Parallel Exact Inference on the Cell Broadband Engine Processor
|
|
|
- Nelson Owen
- 6 years ago
- Views:
Transcription

1 Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, University of Southern California SC 08
2 Overview Background Problem Definition Our Techniques Experimental Results Conclusion 2

3 Bayesian Network Bayesian Network Joint probability distribution Directed acyclic graph (DAG) Applications Network scale is large in some applications Real time constraints in some applications A gene regulation network with 200 nodes; Bayesian network techniques can be used to explore the causal relationship among those genes 3
 Each CPT has: r rows r in-edge")
4 Bayesian Network (2) Conditional Probability Table (CPT) r: number of states of random variables In this example, r=2 (True, False) Each CPT has: r rows r in-edge columns 4
5 Bayesian Network (3) Inference in Bayesian Network Given evidence variables (observations) E, output the posterior probabilities of query variables P(Q E) exact inference & approximate inference Exact inference is NP hard Evidence propagation based on Bayes rule can not be applied directly to non-singly connected networks i.e., Bayesian networks with loops, as it would yield erroneous results Therefore, junction trees are used to implement inference 5
6 Junction Tree Junction Tree Tree of cliques Clique a set of r.v. from Bayesian Network Edge shared r.v. Potential Table Ψ V On clique and edge Describe joint distribution r w entries where r is clique width Ψ(7,3,5) 3,2,1 Ψ(3,2,1) Ψ e (3) 5,3,4 Ψ(5,3,4) Ψ e (3,5) Ψ e (4) Ψ e (5,6) 7,3,5 6,4,5 11,5,6 Ψ e (7) Ψ(6,4,5) Ψ(11,5,6) Ψ(8,7) 8,7 Ψ e (8) Ψ e (7) Ψ(9,8) ,7 Ψ(10,7) 6
7 Exact Inference in Junction Tree General problem definition Given an arbitrary junction tree and evidence, compute the posterior probability of query variables Our focus Parallelization of evidence propagation on the Cell BE processor Key step of exact inference Propagates evidence throughout the junction tree 7
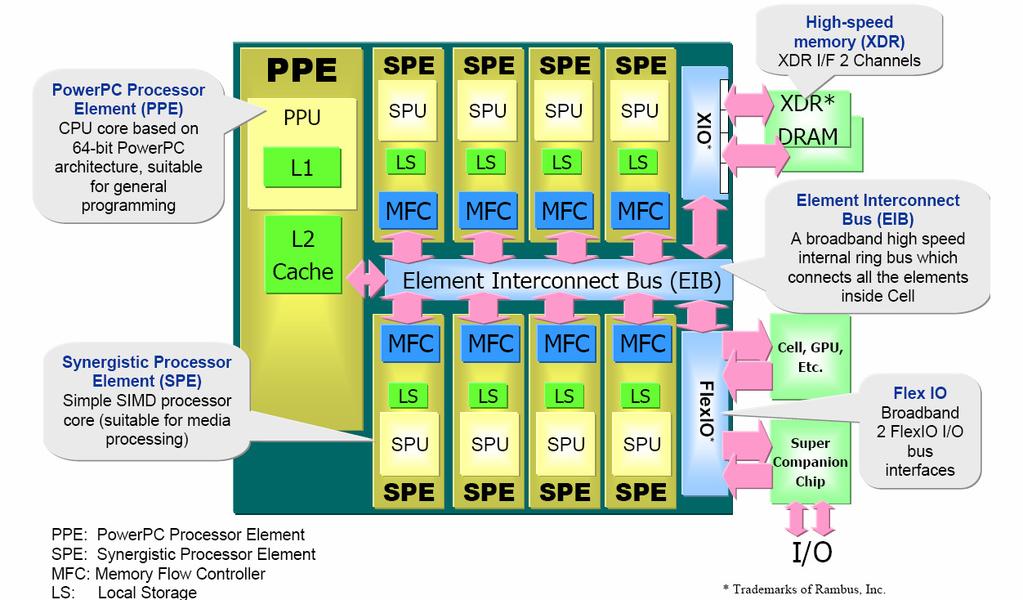
8 Cell BE Architecture 8
9 Challenges Cores are heterogeneous SPE organization: program control, SIMD, mailbox, signal Size of local store is limited (256KB) DMA transfer requires alignment of data Amount of parallelism in junction tree may be limited 9
10 Related Work Existing parallel exact inference techniques Network structure dependent methods Pointer jumping based methods Rerooting techniques Node level primitives Drawbacks Cannot be applied to arbitrary Bayesian networks Constraints on the number and location of evidence cliques Assume homogeneous machine model Do not take memory size into account 10
11 Approach Given an arbitrary junction tree and evidence Construct task dependency graph using junction tree Partition large tasks at runtime Schedule tasks to SPEs dynamically Process tasks using efficient primitives Advantages Efficient dynamic scheduler Optimization of data layout for data transfer Efficient primitives and computation kernels 11
12 Node Level Primitives Definition of node level primitives Basic operations on potential tables for propagating evidence Clique potential table (large) and/or separator potential table (small) Type of primitives Marginalization Generate a separator potential table from a given clique potential table Extension Generate a clique potential table from a given separator potential table Multiplication Element wise multiplication between two potential tables Division Element wise division between two potential tables 12
13 Node Level Primitives Example: Table Extension Input A separator S and its potential table Ψ(S); a clique C, where S C. Output Clique potential tableψ(c) Consistency requirement Entry values inψ(c) and Ψ(S) must be equal if random variables in C and S have the same states in the entries Approach Each entry of Ψ(C) is created by duplicating the entry in Ψ(S) where both random variable sets C and S have the same states E.g. Assuming S={b, c} and C={a, b, c, d, e}, we have Ψ({a=*, b=0, c=0, d=*, e=*}) = Ψ({b=0, c=0}) Ψ({a=*, b=0, c=1, d=*, e=*}) = Ψ({b=0, c=1}) where * denotes an arbitrary value 13

 S ch2")
14 Computations at a Node Node level primitives propagate evidence and update potential tables separator Sch1(C) S ch2 (C) 14


