GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
|
|
|
- Job Stewart
- 5 years ago
- Views:
Transcription

1 GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA
2 WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization Distributed- and shared-memory algorithms Scalable, employs theoretically most scalable factorization algorithm Uses multifrontal method This work concentrates on accelerating numerical factorization phase
3 OBJECTIVE Acceleration of WSMP Demonstrate suitability of GPUs for Sparse Direct Solves Demonstrate suitability of GPUs for very irregular workloads Evaluate methods for accelerating WSMP Simple methods can work well More sophisticated methods can work better
4 OUTLINE Minimally invasive acceleration of BLAS-intensive applications High level interface Acceleration techniques MPI acceleration
5 GPU ACCELERATION: MINIMALLY INVASIVE APPROACH Intercepting BLAS level 3 calls with big dimensions and sending them to GPU Tiling to hide copies CPU H2D Kernel D2H CPU CPU CPU time PCIe and host memory bandwidth are limiting But many of the matrices are not big enough to be tiled (sizes)
6 GPU ACCELERATION: MINIMALLY INVASIVE APPROACH We are intercepting simultaneous moderate-size calls each one is not big enough to fully occupy GPU Use streams to Increase GPU utilization Hide copy-up and copy-down Kernels may overlap Thread 0 Thread 1 Thread 2 Thread 3 CPU CPU CPU CPU CPU CPU CPU CPU
7 GPU ACCELERATION: MINIMALLY INVASIVE APPROACH Use host pinned buffers to increase copy-up/copy-down speed and enable asynchronous memory copies Send small BLAS calls to the CPU (m,n<128, k<512) Large matrices are tiled individually Can be used with ANY application, not just WSMP No recompilation of the code required
8 RESULTS SYSTEM USED Dual-socket Ivy-Bridge 3.0 Ghz 20 cores total, PCIe gen3, E v2 Tesla K40, ECC on Intel MKL for host BLAS calls CUDA 6.5 Standard cublas routines are used for BLAS and BLAS-Like.
9 Performance, Gflops/s RESULTS DROP-IN GPU ACCELERATION x CPU Drop-in x Xeon E v2 + K40 (max boost, ECC=on)
10 SPARSE DIRECT SOLVERS Supernodes collections of columns with similar non-zero pattern provide opportunity for dense matrix math grow with mesh size due to fill The larger the model, the larger the supernodes Supernodes in the factors are detected during symbolic factorization
11 DENSE BLOCK CHOLESKY Basis for sparse direct algorithms L 11 L t 11 = A 11 L 21 L t 11 = A 21 A * 22 = A 22 L 21 L t 21 Emphasizes dense math Dominated by computation of Schur complement POTRF TRSM SYRK POTRF element-wise Cholesky factorization A 11 A t 21 A 21 A 22 L 11 0 I 0 L t 11 = X X L 21 I 0 A 22 L 21 L t 21 GEMM L t 21 0 I TRSM triangular solve Schur complement
12 PARALLEL MULTIFRONTAL METHOD A task that owns the supernode Assembles frontal matrix Factors the supernode Computes update frontal matrix, that will be used by the parent task In the beginning, many independent supernodes to be factored by parallel threads In the end, threads cooperate on the factorization of fewer remaining supernodes
13 POTENTIAL FOR IMPROVEMENT Potentially big BLAS calls are split into smaller ones, hurting performance Same data is moved back and forth many times A lot of pressure on PCIe for data movement A lot of pressure on host memory bandwidth A few GB of memory allocated on the device and has to be pinned on the host
14 SOLUTION HIGH LEVEL INTERFACE Most of the work in Cholesky factorization is performed in dtrsmsyrk calls (dtrsm followed by dsyrk) Bigger BLAS dimensions are more favorable for the GPU Big dtrsmsyrk calls are sent to GPU (inner dimension >= 512) Still need to hide data transfer, but there is much less data motion between the host and the device Less memory needed on the device, less pinned memory on the host

15 DTRSM IMPLEMENTATION L 21 L 11T =A 21 DTRSM is tiled Tiles and related copies are submitted to different streams Results are kept on the GPU, as they will be needed for dsyrk L 11 Copy is sent to the CPU Host buffers are used for staging host data L 21
16 DSYRK IMPLEMENTATION m A * 22 = A 22 L 21 L t 21 Device Memory dtrsm Host Memory, dsyrk Dsyrk is tiled Different tiles and related copies are submitted to the different streams L 21 L 21 t result is sent to host buffer On the host update A 22 - L 21 L 21 t is performed m=384 with 4 streams enough to have GPU occupied
17 TILED DTRSM/DTRSMSYRK A 11 A 21 A 22 B 1, X 1 B 2 When inner dimension of dtrsm is too big, it has to be tiled X 1 is calculated from X 1 A 11T =B 1 as described before dsyrk update is performed if needed B 2 <- B 2 -X 1 A 21T, X 1 is in the GPU memory, B 2 and A 21 are on the CPU Process is repeated for the remainder of the matrix
18 MEMORY REQUIREMENTS For tiled dgemm with at most 2048 by 2048 quad-tiles: 12 tiles, 400 MB For tiled dtrsm-syrk, with at most 2048 by 2048 tiles: 12 tiles, 400 MB Buffer for dtrsm results: With k <= GB is enough for front size up to 61000, bigger fronts can be handled by successive calls to dtrsm and tiled dsyrk Total is less than 2 GB
19 Numerical factorization, Gflops/s RESULTS CPU Drop-in High-level 2 x Xeon E v2 + K40 (max boost, ECC=on)

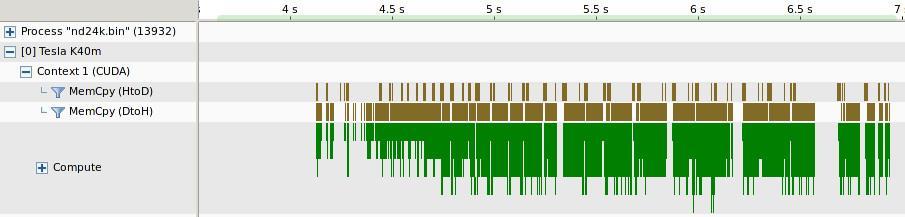
20 PROFILE Drop-in High-level API
21 HIGH LEVEL INTERFACE FOR LDL FACTORIZATION WSMP signals what data is likely to be reused, and it is cached on the GPU
22 LDL T FACTORIZATION 1) L 11 2) 3) L 21 S 21 = L 21 D C=C-S 21 L 21 L 21 L t 11 = A 21 dtrsm scaling (cublasddgmm) symmetric update (cublasdsyrkx) L 21 and S 21 are kept in the GPU memory between operations
23 Numerical Factorization, GFLop/s LDL RESULTS LDL CPU LDL GPU x Xeon E v2 + K40 (max boost, ECC=on)
24 Speed-up SPEEDUP Cholesky LDL Fraction of factorization flops with k>=512
25 DISTRIBUTED MEMORY PARALLEL FACTORIZATION (MPI) Factorization by p processes Best performance when p is power of 2 Factorization of levels below top log p levels is performed by the processes independently Processes cooperate on factoring upper levels of the elimination tree
26 DISTRIBUTED MEMORY PARALLEL FACTORIZATION Update matrices are distributed between processes working on them in a block-cyclic fashion Smaller block size provides better load balancing With bigger block size, efficiency of BLAS3 operations increases
27 DISTRIBUTED MEMORY PARALLEL FACTORIZATION On the GPU block size ideally should be 512 or more Determined by PCIe and host memcopy copy speed Large tiles hurt load balancing For our test system, 512 block size provides best performance
28 CACHING FOR MPI Dtrsm Dgemm Dsyrk results are kept in the GPU cache One of the matrices that is going to be reused is put in the GPU cache in the course of performing dgemm operation One of the matrices are in the GPU cache, another matrix is not reused Matrix can be in the GPU cache from previous operations, or on the host
29 Performance, GFlops/s MPI SCALING RESULTS Serena CPU Serena GPU Audi CPU Audi GPU # of mpi ranks, 10 cores and 1 GPU per rank
30 Factorization Performance, GB/s MPI SCALING ON BLUE WATERS x M10, CPU x M10, GPU M20, CPU M20, GPU Number of cpu cores Blue Waters, AMD Interlagos, 16 CPU cores vs. 8 CPU cores + 1 K20 GPU
31 FUTURE WORK Share the work with CPU now for many models it is idle as almost all work is sent to the GPU Multi-GPU Tuning to automatically set off-load cutoffs for a variety of systems
32 ACKNOWLEDGEMENTS The Private Sector Program at NCSA Blue Waters project, supported by NSF (award number OCI ) and the state of Illinois
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Hierarchical DAG Scheduling for Hybrid Distributed Systems
 June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Accelerating Sparse Cholesky Factorization on GPUs
 Accelerating Sparse Cholesky Factorization on GPUs Submitted to IA 3 Workshop on Irregular Applications: Architectures & Algorithms, to be held Sunday, November 16, 2014, Colorado Convention Center, New
Accelerating Sparse Cholesky Factorization on GPUs Submitted to IA 3 Workshop on Irregular Applications: Architectures & Algorithms, to be held Sunday, November 16, 2014, Colorado Convention Center, New
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement
 Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks
 DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
A GPU Sparse Direct Solver for AX=B
 1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
On the limits of (and opportunities for?) GPU acceleration
 GPU acceleration") On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Automatic Development of Linear Algebra Libraries for the Tesla Series
 Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
NVBLAS LIBRARY. DU _v6.0 February User Guide
 NVBLAS LIBRARY DU-06702-001_v6.0 February 2014 User Guide DU-06702-001_v6.0 2 Chapter 1. INTRODUCTION The is a GPU-accelerated Libary that implements BLAS (Basic Linear Algebra Subprograms). It can accelerate
NVBLAS LIBRARY DU-06702-001_v6.0 February 2014 User Guide DU-06702-001_v6.0 2 Chapter 1. INTRODUCTION The is a GPU-accelerated Libary that implements BLAS (Basic Linear Algebra Subprograms). It can accelerate
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends
 Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
Toward a supernodal sparse direct solver over DAG runtimes
 Toward a supernodal sparse direct solver over DAG runtimes HOSCAR 2013, Bordeaux X. Lacoste Xavier LACOSTE HiePACS team Inria Bordeaux Sud-Ouest November 27, 2012 Guideline Context and goals About PaStiX
Toward a supernodal sparse direct solver over DAG runtimes HOSCAR 2013, Bordeaux X. Lacoste Xavier LACOSTE HiePACS team Inria Bordeaux Sud-Ouest November 27, 2012 Guideline Context and goals About PaStiX
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection
 A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
Issues In Implementing The Primal-Dual Method for SDP. Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM
 Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
A Standard for Batching BLAS Operations
 A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
MAGMA: a New Generation
 1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments
 Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators. Enrique S. Quintana-Ortí
 Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators Enrique S. Quintana-Ortí Disclaimer Not a course on how to program dense linear algebra kernels on s Where have you
Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators Enrique S. Quintana-Ortí Disclaimer Not a course on how to program dense linear algebra kernels on s Where have you
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES. Nikolay Markovskiy Peter Messmer
 GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES Nikolay Markovskiy Peter Messmer ABOUT CP2K Atomistic and molecular simulations of solid state From ab initio DFT and Hartree-Fock
GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES Nikolay Markovskiy Peter Messmer ABOUT CP2K Atomistic and molecular simulations of solid state From ab initio DFT and Hartree-Fock
CUDA 6.0 Performance Report. April 2014
 CUDA 6. Performance Report April 214 1 CUDA 6 Performance Report CUDART CUDA Runtime Library cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse Matrix Library curand Random
CUDA 6. Performance Report April 214 1 CUDA 6 Performance Report CUDART CUDA Runtime Library cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse Matrix Library curand Random
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran. G. Ruetsch, M. Fatica, E. Phillips, N.
 GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS
 NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
Accelerating GPU kernels for dense linear algebra
 Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
rcuda: an approach to provide remote access to GPU computational power
 rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures
 Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures Antoine Petitet et Stefanos Vlachoutsis Juin 2011 Copyright ESI Group, 2009. 2010. All rights reserved.
Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures Antoine Petitet et Stefanos Vlachoutsis Juin 2011 Copyright ESI Group, 2009. 2010. All rights reserved.
Accelerating GPU Kernels for Dense Linear Algebra
 Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication. Steve Rennich Nvidia Developer Technology - Compute
 Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL
 SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
SCALING DGEMM TO MULTIPLE CAYMAN GPUS AND INTERLAGOS MANY-CORE CPUS FOR HPL Matthias Bach and David Rohr Frankfurt Institute for Advanced Studies Goethe University of Frankfurt I: INTRODUCTION 3 Scaling
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
CUDA Toolkit 4.0 Performance Report. June, 2011
 CUDA Toolkit 4. Performance Report June, 211 CUDA Math Libraries High performance math routines for your applications: cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse
CUDA Toolkit 4. Performance Report June, 211 CUDA Math Libraries High performance math routines for your applications: cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Evaluation of Intel Memory Drive Technology Performance for Scientific Applications
 Evaluation of Intel Memory Drive Technology Performance for Scientific Applications Vladimir Mironov, Andrey Kudryavtsev, Yuri Alexeev, Alexander Moskovsky, Igor Kulikov, and Igor Chernykh Introducing
Evaluation of Intel Memory Drive Technology Performance for Scientific Applications Vladimir Mironov, Andrey Kudryavtsev, Yuri Alexeev, Alexander Moskovsky, Igor Kulikov, and Igor Chernykh Introducing
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009
 Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development
 Development") Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
High Performance Linear Algebra
 High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Some notes on efficient computing and high performance computing environments
 Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
BLASFEO. Gianluca Frison. BLIS retreat September 19, University of Freiburg
 University of Freiburg BLIS retreat September 19, 217 Basic Linear Algebra Subroutines For Embedded Optimization performance dgemm_nt 5 4 Intel Core i7 48MQ HP OpenBLAS.2.19 MKL 217.2.174 ATLAS 3.1.3 BLIS.1.6
University of Freiburg BLIS retreat September 19, 217 Basic Linear Algebra Subroutines For Embedded Optimization performance dgemm_nt 5 4 Intel Core i7 48MQ HP OpenBLAS.2.19 MKL 217.2.174 ATLAS 3.1.3 BLIS.1.6
Using OpenACC With CUDA Libraries
 Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2015 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2015 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis
 GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
Fast and reliable linear system solutions on new parallel architectures
 Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Accelerating MCAE with GPUs
 Accelerating MCAE with GPUs Information Sciences Institute 15 Sept 2010 15 Sept 2010 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com Report Documentation
Accelerating MCAE with GPUs Information Sciences Institute 15 Sept 2010 15 Sept 2010 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com Report Documentation
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Accelerating Linpack with CUDA on heterogeneous clusters
 Accelerating Linpack with CUDA on heterogeneous clusters Massimiliano Fatica NVIDIA Corporation 2701 San Tomas Expressway Santa Clara CA 95050 mfatica@nvidia.com ABSTRACT This paper describes the use of
Accelerating Linpack with CUDA on heterogeneous clusters Massimiliano Fatica NVIDIA Corporation 2701 San Tomas Expressway Santa Clara CA 95050 mfatica@nvidia.com ABSTRACT This paper describes the use of
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Sparse LU Factorization for Parallel Circuit Simulation on GPUs
 Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
Programming Dense Linear Algebra Kernels on Vectorized Architectures
 University of Tennessee, Knoxville Trace: Tennessee Research and Creative Exchange Masters Theses Graduate School 5-2013 Programming Dense Linear Algebra Kernels on Vectorized Architectures Jonathan Lawrence
University of Tennessee, Knoxville Trace: Tennessee Research and Creative Exchange Masters Theses Graduate School 5-2013 Programming Dense Linear Algebra Kernels on Vectorized Architectures Jonathan Lawrence
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Brief notes on setting up semi-high performance computing environments. July 25, 2014
 Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters
 1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors
 Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Using OpenACC With CUDA Libraries
 Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2018 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
Using OpenACC With CUDA Libraries John Urbanic with NVIDIA Pittsburgh Supercomputing Center Copyright 2018 3 Ways to Accelerate Applications Applications Libraries Drop-in Acceleration CUDA Libraries are
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Technical Report Performance Analysis of CULA on different NVIDIA GPU Architectures. Prateek Gupta
 Technical Report 2014-02 Performance Analysis of CULA on different NVIDIA GPU Architectures Prateek Gupta May 20, 2014 1 Spring 2014: Performance Analysis of CULA on different NVIDIA GPU Architectures
Technical Report 2014-02 Performance Analysis of CULA on different NVIDIA GPU Architectures Prateek Gupta May 20, 2014 1 Spring 2014: Performance Analysis of CULA on different NVIDIA GPU Architectures
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System
 Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Optimizing the operations with sparse matrices on Intel architecture
 Optimizing the operations with sparse matrices on Intel architecture Gladkikh V. S. victor.s.gladkikh@intel.com Intel Xeon, Intel Itanium are trademarks of Intel Corporation in the U.S. and other countries.
Optimizing the operations with sparse matrices on Intel architecture Gladkikh V. S. victor.s.gladkikh@intel.com Intel Xeon, Intel Itanium are trademarks of Intel Corporation in the U.S. and other countries.
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Quantum ESPRESSO on GPU accelerated systems
 Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control