Artificial Neural Networks MLP, RBF & GMDH
|
|
|
- Felicia Jones
- 5 years ago
- Views:
Transcription
1 Artificial Neural Networks MLP, RBF & GMDH Jan Drchal Computational Intelligence Group Department of Computer Science and Engineering Faculty of Electrical Engineering Czech Technical University in Prague
2 Outline MultiLayer Perceptron (MLP). How many layers and neurons? How to train ANNs and preprocess data? Radial Basis Function (RBF). Group Method of Data Handling (GMDH).

3 Layered ANNs single layer two layers feed-forward networks recurrent network
4 MultiLayer Perceptron (MLP) Inputs x 1 x 2 x 3 Input Layer w ij Hidden Layers w jk w kl Output Layer y 1 y 2 Outputs
5 Neurons in MLPs nonlinear transfer function x 1 x 2 w 1 w 2 neuron output McCulloch-Pitts perceptron. x 3 w 3 y Θ threshold x n w n weights neuron inputs
6 Logistic Sigmoid Function S s = 1 1 e s Sigmoid for different gain/slope parameter γ. But also many other (non)-linear functions...
7 How Many Hidden Layers? MLPs with Discrete Activation Functions see ftp://ftp.sas.com/pub/neural/faq3.html#a_hl for overview Structure Types of Decision Regions Exclusive-OR Problem Classes with Meshed regions Most General Region Shapes Single-Layer Half Plane Bounded By Hyperplane A B B A B A Two-Layer Convex Open Or Closed Regions A B B A B A Three-Layer Arbitrary (Complexity Limited by No. of Nodes) A B B A B A
8 How Many Hidden Layers? Continuous MLPs Universal Approximation property. Kurt Hornik: For MLP using continuous, bounded, and non-constant activation functions a single hidden layer is enough to approximate any function. Leshno, Lin, Pinkus & Schocken 1993: non-polynomial activation function suffices...
9 Continuous MLPs Although one hidden layer is enough for a continuous MLP: we don't know how many neurons to use, fewer neurons are often sufficient for ANN architectures with two (or more) hidden layers. See ftp://ftp.sas.com/pub/neural/faq3.html#a_hl for example.
10 How Many Neurons? No one knows :( we have only rough estimates (upper bounds): ANN with a single hidden layer: N hid = N in. N out, ANN with two hidden layers: N hid 1 =N out. 3 N in N out 2, N hid 2 =N out. 3 N in N out. You have to experiment!
11 Generalization vs. Overfitting When training ANNs we typically want them to perform accurately on new previously unseen data. This ability is known as the generalization. When ANN rather memorizes the training data while giving bad results on new data, we talk about overfitting (overtraining).
12 Training/Testing Sets Training set Testing set Random samples. ~70% ~30% Used to train ANN model. Testing set error generalization
13 Overfitting Example here, we should stop training testing error training error
14 Example: Bad Choice of A Training Set
15 Training/Validation/Testing Sets Ripley Pattern Recognition and Neural Networks, 1996: Training set: A set of examples used for learning, that is to fit the parameters [i.e., weights] of the ANN. Validation set: A set of examples used to tune the parameters [i.e., architecture, not weights] of an ANN, for example to choose the number of hidden units. Test set: A set of examples used only to assess the performance (generalization) of a fully-specified ANN. Separated: ~60%, ~20%, ~20%. Note: meaning of the validation and test sets is often reversed in literature (machine-learning vs. statististics). For example see Priddy, Keller: Artificial neural networks: an introduction (Google books, p. 44)

16 Training/Validation/Testing Sets II Taken from Ricardo Gutierrez-Osuna's slides:
17 k-fold Cross-validation Example 10-fold cross-validation: Split training data to 10 folds of equal size. Training data Repeat 10 times, always chose different fold for validation set (1 of 10). 90% 10% Training set Create 10 ANN models. Suitable for small datasets, reduces the problems caused by random selection of training/testing sets Validation set The cross-validation error is the average over all (10) validation sets.
18 Cleaning Dataset Imputing missing values. Outlier identification: the instance of the data distant from the rest of the data Smoothing-out the noisy data.
19 Data Reduction Often needed for large data sets. The reduced dataset should be representative sample of the original dataset. The simplest algorithm: randomly remove data instances.
20 Data Transformation Normalization: Aggregation: scaling/shifting values to fit given interval or distribution i.e. binning - discretization (continuous values to classes).
21 Learning Process Notes We don't have to choose instances sequentially random selection. We can apply certain instances more frequently than others. We need often hundreds to thousands epochs to train the network. Good strategy might speed things up.

22 Backpropagation (BP) Paul Werbos, 1974, Harvard, PhD thesis. Still popular method, many modifications. BP is a learning method for MLP: continuous, differentiable activation functions!
23 ANN Energy Backpropagation is based on a minimalization of ANN energy (= error). Energy is a measure describing how the network is trained on given data. For BP we define the energy function: where E TOTAL = p E p E p = 1 2 i=1 N o d i o y i o 2 The total sum computed over all patterns of the training set. we will omit p in following slides Note, ½ only for convenience we will see later...
24 ANN Energy II The energy/error is a function of: E= f X, W W X weights (thresholds) variable, inputs fixed (for given pattern).
25 Weight Update We want to update weights in opposite direction to the gradient: w jk = E w jk weight delta learning rate Note: gradient of energy function is a vector which contains partial derivatives for all weights (thresholds)
26 Typical Energy Behaviour During Learning
27 Radial Basis Function (RBF) Networks Two layers, different types of neurons in each layer. Feed-forward. Supervised Learning. Broomhead, Lowe (1988). Universal approximator.
