Optimized Clusters for Disaggregated Electricity Load Forecasting
|
|
|
- Timothy Dawson
- 5 years ago
- Views:
Transcription
1 Optimized Clusters for Disaggregated Electricity Load Forecasting Jean-Michel Poggi Lab. de Mathématique, Univ. Paris-Sud, Orsay & Univ. Paris Descartes Joint work with M. Misiti, Y. Misiti, G. Oppenheim
2 Outline Introduction Data and real-world problem Aggregated versus disaggregated Disaggregation for Prediction A 4-steps procedure Cross-prediction dissimilarity Clusters Optimization Results and performance Future developments 2
3 Introduction Takes places in a scientific collaboration with EDF (the French electrical company) EDF R&D, Osiris dept. Clamart (A. Dessertaine) Goal: To improve the accuracy of electrical load forecast To allow to take into account the variation of the EDF due to the liberalization of the electrical market Idea: to conveniently disaggregate the basic signal Prediction accuracy: High in a stable market (a short-term MAPE about 1%) Decreases in new situations Main objective: study if a significant gain can be reached using such a strategy 3


4 The data Load curve: amount of electricity power used over a period of time 2309 individual industrial customers load curves during 2 years every hour (17520 points) Averaged weeks ISF 2008 J-M. Poggi, M. Misiti, Y. Misiti, G. Oppenheim 4




5 Raw data: 2 years 2000 and


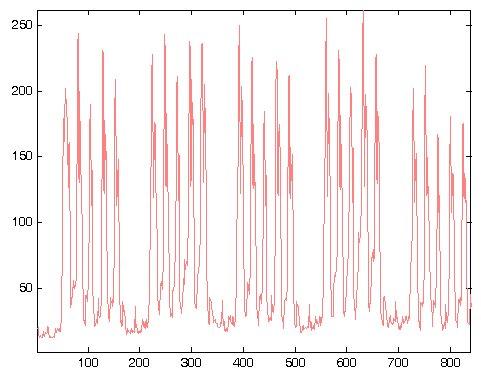
6 Raw data: 5 weeks of
7 Raw data: 1 week of
8 Eventail-like forecasting model We consider a fully automatic version of the EDF operational model Eventail See PhD Thesis V. Lefieux, Rennes 2, oct A recent reference: Bruhns, A., Deurveilher, G., Roy, J. S. (2005) A non linear regression model for mid-term load forecasting and improvements in seasonality Proceedings of the 15th Power Systems Computation Conference 2005, Liege, Belgium 8
9 Aggregated versus disaggregated 1- Result for 2 clusters (but true for p) under independence hypothesis: Data Prediction Error Result ( X1,..., X n ) ( Y1,..., Y n ) = X 1,..., Xn 1 X n E ( Xn ) Y1,..., Y n 1 Y n = E ( Yn ) Err = E [ X + Y ( X + Y n )] DISAG n n n 2 ErrDISAG Err AGGR Si = Xi + Yi S1,..., S n 1 S n = E ( S ) Err = E ( X + Y S n ) n 2- Stratified representative sampling AGGR n n 2 ( ) Var Y ( Y) σ σ = to be compared to Var ( Y strat ) = n 2 2 within n ( Y) 9
10 Aggregated versus disaggregated Disaggregate the global signal to improve forecasts Idea: to find a tradeoff between the within the clusters homogeneity the quality of the models estimation The first increases with the number of clusters while the second decreases Aggregate similar individual customers to : Decrease between clusters variability effects Improve within clusters estimation quality Ascending Strategy mixing : Preprocessing using wavelets and clustering Optimization driven by previsibility 10
11 Disaggregation: a 4 steps procedure A. Preprocessing using wavelets Standardization Coding using Ca6 (approximation coefficients at level 6) B. Preliminary clustering Around numerous centroids, typically 90 clusters of very homogeneous customers Each cluster is then associated with the corresponding aggregated signal C. Iterative optimization Supervised by a cross-prediction dissimilarity index A discrete gradient type procedure based on dissimilarities explores the set of partitions D. Consolidation 11
