Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan
|
|
|
- Noel Phelps
- 5 years ago
- Views:
Transcription
1 Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan
2 Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function 3. An optimization strategy Categorical y {c 1,,c m }: classification Real-valued y: regression Note: usually assume {c 1,,c m } are mutually exclusive and exhaustive
3 Generalized Additive Models Highly flexible form of predictive modeling for regression and classification: g ( link function ) could be the identity or logit or log or whatever The f s are smooth functions often fit using natural cubic splines
4 Basic Backfitting Algorithm arbitrary smoother - could be natural cubic splines
5 Example using R s gam function library(mgcv) set.seed(0) n<-400 x0 <- runif(n, 0, 1) x1 <- runif(n, 0, 1) x2 <- runif(n, 0, 1) x3 <- runif(n, 0, 1) pi <- asin(1) * 2 f <- 2 * sin(pi * x0) f <- f + exp(2 * x1) f <- f * x2^11 * (10 * (1 - x2))^6 +10 * (10 * x2)^3 * (1 - x2)^ e <- rnorm(n, 0, 2) y <- f + e b<-gam(y~s(x0)+s(x1)+s(x2)+s(x3)) summary(b) plot(b,pages=1)
6 Tree Models Easy to understand: recursively divide predictor space into regions where response variable has small variance Predicted value is majority class (classification) or average value (regression) Can handle mixed data, missing values, etc. Usually grow a large tree and prune it back rather than attempt to optimally stop the growing process
7
8
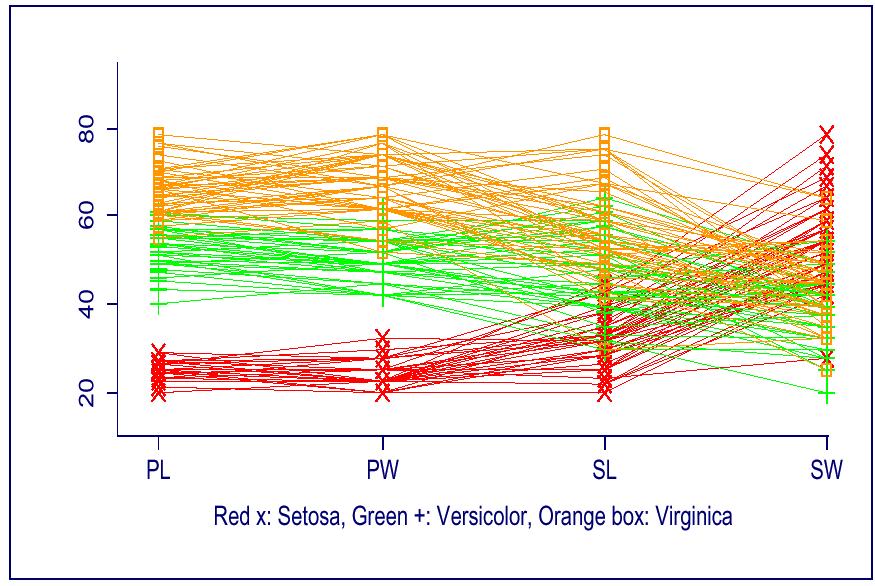
9
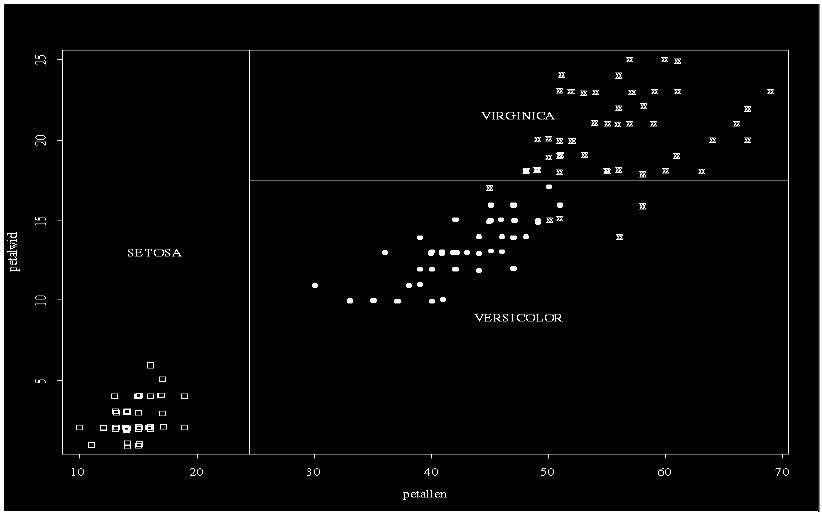
10
11
12
13 Algorithms for Decision Tree Induction Basic algorithm (a greedy algorithm) Tree is constructed in a top-down recursive divide-and-conquer manner At start, all the training examples are at the root Attributes are categorical (if continuous-valued, they are discretized in advance) Examples are partitioned recursively based on selected attributes Test attributes are selected on the basis of a heuristic or statistical measure (e.g., information gain) Conditions for stopping partitioning All samples for a given node belong to the same class There are no remaining attributes for further partitioning majority voting is employed for classifying the leaf There are no samples left
14 Information Gain (ID3/C4.5) Select the attribute with the highest information gain Assume there are two classes, P and N Let the set of examples S contain p elements of class P and n elements of class N The amount of information, needed to decide if an arbitrary example in S belongs to P or N is defined as I( p, n) p p n n =! log 2! log2 p + n p + n p + n p + n e.g. I(0.5,0.5)=1; I(0.9,0.1)=0.47; I(0.99,0.01)=0.08;
15 Shannon Entropy Minimum average message length, in bits, that must be sent to communicate the true value of the random variable to a recipient. Intuitively, use fewer bits to encode the more common symbols
16 Information Gain in Decision Tree Induction Assume that using attribute A a set S will be partitioned into sets {S 1, S 2,, S v } If S i contains p i examples of P and n i examples of N, the entropy, or the expected information needed to classify objects in all subtrees S i is pi + ni E( A)! I( pi, ni ) p n = " i= 1 + The encoding information that would be gained by branching on A Gain ( A) = I( p, n)! E( A)
17 Training Dataset This follows an example from Quinlan s ID3 age income student credit_rating buys_computer <=30 high no fair no <=30 high no excellent no high no fair yes >40 medium no fair yes >40 low yes fair yes >40 low yes excellent no low yes excellent yes <=30 medium no fair no <=30 low yes fair yes >40 medium yes fair yes <=30 medium yes excellent yes medium no excellent yes high yes fair yes >40 medium no excellent no
