Faster Code for Free: Linear Algebra Libraries. Advanced Research Compu;ng 22 Feb 2017
|
|
|
- Alfred Stafford
- 6 years ago
- Views:
Transcription
1 Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017
2 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions
3 Introduc;on 3
4 BLAS Level Opera*ons Complexity Examples 1 Vector- vector O(N) Vector addi;on, scaling, norm 2 Matrix- vector O(N 2 ) Matrix- vector mul;ply 3 Matrix- matrix O(N 3 ) Matrix- matrix mul;plica;on
5 LAPACK Linear Algebra Package for solving: Simultaneous linear equa;ons and least- squares solu;ons of linear systems of equa;ons Eigenvalue and singular value problems Matrix factoriza;ons: LU, Cholesky, QR, SVD, Schur Designed to use as many Level 3 BLAS as possible
6 Related Packages BLACS (Basic Linear Algebra Communica;on Subprograms): Linear algebra message passing SCALAPACK: LAPACK for distributed memory machines (uses BLACS) MAGMA: LAPACK but for heterogeneous/ hybrid architectures (e.g. CPU/GPU)


7 HPC Trends Memory Memory M P GPU Architecture Single core Mul;core GPU Cluster Code Serial BLAS, LAPACK CUBLAS, MAGMA MPI
8 Implementa;ons 8
9 Implementa;ons MKL: Intel, Not free but fast Broader scien;fic library, including e.g. FFTW Some built- in capability for offload to Xeon Phi OpenBLAS: Free Fork of famous GotoBLAS2 project ATLAS: Free, automa;cally tunes to hardware Tough to build and link against Faster in recent versions No thread control at run;me There are others



10 Memory Hierarchy Tuning to size of caches has a big impact on performance Memory L3 L3 L2 L2 L2 L2 L2 L2 L2 L2 L1 L1 L1 L1 L1 L1 L1 L1 P P P P P P P P
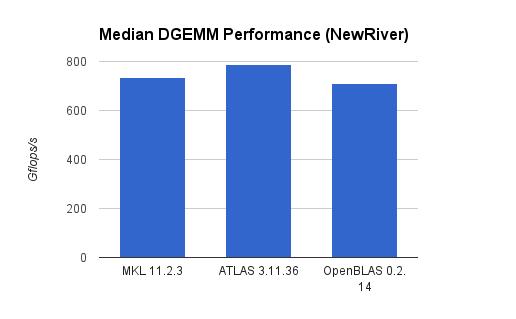
11 Performance Comparison
12 ATLAS Versions ARC tes;ng has shown substan;al performance improvements from the last stable version of ATLAS (3.10.2) to more recent unstable versions (e.g ) Ex: DGEMM of 4224 x 4224 matrices on BlueRidge: : ~210 Gflops/s : ~275 Gflops/s
13 Third- party Packages ARC- installed packages that use MKL include: Aspect: Mantle convec;on Deal II: Finite elements Espresso: Electronic- structure calcula;ons Gromacs: Molecular dynamics Julia: Numerical compu;ng Lammps: Molecular dynamics NWChem: Electronic- structure calcula;ons PETSc: PDE solver Python (numpy): Numerical compu;ng R: Numerical compu;ng Trilinos: Scalable algorithms Vasp: Electronic- structure calcula;ons
14 Example: R and BLAS 300" Run$Time$for$R$2.5$Benchmark$by$Build$Type$ Standard" 250" Op4mized"BLAS" 200" Run$Time$(s)$ 150" 100" 50" 0" gcc" Intel"
15 Using Linear Algebra Libraries 15
16 Func;on Naming Scheme Six lemers: XYYZZZ First lemer indicates the data type: S Real D Double C Complex Z Double complex Next two lemers are matrix type, e.g.: GE General SY Symmetric etc
17 Naming Conven;on (con;nued) Six lemers: XYYZZZ Last 2-3 lemers are the computa;on, e.g.: MM Matrix mul;ply EV Eigenvalue TRF Factorize TRS Solve using factoriza;on etc Examples: dgemm() is double- precision general matrix mul;ply ssyev() is single- precision symmetric eigenvalue
18 Func;on Parameters dgemm ( //calculates alpha*op( A )*op( B ) + beta*c character TRANSA, //transpose A? n or t character TRANSB, //transpose B? n or t integer M, //rows of C integer N, //columns of C integer K, //columns of A double precision ALPHA, //scalar double precision, dimension(lda,*) A, //first matrix integer LDA, //rows (C) or cols (Fort) of A double precision, dimension(ldb,*) B, //second matrix integer LDB, //rows (C) or cols (Fort) of B double precision BETA, //scalar double precision, dimension(ldc,*) C, //C, overwrimen by answer integer LDC //rows (C) or cols (Fort) of C )

