WITH the development of techniques on RGB-D acquiring
|
|
|
- Charla Williamson
- 5 years ago
- Views:
Transcription
1 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST Object Detection and Tracking Under Occlusion for Object-level RGB-D Video Segmentation Qian Xie, Oussama Remil, Yanwen Guo, Mingqiang Wei, Meng Wang, Jun Wang Abstract RGB-D video segmentation is important for many applications, including scene understanding, object tracking and robotic grasping. However, to segment RGB-D frames over a long video sequence into globally consistent segmentation is still a challenging problem. Current methods often lose pixel correspondences between frames under occlusion and thus fail to generate consistent and continuous segmentation results. To address this problem, we propose a novel spatio-temporal RGB-D video segmentation framework that automatically segments and tracks objects with continuity and consistency over time. Our approach first produces consistent segments in some keyframes by region clustering and then propagates the segmentation result to a whole video sequence via a mask propagation scheme in bilateral space. Instead of exploiting local optical flow information to establish correspondences between adjacent frames, we leverage SIFT flow and bilateral representation to solve inconsistency under occlusion. Moreover, our method automatically extracts multiple objects of interest and tracks them without any user input hint. A variety of experiments demonstrate effectiveness and robustness of our proposed method. Index Terms RGB-D video, Region clustering, SIFT flow, Spatio-temporal segmentation. I. INTRODUCTION WITH the development of techniques on RGB-D acquiring devices, video segmentation on RGB-D data has become an attractive research topic recently. Especially in robotics areas, owing to numerous benefits of RGB-D data, RGB-D video is more frequently adopted to act as visual input for robot perception and is used to model environmental structure [1] and locate individual objects [2] that can be manipulated when robots interact with the surroundings. Thus, in order to achieve a better understanding on scenes, the efficient segmentation of RGB-D video has been becoming Manuscript received; revised. This work was supported in part by National Natural Science Foundation of China ( , ), the Fundamental Research Funds for the Central Universities (NE , NE ), the Natural Science Foundation of Jiangsu Province (BK ), the NUAA Fundamental Research Funds (NS ), and Jiangsu Specially-Appointed Professorship. (Corresponding author: Jun Wang.) Q. Xie, O. Remil and J. Wang are with the College of Mechanical and Electrical Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, China ( qianxie@nuaa.edu.cn; remil.oussama@outlook.com; junwang@outlook.com). M. Wei is with the College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing, China ( mqwei@nuaa.edu.cn). M. Wang is with the School of Instrumental Science and Opto-Electronics Engineering and the School of Computer Science and Information Engineering, Hefei University of Technology, Hefei , China ( eric.mengwang@gmail.com). Y. Guo is with the National Key Lab for Novel Software Technology, Nanjing University, Nanjing, China ( ywguo@nju.edu.cn). an important problem [3]. In this paper, we consider the problem of automatically segmenting and tracking objects from scenes where objects could be occluded by each other. More specifically, we aim at propagating multi-object segmentation mask through time in an RGB-D video. As such, the work falls into the category of unsupervised spatio-temporal object segmentation of RGB-D video. It is worthy to notice that RGB video segmentation is a well-studied research area in computer vision. Through coanalyzing a succession of RGB images, it is possible to enhance segmentation via exploiting mutually complementary information between different frames, and further identify meaningful objects based on their correspondences [4], [5]. Inspired by these techniques on RGB video segmentation, recent works [6], [7] capitalize on depth and motion cues to enhance segmentation result for RGB-D video. These methods utilize optical flow to connect pixels between adjoining frames to obtain a consistent segmentation temporally. However, discontinuity and inconsistency are commonly found from their RGB-D video segmentation results, as shown in Figure 2. Optical flow solely discovers the continuity between frames where the time span is small, owing to the assumptions on optical flow computation. Thus, these approaches are not suitable for scenes with occlusion where objects would disappear for a while. In a word, despite the advantages in RGB-D video data, the segmentation of RGB-D video often suffers from inconsistency and discontinuity. Consequently, RGB-D video segmentation with high automation and efficiency is particularly challenging, especially under the consistency (the same object with the same segmentation label) and continuity (tracking the target object over time) constraints. To address the challenge, we propose an effective spatiotemporal RGB-D video segmentation algorithm by leveraging keyframe sampling, region clustering and mask propagation, which can preserve consistency and continuity in scenes under occlusion. An example of such a scene is shown in Figure 1. The main idea is to first produce a consistent segmentation in some keyframes, and subsequently propagate the segmentation result to the whole video sequence via a mask propagation scheme. Traditional video segmentation algorithms first compute optical flow of each frame, then construct a spatiotemporal graph by connecting corresponding pixels between adjoining frames based on the precomputed optical flow. However, due to occlusion, objects would disappear for a while in the scene, as shown in Figure 2. Consequently, the corresponding pixels would not be found in the next frame where occlusion happens, which makes optical flow based pixel connection scheme fail. That is, the same object could


 and (c) show a discontinuity situation where the ball in two different frames is assigned with two different segmentation labels.")
.")




![[14], [15] over decades, there are very few works of object-based segmentation of RGB-D video.](/docs-images/81/84437996/images/2-9.jpg "We divide our discussion on the related work into two parts, RGB-D video segmentation")
2 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST Time Fig. 1. Consistent and continuous segmentation of an RGB-D video by our method. Given an RGB-D video sequence, it is desirable to extract objects and assign the same segmentation label to the same object through the whole sequence without any user input cue. Top: original RGB-D video sequence. Bottom: consistent and continuous object segmentation result (object points are shown bold and colored while background points small and black). lateral space, which can segment multiple objects in the video simultaneously. As a consequence, our method is capable of tracking multiple objects over time. II. R ELATED W ORK Fig. 2. Discontinuity and inconsistency in RGB-D video segmentation. A ball is rolling behind a cylinder object. (a) and (c) show a discontinuity situation where the ball in two different frames is assigned with two different segmentation labels. (b) shows a inconsistent situation where two parts from the ball in a single frame are assigned with two segmentation labels. be regarded as a new object when it appears again owing to the loss of connection information, as shown in Figure 2(b). In contrast with these approaches, our method first samples some keyframes from a video sequence, followed by a graph-based segmentation to extract object segments in the keyframes. Inspired by the idea of using SIFT flow to explore correspondences between videos [8] and images [9], we present a clustering method leveraging SIFT flow to find pixel correspondences between keyframes. In this way, our method can discover the consistency in a video sequence. To ensure the continuity, a mask propagation scheme is extended to RGB-D video segmentation. We convert pixels in RGBD space into a higher bilateral space where divided objects could be grouped together, and subsequently the consistent segmentation result could be continuously propagated through the whole video sequence. Contributions. Overall, our contributions are as follows: We propose a novel RGB-D video segmentation framework, which segments objects with consistency and continuity even in the presence of complete occlusion. We present a region clustering approach by utilizing SIFT flow to establish pixel correspondences between object segments in the keyframes. We design a multi-label segmentation algorithm in bi- While segmentation of RGB video has been extensively studied, both in dense segmentation [10], [11], [12] and objectbased segmentation [13], [14], [15] over decades, there are very few works of object-based segmentation of RGB-D video. We divide our discussion on the related work into two parts, RGB-D video segmentation and bilateral space segmentation. RGB-D video segmentation. Several approaches on RGBD video segmentation have been proposed recently, which can be grouped into two categories. One is the dense RGB-D video segmentation in which pixels are grouped into several clusters of which the properties are similar [16], [17], [18]. The other category essentially divides pixels into two classes, i.e., foreground or background [19], [20]. For dense segmentation, Weikersdorfer et al. [21] combined the position and normal information with color information to compute depth-adaptive supervoxels, then employed spectral graph clustering to partition a video into spatio-temporal segments. However, their method can only handle situations with partial occlusion. Hickson et al. [7] proposed a hierarchical graph-based segmentation approach for RGB-D point clouds. Their method first performs over-segmentation to obtain supertoxel regions in each frame of point cloud separately. These super-toxel regions are then merged together iteratively, followed by a bipartite graph matching to ensure the temporal continuity. However, their results may lose temporal consistency on the situation of occlusion, since features that measure the difference between regions in bipartite graph matching are sensitive to missing data caused by occlusion. Recently, Jiang et al. [22] presented a framework of spatio-temporal video segmentation, which can handle large displacement with significant occlusion. Nevertheless, their method is restricted to videos of a static scene. In contrast with these approaches, the keyframe sampling scheme and the mask propagation in bilateral space enable our method to track objects in dynamic scenes even with complete occlusion.



![[23] presented a segmentation algorithm to segment and track deformable objects in RGB-D video under the framework of conditional random field.](/docs-images/81/84437996/images/3-3.jpg "Their method utilizes semi-supervised learning to make best use of rich feature sets.")

![The concept of bilateral grid is first introduced by Chen et al. [24]. In their paper, pixels are lifted into bilateral space with a higher-dimension based on position and color.](/docs-images/81/84437996/images/3-5.jpg "Thanks to the properties of bilateral space, bilateral filtering can be performed as a standard Gaussian filter. The idea of bilateral grid is then applied to image segmentation by Maerki et al.")
![[25] and they employed a graphcut algorithm on these grid vertices to assign foreground or background labels, and then accumulated labels of image plane pixels from those labeled grid vertices.](/docs-images/81/84437996/images/3-6.jpg "They used the splatting and slicing operations to accumulate values between bilateral grid vertices and image pixels.")