12 Wavelet-based clustering For each signal and for a given wavelet and a maximum decomposition level J: 1. Wavelet decomposition 2. Denoise by wavelet coefficients thresholding 3. Generate partitions, using various common compression wavelet bases hierarchical clustering using Ward method and euclidean distance 4. Select the best partition according to a quality index choose a decomposition level j* choose a number of clusters C ( ca,,, ) J cdj cd j ( ca,,, ) J cdj cd j clusters ( ca,,, ) J cdj cd j I N Z ( P) for 1 j J ( Z, P) ( ZP) Varbetween = CPVar ( )., within * final partition for j and C 12
13 Cross-prediction dissimilarity Dissimilarity index between 2 elements s k and s j : kj (, ) forec = forecast s s kj j k ( , ) E = error s forec Previsibility of s k using a model for s j and vice versa k kj Forecast of 2001 for s k using the model fitted using s j during 2000 Short-term, long-term (LT, CT) MAPE (Mean Absolute Percentage Error) ( ) D = E + E /2, jk kj jk Dissimilarity matrix : D 1 = D = jk, jk, 2 E + E ( ) T ( ) Cost expansive 13
14 Zooming in on optimization Iterative optimization of the initial partition supervised by cross-prediction dissimilarity should be adapted to: prediction horizon error criterion Scheme: Discrete gradient type via a neighborhood definition through a dissimilarity between an element and a cluster induced by D Iterative exploration of elements using nearest D-neighbors Elements are always candidates for cluster change Only the partition evolves and the basic step consists in changing an element from a cluster to another one Generates a non monotonic sequence of partitions (this is not a hierarchical approach) The number of clusters decreases slowly along the iterations, and a cluster disappears if it becomes empty 14
15 Optimization step Performed once step 0 Compute D: dissimilarities between elements step 1 Compute dissimilarities (element, current clusters) using D and a linkage function (e.g. the minimum) Select a neighbor: a couple (E, C) Without updating D step 2 Test the gain of the affectation: error of the disaggregated prediction associated with the resulting partition if the error does not decrease then if it exists candidates then examine the next candidate and step 2 else end {no possible improvement by moving an element from a cluster to another one} else {the error decreases} modify partition and step 1 15
16 Global quantitative result Starting from 90 clusters, the optimized partition reaches MAPE Long Term (LT) MAPE Short Term (ST) 1 cluster 19 clusters GAIN 4.06% 2.39 % % 1 cluster 28 clusters GAIN 2.47 % 1.51% 38.86% Anytime procedure From 90 to 19 clusters: 195 steps 16
17 Preprocessing steps? The two first steps (A and B) wavelet preprocessing and initial clustering, seem to be useful. Indeed: Hierarchical clustering of the original 2309 customers using D Then optimize the associated 90 clusters partition The MAPE-LT error stabilizes around 2.7% instead of 2.4% KM90 Partitions à 19 classes issues de KM90 par CAH avec diverses distances de Linkage Single Ward Complete Average Centroid Median Weight MAPE LT Initiale MAPE LT Finale Nombre final de Classes Effectif Diagonale par rapport à KM90 Pourcentage Diagonale par rapport à KM90 2,617% 3,213% 2,844% 2,854% 2,881% 2,879% 2,893% 2,786% 2,393% 3,028% 2,744% 2,765% 2,774% 2,775% 2,763% 2,744% ,00% 25,21% 29,84% 29,28% 28,28% 30,01% 28,54% 29,45% MAPE CT ISF ,588% 1,870% 1,749% 1,779% 1,781% 1,772% 1,806% 1,775% Initiale J-M. Poggi, M. Misiti, Y. Misiti, G. Oppenheim 17