19 A Cau;on for C Programmers LAPACK wrimen in Fortran (column- major) C/C++ stores matrices in row- major format. Built in transpose if you call them from C
20 A Cau;on for C Programmers Result: Matrices are interpreted as their transpose For matrix- mul;ply, this means that we call the arguments in reverse: dgemm(,b,,a, ) = B T *A T =(AB) T = C T And with the dimensions of B T and A T : dgemm( n, n,n,m,k, )
21 Linking MKL: Lots of op;ons, can get complicated, e.g. -L${MKLROOT}/lib/intel64 -lmkl_intel_lp64 - lmkl_core -lmkl_intel_thread -lpthread -lm MKL Link Line Advisor can help with this OpenBLAS: -L$OPENBLAS_LIB -lopenblas ATLAS: Threaded: -L$ATLAS_LIB -llapack -lptf77blas ltatlas Replace -ltatlas with -latlas for sequen;al
22 Thread Control MKL: Link to sequen;al or threaded libraries MKL_NUM_THREADS environment variable OpenBLAS: OPENBLAS_NUM_THREADS environment variable ATLAS: Link to sequen;al or threaded (all cores) libraries No thread control at run;me
23 Linear Algebra Libraries on ARC Systems 23
24 Module System gemm]$ module purge; module load gcc openblas gemm]$ module list Currently Loaded Modules: 1) gcc/ ) openblas/ gemm]$ module help openblas Module Specific Help for "openblas/0.2.14" OpenBLAS is an open source BLAS library forked from the GotoBLAS BSD version. Define Environment Variables: $OPENBLAS_DIR - root $OPENBLAS_LIB - libraries Prepend Environment Variables: LD_LIBRARY_PATH += $OPENBLAS_LIB
25 Gevng Started on ARC s Systems Request an account (anyone with a VT PID): hmp:// Can also request for external collaborators Request a system unit alloca;on: hmp:// MIC nodes are charged the same as normal nodes
26 Conclusions 26
27 Conclusions Linear algebra libraries make your code: Simpler Faster More standardized
28 References LAPACK User Guide: hmp:// ATLAS Project: hmp://math- atlas.sourceforge.net/ OpenBLAS Project: hmp:// MKL Link Line Advisor: hmps://soxware.intel.com/en- us/ar;cles/ intel- mkl- link- line- advisor 28
29 Ques;ons? This is a new class, so we would appreciate your feedback: hmps://virginiatech.qualtrics.com/jfe/form/ SV_5cpaTH2OhXT8yjz
BLAS. Basic Linear Algebra Subprograms
 BLAS Basic opera+ons with vectors and matrices dominates scien+fic compu+ng programs To achieve high efficiency and clean computer programs an effort has been made in the last few decades to standardize
BLAS Basic opera+ons with vectors and matrices dominates scien+fic compu+ng programs To achieve high efficiency and clean computer programs an effort has been made in the last few decades to standardize
Linear Algebra Libraries: BLAS, LAPACK, ScaLAPACK, PLASMA, MAGMA
 Linear Algebra Libraries: BLAS, LAPACK, ScaLAPACK, PLASMA, MAGMA Shirley Moore svmoore@utep.edu CPS5401 Fall 2012 svmoore.pbworks.com November 8, 2012 1 Learning ObjecNves AOer complenng this lesson, you
Linear Algebra Libraries: BLAS, LAPACK, ScaLAPACK, PLASMA, MAGMA Shirley Moore svmoore@utep.edu CPS5401 Fall 2012 svmoore.pbworks.com November 8, 2012 1 Learning ObjecNves AOer complenng this lesson, you
Dense matrix algebra and libraries (and dealing with Fortran)
") Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
A Few Numerical Libraries for HPC
 A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
Scientific Computing. Some slides from James Lambers, Stanford
 Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
HPC Numerical Libraries. Nicola Spallanzani SuperComputing Applications and Innovation Department
 HPC Numerical Libraries Nicola Spallanzani n.spallanzani@cineca.it SuperComputing Applications and Innovation Department Algorithms and Libraries Many numerical algorithms are well known and largely available.