3 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST Frame sampling Object candidate extraction Region clustering Mask propagation Fig. 3. Algorithm overview. From an input RGB-D video sequence, we first uniformly sample some frames in temporal distribution, i.e., keyframes. For each keyframe, a graph-based segmentation algorithm is applied to generate object segments, i.e., object candidates. Subsequently, we cluster these object candidates into several classes to obtain the consistent segment mask. Finally, the segmentation mask in the keyframes is propagated to the unsegmented frames in bilateral space. As a result, multiple objects in the scene are extracted with consistent segmentation labels. Alternatively, to extract objects from RGB-D video, Alex et al. [23] presented a segmentation algorithm to segment and track deformable objects in RGB-D video under the framework of conditional random field. Their method utilizes semi-supervised learning to make best use of rich feature sets. However, it needs additional segmentation hints labeled by the user, and merely provides foreground/background segmentation results. Comparatively, our method does not require any initial segmentation or label hint as input while capable of segmenting multiple objects simultaneously. Bilateral space segmentation. The concept of bilateral grid is first introduced by Chen et al. [24]. In their paper, pixels are lifted into bilateral space with a higher-dimension based on position and color. Thanks to the properties of bilateral space, bilateral filtering can be performed as a standard Gaussian filter. The idea of bilateral grid is then applied to image segmentation by Maerki et al. [25] and they employed a graphcut algorithm on these grid vertices to assign foreground or background labels, and then accumulated labels of image plane pixels from those labeled grid vertices. They used the splatting and slicing operations to accumulate values between bilateral grid vertices and image pixels. However, it is essentially a semi-supervised approach which requires prior cues as input. Accordingly, we extend the bilateral space concept to RGB-D video segmentation. Comparatively, our algorithm does not rely on any human annotation. We design an automatic multi-label graph-cut segmentation algorithm in bilateral space. Moreover, to exploit the advantages of RGB- D data to the full, we integrate depth cues to the data energy term definition when solving a graph-cut problem. III. OVERVIEW Taking as input an RGB-D video sequence, our goal is to segment objects of interest in each frame and track them over the sequence with spatial-temporal information in the presence of data deficiency (low luminance and complete occlusion). We formulate this as a multi-object segmentation problem, in which the initial segmentation mask is obtained by an object detection process. Specifically, our spatio-temporal RGB-D video segmentation algorithm consists of object candidate extraction, region clustering and mask propagation. The pipeline is illustrated in Figure 3. Object candidate extraction. We first extract segments of objects, i.e. object candidates, in some keyframes, which is formulated as a graph-based object segmentation problem with depth and motion information involved. To overcome the inconsistent segmentation caused by one-by-one frame connection scheme under occlusion, some keyframes are sampled on the temporal dimension from the given RGB- D video sequence. A fast graph-based object segmentation algorithm is subsequently carried out in keyframes. Then we generate segments and design a rejection step to extract those segments belonging to objects. We group those adjoining object segments in 3D space by a region growing scheme and thereby obtain all object candidates in each keyframe. Region clustering. We then classify object candidates into clusters by object categories to produce consistent segmentation in keyframes in Section V. Given the object candidate set, we generate an affinity matrix. SIFT flow is exploited to find correspondences between object candidates, based on which we measure the pairwise similarity. Having the pairwise similarity matrix, we then group object candidates into clusters via Affinity Propagation(AP) clustering. As a result, object candidates of the same object are arranged together and their segmentation labels are unified according to a clustering result. In this way, our method can yield a consistent multi-object segmentation mask in keyframes. Mask propagation. The whole frame set in the video sequence is not segmented yet. In Section VI, we convert pixels in RGB-D space to a bilateral space which can also avoid the inconsistent segmentation caused by occlusion. By splatting properties of pixels to vertices of bilateral grid, a mask propagation is then performed by solving a multiobject graph-based segmentation algorithm in the bilateral space. Finally, we obtain a continuous segmentation in RGB- D space by the slicing operation, which transmits labels on the bilateral grid vertices to the lifted pixels. As a result, our method successfully propagates the initial segmentation mask in keyframes to those unsegmented frames while respecting continuity and consistency over time.

4 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST IV. O BJECT CANDIDATE EXTRACTION In this stage, we present a keyframe sampling strategy and a graph-based segmentation algorithm with the inclusion of depth and motion information. Given an RGB-D video sequence {F 1,..., F N }, which constitutes a set of RGB images {I 1,..., I N }, and depth images {D1,..., DN }, we uniformly sample some frames from the sequence, followed by a graphbased RGB-D image segmentation in the sampled frames to produce partitioning of the entire images. Subsequently, object candidates are obtained by discarding background segments through a learned SVM classifier. A. Keyframe Sampling For most of traditional video segmentation methods, pixellevel mapping is established by connecting corresponding pixels between two neighboring frames based on the precomputed optical flow. However, this connection scheme would result in the loss of connection information under occlusion. That means optical flow would fail to recapture the correspondence when an object disappears and appears again in a short time due to occlusion in the scene. Hence, traditional video segmentation ways, in which frames on the whole video sequence are usually connected one-by-one in a temporal order, can not deal with the occlusion situations as shown in Figure 2. To solve this problem, we propose to uniformly sample some keyframes from the video sequence and explore connections between the keyframes. We sample the collected frames by taking frames with a certain temporal interval η, called as keyframes and denoted by {I i, I i+η, I i+2η,...} and {Di, Di+η, Di+2η,...}. The sampling interval η is an adjustable parameter. Choosing the interval η is a tradeoff between segmentation quality and computation cost. We set η to be 75 in our experiments. Unlike those methods requiring to pre-compute optical flow for each frame, our approach only computes optical flow in the keyframes, which makes our method more efficient, while a segmentation result of high quality can still be achieved by the mask propagation scheme. B. Graph-based Object Segmentation The aim in this step is to extract objects of interest in the keyframes obtained from the previous stage. We formulate it as an unsupervised segmentation problem, which classifies frames into non-overlapping regions R = {rti i = 1, 2,..., k; t = 1, 2,..., m}, where rti denotes the ith segment in frame t which consists of a set of pixels assigned to the same segmentation label. Given a set of keyframes, a graph-based segmentation algorithm is sequentially employed on them separately. For each frame in the keyframe set, we create an undirected graph G = (V, E, W ), where V = {v1,..., vnp } represents image pixels, and eij = (i, j) E is an edge connecting two neighboring pixels, namely vi and vj. The 8-connected neighborhood is utilized here. Each edge eij is weighted by ωij W that measures the dissimilarity between vi and vj. We follow the similar segmentation scheme in [26] while updating formulations of weights between edges. To integrate Fig. 4. Clustering result of object candidates. The first row shows five sampled keyframes with their object candidates extracted from each corresponding frame. On the bottom, the candidates are grouped into clusters based on similarity between their feature representations. depth and motion information, the weight between pixels vi and vj is defined as: ωij = W > Θ (1) Θ = [δijc, δijd, δijm ]> (2) where δijc, δijd and δijm are properties of color, depth and motion between pixels respectively. W > R3 is the weight vector assigning weights to those elements in vector Θ. δijc is the color distance between pixels vi and vj, measured by the Euclidean distance in the HSV color space. To compute the depth error, each RGB-D image is converted into a point cloud, and then we compute the Euclidean distance between two pixels based on their coordinates in 3D space. To make the best use of properties of RGB-D video, we embed motion information into the similarity definition of nodes in graph, which makes the object segmentation more robust. When objects or the camera are moving in the scene, boundary pixels can as well be located using discontinuity in optical flow map. Then, δijm is computed as the distance of optical flow vectors between pixel vi and pixel vj. We employ the algorithm proposed in [27] to calculate optical flow maps between two consecutive frames. Note that optical flows are only computed in the keyframes, which only occupy a small ratio of the whole video sequence. As a consequence, we are able to obtain segmented regions for all keyframes. C. Post-process After performing the graph-based segmentation, each keyframe is divided into a set of segments R. Since our goal is to extract objects of interest in the video, there still exist some false positives segments that we not are interested in, i.e. segments of background. For example, the result may contain large segments, such as walls, tables and floors which have significantly large sizes compared to normal objects. We need to differentiate object segments from the whole segments. Therefore, we introduce R = {r it i = 1, 2,..., n ; t = 1, 2,..., m} as object segments, where r it denotes the ith object segment in the tth frame. In order to get R, a
 classifier to recognize all object segments from the remained segments.")


