BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler, Sanjay Ranka
|
|
|
- Shanon Lindsay Maxwell
- 5 years ago
- Views:
Transcription
1 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler, Sanjay Ranka
2 Topics What is data? Definitions, terminology Types of data and datasets Data preprocessing Data Cleaning Data integration Data transformation Data reduction Data similarity
3 10 What is Data? Collection of data objects and their attributes An attribute is a property or characteristic of an object Examples: eye color of a person, temperature, etc. Attribute is also known as variable, field, characteristic, or feature A collection of attributes describe an object Object is also known as record, point, case, sample, entity, or instance Objects Attributes Tid Refund Marital Status Taxable Income 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No Cheat 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes
4 Types of Attributes Nominal Examples: ID numbers, eye color, zip codes Ordinal Examples: rankings (e.g., taste of potato chips on a scale from 1-10), grades, height in {tall, medium, short} Binary E.g., medical test (positive vs. negative) Interval Examples: calendar dates, temperatures in Celsius or Fahrenheit. Ratio Examples: temperature in Kelvin, length, time, counts
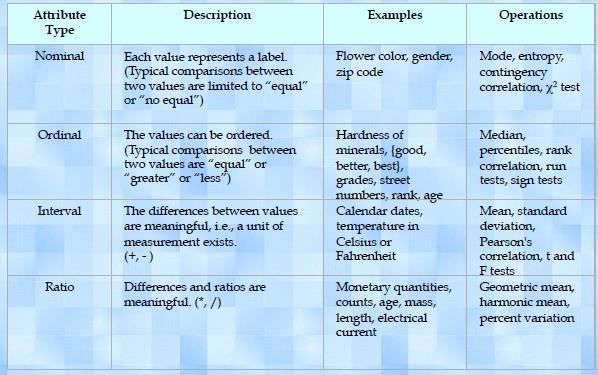
5 Types of attributes

6 Transformations for different types
7 Discrete and Continuous Attributes Discrete attributes A discrete attribute has only a finite or countably infinite set of values. Eg. Zip codes, counts, or the set of words in a document Discrete attributes are often represented as integer variables Binary attributes are a special case of discrete attributes and assume only two values E.g. Yes/no, true/false, male/female Binary attributes are often represented as Boolean variables, or as integer variables that take on the values 0 or 1 Continuous attributes A continuous attribute has real number values. E.g. Temperature, height or weight (Practically real values can only be measured and represented to a finite number of digits) Continuous attributes are typically represented as floating point variables
8 10 Types of data Record Data Matrix Document Data Transaction Data Graph World Wide Web Molecular Structures Ordered Spatial Data Temporal Data Sequential Data Genetic Sequence Data Tid Refund Marital Status Taxable Income 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No Cheat 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes

9 Record data

10 Data matrix

11 Document data

12 Transaction Data

13 Graph data
14 Ordered Data: Transaction Data (AB) (D) (CE) (BD) (C) (E) (CD) (B) (AE)

15 Ordered Data: Genomic Sequence Data

16 Ordered Data: Spatio-temporal Data
17 Data Quality The following are some well known issues Noise and outliers Missing values Duplicate data Inconsistent values
18 Noise and Outliers Noise Modification of original value Outliers random non-random (artifact of measurement) Noise can be temporal spatial Signal processing can reduce (generally not eliminate) noise Small number of points with characteristics different from rest of the data
19 Data Quality: Why Preprocess the Data? Measures for data quality: A multidimensional view Accuracy: correct or wrong, accurate or not Completeness: not recorded, unavailable, Consistency: some modified but some not, dangling, Timeliness: timely update? Believability: how trustable the data are correct? Interpretability: how easily the data can be understood?
20 Major Tasks in Data Preprocessing Data cleaning Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies Data integration Integration of multiple databases, data cubes, or files Data transformation Normalization and aggregation Data reduction Obtains reduced representation in volume but produces the same or similar analytical results Data discretization Part of data reduction but with particular importance, especially for numerical data
21 Data Cleaning: Data in the Real World Is Dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation= (missing data) noisy: containing noise, errors, or outliers e.g., Salary= 10 (an error) inconsistent: containing discrepancies in codes or names, e.g., Age= 42 Birthday= 03/07/2010 Was rating 1,2,3, now rating A, B, C discrepancy between duplicate records Intentional (e.g., disguised missing data) Jan. 1 as everyone s birthday?
22 How to Handle Missing Data? Ignore the tuple: usually done when class label is missing (when doing classification) not effective when the % of missing values per attribute varies considerably Fill in the missing value manually: tedious + infeasible? Fill in it automatically with a global constant : e.g., unknown, a new class?! the attribute mean the attribute mean for all samples belonging to the same class: smarter the most probable value: inference-based such as Bayesian formula or decision tree
23 Missing Values: A simple and effective strategy is to eliminate those records which have missing values. A related strategy is to eliminate attribute that have missing values Drawback: you may end up removing a large number of objects
24 Missing Values: Estimating Them Price of the IBM stock changes in a reasonably smooth fashion. The missing values can be estimated by Interpolation For a data set that has many similar data points, a nearest neighbor approach can be used to estimate the missing value. If the attribute is continuous, then the average attribute value of the nearest neighbors can be used. While if the attribute is categorical, then the most commonly occurring attribute value can be taken
25 Missing Values: Using the Missing Value As Another Value Many data mining approaches can be modified to operate by ignoring missing values E.g. Clustering - Similarity between pairs of data objects needs to be calculated. If one or both objects of a pair have missing values for some attributes, then the similarity can be calculated by using only the other attributes.
