Classification: Decision Trees
|
|
|
- Martina Cross
- 6 years ago
- Views:
Transcription
1 Metodologie per Sistemi Intelligenti Classification: Decision Trees Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo regionale di Como
2 Lecture outline What is a decision tree? Building decision trees Choosing the Splitting Attribute Choosing the Purity Measure The C4.5 Algorithm Pruning From Trees to Rules
3 Weather data: to play or not to play? No True High Mild Rainy Yes False Normal Hot Overcast Yes True High Mild Overcast Yes True Normal Mild Sunny Yes False Normal Mild Rainy Yes False Normal Cool Sunny No False High Mild Sunny Yes True Normal Cool Overcast No True Normal Cool Rainy Yes False Normal Cool Rainy Yes False High Mild Rainy Yes False High Hot Overcast No True High Hot Sunny No False High Hot Sunny Play Windy Humidity Temp Outlook
4 Decision tree for Play? Outlook sunny overcast rain humidity Yes windy high normal true false No Yes No Yes
5 What is a decision tree? An internal node is a test on an attribute. A branch represents an outcome of the test, e.g., outlook=windy. A leaf node represents a class label or class label distribution. At each node, one attribute is chosen to split training examples into distinct classes as much as possible A new case is classified by following a matching path to a leaf node.
6 How to build a decision tree? Top-down tree construction At start, all training examples are at the root. Partition the examples recursively by choosing one attribute each time. Bottom-up tree pruning Remove subtrees or branches, in a bottomup manner, to improve the estimated accuracy on new cases.
7 How to choose the splitting attribute? At each node, available attributes are evaluated on the basis of separating the classes of the training examples. A goodness (purity) function is used for this purpose. Typical goodness functions: information gain (ID3/C4.5) information gain ratio gini index



8 Which attribute to select?
9 A criterion for attribute selection Which is the best attribute? The one which will result in the smallest tree Heuristic: choose the attribute that produces the purest nodes Popular impurity criterion: information gain Information gain increases with the average purity of the subsets that an attribute produces Strategy: choose attribute that results in t t i f ti i
10 Computing information Information is measured in bits Given a probability distribution, the info required to predict an event is the distribution s entropy Entropy gives the information required in bits (this can involve fractions of bits!) Formula for computing the entropy: entropy( p 1, p 2,, p ) = p logp p logp K K n p n logp n

11 *Claude Shannon Father of information theory Born: 30 April 1916 Died: 23 February 2001 Claude Shannon, who has died aged 84, perhaps more than anyone laid the groundwork for today s digital revolution. His exposition of information theory, stating that all information could be represented mathematically as a succession of noughts and ones, facilitated the digital manipulation of data without which today s information society would be unthinkable. Shannon s master s thesis, obtained in 1940 at MIT, demonstrated that problem solving could be achieved by manipulating the symbols 0 and 1 in a process that could be carried out automatically with electrical circuitry. That dissertation has been hailed as one of the most significant master s theses of the 20th century. Eight years later, Shannon published another landmark paper, A Mathematical Theory of Communication, generally taken as his most important scientific contribution. Shannon applied the same radical approach to cryptography research, in which he later became a consultant to the US government. Many of Shannon s pioneering insights were developed before they could be applied in practical form. He was truly a remarkable man, yet unknown to most of the world.
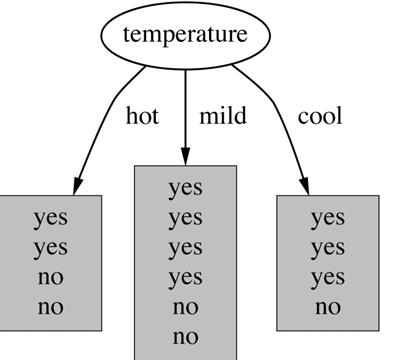
12 Example: attribute Outlook Outlook = Sunny : info([2,3] ) = entropy(2/ 5,3/5) = bits Outlook = Overcast : info([4,0] ) = entropy(1, 0) = 0bits Outlook = Rainy : info([3,2] ) = entropy(3/ 5,2/5) = bits Expected information for attribute: info([3,2],[4,0],[3,2]) = ( 5 / 14) ( 4/ 14) 0 + ( 5/ 14) = bits
13 Information gain Difference between the information before split and the information after split gain("outlook" ) = info([9,5] )-info([2,3],[4,0],[3,2]) = = 0.247bits Information gain for the attributes from the weather data: gain( outlook )=0.247 bits gain( temperature )=0.029 bits gain( humidity )=0.152 bits gain( windy )=0.048 bits
 = 0.")