 Color: Color features are computed in the HSV color space which is more robust with changes in lightness.")
5 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST rejection operation on set R is proposed. Segments far from the camera are discarded first. Supervised learning is then utilized to train a Support Vector Machine (SVM) classifier to recognize all object segments from the remained segments. Since categories of objects in different datasets may differ from each other, every dataset needs a different classifier. That is to say, for each dataset, a new classifier should be trained from scratch on its own data. For our own RGB-D video dataset, we collect another dataset consisting of 29 scenes. The graph-based segmentation is then performed on these videos, generating many segmented regions. To speed up this step, each video consists of only 50 frames. We then manually choose 400 object segments and 300 background segments as the training data of the SVM algorithm with Gaussian Radial Basis Function kernel. Meanwhile, some discriminative features are utilized to present the segmented regions. Here are the features used in our classifier: 1) Color: Color features are computed in the HSV color space which is more robust with changes in lightness. We then compute the variance in the color information (H and S channels) and intensity (V channel) to generate the color features. 2) 2D geometry: These features encoding 2D geometry information of segments are extracted on image plane. Since the size of segment determines the classification result to a great extent, we compute the height, width and area of segments to form the 2D geometry features. 3) 3D geometry: RGB-D image is converted to a 3D point cloud with color. The points are then grouped into patches according to segmentation labels. 3D geometry features reflect the depth variance of patches. Specifically, we utilize geometric features from the work of Reza et al. [28]. We also employ the Geometric Moments [29] to embed shape information of point cloud. After the post-process stage, all object segments in the sampled frames are collected. Subsequently, a region growing scheme is adopted to merge neighboring object segments to generate object candidates in 3D space. The object candidates in some keyframes are shown in Figure 4. V. REGION CLUSTERING Our goal in this step is to search all object candidates belonging to the same object in the keyframes, which is cast as a clustering problem. Given the object candidates R, we perceptually group them by object classes. As shown in Figure 5, after the unsupervised segmentation in keyframes, two types of problems exist. One is that object candidates coming from the same object in two different frames may be assigned with different labels. Because the keyframes are separately segmented in the previous step. As a consequence, the candy boxes in the three keyframes are assigned with three different labels before performing clustering, as shown in Figure 5. The other is that segments belonging to the same object in one frame could have different labels because of inter-object occlusion in the scene. As shown in frame i + η in Figure 5, a ball is divided into two parts due to inter-object occlusion. Hence, the segmentation Cluster 1 Cluster 2 Frame i Frame i+η Frame i+2η Cluster 1 Cluster 2 Frame i Frame i+η Frame i+2η Fig. 5. Illustration of clustering object candidates in keyframes. Before clustering, the object candidates of the same object are with different segmentation labels which are not consistent. Consistent segmentation labels will be assigned to the corresponding object candidates based on the clustering result. algorithm generates two object candidates from the same ball. As a result, the same object is assigned with two different segmentation labels in one frame. To address these two issues, we refer to affinity propagation [30] clustering to assign labels to the object candidates, in which the object candidates with similar properties should possess the same label. Next, we describe the clustering method to process partial presentation in an occluded scene. Affinity propagation associates each data point, i.e. object candidate, with a cluster center within the input data in a way to maximize the overall sum of similarities between data points and their corresponding cluster centers. The algorithm takes as input an affinity matrix which describes the similarity between pairs of object candidates. In order to simplify the notation of object candidates, we leave out the frame index t. The set of object candidates is then rewritten as R = {ri i = 1,..., n}, where n is the total number of object candidates within all keyframes. Given the object candidate set, we form the affinity matrix D R n n. D is a symmetric band pairwise matrix with the following structure: D = D 1,1 D 1,2 D 1,3 D 1,4 D 1,n D 2,1 D 2,2 D 2,3 D 2,4 D 2,n D 3,1 D 3,2 D 3,3 D 3,4 D 3,n.... D i,j. D n,1 D n,2 D n,3 D n,4 D n,n where D i,j represents the similarity measurement between the ith and jth object candidates. Specifically, D i,j is defined as: where σ r is a scaling factor, and (3) D i,j = exp( d2 (r i, r j ) σ 2 r ) (4) d(r i, r j ) = D c (r i, r j ) D o (r i, r j ) D g (r i, r j ) (5) Based on the fact that the object candidates of the same object should have similar appearance, we introduce D c as the color histogram similarity between two object candidates: D c (r i, r j ) = 1 M c χ 2 color(r i, r j ) (6)






 function.")
6 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST Fig. 6. Illustration on the sensitivity of color histogram to missing data. As shown, the color histograms of the occluded part significantly changes from the complete one. where χ 2 color is the χ2 -distance between the color histograms, while M c represents the mean χ 2 -distance of all object candidates. The similarity metric of the color histograms may fail in some cases, such as missing data due to occlusion which often leads to the partial representation. As illustrated in Figure 6. To solve this problem, we propose an overlap measurement to enhance the appearance component in the similarity definition, and we present D o as the overlap measurement between two object candidates ri, r j. It is a vital means to act as the similarity measurement when only part of an object can be seen in some frames due to occlusion. Nevertheless, the overlap measurement can handle the partial correspondence situation. To compute the overlap measurement, we utilize SIFT flow to find the partial correspondences between object candidates. On this basis, we measure overlap between two object candidates as: O(r i, r j ) = r i W arp(r j ) min( r i, r j ) (7) where W arp(rj ) transforms the region of candidate r j to the frame where ri lies in, which is computed by dense SIFT flow [9]. measures the area of elements. The SIFT flow algorithm aligns an image to another similar image, which can establish a dense pixel correspondence across different scenes. It also allows matching of objects located at different parts of a scene. In particular, we compute SIFT flow from the frame of rj to the frame of r i with the region of candidates as the foreground binary masks, which encourages matching between foreground pixels. We then use the computed dense pixel correspondences to wrap pixels in the frame of ri using pixels from the frame of rj, generating the W arp(r j ) function. Accordingly, we define our overlap term as: { 0.01 if O(r D o (ri, rj ) = i, rj ) τ 1 O(ri, r j ) otherwise (8) where τ is an overlap threshold. The intuition behind this equation is that two object candidates are more likely to be from the same object, if their overlap measurement is over a given threshold. To further enhance the robustness of our similarity definition, we incorporate the 3D shape information into the similarity measurement as well. We let D g measure the geometric similarity. In our work, the Geometric Moments [29] is utilized as our shape descriptor thanks to their Fig. 7. Illustration of mask propagation scheme. Unsegmented frames are with red borders. efficient and easy computation characteristics. We convert the regions into point cloud based on camera intrinsic parameters and formulate D g, similar to D c, as: D g (r i, r j ) = 1 M g χ 2 g(r i, r j ) (9) where χ 2 g is the χ 2 -distance between their geometric moments and M g denotes the mean χ 2 -distance of all object candidates. With the given affinity matrix, the affinity propagation clustering algorithm computes the assignment vector whose values are indices of cluster centers. Each object candidate is assigned to a cluster center by the assignment vector. In this way, the object candidates are grouped into several clusters according to their similarity measurements. The clustering result is represented in Figure 4. We use the cluster assignments as labels for the object candidates so as to obtain consistent segmentation labels in the keyframes, as illustrated in Figure 5. VI. MASK PROPAGATION In this section, our mask propagation method in bilateral space is presented. Given the labeled object candidates in the keyframes, we spread the segmentation result to the whole video sequence, as illustrated in Figure 7; hence, our video segmentation can be then formulated as a mask propagation problem, which is performed under a graph-cut framework in bilateral space, i.e. a higher dimensional feature space. We uniformly partition bilateral space to form the bilateral grid, V Γ, and infer labels on the vertices, v V Γ, of this grid. The bilateral grid is a high dimensional array where each dimension corresponds to one feature, and it is generated by regularly sampling in each dimension. Bilateral representation leads to a simple and efficient computation framework, while still preserving large spatio-temporal regularization under occlusion, as shown in Figure 8. It is worthy to notice that one single mask frame is used in [25], which leads to a significant quality degradation on segmentation result with increasing numbers of frames in the video. Comparatively, our method utilizes the keyframes as the initial mask to maintain the quality of the segmentation result through the whole video sequence. By this way, the segmentation quality is still well guaranteed even when the video is enlarged. Furthermore, our
7 one dimension JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST Lifted pixel Bilateral grid 0.9 Splatting Slicing 0.9 Bilateral space Grid vertex Graph cut labels on grid vertices Fig. 8. Illustration of the bilateral representation. Please note this is a simple version for the illustration. method adds the depth channel as an additional dimension to bilateral space. Meanwhile, we replace the graph-cut with a multi-label graph-cut technique. A. Bilateral Space We convert each pixel p = [x, y, d, t] P, the pixel set in all frames, to a vector in a higher dimensional feature space, specifically, a 7-dimensional space: b(p) = [c h, c s, c v, x, y, d, t] R 7 (10) The first three dimensions (c h, c s, c v ) correspond to the three components in HSV color space and (x, y, d) refer to spatial coordinates in the image and depth plane, while t corresponds to the temporal dimension. The bilateral space is then partitioned into a regular grid. Instead of labeling a lifted pixel b(p) directly, we use the splatting operation to accumulate values on the bilateral grid vertices by summing up adjacent lifted pixels with weights. For each vertex v V Γ, the accumulated value is computed as: p(v ) = w(v, b(p i )) ˆp i (11) where p i P ˆp i = (p(l 1 p i ), p(l 2 p i ),..., p(l n p i ), 1) (12) and p(l j p i ) is the probability that label l j is assigned to pixel p i. The weight function w(v, b(p i )) determines the range and influence that the neighboring lifted pixel b(p i ) imposes on the vertex v. Similar to [25], we adopt the adjacent interpolation scheme owing to its good compromise between the quality and the computation, memory efficiency. B. Multi-label Graph-Cut In this section, we leverage a multi-label graph-cut model to handle multiple foreground segmentation, which enables our method to track more than one object simultaneously. At the same time, integrating depth information into the data energy term allows us to measure feature statistics in a relatively complex scene (e.g., low luminance situation) We infer labels of the grid vertices by constructing a graph G Γ = (V Γ, E Γ ), where V Γ represents the vertex set in the bilateral grid. Suppose there exist M objects in the video scene, the task is to find a label from the set of objects to each vertex v V Γ. We introduce L = {l v v V Γ } as the label of V Γ, where l v is defined as the label of vertex v in the bilateral grid. Based on the assumption that segmentation is smooth in bilateral space, our multi-label energy can then be formulated as: E(L) = D v (l v )+λ S v,u (l v, l u )(1 δ(l v l u )) v V Γ v,u E Γ (13) The binary smoothness term S v,u measures the extent to which labels between adjacent vertices are not piecewise smooth, balanced with the multiplier λ. The unary data term D v (l v ) models deviations from the region clustering results. From the definition, our function encourages segmentation consisting of several regions where vertices in the same region have similar labels. In particular, the unary data term is defined as: D v (l v ) = ln p(l v v ) (14) where p(l v v ) denotes the probability of assigning label l v to vertex v. The more the labeling agrees with the clustering result, the lower the score D v (l v ) is. The smoothness term S v,u comprises boundary properties of segmentation, which is interpreted as a penalty for the discontinuity between vertices v and u. As [25] pointed out, in order to make the operation of assigning different labels to two vertices equivalent to the operation of assigning labels to all the original lifted pixel splattered to these two vertices, the weights between vertices should be scaled by the total number of points that have been assigned to the two vertices. Thus, our smoothness term S v,u (l v, l u ) is formulated as: S v,u (l v, l u ) = g(v, u ) S (v ) S (u ) (15) where S (v ) and S (u ) indicate the number of lifted pixels splattered to vertices v and u respectively, see Figure 8. g(v, u ) is a high-dimensional Gaussian kernel, defined as: g(v, u ) = e 1 2 (v u ) T Σ 1 (v u ) (16) where the diagonal matrix Σ scales each dimension to balance the color, spatial and temporal dimensions. The segmentation result on the bilateral grid can be obtained by minimizing the energy function E(L), which can be solved efficiently with the multi-label graph-cut algorithm [31]. When the labels are obtained on the grid vertices, we perform the slicing operation to transmit the labels on the bilateral grid vertices to the lifted pixels, i.e. inverse process of splatting. Accordingly, the same interpolation scheme is adopted to accumulate values for the lifted pixels. As a result, a consistent and continuous RGB-D video segmentation is obtained. VII. RESULTS AND DISCUSSIONS To validate the effectiveness of our method in segmenting RGB-D video, we evaluate our method on several video sequences from the TUM Dataset [32], the NYU V2



