26 Noisy Data Noise: random error or variance in a measured variable Incorrect attribute values may be due to faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention Other data problems which require data cleaning duplicate records incomplete data inconsistent data 26
27 How to Handle Noisy Data? Binning first sort data and partition into (equal-frequency) bins then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Regression smooth by fitting the data into regression functions Clustering detect and remove outliers Combined computer and human inspection detect suspicious values and check by human (e.g., deal with possible outliers)
28 Simple Discretization Methods: Binning Equal-width (distance) partitioning: Divides the range into N intervals of equal size: uniform grid if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B A)/N. The most straightforward, but outliers may dominate presentation Skewed data is not handled well. Equal-depth (frequency) partitioning: Divides the range into N intervals, each containing approximately same number of samples Good data scaling Managing categorical attributes can be tricky.
29 Binning Methods for Data Smoothing Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 Partition into (equi-depth) bins: Bin 1: 4, 8, 9, 15 Bin 2: 21, 21, 24, 25 Bin 3: 26, 28, 29, 34 Smoothing by bin means: Bin 1: 9, 9, 9, 9 Bin 2: 23, 23, 23, 23 Bin 3: 29, 29, 29, 29 Smoothing by bin boundaries: Bin 1: 4, 4, 4, 15 Bin 2: 21, 21, 25, 25 Bin 3: 26, 26, 26, 34
30 Outlier Removal Data points inconsistent with the majority of data Different outliers Valid: CEO s salary, Noisy: One s age = 200, widely deviated points Removal methods Clustering Curve-fitting Hypothesis-testing with a given model
31 Cluster Analysis
32 Regression y Y1 Y1 y = x + 1 X1 x
33 Data Integration Data integration: Combines data from multiple sources into a coherent store Schema integration: e.g., A.cust-id B.cust-# Integrate metadata from different sources Entity identification problem: Identify real world entities from multiple data sources, e.g., Bill Clinton = William Clinton Detecting and resolving data value conflicts For the same real world entity, attribute values from different sources are different Possible reasons: different representations, different scales, e.g., metric vs. British units
34 Handling Redundancy in Data Integration Redundant data occur often when integration of multiple databases Object identification: The same attribute or object may have different names in different databases Derivable data: One attribute may be a derived attribute in another table, e.g., annual revenue Redundant attributes may be able to be detected by correlation analysis Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality
35 Visually Evaluating Correlation Scatter plots showing the similarity from 1 to 1.
36 Data Transformation Methods Aggregation: Summarization Sampling Attribute selection Normalization: Scaled to fall within a small, specified range Attribute/feature construction New attributes constructed from the given ones
37 Aggregation Combining two or more attributes (or objects) into a single attribute (or object) For example, merging daily sales figures to obtain monthly sales figures Purpose Data reduction Reduce the number of attributes or objects Change of scale Cities aggregated into regions, states, countries, etc More stable data Aggregated data tends to have less variability
38 Aggregation Behavior of group of objects in more stable than that of individual objects The aggregate quantities have less variability than the individual objects being aggregated Variation of Precipitation in Australia Standard Deviation of Average Monthly Precipitation Standard Deviation of Average Yearly Precipitation
39 Sampling Sampling is the main technique employed for data selection. It is often used for both the preliminary investigation of the data and the final data analysis. Statisticians sample because obtaining the entire set of data of interest is too expensive or time consuming. Sampling is used in data mining because processing the entire set of data of interest is too expensive or time consuming.
40 Sampling The key principle for effective sampling is the following: using a sample will work almost as well as using the entire data sets, if the sample is representative A sample is representative if it has approximately the same property (of interest) as the original set of data
41 Types of Sampling Simple Random Sampling There is an equal probability of selecting any particular item Sampling without replacement As each item is selected, it is removed from the population Sampling with replacement Objects are not removed from the population as they are selected for the sample. In sampling with replacement, the same object can be picked up more than once Stratified sampling Split the data into several partitions; then draw random samples from each partition
42 Sampling Stratified Sampling When subpopulations vary considerably, it is advantageous to sample each subpopulation (stratum) independently Stratification is the process of grouping members of the population into relatively homogeneous subgroups before sampling The strata should be mutually exclusive : every element in the population must be assigned to only one stratum. The strata should also be collectively exhaustive : no population element can be excluded Then random sampling is applied within each stratum. This often improves the representative-ness of the sample by reducing sampling error

43 Sample size Even if proper sampling technique is known, it is important to choose proper sample size Larger sample sizes increase the probability that a sample will be representative, but also eliminate much of the advantage of sampling With smaller sample size, patterns may be missed or erroneous patters detected 8000 points 2000 Points 500 Points
44 Feature Creation Sometimes, a small number of new attributes can capture the important information in a data set much more efficiently than the original attributes Also, the number of new attributes can be often smaller than the number of original attributes. Hence, we get benefits of dimensionality reduction Three general methodologies: Feature Extraction Mapping the Data to a New Space Feature Construction
45 Feature extraction One approach to dimensionality reduction is feature extraction, which is creation of a new, smaller set of features from the original set of features For example, consider a set of photographs, where each photograph is to be classified whether its human face or not The raw data is set of pixels, and as such is not suitable for many classification algorithms However, if data is processed to provide high-level features like presence or absence of certain types of edges or areas correlated with presence of human faces, then a broader set of classification techniques can be applied to the problem


46 Mapping Data to a New Space Sometimes, a totally different view of the data can reveal important and interesting features Example: Applying Fourier transformation to data to detect time series patterns Two Sine Waves Two Sine Waves + Noise Frequency
47 Feature Construction Sometimes features have the necessary information, but not in the form necessary for the data mining algorithm. In this case, one or more new features constructed out of the original features may be useful Example, there are two attributes that record volume and mass of a set of objects Suppose there exists a classification model based on material of which the objects are constructed Then a density feature constructed from the original two features would help classification
48 Discretization and Binarization Discretization is the process of converting a continuous attribute to a discrete attribute A common example is rounding off real numbers to integers Some data mining algorithms require that the data be in the form of categorical or binary attributes. Thus, it is often necessary to convert continuous attributes in to categorical attributes and / or binary attributes Its pretty straightforward to convert categorical attributes in to discrete or binary attributes
49 Discretization of Continuous Attributes Transformation of continuous attributes to a categorical attributes involves Deciding how many categories to have How to map the values of the continuous attribute to categorical attribute A basic distinction between discretization methods for classification is whether class information is used (supervised) or not (unsupervised)
50 Data Discretization Methods Discretization: Divide the range of a continuous attribute into intervals Typical methods: All the methods can be applied recursively Binning Top-down split, unsupervised Histogram analysis Top-down split, unsupervised Clustering analysis (unsupervised, top-down split or bottom-up merge) Decision-tree analysis (supervised, top-down split) Correlation (e.g., 2 ) analysis (unsupervised, bottom-up merge) 50
51 Discretization Without Using Class Labels Data Equal interval width Equal frequency K-means
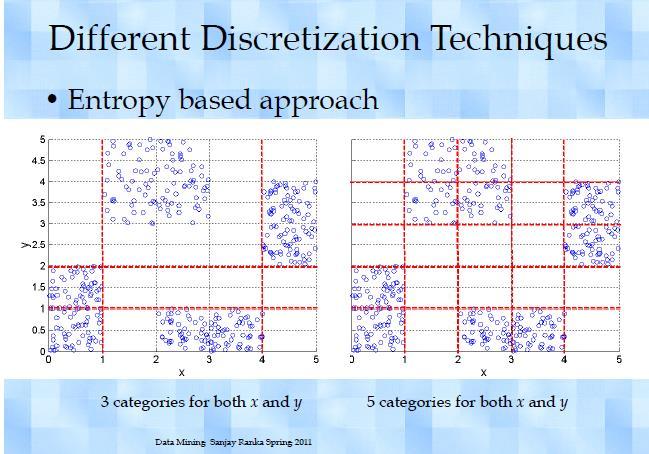
52
53 Discretization by Classification & Correlation Analysis Classification (e.g., decision tree analysis) Supervised: Given class labels, e.g., cancerous vs. benign Using entropy to determine split point (discretization point) Top-down, recursive split Details to be covered in Chapter Classification Correlation analysis (e.g., Chi-merge: χ 2 -based discretization) Supervised: use class information Bottom-up merge: find the best neighboring intervals (those having similar distributions of classes, i.e., low χ 2 values) to merge Merge performed recursively, until a predefined stopping condition 53
54 Attribute Transformation A function that maps the entire set of values of a given attribute to a new set of replacement values such that each old value can be identified with one of the new values Simple functions: x k, log(x), e x, x Standardization and Normalization
55 Normalization Min-max normalization: to [new_min A, new_max A ] v ' v mina maxa min Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0]. Then $73,000 is mapped to Z-score normalization (μ: mean, σ: standard deviation): v' A A Ex. Let μ = 54,000, σ = 16,000. Then Normalization by decimal scaling v A ( new_ max A new_ mina) new_ min 73,600 12,000 (1.0 0) ,000 12,000 73,600 54, ,000 v v' Where j is the smallest integer such that Max( ν ) < 1 j 10 A
56 Topics What is data? Definitions, terminology Types of data and datasets Data preprocessing Data cleaning Data integration Data transformation Data reduction Data similarity
57 Curse of Dimensionality When dimensionality increases, data becomes increasingly sparse in the space that it occupies Definitions of density and distance between points, which is critical for clustering and outlier detection, become less meaningful Randomly generate 500 points Compute difference between max and min distance between any pair of points
58 Dimensionality Reduction Determining dimensions (or combinations of dimensions) that are important for modeling Why dimensionality reduction? Many data mining algorithms work better if the dimensionality of data (i.e. number of attributes) is lower Allows the data to be more easily visualized If dimensionality reduction eliminates irrelevant features or reduces noise, then quality of results may improve Can lead to a more understandable model
59 Dimensionality Reduction Redundant features duplicate much or all of the information contained in one or more attributes The purchase price of product and the sales tax paid contain the same information Irrelevant features contain no information that is useful for data mining task at hand Student ID numbers would be irrelevant to the task of predicting their GPA
