Understanding Clustering Supervising the unsupervised
|
|
|
- Jasmin Angelica Wells
- 5 years ago
- Views:
Transcription
1 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York
2 Clustering Grouping together similar data points into distinct partitions. Items in same cluster are more similar to each other than to the items in other clusters. Common unsupervised machine learning technique. Used for aggregating and summarizing complex multidimensional data. Very important exploratory step to understand data before any statistical analysis or data mining. From perception POV, a scatterplot is the best way to visualize clusters, often accompanied by a low-dimensional projection (PCA/MDS/tsne) onto 2 dimensions.
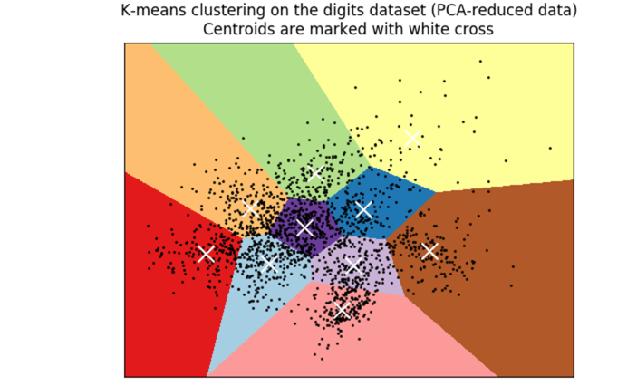
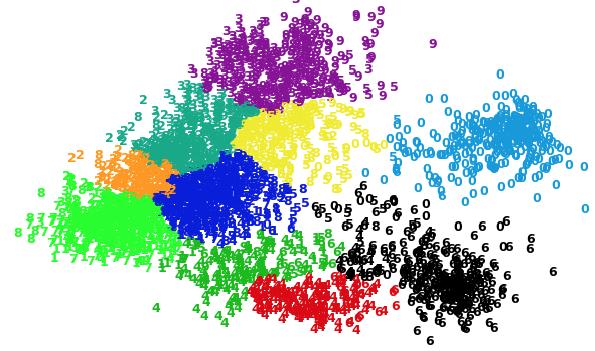
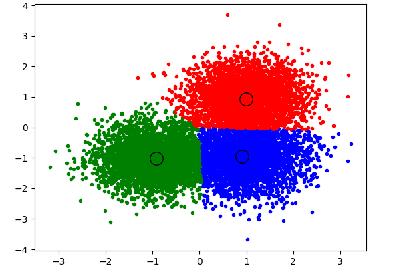
3
4 Clustering algorithms There are a plethora of clustering algorithms that differ in their set of assumptions on data & clusters, and the methods to effectively find clusters. These algorithms have their strengths and weaknesses. The choice of appropriate clustering algorithm and its parameters depend on the individual data set and intended use of the results. However, given a particular dataset and analytical task, there are NO systematic procedures for knowing which algorithm will provide the best clustering.
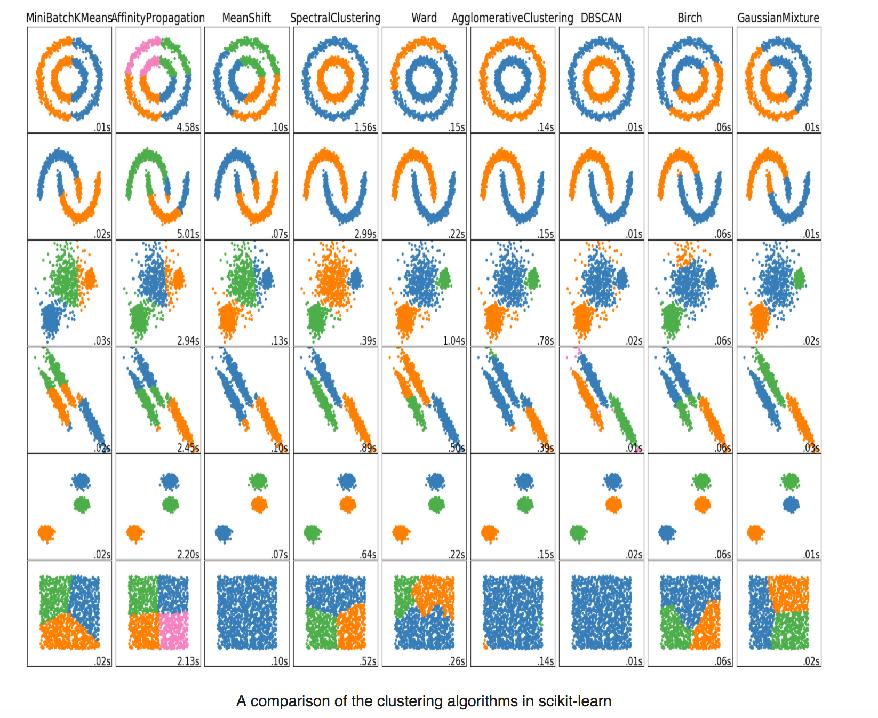
5
6 Centroid-based Clustering algorithms Find cluster representatives, centroids, and assign a data point to the cluster whose centroid is the nearest to the data point. Incredibly hard problem: Infinitely many possibilities, NP hard! Slightly easier version: k- means, assumes there are k clusters in the data. Still NP hard! Can obtain approximate solution (local minima). Lloyd s algorithm: Start with k random centroids, assign points to the nearest centroid, choose new centroid as the mean of the points in the clusters and repeat until a stopping criterion. Partitions data into a Voronoi diagram, also related to Expectation-Maximization. Use case: General-purpose, even cluster size, flat geometry, not too many clusters. Requires: choice of metric, apriori knowledge of k. Drawbacks: Prefers convex and isotropic clusters, not robust to randomness. Modifications: k-mediods, k-medians, k-means++, fuzzy c-means.