18 Attribute Selection by Information Gain Computation γ Class P: buys_computer = yes γ Class N: buys_computer = no γ I(p, n) = I(9, 5) =0.940 γ Compute the entropy for age: age p i n i I(p i, n i ) <= > E( age) = I(2,3) + I(4,0) I(3,2) = Hence Gain( age) = I( p, n)! E( age) = Similarly Gain( income) = Gain( student) = Gain( credit _ rating) = 0.048
19 Gini Index If a data set T contains examples from n classes, gini index, gini(t) is defined as n 2 gini( T) = 1"! p j j= 1 where p j is the relative frequency of class j in T. If a data set T is split into two subsets T 1 and T 2 with sizes N 1 and N 2 respectively, the gini index of the split data contains examples from n classes, the gini index gini(t) is defined as ( ) N1 ( ) N 2 gini split T = gini T1 + gini( T 2) N N The attribute provides the smallest gini split (T) is chosen to split the node
20 Regression Trees Typically choose split to minimize within node sum-of-squares
21 Avoid Overfitting in Classification The generated tree may overfit the training data Too many branches, some may reflect anomalies due to noise or outliers Result is in poor accuracy for unseen samples Two approaches to avoid overfitting Prepruning: Halt tree construction early do not split a node if this would result in the goodness measure falling below a threshold Difficult to choose an appropriate threshold Postpruning: Remove branches from a fully grown tree get a sequence of progressively pruned trees Use a set of data different from the training data to decide which is the best pruned tree
22 Approaches to Determine the Final Tree Size Separate training (2/3) and testing (1/3) sets Use cross validation, e.g., 10-fold cross validation Use minimum description length (MDL) principle: halting growth of the tree when the encoding is minimized
23 Missing Predictor Values For categorical predictors, simply create a value missing For continuous predictors, evaluate split using the complete cases; once a split is chosen find a first surrogate predictor that gives the most similar split Then find the second best surrogate, etc. At prediction time, use the surrogates in order
24 Bagging and Random Forests Big trees tend to have high variance and low bias Small trees tend to have low variance and high bias Is there some way to drive the variance down without increasing bias? Bagging can do this to some extent
25 library(daag) spam.sample <- spam7[sample(seq(1,4601), 500, replace=false), ] boxplot(split(spam.sample$crl.tot, spam.sample$yesno)) > names(spam.sample) [1] "crl.tot" "dollar" "bang" "money" "n000" "make" [7] "yesno"
26 library(rpart) spam.rpart <- rpart(formula = yesno ~ crl.tot + dollar + bang + money + n000 + make, method="class", data=spam7) plot(spam.rpart) text(spam.rpart) printcp(spam.rpart)
27
28
29 car.lo <- loess(mileage ~ Weight, car.test.frame) plot(car.lo, xlab="weight", ylab="mpg") lines(seq(1850,3850), predict(car.lo, data.frame(weight=seq(1850,3850)))) car.tree <- rpart(mileage ~ Weight, data=car.test.frame, control = list(minsplit = 10, minbucket = 5, cp = ), method = "anova") plot(car.tree, uniform=true) text(car.tree, digits=3, use.n=true)
30

31
