Implementing Strassen-like Fast Matrix Multiplication Algorithms with BLIS
|
|
|
- Nigel Norris
- 6 years ago
- Views:
Transcription


1 Implementing Strassen-like Fast Matrix Multiplication Algorithms with BLIS Jianyu Huang, Leslie Rice Joint work with Tyler M. Smith, Greg M. Henry, Robert A. van de Geijn BLIS Retreat 2016



2 *Overlook of the Bay Area. Photo taken in Mission Peak Regional Preserve, Fremont, CA. Summer STRASSEN, from 30,000 feet Volker Strassen (Born in 1936, aged 80) Original Strassen Paper (1969)
 Direct Computation")



3 One-level Strassen s Algorithm (In theory) Direct Computation Strassen s Algorithm 8 multiplications, 8 additions 7 multiplications, 22 additions *Strassen, Volker. "Gaussian elimination is not optimal." Numerische Mathematik 13, no. 4 (1969):
4 Multi-level Strassen s Algorithm (In theory) M 0 := (A 00 +A 11 )(B 00 +B 11 ); M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11 (B 10 B 00 ); M 4 := (A 00 +A 01 )B 11 ; M 5 := (A 10 A 00 )(B 00 +B 01 ); M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 One-level Strassen (1+14.3% speedup) 8 multiplications 7 multiplications ; Two-level Strassen (1+30.6% speedup) 64 multiplications 49 multiplications; d-level Strassen (n 3 /n speedup) 8 d multiplications 7 d multiplications; C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5
5 Multi-level Strassen s Algorithm (In theory) M 0 := (A 00 +A 11 )(B 00 +B 11 ); M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11 (B 10 B 00 ); M 4 := (A 00 +A 01 )B 11 ; M 5 := (A 10 A 00 )(B 00 +B 01 ); M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5 One-level Strassen (1+14.3% speedup) 8 multiplications 7 multiplications ; Two-level Strassen (1+30.6% speedup) 64 multiplications 49 multiplications; d-level Strassen (n 3 /n speedup) 8 d multiplications 7 d multiplications;
6 Strassen s Algorithm (In practice) M 0 := (A 00 +A 11 )(B 00 +B 11 ); M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11 (B 10 B 00 ); M 4 := (A 00 +A 01 )B 11 ; M 5 := (A 10 A 00 )(B 00 +B 01 ); M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5
7 Strassen s Algorithm (In practice) T 0 M 0 := (A 00 +A 11 )(B 00 +B 11 ); T 2 M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11 (B 10 B 00 ); T 5 T 3 T 4 M 4 := (A 00 +A 01 )B 11 ; T 1 T 6 T 7 M 5 := (A 10 A 00 )(B 00 +B 01 ); T 8 T 9 M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 One-level Strassen (1+14.3% speedup) 7 multiplications + 22 additions; Two-level Strassen (1+30.6% speedup) 49 multiplications additions; d-level Strassen (n 3 /n speedup) Numerical unstable; Not achievable C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5
; T 2 M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11")
(B 00 +B 01 ); T 8 T 9 M 6 := (A 01 A 11 )(B 10 +B 11 ); C")
 7 multiplications + 22 additions; Two-level Strassen (1+30.")
 Numerical unstable; Not achievable C 01 M 2 + M 4 C 10 M")
8 Strassen s Algorithm (In practice) T 0 M 0 := (A 00 +A 11 )(B 00 +B 11 ); T 2 M 1 := (A 10 +A 11 )B 00 ; M 2 := A 00 (B 01 B 11 ); M 3 := A 11 (B 10 B 00 ); T 5 T 3 T 4 M 4 := (A 00 +A 01 )B 11 ; T 1 T 6 T 7 M 5 := (A 10 A 00 )(B 00 +B 01 ); T 8 T 9 M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 One-level Strassen (1+14.3% speedup) 7 multiplications + 22 additions; Two-level Strassen (1+30.6% speedup) 49 multiplications additions; d-level Strassen (n 3 /n speedup) Numerical unstable; Not achievable C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5
9 To achieve practical high performance of Strassen s algorithm... Conventional Implementations Our Implementations Matrix Size Must be large Matrix Shape Must be square No Additional Workspace Parallelism
10 To achieve practical high performance of Strassen s algorithm... Conventional Implementations Our Implementations Matrix Size Must be large Matrix Shape Must be square No Additional Workspace Parallelism Usually task parallelism

11 To achieve practical high performance of Strassen s algorithm... Conventional Implementations Our Implementations Matrix Size Must be large Matrix Shape Must be square No Additional Workspace Parallelism Usually task parallelism Can be data parallelism
12 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion
13 Level-3 BLAS Matrix-Matrix Multiplication (GEMM) (General) matrix-matrix multiplication (GEMM) is supported in the level-3 BLAS* interface as Ignoring transa and transb, GEMM computes We consider the simplified version of GEMM *Dongarra, Jack J., et al. "A set of level 3 basic linear algebra subprograms."acm Transactions on Mathematical Software (TOMS) 16.1 (1990): 1-17.
14 State-of-the-art GEMM in BLIS BLAS-like Library Instantiation Software (BLIS) is a portable framework for instantiating BLAS-like dense linear algebra libraries. Field Van Zee, and Robert van de Geijn. BLIS: A Framework for Rapidly Instantiating BLAS Functionality." ACM TOMS 41.3 (2015): 14. BLIS provides a refactoring of GotoBLAS algorithm (best-known approach) to implement GEMM. Kazushige Goto, and Robert van de Geijn. "High-performance implementation of the level-3 BLAS." ACM TOMS 35.1 (2008): 4. Kazushige Goto, and Robert van de Geijn. "Anatomy of high-performance matrix multiplication." ACM TOMS 34.3 (2008): 12. GEMM implementation in BLIS has 6-layers of loops. The outer 5 loops are written i. The inner-most loop (micro-kernel) is written in assembly for high performance. Partition matrices into smaller blocks to fit into the different memory hierarchy. The order of these loops is designed to utilize the cache reuse rate. BLIS opens the black box of GEMM, leading to many applications built on BLIS. Chenhan D. Yu, *Jianyu Huang, Woody Austin, Bo Xiao, and George Biros. "Performance optimization for the k-nearest neighbors kernel on x86 architectures." In SC 15, p. 7. ACM, *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In submission to SC 16. Devin Matthews, Field Van Zee, and Robert van de Geijn. High-Performance Tensor Contraction without BLAS. In submission to SC 16
15 State-of-the-art GEMM in BLIS BLAS-like Library Instantiation Software (BLIS) is a portable framework for instantiating BLAS-like dense linear algebra libraries. Field Van Zee, and Robert van de Geijn. BLIS: A Framework for Rapidly Instantiating BLAS Functionality." ACM TOMS 41.3 (2015): 14. BLIS provides a refactoring of GotoBLAS algorithm (best-known approach) to implement GEMM. Kazushige Goto, and Robert van de Geijn. "High-performance implementation of the level-3 BLAS." ACM TOMS 35.1 (2008): 4. Kazushige Goto, and Robert van de Geijn. "Anatomy of high-performance matrix multiplication." ACM TOMS 34.3 (2008): 12. GEMM implementation in BLIS has 6-layers of loops. The outer 5 loops are written i. The inner-most loop (micro-kernel) is written in assembly for high performance. Partition matrices into smaller blocks to fit into the different memory hierarchy. The order of these loops is designed to utilize the cache reuse rate. BLIS opens the black box of GEMM, leading to many applications built on BLIS. Chenhan D. Yu, Jianyu Huang, Woody Austin, Bo Xiao, and George Biros. "Performance Optimization for the k-nearest Neighbors Kernel on x86 Architectures." In SC 15. Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. To appear in SC 16. Devin Matthews. High-Performance Tensor Contraction without BLAS., arxiv: Paul Springer, Paolo Bientinesi. Design of a High-performance GEMM-like Tensor-Tensor Multiplication, arxiv:
16 GotoBLAS algorithm for GEMM in BLIS *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
17 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j main memory *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
18 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p Pack B p B p B p main memory L3 cache *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
19 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p 3 rd loop around micro-kernel Pack B p B p C i m C m C A i Pack A i A i B p A i m R main memory L3 cache L2 cache *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
20 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p 3 rd loop around micro-kernel Pack B p B p C i m C m C A i Pack A i A i B p C i 2 nd loop around micro-kernel n R n R A i B p m R main memory L3 cache L2 cache *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
21 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p 3 rd loop around micro-kernel Pack B p B p C i m C m C A i Pack A i A i B p C i 2 nd loop around micro-kernel n R n R A i B p m R n R 1 st loop around micro-kernel m R Update C ij main memory L3 cache L2 cache L1 cache registers *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
22 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p 3 rd loop around micro-kernel Pack B p B p C i m C m C A i Pack A i A i B p C i 2 nd loop around micro-kernel n R n R A i B p m R n R 1 st loop around micro-kernel m R Update C ij main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1 *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
23 5 th loop around micro-kernel GotoBLAS algorithm for GEMM in BLIS C j A B j 4 th loop around micro-kernel C j A p B p 3 rd loop around micro-kernel Pack B p B p C i m C m C A i Pack A i A i B p C i 2 nd loop around micro-kernel n R n R A i B p m R n R 1 st loop around micro-kernel m R Update C ij main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1 *Field G. Van Zee, and Tyler M. Smith. Implementing high-performance complex matrix multiplication." In ACM Transactions on Mathematical Software (TOMS), accepted pending modifications.