HPC Numerical Libraries Nicola Spallanzani n.spallanzani@cineca.it SuperComputing Applications and Innovation Department Algorithms and Libraries Many numerical algorithms are well known and largely available.
Linear Algebra libraries in Debian. DebConf 10 New York 05/08/2010 Sylvestre
 Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Some notes on efficient computing and high performance computing environments
 Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
A Standard for Batching BLAS Operations
 A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
A Standard for Batching BLAS Operations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 5/8/16 1 API for Batching BLAS Operations We are proposing, as a community
Parallelism V. HPC Profiling. John Cavazos. Dept of Computer & Information Sciences University of Delaware
 Parallelism V HPC Profiling John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Performance Counters Profiling PAPI TAU HPCToolkit PerfExpert Performance Counters
Parallelism V HPC Profiling John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Performance Counters Profiling PAPI TAU HPCToolkit PerfExpert Performance Counters
Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN. JSC Training Course
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN JSC Training Course May 22, 2012 Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN JSC Training Course May 22, 2012 Outline General Informations Sequential Libraries Parallel
ATLAS (Automatically Tuned Linear Algebra Software),
,") LAPACK library I Scientists have developed a large library of numerical routines for linear algebra. These routines comprise the LAPACK package that can be obtained from http://www.netlib.org/lapack/.
LAPACK library I Scientists have developed a large library of numerical routines for linear algebra. These routines comprise the LAPACK package that can be obtained from http://www.netlib.org/lapack/.
Resources for parallel computing
 Resources for parallel computing BLAS Basic linear algebra subprograms. Originally published in ACM Toms (1979) (Linpack Blas + Lapack). Implement matrix operations upto matrix-matrix multiplication and
Resources for parallel computing BLAS Basic linear algebra subprograms. Originally published in ACM Toms (1979) (Linpack Blas + Lapack). Implement matrix operations upto matrix-matrix multiplication and
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments
 Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
Batch Linear Algebra for GPU-Accelerated High Performance Computing Environments Ahmad Abdelfattah, Azzam Haidar, Stanimire Tomov, and Jack Dongarra SIAM Conference on Computational Science and Engineering
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
AMath 483/583 Lecture 22. Notes: Another Send/Receive example. Notes: Notes: Another Send/Receive example. Outline:
 AMath 483/583 Lecture 22 Outline: MPI Master Worker paradigm Linear algebra LAPACK and the BLAS References: $UWHPSC/codes/mpi class notes: MPI section class notes: Linear algebra Another Send/Receive example
AMath 483/583 Lecture 22 Outline: MPI Master Worker paradigm Linear algebra LAPACK and the BLAS References: $UWHPSC/codes/mpi class notes: MPI section class notes: Linear algebra Another Send/Receive example
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
LAPACK. Linear Algebra PACKage. Janice Giudice David Knezevic 1
 LAPACK Linear Algebra PACKage 1 Janice Giudice David Knezevic 1 Motivating Question Recalling from last week... Level 1 BLAS: vectors ops Level 2 BLAS: matrix-vectors ops 2 2 O( n ) flops on O( n ) data
LAPACK Linear Algebra PACKage 1 Janice Giudice David Knezevic 1 Motivating Question Recalling from last week... Level 1 BLAS: vectors ops Level 2 BLAS: matrix-vectors ops 2 2 O( n ) flops on O( n ) data
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Intel MIC Architecture. Dr. Momme Allalen, LRZ, PRACE PATC: Intel MIC&GPU Programming Workshop
 Intel MKL @ MIC Architecture Dr. Momme Allalen, LRZ, allalen@lrz.de PRACE PATC: Intel MIC&GPU Programming Workshop 1 2 Momme Allalen, HPC with GPGPUs, Oct. 10, 2011 What is the Intel MKL? Math library
Intel MKL @ MIC Architecture Dr. Momme Allalen, LRZ, allalen@lrz.de PRACE PATC: Intel MIC&GPU Programming Workshop 1 2 Momme Allalen, HPC with GPGPUs, Oct. 10, 2011 What is the Intel MKL? Math library
Intel Math Kernel Library (Intel MKL) Latest Features
 Latest Features") Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ, 27.6-29.6.2016 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi - Compiler Assisted Offload - Automatic Offload - Native Execution
PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ, 27.6-29.6.2016 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi - Compiler Assisted Offload - Automatic Offload - Native Execution
Mathematical Libraries and Application Software on JUQUEEN and JURECA
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course May 2017 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course May 2017 I.Gutheil Outline General Informations Sequential Libraries Parallel
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends
 Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
Dense Linear Algebra on Heterogeneous Platforms: State of the Art and Trends Paolo Bientinesi AICES, RWTH Aachen pauldj@aices.rwth-aachen.de ComplexHPC Spring School 2013 Heterogeneous computing - Impact
PRACE PATC Course: Intel MIC Programming Workshop, MKL. Ostrava,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
Automatic Development of Linear Algebra Libraries for the Tesla Series
 Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Mathematical libraries at the CHPC
 Presentation Mathematical libraries at the CHPC Martin Cuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu October 19, 2006 http://www.chpc.utah.edu Overview What and what
Presentation Mathematical libraries at the CHPC Martin Cuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu October 19, 2006 http://www.chpc.utah.edu Overview What and what
Cray Scientific Libraries. Overview
 Cray Scientific Libraries Overview What are libraries for? Building blocks for writing scientific applications Historically allowed the first forms of code re-use Later became ways of running optimized
Cray Scientific Libraries Overview What are libraries for? Building blocks for writing scientific applications Historically allowed the first forms of code re-use Later became ways of running optimized
Mathematical Libraries and Application Software on JUQUEEN and JURECA
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course November 2015 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course November 2015 I.Gutheil Outline General Informations Sequential Libraries Parallel
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Advanced School in High Performance and GRID Computing November Mathematical Libraries. Part I
 1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
BLAS. Christoph Ortner Stef Salvini
 BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
Brief notes on setting up semi-high performance computing environments. July 25, 2014
 Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Fastest and most used math library for Intel -based systems 1
 Fastest and most used math library for Intel -based systems 1 Speaker: Alexander Kalinkin Contributing authors: Peter Caday, Kazushige Goto, Louise Huot, Sarah Knepper, Mesut Meterelliyoz, Arthur Araujo
Fastest and most used math library for Intel -based systems 1 Speaker: Alexander Kalinkin Contributing authors: Peter Caday, Kazushige Goto, Louise Huot, Sarah Knepper, Mesut Meterelliyoz, Arthur Araujo
MAGMA: a New Generation
 1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
Introduc)on to High Performance Compu)ng Advanced Research Computing
on to High Performance Compu)ng Advanced Research Computing") Introduc)on to High Performance Compu)ng Advanced Research Computing Outline What cons)tutes high performance compu)ng (HPC)? When to consider HPC resources What kind of problems are typically solved?
Introduc)on to High Performance Compu)ng Advanced Research Computing Outline What cons)tutes high performance compu)ng (HPC)? When to consider HPC resources What kind of problems are typically solved?