8 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST Fig. 9. Segmentation result in the case of complex scene. The upper row shows some original input frames. The bottom row shows the corresponding segmentation result. Fig. 10. Segmentation result on a realistic scene from the NYU V2 Dataset, in which some furniture disappears in a short time. Note that the segments of the clutter of toys are omitted by our SVM classifier, which is trained with other videos containing furniture in the NYU V2 Dataset. Dataset [33], the T-LESS Dataset [34] and our own dataset. For our own dataset, we use a kinect sensor to collect RGBD video dataset. Each video sequence consists of more than 700 frames of RGB and depth images. All frames are manually segmented to generate the ground truth for the purpose of quantitative evaluation. In general, the datasets include scenes with different levels of luminance, texture and complexity. A. Raw Data Complex scene. The capability of our method to deal with complex scenes is assessed in Figure 9. As shown in the images, objects are stacked together arbitrarily. Both the complexity of the scene and the large quantity of objects impose significant difficulties in consistently segmenting the scene for RGB-D video segmentation methods. However, thanks to our background segments rejection technique, our method is able to extract the segments of objects that we are interested in. Meanwhile, geometry information is invoked to measure the similarity between object candidates, different objects in similar color are clustered into different categories and thus the correct labels are generated in the keyframes. As a consequence, the consistent and continuous segmentation result is achieved over all the video sequence by our method. Realistic scene. We evaluate our method in a realistic scene from the NYU V2 Dataset. Figure 10 shows some of frames with segmentation result. The scene is captured by a handheld RGB-D camera in a play room and contains 995 frames in total. The goal of our algorithm is to correctly segment some items of furniture. Apparently, the camera is moving randomly in the room, making the short-time disappearance of some furniture in the video happens frequently. However, our method leverages the region clustering and bilateral representation to arrange together object candidates of the same object, and consequently the missing connection information between the object candidates between frames is thereby recaptured. Therefore, our method successfully ensures the segmentation labels all consistent through the whole video sequence. Complete occlusion. In Figure 11, we illustrate the capability of our algorithm to segment and track objects in the scenes where objects are completely missing in some frames. There are seven objects on the table and a robot is manipulated to collect the RGB-D video with a kinect sensor while moving in front of the scene. Owing to movement of the camera, a yellow measuring tape becomes entirely disappeared and appeared again. This complete occlusion problem is challenging for current segmentation methods, since they have no ability for re-acquisition when the target is thoroughly missing. The connection established by optical flow becomes invalid here as explained in Section IV. However, by incorporating the diverse information in our object candidate similarity measurement, the same objects in different frames can be clustered together and hence the mask propagation scheme can subsequently transfer the correct segmentation labels to all the frames. As a result, our method succeeds in obtaining the consistent and continuous segmentation result from an occluded scene, even










![al. [7] on segmenting the](/docs-images/81/84437996/images/9-10.jpg "scene with The bottom")

![method and [7].](/docs-images/81/84437996/images/9-12.jpg "Green line represents the")



![[7]. Changes in number of](/docs-images/81/84437996/images/9-16.jpg "segments illustrate the")






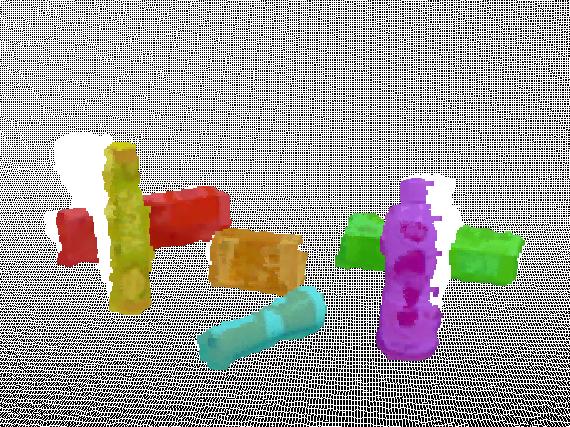


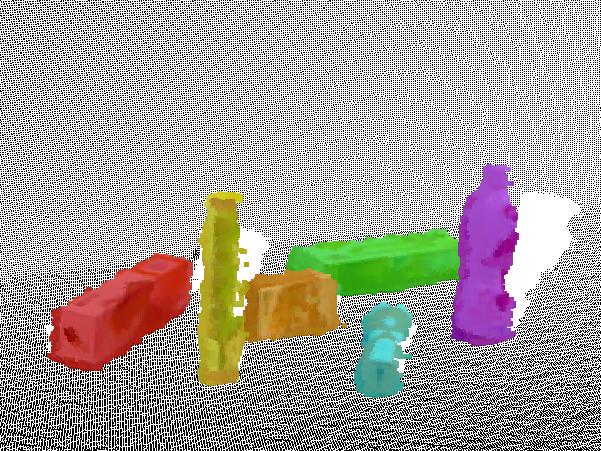
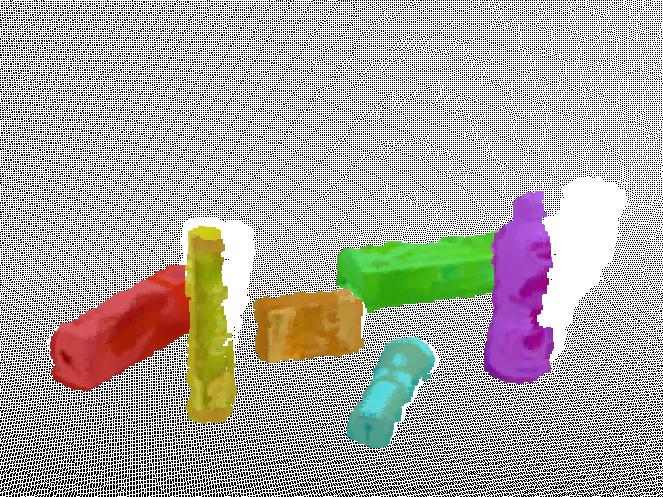
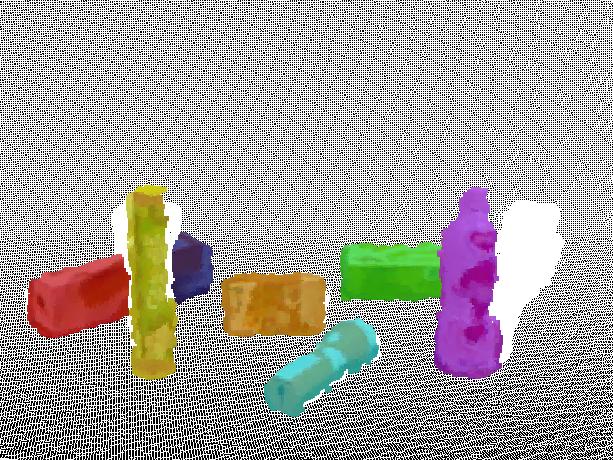
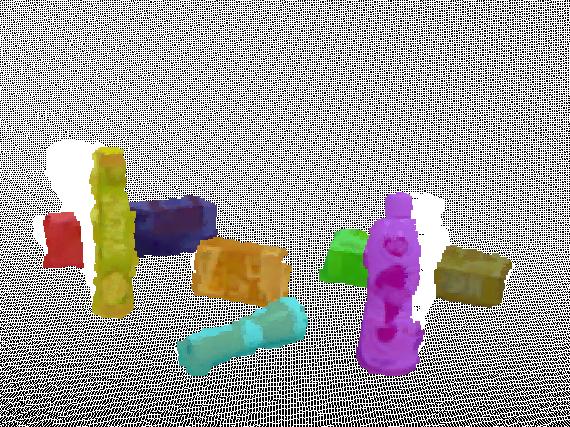
9 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST Fig. 11. Segmentation result in the case of complete occlusion. Even in the presence of complete occlusion as in the middle frame, our method is still able to produce consistent and continuous segmentation. Segmentation result on the T-LESS Dataset. Segments Number Ours Hichson et al. Fig Hichson et al. Ours Ground truth 6 Time Fig. 13. Comparison to Hickson et al. [7] on segmenting the scene with occlusion. The bottom graph shows quantitative comparisons between our method and [7]. Green line represents the ground truth of object number in the scene, blue line denotes the number of our segments and red line refers to the segmentation result in [7]. Changes in number of segments illustrate the discontinuity and inconsistency of their segmentation result. though the objects are completely missing in some frames. We also evaluate the proposed method on the T-LESS Dataset, as shown in Figure 12. Several textureless objects are placed on a rotating platform in the scene. When objects rotate with the platform in the scene, occlusion between objects would happen. In such a case, our method produces consistent segmentation results. Although the appearance between these objects in the scene is quite similar with each other, resulting from their textureless characteristic, the geometric component in the similarity measurement can still differentiate the object candidates apart and group different objects into distinct clusters.
 (b) (c) Fig. 14. result.")
 shows the input RGB images.")
![(b) shows result from [7] and (c) shows our (a) (b)](/docs-images/81/84437996/images/10-2.jpg "(c) Fig. 15. result.")
 shows the result from [7] and (c) shows our B.")


