24 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion
25 One-level Strassen s Algorithm Reloaded M 0 := a(a 00 +A 11 )(B 00 +B 11 ); M 1 := a(a 10 +A 11 )B 00 ; M 2 := aa 00 (B 01 B 11 ); M 3 := aa 11 (B 10 B 00 ); M 4 := a(a 00 +A 01 )B 11 ; M 5 := a(a 10 A 00 )(B 00 +B 01 ); M 6 := a(a 01 A 11 )(B 10 +B 11 ); C 00 M 0 + M 3 M 4 + M 6 C 01 M 2 + M 4 C 10 M 1 + M 3 C 11 M 0 M 1 + M 2 + M 5 M 0 := a(a 00 +A 11 )(B 00 +B 11 ); C 00 M 0 ; C 11 M 0 ; M 1 := a(a 10 +A 11 )B 00 ; C 10 M 1 ; C 11 = M 1 ; M 2 := aa 00 (B 01 B 11 ); C 01 M 2 ; C 11 M 2 ; M 3 := aa 11 (B 10 B 00 ); C 00 M 3 ; C 10 M 3 ; M 4 := a(a 00 +A 01 )B 11 ; C 01 M 4 ; C 00 = M 4 ; M 5 := a(a 10 A 00 )(B 00 +B 01 ); C 11 M 5 ; M 6 := a(a 01 A 11 )(B 10 +B 11 ); C 00 M 6 ; M := a(x+y)(v+w); C M; D M; General operation for one-level Strassen: M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}.


26 High-performance implementation of the general operation? M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. *
27 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16.
28 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. D j C n j C 5 th loop around micro-kernel Y X W V j main memory *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16.
29 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. D j C n j C 5 th loop around micro-kernel Y X W V j 4 th loop around micro-kernel D j C j Y p X p W p V p Pack V p + ew p B p B p main memory L3 cache *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16.
30 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. D j C n j C 5 th loop around micro-kernel Y X W V j 4 th loop around micro-kernel D j C j Y p X p W p V p 3 rd loop around micro-kernel Pack V p + ew p B p D i C i m C m C Y i X i B p Pack X i + dy i A i A i m R main memory L3 cache L2 cache *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16.

31 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. D j C n j C 5 th loop around micro-kernel Y X W V j 4 th loop around micro-kernel D j C j Y p X p W p V p 3 rd loop around micro-kernel Pack V p + ew p B p D i C i m C m C Y i X i B p Pack X i + dy i A i 2 nd loop around micro-kernel n R n R A i B p D i C i n R m R 1 st loop around micro-kernel Update C ij, D ij m R *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16. main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1
32 M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. D j C n j C 5 th loop around micro-kernel Y X W V j 4 th loop around micro-kernel D j C j Y p X p W p V p 3 rd loop around micro-kernel Pack V p + ew p B p D i C i m C m C Y i X i B p Pack X i + dy i A i 2 nd loop around micro-kernel n R n R A i B p D i C i n R m R 1 st loop around micro-kernel Update C ij, D ij m R *Jianyu Huang, Tyler Smith, Greg Henry, and Robert van de Geijn. Strassen s Algorithm Reloaded. In SC 16. main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1
33 5 th loop around micro-kernel 5 th loop around micro-kernel C j A B D j C n j C Y X W V j 4 th loop around micro-kernel 4 th loop around micro-kernel C j A p B p D j C j Y p X p W p V p 3 rd loop around micro-kernel Pack B p B p 3 rd loop around micro-kernel Pack V p + ew p B p C i m C m C A i Pack A i A i B p D i C i m C m C Y i X i B p Pack X i + dy i A i C i 2 nd loop around micro-kernel n R n R A i B p m R n R 1 st loop around micro-kernel 2 nd loop around micro-kernel n R n R A i B p D i C i n R m R 1 st loop around micro-kernel m R Update C ij Update C ij, D ij m R main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1 main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1
34 Two-level Strassen s Algorithm Reloaded
(V+e 1 V 1 +e 2 V 2 +e 3 V 3 ); C 0 g 0 M; C 1 g 1 M; C 2 g 2 M; C 3 g 3 M; g i,d i,e i {-1,")
35 Two-level Strassen s Algorithm Reloaded (Continue) M := a(x 0 +X 1 +X 2 +X 3 )(V+V 1 +V 2 +V 3 ); C 0 M; C 1 M; C 2 M; C 3 M; General operation for two-level Strassen: M := a(x 0 +d 1 X 1 +d 2 X 2 +d 3 X 3 )(V+e 1 V 1 +e 2 V 2 +e 3 V 3 ); C 0 g 0 M; C 1 g 1 M; C 2 g 2 M; C 3 g 3 M; g i,d i,e i {-1, 0, 1}.
36 Additional Levels of Strassen Reloaded The general operation of one-level Strassen: M := a(x+dy)(v+ew); C g 0 M; D g 1 M; g 0, g 1,d,e {-1, 0, 1}. The general operation of two-level Strassen: M := a(x 0 +d 1 X 1 +d 2 X 2 +d 3 X 3 )(V+e 1 V 1 +e 2 V 2 +e 3 V 3 ); C 0 g 0 M; C 1 g 1 M; C 2 g 2 M; C 3 g 3 M; g i,d i,e i {-1, 0, 1}. The general operation needed to integrate k levels of Strassen is given by
37 Building blocks BLIS framework A routine for packing B p into C/Intel intrinsics Adapted to general operation Integrate the addition of multiple matrices V t into A routine for packing A i into C/Intel intrinsics Integrate the addition of multiple matrices X s into A micro-kernel for updating an m R n R submatrix of C. SIMD assembly (AVX, AVX512, etc) Integrate the update of multiple submatrices of C.
38 Variations on a theme Naïve Strassen A traditional implementation with temporary buffers. AB Strassen Integrate the addition of matrices into and. ABC Strassen Integrate the addition of matrices into and. Integrate the update of multiple submatrices of C in the micro-kernel.
39 5 th loop around micro-kernel D j C n j C Y X W V j Parallelization 3 rd loop (along m C direction) 4 th loop around micro-kernel D j C j Y p X p W p V p D i C i m C 3 rd loop around micro-kernel m C Y i X i Pack V p + ew p B p B p Pack X i + dy i A i 2 nd loop (along n R direction) 2 nd loop around micro-kernel n R n R A i B p D i C i n R m R 1 st loop around micro-kernel both 3 rd and 2 nd loop Update C ij, D ij m R main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1 *Tyler M. Smith, Robert Van De Geijn, Mikhail Smelyanskiy, Jeff R. Hammond, and Field G. Van Zee. "Anatomy of high-performance many-threaded matrix multiplication." In Parallel and Distributed Processing Symposium, 2014 IEEE 28th International, pp IEEE, 2014.