32 cp is a proxy for the number of splits cp should be set small enough that the cross-validated error rate achieves a minimum "g11.8" <- function(device="") { if(device!="")gfile(idth=4.5, height=2.5, device=device) titl <- paste("r plot designed to assist in choosing tree size for the", "\ncar weight & mileage data.") oldpar <- par(mar = c(4.1, 4.1, 3.1, 2.6), mgp = c(2.75, 0.75, 0)) on.exit(par(oldpar)) car.rpart1 <- rpart(price~., data=car.test.frame, cp=0.0025) car.rpart2 <- rpart(price~., data=car.test.frame, cp=0.0025) car.rpart3 <- rpart(price~., data=car.test.frame, cp=0.0025) pr1 <- printcp(car.rpart1) pr2 <- printcp(car.rpart2) pr3 <- printcp(car.rpart3) cp <- pr1[,"cp"] cp0 <- sqrt(cp*c(inf,cp[-length(cp)])) nsplit <- pr1[,"nsplit"] plot(nsplit,pr1[,"rel error"], xlab="no. of splits", ylab="relative error", type="b") axis(3,at=nsplit, labels=paste(round(cp0,3))) mtext(side=3, line=2, "Complexity parameter") mtext(side =3, line=2.5,"a", adj=-0.2) plot(nsplit,pr1[,"xerror"], xlab="no. of splits", ylab="xval relative error", type="b") lines(nsplit,pr2[,"xerror"],lty=2, type="b") lines(nsplit,pr2[,"xerror"],lty=3, type="b") lines(nsplit,pr3[,"xerror"],lty=3, type="b") axis(3,at=nsplit,labels=paste(round(cp0, 3))) mtext(side=3,line=2, "Complexity parameter") mtext(side =3, line=2.5,"b", adj=-0.2) cat(titl, "\n") if(device!="")dev.off() invisible() }
33
34 rpart grows a large tree and then prunes back to minimize the cost-complexity measure: R " = R + " size number of leaves number of errors or deviance or Gini etc. α=0 grows the largest tree possible! cp is the parameter α divided by R for the root tree
35 > library(daag) > summary(mifem) outcome age yronset premi smstat live:974 Min. :35.00 Min. :85.00 y :311 c :390 dead:321 1st Qu.: st Qu.:87.00 n :928 x :280 Median :63.00 Median :89.00 nk: 56 n :522 Mean :60.92 Mean :88.79 nk:103 3rd Qu.: rd Qu.:91.00 Max. :69.00 Max. :93.00 diabetes highbp hichol angina stroke y :248 y :813 y :452 y :472 y : 153 n :978 n :406 n :655 n :724 n :1063 nk: 69 nk: 76 nk:188 nk: 99 nk: 79
36 mifem.rpart <- rpart(outcome ~., method="class", data=mifem, cp=0.0025) plotcp(mifem.rpart) printcp(mifem.rpart) Root node error: 321/1295 = n= 1295 CP nsplit rel error xerror xstd
37 mifemb.rpart <- prune(mifem.rpart, cp=0.03) plot(mifemb.rpart) par(xpd=true) text(mifemb.rpart, use.n=t, digits=3) par(xpd=true)
38 spam7a.rpart <- rpart(formula=yesno ~ crl.tot + dollar + bang + money + n000 + make, method="class", data=spam7, cp=0.001)
39
40 Naïve Bayes Classification Recall: p(c k x) p(x c k )p(c k ) Now suppose: Then: Equivalently: C x 1 x 2 x p! = " p j k j k k c x p c p x c p 1 ) ( ) ( ) (! + = ) ( ) ( ) ( ) ( log ) ( ) ( log k j k j k k k k c x p c x p c p c p x c p x c p weights of evidence
41 Evidence Balance Sheet
42 Naïve Bayes (cont.) Despite the crude conditional independence assumption, works well in practice (see Friedman, 1997 for a partial explanation) Can be further enhanced with boosting, bagging, model averaging, etc. Can relax the conditional independence assumptions in myriad ways ( Bayesian networks )
43 Patient Rule Induction (PRIM) Looks for regions of predictor space where the response variable has a high average value Iterative procedure. Starts with a region including all points. At each step, PRIM removes a slice on one dimension If the slice size α is small, this produces a very patient rule induction algorithm

44
45 PRIM Algorithm 1. Start with all of the training data, and a maximal box containing all of the data 2. Consider shrinking the box by compressing along one face, so as to peel off the proportion α of observations having either the highest values of a predictor Xj or the lowest. Choose the peeling that produces the highest response mean in the remaining box 3. Repeat step 2 until some minimal number of observations remain in the box 4. Expand the box along any face so long as the resulting box mean increases 5. Use cross-validation to choose a box from the sequence of boxes constructed above. Call the box B1 6. Remove the data in B1 from the dataset and repeat steps 2-5.