14 Continuing to split gain(" Temperature") = bits gain(" Humidity") = bits gain(" Windy" ) = bits

15 The final decision tree Not all leaves need to be pure; sometimes identical instances have different classes Splitting stops when data can t be split any further
16 *Wish list for a purity measure Properties we require from a purity measure: When node is pure, measure should be zero When impurity is maximal (i.e. all classes equally likely), measure should be maximal Measure should obey multistage property (i.e. decisions can be made in several stages): measure([2,3,4]) = measure([2,7]) + (7/9) measure([3,4]) Entropy is a function that satisfies all three properties!
17 Highly-branching attributes Problematic: attributes with a large number of values (extreme case: ID code) Subsets are more likely to be pure if there is a large number of values Information gain is biased towards choosing attributes with a large number of values This may result in overfitting (selection of an attribute that is non-optimal for prediction)
18 Weather data: adding ID N M L K J I H G F E D C B A ID code No True High Mild Rainy Yes False Normal Hot Overcast Yes True High Mild Overcast Yes True Normal Mild Sunny Yes False Normal Mild Rainy Yes False Normal Cool Sunny No False High Mild Sunny Yes True Normal Cool Overcast No True Normal Cool Rainy Yes False Normal Cool Rainy Yes False High Mild Rainy Yes False High Hot Overcast No True High Hot Sunny No False High Hot Sunny Play Windy Humidity Temp Outlook

19 Split for ID Code attribute Entropy of split = 0 (since each leaf node is pure, having only one case. Information gain is maximal for ID code
20 Gain ratio Gain ratio: a modification of the information gain that reduces its bias on high-branch attributes Gain ratio should be Large when data is evenly spread Small when all data belong to one branch Gain ratio takes number and size of branches into account when choosing an attribute It corrects the information gain by taking the intrinsic information of a split into account (i.e. how much info do we need to tell which branch an instance belongs to)
21 Gain ratio and Intrinsic information. Intrinsic information: entropy of distribution of instances into branches S S IntrinsicI nfo( S, A) log. S i 2 S i Gain ratio normalizes info gain by: GainRatio ( S, A) = GainS (, A) IntrinsicI nfo( S, A).
22 Computing the gain ratio Example: intrinsic information for ID code info([1,1, K,1) = 14 ( 1/ 14 log1/ 14) = bits Importance of attribute decreases as intrinsic information gets larger Example of gain ratio: gain_ratio (" Attribute") = gain("attribute") intrinsic_info("attribute") Example: 0.940bits gain_ratio ("ID_code") = = 3.807bits 0.246
23 Gain ratios for weather data Outlook Temperature Info: Info: Gain: Gain: Split info: info([5,4,5]) Split info: info([4,6,4]) Gain ratio: 0.247/ Gain ratio: 0.029/ Humidity Windy Info: Info: Gain: Gain: Split info: info([7,7]) Split info: info([8,6]) Gain ratio: 0.152/ Gain ratio: 0.048/
24 More on the gain ratio Outlook still comes out top However ID code has greater gain ratio Standard fix: ad hoc test to prevent splitting on that type of attribute Problem: gain ratio: it may overcompensate May choose an attribute just because its intrinsic information is very low Standard fix: First, only consider attributes with greater than average information gain Then, compare them on gain ratio
25 *CART splitting criteria: Gini Index If a data set T contains examples from n classes, gini index, gini(t) is defined as gini( T) = 1 n 2 p j j= 1 where pj is the relative frequency of class j in T. gini(t) is minimized if the classes in T are skewed.
