GaaS Workload Characterization under NUMA Architecture for Virtualized GPU
|
|
|
- Abigail Johnston
- 5 years ago
- Views:
Transcription
 Department of Electrical and Computer Engineering University of")
1 GaaS Workload Characterization under NUMA Architecture for Virtualized GPU Huixiang Chen, Meng Wang, Yang Hu, Mingcong Song, Tao Li Presented by Huixiang Chen ISPASS 2017 April 24, 2017, Santa Rosa, California IDEAL (Intelligent Design of Efficient Architectures Laboratory) Department of Electrical and Computer Engineering University of Florida
2 Talk Overview 1. Background and Motivation 2. Experiment Setup L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 un Core Interconnect QPI Core Interconnect un GPU A LL cache GPU B LL cache PCIe/F MC PCIe/F MC memory memory 3. Characterizations and Analysis 4. DVFS 2 / 27









3 Graphics-as-a-Service (GaaS) Cloud Gaming Video Streaming Virtual Desktop (VDI) 3 / 27
4 Graphics-as-a-Service (GaaS) GPU Virtualization! 4 / 27
5 GPU Virtualization 1. API Intercept 2. GPU pass-through 3. Shared virtualized GPU 5 / 27






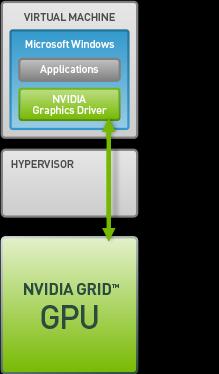

6 GPU Virtualization Intel GVT-s Intel GVT-d Intel GVT-g AMD Firepro vcuda NVIDIA GPU-passthrough NVIDIA GRID 1. API intercept 2. GPU pass-through 3. Virtualized GPU 6 / 27
7 NVIDIA GRID GPU Virtualization XenServer Hypervisor NVIDIA GRID vgpu Manager Nvidia Kernel Driver NVIDIA GPU Management Inferface Streaming engine 3D Graphics Copy Engine Engine Requests from VMs Video Encoder Paravirtualized Interface Video Decoder Guest VM Guest Applications VM Apps Guest VM Driver Guest VM Driver Direct GPU Access Channel CPU Access Timeshared scheduling GPU MMU Framebuffer GPU Access VM1 FB VM2 FB VM1 pagetables VM2 pagetables 7 / 27
8 GPU NUMA issue Unified Architecture Discrete Architecture Socket 0 Socket 1 CPU CPU Cache Controller Last level cache GPU0 Cache QPI Cache Controller Last level cache Unified Architecture GPU1 Cache Controller Socket 0 CPU Last level cache GPU0 PCIE express QPI Socket 1 CPU GPU1 Controller Last level cache Discrete Architecture PCIE express 8 / 27
9 GPU NUMA Issue un L1/L2 Core Interconnect L1/L2 L1/L2 L1/L2 QPI Interconnect L1/L2 Core Interconnect L1/L2 L1/L2 L1/L2 un GPU A PCIe/F LL cache MC GPU B PCIe/F LL cache MC memory Local Access App Real case memory Remote Access App Ideal I/O thread I/O thread 9 / 27
10 Talk Overview 1. Background and motivation 2. Experiment Setup L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 un Core Interconnect QPI Core Interconnect un GPU A LL cache GPU B LL cache PCIe/F MC PCIe/F MC memory memory 3. Characterizations and Analysis 4. DVFS 10 / 27
11 Experiment Setup Platform Configuration 4U Supermicro Server XenServer 7.0 Intel QPI, 6.4 GT/s NVIDIA GRID K2, 8GB GDDR5, 225W, PCIE 3.0 x 16 GRID K2 Physical GPUs 2 VGPU type Frame Buffer (Mbytes) Maximum vgpus per GPU K K K K / 27
 Performance metrics: frame-per-seconds (FPS) GPGPU workloads: Rodinia benchmark Performance metrics:")

12 Workload Selection Workloads and Metrics GaaS workloads: Unigine-Heaven, Unigine-Valley, 3DMark (Return to Proxycon, Firefly Forest, Canyon Fly, Deep Freeze) Performance metrics: frame-per-seconds (FPS) GPGPU workloads: Rodinia benchmark Performance metrics: execution time Local mapping: the Guest VM s vcpus are statically pinned to the local socket close to the GPU. Remote mapping: the vcpus are statically pinned to the remote socket. (XenServer controls the memory affinity automatically close to the CPU affinity). 12 / 27
13 Talk Overview 1. Background and motivation 2. Experiment Setup L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 un Core Interconnect QPI Core Interconnect un GPU A LL cache GPU B LL cache PCIe/F MC PCIe/F MC memory memory 3. Characterizations and Analysis 4. DVFS 13 / 27
14 Bandwidth (MB/s) Bandwidth (MB/s) Bandwidth (MB/s) Bandwidth (MB/s) NUMA Transfer Bandwidth KB 2KB 4KB 8KB LocalHtoD RemoteHtoD 16KB 32KB 64KB 128KB 256KB 512KB 1MB Transfer size 2MB 4MB 8MB 16MB CPU GPU, pinned memory 32MB 64MB KB 2KB 4KB 8KB LocalDtoH RemoteDtoH 16KB 32KB 64KB 128KB 256KB 512KB 1MB Transfer size 2MB 4MB 8MB 16MB GPU CPU, pinned memory 32MB 64MB KB 2KB 4KB 8KB LocalDtoD RemoteHtoD 16KB 32KB 64KB 128KB 256KB 512KB 1MB Transfer size 2MB 4MB 8MB 16MB CPU GPU, pageable memory 32MB 64MB KB 2KB 4KB 8KB LocalDtoH RemoteDtoH 16KB 32KB 64KB 128KB 256KB 512KB 1MB Transfer size 2MB 4MB 8MB 16MB GPU CPU, pageable memory 32MB 64MB 14 / 27
15 NUMA Transfer Bandwidth Pinned memory: 10% NUMA overhead for writing data to GPU, 20% reading data back from GPU Pageable memory: close to 0 NUMA overhead for writing, 50% for reading data back from GPU 15 / 27

