A Brief Look at Optimization
|
|
|
- Gabriel Gardner
- 5 years ago
- Views:
Transcription
1 A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version
2 Overview Introduction Classes of optimization problems Linear programming Steepest (gradient) descent Newton s method Quasi-Newton methods Conjugate gradients Stochastic gradient descent
3 What is optimization? Typical setup (in machine learning, life): Formulate a problem Design a solution (usually a model) Use some quantitative measure to determine how good the solution is. E.g., classification: Create a system to classify images Model is some simple classifier, like logistic regression Quantitative measure is classification error (lower is better in this case) The natural question to ask is: can we find a solution with a better score? Question: what could we change in the classification setup to lower the classification error (what are the free variables)?
 is equivalent to maximizing -f(θ), so we can just talk about minimization")
4 Formal definition f(θ): some arbitrary function c(θ): some arbitrary constraints Minimizing f(θ) is equivalent to maximizing -f(θ), so we can just talk about minimization and be OK.
5 Types of optimization problems Depending on f, c, and the domain of θ we get many problems with many different characteristics. General optimization of arbitrary functions with arbitrary constraints is extremely hard. Most techniques exploit structure in the problem to find a solution more efficiently.
6 Types of optimization Simple enough problems have a closed form solution: f(x) = x 2 Linear regression If f and c are linear functions then we can use linear programming (solvable in polynomial time). If f and c are convex then we can use convex optimization technique (most of machine learning uses these). If f and c are non-convex we usually pretend it s convex and find a sub-optimal, but hopefully good enough solution (e.g., deep learning). In the worst case there are global optimization techniques (operations research is very good at these). There are yet more techniques when the domain of θ is discrete. This list is far from exhaustive.
7 Types of optimization Takeaway: Think hard about your problem, find the simplest category that it fits into, use the tools from that branch of optimization. Sometimes you can solve a hard problem with a special-purpose algorithm, but most times we favor a black-box approach because it s simple and usually works.
8 Really naïve optimization algorithm Suppose D-dimensional vector of parameters where each dimension is bounded above and below. For each dimension I pick some set of values to try: Try all combinations of values for each dimension, record f for each one. Pick the combination that minimizes f.
9 Really naïve optimization algorithm This is called grid search. It works really well in low dimensions when you can afford to evaluate f many times. Less appealing when f is expensive or in high dimensions. You may have already done this when searching for a good L2 penalty value.

10 Convex functions Use the line test.


11 Convex functions
12 Convex optimization We ve talked about 1D functions, but the definition still applies to higher dimensions. Why do we care about convex functions? In a convex function, any local minimum is automatically a global minimum. This means we can apply fairly naïve techniques to find the nearest local minimum and still guarantee that we ve found the best solution!