26 *Gini Index After splitting T into two subsets T1 and T2 with sizes N1 and N2, the gini index of the split data is defined as gini N N 1 ( ) ( T 2 T = gini ) + gini( T 1 N N split 2 The attribute providing smallest gini split (T) is chosen to split the node. )
27 Industrial-strength algorithms For an algorithm to be useful in a wide range of real-world applications it must: Permit numeric attributes Allow missing values Be robust in the presence of noise Be able to approximate arbitrary concept descriptions (at least in principle) Basic schemes need to be extended to fulfill these requirements
28 The C4.5 algorithm Handling Numeric Attributes Finding Best Split(s) Dealing with Missing Values Pruning Pre-pruning, Post-pruning, Error Estimates From Trees to Rules
29 C4.5 History ID3, CHAID 1960s C4.5 innovations (Quinlan): permit numeric attributes deal sensibly with missing values pruning to deal with for noisy data C4.5 - one of best-known and most widely-used learning algorithms Last research version: C4.8, implemented in Weka as J4.8 (Java) Commercial successor: C5.0 (available from Rulequest)
30 Numeric attributes Standard method: binary splits E.g. temp < 45 Unlike nominal attributes, every attribute has many possible split points Solution is straightforward extension: Evaluate info gain (or other measure) for every possible split point of attribute Choose best split point Info gain for best split point is info gain for attribute Computationally more demanding
31 Weather data nominal values Outlook Temperature Humidity Windy Play Sunny Hot High False No Sunny Hot High True No Overcast Hot High False Yes Rainy Mild Normal False Yes If outlook = sunny and humidity = high then play = no If outlook = rainy and windy = true then play = no If outlook = overcast then play = yes If humidity = normal then play = yes If none of the above then play = yes
32 Weather data numeric Outlook Temperature Humidity Windy Play Sunny False No Sunny True No Overcast False Yes Rainy False Yes If outlook = sunny and humidity > 83 then play = no If outlook = rainy and windy = true then play = no If outlook = overcast then play = yes If humidity < 85 then play = yes If none of the above then play = yes
33 Example Split on temperature attribute: Y N Y Y Y N N Y Y Y N Y Y No E.g. temperature < 71.5: yes/4, no/2 temperature 71.5: yes/5, no/3 Info([4,2],[5,3]) = 6/14 info([4,2]) + 8/14 info([5,3]) = bits Place split points halfway between values Can evaluate all split points in one pass!
34 Avoid repeated sorting! Sort instances by the values of the numeric attribute [time complexity O (n log n)] Question: Does this have to be repeated at each node of the tree? Answer: No! Sort order for children can be derived from sort order for parent Time complexity of derivation: O (n) Drawback: need to create and store an array of sorted indices for each numeric attribute
35 More speeding up Entropy only needs to be evaluated between points of different classes (Fayyad & Irani, 1992) Potential optimal breakpoints Breakpoints between values of the same class cannot be optimal
36 Binary vs. multi-way splits Splitting (multi-way) on a nominal attribute exhausts all information in that attribute Nominal attribute is tested (at most) once on any path in the tree Not so for binary splits on numeric attributes! Numeric attribute may be tested several times along a path in the tree Disadvantage: tree is hard to read Remedy: pre-discretize numeric
37 Missing values as a separate value Missing value denoted? in C4.X Simple idea: treat missing as a separate value Q: When this is not appropriate? A: When values are missing due to different reasons Example 1: gene expression could be missing when it is very high or very low Example 2: field IsPregnant=missing for a male patient should be treated differently (no) than for a female patient of age 25 ( k )
38 Missing values Split instances with missing values into pieces A piece going down a branch receives a weight proportional to the popularity of the branch weights sum to 1 Info gain works with fractional instances use sums of weights instead of counts During classification, split the instance into pieces in the same way Merge probability distribution using weights
39 Avoid overfitting in trees The generated tree may overfit the training data Too many branches, some may reflect anomalies due to noise or outliers Result is in poor accuracy for unseen samples Two approaches to avoid overfitting Prepruning: Halt tree construction early do not split a node if this would result in the goodness measure falling below a threshold Difficult to choose an appropriate threshold Postpruning: Remove branches from a fully grown tree get a sequence of progressively pruned trees Use a set of data different from the training data to decide which is the best pruned tree
40 Pruning Goal: Prevent overfitting to noise in the data Two strategies for pruning Postpruning - take a fully-grown decision tree and discard unreliable parts Prepruning - stop growing a branch when information becomes unreliable Postpruning preferred in practice prepruning can stop too early
41 Prepruning Based on statistical significance test Stop growing the tree when there is no statistically significant association between any attribute and the class at a particular node Most popular test: chi-squared test ID3 used chi-squared test in addition to information gain Only statistically significant attributes were allowed to be selected by information gain procedure