Intel Math Kernel Library
 Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Dynamic Selection of Auto-tuned Kernels to the Numerical Libraries in the DOE ACTS Collection
 Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
9. Linear Algebra Computation
 9. Linear Algebra Computation Basic Linear Algebra Subprograms (BLAS) Routines that provide standard, low-level, building blocks for performing basic vector and matrix operations. Originally developed
9. Linear Algebra Computation Basic Linear Algebra Subprograms (BLAS) Routines that provide standard, low-level, building blocks for performing basic vector and matrix operations. Originally developed
Programming for supercomputers
 Programming for supercomputers Anthony Scemama http://scemama.mooo.com Labratoire de Chimie et Physique Quantiques IRSAMC (Toulouse) Note Slides can be downloaded here: http://irpf90.ups-tlse.fr/files/lttc17_supercomputing.pdf
Programming for supercomputers Anthony Scemama http://scemama.mooo.com Labratoire de Chimie et Physique Quantiques IRSAMC (Toulouse) Note Slides can be downloaded here: http://irpf90.ups-tlse.fr/files/lttc17_supercomputing.pdf
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
How to get Access to Shaheen2? Bilel Hadri Computational Scientist KAUST Supercomputing Core Lab
 How to get Access to Shaheen2? Bilel Hadri Computational Scientist KAUST Supercomputing Core Lab Live Survey Please login with your laptop/mobile h#p://'ny.cc/kslhpc And type the code VF9SKGQ6 http://hpc.kaust.edu.sa
How to get Access to Shaheen2? Bilel Hadri Computational Scientist KAUST Supercomputing Core Lab Live Survey Please login with your laptop/mobile h#p://'ny.cc/kslhpc And type the code VF9SKGQ6 http://hpc.kaust.edu.sa
Cray Scientific Libraries: Overview and Performance. Cray XE6 Performance Workshop University of Reading Nov 2012
 Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
High-Performance Libraries and Tools. HPC Fall 2012 Prof. Robert van Engelen
 High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
MAGMA. LAPACK for GPUs. Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville
 MAGMA LAPACK for GPUs Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville Keeneland GPU Tutorial 2011, Atlanta, GA April 14-15,
MAGMA LAPACK for GPUs Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville Keeneland GPU Tutorial 2011, Atlanta, GA April 14-15,
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Toward a supernodal sparse direct solver over DAG runtimes
 Toward a supernodal sparse direct solver over DAG runtimes HOSCAR 2013, Bordeaux X. Lacoste Xavier LACOSTE HiePACS team Inria Bordeaux Sud-Ouest November 27, 2012 Guideline Context and goals About PaStiX
Toward a supernodal sparse direct solver over DAG runtimes HOSCAR 2013, Bordeaux X. Lacoste Xavier LACOSTE HiePACS team Inria Bordeaux Sud-Ouest November 27, 2012 Guideline Context and goals About PaStiX
printf("\n\nx = "); for(i=0;i<5;i++) printf("\n%f %f", X[i],X[i+5]); printf("\n\ny = "); for(i=0;i<5;i++) printf("\n%f", Y[i]);
![printf(\n\nx = ); for(i=0;i<5;i++) printf(\n%f %f, X[i],X[i+5]); printf(\n\ny = ); for(i=0;i<5;i++) printf(\n%f, Y[i]);](/thumbs/74/71096422.jpg "printf(\n\nx = ); for(i=0;i<5;i++) printf(\n%f %f, X[i],X[i+5]); printf(\n\ny = ); for(i=0;i<5;i++) printf(\n%f, Y[i]);") OLS.c / / #include #include #include int main(){ int i,info, ipiv[2]; char trans = 't', notrans ='n'; double alpha = 1.0, beta=0.0; int ncol=2; int nrow=5; int
OLS.c / / #include #include #include int main(){ int i,info, ipiv[2]; char trans = 't', notrans ='n'; double alpha = 1.0, beta=0.0; int ncol=2; int nrow=5; int
Introduction to Numerical Libraries for HPC. Bilel Hadri. Computational Scientist KAUST Supercomputing Lab.
 Introduction to Numerical Libraries for HPC Bilel Hadri bilel.hadri@kaust.edu.sa Computational Scientist KAUST Supercomputing Lab Bilel Hadri 1 Numerical Libraries Application Areas Most used libraries/software
Introduction to Numerical Libraries for HPC Bilel Hadri bilel.hadri@kaust.edu.sa Computational Scientist KAUST Supercomputing Lab Bilel Hadri 1 Numerical Libraries Application Areas Most used libraries/software
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Achieve Better Performance with PEAK on XSEDE Resources
 Achieve Better Performance with PEAK on XSEDE Resources Haihang You, Bilel Hadri, Shirley Moore XSEDE 12 July 18 th 2012 Motivations FACTS ALTD ( Automatic Tracking Library Database ) ref Fahey, Jones,
Achieve Better Performance with PEAK on XSEDE Resources Haihang You, Bilel Hadri, Shirley Moore XSEDE 12 July 18 th 2012 Motivations FACTS ALTD ( Automatic Tracking Library Database ) ref Fahey, Jones,
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Hierarchical DAG Scheduling for Hybrid Distributed Systems
 June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
BLAS: Basic Linear Algebra Subroutines I
 BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
INTEL MKL Vectorized Compact routines
 INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
Get Ready for Intel MKL on Intel Xeon Phi Coprocessors. Zhang Zhang Technical Consulting Engineer Intel Math Kernel Library
 Get Ready for Intel MKL on Intel Xeon Phi Coprocessors Zhang Zhang Technical Consulting Engineer Intel Math Kernel Library Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Get Ready for Intel MKL on Intel Xeon Phi Coprocessors Zhang Zhang Technical Consulting Engineer Intel Math Kernel Library Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
BLAS: Basic Linear Algebra Subroutines I
 BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
BLAS: Basic Linear Algebra Subroutines I Most numerical programs do similar operations 90% time is at 10% of the code If these 10% of the code is optimized, programs will be fast Frequently used subroutines
Compilers & Optimized Librairies
 Institut de calcul intensif et de stockage de masse Compilers & Optimized Librairies Modules Environment.bashrc env $PATH... Compilers : GNU, Intel, Portland Memory considerations : size, top, ulimit Hello
Institut de calcul intensif et de stockage de masse Compilers & Optimized Librairies Modules Environment.bashrc env $PATH... Compilers : GNU, Intel, Portland Memory considerations : size, top, ulimit Hello
NAG Fortran Library Routine Document F01CTF.1
 NAG Fortran Library Routine Document Note: before using this routine, please read the Users Note for your implementation to check the interpretation of bold italicised terms and other implementation-dependent
NAG Fortran Library Routine Document Note: before using this routine, please read the Users Note for your implementation to check the interpretation of bold italicised terms and other implementation-dependent
Performance Modeling for Ranking Blocked Algorithms
 Performance Modeling for Ranking Blocked Algorithms Elmar Peise Aachen Institute for Advanced Study in Computational Engineering Science 27.4.2012 Elmar Peise (AICES) Performance Modeling 27.4.2012 1 Blocked
Performance Modeling for Ranking Blocked Algorithms Elmar Peise Aachen Institute for Advanced Study in Computational Engineering Science 27.4.2012 Elmar Peise (AICES) Performance Modeling 27.4.2012 1 Blocked
NAG Fortran Library Routine Document F01CWF.1
 NAG Fortran Library Routine Document Note: before using this routine, please read the Users Note for your implementation to check the interpretation of bold italicised terms and other implementation-dependent
NAG Fortran Library Routine Document Note: before using this routine, please read the Users Note for your implementation to check the interpretation of bold italicised terms and other implementation-dependent
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview
 School of Physics, IPM February 16-21, 2008 HPC tools: an overview") Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview Stefano Cozzini CNR/INFM Democritos and SISSA/eLab cozzini@democritos.it Agenda Tools for
Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview Stefano Cozzini CNR/INFM Democritos and SISSA/eLab cozzini@democritos.it Agenda Tools for
Implementing Strassen-like Fast Matrix Multiplication Algorithms with BLIS
 Implementing Strassen-like Fast Matrix Multiplication Algorithms with BLIS Jianyu Huang, Leslie Rice Joint work with Tyler M. Smith, Greg M. Henry, Robert A. van de Geijn BLIS Retreat 2016 *Overlook of
Implementing Strassen-like Fast Matrix Multiplication Algorithms with BLIS Jianyu Huang, Leslie Rice Joint work with Tyler M. Smith, Greg M. Henry, Robert A. van de Geijn BLIS Retreat 2016 *Overlook of
2.7 Numerical Linear Algebra Software
 2.7 Numerical Linear Algebra Software In this section we will discuss three software packages for linear algebra operations: (i) (ii) (iii) Matlab, Basic Linear Algebra Subroutines (BLAS) and LAPACK. There
2.7 Numerical Linear Algebra Software In this section we will discuss three software packages for linear algebra operations: (i) (ii) (iii) Matlab, Basic Linear Algebra Subroutines (BLAS) and LAPACK. There
Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators. Enrique S. Quintana-Ortí
 Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators Enrique S. Quintana-Ortí Disclaimer Not a course on how to program dense linear algebra kernels on s Where have you
Optimization of Dense Linear Systems on Platforms with Multiple Hardware Accelerators Enrique S. Quintana-Ortí Disclaimer Not a course on how to program dense linear algebra kernels on s Where have you
Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation
 S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
Parallel Linear Algebra in Julia
 Parallel Linear Algebra in Julia Britni Crocker and Donglai Wei 18.337 Parallel Computing 12.17.2012 1 Table of Contents 1. Abstract... 2 2. Introduction... 3 3. Julia Implementation...7 4. Performance...