16 Normalized execution time Normalized execution time NUMA Performance Difference-GPGPU Workloads Note: only can be configured using K2 for CUDA programs Local Remote Remarks For GPGPU workloads streamcluster, srad_v2, backprop stands out streamcluster srad_v2 100% 80% 60% 40% 20% 0% streamcluster backprop bfs b+tree gaussian heartwall nn pathfinder mummergpu dwt2d Kernel CPU+Other srad_v2 backprop bfs b+tree gaussian heartwall nn pathfinder mummergpu dwt2d Further breakdown shows that for GPGPU workloads, the more time spent on CPU GPU communication, the higher NUMA overhead there is. 16 / 27

17 FPS FPS FPS NUMA Performance Difference-GaaS Workloads VM 4VM 3DMark K240 2VM K260 Local K280 Return to Proxycon 2VM 4VM K240 Remote 2VM K260 Firefly Forest K VM 4VM K240 2VM K260 Local Canyon Flight K280 2VM 4VM Remote K240 2VM K260 Deep Freeze K280 GaaS workloads VM 4VM 2VM Little NUMA overhead exists 0 K240 K260 Unigine-Heaven Local K280 2VM 4VM K240 Remote 2VM K260 Unigine-Valley K / 27



18 GaaS Overhead Analysis Cont. (1) 3DMark streamcluster 1. GPU compute 2.Copy queue copy between CPU and GPU 3D graphics processing 1. GPU compute 2.Copy queue copy between CPU and GPU GPU compute 1. GPU compute Unigine-Heaven 3D graphics processing 1. GPU compute 2.Copy queue backprop srad_v2 GPU compute copy between CPU and GPU 2.Copy queue copy between CPU and GPU 1. GPU compute GPU compute Unigine-Valley 2.Copy queue copy between CPU and GPU 1. GPU compute heartwall GPU compute 3D graphics processing 1. GPU compute 2.Copy queue copy between CPU and GPU 2.Copy queue copy between CPU and GPU GaaS workloads GPGPU workloads 18 / 27
19 GaaS Overhead Analysis Cont. (1) 1. For GaaS workloads, most memory copy operations between CPU and GPU are overlapped with graphics processing operations. However, GPGPU workloads are different. Little overlap happens. 2. The communication time is trivial compared to GPU computing in the graphics queue, which clearly shows the GPU-computation intensive feature. 19 / 27




")


20 GaaS Overhead Analysis Cont. (2) GPU compute 3DMark Copy queue Unigine-Heaven GPU compute GPU compute hearwall Copy queue cudamemcpy(htod) cudamemcpy(dtoh) Copy queue Unigine-Valley GPU compute Copy queue GaaS workloads 20 / 27
21 GaaS Overhead Analysis Cont. (2) GaaS workloads incurs more real-time processing, compared with GPGPU workloads. This kind of workload behavior makes it easier for memory transfers overlapping with GPU computing. 21 / 27
22 normalized L3 miss rate Influence of CPU un VMs on the same socket 4 VMs on seperate socket VM2VM3VM4 VM2VM3VM4 VM2VM3VM4 3DMark Unigine-Heaven Unigine-Valley CPU un has little performance influence on GPU NUMA for GaaS 22 / 27

23 Talk Overview 1. Background and motivation 2. Experiment Setup L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 L1/L2 un Core Interconnect QPI Core Interconnect un GPU A LL cache GPU B LL cache PCIe/F MC PCIe/F MC memory memory 3. Characterizations and Analysis 4. DVFS 23 / 27
24 FPS Power (watt) DVFS-CPU Power (watt) 660 Power (watt) RP FF CF DF UH UV Remarks: Unigine-Heaven power Performance Ondemand Powersave Performance Powersave Ondemand time(s) 3DMark power Performance Powersave Ondemand time (s) time(s) Ondemand CPU frequency scaling achieves the best performance tradeoff between performance and energy for GaaS Unigine-Valley power Performance Powersave Ondemand 24 / 27

25 FPS FPS DVFS-GPU Core Mhz _high _low Mem Mhz mem_high mem_low RP FF CF DF UH UV 0 RP FF CF DF UH UV Remarks: The GPU memory frequency can be tuned lower within a certain range to get energy saving with little performance degradation for GaaS. 25 / 27
26 Conclusions In this work, we conduct a characterization on XenServer using virtual GPU, we found no NUMA overhead for GaaS workloads, due to the fact that most memory copy operations are overlapped with GPU computation. GaaS workloads exhibits different workload behavior with GPGPU workloads. Ondemand CPU frequency scaling achieves the best tradeoff between performance and energy for GaaS. GPU memory clock can be tuned lower within a certain range to save energy for GaaS. 26 / 27

27 Thanks For Your Attention! 27 / 27
DELIVERING HIGH-PERFORMANCE REMOTE GRAPHICS WITH NVIDIA GRID VIRTUAL GPU. Andy Currid NVIDIA
 DELIVERING HIGH-PERFORMANCE REMOTE GRAPHICS WITH NVIDIA GRID VIRTUAL Andy Currid NVIDIA WHAT YOU LL LEARN IN THIS SESSION NVIDIA's GRID Virtual Architecture What it is and how it works Using GRID Virtual
DELIVERING HIGH-PERFORMANCE REMOTE GRAPHICS WITH NVIDIA GRID VIRTUAL Andy Currid NVIDIA WHAT YOU LL LEARN IN THIS SESSION NVIDIA's GRID Virtual Architecture What it is and how it works Using GRID Virtual
UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS
 UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS Neha Agarwal* David Nellans Mike O Connor Stephen W. Keckler Thomas F. Wenisch* NVIDIA University of Michigan* (Major part of this work was done when Neha