13 Steepest (gradient) descent Cauchy (1847)
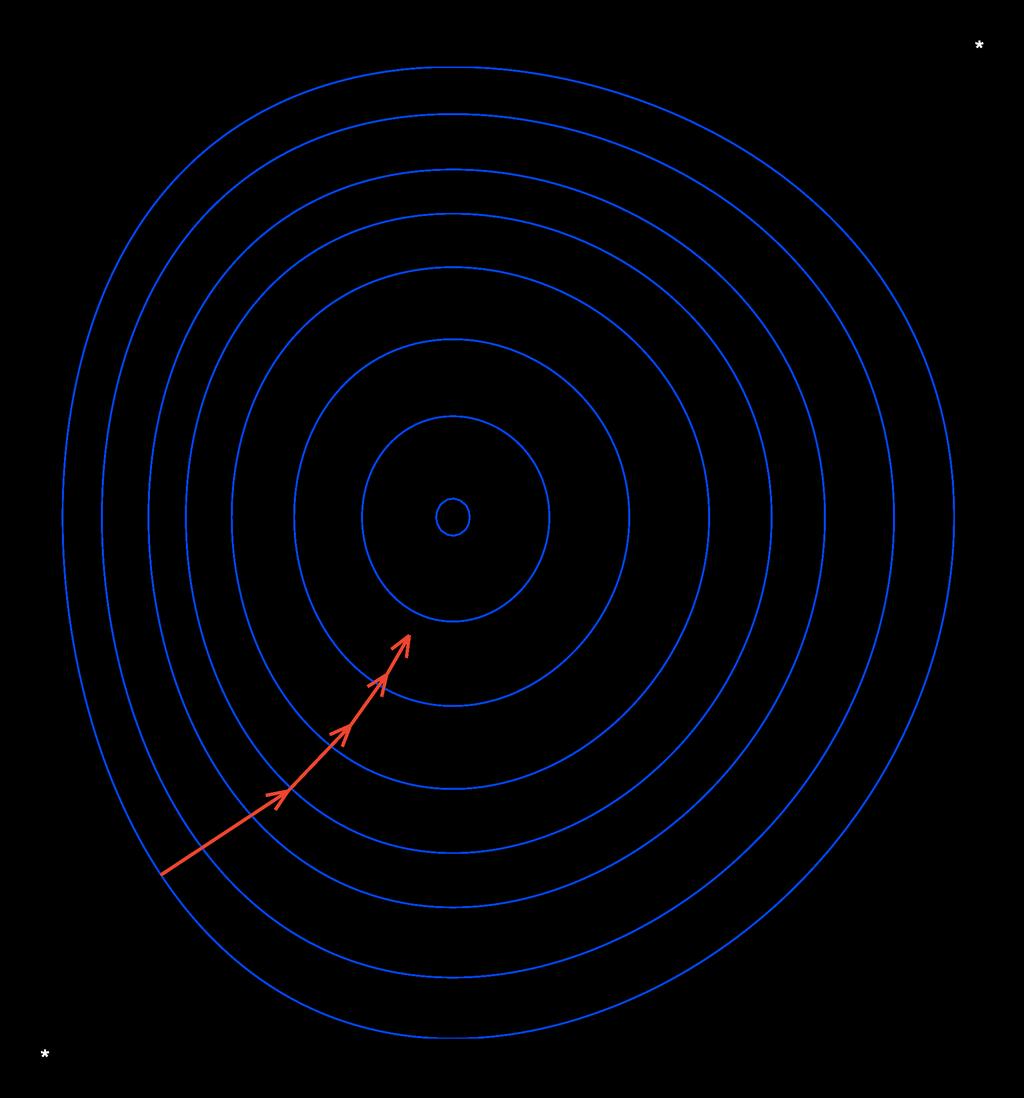
14
15 Aside: Taylor series A Taylor series is a polynomial series that converges to a function f. We say that the Taylor series expansion of at x around a point a, f(x + a) is: Truncating this series gives a polynomial approximation to a function.
16 Blue: exponential function; Red: Taylor series approximation
17 Multivariate Taylor Series The first-order Taylor series expansion of a function f(θ) around a point d is:
 - f(θ + ηd).")
18 Steepest descent derivation Suppose we are at θ and we want to pick a direction d (with norm 1) such that f(θ + ηd) is as small as possible for some step size η. This is equivalent to maximizing f(θ) - f(θ + ηd). Using a linear approximation: This approximation gets better as η gets smaller since as we zoom in on a differentiable function it will look more and more linear.

19 Steepest descent derivation We need to find the value for d that maximizes subject to Using the definition of cosine as the angle between two vectors:
20 How to choose the step size? At iteration t General idea: vary η t until we find the minimum along This is a 1D optimization problem. In the worst case we can just make η t very small, but then we need to take a lot more steps. General strategy: start with a big η t and progressively make it smaller by e.g., halving it until the function decreases.
21 When have we converged? When If the function is convex then we have reached a global minimum.

22 The problem with gradient descent source:
23 Newton s method To speed up convergence, we can use a more accurate approximation. Second order Taylor expansion: H is the Hessian matrix containing second derivatives.

24 Newton s method
25 What is it doing? At each step, Newton s method approximates the function with a quadratic bowl, then goes to the minimum of this bowl. For twice or more differentiable convex functions, this is usually much faster than steepest descent (provably). Con: computing Hessian requires O(D 2 ) time and storage. Inverting the Hessian is even more expensive (up to O(D 3 )). This is problematic in high dimensions.
26 Quasi-Newton methods Computation involving the Hessian is expensive. Modern approaches use computationally cheaper approximations to the Hessian or it s inverse. Deriving these is beyond the scope of this tutorial, but we ll outline some of the key ideas. These are implemented in many good software packages in many languages and can be treated as black box solvers, but it s good to know where they come from so that you know when you use them.
27 BFGS Maintain a running estimate of the Hessian B t. At each iteration, set B t+1 = B t + U t + V t where U and V are rank 1 matrices (these are derived specifically for the algorithm). The advantage of using a low-rank update to improve the Hessian estimate is that B can be cheaply inverted at each iteration.
28 Limited memory BFGS BFGS progressively updates B and so one can think of B t as a sum of rank-1 matrices from steps 1 to t. We could instead store these updates and recompute B t at each iteration (although this would involve a lot of redundant work). L-BFGS only stores the most recent updates, therefore the approximation itself is always low rank and only a limited amount of memory needs to be used (linear in D). L-BFGS works extremely well in practice. L-BFGS-B extends L-BFGS to handle bound constraints on the variables.
29 Conjugate gradients Steepest descent often picks a direction it s travelled in before (this results in the wiggly behavior). Conjugate gradients make sure we don t travel in the same direction again. The derivation for quadratics is more involved than we have time for. The derivation for general convex functions is fairly hacky, but reduces to the quadratic version when the function is indeed quadratic. Takeaway: conjugate gradient works better than steepest descent, almost as good as L-BFGS. It also has a much cheaper per-iteration cost (still linear, but better constants).


30 Stochastic Gradient Descent Recall that we can write the log-likelihood of a distribution as:
31 Stochastic gradient descent Any iteration of a gradient descent (or quasi-newton) method requires that we sum over the entire dataset to compute the gradient. SGD idea: at each iteration, sub-sample a small amount of data (even just 1 point can work) and use that to estimate the gradient. Each update is noisy, but very fast! This is the basis of optimizing ML algorithms with huge datasets (e.g., recent deep learning). Computing gradients using the full dataset is called batch learning, using subsets of data is called minibatch learning.
32 Stochastic gradient descent Suppose we made a copy of each point, y=x so that we now have twice as much data. The log-likelihood is now: In other words, the optimal parameters don t change, but we have to do twice as much work to compute the loglikelihood and it s gradient! The reason SGD works is because similar data yields similar gradients, so if there is enough redundancy in the data, the noisy from subsampling won t be so bad.
33 Stochastic gradient descent In the stochastic setting, line searches break down and so do estimates of the Hessian, so stochastic quasi- Newton methods are very difficult to get right. So how do we choose an appropriate step size? Robbins and Monro (1951): pick a sequence of η t such that: Satisfied by (as one example). Balances making progress with averaging out noise.
34 Final words on SGD SGD is very easy to implement compared to other methods, but the step sizes need to be tuned to different problems, whereas batch learning typically just works. Tip 1: divide the log-likelihood estimate by the size of your mini-batches. This makes the learning rate invariant to mini-batch size. Tip 2: subsample without replacement so that you visit each point on each pass through the dataset (this is known as an epoch).
35 Useful References Linear programming: - Linear Programming: Foundations and Extensions ( Convex optimization: LP solver: Gurobi: Stats (python): Scipy stats: html Optimization (python): Scipy optimize: Optimization (Matlab): minfunc: General ML: Scikit-Learn:
CS281 Section 3: Practical Optimization
 CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
5 Machine Learning Abstractions and Numerical Optimization
 Machine Learning Abstractions and Numerical Optimization 25 5 Machine Learning Abstractions and Numerical Optimization ML ABSTRACTIONS [some meta comments on machine learning] [When you write a large computer
Machine Learning Abstractions and Numerical Optimization 25 5 Machine Learning Abstractions and Numerical Optimization ML ABSTRACTIONS [some meta comments on machine learning] [When you write a large computer
Logistic Regression and Gradient Ascent
 Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
Logistic Regression. Abstract
 Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
Theoretical Concepts of Machine Learning
 Theoretical Concepts of Machine Learning Part 2 Institute of Bioinformatics Johannes Kepler University, Linz, Austria Outline 1 Introduction 2 Generalization Error 3 Maximum Likelihood 4 Noise Models 5
Theoretical Concepts of Machine Learning Part 2 Institute of Bioinformatics Johannes Kepler University, Linz, Austria Outline 1 Introduction 2 Generalization Error 3 Maximum Likelihood 4 Noise Models 5
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Scalable Data Analysis
 Scalable Data Analysis David M. Blei April 26, 2012 1 Why? Olden days: Small data sets Careful experimental design Challenge: Squeeze as much as we can out of the data Modern data analysis: Very large
Scalable Data Analysis David M. Blei April 26, 2012 1 Why? Olden days: Small data sets Careful experimental design Challenge: Squeeze as much as we can out of the data Modern data analysis: Very large
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Hyperparameter optimization. CS6787 Lecture 6 Fall 2017
 Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Logistic Regression
 Logistic Regression ddebarr@uw.edu 2016-05-26 Agenda Model Specification Model Fitting Bayesian Logistic Regression Online Learning and Stochastic Optimization Generative versus Discriminative Classifiers
Logistic Regression ddebarr@uw.edu 2016-05-26 Agenda Model Specification Model Fitting Bayesian Logistic Regression Online Learning and Stochastic Optimization Generative versus Discriminative Classifiers
IE598 Big Data Optimization Summary Nonconvex Optimization
 IE598 Big Data Optimization Summary Nonconvex Optimization Instructor: Niao He April 16, 2018 1 This Course Big Data Optimization Explore modern optimization theories, algorithms, and big data applications
IE598 Big Data Optimization Summary Nonconvex Optimization Instructor: Niao He April 16, 2018 1 This Course Big Data Optimization Explore modern optimization theories, algorithms, and big data applications
M. Sc. (Artificial Intelligence and Machine Learning)
") Course Name: Advanced Python Course Code: MSCAI 122 This course will introduce students to advanced python implementations and the latest Machine Learning and Deep learning libraries, Scikit-Learn and
Course Name: Advanced Python Course Code: MSCAI 122 This course will introduce students to advanced python implementations and the latest Machine Learning and Deep learning libraries, Scikit-Learn and
Introduction to Optimization Problems and Methods
 Introduction to Optimization Problems and Methods wjch@umich.edu December 10, 2009 Outline 1 Linear Optimization Problem Simplex Method 2 3 Cutting Plane Method 4 Discrete Dynamic Programming Problem Simplex
Introduction to Optimization Problems and Methods wjch@umich.edu December 10, 2009 Outline 1 Linear Optimization Problem Simplex Method 2 3 Cutting Plane Method 4 Discrete Dynamic Programming Problem Simplex
25. NLP algorithms. ˆ Overview. ˆ Local methods. ˆ Constrained optimization. ˆ Global methods. ˆ Black-box methods.
 CS/ECE/ISyE 524 Introduction to Optimization Spring 2017 18 25. NLP algorithms ˆ Overview ˆ Local methods ˆ Constrained optimization ˆ Global methods ˆ Black-box methods ˆ Course wrap-up Laurent Lessard
CS/ECE/ISyE 524 Introduction to Optimization Spring 2017 18 25. NLP algorithms ˆ Overview ˆ Local methods ˆ Constrained optimization ˆ Global methods ˆ Black-box methods ˆ Course wrap-up Laurent Lessard
Optimization. Industrial AI Lab.
 Optimization Industrial AI Lab. Optimization An important tool in 1) Engineering problem solving and 2) Decision science People optimize Nature optimizes 2 Optimization People optimize (source: http://nautil.us/blog/to-save-drowning-people-ask-yourself-what-would-light-do)
Optimization Industrial AI Lab. Optimization An important tool in 1) Engineering problem solving and 2) Decision science People optimize Nature optimizes 2 Optimization People optimize (source: http://nautil.us/blog/to-save-drowning-people-ask-yourself-what-would-light-do)
CPSC 340: Machine Learning and Data Mining. More Linear Classifiers Fall 2017
 CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
Modern Methods of Data Analysis - WS 07/08
 Modern Methods of Data Analysis Lecture XV (04.02.08) Contents: Function Minimization (see E. Lohrmann & V. Blobel) Optimization Problem Set of n independent variables Sometimes in addition some constraints
Modern Methods of Data Analysis Lecture XV (04.02.08) Contents: Function Minimization (see E. Lohrmann & V. Blobel) Optimization Problem Set of n independent variables Sometimes in addition some constraints
Introduction to Optimization
 Introduction to Optimization Second Order Optimization Methods Marc Toussaint U Stuttgart Planned Outline Gradient-based optimization (1st order methods) plain grad., steepest descent, conjugate grad.,
Introduction to Optimization Second Order Optimization Methods Marc Toussaint U Stuttgart Planned Outline Gradient-based optimization (1st order methods) plain grad., steepest descent, conjugate grad.,
Data Mining Chapter 8: Search and Optimization Methods Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 8: Search and Optimization Methods Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Search & Optimization Search and Optimization method deals with
Data Mining Chapter 8: Search and Optimization Methods Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Search & Optimization Search and Optimization method deals with
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
Announcements: projects
 Announcements: projects 805 students: Project proposals are due Sun 10/1. If you d like to work with 605 students then indicate this on your proposal. 605 students: the week after 10/1 I will post the
Announcements: projects 805 students: Project proposals are due Sun 10/1. If you d like to work with 605 students then indicate this on your proposal. 605 students: the week after 10/1 I will post the
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions
 SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
CPSC 340: Machine Learning and Data Mining. Multi-Class Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
Introduction to optimization methods and line search
 Introduction to optimization methods and line search Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi How to find optimal solutions? Trial and error widely used in practice, not efficient and
Introduction to optimization methods and line search Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi How to find optimal solutions? Trial and error widely used in practice, not efficient and
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Linear Regression Optimization
 Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models
 Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
How Learning Differs from Optimization. Sargur N. Srihari
 How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
Efficient Tuning of SVM Hyperparameters Using Radius/Margin Bound and Iterative Algorithms
 IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 13, NO. 5, SEPTEMBER 2002 1225 Efficient Tuning of SVM Hyperparameters Using Radius/Margin Bound and Iterative Algorithms S. Sathiya Keerthi Abstract This paper
IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 13, NO. 5, SEPTEMBER 2002 1225 Efficient Tuning of SVM Hyperparameters Using Radius/Margin Bound and Iterative Algorithms S. Sathiya Keerthi Abstract This paper
Constrained and Unconstrained Optimization
 Constrained and Unconstrained Optimization Carlos Hurtado Department of Economics University of Illinois at Urbana-Champaign hrtdmrt2@illinois.edu Oct 10th, 2017 C. Hurtado (UIUC - Economics) Numerical
Constrained and Unconstrained Optimization Carlos Hurtado Department of Economics University of Illinois at Urbana-Champaign hrtdmrt2@illinois.edu Oct 10th, 2017 C. Hurtado (UIUC - Economics) Numerical
Machine Learning: Think Big and Parallel
 Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Gradient Descent. Michail Michailidis & Patrick Maiden
 Gradient Descent Michail Michailidis & Patrick Maiden Outline Mo4va4on Gradient Descent Algorithm Issues & Alterna4ves Stochas4c Gradient Descent Parallel Gradient Descent HOGWILD! Mo4va4on It is good
Gradient Descent Michail Michailidis & Patrick Maiden Outline Mo4va4on Gradient Descent Algorithm Issues & Alterna4ves Stochas4c Gradient Descent Parallel Gradient Descent HOGWILD! Mo4va4on It is good
Today. Golden section, discussion of error Newton s method. Newton s method, steepest descent, conjugate gradient
 Optimization Last time Root finding: definition, motivation Algorithms: Bisection, false position, secant, Newton-Raphson Convergence & tradeoffs Example applications of Newton s method Root finding in
Optimization Last time Root finding: definition, motivation Algorithms: Bisection, false position, secant, Newton-Raphson Convergence & tradeoffs Example applications of Newton s method Root finding in
Experimental Data and Training
 Modeling and Control of Dynamic Systems Experimental Data and Training Mihkel Pajusalu Alo Peets Tartu, 2008 1 Overview Experimental data Designing input signal Preparing data for modeling Training Criterion
Modeling and Control of Dynamic Systems Experimental Data and Training Mihkel Pajusalu Alo Peets Tartu, 2008 1 Overview Experimental data Designing input signal Preparing data for modeling Training Criterion
Module 1 Lecture Notes 2. Optimization Problem and Model Formulation
 Optimization Methods: Introduction and Basic concepts 1 Module 1 Lecture Notes 2 Optimization Problem and Model Formulation Introduction In the previous lecture we studied the evolution of optimization
Optimization Methods: Introduction and Basic concepts 1 Module 1 Lecture Notes 2 Optimization Problem and Model Formulation Introduction In the previous lecture we studied the evolution of optimization
Solution 1 (python) Performance: Enron Samples Rate Recall Precision Total Contribution
 Performance: Enron Samples Rate Recall Precision Total Contribution") Summary Each of the ham/spam classifiers has been tested against random samples from pre- processed enron sets 1 through 6 obtained via: http://www.aueb.gr/users/ion/data/enron- spam/, or the entire set
Summary Each of the ham/spam classifiers has been tested against random samples from pre- processed enron sets 1 through 6 obtained via: http://www.aueb.gr/users/ion/data/enron- spam/, or the entire set
Computational Machine Learning, Fall 2015 Homework 4: stochastic gradient algorithms
 Computational Machine Learning, Fall 2015 Homework 4: stochastic gradient algorithms Due: Tuesday, November 24th, 2015, before 11:59pm (submit via email) Preparation: install the software packages and
Computational Machine Learning, Fall 2015 Homework 4: stochastic gradient algorithms Due: Tuesday, November 24th, 2015, before 11:59pm (submit via email) Preparation: install the software packages and
Convex Optimization MLSS 2015
 Convex Optimization MLSS 2015 Constantine Caramanis The University of Texas at Austin The Optimization Problem minimize : f (x) subject to : x X. The Optimization Problem minimize : f (x) subject to :
Convex Optimization MLSS 2015 Constantine Caramanis The University of Texas at Austin The Optimization Problem minimize : f (x) subject to : x X. The Optimization Problem minimize : f (x) subject to :
Linear Regression and K-Nearest Neighbors 3/28/18
 Linear Regression and K-Nearest Neighbors 3/28/18 Linear Regression Hypothesis Space Supervised learning For every input in the data set, we know the output Regression Outputs are continuous A number,
Linear Regression and K-Nearest Neighbors 3/28/18 Linear Regression Hypothesis Space Supervised learning For every input in the data set, we know the output Regression Outputs are continuous A number,
Regularization and model selection
 CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
HMC CS 158, Fall 2017 Problem Set 3 Programming: Regularized Polynomial Regression
 HMC CS 158, Fall 2017 Problem Set 3 Programming: Regularized Polynomial Regression Goals: To open up the black-box of scikit-learn and implement regression models. To investigate how adding polynomial
HMC CS 158, Fall 2017 Problem Set 3 Programming: Regularized Polynomial Regression Goals: To open up the black-box of scikit-learn and implement regression models. To investigate how adding polynomial
Case Study 1: Estimating Click Probabilities
 Case Study 1: Estimating Click Probabilities SGD cont d AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade March 31, 2015 1 Support/Resources Office Hours Yao Lu:
Case Study 1: Estimating Click Probabilities SGD cont d AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade March 31, 2015 1 Support/Resources Office Hours Yao Lu:
Machine Learning. Topic 5: Linear Discriminants. Bryan Pardo, EECS 349 Machine Learning, 2013
 Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Image Registration Lecture 4: First Examples
 Image Registration Lecture 4: First Examples Prof. Charlene Tsai Outline Example Intensity-based registration SSD error function Image mapping Function minimization: Gradient descent Derivative calculation
Image Registration Lecture 4: First Examples Prof. Charlene Tsai Outline Example Intensity-based registration SSD error function Image mapping Function minimization: Gradient descent Derivative calculation
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Combine the PA Algorithm with a Proximal Classifier
 Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU
Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
9.1. K-means Clustering
 424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
Perceptron Introduction to Machine Learning. Matt Gormley Lecture 5 Jan. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions
 (INTRODUCTION TO MACHINE LEARNING) SS16. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions") COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Regression
COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Regression
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Learning via Optimization
 Lecture 7 1 Outline 1. Optimization Convexity 2. Linear regression in depth Locally weighted linear regression 3. Brief dips Logistic Regression [Stochastic] gradient ascent/descent Support Vector Machines
Lecture 7 1 Outline 1. Optimization Convexity 2. Linear regression in depth Locally weighted linear regression 3. Brief dips Logistic Regression [Stochastic] gradient ascent/descent Support Vector Machines
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Natural Language Processing
 Natural Language Processing Classification III Dan Klein UC Berkeley 1 Classification 2 Linear Models: Perceptron The perceptron algorithm Iteratively processes the training set, reacting to training errors
Natural Language Processing Classification III Dan Klein UC Berkeley 1 Classification 2 Linear Models: Perceptron The perceptron algorithm Iteratively processes the training set, reacting to training errors
Evaluation. Evaluate what? For really large amounts of data... A: Use a validation set.
 Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
More on Neural Networks. Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.
 More on Neural Networks Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.6 Recall the MLP Training Example From Last Lecture log likelihood
More on Neural Networks Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.6 Recall the MLP Training Example From Last Lecture log likelihood
Contents. I Basics 1. Copyright by SIAM. Unauthorized reproduction of this article is prohibited.
 page v Preface xiii I Basics 1 1 Optimization Models 3 1.1 Introduction... 3 1.2 Optimization: An Informal Introduction... 4 1.3 Linear Equations... 7 1.4 Linear Optimization... 10 Exercises... 12 1.5
page v Preface xiii I Basics 1 1 Optimization Models 3 1.1 Introduction... 3 1.2 Optimization: An Informal Introduction... 4 1.3 Linear Equations... 7 1.4 Linear Optimization... 10 Exercises... 12 1.5
Bayesian Methods in Vision: MAP Estimation, MRFs, Optimization
 Bayesian Methods in Vision: MAP Estimation, MRFs, Optimization CS 650: Computer Vision Bryan S. Morse Optimization Approaches to Vision / Image Processing Recurring theme: Cast vision problem as an optimization
Bayesian Methods in Vision: MAP Estimation, MRFs, Optimization CS 650: Computer Vision Bryan S. Morse Optimization Approaches to Vision / Image Processing Recurring theme: Cast vision problem as an optimization
Frameworks in Python for Numeric Computation / ML
 Frameworks in Python for Numeric Computation / ML Why use a framework? Why not use the built-in data structures? Why not write our own matrix multiplication function? Frameworks are needed not only because
Frameworks in Python for Numeric Computation / ML Why use a framework? Why not use the built-in data structures? Why not write our own matrix multiplication function? Frameworks are needed not only because
Memory Bandwidth and Low Precision Computation. CS6787 Lecture 9 Fall 2017
 Memory Bandwidth and Low Precision Computation CS6787 Lecture 9 Fall 2017 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Memory Bandwidth and Low Precision Computation CS6787 Lecture 9 Fall 2017 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Classical Gradient Methods
 Classical Gradient Methods Note simultaneous course at AMSI (math) summer school: Nonlin. Optimization Methods (see http://wwwmaths.anu.edu.au/events/amsiss05/) Recommended textbook (Springer Verlag, 1999):
Classical Gradient Methods Note simultaneous course at AMSI (math) summer school: Nonlin. Optimization Methods (see http://wwwmaths.anu.edu.au/events/amsiss05/) Recommended textbook (Springer Verlag, 1999):
6.034 Quiz 2, Spring 2005
 6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
Newton and Quasi-Newton Methods
 Lab 17 Newton and Quasi-Newton Methods Lab Objective: Newton s method is generally useful because of its fast convergence properties. However, Newton s method requires the explicit calculation of the second
Lab 17 Newton and Quasi-Newton Methods Lab Objective: Newton s method is generally useful because of its fast convergence properties. However, Newton s method requires the explicit calculation of the second
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
ActiveClean: Interactive Data Cleaning For Statistical Modeling. Safkat Islam Carolyn Zhang CS 590
 ActiveClean: Interactive Data Cleaning For Statistical Modeling Safkat Islam Carolyn Zhang CS 590 Outline Biggest Takeaways, Strengths, and Weaknesses Background System Architecture Updating the Model
ActiveClean: Interactive Data Cleaning For Statistical Modeling Safkat Islam Carolyn Zhang CS 590 Outline Biggest Takeaways, Strengths, and Weaknesses Background System Architecture Updating the Model
3 Types of Gradient Descent Algorithms for Small & Large Data Sets
 3 Types of Gradient Descent Algorithms for Small & Large Data Sets Introduction Gradient Descent Algorithm (GD) is an iterative algorithm to find a Global Minimum of an objective function (cost function)
3 Types of Gradient Descent Algorithms for Small & Large Data Sets Introduction Gradient Descent Algorithm (GD) is an iterative algorithm to find a Global Minimum of an objective function (cost function)
06: Logistic Regression
 06_Logistic_Regression 06: Logistic Regression Previous Next Index Classification Where y is a discrete value Develop the logistic regression algorithm to determine what class a new input should fall into
06_Logistic_Regression 06: Logistic Regression Previous Next Index Classification Where y is a discrete value Develop the logistic regression algorithm to determine what class a new input should fall into
CPSC 340: Machine Learning and Data Mining. Kernel Trick Fall 2017
 CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
Lecture 13. Deep Belief Networks. Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen
 Lecture 13 Deep Belief Networks Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen IBM T.J. Watson Research Center Yorktown Heights, New York, USA {picheny,bhuvana,stanchen}@us.ibm.com 12 December 2012
Lecture 13 Deep Belief Networks Michael Picheny, Bhuvana Ramabhadran, Stanley F. Chen IBM T.J. Watson Research Center Yorktown Heights, New York, USA {picheny,bhuvana,stanchen}@us.ibm.com 12 December 2012
Machine Learning Basics. Sargur N. Srihari
 Machine Learning Basics Sargur N. srihari@cedar.buffalo.edu 1 Overview Deep learning is a specific type of ML Necessary to have a solid understanding of the basic principles of ML 2 Topics Stochastic Gradient
Machine Learning Basics Sargur N. srihari@cedar.buffalo.edu 1 Overview Deep learning is a specific type of ML Necessary to have a solid understanding of the basic principles of ML 2 Topics Stochastic Gradient
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Numerical Optimization: Introduction and gradient-based methods
 Numerical Optimization: Introduction and gradient-based methods Master 2 Recherche LRI Apprentissage Statistique et Optimisation Anne Auger Inria Saclay-Ile-de-France November 2011 http://tao.lri.fr/tiki-index.php?page=courses
Numerical Optimization: Introduction and gradient-based methods Master 2 Recherche LRI Apprentissage Statistique et Optimisation Anne Auger Inria Saclay-Ile-de-France November 2011 http://tao.lri.fr/tiki-index.php?page=courses
Solving for dynamic user equilibrium
 Solving for dynamic user equilibrium CE 392D Overall DTA problem 1. Calculate route travel times 2. Find shortest paths 3. Adjust route choices toward equilibrium We can envision each of these steps as
Solving for dynamic user equilibrium CE 392D Overall DTA problem 1. Calculate route travel times 2. Find shortest paths 3. Adjust route choices toward equilibrium We can envision each of these steps as
Lecture 1 Notes. Outline. Machine Learning. What is it? Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 1 Notes Outline 1. Machine Learning What is it? Classification vs. Regression Error Training Error vs. Test Error 2. Linear Classifiers Goals and Motivations
Instructors: Parth Shah, Riju Pahwa Lecture 1 Notes Outline 1. Machine Learning What is it? Classification vs. Regression Error Training Error vs. Test Error 2. Linear Classifiers Goals and Motivations