Parallel Linear Algebra in Julia Britni Crocker and Donglai Wei 18.337 Parallel Computing 12.17.2012 1 Table of Contents 1. Abstract... 2 2. Introduction... 3 3. Julia Implementation...7 4. Performance...
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Introduction to Scientific
 Introduction to Scientific Libraries M. Guarrasi, M. Cremonesi, F. Affinito - CINECA 2015/10/27 Numerical Libraries Groups of functions or subroutines They implement various numerical algorithms, e.g:
Introduction to Scientific Libraries M. Guarrasi, M. Cremonesi, F. Affinito - CINECA 2015/10/27 Numerical Libraries Groups of functions or subroutines They implement various numerical algorithms, e.g:
Intel Math Kernel Library Perspectives and Latest Advances. Noah Clemons Lead Technical Consulting Engineer Developer Products Division, Intel
 Intel Math Kernel Library Perspectives and Latest Advances Noah Clemons Lead Technical Consulting Engineer Developer Products Division, Intel After Compiler and Threading Libraries, what s next? Intel
Intel Math Kernel Library Perspectives and Latest Advances Noah Clemons Lead Technical Consulting Engineer Developer Products Division, Intel After Compiler and Threading Libraries, what s next? Intel
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection
 A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech,
 Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech,") Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech, Atlanta February 24, 2017 Acknowledgements Benoit Jacob
Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech, Atlanta February 24, 2017 Acknowledgements Benoit Jacob
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code
 A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
An Introduc+on to OpenACC Part II
 An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
Use of QE in HPC: trend in technology for HPC, basics of parallelism and performance features Ivan
 Use of QE in HPC: trend in technology for HPC, basics of parallelism and performance features Ivan Giro@o igiro@o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal
Use of QE in HPC: trend in technology for HPC, basics of parallelism and performance features Ivan Giro@o igiro@o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal
Heterogeneous ScaLAPACK Programmers Reference and Installation Manual. Heterogeneous ScaLAPACK Programmers Reference and Installation Manual
 Heterogeneous ScaLAPACK Programmers Reference and Installation Manual 1 Heterogeneous ScaLAPACK Parallel Linear Algebra Programs for Heterogeneous Networks of Computers Version 1.0.0 Ravi Reddy, Alexey
Heterogeneous ScaLAPACK Programmers Reference and Installation Manual 1 Heterogeneous ScaLAPACK Parallel Linear Algebra Programs for Heterogeneous Networks of Computers Version 1.0.0 Ravi Reddy, Alexey
Using recursion to improve performance of dense linear algebra software. Erik Elmroth Dept of Computing Science & HPC2N Umeå University, Sweden
 Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
BLAS and LAPACK + Data Formats for Sparse Matrices. Part of the lecture Wissenschaftliches Rechnen. Hilmar Wobker
 BLAS and LAPACK + Data Formats for Sparse Matrices Part of the lecture Wissenschaftliches Rechnen Hilmar Wobker Institute of Applied Mathematics and Numerics, TU Dortmund email: hilmar.wobker@math.tu-dortmund.de
BLAS and LAPACK + Data Formats for Sparse Matrices Part of the lecture Wissenschaftliches Rechnen Hilmar Wobker Institute of Applied Mathematics and Numerics, TU Dortmund email: hilmar.wobker@math.tu-dortmund.de
MAGMA Library. version 0.1. S. Tomov J. Dongarra V. Volkov J. Demmel
 MAGMA Library version 0.1 S. Tomov J. Dongarra V. Volkov J. Demmel 2 -- MAGMA (version 0.1) -- Univ. of Tennessee, Knoxville Univ. of California, Berkeley Univ. of Colorado, Denver June 2009 MAGMA project