10 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST (a) (b) (c) Fig. 14. result. Segmentation result of an RGB-D video in the NYU V2 Datasets. (a) shows the input RGB images. (b) shows result from [7] and (c) shows our (a) (b) (c) Fig. 15. result. Segmentation result of an RGB-D video in the TUM Datasets. (a) shows the input RGB images. (b) shows the result from [7] and (c) shows our B. Comparisons There is little work focusing on multi-object segmentation and tracking on RGB-D video. We compare with the most related work [7], where RGB-D video is segmented into regions with consistency. To ensure a fair comparison, we perform a rejection process described in Section IV to discard background segments. In order to obtain individual object candidates, a region growing process on the RGB-D point cloud is executed to merge neighboring object segments together based on their positions in 3D space. We show comparative segmentation results on three different datasets, our own dataset, the NYU V2 Dataset and the TUM Dataset, shown in Figure 13, Figure 14 and Figure 15 respectively. Figure 13 compares the segmentation method in [7] and ours on our own dataset. As the camera moves around objects on the table, occlusion synchronously occurs between objects. In [7], edges are constructed between adjacent frames by connecting pixels on the precomputed optical flow and such connection would be broken when objects disappear. When the same object appears again, their method regards it as a new object. Note that their method produces a new segmentation label on the reappeared part of boxes in the middle frame. In contrast, our algorithm leverages region clustering to solve the occlusion problem by grouping separated object candidates of the same object in keyframes. As shown in the first and last frames in Figure 13, their method lacks the continuity in the whole video sequence due to occlusion. It yields two labels on the same box. Comparatively, our method assigns the same labels to segments belonging to the same object within the whole video sequence. Figure 14 and 15 show comparative results on the NYU V2 Dataset and the TUM Dataset respectively. For experiment in Figure 14, we use the same SVM classifier trained on our
![JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11 TABLE I QUANTITATIVE COMPARISONS OF [7] AND OUR METHOD. NOB: NUMBER OF EXTRACTED OBJECTS, GT: GROUND TRUTH.](/docs-images/81/84437996/images/11-0.jpg "Figures Methods TP FP Nob GT Figure 1 Figure 3 Figure 9 Figure 10 Figure 11 Figure 12 Figure 13 Figure 14 Figure 15 Figure 16 Ours 96.5 2.9 5 Hichson el al. 94.2 5.0 6 Ours 98.5 0.8 3 Hichson el al.")




.")
11 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST TABLE I QUANTITATIVE COMPARISONS OF [7] AND OUR METHOD. NOB: NUMBER OF EXTRACTED OBJECTS, GT: GROUND TRUTH. Figures Methods TP FP Nob GT Figure 1 Figure 3 Figure 9 Figure 10 Figure 11 Figure 12 Figure 13 Figure 14 Figure 15 Figure 16 Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al Ours Hichson el al TABLE II TIME CONSUMPTION OF OUR ALGORITHM. KF: KEYFRAME, KS-TIME: KEYFRAME SEGMENTATION TIME, MP-TIME: MASK PROPAGATION TIME AND T: TOTAL TIME(PER FRAME). Figures Frames KF KS-time MP-time T Figure s 29min25s 2.3s Figure s 24min16s 2.1s Figure s 27min06s 2.5s Figure s 41min55s 2.5s Figure s 30min50s 2.3s Figure s 10min34s 2.1s Figure s 33min26s 2.5s Figure s 13min55s 2.7s Figure s 9min58s 2.1s Figure s 26min17s 2.1s own dataset which aims at detecting small objects on the table, and we train a new SVM classifier for Figure 15 by utilizing other videos in the TUM Dataset. As shown in Figure 14, the trashcan at the bottom right corner is recaptured by our method after a short-time disappearance in the scene. However, [7] assigns a different label to the reappeared trashcan because the connection between the frames in their method is cut down by occlusion. See Figure 15, the occlusion between the two persons appears as they walk in front of the camera. [7] mistakenly regards the reappeared person as a new person, which can be seen from the new assigned segmentation label in Figure 15(b). As a result, three persons are detected by their method while our method can track the occluded person all the way along the video sequence, as shown in Figure 15(c). C. Quantitative Evaluation Quantitative metrics: In order to quantify our results, we extend the well-established quantitative metrics that are used in [35]. Specifically, Rt i represents all pixels of the ground truth segmentation of object i in frame t. Similarly, St i denotes all pixels of the segmentation results of the corresponding object. Then the true positive can be described as T Pt i = Rt S i t, i which is the overlap of both pixel sets. Subsequently, the false negative can be measured by F Pt i = St i \ T Pt i. The equations below calculate the average scores over the whole video sequence, where n is the number of object segments and m is the number of frames. T P = 1 n m n m i=1 t=1 T P i t R i t, F P = 1 n m n m i=1 t=1 F P i t S i t (17) Moreover, to evaluate the consistency of the segmentation results, we show the number of extracted objects compared to [7]. Table I shows the corresponding scores for the selected Fig. 16. Failure case of our method in a severely cluttered scene. As two objects are stacked together (the arrows), the region growing scheme groups them together, and consequently our method regards them as one object (dotted circles). scenes as well as the numbers of extracted objects. Note that [7] always obtains a higher number of extracted objects than the ground truth. This is because their method connects neighboring frames one-by-one based on optical flow, which leads to the loss of connection information when encountering occlusion. Consequently, their method mistakenly regards the reappeared part after occlusion as a new object, resulting in discontinuity and inconsistency. It is also worthy to notice that [7] obtains the same number of objects as the ground truth in Figure 16. However, it is just because it regards the reappeared part of the ball as a new object. Parameter analysis: η in Section IV is the interval of frame sampling. To evaluate its impact, we test our method by setting η to be 25, 50, 75, 100, and 125, respectively. We present the overall average error and time consumption over the whole sequence in Figure 17. The segmentation error is the ratio of mislabeled pixels to labeled pixels. Similar to [6], we regard all pixels covering their assigned region in ground truth as correctly labeled pixels, all others are counted as mislabeled pixels. The segmentation error of one video sequence is computed across the segmented objects in all the frames. It turns out that our method always gives better results with the narrowing of sampling interval, while the time consumption increases simultaneously. Figure 17 demonstrates that η is a tradeoff between segmentation quality and computation cost. In our experiment, we set η to be 75, as it generally produces satisfactory segmentation results with only a slight increase in runtime. As for the rest of free parameters, W in Section IV is set to [0.3, 0.5, ], and we set σ r and τ in Section V
12 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST Fig. 17. The segmentation error and time consumption of our method by varying the value of η. The average curve is computed from all the Figures considered in Table I and Table II. to and 0.3 respectively. The multiplier of multi-label energy term in Section VI is set to 0.5. Performance: We have implemented our algorithm in C++ and all experiments are performed on a PC with a 2.4 GHz CPU and 6.0 GB of RAM. Our method consists of three steps. In the first step, thanks to the mask propagation scheme, it is unnecessary to compute the graph-based segmentation for each frame but only the keyframes, which significantly decreases running time. The keyframe segmentation is efficient, because only simple computations are required on similarity measurement between pixels in a minor set of frames. In the second step, the numbers of object category (e.g., 6) and keyframes (e.g., 10) are both small, which leads to a small affinity matrix. Hence, our clustering scheme for grouping the same object candidates is quite fast. In the third step, the mask propagation is performed in bilateral space, which allows for a more efficient mapping from image plane to bilateral space than the super-pixels and k-means clustering approaches. The total time of the proposed algorithm is acceptable for RGB- D video processing. The experimental timings are given in Table II. Note that we omit the time of region clustering stage in the table since it is too small relative to the other two stages. Limitation: Currently, in order to obtain complete object candidates from segments, our method needs to group those object segments close to each other in 3D space. Therefore, segments from two objects may be grouped into one object candidate if they are connected. Consequently, our method may regard these two connected objects as one object, as illustrated in Figure 16. When the box stacks over the flashlight, the region growing scheme would group object segments of these two objects into one object candidate. By embedding an object detector into our system, we should be able to divide these two objects apart, which would be our future work. Meanwhile, the non-realtime performance, as shown in Table II, may hinder practical applications of our method, which is also a limitation. VIII. CONCLUSIONS AND FUTURE WORK In this paper, we have presented an effective framework for segmenting and tracking objects in RGB-D video under occlusion without any user input cue. By introducing a clustering strategy on object candidates in the keyframes, our segmentation method is able to produce the consistent segmentation mask in the keyframes. Based on the mask propagation scheme in bilateral space, our method can propagate the consistent segmentation mask through the whole RGB-D video, which ensures the continuity. A variety of experiments and quantitative analysis have demonstrated that our method can generally produce consistent and continuous segmentation results on RGB-D video, even in the presence of complete occlusion between objects or the missing of a whole object in the scene. In future, we would integrate the learning based object recognition into our system to achieve the semantic segmentation and solve the limitation mentioned above. Moreover, improving the efficiency of the proposed method would be another area for future work. REFERENCES [1] D. Maier, A. Hornung, and M. Bennewitz, Real-time navigation in 3d environments based on depth camera data, in th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), pp [2] Y. Jiang, S. Moseson, and A. Saxena, Efficient grasping from rgbd images: Learning using a new rectangle representation, in Robotics and Automation (ICRA), 2011 IEEE International Conference on, pp [3] A. Fossati, J. Gall, H. Grabner, X. Ren, and K. Konolige, Consumer depth cameras for computer vision: research topics and applications. Springer, [4] S. Kwak, M. Cho, I. Laptev, J. Ponce, and C. Schmid, Unsupervised object discovery and tracking in video collections, in The IEEE International Conference on Computer Vision (ICCV), December [5] M. Grundmann, V. Kwatra, M. Han, and I. Essa, Efficient hierarchical graph-based video segmentation, in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. [6] M. Ghafarianzadeh, M. Blaschko, and G. Sibley, Efficient, dense, object-based segmentation from rgbd video, in International Conference on Robotics and Automation (ICRA), [7] S. Hickson, S. Birchfield, I. Essa, and H. Christensen, Efficient hierarchical graph-based segmentation of rgbd videos, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [8] W. Wang, J. Shen, X. Li, and F. Porikli, Robust video object cosegmentation, IEEE Transactions on Image Processing, vol. 24, no. 10, pp , [9] M. Rubinstein, C. Liu, and W. T. Freeman, Joint inference in weaklyannotated image datasets via dense correspondence, International Journal of Computer Vision, vol. 119, no. 1, pp , [10] A. Khoreva, F. Galasso, M. Hein, and B. Schiele, Classifier based graph construction for video segmentation, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp [11] T. Wang, Z. Ji, Q. Sun, Q. Chen, and X.-Y. Jing, Interactive multilabel image segmentation via robust multilayer graph constraints, IEEE Transactions on Multimedia, vol. 18, no. 12, pp , [12] F. Galasso, M. Keuper, T. Brox, and B. Schiele, Spectral graph reduction for efficient image and streaming video segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp [13] D. Zhang, O. Javed, and M. Shah, Video object segmentation through spatially accurate and temporally dense extraction of primary object regions, in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June [14] N. Shankar Nagaraja, F. R. Schmidt, and T. Brox, Video segmentation with just a few strokes, in The IEEE International Conference on Computer Vision (ICCV), December [15] C. Wang, Y. Guo, J. Zhu, L. Wang, and W. Wang, Video object co-segmentation via subspace clustering and quadratic pseudo-boolean optimization in an mrf framework, IEEE Transactions on Multimedia, vol. 16, no. 4, pp , [16] H. Huang, H. Jiang, C. Brenner, and H. Mayer, Object-level segmentation of rgbd data, ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. 2, no. 3, p. 73, [17] F. Husain, B. Dellen, and C. Torras, Consistent depth video segmentation using adaptive surface models, 2015 IEEE transactions on cybernetics, vol. 45, no. 2, pp [18] D. Sun, E. B. Sudderth, and H. Pfister, Layered rgbd scene flow estimation, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp
![JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 [19] P. Koutlemanis, X. Zabulis, A. Ntelidakis, and A. A. Argyros, Foreground detection with a moving rgbd camera, in International Symposium on Visual Computing.](/docs-images/81/84437996/images/13-0.jpg "Springer, 2013, pp. 216 227. [20] M. Camplani and L.")