42 a b class Early stopping Pre-pruning may stop the growth process prematurely: early stopping Classic example: XOR/Parity-problem No individual attribute exhibits any significant association to the class Structure is only visible in fully expanded tree Pre-pruning won t expand the root node But: XOR-type problems rare in practice And: pre-pruning faster than post-pruning
43 Post-pruning First, build full tree, then prune it Fully-grown tree shows all attribute interactions Problem: some subtrees might be due to chance effects Two pruning operations: Subtree replacement Subtree raising Possible strategies: error estimation significance testing MDL principle
44 Subtree replacement Bottom-up Consider replacing a tree only after considering all its subtrees Example: labor negotiation data

45 Subtree replacement Bottom-up Consider replacing a tree only after considering all its subtrees

46 *Subtree raising Delete node Redistribute instances Slower than subtree replacement (Worthwhile?) X
47 Estimating error rates Prune only if it reduces the estimated error Error on the training data is NOT a useful estimator Q: Why it would result in very little pruning? Use hold-out set for pruning ( reduced-error pruning ) C4.5 s method Derive confidence interval from training data Use a heuristic limit, derived from this, for pruning Standard Bernoulli-process-based method Shaky statistical assumptions (based on training data)
48 *Mean and variance Mean and variance for a Bernoulli trial: p, p (1 p) Expected success rate f=s/n Mean and variance for f : p, p (1 p)/n For large enough N, f follows a Normal distribution c% confidence interval [ z X z] for random variable with 0 mean is given by: Pr[ z X z] = With a symmetric distribution: Pr[ z X z] = 1 2 Pr[ X c z]
49 *Confidence limits Confidence limits for the normal distribution with 0 mean and a variance of 1: Pr[X z] 0.1% 0.5% z Thus: % 5% 10% 20% 25% 40% Pr[ X 1. 65] = 90% To use this we have to reduce our random variable f to have 0 mean and unit variance
50 C4.5 s method Error estimate for subtree is weighted sum of error estimates for all its leaves Error estimate for a node (upper bound): e = f 2 z + 2N + z f N 2 f N + 2 z 4N 1 + If c = 25% then z = 0.69 (from normal distribution) f is the error on the training data N is the number of instances covered by the leaf 2 2 z N

51 f = 5/14 e = 0.46 e < 0.51 so prune! f=0.33 e=0.47 f=0.5 e=0.72 f=0.33 e=0.47 Combined using ratios 6:2:6 gives 0.51
52 *Complexity of tree induction Assume m attributes n training instances tree depth O (log n) Building a tree O (m n log n) Subtree replacement O (n) Subtree raising O (n (log n)2) Every instance may have to be redistributed at every node between its leaf and the root Cost for redistribution (on average): O (log n) Total cost: O (m n log n) + O (n (log n)2)
53 From trees to rules Simple way: one rule for each leaf C4.5rules: greedily prune conditions from each rule if this reduces its estimated error Can produce duplicate rules Check for this at the end Then look at each class in turn consider the rules for that class find a good subset (guided by MDL) Then rank the subsets to avoid conflicts Finally, remove rules (greedily) if this decreases error on the training data
54 C4.5rules: choices and options C4.5rules slow for large and noisy datasets Commercial version C5.0rules uses a different technique, much faster and a bit more accurate C4.5 has two parameters Confidence value (default 25%): lower values incur heavier pruning Minimum number of instances in the two most popular branches (default 2)
55 Classification in large databases Classification a classical problem extensively studied by statisticians and machine learning researchers Scalability: Classifying data sets with millions of examples and hundreds of attributes with reasonable speed Why decision tree induction in data mining? relatively faster learning speed (than other classification methods) convertible to simple and easy to understand classification rules can use SQL queries for accessing databases comparable classification accuracy with other methods
56 Scalable decision tree induction: methods in Data Mining studies SLIQ (EDBT 96 Mehta et al.) builds an index for each attribute and only class list and the current attribute list reside in memory SPRINT (VLDB 96 J. Shafer et al.) constructs an attribute list data structure PUBLIC (VLDB 98 Rastogi & Shim) integrates tree splitting and tree pruning: stop growing the tree earlier RainForest (VLDB 98 Gehrke, Ramakrishnan & Ganti) separates the scalability aspects from the criteria that determine the quality of the tree builds an AVC-list (attribute, value, class label)
57 Summary Classification is an extensively studied problem (mainly in statistics, machine learning & neural networks) Classification is probably one of the most widely used data mining techniques with a lot of extensions Decision Tree Construction Choosing the Splitting Attribute Choosing the purity measure
58 Summary Information Gain biased towards attributes with a large number of values Gain Ratio takes number and size of branches into account when choosing an attribute Scalability is still an important issue for database applications: thus combining classification with database techniques should be a promising topic Research directions: classification of nonrelational data, e.g., text, spatial, multimedia, etc..