40 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion
41 Performance Model Performance Metric Total Time Breakdown Arithmetic Operations Memory Operations
(B 00 +B 11 ); C 00 M 0 ; C 11 M 0 ; M 1 := a(a 10 +A 11 )B 00 ; C 10 M 1 ; C 11 = M 1 ; M 2 :=")
42 Arithmetic Operations DGEMM No extra additions Submatrix multiplication Extra additions with submatrices of A, B, C, respectively One-level Strassen (ABC, AB, Naïve) 7 submatrix multiplications 5 extra additions of submatrices of A and B 12 extra additions of submatrices of C M 0 := a(a 00 +A 11 )(B 00 +B 11 ); C 00 M 0 ; C 11 M 0 ; M 1 := a(a 10 +A 11 )B 00 ; C 10 M 1 ; C 11 = M 1 ; M 2 := aa 00 (B 01 B 11 ); C 01 M 2 ; C 11 M 2 ; M 3 := aa 11 (B 10 B 00 ); C 00 M 3 ; C 10 M 3 ; M 4 := a(a 00 +A 01 )B 11 ; C 01 M 4 ; C 00 = M 4 ; M 5 := a(a 10 A 00 )(B 00 +B 01 ); C 11 M 5 ; M 6 := a(a 01 A 11 )(B 10 +B 11 ); C 00 M 6 ; Two-level Strassen (ABC, AB, Naïve) 49 submatrix multiplications 95 extra additions of submatrices of A and B 154 extra additions of submatrices of C
43 Memory Operations DGEMM One-level ABC Strassen AB Strassen Naïve Strassen Two-level ABC Strassen AB Strassen Naïve Strassen
44 Modeled and Actual Performance on Single Core
45 Observation (Square Matrices) Modeled Performance Actual Performance
46 Observation (Square Matrices) Modeled Performance Actual Performance
47 Observation (Square Matrices) Modeled Performance Actual Performance

48 Observation (Square Matrices) Modeled Performance Actual Performance
49 Observation (Square Matrices) Modeled Performance Actual Performance
50 Observation (Square Matrices) Modeled Performance Actual Performance 26.0% 13.1% Theoretical Speedup over DGEMM One-level Strassen (1+14.3% speedup) 8 multiplications 7 multiplications; Two-level Strassen (1+30.6% speedup) 64 multiplications 49 multiplications;
51 Observation (Square Matrices) Both one-level and two-level For small square matrices, ABC Strassen outperforms AB Strassen For larger square matrices, this trend reverses Reason ABC Strassen avoids storing M (M resides in the register) ABC Strassen increases the number of times for updating submatrices of C
52 5 th loop around micro-kernel 5 th loop around micro-kernel C j A B D j C n j C Y X W V j 4 th loop around micro-kernel 4 th loop around micro-kernel C j A p B p D j C j Y p X p W p V p 3 rd loop around micro-kernel Pack B p B p 3 rd loop around micro-kernel Pack V p + ew p B p C i m C m C A i Pack A i A i B p D i C i m C m C Y i X i B p Pack X i + dy i A i C i 2 nd loop around micro-kernel n R n R A i B p m R n R 1 st loop around micro-kernel 2 nd loop around micro-kernel n R n R A i B p D i C i n R m R 1 st loop around micro-kernel m R Update C ij Update C ij, D ij m R main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1 main memory L3 cache L2 cache L1 cache registers 1 micro-kernel 1
53 Observation (Square Matrices) Both one-level and two-level For small square matrices, ABC Strassen outperforms AB Strassen For larger square matrices, this trend reverses Reason ABC Strassen avoids storing M (M resides in the register) ABC Strassen increases the number of times for updating submatrices of C
54 Observation (Rank-k Update) What is Rank-k update? n m m k n
55 Observation (Rank-k Update) Importance of Rank-k update Blocked LU with partial pivoting (getrf) A 12 A 21 A 22
56 Observation (Rank-k Update) Importance of Rank-k update A 12 A 21 A 22
57 Observation (Rank-k Update) Modeled Performance Actual Performance
58 Observation (Rank-k Update) Modeled Performance Actual Performance
59 Observation (Rank-k Update) Modeled Performance Actual Performance
60 Observation (Rank-k Update) Modeled Performance Actual Performance
61 Observation (Rank-k Update) Modeled Performance Actual Performance
62 Observation (Rank-k Update) Modeled Performance Actual Performance Reason: ABC Strassen avoids forming the temporary matrix M explicitly in the memory (M resides in register), especially important when m, n >> k.
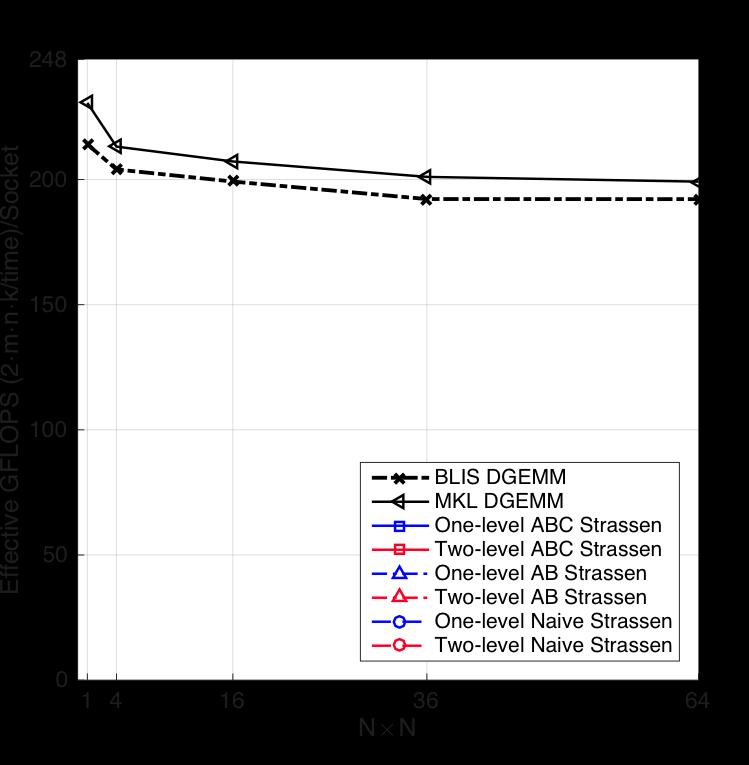
63 Single Node Experiment

64 Rank-k Update Square Matrices 1 core 5 core 10 core
65 Many-core Experiment


66 Intel Xeon Phi coprocessor (KNC)
67 Distributed Memory Experiment
68
69
70
71 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion
72 Level-3 BLAS Symmetric Matrix-Matrix Multiplication (SYMM) Symmetric matrix-matrix multiplication (SYMM) is supported in the level-3 BLAS* interface as SYMM computes *Dongarra, Jack J., et al. "A set of level 3 basic linear algebra subprograms."acm Transactions on Mathematical Software (TOMS) 16.1 (1990): 1-17.
73 Level-3 BLAS Symmetric Matrix-Matrix Multiplication (SYMM) A is a symmetric matrix (square and equal to its transpose); Assume only the lower triangular half is stored; Follow the same algorithm we used for GEMM by modifying the packing routine for matrix A to account for the symmetric nature of A. Example Matrix A is stored as
74 SYMM with One-Level Strassen When partitioning A for one-level Strassen operations, we integrate the symmetric nature of A. A 00 A 01 A 10 A 11
75 SYMM Implementation Platform: BLISlab* What is BLISlab? A Sandbox for Optimizing GEMM that mimics implementation in BLIS A set of exercises that use GEMM to show how high performance can be attained on moderpus with hierarchical memories Used in Prof. Robert van de Geijn s CS 383C Numerical Linear Algebra Contributions Added DSYMM Applied Strassen s algorithm to DGEMM and DSYMM 3 versions: Naive, AB, ABC Strassen improves performance in both DGEMM and DSYMM *
76 DSYMM Results in BLISlab
77 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion
78 (2,2,2) Strassen Algorithm M 0 := (A 00 +A 11 )(B 00 +B 11 ); C 00 M 0 ; C 11 M 0 ; M 1 := (A 10 +A 11 )B 00 ; C 10 M 1 ; C 11 = M 1 ; M 2 := A 00 (B 01 B 11 ); C 01 M 2 ; C 11 M 2 ; M 3 := A 11 (B 10 B 00 ); C 00 M 3 ; C 10 M 3 ; M 4 := (A 00 +A 01 )B 11 ; C 01 M 4 ; C 00 = M 4 ; M 5 := (A 10 A 00 )(B 00 +B 01 ); C 11 M 5 ; M 6 := (A 01 A 11 )(B 10 +B 11 ); C 00 M 6 ;
( B 02 B 10 +B 12 ); C 02 M 3 ;C 12 M 3 ;C 20 =M 3 ; M 4 := ( A 00 +A 01 +A 10 )( B 00 +B 01 +B 11 ); C 00 =M 4 ;C 01 M 4 ;C 11 M 4 ; M 5 := ( A")
79 (3,2,3) Fast Matrix Multiplication M 0 := ( A 01 +A 11 +A 21 )(B 11 +B 12 ); C 02 = M 0 ; M 1 := ( A 00 +A 10 +A 21 )(B 00 B 12 ); C 02 = M 1 ; C 21 = M 1 ; M 2 := ( A 00 +A 10 )( B 01 B 11 ); C 00 =M 2 ;C 01 M 2 ;C 21 M 2 ; M 3 := ( A 10 A 20 +A 21 )( B 02 B 10 +B 12 ); C 02 M 3 ;C 12 M 3 ;C 20 =M 3 ; M 4 := ( A 00 +A 01 +A 10 )( B 00 +B 01 +B 11 ); C 00 =M 4 ;C 01 M 4 ;C 11 M 4 ; M 5 := ( A 10 )( B 00 ); C 00 M 5 ;C 01 =M 5 ;C 10 M 5 ;C 11 =M 5 ;C 20 M 5 ; M 6 := ( A 10 +A 11 +A 20 A 21 )( B 10 B 12 ); C 02 =M 6 ;C 12 =M 6 ; M 7 := ( A 11 )( B 10 ); C 02 M 7 ;C 10 M 7 ;C 12 M 7 ; M 8 := ( A 00 +A 10 +A 20 )( B 01 +B 02 ); C 21 M 8 ; M 9 := ( A 00 +A 01 )( B 00 B 01 ); C 01 M 9 ;C 11 M 9 ; M 10 :=( A 21 )( B 02 +B 12 ); C 02 M 10 ;C 20 M 10 ;C 22 M 10 ; M 11 := ( A 20 A 21 )( B 02 ); C 02 M 11 ;C 12 M 11 ;C 21 =M 11 ;C 22 M 11 ; M 12 := ( A 01 )( B 00 +B 01 +B 10 +B 11 ); C 00 M 12 ; M 13 := ( A 10 A 20 )( B 00 B 02 +B 10 B 12 ); C 20 =M 13 ; M 14 := ( A 00 +A 01 +A 10 A 11 )( B 11 ); C 02 =M 14 ;C 11 =M 14 ; *Austin R. Benson, Grey Ballard. "A framework for practical parallel fast matrix multiplication." PPOPP15.
80
81 Outline Review of State-of-the-art GEMM in BLIS Strassen s Algorithm Reloaded Theoretical Model and Practical Performance Extension to Other BLAS-3 Operation Extension to Other Fast Matrix Multiplication Conclusion


82 To achieve practical high performance of Strassen s algorithm... Conventional Implementations Our Implementations Matrix Size Must be large Matrix Shape Must be square No Additional Workspace Parallelism Usually task parallelism Can be data parallelism

.")


 for their supports.")

83 Acknowledgement - NSF grants ACI / , CCF Intel Corporation through an Intel Parallel Computing Center (IPCC). - Access to the Maverick and Stampede supercomputers administered by TACC. We thank Field Van Zee, Chenhan Yu, Devin Matthews, and the rest of the SHPC team ( for their supports. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
84 Thank you!
High-Performance Implementation of the Level-3 BLAS
 High-Performance Implementation of the Level- BLAS KAZUSHIGE GOTO The University of Texas at Austin and ROBERT VAN DE GEIJN The University of Texas at Austin A simple but highly effective approach for
High-Performance Implementation of the Level- BLAS KAZUSHIGE GOTO The University of Texas at Austin and ROBERT VAN DE GEIJN The University of Texas at Austin A simple but highly effective approach for
Toward Scalable Matrix Multiply on Multithreaded Architectures
 Toward Scalable Matrix Multiply on Multithreaded Architectures Bryan Marker 1, Field G Van Zee 1, Kazushige Goto 1, Gregorio Quintana Ortí 2, and Robert A van de Geijn 1 1 The University of Texas at Austin
Toward Scalable Matrix Multiply on Multithreaded Architectures Bryan Marker 1, Field G Van Zee 1, Kazushige Goto 1, Gregorio Quintana Ortí 2, and Robert A van de Geijn 1 1 The University of Texas at Austin
Algorithms and architectures for N-body methods
 Algorithms and architectures for N-body methods George Biros XPS-DSD CCF-1337393 A2MA - Algorithms and Architectures for Multiresolution Applications 2014-2017 Outline Significance Sketch or algorithm
Algorithms and architectures for N-body methods George Biros XPS-DSD CCF-1337393 A2MA - Algorithms and Architectures for Multiresolution Applications 2014-2017 Outline Significance Sketch or algorithm
Dealing with Asymmetry for Performance and Energy Efficiency
 Dealing with Asymmetryfor Performance and Energy Efficiency Enrique S. QUINTANA-ORTÍ Motivation Moore s law is alive, but Dennard s scaling is over Motivation Welcome dark silicon and asymmetric architectures
Dealing with Asymmetryfor Performance and Energy Efficiency Enrique S. QUINTANA-ORTÍ Motivation Moore s law is alive, but Dennard s scaling is over Motivation Welcome dark silicon and asymmetric architectures
Scheduling of QR Factorization Algorithms on SMP and Multi-core Architectures
 Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
The Basic Linear Algebra Subprograms (BLAS) are an interface to commonly used fundamental linear algebra operations.
 are an interface to commonly used fundamental linear algebra operations.") TITLE Basic Linear Algebra Subprograms BYLINE Robert A. van de Geijn Department of Computer Science The University of Texas at Austin Austin, TX USA rvdg@cs.utexas.edu Kazushige Goto Texas Advanced Computing
TITLE Basic Linear Algebra Subprograms BYLINE Robert A. van de Geijn Department of Computer Science The University of Texas at Austin Austin, TX USA rvdg@cs.utexas.edu Kazushige Goto Texas Advanced Computing
LINPACK Benchmark. on the Fujitsu AP The LINPACK Benchmark. Assumptions. A popular benchmark for floating-point performance. Richard P.
 1 2 The LINPACK Benchmark on the Fujitsu AP 1000 Richard P. Brent Computer Sciences Laboratory The LINPACK Benchmark A popular benchmark for floating-point performance. Involves the solution of a nonsingular
1 2 The LINPACK Benchmark on the Fujitsu AP 1000 Richard P. Brent Computer Sciences Laboratory The LINPACK Benchmark A popular benchmark for floating-point performance. Involves the solution of a nonsingular
High-Performance Libraries and Tools. HPC Fall 2012 Prof. Robert van Engelen
 High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
Mixed Data Layout Kernels for Vectorized Complex Arithmetic
 Mixed Data Layout Kernels for Vectorized Complex Arithmetic Doru T. Popovici, Franz Franchetti, Tze Meng Low Department of Electrical and Computer Engineering Carnegie Mellon University Email: {dpopovic,
Mixed Data Layout Kernels for Vectorized Complex Arithmetic Doru T. Popovici, Franz Franchetti, Tze Meng Low Department of Electrical and Computer Engineering Carnegie Mellon University Email: {dpopovic,
Automatically Tuned Linear Algebra Software (ATLAS) R. Clint Whaley Innovative Computing Laboratory University of Tennessee.
 R. Clint Whaley Innovative Computing Laboratory University of Tennessee.") Automatically Tuned Linear Algebra Software (ATLAS) R. Clint Whaley Innovative Computing Laboratory University of Tennessee Outline Pre-intro: BLAS Motivation What is ATLAS Present release How ATLAS works
Automatically Tuned Linear Algebra Software (ATLAS) R. Clint Whaley Innovative Computing Laboratory University of Tennessee Outline Pre-intro: BLAS Motivation What is ATLAS Present release How ATLAS works
Level-3 BLAS on the TI C6678 multi-core DSP
 Level-3 BLAS on the TI C6678 multi-core DSP Murtaza Ali, Eric Stotzer Texas Instruments {mali,estotzer}@ti.com Francisco D. Igual Dept. Arquitectura de Computadores y Automática Univ. Complutense de Madrid
Level-3 BLAS on the TI C6678 multi-core DSP Murtaza Ali, Eric Stotzer Texas Instruments {mali,estotzer}@ti.com Francisco D. Igual Dept. Arquitectura de Computadores y Automática Univ. Complutense de Madrid
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
A Square Block Format for Symmetric Band Matrices
 A Square Block Format for Symmetric Band Matrices Fred G. Gustavson 1, José R. Herrero 2, E. Morancho 2 1 IBM T.J. Watson Research Center, Emeritus, and Umeå University fg2935@hotmail.com 2 Computer Architecture
A Square Block Format for Symmetric Band Matrices Fred G. Gustavson 1, José R. Herrero 2, E. Morancho 2 1 IBM T.J. Watson Research Center, Emeritus, and Umeå University fg2935@hotmail.com 2 Computer Architecture
Towards ABFT for BLIS GEMM
 Towards ABFT for BLIS GEMM FLAME Working Note #76 Tyler M. Smith Robert A. van de Geijn Mikhail Smelyanskiy Enrique S. Quintana-Ortí Originally published June 13, 2015 Revised November 5, 2015 Abstract
Towards ABFT for BLIS GEMM FLAME Working Note #76 Tyler M. Smith Robert A. van de Geijn Mikhail Smelyanskiy Enrique S. Quintana-Ortí Originally published June 13, 2015 Revised November 5, 2015 Abstract
Hierarchical Decompositions of Kernel Matrices
 Hierarchical Decompositions of Kernel Matrices Bill March UT Austin On the job market! Dec. 12, 2015 Joint work with Bo Xiao, Chenhan Yu, Sameer Tharakan, and George Biros Kernel Matrix Approximation Inputs:
Hierarchical Decompositions of Kernel Matrices Bill March UT Austin On the job market! Dec. 12, 2015 Joint work with Bo Xiao, Chenhan Yu, Sameer Tharakan, and George Biros Kernel Matrix Approximation Inputs:
Programming Dense Linear Algebra Kernels on Vectorized Architectures
 University of Tennessee, Knoxville Trace: Tennessee Research and Creative Exchange Masters Theses Graduate School 5-2013 Programming Dense Linear Algebra Kernels on Vectorized Architectures Jonathan Lawrence
University of Tennessee, Knoxville Trace: Tennessee Research and Creative Exchange Masters Theses Graduate School 5-2013 Programming Dense Linear Algebra Kernels on Vectorized Architectures Jonathan Lawrence
Evaluation and Tuning of the Level 3 CUBLAS for Graphics Processors
 Evaluation and Tuning of the Level 3 CUBLAS for Graphics Processors Sergio Barrachina Maribel Castillo Francisco D. Igual Rafael Mayo Enrique S. Quintana-Ortí Depto. de Ingeniería y Ciencia de Computadores
Evaluation and Tuning of the Level 3 CUBLAS for Graphics Processors Sergio Barrachina Maribel Castillo Francisco D. Igual Rafael Mayo Enrique S. Quintana-Ortí Depto. de Ingeniería y Ciencia de Computadores
SuperMatrix on Heterogeneous Platforms. Jianyu Huang SHPC, UT Austin
 SuperMatrix on Heterogeneous Platforms Jianyu Huang SHPC, U Austin 1 How Heterogeneous? 2 How Many Languages? 3 How Many Languages? 3 Question! 4 FLAME Answer: SuperMatrix libflame SuperMatrix clblas OpenCL
SuperMatrix on Heterogeneous Platforms Jianyu Huang SHPC, U Austin 1 How Heterogeneous? 2 How Many Languages? 3 How Many Languages? 3 Question! 4 FLAME Answer: SuperMatrix libflame SuperMatrix clblas OpenCL
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends
 Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
Anatomy of High-Performance Matrix Multiplication
 12 Anatomy of High-Performance Matrix Multiplication KAZUSHIGE GOTO and ROBERT A. VAN DE GEIJN The University of Texas at Austin We present the basic principles that underlie the high-performance implementation
12 Anatomy of High-Performance Matrix Multiplication KAZUSHIGE GOTO and ROBERT A. VAN DE GEIJN The University of Texas at Austin We present the basic principles that underlie the high-performance implementation
Level-3 BLAS on a GPU: Picking the Low Hanging Fruit
 Level-3 BLAS on a GPU: Picking the Low Hanging Fruit Francisco D. Igual Gregorio Quintana-Ortí Depto. de Ingeniería y Ciencia de Computadores Universidad Jaume I 12.071 Castellón Spain {figualgquintan}@icc.uji.es
Level-3 BLAS on a GPU: Picking the Low Hanging Fruit Francisco D. Igual Gregorio Quintana-Ortí Depto. de Ingeniería y Ciencia de Computadores Universidad Jaume I 12.071 Castellón Spain {figualgquintan}@icc.uji.es
arxiv: v1 [cs.ms] 24 Aug 2018
![arxiv: v1 [cs.ms] 24 Aug 2018](/thumbs/92/109655859.jpg "arxiv: v1 [cs.ms] 24 Aug 2018") Implementing Strassen s Algorithm with CUTLASS on NVIDIA Volta GPUs FLAME Working Note #88 arxiv:1808.07984v1 [cs.ms] 24 Aug 2018 Jianyu Huang *, Chenhan D. Yu *, Robert A. van de Geijn * * Department
Implementing Strassen s Algorithm with CUTLASS on NVIDIA Volta GPUs FLAME Working Note #88 arxiv:1808.07984v1 [cs.ms] 24 Aug 2018 Jianyu Huang *, Chenhan D. Yu *, Robert A. van de Geijn * * Department
Performance Evaluation of BLAS on a Cluster of Multi-Core Intel Processors
 Performance Evaluation of BLAS on a Cluster of Multi-Core Intel Processors Mostafa I. Soliman and Fatma S. Ahmed Computers and Systems Section, Electrical Engineering Department Aswan Faculty of Engineering,
Performance Evaluation of BLAS on a Cluster of Multi-Core Intel Processors Mostafa I. Soliman and Fatma S. Ahmed Computers and Systems Section, Electrical Engineering Department Aswan Faculty of Engineering,
Naïve (1) CS 6354: Memory Hierarchy III. Goto Fig. 4. Naïve (2)
 CS 6354: Memory Hierarchy III. Goto Fig. 4. Naïve (2)") Naïve (1) CS 6354: Memory Hierarchy III 5 September 2016 for (int i = 0; i < I; ++i) { for (int j = 0; j < J; ++j) { for (int k = 0; k < K; ++k) { C[i * K + k] += A[i * J + j] * B[j * K + k]; 1 2 Naïve
Naïve (1) CS 6354: Memory Hierarchy III 5 September 2016 for (int i = 0; i < I; ++i) { for (int j = 0; j < J; ++j) { for (int k = 0; k < K; ++k) { C[i * K + k] += A[i * J + j] * B[j * K + k]; 1 2 Naïve
Optimizations of BLIS Library for AMD ZEN Core
 Optimizations of BLIS Library for AMD ZEN Core 1 Introduction BLIS [1] is a portable software framework for instantiating high-performance BLAS-like dense linear algebra libraries [2] The framework was
Optimizations of BLIS Library for AMD ZEN Core 1 Introduction BLIS [1] is a portable software framework for instantiating high-performance BLAS-like dense linear algebra libraries [2] The framework was
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments
 Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
High performance matrix inversion of SPD matrices on graphics processors
 High performance matrix inversion of SPD matrices on graphics processors Peter Benner, Pablo Ezzatti, Enrique S. Quintana-Ortí and Alfredo Remón Max-Planck-Institute for Dynamics of Complex Technical Systems
High performance matrix inversion of SPD matrices on graphics processors Peter Benner, Pablo Ezzatti, Enrique S. Quintana-Ortí and Alfredo Remón Max-Planck-Institute for Dynamics of Complex Technical Systems
Integrating DMA capabilities into BLIS for on-chip data movement. Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali
 Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
BLASFEO. Gianluca Frison. BLIS retreat September 19, University of Freiburg
 University of Freiburg BLIS retreat September 19, 217 Basic Linear Algebra Subroutines For Embedded Optimization performance dgemm_nt 5 4 Intel Core i7 48MQ HP OpenBLAS.2.19 MKL 217.2.174 ATLAS 3.1.3 BLIS.1.6
University of Freiburg BLIS retreat September 19, 217 Basic Linear Algebra Subroutines For Embedded Optimization performance dgemm_nt 5 4 Intel Core i7 48MQ HP OpenBLAS.2.19 MKL 217.2.174 ATLAS 3.1.3 BLIS.1.6
Automatic Derivation of Linear Algebra Algorithms with Application to Control Theory
 Automatic Derivation of Linear Algebra Algorithms with Application to Control Theory Paolo Bientinesi Sergey Kolos 2 and Robert van de Geijn Department of Computer Sciences The University of Texas at Austin
Automatic Derivation of Linear Algebra Algorithms with Application to Control Theory Paolo Bientinesi Sergey Kolos 2 and Robert van de Geijn Department of Computer Sciences The University of Texas at Austin
CS Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra
 CS 294-73 Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra Slides from James Demmel and Kathy Yelick 1 Outline What is Dense Linear Algebra? Where does the time go in an algorithm?
CS 294-73 Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra Slides from James Demmel and Kathy Yelick 1 Outline What is Dense Linear Algebra? Where does the time go in an algorithm?
Minimizing Computation in Convolutional Neural Networks
 Minimizing Computation in Convolutional Neural Networks Jason Cong and Bingjun Xiao Computer Science Department, University of California, Los Angeles, CA 90095, USA {cong,xiao}@cs.ucla.edu Abstract. Convolutional
Minimizing Computation in Convolutional Neural Networks Jason Cong and Bingjun Xiao Computer Science Department, University of California, Los Angeles, CA 90095, USA {cong,xiao}@cs.ucla.edu Abstract. Convolutional
Using recursion to improve performance of dense linear algebra software. Erik Elmroth Dept of Computing Science & HPC2N Umeå University, Sweden
 Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
Task based parallelization of recursive linear algebra routines using Kaapi
 Task based parallelization of recursive linear algebra routines using Kaapi Clément PERNET joint work with Jean-Guillaume DUMAS and Ziad SULTAN Université Grenoble Alpes, LJK-CASYS January 20, 2017 Journée
Task based parallelization of recursive linear algebra routines using Kaapi Clément PERNET joint work with Jean-Guillaume DUMAS and Ziad SULTAN Université Grenoble Alpes, LJK-CASYS January 20, 2017 Journée
A MATLAB Interface to the GPU
 Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
A Standard for Batching BLAS Operations
 A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
COMPUTATIONAL LINEAR ALGEBRA
 COMPUTATIONAL LINEAR ALGEBRA Matrix Vector Multiplication Matrix matrix Multiplication Slides from UCSD and USB Directed Acyclic Graph Approach Jack Dongarra A new approach using Strassen`s algorithm Jim
COMPUTATIONAL LINEAR ALGEBRA Matrix Vector Multiplication Matrix matrix Multiplication Slides from UCSD and USB Directed Acyclic Graph Approach Jack Dongarra A new approach using Strassen`s algorithm Jim
Analytical Models for the BLIS Framework
 Analytical Models for the BLIS Framework FLAME Working Note #74 Tze Meng Low 1, Francisco D. Igual 2, Tyler M. Smith 1, and Enrique S. Quintana-Orti 3 1 The University of Texas at Austin 2 Universidad
Analytical Models for the BLIS Framework FLAME Working Note #74 Tze Meng Low 1, Francisco D. Igual 2, Tyler M. Smith 1, and Enrique S. Quintana-Orti 3 1 The University of Texas at Austin 2 Universidad
EXPERIMENTS WITH STRASSEN S ALGORITHM: FROM SEQUENTIAL TO PARALLEL
 EXPERIMENTS WITH STRASSEN S ALGORITHM: FROM SEQUENTIAL TO PARALLEL Fengguang Song, Jack Dongarra, and Shirley Moore Computer Science Department University of Tennessee Knoxville, Tennessee 37996, USA email:
EXPERIMENTS WITH STRASSEN S ALGORITHM: FROM SEQUENTIAL TO PARALLEL Fengguang Song, Jack Dongarra, and Shirley Moore Computer Science Department University of Tennessee Knoxville, Tennessee 37996, USA email:
Dense matrix algebra and libraries (and dealing with Fortran)
") Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Tools and Primitives for High Performance Graph Computation
 Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
A Few Numerical Libraries for HPC
 A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
Fast and reliable linear system solutions on new parallel architectures
 Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
The BLIS Framework: Experiments in Portability
 The BLIS Framewor: Experiments in Portability FIELD G. VAN ZEE, TYLER M. SMITH, BRYAN MARKER, TZE MENG LOW, ROBERT A. VAN DE GEIJN, The University of Texas at Austin FRANCISCO D. IGUAL, Univ. Complutense
The BLIS Framewor: Experiments in Portability FIELD G. VAN ZEE, TYLER M. SMITH, BRYAN MARKER, TZE MENG LOW, ROBERT A. VAN DE GEIJN, The University of Texas at Austin FRANCISCO D. IGUAL, Univ. Complutense
Bindel, Fall 2011 Applications of Parallel Computers (CS 5220) Tuning on a single core
 Tuning on a single core") Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
arxiv: v1 [cs.ms] 17 Jan 2019
![arxiv: v1 [cs.ms] 17 Jan 2019](/thumbs/88/117727954.jpg "arxiv: v1 [cs.ms] 17 Jan 2019") Supporting mixed-datatype matrix multiplication within the BLIS framework FLAME Working Note #89 Field G. Van Zee a,b, Devangi N. Parikh a, Robert A. van de Geijn a,b arxiv:191.61v1 [cs.ms] 17 Jan 19 a
Supporting mixed-datatype matrix multiplication within the BLIS framework FLAME Working Note #89 Field G. Van Zee a,b, Devangi N. Parikh a, Robert A. van de Geijn a,b arxiv:191.61v1 [cs.ms] 17 Jan 19 a
LAFF-On High-Performance Programming
 LAFF-On High-Performance Programming Margaret E Myers Robert A van de Geijn Release Date Wednesday 20 th December, 2017 This is a work in progress Copyright 2017, 2018 by Margaret E Myers and Robert A
LAFF-On High-Performance Programming Margaret E Myers Robert A van de Geijn Release Date Wednesday 20 th December, 2017 This is a work in progress Copyright 2017, 2018 by Margaret E Myers and Robert A
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Underutilizing Resources for HPC on Clouds
 Aachen Institute for Advanced Study in Computational Engineering Science Preprint: AICES-21/6-1 1/June/21 Underutilizing Resources for HPC on Clouds R. Iakymchuk, J. Napper and P. Bientinesi Financial
Aachen Institute for Advanced Study in Computational Engineering Science Preprint: AICES-21/6-1 1/June/21 Underutilizing Resources for HPC on Clouds R. Iakymchuk, J. Napper and P. Bientinesi Financial
INTEL MKL Vectorized Compact routines
 INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
2 Fred G. Gustavson, Jerzy Waśniewski and Jack J. Dongarra a. Lower Packed Format fi 2
 Level-3 Cholesky Kernel Subroutine of a Fully Portable High Performance Minimal Storage Hybrid Format Cholesky Algorithm Fred G. Gustavson IBM T.J. Watson Research Center and Jerzy Waśniewski Department
Level-3 Cholesky Kernel Subroutine of a Fully Portable High Performance Minimal Storage Hybrid Format Cholesky Algorithm Fred G. Gustavson IBM T.J. Watson Research Center and Jerzy Waśniewski Department
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Faster Code for Free: Linear Algebra Libraries. Advanced Research Compu;ng 22 Feb 2017
 Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
NUMA-aware Multicore Matrix Multiplication
 Parallel Processing Letters c World Scientific Publishing Company NUMA-aware Multicore Matrix Multiplication WAIL Y. ALKOWAILEET Department of Computer Science (Systems), University of California, Irvine,
Parallel Processing Letters c World Scientific Publishing Company NUMA-aware Multicore Matrix Multiplication WAIL Y. ALKOWAILEET Department of Computer Science (Systems), University of California, Irvine,
A High Performance Parallel Strassen Implementation. Brian Grayson. The University of Texas at Austin.
 A High Performance Parallel Strassen Implementation Brian Grayson Department of Electrical and Computer Engineering The University of Texas at Austin Austin, TX 787 bgrayson@pineeceutexasedu Ajay Pankaj
A High Performance Parallel Strassen Implementation Brian Grayson Department of Electrical and Computer Engineering The University of Texas at Austin Austin, TX 787 bgrayson@pineeceutexasedu Ajay Pankaj
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL
 SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
Optimizing Cache Performance in Matrix Multiplication. UCSB CS240A, 2017 Modified from Demmel/Yelick s slides
 Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Efficient Recursive Implementations for Linear Algebra Operations
 Efficient Recursive Implementations for Linear Algebra Operations Ryma Mahfoudhi, Samy Achour 2, Zaher Mahjoub 3 University of Tunis El Manar, Faculty of Sciences of Tunis University Campus - 2092 Manar
Efficient Recursive Implementations for Linear Algebra Operations Ryma Mahfoudhi, Samy Achour 2, Zaher Mahjoub 3 University of Tunis El Manar, Faculty of Sciences of Tunis University Campus - 2092 Manar
Unleashing the Power of Multi-GPU Accelerators with FLAME
 Unleashing the Power of Multi-GPU Accelerators with FLAME Enrique S. Quintana Ortí Universidad Jaume I quintana@icc.uji.es SIAM Conference on Parallel Processing for Scientific Computing Seattle, 2010
Unleashing the Power of Multi-GPU Accelerators with FLAME Enrique S. Quintana Ortí Universidad Jaume I quintana@icc.uji.es SIAM Conference on Parallel Processing for Scientific Computing Seattle, 2010
PRACE PATC Course: Intel MIC Programming Workshop, MKL. Ostrava,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
Implementing high-performance complex matrix multiplication via the 1m method
 0 Implementing high-performance complex matrix multiplication via the 1m method FIELD G. VAN ZEE, The University of Texas at Austin In this article, we continue exploring the topic of so-called induced
0 Implementing high-performance complex matrix multiplication via the 1m method FIELD G. VAN ZEE, The University of Texas at Austin In this article, we continue exploring the topic of so-called induced
Porting BLIS to new architectures Early experiences
 1st BLIS Retreat. Austin (Texas) Early experiences Universidad Complutense de Madrid (Spain) September 5, 2013 BLIS design principles BLIS = Programmability + Performance + Portability Share experiences
1st BLIS Retreat. Austin (Texas) Early experiences Universidad Complutense de Madrid (Spain) September 5, 2013 BLIS design principles BLIS = Programmability + Performance + Portability Share experiences
Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System
 Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System Allan Richmond R. Morales, Chong Tian, Kwai Wong, Eduardo D Azevedo The George Washington University, The Chinese University
Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System Allan Richmond R. Morales, Chong Tian, Kwai Wong, Eduardo D Azevedo The George Washington University, The Chinese University
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy
 On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
Double-precision General Matrix Multiply (DGEMM)
") Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
How to Write Fast Numerical Code Spring 2012 Lecture 9. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 9 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Today Linear algebra software: history, LAPACK and BLAS Blocking (BLAS 3): key
How to Write Fast Numerical Code Spring 2012 Lecture 9 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Today Linear algebra software: history, LAPACK and BLAS Blocking (BLAS 3): key
A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve
 A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve A. N. Yzelman and Rob H. Bisseling Abstract The sparse matrix vector (SpMV) multiplication is an important kernel
A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve A. N. Yzelman and Rob H. Bisseling Abstract The sparse matrix vector (SpMV) multiplication is an important kernel
A Simple and Practical Linear Algebra Library Interface with Static Size Checking
 OCaml 2014 in Sweden (presented at ML 2014) A Simple and Practical Linear Algebra Library Interface with Static Size Checking Akinori Abe Eijiro Sumii Graduate School of Information Sciences Tohoku University
OCaml 2014 in Sweden (presented at ML 2014) A Simple and Practical Linear Algebra Library Interface with Static Size Checking Akinori Abe Eijiro Sumii Graduate School of Information Sciences Tohoku University
Effective Implementation of DGEMM on modern multicore CPU
 Available online at www.sciencedirect.com Procedia Computer Science 9 (2012 ) 126 135 International Conference on Computational Science, ICCS 2012 Effective Implementation of DGEMM on modern multicore
Available online at www.sciencedirect.com Procedia Computer Science 9 (2012 ) 126 135 International Conference on Computational Science, ICCS 2012 Effective Implementation of DGEMM on modern multicore
Analysis of Matrix Multiplication Computational Methods
 European Journal of Scientific Research ISSN 1450-216X / 1450-202X Vol.121 No.3, 2014, pp.258-266 http://www.europeanjournalofscientificresearch.com Analysis of Matrix Multiplication Computational Methods
European Journal of Scientific Research ISSN 1450-216X / 1450-202X Vol.121 No.3, 2014, pp.258-266 http://www.europeanjournalofscientificresearch.com Analysis of Matrix Multiplication Computational Methods
The BLIS Framework: Experiments in Portability
 The BLIS Framewor: Experiments in Portability FIELD G. VAN ZEE, TYLER SMITH, BRYAN MARKER, TZE MENG LOW, ROBERT A. VAN DE GEIJN, The University of Texas at Austin FRANCISCO D. IGUAL, Univ. Complutense
The BLIS Framewor: Experiments in Portability FIELD G. VAN ZEE, TYLER SMITH, BRYAN MARKER, TZE MENG LOW, ROBERT A. VAN DE GEIJN, The University of Texas at Austin FRANCISCO D. IGUAL, Univ. Complutense
Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory
 Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory Jongsoo Park, Parallel Computing Lab, Intel Corporation with contributions from MKL team 1 Algorithm/
Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory Jongsoo Park, Parallel Computing Lab, Intel Corporation with contributions from MKL team 1 Algorithm/
Accelerating GPU Kernels for Dense Linear Algebra
 Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Beautiful Parallel Code: Evolution vs. Intelligent Design
 Beautiful Parallel Code: Evolution vs. Intelligent Design FLAME Working Note #34 Robert A. van de Geijn Department of Computer Sciences The University of Texas at Austin Austin, Texas 7872 rvdg@cs.utexas.edu
Beautiful Parallel Code: Evolution vs. Intelligent Design FLAME Working Note #34 Robert A. van de Geijn Department of Computer Sciences The University of Texas at Austin Austin, Texas 7872 rvdg@cs.utexas.edu
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Dense linear algebra, LAPACK, MMM optimizations in ATLAS Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Today Linear algebra software: history,
How to Write Fast Numerical Code Lecture: Dense linear algebra, LAPACK, MMM optimizations in ATLAS Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Today Linear algebra software: history,