7 Connectivity-based clustering algorithms AKA Hierarchical clustering, provides a nested partitioning of the data by successively merging (agglomerative) or splitting (divisive) them, thereby producing a hierarchy which can be shown visually as a dendrogram. The root of the dendrogram is the unique cluster containing all the data points, and the leaves are clusters each containing exactly one data point. e.g. in Agglomerative clustering, each data point starts as an individual cluster and are then merged in successive steps. Use case: Many clusters, possibly connectivity constraints, non Euclidean distances. Requires: Choice of a metric (distance between two data points), Linkage criterion (distance between two clusters).
8


9 Different linkages in sklearn different metric choices
10 Density-based clustering algorithms Attempts to find regions of high density (clusters) in the data which are separated by regions of low density (boundaries/noise). Can detect clusters of any shape, not just convex. e.g. DBSCAN: Find highly dense regions as clusters and assign points in the lowdensity regions to the cluster they are closer to. Unassigned points are outliers. Use case: Non-flat geometry, uneven cluster sizes, outliers Requires: Quantify density (e.g. set of points for each of which there exists m number of points at a distance less then d, in sklearn, min_samples and eps). Drawbacks: Need sharp density gradient to detect clusters, not effective where the gradient is continuous e.g. a mixture of Gaussians. Variants: OPTICS, Mean Shift
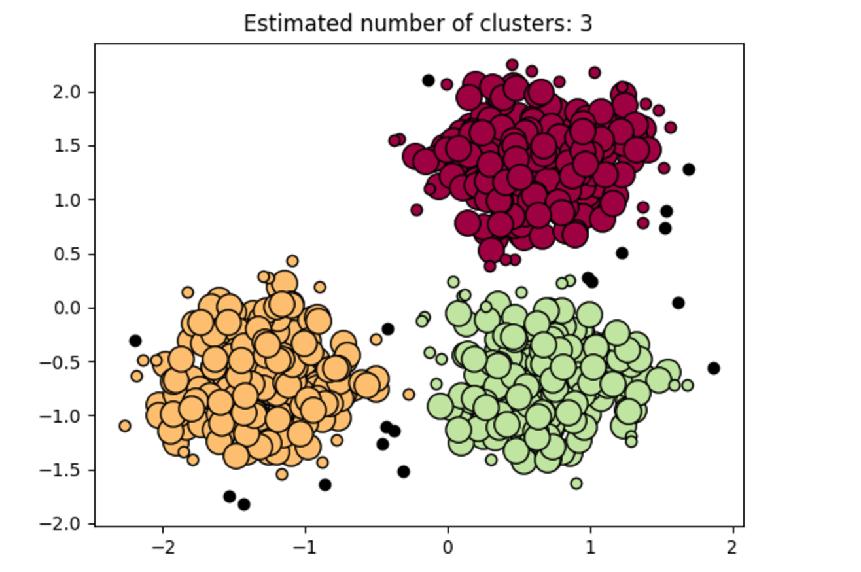
11
12 Probability-based clustering algorithms Distinct clusters are samples from distinct probability distributions. Assume a distribution model, and try to separate based on the parameter estimates. Gaussian Mixture model: The data points are generated from a mixture of a finite number of Gaussian distributions with unknown parameters which are estimated using Expectation-Maximization algorithm. Usually overfits unless constrained model is used, e.g. fixing the number of Gaussians (number of clusters), in fact GMM is a generalisation of k-means to include covariance. Can also constrain covariance. Use case: Flat geometry, good for density estimation. Requires: k (usually), covariance constraint, convergence threshold for EM algorithm, initialization for parameters.