18 Optimisation step? The optimization step seems to be useful, indeed : Starting from the 60 (or 90 clusters) partition If one constructs the hierarchy of partitions (by hierarchical clustering using D) : It is difficult to select a critical number of clusters The MAPE LT error of the 19 clusters partition remains about 2,6% instead of 2,3% «single linkage» «Ward method». Cut for 19 clusters Irrelevant cut for 19 clusters Very «flat» (log scale for «Ward») 18
19 Future developments First direction : Experiment on these electrical data forecasting methods using wavelets Antoniadis, Paparoditis, Sapatinas, JRSS B. (2006) AminGhafari, Poggi, IJ Wav. Inf. Proc. (2007) Adapt forecasting models to the clusters mimicking the approach Hathaway, Bezdek, IEEE Fuzzy Systems (1993) To make profit of external information (meteorologic and economical) for interpretation and performance improvement To study theoretically the conditions to maximize the benefits of disaggregation in more general contexts Second direction : integrate in a global procedure The wavelet and the representation basis The obtained partition and the adaptation of the model to cluster specificities 19
20 References AminGhafari, Poggi, IJ Wav. Inf. Proc. (2007) Antoniadis et al., JRSS B. (2006) Biau et al., IEEE Trans. Inf. Th. (2005) Biau et al., IEEE Trans. Inf. Th. (2007) Bruhns, et al., Proc. PSC Conf (2005) Calinski, Harabasz, Comm. Stat. (1974) Hathaway, Bezdek, IEEE Fuzzy Systems (1993) Kaufman, Rousseeuw, Wiley (2005) James, Sugar, JASA (2003) Mallat, Academic Press (1998) Misiti et al., Hermes, ISTE (2007) Misiti et al., Lect. Not. Comp. Sc (2007) Ramsay, Silverman, Springer (1997) Tibshirani et al., JRSS B (2001) Vlachos et al., SIAM Conf. Data Mining (2003) Vannucci et al., Chem. and Int. Lab. Syst. (2005) 20
Non supervised classification of individual electricity curves
 Non supervised classification of individual electricity curves Jairo Cugliari 17 février 2014 Joint work with Benjamin Auder (LMO, Université Paris-Sud) Outline 1 Motivation 2 Functional clustering 3 Parallel
Non supervised classification of individual electricity curves Jairo Cugliari 17 février 2014 Joint work with Benjamin Auder (LMO, Université Paris-Sud) Outline 1 Motivation 2 Functional clustering 3 Parallel
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Unsupervised Learning
 Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
CS 521 Data Mining Techniques Instructor: Abdullah Mueen
 CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
CS 521 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 2: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Supervised Variable Clustering for Classification of NIR Spectra
 Supervised Variable Clustering for Classification of NIR Spectra Catherine Krier *, Damien François 2, Fabrice Rossi 3, Michel Verleysen, Université catholique de Louvain, Machine Learning Group, place
Supervised Variable Clustering for Classification of NIR Spectra Catherine Krier *, Damien François 2, Fabrice Rossi 3, Michel Verleysen, Université catholique de Louvain, Machine Learning Group, place
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
ECM A Novel On-line, Evolving Clustering Method and Its Applications
 ECM A Novel On-line, Evolving Clustering Method and Its Applications Qun Song 1 and Nikola Kasabov 2 1, 2 Department of Information Science, University of Otago P.O Box 56, Dunedin, New Zealand (E-mail:
ECM A Novel On-line, Evolving Clustering Method and Its Applications Qun Song 1 and Nikola Kasabov 2 1, 2 Department of Information Science, University of Otago P.O Box 56, Dunedin, New Zealand (E-mail:
Clustering Algorithms for general similarity measures
 Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Contents. List of Figures. List of Tables. List of Algorithms. I Clustering, Data, and Similarity Measures 1
 Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Smoothing Dissimilarities for Cluster Analysis: Binary Data and Functional Data
 Smoothing Dissimilarities for Cluster Analysis: Binary Data and unctional Data David B. University of South Carolina Department of Statistics Joint work with Zhimin Chen University of South Carolina Current
Smoothing Dissimilarities for Cluster Analysis: Binary Data and unctional Data David B. University of South Carolina Department of Statistics Joint work with Zhimin Chen University of South Carolina Current
Medical Image Segmentation Based on Mutual Information Maximization
 Medical Image Segmentation Based on Mutual Information Maximization J.Rigau, M.Feixas, M.Sbert, A.Bardera, and I.Boada Institut d Informatica i Aplicacions, Universitat de Girona, Spain {jaume.rigau,miquel.feixas,mateu.sbert,anton.bardera,imma.boada}@udg.es
Medical Image Segmentation Based on Mutual Information Maximization J.Rigau, M.Feixas, M.Sbert, A.Bardera, and I.Boada Institut d Informatica i Aplicacions, Universitat de Girona, Spain {jaume.rigau,miquel.feixas,mateu.sbert,anton.bardera,imma.boada}@udg.es
无监督学习中的选代表和被代表问题 - AP & LLE 张响亮. Xiangliang Zhang. King Abdullah University of Science and Technology. CNCC, Oct 25, 2018 Hangzhou, China
 无监督学习中的选代表和被代表问题 - AP & LLE 张响亮 Xiangliang Zhang King Abdullah University of Science and Technology CNCC, Oct 25, 2018 Hangzhou, China Outline Affinity Propagation (AP) [Frey and Dueck, Science, 2007]
无监督学习中的选代表和被代表问题 - AP & LLE 张响亮 Xiangliang Zhang King Abdullah University of Science and Technology CNCC, Oct 25, 2018 Hangzhou, China Outline Affinity Propagation (AP) [Frey and Dueck, Science, 2007]
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Machine Learning for OR & FE
 Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
CHAPTER-6 WEB USAGE MINING USING CLUSTERING
 CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
Unsupervised Learning
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Clustering algorithms and introduction to persistent homology
 Foundations of Geometric Methods in Data Analysis 2017-18 Clustering algorithms and introduction to persistent homology Frédéric Chazal INRIA Saclay - Ile-de-France frederic.chazal@inria.fr Introduction
Foundations of Geometric Methods in Data Analysis 2017-18 Clustering algorithms and introduction to persistent homology Frédéric Chazal INRIA Saclay - Ile-de-France frederic.chazal@inria.fr Introduction
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Collaborative Rough Clustering
 Collaborative Rough Clustering Sushmita Mitra, Haider Banka, and Witold Pedrycz Machine Intelligence Unit, Indian Statistical Institute, Kolkata, India {sushmita, hbanka r}@isical.ac.in Dept. of Electrical
Collaborative Rough Clustering Sushmita Mitra, Haider Banka, and Witold Pedrycz Machine Intelligence Unit, Indian Statistical Institute, Kolkata, India {sushmita, hbanka r}@isical.ac.in Dept. of Electrical
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
A fuzzy k-modes algorithm for clustering categorical data. Citation IEEE Transactions on Fuzzy Systems, 1999, v. 7 n. 4, p.
 Title A fuzzy k-modes algorithm for clustering categorical data Author(s) Huang, Z; Ng, MKP Citation IEEE Transactions on Fuzzy Systems, 1999, v. 7 n. 4, p. 446-452 Issued Date 1999 URL http://hdl.handle.net/10722/42992
Title A fuzzy k-modes algorithm for clustering categorical data Author(s) Huang, Z; Ng, MKP Citation IEEE Transactions on Fuzzy Systems, 1999, v. 7 n. 4, p. 446-452 Issued Date 1999 URL http://hdl.handle.net/10722/42992
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Clustering. k-mean clustering. Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein
 Clustering k-mean clustering Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein A quick review The clustering problem: homogeneity vs. separation Different representations
Clustering k-mean clustering Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein A quick review The clustering problem: homogeneity vs. separation Different representations
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
A Quantitative Approach for Textural Image Segmentation with Median Filter
 International Journal of Advancements in Research & Technology, Volume 2, Issue 4, April-2013 1 179 A Quantitative Approach for Textural Image Segmentation with Median Filter Dr. D. Pugazhenthi 1, Priya
International Journal of Advancements in Research & Technology, Volume 2, Issue 4, April-2013 1 179 A Quantitative Approach for Textural Image Segmentation with Median Filter Dr. D. Pugazhenthi 1, Priya
CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION
 CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION 6.1 INTRODUCTION Fuzzy logic based computational techniques are becoming increasingly important in the medical image analysis arena. The significant
CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION 6.1 INTRODUCTION Fuzzy logic based computational techniques are becoming increasingly important in the medical image analysis arena. The significant
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Types of general clustering methods. Clustering Algorithms for general similarity measures. Similarity between clusters
 Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
[Raghuvanshi* et al., 5(8): August, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116
![[Raghuvanshi* et al., 5(8): August, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116](/thumbs/90/104488131.jpg "[Raghuvanshi* et al., 5(8): August, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116") IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY A SURVEY ON DOCUMENT CLUSTERING APPROACH FOR COMPUTER FORENSIC ANALYSIS Monika Raghuvanshi*, Rahul Patel Acropolise Institute
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY A SURVEY ON DOCUMENT CLUSTERING APPROACH FOR COMPUTER FORENSIC ANALYSIS Monika Raghuvanshi*, Rahul Patel Acropolise Institute
A Denoising Framework with a ROR Mechanism Using FCM Clustering Algorithm and NLM
 A Denoising Framework with a ROR Mechanism Using FCM Clustering Algorithm and NLM M. Nandhini 1, Dr.T.Nalini 2 1 PG student, Department of CSE, Bharath University, Chennai-73 2 Professor,Department of
A Denoising Framework with a ROR Mechanism Using FCM Clustering Algorithm and NLM M. Nandhini 1, Dr.T.Nalini 2 1 PG student, Department of CSE, Bharath University, Chennai-73 2 Professor,Department of
Spatial Outlier Detection
 Spatial Outlier Detection Chang-Tien Lu Department of Computer Science Northern Virginia Center Virginia Tech Joint work with Dechang Chen, Yufeng Kou, Jiang Zhao 1 Spatial Outlier A spatial data point
Spatial Outlier Detection Chang-Tien Lu Department of Computer Science Northern Virginia Center Virginia Tech Joint work with Dechang Chen, Yufeng Kou, Jiang Zhao 1 Spatial Outlier A spatial data point
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Efficient Image Compression of Medical Images Using the Wavelet Transform and Fuzzy c-means Clustering on Regions of Interest.
 Efficient Image Compression of Medical Images Using the Wavelet Transform and Fuzzy c-means Clustering on Regions of Interest. D.A. Karras, S.A. Karkanis and D. E. Maroulis University of Piraeus, Dept.
Efficient Image Compression of Medical Images Using the Wavelet Transform and Fuzzy c-means Clustering on Regions of Interest. D.A. Karras, S.A. Karkanis and D. E. Maroulis University of Piraeus, Dept.
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Application of Clustering Techniques to Energy Data to Enhance Analysts Productivity
 Application of Clustering Techniques to Energy Data to Enhance Analysts Productivity Wendy Foslien, Honeywell Labs Valerie Guralnik, Honeywell Labs Steve Harp, Honeywell Labs William Koran, Honeywell Atrium
Application of Clustering Techniques to Energy Data to Enhance Analysts Productivity Wendy Foslien, Honeywell Labs Valerie Guralnik, Honeywell Labs Steve Harp, Honeywell Labs William Koran, Honeywell Atrium
Data mining techniques for actuaries: an overview
 Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Data Preprocessing Aggregation Sampling Dimensionality Reduction Feature subset selection Feature creation
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Cluster Tendency Assessment for Fuzzy Clustering of Incomplete Data
 EUSFLAT-LFA 2011 July 2011 Aix-les-Bains, France Cluster Tendency Assessment for Fuzzy Clustering of Incomplete Data Ludmila Himmelspach 1 Daniel Hommers 1 Stefan Conrad 1 1 Institute of Computer Science,
EUSFLAT-LFA 2011 July 2011 Aix-les-Bains, France Cluster Tendency Assessment for Fuzzy Clustering of Incomplete Data Ludmila Himmelspach 1 Daniel Hommers 1 Stefan Conrad 1 1 Institute of Computer Science,
CLUSTER ANALYSIS. V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi
 CLUSTER ANALYSIS V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi-110 012 In multivariate situation, the primary interest of the experimenter is to examine and understand the relationship amongst the
CLUSTER ANALYSIS V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi-110 012 In multivariate situation, the primary interest of the experimenter is to examine and understand the relationship amongst the
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Image Mining: frameworks and techniques
 Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
Introduction to spectral clustering
 Introduction to spectral clustering Vasileios Zografos zografos@isy.liu.se Klas Nordberg klas@isy.liu.se What this course is Basic introduction into the core ideas of spectral clustering Sufficient to
Introduction to spectral clustering Vasileios Zografos zografos@isy.liu.se Klas Nordberg klas@isy.liu.se What this course is Basic introduction into the core ideas of spectral clustering Sufficient to
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Overview Citation. ML Introduction. Overview Schedule. ML Intro Dataset. Introduction to Semi-Supervised Learning Review 10/4/2010
 INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
DISCRETIZATION BASED ON CLUSTERING METHODS. Daniela Joiţa Titu Maiorescu University, Bucharest, Romania
 DISCRETIZATION BASED ON CLUSTERING METHODS Daniela Joiţa Titu Maiorescu University, Bucharest, Romania daniela.oita@utm.ro Abstract. Many data mining algorithms require as a pre-processing step the discretization
DISCRETIZATION BASED ON CLUSTERING METHODS Daniela Joiţa Titu Maiorescu University, Bucharest, Romania daniela.oita@utm.ro Abstract. Many data mining algorithms require as a pre-processing step the discretization
Evaluation of Direct and Indirect Blockmodeling of Regular Equivalence in Valued Networks by Simulations
 Metodološki zvezki, Vol. 6, No. 2, 2009, 99-134 Evaluation of Direct and Indirect Blockmodeling of Regular Equivalence in Valued Networks by Simulations Aleš Žiberna 1 Abstract The aim of the paper is
Metodološki zvezki, Vol. 6, No. 2, 2009, 99-134 Evaluation of Direct and Indirect Blockmodeling of Regular Equivalence in Valued Networks by Simulations Aleš Žiberna 1 Abstract The aim of the paper is
Equi-sized, Homogeneous Partitioning
 Equi-sized, Homogeneous Partitioning Frank Klawonn and Frank Höppner 2 Department of Computer Science University of Applied Sciences Braunschweig /Wolfenbüttel Salzdahlumer Str 46/48 38302 Wolfenbüttel,
Equi-sized, Homogeneous Partitioning Frank Klawonn and Frank Höppner 2 Department of Computer Science University of Applied Sciences Braunschweig /Wolfenbüttel Salzdahlumer Str 46/48 38302 Wolfenbüttel,
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Function approximation using RBF network. 10 basis functions and 25 data points.
 1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
HARD, SOFT AND FUZZY C-MEANS CLUSTERING TECHNIQUES FOR TEXT CLASSIFICATION
 HARD, SOFT AND FUZZY C-MEANS CLUSTERING TECHNIQUES FOR TEXT CLASSIFICATION 1 M.S.Rekha, 2 S.G.Nawaz 1 PG SCALOR, CSE, SRI KRISHNADEVARAYA ENGINEERING COLLEGE, GOOTY 2 ASSOCIATE PROFESSOR, SRI KRISHNADEVARAYA
HARD, SOFT AND FUZZY C-MEANS CLUSTERING TECHNIQUES FOR TEXT CLASSIFICATION 1 M.S.Rekha, 2 S.G.Nawaz 1 PG SCALOR, CSE, SRI KRISHNADEVARAYA ENGINEERING COLLEGE, GOOTY 2 ASSOCIATE PROFESSOR, SRI KRISHNADEVARAYA
K-Means Clustering With Initial Centroids Based On Difference Operator
 K-Means Clustering With Initial Centroids Based On Difference Operator Satish Chaurasiya 1, Dr.Ratish Agrawal 2 M.Tech Student, School of Information and Technology, R.G.P.V, Bhopal, India Assistant Professor,
K-Means Clustering With Initial Centroids Based On Difference Operator Satish Chaurasiya 1, Dr.Ratish Agrawal 2 M.Tech Student, School of Information and Technology, R.G.P.V, Bhopal, India Assistant Professor,
Didacticiel - Études de cas
 Subject In this tutorial, we use the stepwise discriminant analysis (STEPDISC) in order to determine useful variables for a classification task. Feature selection for supervised learning Feature selection.
Subject In this tutorial, we use the stepwise discriminant analysis (STEPDISC) in order to determine useful variables for a classification task. Feature selection for supervised learning Feature selection.
Data Preprocessing. Komate AMPHAWAN
 Data Preprocessing Komate AMPHAWAN 1 Data cleaning (data cleansing) Attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. 2 Missing value
Data Preprocessing Komate AMPHAWAN 1 Data cleaning (data cleansing) Attempt to fill in missing values, smooth out noise while identifying outliers, and correct inconsistencies in the data. 2 Missing value
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data
 Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
Application of fuzzy set theory in image analysis. Nataša Sladoje Centre for Image Analysis
 Application of fuzzy set theory in image analysis Nataša Sladoje Centre for Image Analysis Our topics for today Crisp vs fuzzy Fuzzy sets and fuzzy membership functions Fuzzy set operators Approximate
Application of fuzzy set theory in image analysis Nataša Sladoje Centre for Image Analysis Our topics for today Crisp vs fuzzy Fuzzy sets and fuzzy membership functions Fuzzy set operators Approximate
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Community detection. Leonid E. Zhukov
 Community detection Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Network Science Leonid E.
Community detection Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Network Science Leonid E.
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Tree Models of Similarity and Association. Clustering and Classification Lecture 5
 Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
A Generalized Method to Solve Text-Based CAPTCHAs
 A Generalized Method to Solve Text-Based CAPTCHAs Jason Ma, Bilal Badaoui, Emile Chamoun December 11, 2009 1 Abstract We present work in progress on the automated solving of text-based CAPTCHAs. Our method
A Generalized Method to Solve Text-Based CAPTCHAs Jason Ma, Bilal Badaoui, Emile Chamoun December 11, 2009 1 Abstract We present work in progress on the automated solving of text-based CAPTCHAs. Our method
Clustering and The Expectation-Maximization Algorithm
 Clustering and The Expectation-Maximization Algorithm Unsupervised Learning Marek Petrik 3/7 Some of the figures in this presentation are taken from An Introduction to Statistical Learning, with applications
Clustering and The Expectation-Maximization Algorithm Unsupervised Learning Marek Petrik 3/7 Some of the figures in this presentation are taken from An Introduction to Statistical Learning, with applications
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Additive hedonic regression models for the Austrian housing market ERES Conference, Edinburgh, June
 for the Austrian housing market, June 14 2012 Ao. Univ. Prof. Dr. Fachbereich Stadt- und Regionalforschung Technische Universität Wien Dr. Strategic Risk Management Bank Austria UniCredit, Wien Inhalt
for the Austrian housing market, June 14 2012 Ao. Univ. Prof. Dr. Fachbereich Stadt- und Regionalforschung Technische Universität Wien Dr. Strategic Risk Management Bank Austria UniCredit, Wien Inhalt