![[22] H. Jiang, G. Zhang, H. Wang, and H. Bao, Spatio-temporal video segmentation of static scenes and its applications, 2015 IEEE Transactions on Multimedia, vol. 17, no. 1, pp. 3 15. [23] A.](/docs-images/81/84437996/images/13-2.jpg "Teichman, J. T. Lussier, and S. Thrun, Learning to segment and track in rgbd, 2013 IEEE Transactions on Automation Science and Engineering. [24] J. Chen, S. Paris, and F.")
![Durand, Real-time edge-aware image processing with the bilateral grid, ACM Transactions on Graphics (TOG), vol. 26, no. 3, p. 103, 2007. [25] N. Maerki, F. Perazzi, O. Wang, and A.](/docs-images/81/84437996/images/13-3.jpg "Sorkine-Hornung, Bilateral space video segmentation, in The IEEE Conference on Computer Vision and Pa")
![ttern Recognition (CVPR), 2016. [26] P. F. Felzenszwalb and D. P. Huttenlocher, Efficient graph-based image segmentation, International Journal of Computer Vision, vol. 59, no. 2, pp. 167 181, 2004.](/docs-images/81/84437996/images/13-4.jpg "[27] C. Liu, Beyond pixels: exploring new representations and applications for motion analysis, Ph.D. dissertation, Citeseer, 2009. [28] M. A. Reza and J.")
, vol. 2, no. 1, pp. 20 43, 2006. [30] B. J.")
13 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 [19] P. Koutlemanis, X. Zabulis, A. Ntelidakis, and A. A. Argyros, Foreground detection with a moving rgbd camera, in International Symposium on Visual Computing. Springer, 2013, pp [20] M. Camplani and L. Salgado, Background foreground segmentation with rgb-d kinect data: An efficient combination of classifiers, Journal of Visual Communication and Image Representation, vol. 25, no. 1, pp , [21] D. Weikersdorfer, A. Schick, and D. Cremers, Depth-adaptive supervoxels for rgb-d video segmentation, in 2013 IEEE International Conference on Image Processing, pp [22] H. Jiang, G. Zhang, H. Wang, and H. Bao, Spatio-temporal video segmentation of static scenes and its applications, 2015 IEEE Transactions on Multimedia, vol. 17, no. 1, pp [23] A. Teichman, J. T. Lussier, and S. Thrun, Learning to segment and track in rgbd, 2013 IEEE Transactions on Automation Science and Engineering. [24] J. Chen, S. Paris, and F. Durand, Real-time edge-aware image processing with the bilateral grid, ACM Transactions on Graphics (TOG), vol. 26, no. 3, p. 103, [25] N. Maerki, F. Perazzi, O. Wang, and A. Sorkine-Hornung, Bilateral space video segmentation, in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [26] P. F. Felzenszwalb and D. P. Huttenlocher, Efficient graph-based image segmentation, International Journal of Computer Vision, vol. 59, no. 2, pp , [27] C. Liu, Beyond pixels: exploring new representations and applications for motion analysis, Ph.D. dissertation, Citeseer, [28] M. A. Reza and J. Kosecka, Object recognition and segmentation in indoor scenes from rgb-d images, in Robotics Science and Systems (RSS) conference-5th workshop on RGB-D: Advanced Reasoning with Depth Cameras, [29] A. D. Bimbo and P. Pala, Content-based retrieval of 3d models, ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 2, no. 1, pp , [30] B. J. Frey and D. Dueck, Clustering by passing messages between data points, science, vol. 315, no. 5814, pp , [31] Y. Boykov, O. Veksler, and R. Zabih, Fast approximate energy minimization via graph cuts, 2001 IEEE Transactions on pattern analysis and machine intelligence. [32] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, A benchmark for the evaluation of rgb-d slam systems, in Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ International Conference on. IEEE, 2012, pp [33] P. K. Nathan Silberman, Derek Hoiem and R. Fergus, Indoor segmentation and support inference from rgbd images, in ECCV, [34] T. Hodan, P. Haluza, S. Obdrz a lek, J. Matas, M. Lourakis, and X. Zabulis, T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects, IEEE Winter Conference on Applications of Computer Vision (WACV), [35] A. Uckermann, R. Haschke, and H. Ritter, Real-time 3d segmentation of cluttered scenes for robot grasping, pp , Qian Xie is currently working towards the Ph.D. degree at Nanjing University of Aeronautics and Astronautics (NUAA), China. He received his Bachelor degree in Computer-Aided Design from NUAA in His research interests include computer graphics, robotics and machine learning. 13 Oussama Remil is currently working towards the Ph.D. degree in co-supervision between Ecole Militaire polytechnique (EMP, Algeria) and Nanjing University of Aeronautics and Astronautics (NUAA, China). He received his Bachelor degree in mechanical engineering from the Laboratory of Mechanical Structures LMS (EMP, Algeria) in His research spans the area of data-driven techniques for geometry processing and analysis, geometric modeling, reverse engineering, and computer graphics in general. Yanwen Guo received the Ph.D. degree in applied mathematics from the State Key Lab of CAD&CG, Zhejiang University, China, in He is currently a Full Professor with the National Key Laboratory for Novel Software Technology, Department of Computer Science and Technology, Nanjing University, Jiangsu, China. His research interests include image and video processing, vision, and computer graphics. Mingqiang Wei received his Ph.D degree (2014) in Computer Science and Engineering from The Chinese University of Hong Kong (CUHK). He is an associate professor at Nanjing University of Aeronautics and Astronautics (NUAA)s School of Computer Science and Technology. Before joining NUAA, he served as an assistant professor at Hefei University of Technology, and a postdoctoral fellow at CUHK. His research interest is computer graphics with an emphasis on smart geometry processing. Meng Wang is a professor at the Hefei University of Technology, China. He received his B.E. degree and Ph.D. degree in the Special Class for the Gifted Young and the Department of Electronic Engineering and Information Science from the University of Science and Technology of China (USTC), Hefei, China, in 2003 and 2008, respectively. His current research interests include multimedia content analysis, computer vision, and pattern recognition. He has authored more than 200 book chapters, journal and conference papers in these areas. He is the recipient of the ACM SIGMM Rising Star Award He is an associate editor of IEEE Transactions on Knowledge and Data Engineering (IEEE TKDE), IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT), and IEEE Transactions on Neural Networks and Learning Systems (IEEE TNNLS). Jun Wang is currently a professor at Nanjing University of Aeronautics and Astronautics (NUAA), China. He received his Bachelor and PhD degrees in Computer-Aided Design from NUAA in 2002 and 2007 respectively. From 2008 to 2010, he conducted research as a postdoctoral scholar at the University of California and the University of Wisconsin. From 2010 to 2013, he worked as a senior research engineer at Leica Geosystems, USA. In 2013, he paid an academic visit to the Department of Mathematics at Harvard University. His research interests include geometry processing and geometric modeling.
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Mobile Human Detection Systems based on Sliding Windows Approach-A Review
 Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Robotics Programming Laboratory
 Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Robot localization method based on visual features and their geometric relationship
 , pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
, pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS 664 Segmentation. Daniel Huttenlocher
 CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation
 ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Chapter 3 Image Registration. Chapter 3 Image Registration
 Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Automatic Colorization of Grayscale Images
 Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
A Semi-Automatic 2D-to-3D Video Conversion with Adaptive Key-Frame Selection
 A Semi-Automatic 2D-to-3D Video Conversion with Adaptive Key-Frame Selection Kuanyu Ju and Hongkai Xiong Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai, China ABSTRACT To
A Semi-Automatic 2D-to-3D Video Conversion with Adaptive Key-Frame Selection Kuanyu Ju and Hongkai Xiong Department of Electronic Engineering, Shanghai Jiao Tong University, Shanghai, China ABSTRACT To
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at 14th International Conference of the Biometrics Special Interest Group, BIOSIG, Darmstadt, Germany, 9-11 September,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at 14th International Conference of the Biometrics Special Interest Group, BIOSIG, Darmstadt, Germany, 9-11 September,
Motion Tracking and Event Understanding in Video Sequences
 Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Supervised texture detection in images
 Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
MULTIVIEW REPRESENTATION OF 3D OBJECTS OF A SCENE USING VIDEO SEQUENCES
 MULTIVIEW REPRESENTATION OF 3D OBJECTS OF A SCENE USING VIDEO SEQUENCES Mehran Yazdi and André Zaccarin CVSL, Dept. of Electrical and Computer Engineering, Laval University Ste-Foy, Québec GK 7P4, Canada
MULTIVIEW REPRESENTATION OF 3D OBJECTS OF A SCENE USING VIDEO SEQUENCES Mehran Yazdi and André Zaccarin CVSL, Dept. of Electrical and Computer Engineering, Laval University Ste-Foy, Québec GK 7P4, Canada
Selection of Scale-Invariant Parts for Object Class Recognition
 Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Using temporal seeding to constrain the disparity search range in stereo matching
 Using temporal seeding to constrain the disparity search range in stereo matching Thulani Ndhlovu Mobile Intelligent Autonomous Systems CSIR South Africa Email: tndhlovu@csir.co.za Fred Nicolls Department
Using temporal seeding to constrain the disparity search range in stereo matching Thulani Ndhlovu Mobile Intelligent Autonomous Systems CSIR South Africa Email: tndhlovu@csir.co.za Fred Nicolls Department