59 References (I) C. Apte and S. Weiss. Data mining with decision trees and decision rules. Future Generation Computer Systems, 13, L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth International Group, P. K. Chan and S. J. Stolfo. Learning arbiter and combiner trees from partitioned data for scaling machine learning. In Proc. 1st Int. Conf. Knowledge Discovery and Data Mining (KDD'95), pages 39-44, Montreal, Canada, August U. M. Fayyad. Branching on attribute values in decision tree generation. In Proc AAAI Conf., pages , AAAI Press, J. Gehrke, R. Ramakrishnan, and V. Ganti. Rainforest: A framework for fast decision tree construction of large datasets. In Proc Int. Conf. Very Large Data Bases, pages , New York, NY, August M. Kamber, L. Winstone, W. Gong, S. Cheng, and J. Han. Generalization and decision tree induction: Efficient classification in data mining. In Proc Int. Workshop Research Issues on Data Engineering (RIDE'97), pages , Birmingham, England, April 1997.
60 References (II) J. Magidson. The Chaid approach to segmentation modeling: Chi-squared automatic interaction detection. In R. P. Bagozzi, editor, Advanced Methods of Marketing Research, pages Blackwell Business, Cambridge Massechusetts, M. Mehta, R. Agrawal, and J. Rissanen. SLIQ : A fast scalable classifier for data mining. In Proc Int. Conf. Extending Database Technology (EDBT'96), Avignon, France, March S. K. Murthy, Automatic Construction of Decision Trees from Data: A Multi-Diciplinary Survey, Data Mining and Knowledge Discovery 2(4): , 1998 J. R. Quinlan. Bagging, boosting, and c4.5. In Proc. 13th Natl. Conf. on Artificial Intelligence (AAAI'96), , Portland, OR, Aug R. Rastogi and K. Shim. Public: A decision tree classifer that integrates building and pruning. In Proc Int. Conf. Very Large Data Bases, , New York, NY, August J. Shafer, R. Agrawal, and M. Mehta. SPRINT : A scalable parallel classifier for data mining. In Proc Int. Conf. Very Large Data Bases, , Bombay, India, Sept S. M. Weiss and C. A. Kulikowski. Computer Systems that Learn: Classification and Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems. Morgan Kaufman, 1991.
Machine Learning in Real World: C4.5
 Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Data Mining Practical Machine Learning Tools and Techniques
 Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Classification and Prediction
 Objectives Introduction What is Classification? Classification vs Prediction Supervised and Unsupervised Learning D t P Data Preparation ti Classification Accuracy ID3 Algorithm Information Gain Bayesian
Objectives Introduction What is Classification? Classification vs Prediction Supervised and Unsupervised Learning D t P Data Preparation ti Classification Accuracy ID3 Algorithm Information Gain Bayesian
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Advanced learning algorithms
 Advanced learning algorithms Extending decision trees; Extraction of good classification rules; Support vector machines; Weighted instance-based learning; Design of Model Tree Clustering Association Mining
Advanced learning algorithms Extending decision trees; Extraction of good classification rules; Support vector machines; Weighted instance-based learning; Design of Model Tree Clustering Association Mining
Lecture outline. Decision-tree classification
 Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Lecture 6 Classification and Prediction
 Lecture 6 Classification and Prediction (Part B) Zhou Shuigeng April 9, 2006 2006-4-16 Data Mining: Tech. & Appl. 1 Outline Instance-Based Method Classification based on concepts from association rule
Lecture 6 Classification and Prediction (Part B) Zhou Shuigeng April 9, 2006 2006-4-16 Data Mining: Tech. & Appl. 1 Outline Instance-Based Method Classification based on concepts from association rule
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Tree CE-717 : Machine Learning Sharif University of Technology
 Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Data Mining Practical Machine Learning Tools and Techniques. Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Decision Tree Learning
 Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Outline. RainForest A Framework for Fast Decision Tree Construction of Large Datasets. Introduction. Introduction. Introduction (cont d)
") Outline RainForest A Framework for Fast Decision Tree Construction of Large Datasets resented by: ov. 25, 2004 1. 2. roblem Definition 3. 4. Family of Algorithms 5. 6. 2 Classification is an important
Outline RainForest A Framework for Fast Decision Tree Construction of Large Datasets resented by: ov. 25, 2004 1. 2. roblem Definition 3. 4. Family of Algorithms 5. 6. 2 Classification is an important
Data Mining. Decision Tree. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Decision Tree Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 24 Table of contents 1 Introduction 2 Decision tree