UNLOCKING BANDWIDTH FOR GPUS IN CC-NUMA SYSTEMS Neha Agarwal* David Nellans Mike O Connor Stephen W. Keckler Thomas F. Wenisch* NVIDIA University of Michigan* (Major part of this work was done when Neha
REAL PERFORMANCE RESULTS WITH VMWARE HORIZON AND VIEWPLANNER
 April 4-7, 2016 Silicon Valley REAL PERFORMANCE RESULTS WITH VMWARE HORIZON AND VIEWPLANNER Manvender Rawat, NVIDIA Jason K. Lee, NVIDIA Uday Kurkure, VMware Inc. Overview of VMware Horizon 7 and NVIDIA
April 4-7, 2016 Silicon Valley REAL PERFORMANCE RESULTS WITH VMWARE HORIZON AND VIEWPLANNER Manvender Rawat, NVIDIA Jason K. Lee, NVIDIA Uday Kurkure, VMware Inc. Overview of VMware Horizon 7 and NVIDIA
PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS
 PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS Neha Agarwal* David Nellans Mark Stephenson Mike O Connor Stephen W. Keckler NVIDIA University of Michigan* ASPLOS 2015 EVOLVING GPU
PAGE PLACEMENT STRATEGIES FOR GPUS WITHIN HETEROGENEOUS MEMORY SYSTEMS Neha Agarwal* David Nellans Mark Stephenson Mike O Connor Stephen W. Keckler NVIDIA University of Michigan* ASPLOS 2015 EVOLVING GPU
Boosting GPU Virtualization Performance with Hybrid Shadow Page Tables
 Boosting GPU Virtualization Performance with Hybrid Shadow Page Tables Yaozu Dong Mochi Xue Xiao Zheng Jiajun Wang Zhengwei Qi Haibing Guan Shanghai Jiao Tong University Intel Corporation GPU Usage Gaming
Boosting GPU Virtualization Performance with Hybrid Shadow Page Tables Yaozu Dong Mochi Xue Xiao Zheng Jiajun Wang Zhengwei Qi Haibing Guan Shanghai Jiao Tong University Intel Corporation GPU Usage Gaming
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies
 Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
Virtual GPU 을활용한 VDI 구현엔비디아서완석.
 Virtual GPU 을활용한 VDI 구현엔비디아서완석 wseo@nvidia.com Graphics Computing Cloud Graphics Computing share graphic data in workflow at anywhere NVIDIA VGX Lower Latency Higher Density z Power Efficient DESIGNER
Virtual GPU 을활용한 VDI 구현엔비디아서완석 wseo@nvidia.com Graphics Computing Cloud Graphics Computing share graphic data in workflow at anywhere NVIDIA VGX Lower Latency Higher Density z Power Efficient DESIGNER
GPU Consolidation for Cloud Games: Are We There Yet?
 GPU Consolidation for Cloud Games: Are We There Yet? Hua-Jun Hong 1, Tao-Ya Fan-Chiang 1, Che-Run Lee 1, Kuan-Ta Chen 2, Chun-Ying Huang 3, Cheng-Hsin Hsu 1 1 Department of Computer Science, National Tsing
GPU Consolidation for Cloud Games: Are We There Yet? Hua-Jun Hong 1, Tao-Ya Fan-Chiang 1, Che-Run Lee 1, Kuan-Ta Chen 2, Chun-Ying Huang 3, Cheng-Hsin Hsu 1 1 Department of Computer Science, National Tsing
Machine Learning on VMware vsphere with NVIDIA GPUs
 Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Elaborazione dati real-time su architetture embedded many-core e FPGA
 Elaborazione dati real-time su architetture embedded many-core e FPGA DAVIDE ROSSI A L E S S A N D R O C A P O T O N D I G I U S E P P E T A G L I A V I N I A N D R E A M A R O N G I U C I R I - I C T
Elaborazione dati real-time su architetture embedded many-core e FPGA DAVIDE ROSSI A L E S S A N D R O C A P O T O N D I G I U S E P P E T A G L I A V I N I A N D R E A M A R O N G I U C I R I - I C T
How NVIDIA GRID Brings Amazing Graphics to the Virtualized Experience
 How NVIDIA GRID Brings Amazing Graphics to the ized Experience Who is NVIDIA AGENDA GRID For VDI GRID Enabled Solutions User Profiles and Experiences From Super Phones to Super Cars GPU NVIDIA Brands Mobile
How NVIDIA GRID Brings Amazing Graphics to the ized Experience Who is NVIDIA AGENDA GRID For VDI GRID Enabled Solutions User Profiles and Experiences From Super Phones to Super Cars GPU NVIDIA Brands Mobile
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood
 gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
EVALUATING WINDOWS 10 LEARN WHY YOUR USERS NEED GPU ACCELERATION
 May 8-11 2017 Silicon Valley EVALUATING WINDOWS 10 LEARN WHY YOUR USERS NEED GPU ACCELERATION Jason Kyungho Lee, Sr Performance Engineer, NVIDAI GRID @NVIDIA Hari Sivaraman, Staff Engineer @ VMware Introduction
May 8-11 2017 Silicon Valley EVALUATING WINDOWS 10 LEARN WHY YOUR USERS NEED GPU ACCELERATION Jason Kyungho Lee, Sr Performance Engineer, NVIDAI GRID @NVIDIA Hari Sivaraman, Staff Engineer @ VMware Introduction
NLVMUG 16 maart Display protocols in Horizon
 NLVMUG 16 maart 2017 Display protocols in Horizon NLVMUG 16 maart 2017 Display protocols in Horizon Topics Introduction Display protocols - Basics PCoIP vs Blast Extreme Optimizing Monitoring Future Recap
NLVMUG 16 maart 2017 Display protocols in Horizon NLVMUG 16 maart 2017 Display protocols in Horizon Topics Introduction Display protocols - Basics PCoIP vs Blast Extreme Optimizing Monitoring Future Recap
Graphics in the Cloud Will Wade, NVIDIA VGX Product Line Manager Ian Williams, Director of Applied Engineering
 Graphics in the Cloud Will Wade, NVIDIA VGX Product Line Manager Ian Williams, Director of Applied Engineering Siggraph August, 2012 A Brand New Idea Graphics Graphics Computing Cloud Graphics Computing
Graphics in the Cloud Will Wade, NVIDIA VGX Product Line Manager Ian Williams, Director of Applied Engineering Siggraph August, 2012 A Brand New Idea Graphics Graphics Computing Cloud Graphics Computing
GRID SOFTWARE. DU _v4.6 January User Guide
 GRID SOFTWARE DU-06920-001 _v.6 January 2018 User Guide TABLE OF CONTENTS Chapter 1. Introduction to NVIDIA... 1 1.1. How this guide is organized... 1 1.2. GRID vgpu architecture... 2 1.3. Supported GPUs...
GRID SOFTWARE DU-06920-001 _v.6 January 2018 User Guide TABLE OF CONTENTS Chapter 1. Introduction to NVIDIA... 1 1.1. How this guide is organized... 1 1.2. GRID vgpu architecture... 2 1.3. Supported GPUs...
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
LoGA: Low-overhead GPU accounting using events
 : Low-overhead GPU accounting using events Jens Kehne Stanislav Spassov Marius Hillenbrand Marc Rittinghaus Frank Bellosa Karlsruhe Institute of Technology (KIT) Operating Systems Group os@itec.kit.edu
: Low-overhead GPU accounting using events Jens Kehne Stanislav Spassov Marius Hillenbrand Marc Rittinghaus Frank Bellosa Karlsruhe Institute of Technology (KIT) Operating Systems Group os@itec.kit.edu
Fujitsu VDI / vgpu Virtualization
 Fujitsu VDI / vgpu Virtualization Antti Sirkiä Service Partner Manager, Certified Trainer Fujitsu, Product Business Unit Why Virtualization / Graphics Virtualization? :: GRAPHICS VIRTUALIZATION :: Multiple
Fujitsu VDI / vgpu Virtualization Antti Sirkiä Service Partner Manager, Certified Trainer Fujitsu, Product Business Unit Why Virtualization / Graphics Virtualization? :: GRAPHICS VIRTUALIZATION :: Multiple
VIRTUAL GPU SOFTWARE. DU _v5.0 through 5.2 Revision 05 March User Guide
 VIRTUAL GPU SOFTWARE DU-69- _v5. through 5. Revision 5 March 8 User Guide TABLE OF CONTENTS Chapter. Introduction to NVIDIA vgpu Software..... How this Guide Is Organized..... NVIDIA vgpu Architecture....3.
VIRTUAL GPU SOFTWARE DU-69- _v5. through 5. Revision 5 March 8 User Guide TABLE OF CONTENTS Chapter. Introduction to NVIDIA vgpu Software..... How this Guide Is Organized..... NVIDIA vgpu Architecture....3.
NVIDIA GRID. Ralph Stocker, GRID Sales Specialist, Central Europe
 NVIDIA GRID Ralph Stocker, GRID Sales Specialist, Central Europe rstocker@nvidia.com GAMING AUTO ENTERPRISE HPC & CLOUD TECHNOLOGY THE WORLD LEADER IN VISUAL COMPUTING PERFORMANCE DELIVERED FROM THE CLOUD
NVIDIA GRID Ralph Stocker, GRID Sales Specialist, Central Europe rstocker@nvidia.com GAMING AUTO ENTERPRISE HPC & CLOUD TECHNOLOGY THE WORLD LEADER IN VISUAL COMPUTING PERFORMANCE DELIVERED FROM THE CLOUD
NVIDIA GRID A True PC Experience for Everyone Anywhere
 NVIDIA GRID A True PC Experience for Everyone Anywhere Why Every PC Has a GPU AGENDA NVIDIA GRID GPUs for Virtual Computing Solutions Roadmaps Resources at NVIDIA NVIDIA THE VISUAL COMPUTING COMPANY What
NVIDIA GRID A True PC Experience for Everyone Anywhere Why Every PC Has a GPU AGENDA NVIDIA GRID GPUs for Virtual Computing Solutions Roadmaps Resources at NVIDIA NVIDIA THE VISUAL COMPUTING COMPANY What
Nested Virtualization and Server Consolidation
 Nested Virtualization and Server Consolidation Vara Varavithya Department of Electrical Engineering, KMUTNB varavithya@gmail.com 1 Outline Virtualization & Background Nested Virtualization Hybrid-Nested
Nested Virtualization and Server Consolidation Vara Varavithya Department of Electrical Engineering, KMUTNB varavithya@gmail.com 1 Outline Virtualization & Background Nested Virtualization Hybrid-Nested
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Intel Graphics Virtualization Technology. Kevin Tian Graphics Virtualization Architect
 Intel Graphics Virtualization Technology Kevin Tian Graphics Virtualization Architect Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR
Intel Graphics Virtualization Technology Kevin Tian Graphics Virtualization Architect Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR
Efficiency Considerations of Cauchy Reed-Solomon Implementations on Accelerator and Multi-Core Platforms
 Efficiency Considerations of Cauchy Reed-Solomon Implementations on Accelerator and Multi-Core Platforms SAAHPC June 15 2010 Knoxville, TN Kathrin Peter Sebastian Borchert Thomas Steinke Zuse Institute
Efficiency Considerations of Cauchy Reed-Solomon Implementations on Accelerator and Multi-Core Platforms SAAHPC June 15 2010 Knoxville, TN Kathrin Peter Sebastian Borchert Thomas Steinke Zuse Institute
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Parallels Remote Application Server
 Parallels Remote Application Server GPU Accelerated Application Publishing v16.2 Parallels International GmbH Vordergasse 59 8200 Schaffhausen Switzerland Tel: + 41 52 672 20 30 www.parallels.com Copyright
Parallels Remote Application Server GPU Accelerated Application Publishing v16.2 Parallels International GmbH Vordergasse 59 8200 Schaffhausen Switzerland Tel: + 41 52 672 20 30 www.parallels.com Copyright
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
GPGPU, 4th Meeting Mordechai Butrashvily, CEO GASS Company for Advanced Supercomputing Solutions
 GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
Pexip Infinity Server Design Guide
 Pexip Infinity Server Design Guide Introduction This document describes the recommended specifications and deployment for servers hosting the Pexip Infinity platform. It starts with a Summary of recommendations
Pexip Infinity Server Design Guide Introduction This document describes the recommended specifications and deployment for servers hosting the Pexip Infinity platform. It starts with a Summary of recommendations
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
Citrix XenApp / Microsoft RDSH. How to get the Best User Experience and Performance with NVIDIA vgpu Technology
 Citrix XenApp / Microsoft RDSH How to get the Best User Experience and Performance with NVIDIA vgpu Technology G day and Welcome Jan Hendrik Meier Citrix Systems GmbH Senior Systems Engineer @jhmeier Thomas
Citrix XenApp / Microsoft RDSH How to get the Best User Experience and Performance with NVIDIA vgpu Technology G day and Welcome Jan Hendrik Meier Citrix Systems GmbH Senior Systems Engineer @jhmeier Thomas
Live Migration with Mdev Device
 Live Migration with Mdev Device Yulei Zhang yulei.zhang@intel.com 1 Background and Motivation Live Migration Desgin of Mediated Device vgpu Live Migration Implementation Current Status and Demo Future
Live Migration with Mdev Device Yulei Zhang yulei.zhang@intel.com 1 Background and Motivation Live Migration Desgin of Mediated Device vgpu Live Migration Implementation Current Status and Demo Future
FusionSim: Characterizing the Performance Benefits of Fused CPU/GPU Systems
 FusionSim: Characterizing the Performance Benefits of Fused CPU/GPU Systems by Vitaly Zakharenko A thesis submitted in conformity with the requirements for the degree of Master of Applied Science Graduate
FusionSim: Characterizing the Performance Benefits of Fused CPU/GPU Systems by Vitaly Zakharenko A thesis submitted in conformity with the requirements for the degree of Master of Applied Science Graduate
Agilio CX 2x40GbE with OVS-TC
 PERFORMANCE REPORT Agilio CX 2x4GbE with OVS-TC OVS-TC WITH AN AGILIO CX SMARTNIC CAN IMPROVE A SIMPLE L2 FORWARDING USE CASE AT LEAST 2X. WHEN SCALED TO REAL LIFE USE CASES WITH COMPLEX RULES TUNNELING
PERFORMANCE REPORT Agilio CX 2x4GbE with OVS-TC OVS-TC WITH AN AGILIO CX SMARTNIC CAN IMPROVE A SIMPLE L2 FORWARDING USE CASE AT LEAST 2X. WHEN SCALED TO REAL LIFE USE CASES WITH COMPLEX RULES TUNNELING
CSE Computer Architecture I Fall 2011 Homework 07 Memory Hierarchies Assigned: November 8, 2011, Due: November 22, 2011, Total Points: 100
 CSE 30321 Computer Architecture I Fall 2011 Homework 07 Memory Hierarchies Assigned: November 8, 2011, Due: November 22, 2011, Total Points: 100 Problem 1: (30 points) Background: One possible organization
CSE 30321 Computer Architecture I Fall 2011 Homework 07 Memory Hierarchies Assigned: November 8, 2011, Due: November 22, 2011, Total Points: 100 Problem 1: (30 points) Background: One possible organization
A Framework for Modeling GPUs Power Consumption
 A Framework for Modeling GPUs Power Consumption Sohan Lal, Jan Lucas, Michael Andersch, Mauricio Alvarez-Mesa, Ben Juurlink Embedded Systems Architecture Technische Universität Berlin Berlin, Germany January
A Framework for Modeling GPUs Power Consumption Sohan Lal, Jan Lucas, Michael Andersch, Mauricio Alvarez-Mesa, Ben Juurlink Embedded Systems Architecture Technische Universität Berlin Berlin, Germany January
Improving Virtual Machine Scheduling in NUMA Multicore Systems
 Improving Virtual Machine Scheduling in NUMA Multicore Systems Jia Rao, Xiaobo Zhou University of Colorado, Colorado Springs Kun Wang, Cheng-Zhong Xu Wayne State University http://cs.uccs.edu/~jrao/ Multicore
Improving Virtual Machine Scheduling in NUMA Multicore Systems Jia Rao, Xiaobo Zhou University of Colorado, Colorado Springs Kun Wang, Cheng-Zhong Xu Wayne State University http://cs.uccs.edu/~jrao/ Multicore
Live Migration of vgpu
 Live Migration of vgpu Aug 2016 Xiao Zheng xiao.zheng@intel.com Kevin Tian kevin.tian@intel.com Agenda GPU Virtualization and vgpu Live Migration vgpu Resources Design and Solution Current Status Summary
Live Migration of vgpu Aug 2016 Xiao Zheng xiao.zheng@intel.com Kevin Tian kevin.tian@intel.com Agenda GPU Virtualization and vgpu Live Migration vgpu Resources Design and Solution Current Status Summary
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Maximizing Six-Core AMD Opteron Processor Performance with RHEL
 Maximizing Six-Core AMD Opteron Processor Performance with RHEL Bhavna Sarathy Red Hat Technical Lead, AMD Sanjay Rao Senior Software Engineer, Red Hat Sept 4, 2009 1 Agenda Six-Core AMD Opteron processor
Maximizing Six-Core AMD Opteron Processor Performance with RHEL Bhavna Sarathy Red Hat Technical Lead, AMD Sanjay Rao Senior Software Engineer, Red Hat Sept 4, 2009 1 Agenda Six-Core AMD Opteron processor
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Live Migration of vgpu
 Live Migration of vgpu Aug 2016 Xiao Zheng xiao.zheng@intel.com Kevin Tian kevin.tian@intel.com Agenda GPU Virtualization and vgpu Live Migration vgpu Resources Design and Solution Current Status Summary
Live Migration of vgpu Aug 2016 Xiao Zheng xiao.zheng@intel.com Kevin Tian kevin.tian@intel.com Agenda GPU Virtualization and vgpu Live Migration vgpu Resources Design and Solution Current Status Summary
Jackson Marusarz Intel Corporation
 Jackson Marusarz Intel Corporation Intel VTune Amplifier Quick Introduction Get the Data You Need Hotspot (Statistical call tree), Call counts (Statistical) Thread Profiling Concurrency and Lock & Waits
Jackson Marusarz Intel Corporation Intel VTune Amplifier Quick Introduction Get the Data You Need Hotspot (Statistical call tree), Call counts (Statistical) Thread Profiling Concurrency and Lock & Waits
CS-580K/480K Advanced Topics in Cloud Computing. VM Virtualization II
 CS-580K/480K Advanced Topics in Cloud Computing VM Virtualization II 1 How to Build a Virtual Machine? 2 How to Run a Program Compiling Source Program Loading Instruction Instruction Instruction Instruction
CS-580K/480K Advanced Topics in Cloud Computing VM Virtualization II 1 How to Build a Virtual Machine? 2 How to Run a Program Compiling Source Program Loading Instruction Instruction Instruction Instruction
GPU TECHNOLOGY WORKSHOP SOUTH EAST ASIA 2014
 GPU TECHNOLOGY WORKSHOP SOUTH EAST ASIA 2014 Delivering virtualized 3D graphics apps with Citrix XenDesktop & NVIDIA Grid GPUs Garry Soriano Solution Engineer, ASEAN Citrix Systems garry.soriano@citrix.com
GPU TECHNOLOGY WORKSHOP SOUTH EAST ASIA 2014 Delivering virtualized 3D graphics apps with Citrix XenDesktop & NVIDIA Grid GPUs Garry Soriano Solution Engineer, ASEAN Citrix Systems garry.soriano@citrix.com
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Visualization of OpenCL Application Execution on CPU-GPU Systems
 Visualization of OpenCL Application Execution on CPU-GPU Systems A. Ziabari*, R. Ubal*, D. Schaa**, D. Kaeli* *NUCAR Group, Northeastern Universiy **AMD Northeastern University Computer Architecture Research
Visualization of OpenCL Application Execution on CPU-GPU Systems A. Ziabari*, R. Ubal*, D. Schaa**, D. Kaeli* *NUCAR Group, Northeastern Universiy **AMD Northeastern University Computer Architecture Research
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Understanding The Performance of DPDK as a Computer Architect
 Understanding The Performance of DPDK as a Computer Architect XIAOBAN WU *, PEILONG LI *, YAN LUO *, LIANG- MIN (LARRY) WANG +, MARC PEPIN +, AND JOHN MORGAN + * UNIVERSITY OF MASSACHUSETTS LOWELL + INTEL
Understanding The Performance of DPDK as a Computer Architect XIAOBAN WU *, PEILONG LI *, YAN LUO *, LIANG- MIN (LARRY) WANG +, MARC PEPIN +, AND JOHN MORGAN + * UNIVERSITY OF MASSACHUSETTS LOWELL + INTEL
Comparing Memory Systems for Chip Multiprocessors
 Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
CSC501 Operating Systems Principles. OS Structure
 CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
Virtualization Station. Brings an Efficient Virtualization Environment 4 essential aspects
 Virtualization Station Brings an Efficient Virtualization Environment 4 essential aspects Core values of Virtualization Logically dividing the physical computer resource (CPU, memory, storage and network)
Virtualization Station Brings an Efficient Virtualization Environment 4 essential aspects Core values of Virtualization Logically dividing the physical computer resource (CPU, memory, storage and network)
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems
 NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana
NUMA-Aware Data-Transfer Measurements for Power/NVLink Multi-GPU Systems Carl Pearson 1, I-Hsin Chung 2, Zehra Sura 2, Wen-Mei Hwu 1, and Jinjun Xiong 2 1 University of Illinois Urbana-Champaign, Urbana
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Virtualization. Michael Tsai 2018/4/16
 Virtualization Michael Tsai 2018/4/16 What is virtualization? Let s first look at a video from VMware http://www.vmware.com/tw/products/vsphere.html Problems? Low utilization Different needs DNS DHCP Web
Virtualization Michael Tsai 2018/4/16 What is virtualization? Let s first look at a video from VMware http://www.vmware.com/tw/products/vsphere.html Problems? Low utilization Different needs DNS DHCP Web
An Investigation of Unified Memory Access Performance in CUDA
 An Investigation of Unified Memory Access Performance in CUDA Raphael Landaverde, Tiansheng Zhang, Ayse K. Coskun and Martin Herbordt Electrical and Computer Engineering Department, Boston University,
An Investigation of Unified Memory Access Performance in CUDA Raphael Landaverde, Tiansheng Zhang, Ayse K. Coskun and Martin Herbordt Electrical and Computer Engineering Department, Boston University,
WHITE PAPER SINGLE & MULTI CORE PERFORMANCE OF AN ERASURE CODING WORKLOAD ON AMD EPYC
 WHITE PAPER SINGLE & MULTI CORE PERFORMANCE OF AN ERASURE CODING WORKLOAD ON AMD EPYC INTRODUCTION With the EPYC processor line, AMD is expected to take a strong position in the server market including
WHITE PAPER SINGLE & MULTI CORE PERFORMANCE OF AN ERASURE CODING WORKLOAD ON AMD EPYC INTRODUCTION With the EPYC processor line, AMD is expected to take a strong position in the server market including
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
VIRTUAL GPU SOFTWARE. DU _v6.0 March User Guide
 VIRTUAL GPU SOFTWARE DU-69- _v6. March User Guide TABLE OF CONTENTS Chapter. Introduction to NVIDIA vgpu Software..... How this Guide Is Organized..... NVIDIA vgpu Architecture....3. Supported GPUs....3..
VIRTUAL GPU SOFTWARE DU-69- _v6. March User Guide TABLE OF CONTENTS Chapter. Introduction to NVIDIA vgpu Software..... How this Guide Is Organized..... NVIDIA vgpu Architecture....3. Supported GPUs....3..
Fit for Purpose Platform Positioning and Performance Architecture
 Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
NVIDIA GRID APPLICATION SIZING FOR AUTODESK REVIT 2016
 NVIDIA GRID APPLICATION SIZING FOR AUTODESK REVIT 2016 BPG-08489-001 March 2017 Best Practices Guide TABLE OF CONTENTS Users Per Server (UPS)... 1 Technology Overview... 3 Autodesk Revit 2016 Application...
NVIDIA GRID APPLICATION SIZING FOR AUTODESK REVIT 2016 BPG-08489-001 March 2017 Best Practices Guide TABLE OF CONTENTS Users Per Server (UPS)... 1 Technology Overview... 3 Autodesk Revit 2016 Application...
ECE 571 Advanced Microprocessor-Based Design Lecture 20
 ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
Graphics Pass-through with VT-d
 Graphics Pass-through with VT-d Nov-19-2009 Weidong Han Ben Lin Xen Summit Asia 2009 Agenda Graphics Virtualization Introduction Graphics Pass-through with VT-d Performance Conclusion 2 Requirements on
Graphics Pass-through with VT-d Nov-19-2009 Weidong Han Ben Lin Xen Summit Asia 2009 Agenda Graphics Virtualization Introduction Graphics Pass-through with VT-d Performance Conclusion 2 Requirements on
Dongjun Shin Samsung Electronics
 2014.10.31. Dongjun Shin Samsung Electronics Contents 2 Background Understanding CPU behavior Experiments Improvement idea Revisiting Linux I/O stack Conclusion Background Definition 3 CPU bound A computer
2014.10.31. Dongjun Shin Samsung Electronics Contents 2 Background Understanding CPU behavior Experiments Improvement idea Revisiting Linux I/O stack Conclusion Background Definition 3 CPU bound A computer
IsoStack Highly Efficient Network Processing on Dedicated Cores
 IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
CSE Computer Architecture I Fall 2009 Homework 08 Pipelined Processors and Multi-core Programming Assigned: Due: Problem 1: (10 points)
") CSE 30321 Computer Architecture I Fall 2009 Homework 08 Pipelined Processors and Multi-core Programming Assigned: November 17, 2009 Due: December 1, 2009 This assignment can be done in groups of 1, 2,
CSE 30321 Computer Architecture I Fall 2009 Homework 08 Pipelined Processors and Multi-core Programming Assigned: November 17, 2009 Due: December 1, 2009 This assignment can be done in groups of 1, 2,
Position Paper: OpenMP scheduling on ARM big.little architecture
 Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
Framework of rcuda: An Overview
 Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT
 EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT JOSEPH L. GREATHOUSE, MAYANK DAGA AMD RESEARCH 11/20/2014 THIS TALK IN ONE SLIDE Demonstrate how to save space and time
EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT JOSEPH L. GREATHOUSE, MAYANK DAGA AMD RESEARCH 11/20/2014 THIS TALK IN ONE SLIDE Demonstrate how to save space and time
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
Parallel LZ77 Decoding with a GPU. Emmanuel Morfiadakis Supervisor: Dr Eric McCreath College of Engineering and Computer Science, ANU
 Parallel LZ77 Decoding with a GPU Emmanuel Morfiadakis Supervisor: Dr Eric McCreath College of Engineering and Computer Science, ANU Outline Background (What?) Problem definition and motivation (Why?)
Parallel LZ77 Decoding with a GPU Emmanuel Morfiadakis Supervisor: Dr Eric McCreath College of Engineering and Computer Science, ANU Outline Background (What?) Problem definition and motivation (Why?)