CS 534: Computer Vision Segmentation and Perceptual Grouping
 CS 534: Computer Vision Segmentation and Perceptual Grouping Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Outlines Mid-level vision What is segmentation Perceptual Grouping Segmentation
CS 534: Computer Vision Segmentation and Perceptual Grouping Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Outlines Mid-level vision What is segmentation Perceptual Grouping Segmentation
Translation Symmetry Detection: A Repetitive Pattern Analysis Approach
 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops Translation Symmetry Detection: A Repetitive Pattern Analysis Approach Yunliang Cai and George Baciu GAMA Lab, Department of Computing
2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops Translation Symmetry Detection: A Repetitive Pattern Analysis Approach Yunliang Cai and George Baciu GAMA Lab, Department of Computing
Motion Estimation and Optical Flow Tracking
 Image Matching Image Retrieval Object Recognition Motion Estimation and Optical Flow Tracking Example: Mosiacing (Panorama) M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 Example 3D Reconstruction
Image Matching Image Retrieval Object Recognition Motion Estimation and Optical Flow Tracking Example: Mosiacing (Panorama) M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 Example 3D Reconstruction
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Enhanced Hemisphere Concept for Color Pixel Classification
 2016 International Conference on Multimedia Systems and Signal Processing Enhanced Hemisphere Concept for Color Pixel Classification Van Ng Graduate School of Information Sciences Tohoku University Sendai,
2016 International Conference on Multimedia Systems and Signal Processing Enhanced Hemisphere Concept for Color Pixel Classification Van Ng Graduate School of Information Sciences Tohoku University Sendai,
Texture Sensitive Image Inpainting after Object Morphing
 Texture Sensitive Image Inpainting after Object Morphing Yin Chieh Liu and Yi-Leh Wu Department of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taiwan
Texture Sensitive Image Inpainting after Object Morphing Yin Chieh Liu and Yi-Leh Wu Department of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taiwan
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
Improving Image Segmentation Quality Via Graph Theory
 International Symposium on Computers & Informatics (ISCI 05) Improving Image Segmentation Quality Via Graph Theory Xiangxiang Li, Songhao Zhu School of Automatic, Nanjing University of Post and Telecommunications,
International Symposium on Computers & Informatics (ISCI 05) Improving Image Segmentation Quality Via Graph Theory Xiangxiang Li, Songhao Zhu School of Automatic, Nanjing University of Post and Telecommunications,
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Short Survey on Static Hand Gesture Recognition
 Short Survey on Static Hand Gesture Recognition Huu-Hung Huynh University of Science and Technology The University of Danang, Vietnam Duc-Hoang Vo University of Science and Technology The University of
Short Survey on Static Hand Gesture Recognition Huu-Hung Huynh University of Science and Technology The University of Danang, Vietnam Duc-Hoang Vo University of Science and Technology The University of
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology
 Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
An Approach for Reduction of Rain Streaks from a Single Image
 An Approach for Reduction of Rain Streaks from a Single Image Vijayakumar Majjagi 1, Netravati U M 2 1 4 th Semester, M. Tech, Digital Electronics, Department of Electronics and Communication G M Institute
An Approach for Reduction of Rain Streaks from a Single Image Vijayakumar Majjagi 1, Netravati U M 2 1 4 th Semester, M. Tech, Digital Electronics, Department of Electronics and Communication G M Institute
Local Feature Detectors
 Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
Use of Shape Deformation to Seamlessly Stitch Historical Document Images
 Use of Shape Deformation to Seamlessly Stitch Historical Document Images Wei Liu Wei Fan Li Chen Jun Sun Satoshi Naoi In China, efforts are being made to preserve historical documents in the form of digital
Use of Shape Deformation to Seamlessly Stitch Historical Document Images Wei Liu Wei Fan Li Chen Jun Sun Satoshi Naoi In China, efforts are being made to preserve historical documents in the form of digital
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry
 cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry Steven Scher December 2, 2004 Steven Scher SteveScher@alumni.princeton.edu Abstract Three-dimensional
cse 252c Fall 2004 Project Report: A Model of Perpendicular Texture for Determining Surface Geometry Steven Scher December 2, 2004 Steven Scher SteveScher@alumni.princeton.edu Abstract Three-dimensional
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images
 Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Analysis of Image and Video Using Color, Texture and Shape Features for Object Identification
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VI (Nov Dec. 2014), PP 29-33 Analysis of Image and Video Using Color, Texture and Shape Features
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VI (Nov Dec. 2014), PP 29-33 Analysis of Image and Video Using Color, Texture and Shape Features
Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial Region Segmentation
 IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.11, November 2013 1 Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial
IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.11, November 2013 1 Moving Object Segmentation Method Based on Motion Information Classification by X-means and Spatial
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field
 07 5th European Signal Processing Conference (EUSIPCO) 3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Josep R.Casas Montse Pardás Abstract Traditional image segmentation
07 5th European Signal Processing Conference (EUSIPCO) 3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Josep R.Casas Montse Pardás Abstract Traditional image segmentation
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS
 SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION
 MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION Panca Mudjirahardjo, Rahmadwati, Nanang Sulistiyanto and R. Arief Setyawan Department of Electrical Engineering, Faculty of
MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION Panca Mudjirahardjo, Rahmadwati, Nanang Sulistiyanto and R. Arief Setyawan Department of Electrical Engineering, Faculty of
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey
 Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field
 3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Image Processing Group Technical University of Catalonia (UPC) Barcelona, Spain Josep R.Casas Image Processing Group
3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Image Processing Group Technical University of Catalonia (UPC) Barcelona, Spain Josep R.Casas Image Processing Group
MOVING OBJECT DETECTION USING BACKGROUND SUBTRACTION ALGORITHM USING SIMULINK
 MOVING OBJECT DETECTION USING BACKGROUND SUBTRACTION ALGORITHM USING SIMULINK Mahamuni P. D 1, R. P. Patil 2, H.S. Thakar 3 1 PG Student, E & TC Department, SKNCOE, Vadgaon Bk, Pune, India 2 Asst. Professor,
MOVING OBJECT DETECTION USING BACKGROUND SUBTRACTION ALGORITHM USING SIMULINK Mahamuni P. D 1, R. P. Patil 2, H.S. Thakar 3 1 PG Student, E & TC Department, SKNCOE, Vadgaon Bk, Pune, India 2 Asst. Professor,
Color Local Texture Features Based Face Recognition
 Color Local Texture Features Based Face Recognition Priyanka V. Bankar Department of Electronics and Communication Engineering SKN Sinhgad College of Engineering, Korti, Pandharpur, Maharashtra, India
Color Local Texture Features Based Face Recognition Priyanka V. Bankar Department of Electronics and Communication Engineering SKN Sinhgad College of Engineering, Korti, Pandharpur, Maharashtra, India
Object Extraction Using Image Segmentation and Adaptive Constraint Propagation
 Object Extraction Using Image Segmentation and Adaptive Constraint Propagation 1 Rajeshwary Patel, 2 Swarndeep Saket 1 Student, 2 Assistant Professor 1 2 Department of Computer Engineering, 1 2 L. J. Institutes
Object Extraction Using Image Segmentation and Adaptive Constraint Propagation 1 Rajeshwary Patel, 2 Swarndeep Saket 1 Student, 2 Assistant Professor 1 2 Department of Computer Engineering, 1 2 L. J. Institutes
Image Segmentation for Image Object Extraction
 Image Segmentation for Image Object Extraction Rohit Kamble, Keshav Kaul # Computer Department, Vishwakarma Institute of Information Technology, Pune kamble.rohit@hotmail.com, kaul.keshav@gmail.com ABSTRACT
Image Segmentation for Image Object Extraction Rohit Kamble, Keshav Kaul # Computer Department, Vishwakarma Institute of Information Technology, Pune kamble.rohit@hotmail.com, kaul.keshav@gmail.com ABSTRACT
Multiple-Choice Questionnaire Group C
 Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
A Feature Point Matching Based Approach for Video Objects Segmentation
 A Feature Point Matching Based Approach for Video Objects Segmentation Yan Zhang, Zhong Zhou, Wei Wu State Key Laboratory of Virtual Reality Technology and Systems, Beijing, P.R. China School of Computer
A Feature Point Matching Based Approach for Video Objects Segmentation Yan Zhang, Zhong Zhou, Wei Wu State Key Laboratory of Virtual Reality Technology and Systems, Beijing, P.R. China School of Computer
Color Image Segmentation
 Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
Equation to LaTeX. Abhinav Rastogi, Sevy Harris. I. Introduction. Segmentation.
 Equation to LaTeX Abhinav Rastogi, Sevy Harris {arastogi,sharris5}@stanford.edu I. Introduction Copying equations from a pdf file to a LaTeX document can be time consuming because there is no easy way