Accelerating GPU kernels for dense linear algebra
 Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
*Yuta SAWA and Reiji SUDA The University of Tokyo
 Auto Tuning Method for Deciding Block Size Parameters in Dynamically Load-Balanced BLAS *Yuta SAWA and Reiji SUDA The University of Tokyo iwapt 29 October 1-2 *Now in Central Research Laboratory, Hitachi,
Auto Tuning Method for Deciding Block Size Parameters in Dynamically Load-Balanced BLAS *Yuta SAWA and Reiji SUDA The University of Tokyo iwapt 29 October 1-2 *Now in Central Research Laboratory, Hitachi,
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
BLAS: Basic Linear Algebra Subroutines I
 BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
Implementing Level-3 BLAS Routines in OpenCL on Different Processing Units
 Technical Report 2014-001 Implementing Level-3 BLAS Routines in OpenCL on Different Processing Units Kazuya Matsumoto, Naohito Nakasato, and Stanislav Sedukhin October 22, 2014 Graduate School of Computer
Technical Report 2014-001 Implementing Level-3 BLAS Routines in OpenCL on Different Processing Units Kazuya Matsumoto, Naohito Nakasato, and Stanislav Sedukhin October 22, 2014 Graduate School of Computer
Algorithm Engineering
 Algorithm Engineering Paolo D Alberto Electrical and Computer Engineering Carnegie Mellon University Personal Research Background Embedded and High Performance Computing Compiler: Static and Dynamic Theory
Algorithm Engineering Paolo D Alberto Electrical and Computer Engineering Carnegie Mellon University Personal Research Background Embedded and High Performance Computing Compiler: Static and Dynamic Theory
IMPLEMENTATION OF AN OPTIMAL MATRIX-CHAIN PRODUCT EXPLOITING MATRIX SPECIALIZATION
 IMPLEMENTATION OF AN OPTIMAL MATRIX-CHAIN PRODUCT EXPLOITING MATRIX SPECIALIZATION Swetha Kukkala and Andrew A. Anda Computer Science Department St Cloud State University St Cloud, MN 56301 kusw0601@stcloudstate.edu
IMPLEMENTATION OF AN OPTIMAL MATRIX-CHAIN PRODUCT EXPLOITING MATRIX SPECIALIZATION Swetha Kukkala and Andrew A. Anda Computer Science Department St Cloud State University St Cloud, MN 56301 kusw0601@stcloudstate.edu
The M4RI & M4RIE libraries for linear algebra over F 2 and small extensions
 The M4RI & M4RIE libraries for linear algebra over F 2 and small extensions Martin R. Albrecht Nancy, March 30, 2011 Outline M4RI Introduction Multiplication Elimination M4RIE Introduction Travolta Tables
The M4RI & M4RIE libraries for linear algebra over F 2 and small extensions Martin R. Albrecht Nancy, March 30, 2011 Outline M4RI Introduction Multiplication Elimination M4RIE Introduction Travolta Tables
Auto-tuning a Matrix Routine for High Performance. Rune E. Jensen Ian Karlin Anne C. Elster
 Auto-tuning a Matrix Routine for High Performance Rune E. Jensen Ian Karlin Anne C. Elster (runeerle,iank,elster)@idi.ntnu.no Abstract Well-written scientific simulations typically get tremendous performance
Auto-tuning a Matrix Routine for High Performance Rune E. Jensen Ian Karlin Anne C. Elster (runeerle,iank,elster)@idi.ntnu.no Abstract Well-written scientific simulations typically get tremendous performance
Cache Oblivious Dense and Sparse Matrix Multiplication Based on Peano Curves
 Cache Oblivious Dense and Sparse Matrix Multiplication Based on eano Curves Michael Bader and Alexander Heinecke Institut für Informatik, Technische Universitüt München, Germany Abstract. Cache oblivious
Cache Oblivious Dense and Sparse Matrix Multiplication Based on eano Curves Michael Bader and Alexander Heinecke Institut für Informatik, Technische Universitüt München, Germany Abstract. Cache oblivious
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
arxiv: v3 [cs.ms] 7 Jan 2018
![arxiv: v3 [cs.ms] 7 Jan 2018](/thumbs/77/76170604.jpg "arxiv: v3 [cs.ms] 7 Jan 2018") BLASFEO: basic linear algebra subroutines for embedded optimization Gianluca Frison, Dimitris Kouzoupis, Tommaso Sartor, Andrea Zanelli, Moritz Diehl University of Freiburg, Department of Microsystems
BLASFEO: basic linear algebra subroutines for embedded optimization Gianluca Frison, Dimitris Kouzoupis, Tommaso Sartor, Andrea Zanelli, Moritz Diehl University of Freiburg, Department of Microsystems
Neural Network Assisted Tile Size Selection
 Neural Network Assisted Tile Size Selection Mohammed Rahman, Louis-Noël Pouchet and P. Sadayappan Dept. of Computer Science and Engineering Ohio State University June 22, 2010 iwapt 2010 Workshop Berkeley,
Neural Network Assisted Tile Size Selection Mohammed Rahman, Louis-Noël Pouchet and P. Sadayappan Dept. of Computer Science and Engineering Ohio State University June 22, 2010 iwapt 2010 Workshop Berkeley,
OpenMP * Past, Present and Future
 OpenMP * Past, Present and Future Tim Mattson Intel Corporation Microprocessor Technology Labs timothy.g.mattson@intel.com * The name OpenMP is the property of the OpenMP Architecture Review Board. 1 OpenMP
OpenMP * Past, Present and Future Tim Mattson Intel Corporation Microprocessor Technology Labs timothy.g.mattson@intel.com * The name OpenMP is the property of the OpenMP Architecture Review Board. 1 OpenMP
Parallel Reduction from Block Hessenberg to Hessenberg using MPI
 Parallel Reduction from Block Hessenberg to Hessenberg using MPI Viktor Jonsson May 24, 2013 Master s Thesis in Computing Science, 30 credits Supervisor at CS-UmU: Lars Karlsson Examiner: Fredrik Georgsson
Parallel Reduction from Block Hessenberg to Hessenberg using MPI Viktor Jonsson May 24, 2013 Master s Thesis in Computing Science, 30 credits Supervisor at CS-UmU: Lars Karlsson Examiner: Fredrik Georgsson
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
BLAS. Christoph Ortner Stef Salvini
 BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
Towards an Efficient Tile Matrix Inversion of Symmetric Positive Definite Matrices on Multicore Architectures
 Towards an Efficient Tile Matrix Inversion of Symmetric Positive Definite Matrices on Multicore Architectures Emmanuel Agullo 1, Henricus Bouwmeester 2, Jack Dongarra 1, Jakub Kurzak 1, Julien Langou 2,andLeeRosenberg
Towards an Efficient Tile Matrix Inversion of Symmetric Positive Definite Matrices on Multicore Architectures Emmanuel Agullo 1, Henricus Bouwmeester 2, Jack Dongarra 1, Jakub Kurzak 1, Julien Langou 2,andLeeRosenberg
1 Motivation for Improving Matrix Multiplication
 CS170 Spring 2007 Lecture 7 Feb 6 1 Motivation for Improving Matrix Multiplication Now we will just consider the best way to implement the usual algorithm for matrix multiplication, the one that take 2n
CS170 Spring 2007 Lecture 7 Feb 6 1 Motivation for Improving Matrix Multiplication Now we will just consider the best way to implement the usual algorithm for matrix multiplication, the one that take 2n
Sparse Direct Solvers for Extreme-Scale Computing
 Sparse Direct Solvers for Extreme-Scale Computing Iain Duff Joint work with Florent Lopez and Jonathan Hogg STFC Rutherford Appleton Laboratory SIAM Conference on Computational Science and Engineering
Sparse Direct Solvers for Extreme-Scale Computing Iain Duff Joint work with Florent Lopez and Jonathan Hogg STFC Rutherford Appleton Laboratory SIAM Conference on Computational Science and Engineering