3 Perceptron Learning; Maximum Margin Classifiers
 Perceptron Learning; Maximum Margin lassifiers Perceptron Learning; Maximum Margin lassifiers Perceptron Algorithm (cont d) Recall: linear decision fn f (x) = w x (for simplicity, no ) decision boundary
Perceptron Learning; Maximum Margin lassifiers Perceptron Learning; Maximum Margin lassifiers Perceptron Algorithm (cont d) Recall: linear decision fn f (x) = w x (for simplicity, no ) decision boundary
Memory Bandwidth and Low Precision Computation. CS6787 Lecture 10 Fall 2018
 Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
CSE 546 Machine Learning, Autumn 2013 Homework 2
 CSE 546 Machine Learning, Autumn 2013 Homework 2 Due: Monday, October 28, beginning of class 1 Boosting [30 Points] We learned about boosting in lecture and the topic is covered in Murphy 16.4. On page
CSE 546 Machine Learning, Autumn 2013 Homework 2 Due: Monday, October 28, beginning of class 1 Boosting [30 Points] We learned about boosting in lecture and the topic is covered in Murphy 16.4. On page
10.4 Linear interpolation method Newton s method
 10.4 Linear interpolation method The next best thing one can do is the linear interpolation method, also known as the double false position method. This method works similarly to the bisection method by
10.4 Linear interpolation method The next best thing one can do is the linear interpolation method, also known as the double false position method. This method works similarly to the bisection method by
Class 6 Large-Scale Image Classification
 Class 6 Large-Scale Image Classification Liangliang Cao, March 7, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual
Class 6 Large-Scale Image Classification Liangliang Cao, March 7, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual
CPSC 340: Machine Learning and Data Mining. Feature Selection Fall 2016
 CPSC 34: Machine Learning and Data Mining Feature Selection Fall 26 Assignment 3: Admin Solutions will be posted after class Wednesday. Extra office hours Thursday: :3-2 and 4:3-6 in X836. Midterm Friday:
CPSC 34: Machine Learning and Data Mining Feature Selection Fall 26 Assignment 3: Admin Solutions will be posted after class Wednesday. Extra office hours Thursday: :3-2 and 4:3-6 in X836. Midterm Friday:
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent
 Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2017
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
ECE 285 Final Project
 ECE 285 Final Project Michael Threet mthreet@ucsd.edu Chenyin Liu chl586@ucsd.edu Rui Guo rug009@eng.ucsd.edu Abstract Source localization allows for range finding in underwater acoustics. Traditionally,
ECE 285 Final Project Michael Threet mthreet@ucsd.edu Chenyin Liu chl586@ucsd.edu Rui Guo rug009@eng.ucsd.edu Abstract Source localization allows for range finding in underwater acoustics. Traditionally,
Constrained Optimization COS 323
 Constrained Optimization COS 323 Last time Introduction to optimization objective function, variables, [constraints] 1-dimensional methods Golden section, discussion of error Newton s method Multi-dimensional
Constrained Optimization COS 323 Last time Introduction to optimization objective function, variables, [constraints] 1-dimensional methods Golden section, discussion of error Newton s method Multi-dimensional
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
LECTURE NOTES Non-Linear Programming
 CEE 6110 David Rosenberg p. 1 Learning Objectives LECTURE NOTES Non-Linear Programming 1. Write out the non-linear model formulation 2. Describe the difficulties of solving a non-linear programming model
CEE 6110 David Rosenberg p. 1 Learning Objectives LECTURE NOTES Non-Linear Programming 1. Write out the non-linear model formulation 2. Describe the difficulties of solving a non-linear programming model
Recap Hill Climbing Randomized Algorithms SLS for CSPs. Local Search. CPSC 322 Lecture 12. January 30, 2006 Textbook 3.8
 Local Search CPSC 322 Lecture 12 January 30, 2006 Textbook 3.8 Local Search CPSC 322 Lecture 12, Slide 1 Lecture Overview Recap Hill Climbing Randomized Algorithms SLS for CSPs Local Search CPSC 322 Lecture
Local Search CPSC 322 Lecture 12 January 30, 2006 Textbook 3.8 Local Search CPSC 322 Lecture 12, Slide 1 Lecture Overview Recap Hill Climbing Randomized Algorithms SLS for CSPs Local Search CPSC 322 Lecture
Optimization for Machine Learning
 with a focus on proximal gradient descent algorithm Department of Computer Science and Engineering Outline 1 History & Trends 2 Proximal Gradient Descent 3 Three Applications A Brief History A. Convex
with a focus on proximal gradient descent algorithm Department of Computer Science and Engineering Outline 1 History & Trends 2 Proximal Gradient Descent 3 Three Applications A Brief History A. Convex