Equation to LaTeX Abhinav Rastogi, Sevy Harris {arastogi,sharris5}@stanford.edu I. Introduction Copying equations from a pdf file to a LaTeX document can be time consuming because there is no easy way
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Object detection using non-redundant local Binary Patterns
 University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
CS 223B Computer Vision Problem Set 3
 CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
Exploiting Depth Camera for 3D Spatial Relationship Interpretation
 Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
Model-based segmentation and recognition from range data
 Model-based segmentation and recognition from range data Jan Boehm Institute for Photogrammetry Universität Stuttgart Germany Keywords: range image, segmentation, object recognition, CAD ABSTRACT This
Model-based segmentation and recognition from range data Jan Boehm Institute for Photogrammetry Universität Stuttgart Germany Keywords: range image, segmentation, object recognition, CAD ABSTRACT This
Human Motion Detection and Tracking for Video Surveillance
 Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Image Resizing Based on Gradient Vector Flow Analysis
 Image Resizing Based on Gradient Vector Flow Analysis Sebastiano Battiato battiato@dmi.unict.it Giovanni Puglisi puglisi@dmi.unict.it Giovanni Maria Farinella gfarinellao@dmi.unict.it Daniele Ravì rav@dmi.unict.it
Image Resizing Based on Gradient Vector Flow Analysis Sebastiano Battiato battiato@dmi.unict.it Giovanni Puglisi puglisi@dmi.unict.it Giovanni Maria Farinella gfarinellao@dmi.unict.it Daniele Ravì rav@dmi.unict.it
Prof. Fanny Ficuciello Robotics for Bioengineering Visual Servoing
 Visual servoing vision allows a robotic system to obtain geometrical and qualitative information on the surrounding environment high level control motion planning (look-and-move visual grasping) low level
Visual servoing vision allows a robotic system to obtain geometrical and qualitative information on the surrounding environment high level control motion planning (look-and-move visual grasping) low level
C. Premsai 1, Prof. A. Kavya 2 School of Computer Science, School of Computer Science Engineering, Engineering VIT Chennai, VIT Chennai
 Traffic Sign Detection Via Graph-Based Ranking and Segmentation Algorithm C. Premsai 1, Prof. A. Kavya 2 School of Computer Science, School of Computer Science Engineering, Engineering VIT Chennai, VIT
Traffic Sign Detection Via Graph-Based Ranking and Segmentation Algorithm C. Premsai 1, Prof. A. Kavya 2 School of Computer Science, School of Computer Science Engineering, Engineering VIT Chennai, VIT
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
3D object recognition used by team robotto
 3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Efficient Acquisition of Human Existence Priors from Motion Trajectories
 Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
Automatic Shadow Removal by Illuminance in HSV Color Space
 Computer Science and Information Technology 3(3): 70-75, 2015 DOI: 10.13189/csit.2015.030303 http://www.hrpub.org Automatic Shadow Removal by Illuminance in HSV Color Space Wenbo Huang 1, KyoungYeon Kim
Computer Science and Information Technology 3(3): 70-75, 2015 DOI: 10.13189/csit.2015.030303 http://www.hrpub.org Automatic Shadow Removal by Illuminance in HSV Color Space Wenbo Huang 1, KyoungYeon Kim
Graph-Based Superpixel Labeling for Enhancement of Online Video Segmentation
 Graph-Based Superpixel Labeling for Enhancement of Online Video Segmentation Alaa E. Abdel-Hakim Electrical Engineering Department Assiut University Assiut, Egypt alaa.aly@eng.au.edu.eg Mostafa Izz Cairo
Graph-Based Superpixel Labeling for Enhancement of Online Video Segmentation Alaa E. Abdel-Hakim Electrical Engineering Department Assiut University Assiut, Egypt alaa.aly@eng.au.edu.eg Mostafa Izz Cairo
Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization
 Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization Kosuke Fukano, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra, Akihiro Sugimoto, and Hiroshi Ishikawa Waseda
Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization Kosuke Fukano, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra, Akihiro Sugimoto, and Hiroshi Ishikawa Waseda
CS4495/6495 Introduction to Computer Vision
 CS4495/6495 Introduction to Computer Vision 9C-L1 3D perception Some slides by Kelsey Hawkins Motivation Why do animals, people & robots need vision? To detect and recognize objects/landmarks Is that a
CS4495/6495 Introduction to Computer Vision 9C-L1 3D perception Some slides by Kelsey Hawkins Motivation Why do animals, people & robots need vision? To detect and recognize objects/landmarks Is that a
Image Segmentation Using Iterated Graph Cuts Based on Multi-scale Smoothing
 Image Segmentation Using Iterated Graph Cuts Based on Multi-scale Smoothing Tomoyuki Nagahashi 1, Hironobu Fujiyoshi 1, and Takeo Kanade 2 1 Dept. of Computer Science, Chubu University. Matsumoto 1200,
Image Segmentation Using Iterated Graph Cuts Based on Multi-scale Smoothing Tomoyuki Nagahashi 1, Hironobu Fujiyoshi 1, and Takeo Kanade 2 1 Dept. of Computer Science, Chubu University. Matsumoto 1200,
Scene Text Detection Using Machine Learning Classifiers
 601 Scene Text Detection Using Machine Learning Classifiers Nafla C.N. 1, Sneha K. 2, Divya K.P. 3 1 (Department of CSE, RCET, Akkikkvu, Thrissur) 2 (Department of CSE, RCET, Akkikkvu, Thrissur) 3 (Department
601 Scene Text Detection Using Machine Learning Classifiers Nafla C.N. 1, Sneha K. 2, Divya K.P. 3 1 (Department of CSE, RCET, Akkikkvu, Thrissur) 2 (Department of CSE, RCET, Akkikkvu, Thrissur) 3 (Department
Motion Estimation. There are three main types (or applications) of motion estimation:
 of motion estimation:") Members: D91922016 朱威達 R93922010 林聖凱 R93922044 謝俊瑋 Motion Estimation There are three main types (or applications) of motion estimation: Parametric motion (image alignment) The main idea of parametric motion
Members: D91922016 朱威達 R93922010 林聖凱 R93922044 謝俊瑋 Motion Estimation There are three main types (or applications) of motion estimation: Parametric motion (image alignment) The main idea of parametric motion
WP1: Video Data Analysis
 Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos
 Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos Sung Chun Lee, Chang Huang, and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA sungchun@usc.edu,
Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos Sung Chun Lee, Chang Huang, and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA sungchun@usc.edu,
A Keypoint Descriptor Inspired by Retinal Computation
 A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Medical images, segmentation and analysis
 Medical images, segmentation and analysis ImageLab group http://imagelab.ing.unimo.it Università degli Studi di Modena e Reggio Emilia Medical Images Macroscopic Dermoscopic ELM enhance the features of
Medical images, segmentation and analysis ImageLab group http://imagelab.ing.unimo.it Università degli Studi di Modena e Reggio Emilia Medical Images Macroscopic Dermoscopic ELM enhance the features of
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Saliency Detection for Videos Using 3D FFT Local Spectra
 Saliency Detection for Videos Using 3D FFT Local Spectra Zhiling Long and Ghassan AlRegib School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, GA 30332, USA ABSTRACT
Saliency Detection for Videos Using 3D FFT Local Spectra Zhiling Long and Ghassan AlRegib School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, GA 30332, USA ABSTRACT
CS 231A Computer Vision (Fall 2012) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation
 A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
CS 4758: Automated Semantic Mapping of Environment
 CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
Texture Segmentation by Windowed Projection
 Texture Segmentation by Windowed Projection 1, 2 Fan-Chen Tseng, 2 Ching-Chi Hsu, 2 Chiou-Shann Fuh 1 Department of Electronic Engineering National I-Lan Institute of Technology e-mail : fctseng@ccmail.ilantech.edu.tw
Texture Segmentation by Windowed Projection 1, 2 Fan-Chen Tseng, 2 Ching-Chi Hsu, 2 Chiou-Shann Fuh 1 Department of Electronic Engineering National I-Lan Institute of Technology e-mail : fctseng@ccmail.ilantech.edu.tw
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Detecting motion by means of 2D and 3D information
 Detecting motion by means of 2D and 3D information Federico Tombari Stefano Mattoccia Luigi Di Stefano Fabio Tonelli Department of Electronics Computer Science and Systems (DEIS) Viale Risorgimento 2,
Detecting motion by means of 2D and 3D information Federico Tombari Stefano Mattoccia Luigi Di Stefano Fabio Tonelli Department of Electronics Computer Science and Systems (DEIS) Viale Risorgimento 2,
Layered Scene Decomposition via the Occlusion-CRF Supplementary material
 Layered Scene Decomposition via the Occlusion-CRF Supplementary material Chen Liu 1 Pushmeet Kohli 2 Yasutaka Furukawa 1 1 Washington University in St. Louis 2 Microsoft Research Redmond 1. Additional
Layered Scene Decomposition via the Occlusion-CRF Supplementary material Chen Liu 1 Pushmeet Kohli 2 Yasutaka Furukawa 1 1 Washington University in St. Louis 2 Microsoft Research Redmond 1. Additional
Figure 1: Workflow of object-based classification
 Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task
 QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk
Introduction to Medical Imaging (5XSA0) Module 5
 Module 5") Introduction to Medical Imaging (5XSA0) Module 5 Segmentation Jungong Han, Dirk Farin, Sveta Zinger ( s.zinger@tue.nl ) 1 Outline Introduction Color Segmentation region-growing region-merging watershed
Introduction to Medical Imaging (5XSA0) Module 5 Segmentation Jungong Han, Dirk Farin, Sveta Zinger ( s.zinger@tue.nl ) 1 Outline Introduction Color Segmentation region-growing region-merging watershed