Energy-Efficient Scheduling for Memory-Intensive GPGPU Workloads
 Energy-Efficient Scheduling for Memory-Intensive GPGPU Workloads Seokwoo Song, Minseok Lee, John Kim KAIST Daejeon, Korea {sukwoo, lms5, jjk}@kaist.ac.kr Woong Seo, Yeongon Cho, Soojung Ryu Samsung Electronics
Energy-Efficient Scheduling for Memory-Intensive GPGPU Workloads Seokwoo Song, Minseok Lee, John Kim KAIST Daejeon, Korea {sukwoo, lms5, jjk}@kaist.ac.kr Woong Seo, Yeongon Cho, Soojung Ryu Samsung Electronics
Knut Omang Ifi/Oracle 20 Oct, Introduction to virtualization (Virtual machines) Aspects of network virtualization:
 Aspects of network virtualization:") Software and hardware support for Network Virtualization part 2 Knut Omang Ifi/Oracle 20 Oct, 2015 32 Overview Introduction to virtualization (Virtual machines) Aspects of network virtualization: Virtual
Software and hardware support for Network Virtualization part 2 Knut Omang Ifi/Oracle 20 Oct, 2015 32 Overview Introduction to virtualization (Virtual machines) Aspects of network virtualization: Virtual
S5006 YOUR HORIZON VIEW DEPLOYMENT IS GPU READY, JUST ADD NVIDIA GRID. Jeremy Main Senior Solution Architect - GRID
 S5006 YOUR HORIZON VIEW DEPLOYMENT IS GPU READY, JUST ADD NVIDIA GRID Jeremy Main Senior Solution Architect - GRID AGENDA 1 Overview 2 Prerequisites 3 Differences between vsga and vdga 4 vsga setup and
S5006 YOUR HORIZON VIEW DEPLOYMENT IS GPU READY, JUST ADD NVIDIA GRID Jeremy Main Senior Solution Architect - GRID AGENDA 1 Overview 2 Prerequisites 3 Differences between vsga and vdga 4 vsga setup and
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
What s New in VMware vsphere 4.1 Performance. VMware vsphere 4.1
 What s New in VMware vsphere 4.1 Performance VMware vsphere 4.1 T E C H N I C A L W H I T E P A P E R Table of Contents Scalability enhancements....................................................................
What s New in VMware vsphere 4.1 Performance VMware vsphere 4.1 T E C H N I C A L W H I T E P A P E R Table of Contents Scalability enhancements....................................................................
SmartMD: A High Performance Deduplication Engine with Mixed Pages
 SmartMD: A High Performance Deduplication Engine with Mixed Pages Fan Guo 1, Yongkun Li 1, Yinlong Xu 1, Song Jiang 2, John C. S. Lui 3 1 University of Science and Technology of China 2 University of Texas,
SmartMD: A High Performance Deduplication Engine with Mixed Pages Fan Guo 1, Yongkun Li 1, Yinlong Xu 1, Song Jiang 2, John C. S. Lui 3 1 University of Science and Technology of China 2 University of Texas,
CHAPTER 16 - VIRTUAL MACHINES
 CHAPTER 16 - VIRTUAL MACHINES 1 OBJECTIVES Explore history and benefits of virtual machines. Discuss the various virtual machine technologies. Describe the methods used to implement virtualization. Show
CHAPTER 16 - VIRTUAL MACHINES 1 OBJECTIVES Explore history and benefits of virtual machines. Discuss the various virtual machine technologies. Describe the methods used to implement virtualization. Show
Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology
 Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology Dan Amerson, Technical Director, Emergent Game Technologies Purpose Why am I giving this talk? To answer this question:
Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology Dan Amerson, Technical Director, Emergent Game Technologies Purpose Why am I giving this talk? To answer this question:
Energy-centric DVFS Controlling Method for Multi-core Platforms
 Energy-centric DVFS Controlling Method for Multi-core Platforms Shin-gyu Kim, Chanho Choi, Hyeonsang Eom, Heon Y. Yeom Seoul National University, Korea MuCoCoS 2012 Salt Lake City, Utah Abstract Goal To
Energy-centric DVFS Controlling Method for Multi-core Platforms Shin-gyu Kim, Chanho Choi, Hyeonsang Eom, Heon Y. Yeom Seoul National University, Korea MuCoCoS 2012 Salt Lake City, Utah Abstract Goal To
GViM: GPU-accelerated Virtual Machines
 GViM: GPU-accelerated Virtual Machines Vishakha Gupta, Ada Gavrilovska, Karsten Schwan, Harshvardhan Kharche @ Georgia Tech Niraj Tolia, Vanish Talwar, Partha Ranganathan @ HP Labs Trends in Processor
GViM: GPU-accelerated Virtual Machines Vishakha Gupta, Ada Gavrilovska, Karsten Schwan, Harshvardhan Kharche @ Georgia Tech Niraj Tolia, Vanish Talwar, Partha Ranganathan @ HP Labs Trends in Processor
GRID SOFTWARE FOR HUAWEI UVP VERSION /370.12
 GRID SOFTWARE FOR HUAWEI UVP VERSION 367.122/370.12 RN-07939-001 _v4.4 (GRID) Revision 02 October 2017 Release Notes TABLE OF CONTENTS Chapter 1. Release Notes... 1 Chapter 2. Validated Platforms...2 2.1.
GRID SOFTWARE FOR HUAWEI UVP VERSION 367.122/370.12 RN-07939-001 _v4.4 (GRID) Revision 02 October 2017 Release Notes TABLE OF CONTENTS Chapter 1. Release Notes... 1 Chapter 2. Validated Platforms...2 2.1.