 comparing k means and EM")
13 Cluster analysis performed on an artificial dataset ("Mouse", similar to a well-known comic figure) comparing k means and EM clustering results.
14 Issues in cluster analysis So many algorithms to choose from, NO systematicmathematical way to decide. Optimal parameters for the chosen algorithm depends on the dataset and the analytical task at hand. The notion of cluster can t be precisely defined. Clustering is in the eyes of the beholder. - Why so many clustering algorithms, Vladimir Estivill-Castro Ability to compare various clustering results and estimate quality of a clustering result. Unsupervised method - lack of ground truth. Evaluation is difficult.
15
16 Clustering evaluation metrics Difficult task, at least as difficult as clustering (Pfitzner et al). External evaluation: results are compared with ground truth. Not practical. Internal evaluation: results are aggregated into a single statistic. Without ground truth. Manual evaluation: human expert makes decision, not practical in this big data paradigm. Internal evaluation with human-in-the-loop?
17 Silhouette coefficient The Silhouette Coefficient is a measure of how similar a point is to its own cluster compared to other clusters, where a high value indicates that the object is well matched to its own cluster and poorly matched to neighbouring clusters. For a data point x proposed to be in cluster C, the Silhouette Coefficient is defined as where is the average distance between x and all other points in C, and is the distance between x and all the points in the cluster nearest to x. The Silhouette coefficient for the whole clustering is defined to be mean of the values for all the data points. The value lies in ( 1, 1) where the higher the value of the coefficient, the better the clustering. Reference: P. J. Rousseeuw Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20:53 65, 1987 (sklearn.metrics.silhouette_score)
18 Calinski-Harabaz index The Calinski-Harabaz index of a clustering is defined as the ratio of the between-cluster variance and the within-cluster variance. Well-defined clusters have higher between-cluster variance and lower within-cluster variance, thus higher value of the index. For k clusters, CZ(k) = Total inter-cluster variance / Total intra-cluster variance, where Here i-th cluster, has mean and contains elements, and is the overall mean of the data. Reference: M. Kozak. A dendrite method for cluster analysis by Calinski and Harabaz: A classical work that is far too often incorrectly cited. Communications in Statistics - Theory and Methods, 41(12): , 2012 (sklearn.metrics.calinski_harabaz_score)
19 Davies-Bouldin coefficient Similar to Calinski-Harabaz index, is defined as the average over all clusters the ratio of within-cluster dispersion and the pairwise between-cluster dispersion. Here is the average distance between each point in the i-th cluster and its centroid, and is the average distance between the centroids of the i-th and the j-th cluster. Smaller the Davies-Bouldin index, better the clustering results are. Reference: D. L. Davies and D. W. Bouldin. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell., 1(2): , Feb
20 Gap statistic The elbow method, where a metric(usually within to between-cluster distance ratio) is plotting against an internal parameter, is a popular and intuitive method to find the optimal value of the parameter. Tibshirani et al provided a statistical formulation of this technique and defined gap statistic. The idea is to consider clustering of random permutations of the data to observe how they compare with a null reference distribution of data with no clustering structure. Within groups sum of squares Reference: R. Tibshirani, G. Walther, and T. Hastie. Estimating the number of clusters in a dataset via the gap statistic. 63: , Number of Clusters
21 Sdb_w Sdb_w attempts to measure quality by taking into consideration the compactness, separation, and the density of the clusters. Relies on the notion of the density of a point x relative to a pair of clusters which is equal to the number of points in these clusters which are inside a ball centered at x. Defined under the assumption that for each pair of clusters, the density of at least one of the centroids must be greater than the density of their midpoint to have a good clustering Reference: M. Halkidi and M. Vazirgiannis. Clustering validity assessment: Finding the optimal partitioning of a data set. In Proceedings of the 2001 IEEE International Conference on Data Mining, ICDM 01, pp IEEE Computer Society, Washington, DC, USA, 2001


22 Selecting number of clusters using Silhouette analysis k=3,5 are not good options!! Which is the best (most optimal) value of k?
23 Clustervision Clustervision is a visual analytical tool that helps ensure data scientists find the right clustering among the large amount of techniques and parameters available. Developed by researchers at IBM Watson Research Center. The system clusters data using a variety of clustering techniques and parameters and then ranks clustering results utilizing five quality scoring metrics. The visual user interface allows users to find high quality clustering results, explore the clusters using several coordinated visualization techniques, and select the cluster result that best suits their task. To appear at IEEE Vis October 2017.