Data Mining Decision Tree Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 24 Table of contents 1 Introduction 2 Decision tree
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.7
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.7 March 1, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.7 March 1, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
Lecture 5: Decision Trees (Part II)
") Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
9/6/14. Our first learning algorithm. Comp 135 Introduction to Machine Learning and Data Mining. knn Algorithm. knn Algorithm (simple form)
") Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
Decision tree learning
 Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Data Mining Algorithms: Basic Methods
 Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Knowledge discovery & data mining. Classification & fraud detection
 Knowledge discovery & data mining Classification & fraud detection Fosca Giannotti and Dino Pedreschi Pisa KDD Lab CNUCE-CNR & Univ. Pisa http://www-kdd.di.unipi.it/ Module outline The classification task
Knowledge discovery & data mining Classification & fraud detection Fosca Giannotti and Dino Pedreschi Pisa KDD Lab CNUCE-CNR & Univ. Pisa http://www-kdd.di.unipi.it/ Module outline The classification task
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Nominal Data. May not have a numerical representation Distance measures might not make sense. PR and ANN
 NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
Introduction to Machine Learning
 Introduction to Machine Learning Decision Tree Example Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short} Class: Country = {Gromland, Polvia} CS4375 --- Fall 2018 a
Introduction to Machine Learning Decision Tree Example Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short} Class: Country = {Gromland, Polvia} CS4375 --- Fall 2018 a
Lecture 5 of 42. Decision Trees, Occam s Razor, and Overfitting
 Lecture 5 of 42 Decision Trees, Occam s Razor, and Overfitting Friday, 01 February 2008 William H. Hsu, KSU http://www.cis.ksu.edu/~bhsu Readings: Chapter 3.6-3.8, Mitchell Lecture Outline Read Sections
Lecture 5 of 42 Decision Trees, Occam s Razor, and Overfitting Friday, 01 February 2008 William H. Hsu, KSU http://www.cis.ksu.edu/~bhsu Readings: Chapter 3.6-3.8, Mitchell Lecture Outline Read Sections
PATTERN DISCOVERY IN TIME-ORIENTED DATA
 PATTERN DISCOVERY IN TIME-ORIENTED DATA Mohammad Saraee, George Koundourakis and Babis Theodoulidis TimeLab Information Management Group Department of Computation, UMIST, Manchester, UK Email: saraee,
PATTERN DISCOVERY IN TIME-ORIENTED DATA Mohammad Saraee, George Koundourakis and Babis Theodoulidis TimeLab Information Management Group Department of Computation, UMIST, Manchester, UK Email: saraee,
Decision Trees: Discussion
 Decision Trees: Discussion Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning
Decision Trees: Discussion Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning
Supervised Learning. Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
 Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Dynamic Load Balancing of Unstructured Computations in Decision Tree Classifiers
 Dynamic Load Balancing of Unstructured Computations in Decision Tree Classifiers A. Srivastava E. Han V. Kumar V. Singh Information Technology Lab Dept. of Computer Science Information Technology Lab Hitachi
Dynamic Load Balancing of Unstructured Computations in Decision Tree Classifiers A. Srivastava E. Han V. Kumar V. Singh Information Technology Lab Dept. of Computer Science Information Technology Lab Hitachi
PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning
 Data Mining and Knowledge Discovery, 4, 315 344, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning RAJEEV
Data Mining and Knowledge Discovery, 4, 315 344, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning RAJEEV
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
Decision Tree Learning
 Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
ISSUES IN DECISION TREE LEARNING
 ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Data Mining and Analytics
 Data Mining and Analytics Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/22/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/bsbt6111/
Data Mining and Analytics Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/22/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/bsbt6111/
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Data Mining. 3.3 Rule-Based Classification. Fall Instructor: Dr. Masoud Yaghini. Rule-Based Classification
 Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining. Practical Machine Learning Tools and Techniques. Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A.
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
Representing structural patterns: Reading Material: Chapter 3 of the textbook by Witten
 Representing structural patterns: Plain Classification rules Decision Tree Rules with exceptions Relational solution Tree for Numerical Prediction Instance-based presentation Reading Material: Chapter
Representing structural patterns: Plain Classification rules Decision Tree Rules with exceptions Relational solution Tree for Numerical Prediction Instance-based presentation Reading Material: Chapter
Part I. Instructor: Wei Ding
 Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Nominal Data. May not have a numerical representation Distance measures might not make sense PR, ANN, & ML
 Decision Trees Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
Decision Trees Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
Lecture 2 :: Decision Trees Learning
 Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Machine Learning. Decision Trees. Le Song /15-781, Spring Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU
 Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Basic Concepts Weka Workbench and its terminology
 Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Fuzzy Partitioning with FID3.1
 Fuzzy Partitioning with FID3.1 Cezary Z. Janikow Dept. of Mathematics and Computer Science University of Missouri St. Louis St. Louis, Missouri 63121 janikow@umsl.edu Maciej Fajfer Institute of Computing
Fuzzy Partitioning with FID3.1 Cezary Z. Janikow Dept. of Mathematics and Computer Science University of Missouri St. Louis St. Louis, Missouri 63121 janikow@umsl.edu Maciej Fajfer Institute of Computing
Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees
 Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees Dominik Vinan February 6, 2018 Abstract Decision Trees are a well-known part of most modern Machine Learning toolboxes.
Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees Dominik Vinan February 6, 2018 Abstract Decision Trees are a well-known part of most modern Machine Learning toolboxes.
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
CONCEPT FORMATION AND DECISION TREE INDUCTION USING THE GENETIC PROGRAMMING PARADIGM
 1 CONCEPT FORMATION AND DECISION TREE INDUCTION USING THE GENETIC PROGRAMMING PARADIGM John R. Koza Computer Science Department Stanford University Stanford, California 94305 USA E-MAIL: Koza@Sunburn.Stanford.Edu
1 CONCEPT FORMATION AND DECISION TREE INDUCTION USING THE GENETIC PROGRAMMING PARADIGM John R. Koza Computer Science Department Stanford University Stanford, California 94305 USA E-MAIL: Koza@Sunburn.Stanford.Edu
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Data Mining Part 4. Tony C Smith WEKA Machine Learning Group Department of Computer Science University of Waikato
 Data Mining Part 4 Tony C Smith WEKA Machine Learning Group Department of Computer Science University of Waikato Algorithms: The basic methods Inferring rudimentary rules Statistical modeling Constructing
Data Mining Part 4 Tony C Smith WEKA Machine Learning Group Department of Computer Science University of Waikato Algorithms: The basic methods Inferring rudimentary rules Statistical modeling Constructing
Machine Learning Chapter 2. Input
 Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
Decision Trees. Query Selection
 CART Query Selection Key Question: Given a partial tree down to node N, what feature s should we choose for the property test T? The obvious heuristic is to choose the feature that yields as big a decrease
CART Query Selection Key Question: Given a partial tree down to node N, what feature s should we choose for the property test T? The obvious heuristic is to choose the feature that yields as big a decrease
Data Mining and Machine Learning: Techniques and Algorithms
 Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
arxiv: v1 [stat.ml] 25 Jan 2018
![arxiv: v1 [stat.ml] 25 Jan 2018](/thumbs/80/81231421.jpg "arxiv: v1 [stat.ml] 25 Jan 2018") arxiv:1801.08310v1 [stat.ml] 25 Jan 2018 Information gain ratio correction: Improving prediction with more balanced decision tree splits Antonin Leroux 1, Matthieu Boussard 1, and Remi Dès 1 1 craft ai
arxiv:1801.08310v1 [stat.ml] 25 Jan 2018 Information gain ratio correction: Improving prediction with more balanced decision tree splits Antonin Leroux 1, Matthieu Boussard 1, and Remi Dès 1 1 craft ai
CS229 Lecture notes. Raphael John Lamarre Townshend
 CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
International Journal of Software and Web Sciences (IJSWS)
") International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Practical Machine Learning Tools and Techniques
 Input: Concepts, instances, attributes Data ining Practical achine Learning Tools and Techniques Slides for Chapter 2 of Data ining by I. H. Witten and E. rank Terminology What s a concept z Classification,