")




15 Task Definition A task is the computation to update a (partial) clique potential table using the input separators and then generate the output separators Each clique is related to two tasks 15
16 Task Partitioning Decompose a task into subtasks Explore fine granularity parallelism Fit in the local store (LS) of SPEs Regular task A task involving complete potential tables Partition regular tasks into type-a and type-b tasks Chop a potential table into k chunks to fit in LS Create two subtasks (type-a & type-b) for each chunk type-a task marginalizes a chunk type-b task updates a chunk 16
17 Task Partitioning (2) Illustration of task partitioning Regular task large potential table Ψ c Subtask a chunk of Ψ c Regular task Subtasks 17



18 Task Dependency Graph Create task dependency graph using junction trees Upper portion evidence collection Lower portion evidence distribution Dynamical modification due to partitioning 18
19 Dynamic Scheduler Centralized scheduler on PPE Partitioning for fine granularity parallelism Small S I results in idle SPEs Dependency degree SPE T 1 T j+1 T j+2 n 1 n j+1 n j+2 Task ID Fetch I Partition PPE Fetch II Issue SPE Successors T 1 T 2 T N n j+1 SPE S L S I T n 19
 S")
20 Data layout for Cell Optimization Clique data package Consist of clique and child separator potential tables Stored in contiguous locations Aligned for data transfer and computation Minimize the overhead of DMAs Clique data package Sch1(C) S ch2 (C) 20



21 Potential Table Organization Basic terms for potential table organization Variable vector State string Conversion between state string and table index potential value state string table index 21
22 Efficient Node Level Primitives Improve the performance of primitives Relationship between entries from two potential tables indices decoding Develop computation kernels Optimize collection & distribution Vectorize computation for primitives Example : Implementation of marginalization by vectorized accumulation 22
23 Experiments Cell BE system IBM Blade Center QS GHz Cell BE processors 512 KB Level 2 cache 1 GB main memory Fedora Core 7 Operating System Cell BE SDK 3.0 Developer package Parameters of input junction trees Junction tree with 512 and 1024 cliques Various clique widths from 5 to 10 Various number of states for random variables from 2 to 4 Various clique degrees ranging from 2 to 4 Single precision floating point data for potential table entries 23
24 Experimental Results (1) Normalized execution time for exact inference on the Cell 24
25 Experimental Results (2) Speedup for various junction trees The average number of children for cliques (k) is 2 25
26 Experimental Results (3) Speedup for various junction trees The average number of children for cliques (k) is 4 26

27 Experimental Results (4) Efficiency of the scheduler for various junction trees N: number of cliques w: clique width r: number of states of random variables Scheduling is hidden because of double buffering 27

28 Experimental Results (5) Load balancing for exact inference on the Cell 28
29 Experimental Results (6) Various platforms for comparison Intel Xeon (x86 64, E5335) 2.0 GHz, Dual quad-core with Streaming SIMD Extensions (SSE) Peak Flops: 32 GFlops (64 GFlops for dual quad-core) 8 concurrent threads created by Pthreads AMD Opteron (x86 64, 2347) 1.9 GHz, Dual quad-core with SSE Peak Flops: 30.4 GFlops (60.8 GFlops for dual quad-core) 8 concurrent threads created by Pthreads Intel Pentium GHz, 16 KB L1, 2 MB L2 Single thread with O3 level optimization IBM Power 4 (P655) 1.5 GHz, 128 KB + 64 KB L1, L2 1.4 MB L2, 32 MB L3 Single thread with O3 level optimization Input junction trees 512 and 1024 cliques, clique width are 8 and 10, number of states is 2, clique degree is 4 29

30 Experimental Results (7) Execution time on various processors Speedups of 2, 4, 2 and 6 over Opteron, Pentium 4, Xeon and Power 4 30
31 Concluding Remarks Contributions Task dependency graph construction Partition large tasks at runtime Dynamic scheduling scheme Efficient primitives and computation kernels Future work Investigation of efficient algorithms for the issuer Task merge and partition for load balancing Minimizing critical path of the exact inference Websites
32 Questions?
Parallel Exact Inference on the Cell Broadband Engine Processor,
 Parallel Exact Inference on the Cell Broadband Engine Processor, Yinglong Xia Computer Science Department, University of Southern California Los Angeles, CA 90089, U.S.A. Viktor K. Prasanna Ming Hsieh
Parallel Exact Inference on the Cell Broadband Engine Processor, Yinglong Xia Computer Science Department, University of Southern California Los Angeles, CA 90089, U.S.A. Viktor K. Prasanna Ming Hsieh
Parallel Evidence Propagation on Multicore Processors
 Parallel Evidence Propagation on Multicore Processors Yinglong Xia 1, Xiaojun Feng 3 and Viktor K. Prasanna 2,1 Computer Science Department 1 and Department of Electrical Engineering 2 University of Southern
Parallel Evidence Propagation on Multicore Processors Yinglong Xia 1, Xiaojun Feng 3 and Viktor K. Prasanna 2,1 Computer Science Department 1 and Department of Electrical Engineering 2 University of Southern
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
( ZIH ) Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems
 Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems") ( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Parallelized Progressive Network Coding with Hardware Acceleration
 Parallelized Progressive Network Coding with Hardware Acceleration Hassan Shojania, Baochun Li Department of Electrical and Computer Engineering University of Toronto Network coding Information is coded
Parallelized Progressive Network Coding with Hardware Acceleration Hassan Shojania, Baochun Li Department of Electrical and Computer Engineering University of Toronto Network coding Information is coded
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Multicore Challenge in Vector Pascal. P Cockshott, Y Gdura
 Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Speeding Up Computation in Probabilistic Graphical Models using GPGPUs
 Speeding Up Computation in Probabilistic Graphical Models using GPGPUs Lu Zheng & Ole J. Mengshoel {lu.zheng ole.mengshoel}@sv.cmu.edu GPU Technology Conference San Jose, CA, March 20, 2013 CMU in Silicon
Speeding Up Computation in Probabilistic Graphical Models using GPGPUs Lu Zheng & Ole J. Mengshoel {lu.zheng ole.mengshoel}@sv.cmu.edu GPU Technology Conference San Jose, CA, March 20, 2013 CMU in Silicon
Cell Processor and Playstation 3
 Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Double-precision General Matrix Multiply (DGEMM)
") Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine. David A. Bader, Virat Agarwal
 FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Scalable Parallel Implementation of Bayesian Network to Junction Tree Conversion for Exact Inference 1
 Scalable Parallel Implementation of Bayesian Network to Junction Tree Conversion for Exact Inference Vasanth Krishna Namasivayam, Animesh Pathak and Viktor K. Prasanna Department of Electrical Engineering
Scalable Parallel Implementation of Bayesian Network to Junction Tree Conversion for Exact Inference Vasanth Krishna Namasivayam, Animesh Pathak and Viktor K. Prasanna Department of Electrical Engineering
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
EE/CSCI 451 Midterm 1
 EE/CSCI 451 Midterm 1 Spring 2018 Instructor: Xuehai Qian Friday: 02/26/2018 Problem # Topic Points Score 1 Definitions 20 2 Memory System Performance 10 3 Cache Performance 10 4 Shared Memory Programming
EE/CSCI 451 Midterm 1 Spring 2018 Instructor: Xuehai Qian Friday: 02/26/2018 Problem # Topic Points Score 1 Definitions 20 2 Memory System Performance 10 3 Cache Performance 10 4 Shared Memory Programming
STAT 598L Probabilistic Graphical Models. Instructor: Sergey Kirshner. Exact Inference
 STAT 598L Probabilistic Graphical Models Instructor: Sergey Kirshner Exact Inference What To Do With Bayesian/Markov Network? Compact representation of a complex model, but Goal: efficient extraction of
STAT 598L Probabilistic Graphical Models Instructor: Sergey Kirshner Exact Inference What To Do With Bayesian/Markov Network? Compact representation of a complex model, but Goal: efficient extraction of
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
The Pennsylvania State University. The Graduate School. College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM
 The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Machine Learning. Sourangshu Bhattacharya
 Machine Learning Sourangshu Bhattacharya Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares
Machine Learning Sourangshu Bhattacharya Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
A Parallel Algorithm for Exact Structure Learning of Bayesian Networks
 A Parallel Algorithm for Exact Structure Learning of Bayesian Networks Olga Nikolova, Jaroslaw Zola, and Srinivas Aluru Department of Computer Engineering Iowa State University Ames, IA 0010 {olia,zola,aluru}@iastate.edu
A Parallel Algorithm for Exact Structure Learning of Bayesian Networks Olga Nikolova, Jaroslaw Zola, and Srinivas Aluru Department of Computer Engineering Iowa State University Ames, IA 0010 {olia,zola,aluru}@iastate.edu
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
Modeling Multigrain Parallelism on Heterogeneous Multi-core Processors
 Modeling Multigrain Parallelism on Heterogeneous Multi-core Processors Filip Blagojevic, Xizhou Feng, Kirk W. Cameron and Dimitrios S. Nikolopoulos Center for High-End Computing Systems Department of Computer
Modeling Multigrain Parallelism on Heterogeneous Multi-core Processors Filip Blagojevic, Xizhou Feng, Kirk W. Cameron and Dimitrios S. Nikolopoulos Center for High-End Computing Systems Department of Computer
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
CellSort: High Performance Sorting on the Cell Processor
 CellSort: High Performance Sorting on the Cell Processor Buğra Gedik bgedik@us.ibm.com Rajesh R. Bordawekar bordaw@us.ibm.com Philip S. Yu psyu@us.ibm.com Thomas J. Watson Research Center, IBM Research,
CellSort: High Performance Sorting on the Cell Processor Buğra Gedik bgedik@us.ibm.com Rajesh R. Bordawekar bordaw@us.ibm.com Philip S. Yu psyu@us.ibm.com Thomas J. Watson Research Center, IBM Research,
HIERARCHICAL BAYESIAN CORTICAL MODELS: ANALYSIS AND ACCELERATION ON MULTICORE ARCHITECTURES
 Clemson University TigerPrints All Theses Theses 8-2009 HIERARCHICAL BAYESIAN CORTICAL MODELS: ANALYSIS AND ACCELERATION ON MULTICORE ARCHITECTURES Pavan Yalamanchili Clemson University, pyalama@clemson.edu
Clemson University TigerPrints All Theses Theses 8-2009 HIERARCHICAL BAYESIAN CORTICAL MODELS: ANALYSIS AND ACCELERATION ON MULTICORE ARCHITECTURES Pavan Yalamanchili Clemson University, pyalama@clemson.edu
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters
 PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
2. Graphical Models. Undirected graphical models. Factor graphs. Bayesian networks. Conversion between graphical models. Graphical Models 2-1
 Graphical Models 2-1 2. Graphical Models Undirected graphical models Factor graphs Bayesian networks Conversion between graphical models Graphical Models 2-2 Graphical models There are three families of
Graphical Models 2-1 2. Graphical Models Undirected graphical models Factor graphs Bayesian networks Conversion between graphical models Graphical Models 2-2 Graphical models There are three families of
High-Performance Packet Classification on GPU
 High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California 1 Outline Introduction
High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California 1 Outline Introduction
Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine
 37th International Conference on Parallel Processing Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine Seunghwa Kang David A. Bader Georgia Institute of Technology, Atlanta, GA 30332
37th International Conference on Parallel Processing Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine Seunghwa Kang David A. Bader Georgia Institute of Technology, Atlanta, GA 30332
Acceleration of Correlation Matrix on Heterogeneous Multi-Core CELL-BE Platform
 Acceleration of Correlation Matrix on Heterogeneous Multi-Core CELL-BE Platform Manish Kumar Jaiswal Assistant Professor, Faculty of Science & Technology, The ICFAI University, Dehradun, India. manish.iitm@yahoo.co.in
Acceleration of Correlation Matrix on Heterogeneous Multi-Core CELL-BE Platform Manish Kumar Jaiswal Assistant Professor, Faculty of Science & Technology, The ICFAI University, Dehradun, India. manish.iitm@yahoo.co.in
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
QDP++/Chroma on IBM PowerXCell 8i Processor
 QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
Analyzing Cache Bandwidth on the Intel Core 2 Architecture
 John von Neumann Institute for Computing Analyzing Cache Bandwidth on the Intel Core 2 Architecture Robert Schöne, Wolfgang E. Nagel, Stefan Pflüger published in Parallel Computing: Architectures, Algorithms
John von Neumann Institute for Computing Analyzing Cache Bandwidth on the Intel Core 2 Architecture Robert Schöne, Wolfgang E. Nagel, Stefan Pflüger published in Parallel Computing: Architectures, Algorithms
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Parallel Exact Inference on Multicore Using MapReduce
 Parallel Exact Inference on Multicore Using MapReduce Nam Ma Computer Science Department University of Southern California Los Angeles, CA 9009 Email: namma@usc.edu Yinglong Xia IBM T.J. Watson Research
Parallel Exact Inference on Multicore Using MapReduce Nam Ma Computer Science Department University of Southern California Los Angeles, CA 9009 Email: namma@usc.edu Yinglong Xia IBM T.J. Watson Research
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Executing Stream Joins on the Cell Processor
 Executing Stream Joins on the Cell Processor Buğra Gedik bgedik@us.ibm.com Philip S. Yu psyu@us.ibm.com Thomas J. Watson Research Center IBM Research, Hawthorne, NY, 1532, USA Rajesh R. Bordawekar bordaw@us.ibm.com
Executing Stream Joins on the Cell Processor Buğra Gedik bgedik@us.ibm.com Philip S. Yu psyu@us.ibm.com Thomas J. Watson Research Center IBM Research, Hawthorne, NY, 1532, USA Rajesh R. Bordawekar bordaw@us.ibm.com
Accelerated Library Framework for Hybrid-x86
 Software Development Kit for Multicore Acceleration Version 3.0 Accelerated Library Framework for Hybrid-x86 Programmer s Guide and API Reference Version 1.0 DRAFT SC33-8406-00 Software Development Kit
Software Development Kit for Multicore Acceleration Version 3.0 Accelerated Library Framework for Hybrid-x86 Programmer s Guide and API Reference Version 1.0 DRAFT SC33-8406-00 Software Development Kit
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL
 SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
Cell Programming Tips & Techniques
 Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
A Transport Kernel on the Cell Broadband Engine
 A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
Presented by: Nafiseh Mahmoudi Spring 2017
 Presented by: Nafiseh Mahmoudi Spring 2017 Authors: Publication: Type: ACM Transactions on Storage (TOS), 2016 Research Paper 2 High speed data processing demands high storage I/O performance. Flash memory
Presented by: Nafiseh Mahmoudi Spring 2017 Authors: Publication: Type: ACM Transactions on Storage (TOS), 2016 Research Paper 2 High speed data processing demands high storage I/O performance. Flash memory
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Parallel and Distributed Computing
 Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
 Parallel Tiled Algorithms for Multicore Architectures Alfredo Buttari, Jack Dongarra, Jakub Kurzak and Julien Langou SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
Parallel Tiled Algorithms for Multicore Architectures Alfredo Buttari, Jack Dongarra, Jakub Kurzak and Julien Langou SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA
 Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Transparent Pointer Compression for Linked Data Structures
 Transparent Pointer Compression for Linked Data Structures lattner@cs.uiuc.edu Vikram Adve vadve@cs.uiuc.edu June 12, 2005 MSP 2005 http://llvm.cs.uiuc.edu llvm.cs.uiuc.edu/ Growth of 64-bit computing
Transparent Pointer Compression for Linked Data Structures lattner@cs.uiuc.edu Vikram Adve vadve@cs.uiuc.edu June 12, 2005 MSP 2005 http://llvm.cs.uiuc.edu llvm.cs.uiuc.edu/ Growth of 64-bit computing
Production. Visual Effects. Fluids, RBD, Cloth. 2. Dynamics Simulation. 4. Compositing
 Visual Effects Pr roduction on the Cell/BE Andrew Clinton, Side Effects Software Visual Effects Production 1. Animation Character, Keyframing 2. Dynamics Simulation Fluids, RBD, Cloth 3. Rendering Raytrac
Visual Effects Pr roduction on the Cell/BE Andrew Clinton, Side Effects Software Visual Effects Production 1. Animation Character, Keyframing 2. Dynamics Simulation Fluids, RBD, Cloth 3. Rendering Raytrac
David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
 Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
Distributed Evidence Propagation in Junction Trees on Clusters
 IEEE TRANSACTIONS ON PARALLEL & DISTRIBUTED SYSTEMS, VOL. XX, NO. XX, AUGUST 2010 1 Distributed Evidence Propagation in Junction Trees on Clusters Yinglong Xia, and Viktor K. Prasanna Fellow, IEEE Abstract
IEEE TRANSACTIONS ON PARALLEL & DISTRIBUTED SYSTEMS, VOL. XX, NO. XX, AUGUST 2010 1 Distributed Evidence Propagation in Junction Trees on Clusters Yinglong Xia, and Viktor K. Prasanna Fellow, IEEE Abstract
Automatic Intra-Application Load Balancing for Heterogeneous Systems
 Automatic Intra-Application Load Balancing for Heterogeneous Systems Michael Boyer, Shuai Che, and Kevin Skadron Department of Computer Science University of Virginia Jayanth Gummaraju and Nuwan Jayasena
Automatic Intra-Application Load Balancing for Heterogeneous Systems Michael Boyer, Shuai Che, and Kevin Skadron Department of Computer Science University of Virginia Jayanth Gummaraju and Nuwan Jayasena
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
GLADE: A Scalable Framework for Efficient Analytics. Florin Rusu University of California, Merced
 GLADE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced Motivation and Objective Large scale data processing Map-Reduce is standard technique Targeted to distributed
GLADE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced Motivation and Objective Large scale data processing Map-Reduce is standard technique Targeted to distributed
Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures
 Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures University of Virginia Dept. of Computer Science Technical Report #CS-2011-09 Jeremy W. Sheaffer and Kevin
Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures University of Virginia Dept. of Computer Science Technical Report #CS-2011-09 Jeremy W. Sheaffer and Kevin
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Parallel Processing. Parallel Processing. 4 Optimization Techniques WS 2018/19
 Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 5 Inference
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 5 Inference
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2016 Lecturer: Trevor Cohn 21. Independence in PGMs; Example PGMs Independence PGMs encode assumption of statistical independence between variables. Critical
COMP90051 Statistical Machine Learning Semester 2, 2016 Lecturer: Trevor Cohn 21. Independence in PGMs; Example PGMs Independence PGMs encode assumption of statistical independence between variables. Critical
Portable Parallel Programming for Multicore Computing
 Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1
 Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1 Shijie Zhou, Yun R. Qu, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering, University of Southern
Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1 Shijie Zhou, Yun R. Qu, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering, University of Southern
Parallel Computer Architecture - Basics -
 Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Performance impact of dynamic parallelism on different clustering algorithms
 Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
Implementation of a backprojection algorithm on CELL
 Implementation of a backprojection algorithm on CELL Mario Koerner March 17, 2006 1 Introduction X-ray imaging is one of the most important imaging technologies in medical applications. It allows to look
Implementation of a backprojection algorithm on CELL Mario Koerner March 17, 2006 1 Introduction X-ray imaging is one of the most important imaging technologies in medical applications. It allows to look
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU
 Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU Scott Rostrup and Hans De Sterck Department of Applied Mathematics, University of Waterloo, Waterloo, Ontario, N2L 3G1, Canada Abstract Increasingly,
Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU Scott Rostrup and Hans De Sterck Department of Applied Mathematics, University of Waterloo, Waterloo, Ontario, N2L 3G1, Canada Abstract Increasingly,
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Cell Broadband Engine. Spencer Dennis Nicholas Barlow
 Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
2. Graphical Models. Undirected pairwise graphical models. Factor graphs. Bayesian networks. Conversion between graphical models. Graphical Models 2-1
 Graphical Models 2-1 2. Graphical Models Undirected pairwise graphical models Factor graphs Bayesian networks Conversion between graphical models Graphical Models 2-2 Graphical models Families of graphical
Graphical Models 2-1 2. Graphical Models Undirected pairwise graphical models Factor graphs Bayesian networks Conversion between graphical models Graphical Models 2-2 Graphical models Families of graphical