28 RBF Architecture Input 1 Input 2
29 RBF Neurons Hidden layer: inner potential n ϕ= i=1 ( x i c i ) 2 non-linear activation function y * = f(φ Output layer: linear perceptron n y= i=1 w i y i *
 α, ß 0, 0 < α< 2 y * σ =e 2,")
30 Typical RBF Activation Functions y * = φ y * = φ 2 log φ y * = (φ 2 + ß) α, ß 0, 0 < α< 2 y * σ =e 2, 0
31 Sphere of Influence Hypersphere with center C and radius R. Determined by euclidean metric. The center is called the prototype. The prototype represents a cluster of input data.
32 How to Determine the Sphere of Influence? Mostly we use Gauss function: If an input vector has same weights as the prototype (ϕ = 0), the function gains maximum (= 1). This is also the maximum activation value of the neuron. With increasing distance of input vector from the prototype the activity of neuron decreases. σ (which corresponds to a variance of normal distribution) determines a gain (width) of the activation function.

33 Sphere of Influence: Example
34 Sphere of Influence for Hardware Implementations
35 Neuron Types Discussion RBF neurons: inner potential is a measure of distance between input vector and the prototype (represented by the weights), activation function delimits the sphere of influence. Output neurons: accumulate RBF neurons' outputs to achieve accurate approximation, OR perform union of sets for classification.
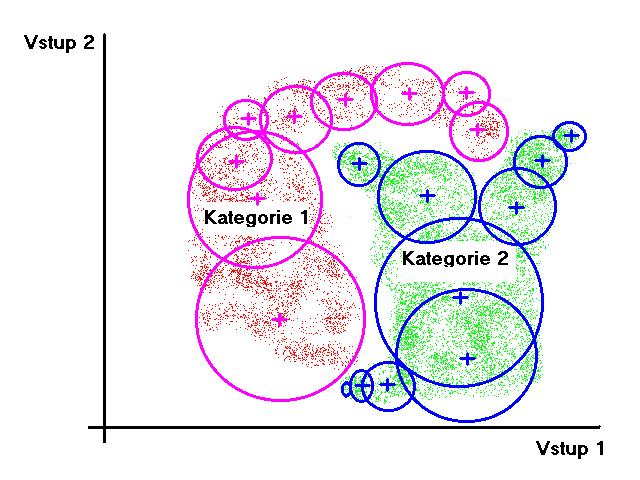
36 RBF as a Classifier
37 Application Areas Same as MLPs. Universal approximator (1991: Park, Sandberg).
38 Training RBF Networks Two phases: training prototypes, training output neurons. Training prototypes: Unsupervised: Cluster Analysis. Training output neurons: Supervised.
39 Training Prototypes I Estimate the number of clusters in input data :( Define a membership function m(x): determines whether an input pattern belongs to a certain cluster, choose cluster by the closest prototype. Estimate coordinates of all vectors Cp which correspond to cluster centers: we use a well-known K-means algorithm.
40 Training Prototypes II: K-means Steps of K-means algorithm: randomly initialize centers C i of RBF neurons, *) evaluate m() for all input patterns, determine a new center C k as an average of all patterns which belong to cluster k according to m(). stop when m() does not change anymore, otherwise go to *)
41 Training Prototypes III There exists also an adaptive version of the previous algorithm: reminds perceptron learning algorithms (i.e. delta rule), moves a center closer to input vectors.
42 Training Prototypes IV: Adaptive K-means Steps of adaptive K-means: randomly initialize centers C i, *) take input pattern X, determine closest center C k and change its coordinates according to: C k (t+ 1) = C k t + η( X (t ) C k t ) where η denotes adaptation rate, which decreases with successive iterations. stop when η = 0 or after certain # of iterations. Otherwise continue with *).
43 Training Prototypes V: Estimate # of Clusters Start with zero number of clusters, *) take input pattern X, Find the closest cluster k, If the distance between C k and X < some constant r, modify: If the distance > r, create a new center with coordinates of X: stop when η = 0 or after certain # of iterations. Otherwise continue with *). How to choose r? C k (t+ 1) = C k t + η( X (t ) C k t ) C k t+ 1 = X (t )
44 Training Prototypes V: Determine σ Parameter σ is determined by a root mean squared deviation (RMSD) of distance between patterns and cluster center: σ k = 1 Q Q q=1 where X q is q-th pattern which belongs to cluster with center C k. C k X q 2 Other approach uses fixed σ
45 Training Output Neurons Find weights by minimization of this energy function: Δ w (t ) = η E (t ) =η( D ( t ) Y (t ) )Y *(t ) Is it familiar? m i=1 n ( d i ( t ) y i (t ) ) 2 E = 1 2 t=1
46 MLP vs. RBF Learning RBF learns faster. Applications MLP/RBF usable for regression & classification X 2 X 1 MLP Properties both are universal approximators. X 2 RBF As classifiers: MLPs - hyperplanes, RBFs - hyperspheres. X 1

47 The Spiral problem One of the most challenging artificial benchmarks: separate two inter-winded spirals. How can MLP solve it? How about RBF?
48 RBF for Approximation
49 Approximation by RBF: Example f(x) x Unit n

50 GMDH Group Method of Data Handling. By A.G. Ivakhnenko, Network is constructed by induction. Multiple layers. Feed-forward. Supervised. See
51 Induction vs. Deduction There are two approaches to create a model of a system: data-driven: based on observations of a real system. The task is to infer general rule from specific cases this the way GMDH model is built induction, theory-driven: based on theoretical knowledge of system functionality the way to create mathematical models deduction.
52 GMDH Types Parametric parameters are set during training, MIA (Multilayer Iterative Algorithm) partial induction COMBI (Combinatorial Algorithm) full induction Other variants are non-parametric.