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Lecture outline. Decision-tree classification
 Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Classification and Regression Trees
 Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Classification: Decision Trees
 Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Decision Tree Learning
 Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Data Mining. 3.3 Rule-Based Classification. Fall Instructor: Dr. Masoud Yaghini. Rule-Based Classification
 Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Tree CE-717 : Machine Learning Sharif University of Technology
 Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Exam Advanced Data Mining Date: Time:
 Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
Introduction to Classification & Regression Trees
 Introduction to Classification & Regression Trees ISLR Chapter 8 vember 8, 2017 Classification and Regression Trees Carseat data from ISLR package Classification and Regression Trees Carseat data from
Introduction to Classification & Regression Trees ISLR Chapter 8 vember 8, 2017 Classification and Regression Trees Carseat data from ISLR package Classification and Regression Trees Carseat data from
Ensemble Learning: An Introduction. Adapted from Slides by Tan, Steinbach, Kumar
 Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Lecture 19: Decision trees
 Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Decision trees. Decision trees are useful to a large degree because of their simplicity and interpretability
 Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Data Warehousing & Data Mining
 Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Sequence Patterns: Generalized
Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Sequence Patterns: Generalized
Machine Learning in Real World: C4.5
 Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Data Mining Practical Machine Learning Tools and Techniques
 Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
The Basics of Decision Trees
 Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
8. Tree-based approaches
 Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Notes based on: Data Mining for Business Intelligence
 Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
Decision tree learning
 Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Part I. Classification & Decision Trees. Classification. Classification. Week 4 Based in part on slides from textbook, slides of Susan Holmes
 Week 4 Based in part on slides from textbook, slides of Susan Holmes Part I Classification & Decision Trees October 19, 2012 1 / 1 2 / 1 Classification Classification Problem description We are given a
Week 4 Based in part on slides from textbook, slides of Susan Holmes Part I Classification & Decision Trees October 19, 2012 1 / 1 2 / 1 Classification Classification Problem description We are given a
Data Science with R. Decision Trees.
 http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
Lecture 20: Bagging, Random Forests, Boosting
 Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Building Classifiers using Bayesian Networks
 Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Example of DT Apply Model Example Learn Model Hunt s Alg. Measures of Node Impurity DT Examples and Characteristics. Classification.
 lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Decision Tree Learning
 Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
CS229 Lecture notes. Raphael John Lamarre Townshend
 CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
Didacticiel - Études de cas. Comparison of the implementation of the CART algorithm under Tanagra and R (rpart package).