Input: Concepts, instances, attributes Data ining Practical achine Learning Tools and Techniques Slides for Chapter 2 of Data ining by I. H. Witten and E. rank Terminology What s a concept z Classification,
Induction of Decision Trees
 Induction of Decision Trees Blaž Zupan and Ivan Bratko magixfriuni-ljsi/predavanja/uisp An Example Data Set and Decision Tree # Attribute Class Outlook Company Sailboat Sail? 1 sunny big small yes 2 sunny
Induction of Decision Trees Blaž Zupan and Ivan Bratko magixfriuni-ljsi/predavanja/uisp An Example Data Set and Decision Tree # Attribute Class Outlook Company Sailboat Sail? 1 sunny big small yes 2 sunny
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan
 Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
Implementation of Classification Rules using Oracle PL/SQL
 1 Implementation of Classification Rules using Oracle PL/SQL David Taniar 1 Gillian D cruz 1 J. Wenny Rahayu 2 1 School of Business Systems, Monash University, Australia Email: David.Taniar@infotech.monash.edu.au
1 Implementation of Classification Rules using Oracle PL/SQL David Taniar 1 Gillian D cruz 1 J. Wenny Rahayu 2 1 School of Business Systems, Monash University, Australia Email: David.Taniar@infotech.monash.edu.au
Data Mining Practical Machine Learning Tools and Techniques
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter of Data Mining by I. H. Witten and E. Frank Decision trees Implementation: Real machine learning schemes z From ID3 to C4.5
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter of Data Mining by I. H. Witten and E. Frank Decision trees Implementation: Real machine learning schemes z From ID3 to C4.5
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Classification: Decision Trees
 Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Machine Learning. A. Supervised Learning A.7. Decision Trees. Lars Schmidt-Thieme
 Machine Learning A. Supervised Learning A.7. Decision Trees Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany 1 /
Machine Learning A. Supervised Learning A.7. Decision Trees Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany 1 /
Data Mining in Bioinformatics Day 1: Classification
 Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-18) LEARNING FROM EXAMPLES DECISION TREES Outline 1- Introduction 2- know your data 3- Classification
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-18) LEARNING FROM EXAMPLES DECISION TREES Outline 1- Introduction 2- know your data 3- Classification
Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Data mining - detailed outline. Problem
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Data Mining. Practical Machine Learning Tools and Techniques. Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A.
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Output: Knowledge representation Tables Linear models Trees Rules
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Output: Knowledge representation Tables Linear models Trees Rules
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Decision Tree Induction from Distributed Heterogeneous Autonomous Data Sources
 Decision Tree Induction from Distributed Heterogeneous Autonomous Data Sources Doina Caragea, Adrian Silvescu, and Vasant Honavar Artificial Intelligence Research Laboratory, Computer Science Department,
Decision Tree Induction from Distributed Heterogeneous Autonomous Data Sources Doina Caragea, Adrian Silvescu, and Vasant Honavar Artificial Intelligence Research Laboratory, Computer Science Department,
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Classification and Regression Trees
 Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
Prediction. What is Prediction. Simple methods for Prediction. Classification by decision tree induction. Classification and regression evaluation
 Prediction Prediction What is Prediction Simple methods for Prediction Classification by decision tree induction Classification and regression evaluation 2 Prediction Goal: to predict the value of a given
Prediction Prediction What is Prediction Simple methods for Prediction Classification by decision tree induction Classification and regression evaluation 2 Prediction Goal: to predict the value of a given
Data mining - detailed outline. Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Problem.
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
Data Mining Practical Machine Learning Tools and Techniques
 Output: Knowledge representation Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter of Data Mining by I. H. Witten and E. Frank Decision tables Decision trees Decision rules
Output: Knowledge representation Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter of Data Mining by I. H. Witten and E. Frank Decision tables Decision trees Decision rules
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng: