Two-Stream Neural Networks for Tampered Face Detection
|
|
|
- Annis Poole
- 5 years ago
- Views:
Transcription


1 Two-Stream Neural Networks for Tampered Face Detection Peng Zhou Xintong Han Vlad I. Morariu Larry S. Davis University of Maryland, College Park Abstract We propose a two-stream network for face tampering detection. We train GoogLeNet to detect tampering artifacts in a face classification stream, and train a patch based triplet network to leverage features capturing local noise residuals and camera characteristics as a second stream. In addition, we use two different online face swapping applications to create a new dataset that consists of 2010 tampered images, each of which contains a tampered face. We evaluate the proposed two-stream network on our newly collected dataset. Experimental results demonstrate the effectiveness of our method. (a) (b) 1. Introduction People post photos every day on popular social websites such as Facebook, Instagram and Twitter. A considerable number of these photos are authentic as they are generated from people s real life and shared as a part of their social experience. However, maliciously or not, more and more tampered images, especially ones involving face regions, are emerging on the Internet. Image splicing, which is the most common tampering manipulation, is the process of cutting one part of a source image, such as the face regions, and inserting it in the target image. To make the tampered result more realistic, adjustments on the shape, boundary, illumination and scaling are necessary, which make tamper detection challenging. Given advances in face detection and recognition techniques, anyone is able to swap faces with low cost using mobile applications [2] or open-source software [1]. Some tampered image examples generated from commercial software are shown in Figure 1. Even after close inspection, people mistake the tampered faces as original. The consequence would be even more serious if manipulated images are used for political or commercial purposes. Even though image tampering detection has been an active research area during the last decade, limitations still The first two authors contribute equally to this work. (c) Figure 1. Examples of tampered faces. (a) original image. (b) Tampered image. The face in the middle has been tampered. (c) Original image. (d) Tampered image. The face on the right has been tampered. exist for current approaches since they focus on a particular source of tampering evidence [20, 14, 4, 11]. For example, local noise analysis fails to deal with tampered images constructed using careful post processing and Color Filter Array (CFA) models cannot deal with resized images. To avoid focusing on specific tampering evidence and achieve robust tampering detection, we propose a twostream network architecture to capture both tampering artifact evidence and local noise residual evidence as shown in Figure 2. This is inspired by recent research on CNNs showing the potential to learn tampering evidence [3, 21, 7] and rich models [15, 9, 10, 16], which are models of the noise components that produce informative features for steganalysis and we call the features produced by these models steganalysis features in the rest of this paper, showing good performance on tampering detection. One of our (d) 1

2 Face Classification Stream Steganalysis feature extractor Patch Triplet Stream Triplet Loss SVM Two stream Fusion Figure 2. Illustration of our two-stream network. The face classification stream models visual appearance by classifying a face is tampered or not. The patch triplet stream is trained on steganalysis features to ensure patches from the same image are close in the embedding space, and an SVM trained on the learned features classifies each patch. Finally, the scores of two streams are fused to recognize a tampered face. streams is a CNN based face classification stream and the other one is a steganalysis feature based triplet stream. The face classification stream, based on GoogLeNet [23], is trained on tampered and authentic images and serves as a tampered face classifier. The patch triplet stream, based on patch level steganalysis features [15, 16], captures lowlevel camera characteristics like CFA pattern and local noise residuals. Instead of utilizing steganalysis features directly, we train a triplet network after extracting steganalysis features to allow the model to refine steganalysis features. Combining the two streams reveals both evidence of highlevel tampering artifacts and low-level noise residual features, and yields very good performance for face tamper detection. To train and evaluate our approach, we created a new face tampering dataset. The new dataset overcomes the drawback of existing datasets [19, 13, 12, 11] that are either small or in which the tampering is easily distinguishable even through visual inspection. We chose two face swapping apps to create two parallel sets of tampered images where the same target face is swapped with the same source face, but using different swapping algorithms. Only tampered images of good quality were retained. There are 1005 tampered images for each tampering technique (2010 tampered images in total) and 1400 authentic images for each subset. Evaluation on this dataset shows the effectiveness of our approach. Our contribution is two-fold. First, by incorporating GoogLeNet and the triplet network as a two-stream network architecture, our method learns both tampering artifacts and local noise residual features. In addition, we create a new challenging dataset specific to face region tampering detection. 2. Related Work There is growing research activity on tampering detection and localization. Prior methods can be classified according to the image features that they target, such as local noise estimation [20], double JPEG localization [4], CFA pattern analysis [14], illumination model [11] and steganalysis feature classification [8]. Recently, some methods based on Convolutional Neural Networks (CNN) [3, 7, 21] have achieved very good results. The premise behind local noise estimation based techniques is that the difference between global noise characteristics and local noise characteristics reveals the hidden tampered regions. For example, Lyu et al. [18] cast noise statistic estimation as a closed-form optimization problem. By exploiting the property of kurtosis of natural images in band-pass domains and the relationship between noise characteristics and kurtosis, they reveal the inconsistency between global noise and local noise. However, the assumption that local noise is inconsistent with global noise fails if post processing techniques like filtering or image blending are applied after splicing. In contrast, our method is built on a triplet network to learn local noise residuals. This provides more reliable features for detection. Double JPEG localization techniques can be classified into aligned double JPEG compression and non-aligned double JPEG compression, depending on whether or not the quantization factors align well after two applications of JPEG compression to the same image. The assumption is that the background regions undergo double JPEG compression while the tampered regions do not. For example,
![Bianchi et al. [4] presented a probability model that estimates DCT coefficients together with quantization factors.](/docs-images/87/95278061/images/3-0.jpg "The advantage of this method is that it can be used for both aligned double JPEG and non-aligned double JPEG. However, this kind of technique strongly depends on the double JPEG assumption.")

3 Bianchi et al. [4] presented a probability model that estimates DCT coefficients together with quantization factors. The advantage of this method is that it can be used for both aligned double JPEG and non-aligned double JPEG. However, this kind of technique strongly depends on the double JPEG assumption. CFA localization based methods assume that the CFA pattern differs between tampered regions and authentic regions, due to the use of different imaging devices or other low-level artifacts introduced by the tampering process. By estimating the CFA pattern for the tampered image, it is possible to distinguish the tampered regions and authentic regions from each other. For example, Ferrara et al. [14] proposed an algorithm that estimates the camera filter pattern based on the fact that the variance of prediction error between CFA present regions (authentic regions) and CFA absent regions (tampered regions) is different. After a Gaussian Mixture Model (GMM) classification, the tampered regions can be localized. However, the assumption might not hold true if the tampered region has similar CFA pattern or the whole image is resized (whole resizing destroys the original camera CFA information and introduces new noise). Even though our method is also built on a CFA aware steganalysis features, we have a second stream that provides additional evidence in such scenarios. Illumination based methods aim to detect illumination inconsistencies between tampered regions and authentic regions. For example, the tampered face and another face in the background may have different light source directions. Carvalho et al. [5] were able to estimate the light source direction for objects in an image, and thus use the light inconsistency to locate the tampered regions. De et al. [11] extracted the illumination features from image and use a Support Vector Machine (SVM) classifier for tampering classification. For face tamper detection, the performance can degrade as some applications only modify a small region of the tampered face, leaving the global illumination features of the face relatively unaltered. Steganalysis feature [15] based methods extract diverse low-level information like local noise residuals. The steganalysis feature is a local descriptor based on cooccurrence statistics of nearby pixel noise residuals obtained from multiple linear and non-linear filters. Cozzolino et al. [8] used simplified steganalysis features and built a single Gaussian model to identify tampered regions. An improved method is [10], which treated tamper detection as anomaly detection and used a discriminative learning autoencoder outlier removing method based on steganalysis features. These methods show that steganalysis features are quite useful as lowlevel features which can be used in tamper detection. Goljan et al. [16] showed that this steganalysis model can also be utilized to estimate and extract CFA features, which extends their application. The difference between CFA aware Positive Anchor Negative Learning Positive Anchor Negative Figure 3. Illustration of weakly-supervised triplet network. By minimizing the triplet loss, the distance between patches from the same image (anchor and positive patches in the left image) in the learned embedding space becomes smaller than distance between two patches from different images (anchor patch in the left image and negative patch in the right image). Two boxes and circles of the same color represent a patch and its corresponding embedding, respectively. steganalysis features and our approach is that we fine tune these features to improve their detection performance. Recently, methods based on CNNs have been developed. For example, by adding an additional median filter layer before the first convolutional layer, Chen et al. [7] achieved good performance in median filtering tampering. Bayar et al. [3] designed an adaptive filter kernel layer to estimate the filter kernel used in the tampering process, detecting various filtering tampered contents. However, the performance degrades significantly when multiple post processing techniques are applied to tampered regions. Rao et al. [21] combined a CNN with steganalysis features by initializing the kernel of the first convolution layer with steganalysis filter kernels. 3. Approach Figure 2 shows our two stream framework. The face classification stream is a CNN trained to classify whether a face image is tampered or authentic. Thus, it learns the artifacts created by the tampering process. The patch triplet stream, which is trained on steganalysis features [16] of image patches with a triplet loss, models the traces left by incamera processing and local noise characteristics Face Classification Stream Since face tampering often creates artifacts (strong edges near lips, blurred areas on forehead, etc.), the visual information present in the tampered face plays an important role in tampered face detection. We adapt a deep convolutional neural network [23] trained for large-scale image recogni-
4 tion task, and fine-tune it to classify if a face is tampered or not. Given a face q i, we denote the tampering score of this CNN as F (q i ) Patch Triplet Stream In addition to modeling the visual appearance of tampered faces, we also leverage informative clues hidden in the in-camera processing for accurate tampered face detection. Recent research has shown that co-occurrence based local features (e.g., steganalysis features [16]) can capture this hidden information and are effective in image splicing detection [10, 8]. In contrast to previous works that directly use these features, we refine the steganalysis features by a data-driven approach based on a triplet loss [22]. By training this triplet network, we ensure that a pair of patches from the same image are closer in the learned embedding space, while the distance between a pair of patches from two different images is large, as shown in Figure 3. Formally, given an image patch x a (anchor patch), a patch x p (positive patch) from the same image, and x n (negative patch) from a different image, we enforce that the distance between x a and x p is smaller than that between x a and x n by some margin m: d(f(r(x a )), f(r(x p ))) + m < d(f(r(x a )), f(r(x n ))) (1) where r(x) is the steganalysis features of patch x, f(r(x)) is the embedding of x we want to learn, and d() is the sum of squares distance measure. We model f by a two layer fully connected neural network. This constraint is then converted into minimizing the following loss function: L(f) = a,p,n max(0, m + d(f a, f p ) d(f a, f n )) (2) where we use f a to denote f(r(x a )) for simplicity. Instead of generating hard negatives in an online fashion [22], we randomly sample patch triplets from authentic images. Each triplet contains three patches (one anchor, one positive, and one negative patch). We do not use hard negative sampling because our method is weakly supervised - for an anchor patch, its negative patches might be from the images taken from the same camera, thus have the same camera characteristics. During hard negative mining, these pseudo negatives will be treated as true hard negatives and the model will eventually project all patches into the same point in the embedding space in order to minimize L. The triplet network is designed to determine whether or not two patches come from the same image. Face tampering detection works in a similar way. All the patches in an authentic region are from the same image and have small distances between each other in triplet embedding space, while the patches in tampered face regions have large distance from those authentic patches in the triplet embedding space because they are from another image. For each tampered image, the tampered regions have different characteristics from the authentic regions. Therefore, we treat the tampered and authentic regions in each image as two different classes and train a classifier for each image to predict the tampered regions. We choose SVM as our classifier and train it for each test face on-thefly. This process is shown in Figure 4. The SVM samples are obtained by extracting the triplet features on each patch through sliding windows. We treat the features extracted from non-face-region patches as negative samples because they are from the same image. To balance the negative samples, we randomly select the features extracted from other image patches as positive samples. Only the features from the automatically detected face regions in an image are treated as test samples. (e.g., the left face of the test image in Figure 4). If a face region has been tampered, then the extracted features should have similar characteristics with positive samples; otherwise they should be similar to negative samples. For a patch x, the prediction of this SVM model S(x) indicates the probability that x is from another image, and thus is equivalent to the probability of tampering. As a face might contain multiple patches, we then take the average score for the patches in the face region as the final score for the face Two-stream Score Fusion At test time, the final score for a face q is obtained by simply combining the output scores of the two streams: F (q) + λ 1 S(x) (3) N q x q where N q is the number of patches inside face q. λ is a balance factor that ensures the two scores are at similar scale. 4. Experiments In this section, we introduce our newly collected SwapMe and FaceSwap dataset, and then evaluate our method on it. Furthermore, we visualize the detection results of our method to better understand the proposed twostream network. Finally, different training and test protocols are discussed SwapMe and FaceSwap Dataset Even though datasets for image tampering detection exist [19, 12, 13, 11], they are not well suited for large scale face tamper detection. Columbia Image Splicing dataset [19] and CASIA [12, 13] are large but most of the tampered


![DSI-1 dataset [11] focuses on face tampering but the total number of tampered images is only 25. Moreover, it is difficult to train deep learning methods on these datasets for face tamper detection.](/docs-images/87/95278061/images/5-2.jpg "To this end, we created a dataset utilizing one ios app called SwapMe [2] and an open-source face swap application called FaceSwap [1].")



5 Test Positive Negative SVM Test image Triplet learned embedding space Randomly selected images Figure 4. Demonstration of SVM training process. Suppose we want to test on the left face in the test image in a sliding window fashion. Green boxes are the test face patches; red boxes are randomly selected patches from other images and used as positive samples; blue boxes are the negative samples indicating patches from the same image. After SVM prediction, green boxes are more likely to be the ones from other images and thus the left face in the test image is classified to be a tampered face. regions are not human faces. DSI-1 dataset [11] focuses on face tampering but the total number of tampered images is only 25. Moreover, it is difficult to train deep learning methods on these datasets for face tamper detection. To this end, we created a dataset utilizing one ios app called SwapMe [2] and an open-source face swap application called FaceSwap [1]. Given a source face and a target face, they automatically replace the target face with the source face. Then, post processing such as boundary blurring, resizing and blending is applied to the tampered face, which makes it very difficult to visually distinguish the tampered from authentic images. Some examples created by SwapMe and FaceSwap are shown in Figure 5. We selected 1005 target-source face pairs, and generated 1005 images with one tampered face in each image for each of the two applications. We further split these 1005 images into 705 for training and 300 for testing. The 705 training images together with another 1400 authentic images form the training set. The 300 test images are combined with 300 authentic images as the test set. For each test image, two faces are sampled for testing (one tampered and one authentic for a tampered image, and two authentic faces for an authentic image). Thus, in total, for each application, we have 705 tampered faces and 1400 authentic faces for training, and 900 authentic faces and 300 tampered faces for testing. Note that the selected images cover diverse events (e.g., holidays, sports, conferences) and identities of different ages, genders and races. When needed, the face bounding boxes are generated using Dlib [17] face detection. Our dataset has the following advantages: 1) It is a large dataset focus on face regions and is specifically designed for (a) (c) Figure 5. Examples of tampered images using SwapMe and FaceSwap. (a) Source image. The red bounding box shows the face moved to the tampered images. (b) Target image. The red bounding box shows the face before tampering. (c) Tampered image using SwapMe. (d) Tampered image using FaceSwap. face tamper detection. 2) The quality of tampering is very good and the tampered faces look realistic. Generally, only face regions like the mouth, skin or eyes are tampered. 3) Since we use two different tampering techniques, we avoid learning the artifacts of one swapping algorithm, which may not be predictive when testing on the other. (b) (d)
6 True Positive Rate ROC curve on SwapMe test set IDC [4] (0.543) CFA pattern [14] (0.618) Steganalysis features [16] + SVM (0.794) Face classification stream (0.854) Patch triplet stream (0.875) Two-stream network (0.928) False Positive Rate Figure 6. Face-level ROC comparison between our two-stream network and other methods Experiment Setup Training and Test Protocol. In order to avoid learning application-specific features, we train our model on one dataset and test on the other dataset. We train on FaceSwap training subset and test on SwapMe test subset. This is because tampering quality of FaceSwap is not as good as SwapMe. We do this for two reasons. On one hand, it might take attackers considerable effort to improve the tampered image in order to confuse the viewer. On the other hand, tamper detection algorithms typically will not know the specific technique attackers used to tamper images. We use the 705 FaceSwap tampered images and 1400 authentic images for training, and 300 SwapMe tampered images together with 300 authentic images for testing. The face-level tampering detection ROC curve and corresponding AUC are used for evaluation. Face Classification Stream. We use GoogLeNet Inception V3 model [23] for training the tampered face classifier. Faces are resized to and provided as input to the CNN. We set the initial learning rate to 0.1 and decrease it by a factor of 2 every 8 epochs. The batch size is set to 32. Finally we fine-tune all layers of the CNN pre-trained on ImageNet and stop the training process after 16k steps. Patch Triplet Stream. Each triplet contains patches, and 5514D steganalysis features [16] are extracted for each patch. We randomly sample such triplets from authentic training images, of which are used for training and 3000 for validation. The triplet network contains two fully connected layers, the first layer contains 1024 neurons and the second one contains 512 neurons. The output of this network is then L2 normalized. During training, the initial learning rate is set to 0.1 and decreased by 2 Methods AUC IDC [4] CFA pattern [14] Steganalysis features [16] + SVM Face classification stream Patch triplet stream Two-stream network (Ours) Table 1. AUC of face-level ROC for different methods. every 8 epochs. The margin m in Eqn. 1 is fixed to During testing, we extract image patches in a sliding window fashion (window size = 128, stride = 64). The 512D learned representation is extracted for each patch then used for training a linear SVM using liblinear [6] with C = 100. Finally, we apply the trained SVM on face patches, and the average score of face patches is used as the face-level score Comparison with other methods We compare our method with prior work on the SwapMe test set. The code for prior work is either provided by the authors or obtained from publicly available implementations on GitHub 1 [24]. The details of the methods and baselines are as follows. Face classification stream. Only the output of the face classification CNN is used as the face tampering detection score. Patch triplet stream. Only the patch triplet stream is used for detection of tampered faces. Steganalysis features [16] + SVM. We train a linear SVM model directly on the features extracted from the steganalysis model [16]. This method is equivalent to removing the triplet network from our patch triplet stream. CFA pattern [14]. This method estimates the CFA pattern and uses a GMM algorithm to classify the variance of prediction error using the estimated CFA pattern. The output of this method is a local level tampering probability map. For the face region, an average probability is calculated as the final score. Improved DCT Coefficient (IDC) [4]. This method estimates the DCT coefficients for all the regions in the given image to find the singly JPEG compressed regions and classifies them as tampered regions. The output of this method is a probability map indicating tampering. To calculate the ROC curve, we take an average of the heat map score in the face region. Figure 6 and Table 1 show the results on the SwapMe test set. CFA pattern [14] does not achieve good performance. Because images in the SwapMe dataset have been resized and the nearby pixel information is lost, this method fails to make correct predictions. The assumption of IDC [4] is that tampered regions are singly JPEG compressed while 1














![method used in [25] to generate Class Activation Maps (CAMs)](/docs-images/87/95278061/images/7-14.jpg "from the GoogLeNet, which are shown in Figure 7.")






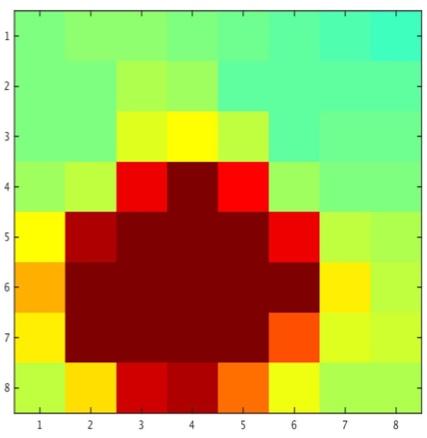






7 89 Original Tampered CAM Overlay CAM Original Tampered CAM SVM score map Figure 7. Class Activation Maps (CAMs) obtained from the face classification network. Each row shows the original image, the corresponding tampered face, the CAM, and a smoothing CAM overlaid with the tampered face for better visualization. In CAMs, red denotes high probability of tampering, and blue denotes low probability of tampering. We can observe that our face classification stream learns important artifacts created by the application during face tampering, such as stitching artifacts near face boundaries, strong edges around lips, and blurring effect when glasses are involved. the authentic regions are doubly JPEG compressed. This is not the case in SwapMe, as both tampered regions and authentic regions have been doubly JPEG compressed. Steganalysis features + SVM performs reasonably well. By refining steganalysis features, our patch triplet stream generates more informative features and obtains better result than steganalysis features + SVM (AUC improved from to 0.875). By combining the patch triplet stream with the face classification stream, our full method models both high-level visual artifacts and low-level local features and thus is robust to post processing like resizing and boundary smoothing. As a result, it outperforms all other methods by a large margin Discussion Class Activation Map of Tampered Faces. To better understand what visual clues the face classification stream relies on to detect a tampered face, we follow the method used in [25] to generate Class Activation Maps (CAMs) from the GoogLeNet, which are shown in Figure 7. Since the last feature map before the global average pooling layer Figure 8. Heat map visualization of our two-stream network. Each row contains the original and tampered face, the corresponding CAM generated in the face classification stream in and SVM score map derived from the SVMs in the patch triplet stream. the In CAMs, red denotes high probability of tampering, and blue denotes low probability of tampering. In SVM score maps, red regions are more likely to be from different images other than the tampered images. In the first example, both streams can detect the tampered face. In the second and third examples, one stream fails while the other stream works, and fusing two streams successfully detects the tampered faces. Last row shows a failure case when the input face is small. in GoogLeNet is of size , the CAM for each face is of size 8 8. As shown in Figure 7, it is clear that our method learns the tampering artifacts created by the applications. The network is able to detect the stitching artifacts near the boundary of faces (as in the first two examples), strong edges near lips (as in the third example), and some blurring effect near eyes when glasses are involved during the tampering (last example). This visualization indicates that our approach is able to learn reasonable features that are useful for tampering detection. Effectiveness of Two-stream Fusion. By fusing the detection scores of two streams, our method achieves better performance than each individual stream by a large margin. In Figure 8, we show some examples to visualize the detection results of both streams. In the first example, both streams can detect the tampered face - the face classification stream detects the unnatural edges near the mouth and beard, and the patch triplet network discovers the different noise residual distributions of the tampered region. In
8 SwapMe test FaceSwap test SwapMe train FaceSwap train SwapMe + FaceSwap train Table 2. AUC of face classification stream comparison using different training and test splits. The row is the training dataset and the column is the test dataset. the second and third examples, only one stream is able to detect the tampering; however, with our two-stream fusion scheme, combining two streams detects the tampered face effectively. Our method fails to detect very small tampered faces as shown in the last example in Figure 8. In this example, the face is only of size Since our face classification stream needs to resize the input face to , the upsampling of small faces loses some crucial visual information for tampering detection. Moreover, the patch size of our patch triplet stream is , which makes our method less robust when the tampered face is small because a large portion of the input patch will be authentic regions. Tampered Face Detection in Different Protocols. In addition to training on FaceSwap and testing on SwapMe, we report the results of different protocols in Table 2. The row is the training dataset and the column is the test dataset. We use 705 tampered authentic images for training and 300 tampered authentic images for test when both training and testing are from the same dataset. We use images for training and 300 tampered authentic images for test when training on both SwapMe and FaceSwap and testing on one of them. The near perfect performance on either SwapMe or FaceSwap test set when training on common datasets indicates that our face classification stream has learned application-specific features. 5. Conclusion We described a two-stream tampered face detection technique, where one stream detects low-level inconsistencies between image patches and another stream explicitly detects tamper faces. To evaluate our approach, we created a new data set that is challenging as multiple post processing are applied to the spliced region. The experimental results show that our approach outperforms other methods because it is able to learn both tampering artifacts and hidden noise residual features. Since our method needs steganalysis features extraction for the triplet network, an end-to-end architecture design is worth investigating and will be one of the main directions for future research. References [1] Faceswap. MarekKowalski/FaceSwap/. 1, 5 [2] Swapme. swapme-by-faciometrics/. * This company has been acquired by Facebook and no longer available in App- Store. 1, 5 [3] B. Bayar and M. C. Stamm. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, pages ACM, , 2, 3 [4] T. Bianchi, A. De Rosa, and A. Piva. Improved dct coefficient analysis for forgery localization in jpeg images. In Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on, pages IEEE, , 2, 3, 6 [5] T. Carvalho, H. Farid, and E. Kee. Exposing photo manipulation from user-guided 3d lighting analysis. In SPIE/IS&T Electronic Imaging, pages International Society for Optics and Photonics, [6] C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2:27:1 27:27, Software available at cjlin/libsvm. 6 [7] J. Chen, X. Kang, Y. Liu, and Z. J. Wang. Median filtering forensics based on convolutional neural networks. IEEE Signal Processing Letters, 22(11): , , 2, 3 [8] D. Cozzolino, D. Gragnaniello, and L. Verdoliva. Image forgery localization through the fusion of camera-based, feature-based and pixel-based techniques. In Image Processing (ICIP), 2014 IEEE International Conference on, pages IEEE, , 3, 4 [9] D. Cozzolino, G. Poggi, and L. Verdoliva. Splicebuster: A new blind image splicing detector. In Information Forensics and Security (WIFS), 2015 IEEE International Workshop on, pages 1 6. IEEE, [10] D. Cozzolino and L. Verdoliva. Single-image splicing localization through autoencoder-based anomaly detection. In Information Forensics and Security (WIFS), 2016 IEEE International Workshop on, pages 1 6. IEEE, , 3, 4 [11] T. J. De Carvalho, C. Riess, E. Angelopoulou, H. Pedrini, and A. de Rezende Rocha. Exposing digital image forgeries by illumination color classification. ieee transactions on information forensics and security, 8(7): , , 2, 3, 4, 5 [12] J. Dong, W. Wang, and T. Tan. Casia image tampering detection evaluation database In 2, 4 [13] J. Dong, W. Wang, and T. Tan. Casia image tampering detection evaluation database. In Signal and Information Processing (ChinaSIP), 2013 IEEE China Summit & International Conference on, pages IEEE, , 4 [14] P. Ferrara, T. Bianchi, A. De Rosa, and A. Piva. Image forgery localization via fine-grained analysis of cfa artifacts. IEEE Transactions on Information Forensics and Security, 7(5): , , 2, 3, 6 [15] J. Fridrich and J. Kodovsky. Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 7(3): , , 2, 3
9 [16] M. Goljan and J. Fridrich. Cfa-aware features for steganalysis of color images. In SPIE/IS&T Electronic Imaging, pages 94090V 94090V. International Society for Optics and Photonics, , 2, 3, 4, 6 [17] D. E. King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research, 10: , [18] S. Lyu, X. Pan, and X. Zhang. Exposing region splicing forgeries with blind local noise estimation. International journal of computer vision, 110(2): , [19] T.-T. Ng, J. Hsu, and S.-F. Chang. Columbia image splicing detection evaluation dataset, , 4 [20] X. Pan, X. Zhang, and S. Lyu. Exposing image splicing with inconsistent local noise variances. In Computational Photography (ICCP), 2012 IEEE International Conference on, pages IEEE, , 2 [21] Y. Rao and J. Ni. A deep learning approach to detection of splicing and copy-move forgeries in images. In Information Forensics and Security (WIFS), 2016 IEEE International Workshop on, pages 1 6. IEEE, , 2, 3 [22] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [23] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , , 3, 6 [24] M. Zampoglou, S. Papadopoulos, and Y. Kompatsiaris. Detecting image splicing in the wild (web). In Multimedia & Expo Workshops (ICMEW), 2015 IEEE International Conference on, pages 1 6. IEEE, [25] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages ,
Detecting malicious tampering in digital images
 Detecting malicious tampering in digital images Markos Zampoglou - markzampoglou@iti.gr Information Technologies Institute (ITI) Centre for Research and Technology Hellas (CERTH) Workshop on Tools for
Detecting malicious tampering in digital images Markos Zampoglou - markzampoglou@iti.gr Information Technologies Institute (ITI) Centre for Research and Technology Hellas (CERTH) Workshop on Tools for
A Generic Approach Towards Image Manipulation Parameter Estimation Using Convolutional Neural Networks
 A Generic Approach Towards Image Manipulation Parameter Estimation Using Convolutional Neural Networks ABSTRACT Belhassen Bayar Drexel University Dept. of Electrical & Computer Engineering Philadelphia,
A Generic Approach Towards Image Manipulation Parameter Estimation Using Convolutional Neural Networks ABSTRACT Belhassen Bayar Drexel University Dept. of Electrical & Computer Engineering Philadelphia,
DYADIC WAVELETS AND DCT BASED BLIND COPY-MOVE IMAGE FORGERY DETECTION
 DYADIC WAVELETS AND DCT BASED BLIND COPY-MOVE IMAGE FORGERY DETECTION Ghulam Muhammad*,1, Muhammad Hussain 2, Anwar M. Mirza 1, and George Bebis 3 1 Department of Computer Engineering, 2 Department of
DYADIC WAVELETS AND DCT BASED BLIND COPY-MOVE IMAGE FORGERY DETECTION Ghulam Muhammad*,1, Muhammad Hussain 2, Anwar M. Mirza 1, and George Bebis 3 1 Department of Computer Engineering, 2 Department of
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Deliverable D6.3 Release of publicly available datasets and software tools
 Grant Agreement No. 268478 Deliverable D6.3 Release of publicly available datasets and software tools Lead partner for this deliverable: PoliMI Version: 1.0 Dissemination level: Public April 29, 2013 Contents
Grant Agreement No. 268478 Deliverable D6.3 Release of publicly available datasets and software tools Lead partner for this deliverable: PoliMI Version: 1.0 Dissemination level: Public April 29, 2013 Contents
The Watchful Forensic Analyst: Multi-Clue Information Fusion with Background Knowledge
 WIFS 13 The Watchful Forensic Analyst: Multi-Clue Information Fusion with Background Knowledge Marco Fontani #, Enrique Argones-Rúa*, Carmela Troncoso*, Mauro Barni # # University of Siena (IT) * GRADIANT:
WIFS 13 The Watchful Forensic Analyst: Multi-Clue Information Fusion with Background Knowledge Marco Fontani #, Enrique Argones-Rúa*, Carmela Troncoso*, Mauro Barni # # University of Siena (IT) * GRADIANT:
Improved LBP and K-Nearest Neighbors Algorithm
 Image-Splicing Forgery Detection Based On Improved LBP and K-Nearest Neighbors Algorithm Fahime Hakimi, Department of Electrical and Computer engineering. Zanjan branch, Islamic Azad University. Zanjan,
Image-Splicing Forgery Detection Based On Improved LBP and K-Nearest Neighbors Algorithm Fahime Hakimi, Department of Electrical and Computer engineering. Zanjan branch, Islamic Azad University. Zanjan,
Detecting Digital Image Forgeries By Multi-illuminant Estimators
 Research Paper Volume 2 Issue 8 April 2015 International Journal of Informative & Futuristic Research ISSN (Online): 2347-1697 Detecting Digital Image Forgeries By Multi-illuminant Estimators Paper ID
Research Paper Volume 2 Issue 8 April 2015 International Journal of Informative & Futuristic Research ISSN (Online): 2347-1697 Detecting Digital Image Forgeries By Multi-illuminant Estimators Paper ID
Deep Face Recognition. Nathan Sun
 Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Towards Order of Processing Operations Detection in JPEGcompressed Images with Convolutional Neural Networks
 https://doi.org/10.2352/issn.2470-1173.2018.07.mwsf-211 2018, Society for Imaging Science and Technology Towards Order of Processing Operations Detection in JPEGcompressed Images with Convolutional Neural
https://doi.org/10.2352/issn.2470-1173.2018.07.mwsf-211 2018, Society for Imaging Science and Technology Towards Order of Processing Operations Detection in JPEGcompressed Images with Convolutional Neural
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Research Article A Novel Steganalytic Algorithm based on III Level DWT with Energy as Feature
 Research Journal of Applied Sciences, Engineering and Technology 7(19): 4100-4105, 2014 DOI:10.19026/rjaset.7.773 ISSN: 2040-7459; e-issn: 2040-7467 2014 Maxwell Scientific Publication Corp. Submitted:
Research Journal of Applied Sciences, Engineering and Technology 7(19): 4100-4105, 2014 DOI:10.19026/rjaset.7.773 ISSN: 2040-7459; e-issn: 2040-7467 2014 Maxwell Scientific Publication Corp. Submitted:
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Digital Image Forgery Detection Based on GLCM and HOG Features
 Digital Image Forgery Detection Based on GLCM and HOG Features Liya Baby 1, Ann Jose 2 Department of Electronics and Communication, Ilahia College of Engineering and Technology, Muvattupuzha, Ernakulam,
Digital Image Forgery Detection Based on GLCM and HOG Features Liya Baby 1, Ann Jose 2 Department of Electronics and Communication, Ilahia College of Engineering and Technology, Muvattupuzha, Ernakulam,
(JBE Vol. 23, No. 6, November 2018) Detection of Frame Deletion Using Convolutional Neural Network. Abstract
 Detection of Frame Deletion Using Convolutional Neural Network. Abstract") (JBE Vol. 23, No. 6, November 2018) (Regular Paper) 23 6, 2018 11 (JBE Vol. 23, No. 6, November 2018) https://doi.org/10.5909/jbe.2018.23.6.886 ISSN 2287-9137 (Online) ISSN 1226-7953 (Print) CNN a), a),
(JBE Vol. 23, No. 6, November 2018) (Regular Paper) 23 6, 2018 11 (JBE Vol. 23, No. 6, November 2018) https://doi.org/10.5909/jbe.2018.23.6.886 ISSN 2287-9137 (Online) ISSN 1226-7953 (Print) CNN a), a),
Video Inter-frame Forgery Identification Based on Optical Flow Consistency
 Sensors & Transducers 24 by IFSA Publishing, S. L. http://www.sensorsportal.com Video Inter-frame Forgery Identification Based on Optical Flow Consistency Qi Wang, Zhaohong Li, Zhenzhen Zhang, Qinglong
Sensors & Transducers 24 by IFSA Publishing, S. L. http://www.sensorsportal.com Video Inter-frame Forgery Identification Based on Optical Flow Consistency Qi Wang, Zhaohong Li, Zhenzhen Zhang, Qinglong
SHADOW REMOVAL DETECTION AND LOCALIZATION FOR FORENSICS ANALYSIS
 SHADOW REMOVAL DETECTION AND LOCALIZATION FOR FORENSICS ANALYSIS S. K. Yarlagadda, D. Güera, D. M. Montserrat, F. M. Zhu, E. J. Delp Video and Image Processing Laboratory (VIPER), Purdue University P.
SHADOW REMOVAL DETECTION AND LOCALIZATION FOR FORENSICS ANALYSIS S. K. Yarlagadda, D. Güera, D. M. Montserrat, F. M. Zhu, E. J. Delp Video and Image Processing Laboratory (VIPER), Purdue University P.
Forensic analysis of JPEG image compression
 Forensic analysis of JPEG image compression Visual Information Privacy and Protection (VIPP Group) Course on Multimedia Security 2015/2016 Introduction Summary Introduction The JPEG (Joint Photographic
Forensic analysis of JPEG image compression Visual Information Privacy and Protection (VIPP Group) Course on Multimedia Security 2015/2016 Introduction Summary Introduction The JPEG (Joint Photographic
Politecnico di Torino. Porto Institutional Repository
 Politecnico di Torino Porto Institutional Repository [Proceeding] Detection and classification of double compressed MP3 audio tracks Original Citation: Tiziano Bianchi;Alessia De Rosa;Marco Fontani;Giovanni
Politecnico di Torino Porto Institutional Repository [Proceeding] Detection and classification of double compressed MP3 audio tracks Original Citation: Tiziano Bianchi;Alessia De Rosa;Marco Fontani;Giovanni
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Recognition of Animal Skin Texture Attributes in the Wild. Amey Dharwadker (aap2174) Kai Zhang (kz2213)
 Kai Zhang (kz2213)") Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
arxiv: v1 [cs.cv] 24 Nov 2018
![arxiv: v1 [cs.cv] 24 Nov 2018](/thumbs/90/104464263.jpg "arxiv: v1 [cs.cv] 24 Nov 2018") Generate, Segment and Replace: Towards Generic Manipulation Segmentation Peng Zhou 1 Bor-Chun Chen 1 Xintong Han 2 Mahyar Najibi 1 Larry S. Davis 1 1 University of Maryland, College Park 2 Malong Technologies
Generate, Segment and Replace: Towards Generic Manipulation Segmentation Peng Zhou 1 Bor-Chun Chen 1 Xintong Han 2 Mahyar Najibi 1 Larry S. Davis 1 1 University of Maryland, College Park 2 Malong Technologies
Stacked Denoising Autoencoders for Face Pose Normalization
 Stacked Denoising Autoencoders for Face Pose Normalization Yoonseop Kang 1, Kang-Tae Lee 2,JihyunEun 2, Sung Eun Park 2 and Seungjin Choi 1 1 Department of Computer Science and Engineering Pohang University
Stacked Denoising Autoencoders for Face Pose Normalization Yoonseop Kang 1, Kang-Tae Lee 2,JihyunEun 2, Sung Eun Park 2 and Seungjin Choi 1 1 Department of Computer Science and Engineering Pohang University
Using Machine Learning for Classification of Cancer Cells
 Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Fake Face Detection Methods: Can They Be Generalized?
 Fake Face Detection Methods: Can They Be Generalized? 1st Ali Khodabakhsh, 2nd Raghavendra Ramachandra, 3rd Kiran Raja, 4th Pankaj Wasnik, 5th Christoph Busch Department of Information Security and Communication
Fake Face Detection Methods: Can They Be Generalized? 1st Ali Khodabakhsh, 2nd Raghavendra Ramachandra, 3rd Kiran Raja, 4th Pankaj Wasnik, 5th Christoph Busch Department of Information Security and Communication
Face Recognition A Deep Learning Approach
 Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Evaluation of Image Forgery Detection Using Multi-scale Weber Local Descriptors
 Evaluation of Image Forgery Detection Using Multi-scale Weber Local Descriptors Sahar Q. Saleh 1, Muhammad Hussain 1, Ghulam Muhammad 1, and George Bebis 2 1 College of Computer and Information Sciences,
Evaluation of Image Forgery Detection Using Multi-scale Weber Local Descriptors Sahar Q. Saleh 1, Muhammad Hussain 1, Ghulam Muhammad 1, and George Bebis 2 1 College of Computer and Information Sciences,
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Tracing images back to their social network of origin: a CNN-based approach
 Tracing images back to their social network of origin: a CNN-based approach Irene Amerini, Tiberio Uricchio and Roberto Caldelli Media Integration and Communication Center (MICC), University of Florence,
Tracing images back to their social network of origin: a CNN-based approach Irene Amerini, Tiberio Uricchio and Roberto Caldelli Media Integration and Communication Center (MICC), University of Florence,
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Reverse engineering of double compressed images in the presence of contrast enhancement
 Reverse engineering of double compressed images in the presence of contrast enhancement P. Ferrara #, T. Bianchi, A. De Rosa, A. Piva # National Institute of Optics (INO), Firenze, Italy pasquale.ferrara@ino.it
Reverse engineering of double compressed images in the presence of contrast enhancement P. Ferrara #, T. Bianchi, A. De Rosa, A. Piva # National Institute of Optics (INO), Firenze, Italy pasquale.ferrara@ino.it
Robust Face Recognition Based on Convolutional Neural Network
 2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
Fishy Faces: Crafting Adversarial Images to Poison Face Authentication
 Fishy Faces: Crafting Adversarial Images to Poison Face Authentication Giuseppe Garofalo, Vera Rimmer, Tim Van hamme, Davy Preuveneers and Wouter Joosen WOOT 2018, August 13-14 (Baltimore, MD, USA) Face
Fishy Faces: Crafting Adversarial Images to Poison Face Authentication Giuseppe Garofalo, Vera Rimmer, Tim Van hamme, Davy Preuveneers and Wouter Joosen WOOT 2018, August 13-14 (Baltimore, MD, USA) Face
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS
 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Copy Move Forgery using Hu s Invariant Moments and Log-Polar Transformations
 Copy Move Forgery using Hu s Invariant Moments and Log-Polar Transformations Tejas K, Swathi C, Rajesh Kumar M, Senior member, IEEE School of Electronics Engineering Vellore Institute of Technology Vellore,
Copy Move Forgery using Hu s Invariant Moments and Log-Polar Transformations Tejas K, Swathi C, Rajesh Kumar M, Senior member, IEEE School of Electronics Engineering Vellore Institute of Technology Vellore,
Robust Steganography Using Texture Synthesis
 Robust Steganography Using Texture Synthesis Zhenxing Qian 1, Hang Zhou 2, Weiming Zhang 2, Xinpeng Zhang 1 1. School of Communication and Information Engineering, Shanghai University, Shanghai, 200444,
Robust Steganography Using Texture Synthesis Zhenxing Qian 1, Hang Zhou 2, Weiming Zhang 2, Xinpeng Zhang 1 1. School of Communication and Information Engineering, Shanghai University, Shanghai, 200444,
Gabor Filter HOG Based Copy Move Forgery Detection
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p-ISSN: 2278-8735 PP 41-45 www.iosrjournals.org Gabor Filter HOG Based Copy Move Forgery Detection Monisha Mohan
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p-ISSN: 2278-8735 PP 41-45 www.iosrjournals.org Gabor Filter HOG Based Copy Move Forgery Detection Monisha Mohan
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Multi-feature face liveness detection method combining motion information
 Volume 04 - Issue 11 November 2018 PP. 36-40 Multi-feature face liveness detection method combining motion information Changlin LI (School of Computer Science and Technology, University of Science and
Volume 04 - Issue 11 November 2018 PP. 36-40 Multi-feature face liveness detection method combining motion information Changlin LI (School of Computer Science and Technology, University of Science and
Smart Content Recognition from Images Using a Mixture of Convolutional Neural Networks *
 Smart Content Recognition from Images Using a Mixture of Convolutional Neural Networks * Tee Connie *, Mundher Al-Shabi *, and Michael Goh Faculty of Information Science and Technology, Multimedia University,
Smart Content Recognition from Images Using a Mixture of Convolutional Neural Networks * Tee Connie *, Mundher Al-Shabi *, and Michael Goh Faculty of Information Science and Technology, Multimedia University,
A Fast Personal Palm print Authentication based on 3D-Multi Wavelet Transformation
 A Fast Personal Palm print Authentication based on 3D-Multi Wavelet Transformation * A. H. M. Al-Helali, * W. A. Mahmmoud, and * H. A. Ali * Al- Isra Private University Email: adnan_hadi@yahoo.com Abstract:
A Fast Personal Palm print Authentication based on 3D-Multi Wavelet Transformation * A. H. M. Al-Helali, * W. A. Mahmmoud, and * H. A. Ali * Al- Isra Private University Email: adnan_hadi@yahoo.com Abstract:
IMAGE and video editing has become increasingly easy
 IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. Y, MONTH YEAR 1 ACE - An Effective Anti-forensic Contrast Enhancement Technique Hareesh Ravi, Member, IEEE, A V Subramanyam, Member, IEEE, and Sabu Emmanuel,
IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. Y, MONTH YEAR 1 ACE - An Effective Anti-forensic Contrast Enhancement Technique Hareesh Ravi, Member, IEEE, A V Subramanyam, Member, IEEE, and Sabu Emmanuel,
LEARNED FORENSIC SOURCE SIMILARITY FOR UNKNOWN CAMERA MODELS. Owen Mayer, Matthew C. Stamm
 LEARNED FORENSIC SOURCE SIMILARITY FOR UNKNOWN CAMERA MODELS Owen Mayer, Matthew C. Stamm Drexel University Department of Electrical and Computer Engineering Philadelphia, Pennsylvania USA ABSTRACT Information
LEARNED FORENSIC SOURCE SIMILARITY FOR UNKNOWN CAMERA MODELS Owen Mayer, Matthew C. Stamm Drexel University Department of Electrical and Computer Engineering Philadelphia, Pennsylvania USA ABSTRACT Information
Face Recognition Using Vector Quantization Histogram and Support Vector Machine Classifier Rong-sheng LI, Fei-fei LEE *, Yan YAN and Qiu CHEN
 2016 International Conference on Artificial Intelligence: Techniques and Applications (AITA 2016) ISBN: 978-1-60595-389-2 Face Recognition Using Vector Quantization Histogram and Support Vector Machine
2016 International Conference on Artificial Intelligence: Techniques and Applications (AITA 2016) ISBN: 978-1-60595-389-2 Face Recognition Using Vector Quantization Histogram and Support Vector Machine
A Deep Learning Framework for Authorship Classification of Paintings
 A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach
 Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Detecting tampered videos with multimedia forensics and deep learning
 Detecting tampered videos with multimedia forensics and deep learning Markos Zampoglou 1, Foteini Markatopoulou 1, Gregoire Mercier 2, Despoina Touska 1, Evlampios Apostolidis 1,3, Symeon Papadopoulos
Detecting tampered videos with multimedia forensics and deep learning Markos Zampoglou 1, Foteini Markatopoulou 1, Gregoire Mercier 2, Despoina Touska 1, Evlampios Apostolidis 1,3, Symeon Papadopoulos
Copy-Move Forgery Detection using DCT and SIFT
 Copy-Move Forgery Detection using DCT and SIFT Amanpreet Kaur Department of Computer Science and Engineering, Lovely Professional University, Punjab, India. Richa Sharma Department of Computer Science
Copy-Move Forgery Detection using DCT and SIFT Amanpreet Kaur Department of Computer Science and Engineering, Lovely Professional University, Punjab, India. Richa Sharma Department of Computer Science
Digital Image Forgery detection using color Illumination and Decision Tree Classification
 RESEARCH ARTICLE OPEN ACCESS Digital Image Forgery detection using color Illumination and Decision Tree Classification Chitra Ganesan, V.R. Bhuma Chitra Ganesan, the author is currently pursuing M.E (Software
RESEARCH ARTICLE OPEN ACCESS Digital Image Forgery detection using color Illumination and Decision Tree Classification Chitra Ganesan, V.R. Bhuma Chitra Ganesan, the author is currently pursuing M.E (Software
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
FUSION MODEL BASED ON CONVOLUTIONAL NEURAL NETWORKS WITH TWO FEATURES FOR ACOUSTIC SCENE CLASSIFICATION
 Please contact the conference organizers at dcasechallenge@gmail.com if you require an accessible file, as the files provided by ConfTool Pro to reviewers are filtered to remove author information, and
Please contact the conference organizers at dcasechallenge@gmail.com if you require an accessible file, as the files provided by ConfTool Pro to reviewers are filtered to remove author information, and
IMAGE and video editing has become increasingly easy and
 IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. Y, MONTH YEAR 1 ACE - An Effective Anti-forensic Contrast Enhancement Technique Hareesh Ravi, Member, IEEE, A V Subramanyam, Member, IEEE, and Sabu Emmanuel,
IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. Y, MONTH YEAR 1 ACE - An Effective Anti-forensic Contrast Enhancement Technique Hareesh Ravi, Member, IEEE, A V Subramanyam, Member, IEEE, and Sabu Emmanuel,
FACE DETECTION AND RECOGNITION OF DRAWN CHARACTERS HERMAN CHAU
 FACE DETECTION AND RECOGNITION OF DRAWN CHARACTERS HERMAN CHAU 1. Introduction Face detection of human beings has garnered a lot of interest and research in recent years. There are quite a few relatively
FACE DETECTION AND RECOGNITION OF DRAWN CHARACTERS HERMAN CHAU 1. Introduction Face detection of human beings has garnered a lot of interest and research in recent years. There are quite a few relatively
Convolution Neural Networks for Chinese Handwriting Recognition
 Convolution Neural Networks for Chinese Handwriting Recognition Xu Chen Stanford University 450 Serra Mall, Stanford, CA 94305 xchen91@stanford.edu Abstract Convolutional neural networks have been proven
Convolution Neural Networks for Chinese Handwriting Recognition Xu Chen Stanford University 450 Serra Mall, Stanford, CA 94305 xchen91@stanford.edu Abstract Convolutional neural networks have been proven
A Forensic Tool for Investigating Image Forgeries
 A Forensic Tool for Investigating Image Forgeries Marco Fontani, University of Siena, Via Roma 56, 53100, Siena, Italy Tiziano Bianchi, Politecnico di Torino, Corso Duca degli Abruzzi 24, 10129, Torino,
A Forensic Tool for Investigating Image Forgeries Marco Fontani, University of Siena, Via Roma 56, 53100, Siena, Italy Tiziano Bianchi, Politecnico di Torino, Corso Duca degli Abruzzi 24, 10129, Torino,
Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations
 Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations Caglar Aytekin, Xingyang Ni, Francesco Cricri and Emre Aksu Nokia Technologies, Tampere, Finland Corresponding
Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations Caglar Aytekin, Xingyang Ni, Francesco Cricri and Emre Aksu Nokia Technologies, Tampere, Finland Corresponding
CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning
 CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning Justin Chen Stanford University justinkchen@stanford.edu Abstract This paper focuses on experimenting with
CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning Justin Chen Stanford University justinkchen@stanford.edu Abstract This paper focuses on experimenting with
Classifying Depositional Environments in Satellite Images
 Classifying Depositional Environments in Satellite Images Alex Miltenberger and Rayan Kanfar Department of Geophysics School of Earth, Energy, and Environmental Sciences Stanford University 1 Introduction
Classifying Depositional Environments in Satellite Images Alex Miltenberger and Rayan Kanfar Department of Geophysics School of Earth, Energy, and Environmental Sciences Stanford University 1 Introduction
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 24, NO. 3, MARCH
 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 24, NO. 3, MARCH 215 187 On Antiforensic Concealability With Rate-Distortion Tradeoff Xiaoyu Chu, Student Member, IEEE, Matthew Christopher Stamm, Member, IEEE,
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 24, NO. 3, MARCH 215 187 On Antiforensic Concealability With Rate-Distortion Tradeoff Xiaoyu Chu, Student Member, IEEE, Matthew Christopher Stamm, Member, IEEE,
Quantitative and Binary Steganalysis in JPEG: A Comparative Study
 Quantitative and Binary Steganalysis in JPEG: A Comparative Study Ahmad ZAKARIA LIRMM, Univ Montpellier, CNRS ahmad.zakaria@lirmm.fr Marc CHAUMONT LIRMM, Univ Nîmes, CNRS marc.chaumont@lirmm.fr Gérard
Quantitative and Binary Steganalysis in JPEG: A Comparative Study Ahmad ZAKARIA LIRMM, Univ Montpellier, CNRS ahmad.zakaria@lirmm.fr Marc CHAUMONT LIRMM, Univ Nîmes, CNRS marc.chaumont@lirmm.fr Gérard
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Storage Efficient NL-Means Burst Denoising for Programmable Cameras
 Storage Efficient NL-Means Burst Denoising for Programmable Cameras Brendan Duncan Stanford University brendand@stanford.edu Miroslav Kukla Stanford University mkukla@stanford.edu Abstract An effective
Storage Efficient NL-Means Burst Denoising for Programmable Cameras Brendan Duncan Stanford University brendand@stanford.edu Miroslav Kukla Stanford University mkukla@stanford.edu Abstract An effective
Louis Fourrier Fabien Gaie Thomas Rolf
 CS 229 Stay Alert! The Ford Challenge Louis Fourrier Fabien Gaie Thomas Rolf Louis Fourrier Fabien Gaie Thomas Rolf 1. Problem description a. Goal Our final project is a recent Kaggle competition submitted
CS 229 Stay Alert! The Ford Challenge Louis Fourrier Fabien Gaie Thomas Rolf Louis Fourrier Fabien Gaie Thomas Rolf 1. Problem description a. Goal Our final project is a recent Kaggle competition submitted
DescriptorEnsemble: An Unsupervised Approach to Image Matching and Alignment with Multiple Descriptors
 DescriptorEnsemble: An Unsupervised Approach to Image Matching and Alignment with Multiple Descriptors 林彥宇副研究員 Yen-Yu Lin, Associate Research Fellow 中央研究院資訊科技創新研究中心 Research Center for IT Innovation, Academia
DescriptorEnsemble: An Unsupervised Approach to Image Matching and Alignment with Multiple Descriptors 林彥宇副研究員 Yen-Yu Lin, Associate Research Fellow 中央研究院資訊科技創新研究中心 Research Center for IT Innovation, Academia
Boosting face recognition via neural Super-Resolution
 Boosting face recognition via neural Super-Resolution Guillaume Berger, Cle ment Peyrard and Moez Baccouche Orange Labs - 4 rue du Clos Courtel, 35510 Cesson-Se vigne - France Abstract. We propose a two-step
Boosting face recognition via neural Super-Resolution Guillaume Berger, Cle ment Peyrard and Moez Baccouche Orange Labs - 4 rue du Clos Courtel, 35510 Cesson-Se vigne - France Abstract. We propose a two-step
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging
 1 CS 9 Final Project Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging Feiyu Chen Department of Electrical Engineering ABSTRACT Subject motion is a significant
1 CS 9 Final Project Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging Feiyu Chen Department of Electrical Engineering ABSTRACT Subject motion is a significant
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Bagging for One-Class Learning
 Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
PEOPLE IN SEATS COUNTING VIA SEAT DETECTION FOR MEETING SURVEILLANCE
 PEOPLE IN SEATS COUNTING VIA SEAT DETECTION FOR MEETING SURVEILLANCE Hongyu Liang, Jinchen Wu, and Kaiqi Huang National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Science
PEOPLE IN SEATS COUNTING VIA SEAT DETECTION FOR MEETING SURVEILLANCE Hongyu Liang, Jinchen Wu, and Kaiqi Huang National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Science
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Exploring DCT Coefficient Quantization Effect for Image Tampering Localization
 Exploring DCT Coefficient Quantization Effect for Image Tampering Localization Wei Wang, Jing Dong, Tieniu Tan National Laboratory of attern Recognition, Institute of Automation.O. Box 2728, Beijing,.R.
Exploring DCT Coefficient Quantization Effect for Image Tampering Localization Wei Wang, Jing Dong, Tieniu Tan National Laboratory of attern Recognition, Institute of Automation.O. Box 2728, Beijing,.R.
EXPOSING THE DOUBLE COMPRESSION IN MP3 AUDIO BY FREQUENCY VIBRATION. Tianzhuo Wang, Xiangwei Kong, Yanqing Guo, Bo Wang
 EXPOSIG THE DOUBLE COMPRESSIO I MP3 AUDIO BY FREQUECY VIBRATIO Tianzhuo Wang, Xiangwei Kong, Yanqing Guo, Bo Wang School of Information and Communication Engineering Dalian University of Technology, Dalian,
EXPOSIG THE DOUBLE COMPRESSIO I MP3 AUDIO BY FREQUECY VIBRATIO Tianzhuo Wang, Xiangwei Kong, Yanqing Guo, Bo Wang School of Information and Communication Engineering Dalian University of Technology, Dalian,
Rich feature hierarchies for accurate object detection and semant
 Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
2028 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 26, NO. 4, APRIL 2017
 2028 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 26, NO. 4, APRIL 2017 Weakly Supervised PatchNets: Describing and Aggregating Local Patches for Scene Recognition Zhe Wang, Limin Wang, Yali Wang, Bowen
2028 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 26, NO. 4, APRIL 2017 Weakly Supervised PatchNets: Describing and Aggregating Local Patches for Scene Recognition Zhe Wang, Limin Wang, Yali Wang, Bowen
Handwritten Chinese Character Recognition by Joint Classification and Similarity Ranking
 2016 15th International Conference on Frontiers in Handwriting Recognition Handwritten Chinese Character Recognition by Joint Classification and Similarity Ranking Cheng Cheng, Xu-Yao Zhang, Xiao-Hu Shao
2016 15th International Conference on Frontiers in Handwriting Recognition Handwritten Chinese Character Recognition by Joint Classification and Similarity Ranking Cheng Cheng, Xu-Yao Zhang, Xiao-Hu Shao
Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers
 Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers A. Salhi, B. Minaoui, M. Fakir, H. Chakib, H. Grimech Faculty of science and Technology Sultan Moulay Slimane
Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers A. Salhi, B. Minaoui, M. Fakir, H. Chakib, H. Grimech Faculty of science and Technology Sultan Moulay Slimane
Color Local Texture Features Based Face Recognition
 Color Local Texture Features Based Face Recognition Priyanka V. Bankar Department of Electronics and Communication Engineering SKN Sinhgad College of Engineering, Korti, Pandharpur, Maharashtra, India
Color Local Texture Features Based Face Recognition Priyanka V. Bankar Department of Electronics and Communication Engineering SKN Sinhgad College of Engineering, Korti, Pandharpur, Maharashtra, India
Automatic Colorization of Grayscale Images
 Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
Janitor Bot - Detecting Light Switches Jiaqi Guo, Haizi Yu December 10, 2010
 1. Introduction Janitor Bot - Detecting Light Switches Jiaqi Guo, Haizi Yu December 10, 2010 The demand for janitorial robots has gone up with the rising affluence and increasingly busy lifestyles of people
1. Introduction Janitor Bot - Detecting Light Switches Jiaqi Guo, Haizi Yu December 10, 2010 The demand for janitorial robots has gone up with the rising affluence and increasingly busy lifestyles of people
Automated Diagnosis of Vertebral Fractures using 2D and 3D Convolutional Networks
 Automated Diagnosis of Vertebral Fractures using 2D and 3D Convolutional Networks CS189 Final Project Naofumi Tomita Overview Automated diagnosis of osteoporosis-related vertebral fractures is a useful
Automated Diagnosis of Vertebral Fractures using 2D and 3D Convolutional Networks CS189 Final Project Naofumi Tomita Overview Automated diagnosis of osteoporosis-related vertebral fractures is a useful
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS
 AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
On the Performance of Wavelet Decomposition Steganalysis with JSteg Steganography
 On the Performance of Wavelet Decomposition Steganalysis with JSteg Steganography Ainuddin Wahid Abdul Wahab, Johann A Briffa and Hans Georg Schaathun Department of Computing, University of Surrey Abstract.
On the Performance of Wavelet Decomposition Steganalysis with JSteg Steganography Ainuddin Wahid Abdul Wahab, Johann A Briffa and Hans Georg Schaathun Department of Computing, University of Surrey Abstract.
Kaggle Data Science Bowl 2017 Technical Report
 Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Histograms of Oriented Gradients
 Histograms of Oriented Gradients Carlo Tomasi September 18, 2017 A useful question to ask of an image is whether it contains one or more instances of a certain object: a person, a face, a car, and so forth.
Histograms of Oriented Gradients Carlo Tomasi September 18, 2017 A useful question to ask of an image is whether it contains one or more instances of a certain object: a person, a face, a car, and so forth.
COPY-MOVE FORGERY DETECTION USING DYADIC WAVELET TRANSFORM. College of Computer and Information Sciences, Prince Norah Bint Abdul Rahman University
 2011 Eighth International Conference Computer Graphics, Imaging and Visualization COPY-MOVE FORGERY DETECTION USING DYADIC WAVELET TRANSFORM Najah Muhammad 1, Muhammad Hussain 2, Ghulam Muhammad 2, and
2011 Eighth International Conference Computer Graphics, Imaging and Visualization COPY-MOVE FORGERY DETECTION USING DYADIC WAVELET TRANSFORM Najah Muhammad 1, Muhammad Hussain 2, Ghulam Muhammad 2, and
Block Mean Value Based Image Perceptual Hashing for Content Identification
 Block Mean Value Based Image Perceptual Hashing for Content Identification Abstract. Image perceptual hashing has been proposed to identify or authenticate image contents in a robust way against distortions
Block Mean Value Based Image Perceptual Hashing for Content Identification Abstract. Image perceptual hashing has been proposed to identify or authenticate image contents in a robust way against distortions
CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM
 CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM 1 PHYO THET KHIN, 2 LAI LAI WIN KYI 1,2 Department of Information Technology, Mandalay Technological University The Republic of the Union of Myanmar
CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM 1 PHYO THET KHIN, 2 LAI LAI WIN KYI 1,2 Department of Information Technology, Mandalay Technological University The Republic of the Union of Myanmar
Tag Recommendation for Photos
 Tag Recommendation for Photos Gowtham Kumar Ramani, Rahul Batra, Tripti Assudani December 10, 2009 Abstract. We present a real-time recommendation system for photo annotation that can be used in Flickr.
Tag Recommendation for Photos Gowtham Kumar Ramani, Rahul Batra, Tripti Assudani December 10, 2009 Abstract. We present a real-time recommendation system for photo annotation that can be used in Flickr.
Detection and localization of double compression in MP3 audio tracks
 Bianchi et al. EURASIP Journal on Information Security 214, 214:1 http://jis.eurasipjournals.com/content/214/1/1 RESEARCH Detection and localization of double compression in MP3 audio tracks Tiziano Bianchi
Bianchi et al. EURASIP Journal on Information Security 214, 214:1 http://jis.eurasipjournals.com/content/214/1/1 RESEARCH Detection and localization of double compression in MP3 audio tracks Tiziano Bianchi
Design of a Dynamic Data-Driven System for Multispectral Video Processing
 Design of a Dynamic Data-Driven System for Multispectral Video Processing Shuvra S. Bhattacharyya University of Maryland at College Park ssb@umd.edu With contributions from H. Li, K. Sudusinghe, Y. Liu,
Design of a Dynamic Data-Driven System for Multispectral Video Processing Shuvra S. Bhattacharyya University of Maryland at College Park ssb@umd.edu With contributions from H. Li, K. Sudusinghe, Y. Liu,
IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS
 IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS In-Jae Yu, Do-Guk Kim, Jin-Seok Park, Jong-Uk Hou, Sunghee Choi, and Heung-Kyu Lee Korea Advanced Institute of Science and
IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS In-Jae Yu, Do-Guk Kim, Jin-Seok Park, Jong-Uk Hou, Sunghee Choi, and Heung-Kyu Lee Korea Advanced Institute of Science and
Leaf Image Recognition Based on Wavelet and Fractal Dimension
 Journal of Computational Information Systems 11: 1 (2015) 141 148 Available at http://www.jofcis.com Leaf Image Recognition Based on Wavelet and Fractal Dimension Haiyan ZHANG, Xingke TAO School of Information,
Journal of Computational Information Systems 11: 1 (2015) 141 148 Available at http://www.jofcis.com Leaf Image Recognition Based on Wavelet and Fractal Dimension Haiyan ZHANG, Xingke TAO School of Information,