.") 1 Theme Comparison of the implementation of the CART algorithm under Tanagra and R (rpart package). CART (Breiman and al., 1984) is a very popular classification tree (says also decision tree) learning
1 Theme Comparison of the implementation of the CART algorithm under Tanagra and R (rpart package). CART (Breiman and al., 1984) is a very popular classification tree (says also decision tree) learning
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Classification and Regression Trees
 Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN
 INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Nesnelerin İnternetinde Veri Analizi
 Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
Credit card Fraud Detection using Predictive Modeling: a Review
 February 207 IJIRT Volume 3 Issue 9 ISSN: 2396002 Credit card Fraud Detection using Predictive Modeling: a Review Varre.Perantalu, K. BhargavKiran 2 PG Scholar, CSE, Vishnu Institute of Technology, Bhimavaram,
February 207 IJIRT Volume 3 Issue 9 ISSN: 2396002 Credit card Fraud Detection using Predictive Modeling: a Review Varre.Perantalu, K. BhargavKiran 2 PG Scholar, CSE, Vishnu Institute of Technology, Bhimavaram,
Supervised Learning. Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
 Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Uninformed Search Methods. Informed Search Methods. Midterm Exam 3/13/18. Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall
 Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
CART. Classification and Regression Trees. Rebecka Jörnsten. Mathematical Sciences University of Gothenburg and Chalmers University of Technology
 CART Classification and Regression Trees Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology CART CART stands for Classification And Regression Trees.
CART Classification and Regression Trees Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology CART CART stands for Classification And Regression Trees.
Lecture 2 :: Decision Trees Learning
 Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
Cse634 DATA MINING TEST REVIEW. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Nonparametric Classification Methods
 Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Lecture 13: Model selection and regularization
 Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Algorithms: Decision Trees
 Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Chapter 5. Tree-based Methods
 Chapter 5. Tree-based Methods Wei Pan Division of Biostatistics, School of Public Health, University of Minnesota, Minneapolis, MN 55455 Email: weip@biostat.umn.edu PubH 7475/8475 c Wei Pan Regression
Chapter 5. Tree-based Methods Wei Pan Division of Biostatistics, School of Public Health, University of Minnesota, Minneapolis, MN 55455 Email: weip@biostat.umn.edu PubH 7475/8475 c Wei Pan Regression
Chapter 3: Supervised Learning
 Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Lecture 06 Decision Trees I
 Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
Logical Rhythm - Class 3. August 27, 2018
 Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Predictive modelling / Machine Learning Course on Big Data Analytics
 Predictive modelling / Machine Learning Course on Big Data Analytics Roberta Turra, Cineca 19 September 2016 Going back to the definition of data analytics process of extracting valuable information from
Predictive modelling / Machine Learning Course on Big Data Analytics Roberta Turra, Cineca 19 September 2016 Going back to the definition of data analytics process of extracting valuable information from
Data Mining and Knowledge Discovery Practice notes 2
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
List of Exercises: Data Mining 1 December 12th, 2015
 List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
ISSUES IN DECISION TREE LEARNING
 ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
A Method for Comparing Multiple Regression Models
 CSIS Discussion Paper No. 141 A Method for Comparing Multiple Regression Models Yuki Hiruta Yasushi Asami Department of Urban Engineering, the University of Tokyo e-mail: hiruta@ua.t.u-tokyo.ac.jp asami@csis.u-tokyo.ac.jp
CSIS Discussion Paper No. 141 A Method for Comparing Multiple Regression Models Yuki Hiruta Yasushi Asami Department of Urban Engineering, the University of Tokyo e-mail: hiruta@ua.t.u-tokyo.ac.jp asami@csis.u-tokyo.ac.jp
CART Bagging Trees Random Forests. Leo Breiman
 CART Bagging Trees Random Forests Leo Breiman Breiman, L., J. Friedman, R. Olshen, and C. Stone, 1984: Classification and regression trees. Wadsworth Books, 358. Breiman, L., 1996: Bagging predictors.
CART Bagging Trees Random Forests Leo Breiman Breiman, L., J. Friedman, R. Olshen, and C. Stone, 1984: Classification and regression trees. Wadsworth Books, 358. Breiman, L., 1996: Bagging predictors.
Machine Learning. Decision Trees. Le Song /15-781, Spring Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU
 Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Data Mining and Knowledge Discovery Practice notes: Numeric Prediction, Association Rules
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
International Journal of Software and Web Sciences (IJSWS)
") International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
10601 Machine Learning. Model and feature selection
 10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]
![Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]](/thumbs/85/91370094.jpg "Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]") Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Model Evaluation
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Model Evaluation
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Fast Edge Detection Using Structured Forests
 Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction
Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction