form of indirect network (1 physical channel, topology changes at every transaction)
35 Multistage networks - indirect A generalized Multistage Interconnection Network (MIN) built with a x b switches and a specific InterStage Connection (ISC) pattern
36 Multistage networks - indirect Switch networks often use 2x2 switches N inputs require log2n stages of 2x2 switches Each stage requires N/2 switch modules The number of stages determines the delay of the network
37 Omega networks - indirect
38 Crossbars (X-bars) The X-bar connects every input to every output It is indirect, yet has a fully connected logical topology The cost of this network scales very badly as each node requires n*m channels
39 X-bar switches

40 X-bar switches
41 Scaling in indirect networks
42 Direct vs. indirect Direct networks provide more efficient communication at the expense of dedicated wires for every channel Indirect requires larger latencies due to hops Indirect requires routing through the intermediate nodes Except for buses, once switched the distance is 1 Except for cross bars, only one switch required Multistage: N hops where N is the number of stages
43 Network switching Network switching: how channels are established Circuit switching: the channels are established for the entire communication (eg. old telephone system) Packet switching: communication split into packets, channels established for individual packets Parallel computers have evolved from circuit to packet switching, which is more flexible, yet more costly
44 Packet switching Store-andforward: Packet is the smallest entity Packet buffered at every node
45 Packet switching Wormhole routing: Packet split in flits One packet can occupy multiple links A form of pipelining
46 Tree saturation Occurs when the head of the packet cannot advance, and tail flits are keeping channels busy As the channels are blocked, other packets get stuck This blocking behavior propagates with the structure of a tree Two solutions: virtual channels (cf later) and virtual cut-through switching
47 Virtual cut-through switching Mix of wormhole routing and store-and-forward: Flits advance as with wormhole Each node has a buffer for an entire packet If the head cannot advance, all the tail flits can accumulate at the node where the head is blocked, freeing the other channels
48 Network routing Network routing: how data is steered through the channels Which paths messages should take Intimately depends on topology and how many nodes per link (direct vs. indirect)
49 Routing techniques Source-based routing: Routers eat the head of a packet Larger packets, no fault tolerance, no contention management Local routing: more complex, more flexible Routing may cause deadlocks Buffer deadlocks (store and forward) Channel deadlock (wormhole)
50 Deterministic vs. adaptive routing Deterministic (non-adaptive) routing : fixed path Minimal and deadlock free Adaptive routing : exploits alternative paths Less prone to contention and more fault-tolerant Potential deadlocks Reassembling of messages (out-of-order arrival of packets)
51 Dimension-order routing In multi-dimensional, non-cyclic networks, if routing is restricted then we can still maintain the one buffer per direction limit while avoiding cyclic dependencies The restriction is to route different dimensions in some fixed order, i.e. route all packets in X before routing in Y in a 2D mesh (XY-routing)

52 Dimension-order routing With dimension-order routing there is just one path between any two nodes in a regular network and if there is congestion on-route it can not be avoided This is the one disadvantage of dimension-order routing
53 Deadlocks in dimension order routing In cyclic networks, rings, toruses, etc. dimension-order routing can still cause deadlock cyclic dependencies can again arise due to wrap around in any dimension Possible to avoid this by providing a second buffer, aka another virtual channel packets are transferred from one virtual channel (buffer) to another at some fixed point in the cycle, called the date line
54 Virtual channels Deadlock occurs when there are cycles in the channel dependency graph Virtual channels remove cycles hence deadlocks Implemented with different buffers at nodes
55 Virtual channels Virtual channels are logical links between two nodes using their own buffers and multipexed over a single physical channel Virtual channels break dependency cycles
56 Adaptive routing with virtual networks Consider a 2-D Mesh Network One partition is that all messages are routed in one of four unidirectional grids, e.g. +X,+Y +X,-Y -X,+Y -X,-Y Partition decided when message is constructed, based on source and destination address Restriction is that messages are always routed on shortest paths, they may adapt to congestion however between shortest paths in each grid

57 Virtual networks
58 Virtual channels Advantages Increased network throughput Deadlock avoidance Virtual topologies Dedicated channels (e.g. debugging, monitoring) Disadvantages Hardware cost (more buffers) Higher latency Incoming packets may be out-of-order
59 Summary Networks are not scalable Either cost or cross-section may be but not both Networks can be designed so that both cost and latency grow slowly with scalable bisection Topology buffering and flow control are all important design parameters in network design Buffering and virtual channels can control deadlock
Physical Organization of Parallel Platforms. Alexandre David
 Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
Interconnection Network
 Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
Interconnection Networks: Topology. Prof. Natalie Enright Jerger
 Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Lecture 12: Interconnection Networks. Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E)
") Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 2: Topology - I
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
Lecture 26: Interconnects. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
CS575 Parallel Processing
 CS575 Parallel Processing Lecture three: Interconnection Networks Wim Bohm, CSU Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license.
CS575 Parallel Processing Lecture three: Interconnection Networks Wim Bohm, CSU Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license.
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
INTERCONNECTION NETWORKS LECTURE 4
 INTERCONNECTION NETWORKS LECTURE 4 DR. SAMMAN H. AMEEN 1 Topology Specifies way switches are wired Affects routing, reliability, throughput, latency, building ease Routing How does a message get from source
INTERCONNECTION NETWORKS LECTURE 4 DR. SAMMAN H. AMEEN 1 Topology Specifies way switches are wired Affects routing, reliability, throughput, latency, building ease Routing How does a message get from source
CSC630/CSC730: Parallel Computing
 CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
Interconnection Network. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
Interconnection Networks. Issues for Networks
 Interconnection Networks Communications Among Processors Chris Nevison, Colgate University Issues for Networks Total Bandwidth amount of data which can be moved from somewhere to somewhere per unit time
Interconnection Networks Communications Among Processors Chris Nevison, Colgate University Issues for Networks Total Bandwidth amount of data which can be moved from somewhere to somewhere per unit time
Network-on-chip (NOC) Topologies
 Topologies") Network-on-chip (NOC) Topologies 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and performance
Network-on-chip (NOC) Topologies 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and performance
Interconnection Network
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Lecture: Interconnection Networks
 Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Interconnect Technology and Computational Speed
 Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Interconnection Networks
 Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
Lecture 24: Interconnection Networks. Topics: topologies, routing, deadlocks, flow control
 Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Advanced Parallel Architecture. Annalisa Massini /2017
 Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Dr e v prasad Dt
 Dr e v prasad Dt. 12.10.17 Contents Characteristics of Multiprocessors Interconnection Structures Inter Processor Arbitration Inter Processor communication and synchronization Cache Coherence Introduction
Dr e v prasad Dt. 12.10.17 Contents Characteristics of Multiprocessors Interconnection Structures Inter Processor Arbitration Inter Processor communication and synchronization Cache Coherence Introduction
Overview. Processor organizations Types of parallel machines. Real machines
 Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Interconnection networks
 Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Recall: The Routing problem: Local decisions. Recall: Multidimensional Meshes and Tori. Properties of Routing Algorithms
 CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
TDT Appendix E Interconnection Networks
 TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
Parallel Systems Prof. James L. Frankel Harvard University. Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved.
 Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: ABCs of Networks Starting Point: Send bits between 2 computers Queue
Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: ABCs of Networks Starting Point: Send bits between 2 computers Queue
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
CPS 303 High Performance Computing. Wensheng Shen Department of Computational Science SUNY Brockport
 CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 2: Architecture of Parallel Computers Hardware Software 2.1.1 Flynn s taxonomy Single-instruction
CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 2: Architecture of Parallel Computers Hardware Software 2.1.1 Flynn s taxonomy Single-instruction
Parallel Architecture. Sathish Vadhiyar
 Parallel Architecture Sathish Vadhiyar Motivations of Parallel Computing Faster execution times From days or months to hours or seconds E.g., climate modelling, bioinformatics Large amount of data dictate
Parallel Architecture Sathish Vadhiyar Motivations of Parallel Computing Faster execution times From days or months to hours or seconds E.g., climate modelling, bioinformatics Large amount of data dictate
CSE Introduction to Parallel Processing. Chapter 4. Models of Parallel Processing
 Dr Izadi CSE-4533 Introduction to Parallel Processing Chapter 4 Models of Parallel Processing Elaborate on the taxonomy of parallel processing from chapter Introduce abstract models of shared and distributed
Dr Izadi CSE-4533 Introduction to Parallel Processing Chapter 4 Models of Parallel Processing Elaborate on the taxonomy of parallel processing from chapter Introduce abstract models of shared and distributed
Outline. Distributed Shared Memory. Shared Memory. ECE574 Cluster Computing. Dichotomy of Parallel Computing Platforms (Continued)
") Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
CMSC 611: Advanced. Interconnection Networks
 CMSC 611: Advanced Computer Architecture Interconnection Networks Interconnection Networks Massively parallel processor networks (MPP) Thousands of nodes Short distance (
CMSC 611: Advanced Computer Architecture Interconnection Networks Interconnection Networks Massively parallel processor networks (MPP) Thousands of nodes Short distance (
Topologies. Maurizio Palesi. Maurizio Palesi 1
 Topologies Maurizio Palesi Maurizio Palesi 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and
Topologies Maurizio Palesi Maurizio Palesi 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and
Multiprocessor Interconnection Networks
 Multiprocessor Interconnection Networks Todd C. Mowry CS 740 November 19, 1998 Topics Network design space Contention Active messages Networks Design Options: Topology Routing Direct vs. Indirect Physical
Multiprocessor Interconnection Networks Todd C. Mowry CS 740 November 19, 1998 Topics Network design space Contention Active messages Networks Design Options: Topology Routing Direct vs. Indirect Physical
Module 17: "Interconnection Networks" Lecture 37: "Introduction to Routers" Interconnection Networks. Fundamentals. Latency and bandwidth
 Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Lecture 18: Communication Models and Architectures: Interconnection Networks
 Design & Co-design of Embedded Systems Lecture 18: Communication Models and Architectures: Interconnection Networks Sharif University of Technology Computer Engineering g Dept. Winter-Spring 2008 Mehdi
Design & Co-design of Embedded Systems Lecture 18: Communication Models and Architectures: Interconnection Networks Sharif University of Technology Computer Engineering g Dept. Winter-Spring 2008 Mehdi
JUNCTION BASED ROUTING: A NOVEL TECHNIQUE FOR LARGE NETWORK ON CHIP PLATFORMS
 1 JUNCTION BASED ROUTING: A NOVEL TECHNIQUE FOR LARGE NETWORK ON CHIP PLATFORMS Shabnam Badri THESIS WORK 2011 ELECTRONICS JUNCTION BASED ROUTING: A NOVEL TECHNIQUE FOR LARGE NETWORK ON CHIP PLATFORMS
1 JUNCTION BASED ROUTING: A NOVEL TECHNIQUE FOR LARGE NETWORK ON CHIP PLATFORMS Shabnam Badri THESIS WORK 2011 ELECTRONICS JUNCTION BASED ROUTING: A NOVEL TECHNIQUE FOR LARGE NETWORK ON CHIP PLATFORMS
SHARED MEMORY VS DISTRIBUTED MEMORY
 OVERVIEW Important Processor Organizations 3 SHARED MEMORY VS DISTRIBUTED MEMORY Classical parallel algorithms were discussed using the shared memory paradigm. In shared memory parallel platform processors
OVERVIEW Important Processor Organizations 3 SHARED MEMORY VS DISTRIBUTED MEMORY Classical parallel algorithms were discussed using the shared memory paradigm. In shared memory parallel platform processors
Interconnection Networks
 Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
CS252 Graduate Computer Architecture Lecture 14. Multiprocessor Networks March 9 th, 2011
 CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
Lecture 12: Interconnection Networks. Topics: dimension/arity, routing, deadlock, flow control
 Lecture 12: Interconnection Networks Topics: dimension/arity, routing, deadlock, flow control 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees, butterflies,
Lecture 12: Interconnection Networks Topics: dimension/arity, routing, deadlock, flow control 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees, butterflies,
EE382 Processor Design. Illinois
 EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate
EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate
Topologies. Maurizio Palesi. Maurizio Palesi 1
 Topologies Maurizio Palesi Maurizio Palesi 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and
Topologies Maurizio Palesi Maurizio Palesi 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #4 1/24/2018 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Announcements PA #1
EE/CSCI 451: Parallel and Distributed Computation Lecture #4 1/24/2018 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Announcements PA #1
Parallel Architectures
 Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
A closer look at network structure:
 T1: Introduction 1.1 What is computer network? Examples of computer network The Internet Network structure: edge and core 1.2 Why computer networks 1.3 The way networks work 1.4 Performance metrics: Delay,
T1: Introduction 1.1 What is computer network? Examples of computer network The Internet Network structure: edge and core 1.2 Why computer networks 1.3 The way networks work 1.4 Performance metrics: Delay,
CS4961 Parallel Programming. Lecture 4: Memory Systems and Interconnects 9/1/11. Administrative. Mary Hall September 1, Homework 2, cont.
 CS4961 Parallel Programming Lecture 4: Memory Systems and Interconnects Administrative Nikhil office hours: - Monday, 2-3PM - Lab hours on Tuesday afternoons during programming assignments First homework
CS4961 Parallel Programming Lecture 4: Memory Systems and Interconnects Administrative Nikhil office hours: - Monday, 2-3PM - Lab hours on Tuesday afternoons during programming assignments First homework
Design of Parallel Algorithms. The Architecture of a Parallel Computer
 + Design of Parallel Algorithms The Architecture of a Parallel Computer + Trends in Microprocessor Architectures n Microprocessor clock speeds are no longer increasing and have reached a limit of 3-4 Ghz
+ Design of Parallel Algorithms The Architecture of a Parallel Computer + Trends in Microprocessor Architectures n Microprocessor clock speeds are no longer increasing and have reached a limit of 3-4 Ghz
MULTIPROCESSORS. Characteristics of Multiprocessors. Interconnection Structures. Interprocessor Arbitration
 MULTIPROCESSORS Characteristics of Multiprocessors Interconnection Structures Interprocessor Arbitration Interprocessor Communication and Synchronization Cache Coherence 2 Characteristics of Multiprocessors
MULTIPROCESSORS Characteristics of Multiprocessors Interconnection Structures Interprocessor Arbitration Interprocessor Communication and Synchronization Cache Coherence 2 Characteristics of Multiprocessors
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Interconnection Networks
 Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Multiple Processor Systems. Lecture 15 Multiple Processor Systems. Multiprocessor Hardware (1) Multiprocessors. Multiprocessor Hardware (2)
 Multiprocessors. Multiprocessor Hardware (2)") Lecture 15 Multiple Processor Systems Multiple Processor Systems Multiprocessors Multicomputers Continuous need for faster computers shared memory model message passing multiprocessor wide area distributed
Lecture 15 Multiple Processor Systems Multiple Processor Systems Multiprocessors Multicomputers Continuous need for faster computers shared memory model message passing multiprocessor wide area distributed
Lecture 13: Interconnection Networks. Topics: lots of background, recent innovations for power and performance
 Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
CS 770G - Parallel Algorithms in Scientific Computing Parallel Architectures. May 7, 2001 Lecture 2
 CS 770G - arallel Algorithms in Scientific Computing arallel Architectures May 7, 2001 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan Kaufmann
CS 770G - arallel Algorithms in Scientific Computing arallel Architectures May 7, 2001 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan Kaufmann
ECE 4750 Computer Architecture, Fall 2017 T06 Fundamental Network Concepts
 ECE 4750 Computer Architecture, Fall 2017 T06 Fundamental Network Concepts School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-26 1 Network/Roadway Analogy 3 1.1. Running
ECE 4750 Computer Architecture, Fall 2017 T06 Fundamental Network Concepts School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-26 1 Network/Roadway Analogy 3 1.1. Running
Network Properties, Scalability and Requirements For Parallel Processing. Communication assist (CA)
") Network Properties, Scalability and Requirements For Parallel Processing Scalable Parallel Performance: Continue to achieve good parallel performance "speedup"as the sizes of the system/problem are increased.
Network Properties, Scalability and Requirements For Parallel Processing Scalable Parallel Performance: Continue to achieve good parallel performance "speedup"as the sizes of the system/problem are increased.
Lecture: Interconnection Networks. Topics: TM wrap-up, routing, deadlock, flow control, virtual channels
 Lecture: Interconnection Networks Topics: TM wrap-up, routing, deadlock, flow control, virtual channels 1 TM wrap-up Eager versioning: create a log of old values Handling problematic situations with a
Lecture: Interconnection Networks Topics: TM wrap-up, routing, deadlock, flow control, virtual channels 1 TM wrap-up Eager versioning: create a log of old values Handling problematic situations with a
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
Lecture 3: Topology - II
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
CS Parallel Algorithms in Scientific Computing
 CS 775 - arallel Algorithms in Scientific Computing arallel Architectures January 2, 2004 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan
CS 775 - arallel Algorithms in Scientific Computing arallel Architectures January 2, 2004 Lecture 2 References arallel Computer Architecture: A Hardware / Software Approach Culler, Singh, Gupta, Morgan
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
Communication Performance in Network-on-Chips
 Communication Performance in Network-on-Chips Axel Jantsch Royal Institute of Technology, Stockholm November 24, 2004 Network on Chip Seminar, Linköping, November 25, 2004 Communication Performance In
Communication Performance in Network-on-Chips Axel Jantsch Royal Institute of Technology, Stockholm November 24, 2004 Network on Chip Seminar, Linköping, November 25, 2004 Communication Performance In
Characteristics of Mult l ip i ro r ce c ssors r
 Characteristics of Multiprocessors A multiprocessor system is an interconnection of two or more CPUs with memory and input output equipment. The term processor in multiprocessor can mean either a central
Characteristics of Multiprocessors A multiprocessor system is an interconnection of two or more CPUs with memory and input output equipment. The term processor in multiprocessor can mean either a central
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Lecture 15: PCM, Networks. Today: PCM wrap-up, projects discussion, on-chip networks background
 Lecture 15: PCM, Networks Today: PCM wrap-up, projects discussion, on-chip networks background 1 Hard Error Tolerance in PCM PCM cells will eventually fail; important to cause gradual capacity degradation
Lecture 15: PCM, Networks Today: PCM wrap-up, projects discussion, on-chip networks background 1 Hard Error Tolerance in PCM PCM cells will eventually fail; important to cause gradual capacity degradation
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Understanding the Routing Requirements for FPGA Array Computing Platform. Hayden So EE228a Project Presentation Dec 2 nd, 2003
 Understanding the Routing Requirements for FPGA Array Computing Platform Hayden So EE228a Project Presentation Dec 2 nd, 2003 What is FPGA Array Computing? Aka: Reconfigurable Computing Aka: Spatial computing,
Understanding the Routing Requirements for FPGA Array Computing Platform Hayden So EE228a Project Presentation Dec 2 nd, 2003 What is FPGA Array Computing? Aka: Reconfigurable Computing Aka: Spatial computing,
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Multiprocessor Interconnection Networks- Part Three
 Babylon University College of Information Technology Software Department Multiprocessor Interconnection Networks- Part Three By The k-ary n-cube Networks The k-ary n-cube network is a radix k cube with
Babylon University College of Information Technology Software Department Multiprocessor Interconnection Networks- Part Three By The k-ary n-cube Networks The k-ary n-cube network is a radix k cube with
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Network Properties, Scalability and Requirements For Parallel Processing. Communication assist (CA)
") Network Properties, Scalability and Requirements For Parallel Processing Scalable Parallel Performance: Continue to achieve good parallel performance "speedup"as the sizes of the system/problem are increased.
Network Properties, Scalability and Requirements For Parallel Processing Scalable Parallel Performance: Continue to achieve good parallel performance "speedup"as the sizes of the system/problem are increased.
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Chapter 3 : Topology basics
 1 Chapter 3 : Topology basics What is the network topology Nomenclature Traffic pattern Performance Packaging cost Case study: the SGI Origin 2000 2 Network topology (1) It corresponds to the static arrangement
1 Chapter 3 : Topology basics What is the network topology Nomenclature Traffic pattern Performance Packaging cost Case study: the SGI Origin 2000 2 Network topology (1) It corresponds to the static arrangement
Concurrent/Parallel Processing
 Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
Concurrent/Parallel Processing David May: April 9, 2014 Introduction The idea of using a collection of interconnected processing devices is not new. Before the emergence of the modern stored program computer,
06-Dec-17. Credits:4. Notes by Pritee Parwekar,ANITS 06-Dec-17 1
 Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Lecture 16: On-Chip Networks. Topics: Cache networks, NoC basics
 Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
[ ] In earlier lectures, we have seen that switches in an interconnection network connect inputs to outputs, usually with some kind buffering.
![[ ] In earlier lectures, we have seen that switches in an interconnection network connect inputs to outputs, usually with some kind buffering.](/thumbs/81/83491247.jpg "[ ] In earlier lectures, we have seen that switches in an interconnection network connect inputs to outputs, usually with some kind buffering.") Switch Design [ 10.3.2] In earlier lectures, we have seen that switches in an interconnection network connect inputs to outputs, usually with some kind buffering. Here is a basic diagram of a switch. Receiver
Switch Design [ 10.3.2] In earlier lectures, we have seen that switches in an interconnection network connect inputs to outputs, usually with some kind buffering. Here is a basic diagram of a switch. Receiver
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Extended Junction Based Source Routing Technique for Large Mesh Topology Network on Chip Platforms
 Extended Junction Based Source Routing Technique for Large Mesh Topology Network on Chip Platforms Usman Mazhar Mirza Master of Science Thesis 2011 ELECTRONICS Postadress: Besöksadress: Telefon: Box 1026
Extended Junction Based Source Routing Technique for Large Mesh Topology Network on Chip Platforms Usman Mazhar Mirza Master of Science Thesis 2011 ELECTRONICS Postadress: Besöksadress: Telefon: Box 1026
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow
 FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies. Mohsin Y Ahmed Conlan Wesson
 Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies Mohsin Y Ahmed Conlan Wesson Overview NoC: Future generation of many core processor on a single chip
Fault Tolerant and Secure Architectures for On Chip Networks With Emerging Interconnect Technologies Mohsin Y Ahmed Conlan Wesson Overview NoC: Future generation of many core processor on a single chip
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Networks, Routers and Transputers:
 This is Chapter 1 from the second edition of : Networks, Routers and Transputers: Function, Performance and applications Edited M.D. by: May, P.W. Thompson, and P.H. Welch INMOS Limited 1993 This edition
This is Chapter 1 from the second edition of : Networks, Routers and Transputers: Function, Performance and applications Edited M.D. by: May, P.W. Thompson, and P.H. Welch INMOS Limited 1993 This edition