60 Dimensionality Reduction Purpose: Avoid curse of dimensionality Reduce amount of time and memory required by data mining algorithms Allow data to be more easily visualized May help to eliminate irrelevant features or reduce noise Techniques Principle Component Analysis Singular Value Decomposition Others: supervised and non-linear techniques
61 Dimensionality Reduction: PCA Goal is to find a projection that captures the largest amount of variation in data x 2 e x 1
62 Dimensionality Reduction: PCA Find the eigenvectors of the covariance matrix The eigenvectors define the new space x 2 e x 1
63 Principal Component Analysis (Steps) Given N data vectors from n-dimensions, find k n orthogonal vectors (principal components) that can be best used to represent data Normalize input data: Each attribute falls within the same range Compute k orthonormal (unit) vectors, i.e., principal components Each input data (vector) is a linear combination of the k principal component vectors The principal components are sorted in order of decreasing significance or strength Since the components are sorted, the size of the data can be reduced by eliminating the weak components, i.e., those with low variance (i.e., using the strongest principal components, it is possible to reconstruct a good approximation of the original data) Works for numeric data only
64 PCA Algorithm PCA algorithm: 1. X Create N x d data matrix, with one row vector x n per data point 2. X subtract mean x from each row vector x n in X 3. Σ covariance matrix of X Find eigenvectors and eigenvalues of Σ PC s the M eigenvectors with largest eigenvalues
65 PCA Algorithm in Matlab % generate data Data = mvnrnd([5, 5],[1 1.5; 1.5 3], 100); figure(1); plot(data(:,1), Data(:,2), '+'); %center the data for i = 1:size(Data,1) Data(i, :) = Data(i, :) - mean(data); end DataCov = cov(data); %covariance matrix [PC, variances, explained] = pcacov(datacov); %eigen % plot principal components figure(2); clf; hold on; plot(data(:,1), Data(:,2), '+b'); plot(pc(1,1)*[-5 5], PC(2,1)*[-5 5], '-r ) plot(pc(1,2)*[-5 5], PC(2,2)*[-5 5], '-b ); hold off % project down to 1 dimension PcaPos = Data * PC(:, 1);
66 2d Data
67 Principal Components 5 1 st principal vector 4 Gives best axis to project Principal vectors are orthogonal nd principal vector
68 How many components? Check the distribution of eigen-values Take enough many eigen-vectors to cover 80-90% of the variance
69 Problems and limitations What if very large dimensional data? e.g., Images (d 10 4 ) Problem: Covariance matrix Σ is size (d 2 ) d=10 4 Σ = 10 8 Singular Value Decomposition (SVD)! efficient algorithms available (Matlab) some implementations find just top N eigenvectors
70 Numerosity Reduction Parametric methods Assume the data fits some model, estimate model parameters, store only the parameters, and discard the data (except possible outliers) Log-linear models: obtain value at a point in m-d space as the product on appropriate marginal subspaces Non-parametric methods Do not assume models Major families: histograms, clustering, sampling
71 Histograms A popular data reduction technique Divide data into buckets and store average (sum) for each bucket Can be constructed optimally in one dimension using dynamic programming Related to quantization problems
72 Clustering Partition data set into clusters, and one can store cluster representation only Can be very effective if data is clustered Can have hierarchical clustering and be stored in multi-dimensional index tree structures There are many choices of clustering definitions and clustering algorithms, further will be discussed
73 Feature Subset Selection Another way to reduce dimensionality of data Redundant features duplicate much or all of the information contained in one or more other attributes Irrelevant features contain no information that is useful for the data mining task at hand
74 Feature Subset Selection Techniques: Brute-force approch: Try all possible feature subsets as input to data mining algorithm Embedded approaches: Feature selection occurs naturally as part of the data mining algorithm Filter approaches: Features are selected before data mining algorithm is run Wrapper approaches: Use the data mining algorithm as a black box to find best subset of attributes
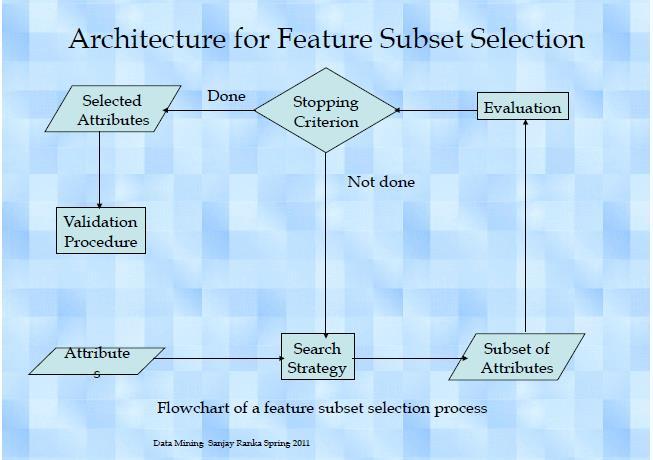
75
76 Topics What is data? Definitions, terminology Types of data and datasets Data preprocessing Data Cleaning Data integration Data transformation Data reduction Data similarity
77 Similarity and Dissimilarity Similarity Numerical measure of how alike two data objects are. Is higher when objects are more alike. Often falls in the range [0,1] Dissimilarity Numerical measure of how different are two data objects Lower when objects are more alike Minimum dissimilarity is often 0 Upper limit varies Proximity refers to a similarity or dissimilarity
78 Similarity/Dissimilarity for Simple Attributes p and q are the attribute values for two data objects.
79 Euclidean Distance Euclidean Distance (L 2 norm) Where n is the number of dimensions (attributes) and p k and q k are, respectively, the k th attributes (components) or data objects p and q. Standardization is necessary, if scales differ. dist n k 1 ( p k q k 2 )
80 Minkowski Distance Minkowski Distance (L p norm) is a generalization of Euclidean Distance Where r is a parameter, n is the number of dimensions (attributes) and p k and q k are, respectively, the kth attributes (components) or data objects p and q. n dist = ( å p k - q k p ) k=1 1 p
81 Minkowski Distance: Examples p = 1. City block (Manhattan, taxicab, L 1 norm) distance. A common example of this is the Hamming distance, which is just the number of bits that are different between two binary vectors p = 2. Euclidean distance p. supremum (L max norm, L norm) distance. This is the maximum difference between any component of the vectors Do not confuse p with n, i.e., all these distances are defined for all numbers of dimensions.