MAGMA Library version 0.1 S. Tomov J. Dongarra V. Volkov J. Demmel 2 -- MAGMA (version 0.1) -- Univ. of Tennessee, Knoxville Univ. of California, Berkeley Univ. of Colorado, Denver June 2009 MAGMA project
Using R for HPC Data Science. Session: Parallel Programming Paradigms. George Ostrouchov
 Using R for HPC Data Science Session: Parallel Programming Paradigms George Ostrouchov Oak Ridge National Laboratory and University of Tennessee and pbdr Core Team Course at IT4Innovations, Ostrava, October
Using R for HPC Data Science Session: Parallel Programming Paradigms George Ostrouchov Oak Ridge National Laboratory and University of Tennessee and pbdr Core Team Course at IT4Innovations, Ostrava, October
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms
 FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
Introduction to Parallel Programming & Cluster Computing
 Introduction to Parallel Programming & Cluster Computing Scientific Libraries & I/O Libraries Joshua Alexander, U Oklahoma Ivan Babic, Earlham College Michial Green, Contra Costa College Mobeen Ludin,
Introduction to Parallel Programming & Cluster Computing Scientific Libraries & I/O Libraries Joshua Alexander, U Oklahoma Ivan Babic, Earlham College Michial Green, Contra Costa College Mobeen Ludin,
*Yuta SAWA and Reiji SUDA The University of Tokyo
 Auto Tuning Method for Deciding Block Size Parameters in Dynamically Load-Balanced BLAS *Yuta SAWA and Reiji SUDA The University of Tokyo iwapt 29 October 1-2 *Now in Central Research Laboratory, Hitachi,
Auto Tuning Method for Deciding Block Size Parameters in Dynamically Load-Balanced BLAS *Yuta SAWA and Reiji SUDA The University of Tokyo iwapt 29 October 1-2 *Now in Central Research Laboratory, Hitachi,
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development
 Development") Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Scheduling of QR Factorization Algorithms on SMP and Multi-core Architectures
 Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System
 Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System Allan Richmond R. Morales, Chong Tian, Kwai Wong, Eduardo D Azevedo The George Washington University, The Chinese University
Runtime Systems and Out-of-Core Cholesky Factorization on the Intel Xeon Phi System Allan Richmond R. Morales, Chong Tian, Kwai Wong, Eduardo D Azevedo The George Washington University, The Chinese University
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
ABSTRACT 1. INTRODUCTION. * phone ; fax ; emphotonics.com
 CULA: Hybrid GPU Accelerated Linear Algebra Routines John R. Humphrey *, Daniel K. Price, Kyle E. Spagnoli, Aaron L. Paolini, Eric J. Kelmelis EM Photonics, Inc, 51 E Main St, Suite 203, Newark, DE, USA
CULA: Hybrid GPU Accelerated Linear Algebra Routines John R. Humphrey *, Daniel K. Price, Kyle E. Spagnoli, Aaron L. Paolini, Eric J. Kelmelis EM Photonics, Inc, 51 E Main St, Suite 203, Newark, DE, USA
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Dealing with Asymmetry for Performance and Energy Efficiency
 Dealing with Asymmetryfor Performance and Energy Efficiency Enrique S. QUINTANA-ORTÍ Motivation Moore s law is alive, but Dennard s scaling is over Motivation Welcome dark silicon and asymmetric architectures
Dealing with Asymmetryfor Performance and Energy Efficiency Enrique S. QUINTANA-ORTÍ Motivation Moore s law is alive, but Dennard s scaling is over Motivation Welcome dark silicon and asymmetric architectures
Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster
 th IEEE International Conference on Computer and Information Technology (CIT ) Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster WANG Lei ZHANG Yunquan
th IEEE International Conference on Computer and Information Technology (CIT ) Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster WANG Lei ZHANG Yunquan