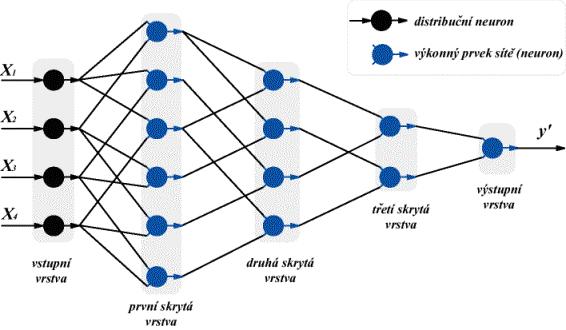
53 GMDH MIA Architecture
54 Remarks The structure (topology) of this network forms itself during learning process. # of neurons and even # of hidden layers changes during learning, network self-organizes (but in a different way than SOM)

55 GMDH MIA Neuron y=ai 2 + bij+ cj 2 + di+ ej+ f Ivakhnenko's polynomial. Example of other Ivakhnenko's polynomials: y=a+ bi+ cj, y=ai+ bjk.
56 MIA Characteristics MIA network uses supervised learning. MIA uses single type of neurons (unlike other GMDH variants). Training: network is built layer by layer, layers are added until some error criterion is met. Network evaluation is simple: feed-forward, only single output.
57 MIA Training Configure k-th layer (k denotes actual layer) create new neurons in the layer, compute all six coefficients of polynomial. Selection of neurons in k-th layer elimination of unsuccessful neurons. Repeat or finish training.
58 MIA Training II Lemke,Müller:SELF-ORGANIZING DATA MINING BASED ON GMDH PRINCIPLE
59 MIA Training III 1s t layer creation: Active neurons with optimized transfer function y k =f k (v i,v j ). Two inputs only! They form initial population. How many neurons?
60 MIA Training III 1s t layer creation: Active neurons with optimized transfer function y k =f k (v i,v j ). Two inputs only! They form initial population. How many neurons? N 2 = N N 1 2
61 MIA Training IV How to optimize neuron's coefficients? Least Mean Squares (LMS), we have to optimize six coefficients choose 6 random input vectors solve system of 6 linear equations y=ai 2 + bij+ cj 2 + di+ ej+ f
 some neurons survive, others not.")
62 MIA Training V Next step: Selection. According to a criterion (see later) some neurons survive, others not... If we are satisfied with the output (low error) stop. Similar to evolutionary algorithms...
63 MIA Training VI 2nd layer: Again, initial population has to be created. Active neurons form the possible network output. Next step?
64 MIA Training VII Selection again. Competing neurons (survive and die) are of the same complexity. If we are still not satisfied with them next layer is created.
65 MIA Training VII
66 When to End Training? F = quadratic error of the best neuron of layer k Here, we stop adding new layers. This layer becomes the output layer. number of hidden layers
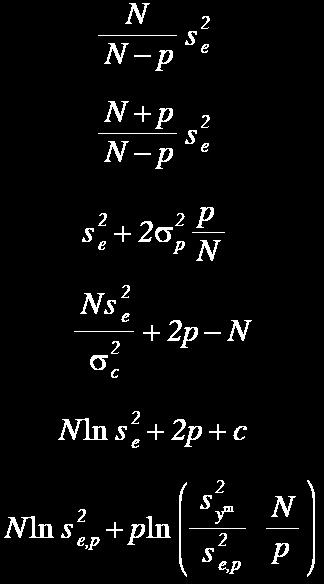
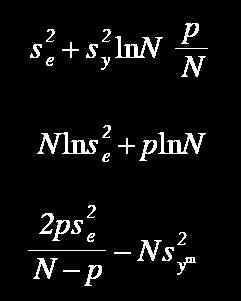

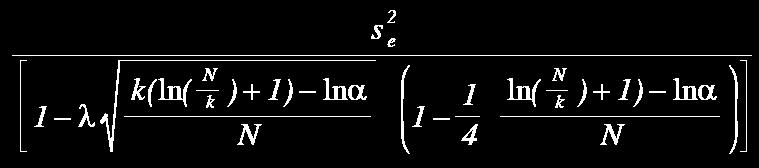
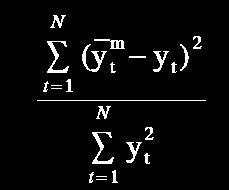
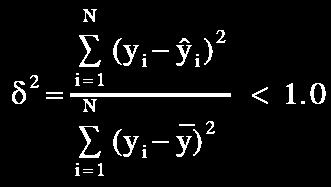
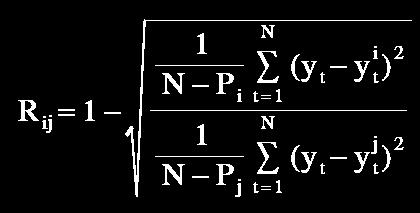
67 Possibilities to Determine Fmin :) Regularity criterion FPE Discrimination criterion PSE Validation criterion
68 Most Common Regularity Criterion: neuron s output trained on the A-subset. Neurons are then ordered according to their error on validation data B-subset.
69 GMDH Mathematical Model Example: x 1 x 2 P 1 P 2 P 3 y x 3 P i are linear y=ρ 3 (Ρ 2 ( x 1, x 3 ), Ρ 1 ( x 1, x 2 ))=a 31 (a 11 x 1 + a 12 x 3 + a 13 )+ a 32 (a 21 x 1 + a 22 x 2 + a 23 )+ a 33 = ( a 31 a 11 + a 32 a 21 )x 1 + ( a 32 a 22 )x 2 + (a 31 a 21 )x 3 + a 31 a 13 + a 32 a 23 + a 33
70 GMDH Mathematical Model II Problems: Solution? real systems are too complex and... equations become too confusing. Visualize model behaviour!