82 Mahalanobis Distance n i k ik j ij k j X X X X n 1, ) )( ( 1 1 T q p q p q p s mahalanobi ) ( ) ( ), ( 1 For red points, the Euclidean distance is 14.7, Mahalanobis distance is 6. is the covariance matrix of the input data X
83 Mahalanobis Distance C Covariance Matrix: B A A: (0.5, 0.5) B: (0, 1) C: (1.5, 1.5) Mahal(A,B) = 5 Mahal(A,C) = 4
84 Similarity Between Binary Vectors Common situation is that objects, p and q, have only binary attributes Compute similarities using the following quantities M 01 = the number of attributes where p was 0 and q was 1 M 10 = the number of attributes where p was 1 and q was 0 M 00 = the number of attributes where p was 0 and q was 0 M 11 = the number of attributes where p was 1 and q was 1 Simple Matching and Jaccard Coefficients SMC = number of matches / number of attributes = (M 11 + M 00 ) / (M 01 + M 10 + M 11 + M 00 ) J = number of 11 matches / number of not-both-zero attributes values = (M 11 ) / (M 01 + M 10 + M 11 )
85 SMC versus Jaccard: Example p = q = M 01 = 2 (the number of attributes where p was 0 and q was 1) M 10 = 1 (the number of attributes where p was 1 and q was 0) M 00 = 7 (the number of attributes where p was 0 and q was 0) M 11 = 0 (the number of attributes where p was 1 and q was 1) SMC = (M 11 + M 00 )/(M 01 + M 10 + M 11 + M 00 ) = (0+7) / ( ) = 0.7 J = (M 11 ) / (M 01 + M 10 + M 11 ) = 0 / ( ) = 0
86 Cosine Similarity If d 1 and d 2 are two document vectors, then cos( d 1, d 2 ) = (d 1 d 2 ) / d 1 d 2, where indicates vector dot product and d is the length of vector d. Example: d 1 = d 2 = d 1 d 2 = 3*1 + 2*0 + 0*0 + 5*0 + 0*0 + 0*0 + 0*0 + 2*1 + 0*0 + 0*2 = 5 d 1 = (3*3+2*2+0*0+5*5+0*0+0*0+0*0+2*2+0*0+0*0) 0.5 = (42) 0.5 = d 2 = (1*1+0*0+0*0+0*0+0*0+0*0+0*0+1*1+0*0+2*2) 0.5 = (6) 0.5 = cos( d 1, d 2 ) =
87 Using Weights to Combine Similarities May not want to treat all attributes the same. Use weights w k which are between 0 and 1 and sum to 1.
88 Summary Data preparation is a big issue for data mining Data preparation includes Data cleaning and data integration Data reduction and feature selection Discretization Many methods have been proposed but still an active area of research Method to choose depends on the nature of the data
Data Mining: Data. What is Data? Lecture Notes for Chapter 2. Introduction to Data Mining. Properties of Attribute Values. Types of Attributes
 0 Data Mining: Data What is Data? Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Collection of data objects and their attributes An attribute is a property or characteristic
0 Data Mining: Data What is Data? Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Collection of data objects and their attributes An attribute is a property or characteristic
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 10 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 What is Data? Collection of data objects
10 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 What is Data? Collection of data objects
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing. Data Preprocessing
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
University of Florida CISE department Gator Engineering. Data Preprocessing. Dr. Sanjay Ranka
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing. Why Data Preprocessing? MIT-652 Data Mining Applications. Chapter 3: Data Preprocessing. Multi-Dimensional Measure of Data Quality
 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Data Preprocessing. S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha
 Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing
 Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
CS 521 Data Mining Techniques Instructor: Abdullah Mueen
 CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
UNIT 2 Data Preprocessing
 UNIT 2 Data Preprocessing Lecture Topic ********************************************** Lecture 13 Why preprocess the data? Lecture 14 Lecture 15 Lecture 16 Lecture 17 Data cleaning Data integration and
UNIT 2 Data Preprocessing Lecture Topic ********************************************** Lecture 13 Why preprocess the data? Lecture 14 Lecture 15 Lecture 16 Lecture 17 Data cleaning Data integration and
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3
 Chapter 3") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Preprocessing Short Lecture Notes cse352. Professor Anita Wasilewska
 Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Data Preprocessing. Data Mining 1
 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size and their likely origin from multiple, heterogenous sources.
Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size and their likely origin from multiple, heterogenous sources.
2. Data Preprocessing
 2. Data Preprocessing Contents of this Chapter 2.1 Introduction 2.2 Data cleaning 2.3 Data integration 2.4 Data transformation 2.5 Data reduction Reference: [Han and Kamber 2006, Chapter 2] SFU, CMPT 459
2. Data Preprocessing Contents of this Chapter 2.1 Introduction 2.2 Data cleaning 2.3 Data integration 2.4 Data transformation 2.5 Data reduction Reference: [Han and Kamber 2006, Chapter 2] SFU, CMPT 459
3. Data Preprocessing. 3.1 Introduction
 3. Data Preprocessing Contents of this Chapter 3.1 Introduction 3.2 Data cleaning 3.3 Data integration 3.4 Data transformation 3.5 Data reduction SFU, CMPT 740, 03-3, Martin Ester 84 3.1 Introduction Motivation
3. Data Preprocessing Contents of this Chapter 3.1 Introduction 3.2 Data cleaning 3.3 Data integration 3.4 Data transformation 3.5 Data reduction SFU, CMPT 740, 03-3, Martin Ester 84 3.1 Introduction Motivation
Data Preprocessing Yudho Giri Sucahyo y, Ph.D , CISA
 Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 02 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 02 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES 2: Data Pre-Processing Instructor: Yizhou Sun yzsun@ccs.neu.edu September 10, 2013 2: Data Pre-Processing Getting to know your data Basic Statistical Descriptions of Data
CS6220: DATA MINING TECHNIQUES 2: Data Pre-Processing Instructor: Yizhou Sun yzsun@ccs.neu.edu September 10, 2013 2: Data Pre-Processing Getting to know your data Basic Statistical Descriptions of Data
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Fall 2013 Reading: Chapter 3 Han, Chapter 2 Tan Anca Doloc-Mihu, Ph.D. Some slides courtesy of Li Xiong, Ph.D. and 2011 Han, Kamber & Pei. Data Mining. Morgan Kaufmann.
CS570: Introduction to Data Mining Fall 2013 Reading: Chapter 3 Han, Chapter 2 Tan Anca Doloc-Mihu, Ph.D. Some slides courtesy of Li Xiong, Ph.D. and 2011 Han, Kamber & Pei. Data Mining. Morgan Kaufmann.
CSE4334/5334 Data Mining 4 Data and Data Preprocessing. Chengkai Li University of Texas at Arlington Fall 2017
 CSE4334/5334 Data Mining 4 Data and Data Preprocessing Chengkai Li University of Texas at Arlington Fall 2017 10 What is Data? Collection of data objects and their attributes Attributes An attribute is
CSE4334/5334 Data Mining 4 Data and Data Preprocessing Chengkai Li University of Texas at Arlington Fall 2017 10 What is Data? Collection of data objects and their attributes Attributes An attribute is
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad
 By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Chapter 2 Data Preprocessing
 Chapter 2 Data Preprocessing CISC4631 1 Outline General data characteristics Data cleaning Data integration and transformation Data reduction Summary CISC4631 2 1 Types of Data Sets Record Relational records
Chapter 2 Data Preprocessing CISC4631 1 Outline General data characteristics Data cleaning Data integration and transformation Data reduction Summary CISC4631 2 1 Types of Data Sets Record Relational records
Jarek Szlichta
 Jarek Szlichta http://data.science.uoit.ca/ Open data Business Data Web Data Available at different formats 2 Data Scientist: The Sexiest Job of the 21 st Century Harvard Business Review Oct. 2012 (c)
Jarek Szlichta http://data.science.uoit.ca/ Open data Business Data Web Data Available at different formats 2 Data Scientist: The Sexiest Job of the 21 st Century Harvard Business Review Oct. 2012 (c)
Data Preprocessing UE 141 Spring 2013
 Data Preprocessing UE 141 Spring 2013 Jing Gao SUNY Buffalo 1 Outline Data Data Preprocessing Improve data quality Prepare data for analysis Exploring Data Statistics Visualization 2 Document Data Each
Data Preprocessing UE 141 Spring 2013 Jing Gao SUNY Buffalo 1 Outline Data Data Preprocessing Improve data quality Prepare data for analysis Exploring Data Statistics Visualization 2 Document Data Each
Data preprocessing Functional Programming and Intelligent Algorithms
 Data preprocessing Functional Programming and Intelligent Algorithms Que Tran Høgskolen i Ålesund 20th March 2017 1 Why data preprocessing? Real-world data tend to be dirty incomplete: lacking attribute
Data preprocessing Functional Programming and Intelligent Algorithms Que Tran Høgskolen i Ålesund 20th March 2017 1 Why data preprocessing? Real-world data tend to be dirty incomplete: lacking attribute
CS378 Introduction to Data Mining. Data Exploration and Data Preprocessing. Li Xiong
 CS378 Introduction to Data Mining Data Exploration and Data Preprocessing Li Xiong Data Exploration and Data Preprocessing Data and Attributes Data exploration Data pre-processing Data Mining: Concepts
CS378 Introduction to Data Mining Data Exploration and Data Preprocessing Li Xiong Data Exploration and Data Preprocessing Data and Attributes Data exploration Data pre-processing Data Mining: Concepts
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 03 : 13/10/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 03 : 13/10/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Summary of Last Chapter. Course Content. Chapter 3 Objectives. Chapter 3: Data Preprocessing. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Chapter 3: Data Mining:
 Chapter 3: Data Mining: 3.1 What is Data Mining? Data Mining is the process of automatically discovering useful information in large repository. Why do we need Data mining? Conventional database systems
Chapter 3: Data Mining: 3.1 What is Data Mining? Data Mining is the process of automatically discovering useful information in large repository. Why do we need Data mining? Conventional database systems
CS570 Introduction to Data Mining
 CS570 Introduction to Data Mining Department of Mathematics and Computer Science Li Xiong Data Exploration and Data Preprocessing Data and attributes Data exploration Data pre-processing 2 10 What is Data?
CS570 Introduction to Data Mining Department of Mathematics and Computer Science Li Xiong Data Exploration and Data Preprocessing Data and attributes Data exploration Data pre-processing 2 10 What is Data?
Data Preprocessing. Erwin M. Bakker & Stefan Manegold. https://homepages.cwi.nl/~manegold/dbdm/
 Data Preprocessing Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl 9/26/17
Data Preprocessing Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl 9/26/17
Data Exploration and Preparation Data Mining and Text Mining (UIC Politecnico di Milano)
") Data Exploration and Preparation Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining, : Concepts and Techniques", The Morgan Kaufmann
Data Exploration and Preparation Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining, : Concepts and Techniques", The Morgan Kaufmann
UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES
 UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES Data Pre-processing-Data Cleaning, Integration, Transformation, Reduction, Discretization Concept Hierarchies-Concept Description: Data Generalization And
UNIT 2. DATA PREPROCESSING AND ASSOCIATION RULES Data Pre-processing-Data Cleaning, Integration, Transformation, Reduction, Discretization Concept Hierarchies-Concept Description: Data Generalization And
ECLT 5810 Data Preprocessing. Prof. Wai Lam
 ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
Data Mining. Data preprocessing. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Preprocessing. Komate AMPHAWAN
 Data Preprocessing Komate AMPHAWAN 1 Data cleaning (data cleansing) Attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. 2 Missing value
Data Preprocessing Komate AMPHAWAN 1 Data cleaning (data cleansing) Attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. 2 Missing value
Data Mining. Data preprocessing. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining Data preprocessing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 15 Table of contents 1 Introduction 2 Data preprocessing
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3
 Chapter 3") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
ECT7110. Data Preprocessing. Prof. Wai Lam. ECT7110 Data Preprocessing 1
 ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
Week 2 Engineering Data
 Week 2 Engineering Data Seokho Chi Associate Professor Ph.D. SNU Construction Innovation Lab Source: Tan, Kumar, Steinback (2006) 10 What is Data? Collection of data objects and their attributes An attribute
Week 2 Engineering Data Seokho Chi Associate Professor Ph.D. SNU Construction Innovation Lab Source: Tan, Kumar, Steinback (2006) 10 What is Data? Collection of data objects and their attributes An attribute
cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska
 cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska Chapter 2: Data Preprocessing (book slide) Why preprocess the data? Descriptive data summarization Data cleaning Data
cse634 Data Mining Preprocessing Lecture Notes Chapter 2 Professor Anita Wasilewska Chapter 2: Data Preprocessing (book slide) Why preprocess the data? Descriptive data summarization Data cleaning Data
Data Mining: Concepts and Techniques
 Data Mining: Concepts and Techniques Chapter 2 Original Slides: Jiawei Han and Micheline Kamber Modification: Li Xiong Data Mining: Concepts and Techniques 1 Chapter 2: Data Preprocessing Why preprocess
Data Mining: Concepts and Techniques Chapter 2 Original Slides: Jiawei Han and Micheline Kamber Modification: Li Xiong Data Mining: Concepts and Techniques 1 Chapter 2: Data Preprocessing Why preprocess
Data Mining and Analytics. Introduction
 Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
K236: Basis of Data Science
 Schedule of K236 K236: Basis of Data Science Lecture 6: Data Preprocessing Lecturer: Tu Bao Ho and Hieu Chi Dam TA: Moharasan Gandhimathi and Nuttapong Sanglerdsinlapachai 1. Introduction to data science
Schedule of K236 K236: Basis of Data Science Lecture 6: Data Preprocessing Lecturer: Tu Bao Ho and Hieu Chi Dam TA: Moharasan Gandhimathi and Nuttapong Sanglerdsinlapachai 1. Introduction to data science
Proximity and Data Pre-processing
 Proximity and Data Pre-processing Slide 1/47 Proximity and Data Pre-processing Huiping Cao Proximity and Data Pre-processing Slide 2/47 Outline Types of data Data quality Measurement of proximity Data
Proximity and Data Pre-processing Slide 1/47 Proximity and Data Pre-processing Huiping Cao Proximity and Data Pre-processing Slide 2/47 Outline Types of data Data quality Measurement of proximity Data
DATA PREPROCESSING. Tzompanaki Katerina
 DATA PREPROCESSING Tzompanaki Katerina Background: Data storage formats Data in DBMS ODBC, JDBC protocols Data in flat files Fixed-width format (each column has a specific number of characters, filled
DATA PREPROCESSING Tzompanaki Katerina Background: Data storage formats Data in DBMS ODBC, JDBC protocols Data in flat files Fixed-width format (each column has a specific number of characters, filled
Road Map. Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary
 2. Data preprocessing Road Map Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary 2 Data types Categorical vs. Numerical Scale types
2. Data preprocessing Road Map Data types Measuring data Data cleaning Data integration Data transformation Data reduction Data discretization Summary 2 Data types Categorical vs. Numerical Scale types
Data Preprocessing in Python. Prof.Sushila Aghav
 Data Preprocessing in Python Prof.Sushila Aghav Sushila.aghav@mitcoe.edu.in Content Why preprocess the data? Descriptive data summarization Data cleaning Data integration and transformation April 24, 2018
Data Preprocessing in Python Prof.Sushila Aghav Sushila.aghav@mitcoe.edu.in Content Why preprocess the data? Descriptive data summarization Data cleaning Data integration and transformation April 24, 2018
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Machine Learning Feature Creation and Selection
 Machine Learning Feature Creation and Selection Jeff Howbert Introduction to Machine Learning Winter 2012 1 Feature creation Well-conceived new features can sometimes capture the important information
Machine Learning Feature Creation and Selection Jeff Howbert Introduction to Machine Learning Winter 2012 1 Feature creation Well-conceived new features can sometimes capture the important information
Data Mining: Concepts and Techniques. Chapter 2
 Data Mining: Concepts and Techniques Chapter 2 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Data Mining: Concepts and Techniques Chapter 2 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3
 Chapter 3") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Dimension Reduction CS534
 Dimension Reduction CS534 Why dimension reduction? High dimensionality large number of features E.g., documents represented by thousands of words, millions of bigrams Images represented by thousands of
Dimension Reduction CS534 Why dimension reduction? High dimensionality large number of features E.g., documents represented by thousands of words, millions of bigrams Images represented by thousands of
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Data can be in the form of numbers, words, measurements, observations or even just descriptions of things.
 + What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
+ What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Data mining. Classification k-nn Classifier. Piotr Paszek. (Piotr Paszek) Data mining k-nn 1 / 20
 Data mining k-nn 1 / 20") Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Data Preparation. Data Preparation. (Data pre-processing) Why Prepare Data? Why Prepare Data? Some data preparation is needed for all mining tools
 Why Prepare Data? Why Prepare Data? Some data preparation is needed for all mining tools") Data Preparation Data Preparation (Data pre-processing) Why prepare the data? Discretization Data cleaning Data integration and transformation Data reduction, Feature selection 2 Why Prepare Data? Why
Data Preparation Data Preparation (Data pre-processing) Why prepare the data? Discretization Data cleaning Data integration and transformation Data reduction, Feature selection 2 Why Prepare Data? Why
Getting to Know Your Data
 Chapter 2 Getting to Know Your Data 2.1 Exercises 1. Give three additional commonly used statistical measures (i.e., not illustrated in this chapter) for the characterization of data dispersion, and discuss
Chapter 2 Getting to Know Your Data 2.1 Exercises 1. Give three additional commonly used statistical measures (i.e., not illustrated in this chapter) for the characterization of data dispersion, and discuss
BUSINESS DECISION MAKING. Topic 1 Introduction to Statistical Thinking and Business Decision Making Process; Data Collection and Presentation
 BUSINESS DECISION MAKING Topic 1 Introduction to Statistical Thinking and Business Decision Making Process; Data Collection and Presentation (Chap 1 The Nature of Probability and Statistics) (Chap 2 Frequency
BUSINESS DECISION MAKING Topic 1 Introduction to Statistical Thinking and Business Decision Making Process; Data Collection and Presentation (Chap 1 The Nature of Probability and Statistics) (Chap 2 Frequency
Sponsored by AIAT.or.th and KINDML, SIIT
 CC: BY NC ND Table of Contents Chapter 2. Data Preprocessing... 31 2.1. Basic Representation for Data: Database Viewpoint... 31 2.2. Data Preprocessing in the Database Point of View... 33 2.3. Data Cleaning...
CC: BY NC ND Table of Contents Chapter 2. Data Preprocessing... 31 2.1. Basic Representation for Data: Database Viewpoint... 31 2.2. Data Preprocessing in the Database Point of View... 33 2.3. Data Cleaning...
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
CAP-359 PRINCIPLES AND APPLICATIONS OF DATA MINING. Rafael Santos
 CAP-359 PRINCIPLES AND APPLICATIONS OF DATA MINING Rafael Santos rafael.santos@inpe.br www.lac.inpe.br/~rafael.santos/ Overview So far What is Data Mining? Applications, Examples. Let s think about your
CAP-359 PRINCIPLES AND APPLICATIONS OF DATA MINING Rafael Santos rafael.santos@inpe.br www.lac.inpe.br/~rafael.santos/ Overview So far What is Data Mining? Applications, Examples. Let s think about your
Classification and Regression
 Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Data Mining Course Overview
 Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Feature Selection. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Preprocessing DWML, /33
 Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Data Preprocessing. Data Mining: Concepts and Techniques. c 2012 Elsevier Inc. All rights reserved.
 3 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size (often several gigabytes or more) and their likely origin
3 Data Preprocessing Today s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size (often several gigabytes or more) and their likely origin
2 CONTENTS. 3.8 Bibliographic Notes... 45
 Contents 3 Data Preprocessing 3 3.1 Data Preprocessing: An Overview................. 4 3.1.1 Data Quality: Why Preprocess the Data?......... 4 3.1.2 Major Tasks in Data Preprocessing............. 5 3.2
Contents 3 Data Preprocessing 3 3.1 Data Preprocessing: An Overview................. 4 3.1.1 Data Quality: Why Preprocess the Data?......... 4 3.1.2 Major Tasks in Data Preprocessing............. 5 3.2
Discriminate Analysis
 Discriminate Analysis Outline Introduction Linear Discriminant Analysis Examples 1 Introduction What is Discriminant Analysis? Statistical technique to classify objects into mutually exclusive and exhaustive
Discriminate Analysis Outline Introduction Linear Discriminant Analysis Examples 1 Introduction What is Discriminant Analysis? Statistical technique to classify objects into mutually exclusive and exhaustive
Data Preprocessing. Javier Béjar. URL - Spring 2018 CS - MAI 1/78 BY: $\
 Data Preprocessing Javier Béjar BY: $\ URL - Spring 2018 C CS - MAI 1/78 Introduction Data representation Unstructured datasets: Examples described by a flat set of attributes: attribute-value matrix Structured
Data Preprocessing Javier Béjar BY: $\ URL - Spring 2018 C CS - MAI 1/78 Introduction Data representation Unstructured datasets: Examples described by a flat set of attributes: attribute-value matrix Structured
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Data Collection, Preprocessing and Implementation
 Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
Data Warehousing and Machine Learning
 Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Data Mining: Exploring Data. Lecture Notes for Chapter 3
 Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
DATA MINING LECTURE 10B. Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines
 DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data. Lecture Notes for Data Exploration Chapter. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Data Exploration Chapter Introduction to Data Mining by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 What is data exploration?
Data Mining: Exploring Data Lecture Notes for Data Exploration Chapter Introduction to Data Mining by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 What is data exploration?