71 COMBI vs. MIA What's the difference between partial and full induction? COMBI uses supervised learning, too. COMBI employs different types of neurons, but: same in a single layer, more complex in following layers, not connected to a previous layer, but to network inputs always combine the most fit.
72 Notes The full induction network (COMBI) works with a full input space all the time. It tries to apply successively complex transformations. The partial induction network (MIA) applies only a single transformation to most promising input subspaces. It is a heuristic which speeds up the algorithm.
73 Other Inductive Approaches Cascade Correlation: diploma thesis by Minh Duc Do: NEAT and other TWEANNs (Topology and Weight Evolving Neural Networks) we will see later...
74 Next Lecture Recurrent ANNs = RNNs
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS
 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS
 LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
Supervised Learning in Neural Networks (Part 2)
") Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Classification Lecture Notes cse352. Neural Networks. Professor Anita Wasilewska
 Classification Lecture Notes cse352 Neural Networks Professor Anita Wasilewska Neural Networks Classification Introduction INPUT: classification data, i.e. it contains an classification (class) attribute
Classification Lecture Notes cse352 Neural Networks Professor Anita Wasilewska Neural Networks Classification Introduction INPUT: classification data, i.e. it contains an classification (class) attribute
Artificial Neural Networks Unsupervised learning: SOM
 Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Regularization of Evolving Polynomial Models
 Regularization of Evolving Polynomial Models Pavel Kordík Dept. of Computer Science and Engineering, Karlovo nám. 13, 121 35 Praha 2, Czech Republic kordikp@fel.cvut.cz Abstract. Black box models such
Regularization of Evolving Polynomial Models Pavel Kordík Dept. of Computer Science and Engineering, Karlovo nám. 13, 121 35 Praha 2, Czech Republic kordikp@fel.cvut.cz Abstract. Black box models such
Machine Learning in Biology
 Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
Data Mining. Neural Networks
 Data Mining Neural Networks Goals for this Unit Basic understanding of Neural Networks and how they work Ability to use Neural Networks to solve real problems Understand when neural networks may be most
Data Mining Neural Networks Goals for this Unit Basic understanding of Neural Networks and how they work Ability to use Neural Networks to solve real problems Understand when neural networks may be most
COMPUTATIONAL INTELLIGENCE
 COMPUTATIONAL INTELLIGENCE Radial Basis Function Networks Adrian Horzyk Preface Radial Basis Function Networks (RBFN) are a kind of artificial neural networks that use radial basis functions (RBF) as activation
COMPUTATIONAL INTELLIGENCE Radial Basis Function Networks Adrian Horzyk Preface Radial Basis Function Networks (RBFN) are a kind of artificial neural networks that use radial basis functions (RBF) as activation
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
Learning. Learning agents Inductive learning. Neural Networks. Different Learning Scenarios Evaluation
 Learning Learning agents Inductive learning Different Learning Scenarios Evaluation Slides based on Slides by Russell/Norvig, Ronald Williams, and Torsten Reil Material from Russell & Norvig, chapters
Learning Learning agents Inductive learning Different Learning Scenarios Evaluation Slides based on Slides by Russell/Norvig, Ronald Williams, and Torsten Reil Material from Russell & Norvig, chapters
Support Vector Machines
 Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Artificial neural networks are the paradigm of connectionist systems (connectionism vs. symbolism)
") Artificial Neural Networks Analogy to biological neural systems, the most robust learning systems we know. Attempt to: Understand natural biological systems through computational modeling. Model intelligent
Artificial Neural Networks Analogy to biological neural systems, the most robust learning systems we know. Attempt to: Understand natural biological systems through computational modeling. Model intelligent
Linear Separability. Linear Separability. Capabilities of Threshold Neurons. Capabilities of Threshold Neurons. Capabilities of Threshold Neurons
 Linear Separability Input space in the two-dimensional case (n = ): - - - - - - w =, w =, = - - - - - - w = -, w =, = - - - - - - w = -, w =, = Linear Separability So by varying the weights and the threshold,
Linear Separability Input space in the two-dimensional case (n = ): - - - - - - w =, w =, = - - - - - - w = -, w =, = - - - - - - w = -, w =, = Linear Separability So by varying the weights and the threshold,
An Algorithm For Training Multilayer Perceptron (MLP) For Image Reconstruction Using Neural Network Without Overfitting.
 For Image Reconstruction Using Neural Network Without Overfitting.") An Algorithm For Training Multilayer Perceptron (MLP) For Image Reconstruction Using Neural Network Without Overfitting. Mohammad Mahmudul Alam Mia, Shovasis Kumar Biswas, Monalisa Chowdhury Urmi, Abubakar
An Algorithm For Training Multilayer Perceptron (MLP) For Image Reconstruction Using Neural Network Without Overfitting. Mohammad Mahmudul Alam Mia, Shovasis Kumar Biswas, Monalisa Chowdhury Urmi, Abubakar
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
4.12 Generalization. In back-propagation learning, as many training examples as possible are typically used.
 1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
Support Vector Machines
 Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Cse634 DATA MINING TEST REVIEW. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Perceptrons and Backpropagation. Fabio Zachert Cognitive Modelling WiSe 2014/15
 Perceptrons and Backpropagation Fabio Zachert Cognitive Modelling WiSe 2014/15 Content History Mathematical View of Perceptrons Network Structures Gradient Descent Backpropagation (Single-Layer-, Multilayer-Networks)
Perceptrons and Backpropagation Fabio Zachert Cognitive Modelling WiSe 2014/15 Content History Mathematical View of Perceptrons Network Structures Gradient Descent Backpropagation (Single-Layer-, Multilayer-Networks)
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
Dr. Qadri Hamarsheh Supervised Learning in Neural Networks (Part 1) learning algorithm Δwkj wkj Theoretically practically
 learning algorithm Δwkj wkj Theoretically practically") Supervised Learning in Neural Networks (Part 1) A prescribed set of well-defined rules for the solution of a learning problem is called a learning algorithm. Variety of learning algorithms are existing,
Supervised Learning in Neural Networks (Part 1) A prescribed set of well-defined rules for the solution of a learning problem is called a learning algorithm. Variety of learning algorithms are existing,
COMPUTATIONAL INTELLIGENCE
 COMPUTATIONAL INTELLIGENCE Fundamentals Adrian Horzyk Preface Before we can proceed to discuss specific complex methods we have to introduce basic concepts, principles, and models of computational intelligence
COMPUTATIONAL INTELLIGENCE Fundamentals Adrian Horzyk Preface Before we can proceed to discuss specific complex methods we have to introduce basic concepts, principles, and models of computational intelligence
CMPT 882 Week 3 Summary
 CMPT 882 Week 3 Summary! Artificial Neural Networks (ANNs) are networks of interconnected simple units that are based on a greatly simplified model of the brain. ANNs are useful learning tools by being
CMPT 882 Week 3 Summary! Artificial Neural Networks (ANNs) are networks of interconnected simple units that are based on a greatly simplified model of the brain. ANNs are useful learning tools by being
Supervised Learning (contd) Linear Separation. Mausam (based on slides by UW-AI faculty)
 Linear Separation. Mausam (based on slides by UW-AI faculty)") Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
More on Learning. Neural Nets Support Vectors Machines Unsupervised Learning (Clustering) K-Means Expectation-Maximization
 K-Means Expectation-Maximization") More on Learning Neural Nets Support Vectors Machines Unsupervised Learning (Clustering) K-Means Expectation-Maximization Neural Net Learning Motivated by studies of the brain. A network of artificial
More on Learning Neural Nets Support Vectors Machines Unsupervised Learning (Clustering) K-Means Expectation-Maximization Neural Net Learning Motivated by studies of the brain. A network of artificial
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
CP365 Artificial Intelligence
 CP365 Artificial Intelligence Tech News! Apple news conference tomorrow? Tech News! Apple news conference tomorrow? Google cancels Project Ara modular phone Weather-Based Stock Market Predictions? Dataset
CP365 Artificial Intelligence Tech News! Apple news conference tomorrow? Tech News! Apple news conference tomorrow? Google cancels Project Ara modular phone Weather-Based Stock Market Predictions? Dataset
CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks
 Networks") CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks Part IV 1 Function approximation MLP is both a pattern classifier and a function approximator As a function approximator,
CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks Part IV 1 Function approximation MLP is both a pattern classifier and a function approximator As a function approximator,
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Vulnerability of machine learning models to adversarial examples
 Vulnerability of machine learning models to adversarial examples Petra Vidnerová Institute of Computer Science The Czech Academy of Sciences Hora Informaticae 1 Outline Introduction Works on adversarial
Vulnerability of machine learning models to adversarial examples Petra Vidnerová Institute of Computer Science The Czech Academy of Sciences Hora Informaticae 1 Outline Introduction Works on adversarial
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
11/14/2010 Intelligent Systems and Soft Computing 1
 Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
Lecture 7 Artificial neural networks: Supervised learning Introduction, or how the brain works The neuron as a simple computing element The perceptron Multilayer neural networks Accelerated learning in
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Pattern Classification Algorithms for Face Recognition
 Chapter 7 Pattern Classification Algorithms for Face Recognition 7.1 Introduction The best pattern recognizers in most instances are human beings. Yet we do not completely understand how the brain recognize
Chapter 7 Pattern Classification Algorithms for Face Recognition 7.1 Introduction The best pattern recognizers in most instances are human beings. Yet we do not completely understand how the brain recognize
Machine Learning written examination
 Institutionen för informationstenologi Olle Gällmo Universitetsadjunt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Machine Learning written examination Friday, June 10, 2011 8 00-13 00 Allowed help
Institutionen för informationstenologi Olle Gällmo Universitetsadjunt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Machine Learning written examination Friday, June 10, 2011 8 00-13 00 Allowed help
Notes on Multilayer, Feedforward Neural Networks
 Notes on Multilayer, Feedforward Neural Networks CS425/528: Machine Learning Fall 2012 Prepared by: Lynne E. Parker [Material in these notes was gleaned from various sources, including E. Alpaydin s book
Notes on Multilayer, Feedforward Neural Networks CS425/528: Machine Learning Fall 2012 Prepared by: Lynne E. Parker [Material in these notes was gleaned from various sources, including E. Alpaydin s book
Bioinformatics - Lecture 07
 Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
A Dendrogram. Bioinformatics (Lec 17)
") A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
Nelder-Mead Enhanced Extreme Learning Machine
 Philip Reiner, Bogdan M. Wilamowski, "Nelder-Mead Enhanced Extreme Learning Machine", 7-th IEEE Intelligent Engineering Systems Conference, INES 23, Costa Rica, June 9-2., 29, pp. 225-23 Nelder-Mead Enhanced
Philip Reiner, Bogdan M. Wilamowski, "Nelder-Mead Enhanced Extreme Learning Machine", 7-th IEEE Intelligent Engineering Systems Conference, INES 23, Costa Rica, June 9-2., 29, pp. 225-23 Nelder-Mead Enhanced
Assignment # 5. Farrukh Jabeen Due Date: November 2, Neural Networks: Backpropation
 Farrukh Jabeen Due Date: November 2, 2009. Neural Networks: Backpropation Assignment # 5 The "Backpropagation" method is one of the most popular methods of "learning" by a neural network. Read the class
Farrukh Jabeen Due Date: November 2, 2009. Neural Networks: Backpropation Assignment # 5 The "Backpropagation" method is one of the most popular methods of "learning" by a neural network. Read the class
In this assignment, we investigated the use of neural networks for supervised classification
 Paul Couchman Fabien Imbault Ronan Tigreat Gorka Urchegui Tellechea Classification assignment (group 6) Image processing MSc Embedded Systems March 2003 Classification includes a broad range of decision-theoric
Paul Couchman Fabien Imbault Ronan Tigreat Gorka Urchegui Tellechea Classification assignment (group 6) Image processing MSc Embedded Systems March 2003 Classification includes a broad range of decision-theoric
Optimization Methods for Machine Learning (OMML)
") Optimization Methods for Machine Learning (OMML) 2nd lecture Prof. L. Palagi References: 1. Bishop Pattern Recognition and Machine Learning, Springer, 2006 (Chap 1) 2. V. Cherlassky, F. Mulier - Learning
Optimization Methods for Machine Learning (OMML) 2nd lecture Prof. L. Palagi References: 1. Bishop Pattern Recognition and Machine Learning, Springer, 2006 (Chap 1) 2. V. Cherlassky, F. Mulier - Learning
Week 3: Perceptron and Multi-layer Perceptron
 Week 3: Perceptron and Multi-layer Perceptron Phong Le, Willem Zuidema November 12, 2013 Last week we studied two famous biological neuron models, Fitzhugh-Nagumo model and Izhikevich model. This week,
Week 3: Perceptron and Multi-layer Perceptron Phong Le, Willem Zuidema November 12, 2013 Last week we studied two famous biological neuron models, Fitzhugh-Nagumo model and Izhikevich model. This week,
Neural Network Learning. Today s Lecture. Continuation of Neural Networks. Artificial Neural Networks. Lecture 24: Learning 3. Victor R.
 Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
CHAPTER VI BACK PROPAGATION ALGORITHM
 6.1 Introduction CHAPTER VI BACK PROPAGATION ALGORITHM In the previous chapter, we analysed that multiple layer perceptrons are effectively applied to handle tricky problems if trained with a vastly accepted
6.1 Introduction CHAPTER VI BACK PROPAGATION ALGORITHM In the previous chapter, we analysed that multiple layer perceptrons are effectively applied to handle tricky problems if trained with a vastly accepted
Radial Basis Function Networks: Algorithms
 Radial Basis Function Networks: Algorithms Neural Computation : Lecture 14 John A. Bullinaria, 2015 1. The RBF Mapping 2. The RBF Network Architecture 3. Computational Power of RBF Networks 4. Training
Radial Basis Function Networks: Algorithms Neural Computation : Lecture 14 John A. Bullinaria, 2015 1. The RBF Mapping 2. The RBF Network Architecture 3. Computational Power of RBF Networks 4. Training
Neural Networks. Neural Network. Neural Network. Neural Network 2/21/2008. Andrew Kusiak. Intelligent Systems Laboratory Seamans Center
 Neural Networks Neural Network Input Andrew Kusiak Intelligent t Systems Laboratory 2139 Seamans Center Iowa City, IA 52242-1527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Tel. 319-335
Neural Networks Neural Network Input Andrew Kusiak Intelligent t Systems Laboratory 2139 Seamans Center Iowa City, IA 52242-1527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Tel. 319-335
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Review: Final Exam CPSC Artificial Intelligence Michael M. Richter
 Review: Final Exam Model for a Learning Step Learner initially Environm ent Teacher Compare s pe c ia l Information Control Correct Learning criteria Feedback changed Learner after Learning Learning by
Review: Final Exam Model for a Learning Step Learner initially Environm ent Teacher Compare s pe c ia l Information Control Correct Learning criteria Feedback changed Learner after Learning Learning by
Face Detection Using Radial Basis Function Neural Networks With Fixed Spread Value
 Detection Using Radial Basis Function Neural Networks With Fixed Value Khairul Azha A. Aziz Faculty of Electronics and Computer Engineering, Universiti Teknikal Malaysia Melaka, Ayer Keroh, Melaka, Malaysia.
Detection Using Radial Basis Function Neural Networks With Fixed Value Khairul Azha A. Aziz Faculty of Electronics and Computer Engineering, Universiti Teknikal Malaysia Melaka, Ayer Keroh, Melaka, Malaysia.
Classification and Regression using Linear Networks, Multilayer Perceptrons and Radial Basis Functions
 ENEE 739Q SPRING 2002 COURSE ASSIGNMENT 2 REPORT 1 Classification and Regression using Linear Networks, Multilayer Perceptrons and Radial Basis Functions Vikas Chandrakant Raykar Abstract The aim of the
ENEE 739Q SPRING 2002 COURSE ASSIGNMENT 2 REPORT 1 Classification and Regression using Linear Networks, Multilayer Perceptrons and Radial Basis Functions Vikas Chandrakant Raykar Abstract The aim of the
Multilayer Feed-forward networks
 Multi Feed-forward networks 1. Computational models of McCulloch and Pitts proposed a binary threshold unit as a computational model for artificial neuron. This first type of neuron has been generalized
Multi Feed-forward networks 1. Computational models of McCulloch and Pitts proposed a binary threshold unit as a computational model for artificial neuron. This first type of neuron has been generalized
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis
 Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Review on Methods of Selecting Number of Hidden Nodes in Artificial Neural Network
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Neural Networks. Theory And Practice. Marco Del Vecchio 19/07/2017. Warwick Manufacturing Group University of Warwick
 Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
Function approximation using RBF network. 10 basis functions and 25 data points.
 1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
Linear Models. Lecture Outline: Numeric Prediction: Linear Regression. Linear Classification. The Perceptron. Support Vector Machines
 Linear Models Lecture Outline: Numeric Prediction: Linear Regression Linear Classification The Perceptron Support Vector Machines Reading: Chapter 4.6 Witten and Frank, 2nd ed. Chapter 4 of Mitchell Solving
Linear Models Lecture Outline: Numeric Prediction: Linear Regression Linear Classification The Perceptron Support Vector Machines Reading: Chapter 4.6 Witten and Frank, 2nd ed. Chapter 4 of Mitchell Solving
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks Radial Basis Function Networks Rudolf Kruse
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks Radial Basis Function Networks Rudolf Kruse
Feature scaling in support vector data description
 Feature scaling in support vector data description P. Juszczak, D.M.J. Tax, R.P.W. Duin Pattern Recognition Group, Department of Applied Physics, Faculty of Applied Sciences, Delft University of Technology,
Feature scaling in support vector data description P. Juszczak, D.M.J. Tax, R.P.W. Duin Pattern Recognition Group, Department of Applied Physics, Faculty of Applied Sciences, Delft University of Technology,
IMPLEMENTATION OF RBF TYPE NETWORKS BY SIGMOIDAL FEEDFORWARD NEURAL NETWORKS
 IMPLEMENTATION OF RBF TYPE NETWORKS BY SIGMOIDAL FEEDFORWARD NEURAL NETWORKS BOGDAN M.WILAMOWSKI University of Wyoming RICHARD C. JAEGER Auburn University ABSTRACT: It is shown that by introducing special
IMPLEMENTATION OF RBF TYPE NETWORKS BY SIGMOIDAL FEEDFORWARD NEURAL NETWORKS BOGDAN M.WILAMOWSKI University of Wyoming RICHARD C. JAEGER Auburn University ABSTRACT: It is shown that by introducing special
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning : Clustering, Self-Organizing Maps
 Machine Learning Clustering, Self-Organizing Maps 12/12/2013 Machine Learning : Clustering, Self-Organizing Maps Clustering The task: partition a set of objects into meaningful subsets (clusters). The
Machine Learning Clustering, Self-Organizing Maps 12/12/2013 Machine Learning : Clustering, Self-Organizing Maps Clustering The task: partition a set of objects into meaningful subsets (clusters). The
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Opening the Black Box Data Driven Visualizaion of Neural N
 Opening the Black Box Data Driven Visualizaion of Neural Networks September 20, 2006 Aritificial Neural Networks Limitations of ANNs Use of Visualization (ANNs) mimic the processes found in biological
Opening the Black Box Data Driven Visualizaion of Neural Networks September 20, 2006 Aritificial Neural Networks Limitations of ANNs Use of Visualization (ANNs) mimic the processes found in biological
DM6 Support Vector Machines
 DM6 Support Vector Machines Outline Large margin linear classifier Linear separable Nonlinear separable Creating nonlinear classifiers: kernel trick Discussion on SVM Conclusion SVM: LARGE MARGIN LINEAR
DM6 Support Vector Machines Outline Large margin linear classifier Linear separable Nonlinear separable Creating nonlinear classifiers: kernel trick Discussion on SVM Conclusion SVM: LARGE MARGIN LINEAR
Multi Layer Perceptron with Back Propagation. User Manual
 Multi Layer Perceptron with Back Propagation User Manual DAME-MAN-NA-0011 Issue: 1.3 Date: September 03, 2013 Author: S. Cavuoti, M. Brescia Doc. : MLPBP_UserManual_DAME-MAN-NA-0011-Rel1.3 1 INDEX 1 Introduction...
Multi Layer Perceptron with Back Propagation User Manual DAME-MAN-NA-0011 Issue: 1.3 Date: September 03, 2013 Author: S. Cavuoti, M. Brescia Doc. : MLPBP_UserManual_DAME-MAN-NA-0011-Rel1.3 1 INDEX 1 Introduction...
Univariate and Multivariate Decision Trees
 Univariate and Multivariate Decision Trees Olcay Taner Yıldız and Ethem Alpaydın Department of Computer Engineering Boğaziçi University İstanbul 80815 Turkey Abstract. Univariate decision trees at each
Univariate and Multivariate Decision Trees Olcay Taner Yıldız and Ethem Alpaydın Department of Computer Engineering Boğaziçi University İstanbul 80815 Turkey Abstract. Univariate decision trees at each
4. Feedforward neural networks. 4.1 Feedforward neural network structure
 4. Feedforward neural networks 4.1 Feedforward neural network structure Feedforward neural network is one of the most common network architectures. Its structure and some basic preprocessing issues required
4. Feedforward neural networks 4.1 Feedforward neural network structure Feedforward neural network is one of the most common network architectures. Its structure and some basic preprocessing issues required
Introduction to ANSYS DesignXplorer
 Lecture 4 14. 5 Release Introduction to ANSYS DesignXplorer 1 2013 ANSYS, Inc. September 27, 2013 s are functions of different nature where the output parameters are described in terms of the input parameters
Lecture 4 14. 5 Release Introduction to ANSYS DesignXplorer 1 2013 ANSYS, Inc. September 27, 2013 s are functions of different nature where the output parameters are described in terms of the input parameters
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Basis Functions. Volker Tresp Summer 2017
 Basis Functions Volker Tresp Summer 2017 1 Nonlinear Mappings and Nonlinear Classifiers Regression: Linearity is often a good assumption when many inputs influence the output Some natural laws are (approximately)
Basis Functions Volker Tresp Summer 2017 1 Nonlinear Mappings and Nonlinear Classifiers Regression: Linearity is often a good assumption when many inputs influence the output Some natural laws are (approximately)
Neural Networks (Overview) Prof. Richard Zanibbi
 Prof. Richard Zanibbi") Neural Networks (Overview) Prof. Richard Zanibbi Inspired by Biology Introduction But as used in pattern recognition research, have little relation with real neural systems (studied in neurology and neuroscience)
Neural Networks (Overview) Prof. Richard Zanibbi Inspired by Biology Introduction But as used in pattern recognition research, have little relation with real neural systems (studied in neurology and neuroscience)
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Model learning for robot control: a survey
 Model learning for robot control: a survey Duy Nguyen-Tuong, Jan Peters 2011 Presented by Evan Beachly 1 Motivation Robots that can learn how their motors move their body Complexity Unanticipated Environments
Model learning for robot control: a survey Duy Nguyen-Tuong, Jan Peters 2011 Presented by Evan Beachly 1 Motivation Robots that can learn how their motors move their body Complexity Unanticipated Environments
Introduction to Neural Networks: Structure and Training
 Introduction to Neural Networks: Structure and Training Qi-Jun Zhang Department of Electronics Carleton University, Ottawa, ON, Canada A Quick Illustration Example: Neural Network Model for Delay Estimation
Introduction to Neural Networks: Structure and Training Qi-Jun Zhang Department of Electronics Carleton University, Ottawa, ON, Canada A Quick Illustration Example: Neural Network Model for Delay Estimation
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR
 EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR 1.Introductıon. 2.Multi Layer Perception.. 3.Fuzzy C-Means Clustering.. 4.Real
EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR 1.Introductıon. 2.Multi Layer Perception.. 3.Fuzzy C-Means Clustering.. 4.Real
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Recent Developments in Model-based Derivative-free Optimization
 Recent Developments in Model-based Derivative-free Optimization Seppo Pulkkinen April 23, 2010 Introduction Problem definition The problem we are considering is a nonlinear optimization problem with constraints:
Recent Developments in Model-based Derivative-free Optimization Seppo Pulkkinen April 23, 2010 Introduction Problem definition The problem we are considering is a nonlinear optimization problem with constraints:
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
A Comparative Study of SVM Kernel Functions Based on Polynomial Coefficients and V-Transform Coefficients
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 6 Issue 3 March 2017, Page No. 20765-20769 Index Copernicus value (2015): 58.10 DOI: 18535/ijecs/v6i3.65 A Comparative
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 6 Issue 3 March 2017, Page No. 20765-20769 Index Copernicus value (2015): 58.10 DOI: 18535/ijecs/v6i3.65 A Comparative
Basis Functions. Volker Tresp Summer 2016
 Basis Functions Volker Tresp Summer 2016 1 I am an AI optimist. We ve got a lot of work in machine learning, which is sort of the polite term for AI nowadays because it got so broad that it s not that
Basis Functions Volker Tresp Summer 2016 1 I am an AI optimist. We ve got a lot of work in machine learning, which is sort of the polite term for AI nowadays because it got so broad that it s not that
Face Detection Using Radial Basis Function Neural Networks with Fixed Spread Value
 IJCSES International Journal of Computer Sciences and Engineering Systems, Vol., No. 3, July 2011 CSES International 2011 ISSN 0973-06 Face Detection Using Radial Basis Function Neural Networks with Fixed
IJCSES International Journal of Computer Sciences and Engineering Systems, Vol., No. 3, July 2011 CSES International 2011 ISSN 0973-06 Face Detection Using Radial Basis Function Neural Networks with Fixed
Neural Bag-of-Features Learning
 Neural Bag-of-Features Learning Nikolaos Passalis, Anastasios Tefas Department of Informatics, Aristotle University of Thessaloniki Thessaloniki 54124, Greece Tel,Fax: +30-2310996304 Abstract In this paper,
Neural Bag-of-Features Learning Nikolaos Passalis, Anastasios Tefas Department of Informatics, Aristotle University of Thessaloniki Thessaloniki 54124, Greece Tel,Fax: +30-2310996304 Abstract In this paper,
Research Article Forecasting SPEI and SPI Drought Indices Using the Integrated Artificial Neural Networks
 Computational Intelligence and Neuroscience Volume 2016, Article ID 3868519, 17 pages http://dx.doi.org/10.1155/2016/3868519 Research Article Forecasting SPEI and SPI Drought Indices Using the Integrated
Computational Intelligence and Neuroscience Volume 2016, Article ID 3868519, 17 pages http://dx.doi.org/10.1155/2016/3868519 Research Article Forecasting SPEI and SPI Drought Indices Using the Integrated
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
Data Mining: Concepts and Techniques. Chapter 9 Classification: Support Vector Machines. Support Vector Machines (SVMs)
") Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Lecture-12: Closed Sets
 and Its Examples Properties of Lecture-12: Dr. Department of Mathematics Lovely Professional University Punjab, India October 18, 2014 Outline Introduction and Its Examples Properties of 1 Introduction
and Its Examples Properties of Lecture-12: Dr. Department of Mathematics Lovely Professional University Punjab, India October 18, 2014 Outline Introduction and Its Examples Properties of 1 Introduction
CS229 Final Project: Predicting Expected Response Times
 CS229 Final Project: Predicting Expected Email Response Times Laura Cruz-Albrecht (lcruzalb), Kevin Khieu (kkhieu) December 15, 2017 1 Introduction Each day, countless emails are sent out, yet the time
CS229 Final Project: Predicting Expected Email Response Times Laura Cruz-Albrecht (lcruzalb), Kevin Khieu (kkhieu) December 15, 2017 1 Introduction Each day, countless emails are sent out, yet the time