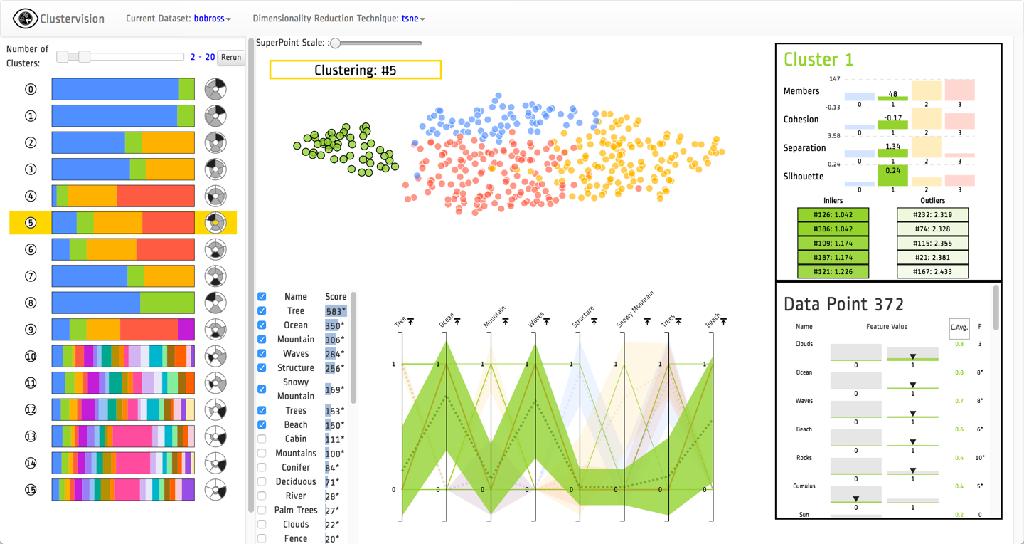
24
25 Randomness in clustering Many clustering algorithms like k-means, GMM use a random initialization. Since these algorithms are approximate solutions to the optimization problem, they attempt to find a local minima. Which local minima is found, depends on the initial state, and thus we can get different results for multiple runs on same data, using same algorithm and its parameters. Also makes difficult to compare the clustering results from different models.
26 Consensus clustering One way to get better hold of the sensitivity to random initialization is to do multiple runs of the clustering algorithm, and observe the differences between the runs. Ideally, define a statistic which quantifies the differences among the results of different runs in the ensemble. First, define the consensus matrix whose entries reflect the probability that two different data items belong to the same cluster. Perform clustering m times, then the ij-th entry in the consensus matrix C_ij = #(i and j are in same cluster)/m Define dispersion of the clustering as The value of the coefficient is 1 for a perfect consensus matrix (all entries 0 or 1). Ideally we want this value to the as close to 1 as possible. This indicates that the different clusterings in the ensemble are statistically similar and are thus robust of the random initializations.
27 Consensus clustering This can also be used as a clustering evaluation metric and thus can be used to compute the optimal number of clusters. Compute dispersion for different values of k and then choose k with maximal value of dispersion. Another such metric is cophenetic correlation. If multiple clusterings have been obtained for a given dataset e.g. for different algorithms, same algorithm different parameters, different initialization etc. it s desirable to obtain a single clustering which is an aggregate of all the runs in the ensemble. Such a clustering, called consensus clustering, provides a reconciliation of clusterings from different sources. Many different ways to compute the consensus clustering.
28
29 Consensus clustering computation The rows of the consensus matrix provides a vector representation for the data points in terms of how they were clustered across multiple runs. Compute the point-wise similarity. Various metrics like cosine, Euclidean, KL-divergence etc. can be used to compute the similarity. Now we perform another clustering on the similarity matrix to obtain the consensus.
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Foundations of Machine Learning CentraleSupélec Fall Clustering Chloé-Agathe Azencot
 Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Motivation. Technical Background
 Handling Outliers through Agglomerative Clustering with Full Model Maximum Likelihood Estimation, with Application to Flow Cytometry Mark Gordon, Justin Li, Kevin Matzen, Bryce Wiedenbeck Motivation Clustering
Handling Outliers through Agglomerative Clustering with Full Model Maximum Likelihood Estimation, with Application to Flow Cytometry Mark Gordon, Justin Li, Kevin Matzen, Bryce Wiedenbeck Motivation Clustering
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Clustering and Dissimilarity Measures. Clustering. Dissimilarity Measures. Cluster Analysis. Perceptually-Inspired Measures
 Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Lecture 10: Semantic Segmentation and Clustering
 Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Objective of clustering
 Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
On Order-Constrained Transitive Distance
 On Order-Constrained Transitive Distance Author: Zhiding Yu and B. V. K. Vijaya Kumar, et al. Dept of Electrical and Computer Engineering Carnegie Mellon University 1 Clustering Problem Important Issues:
On Order-Constrained Transitive Distance Author: Zhiding Yu and B. V. K. Vijaya Kumar, et al. Dept of Electrical and Computer Engineering Carnegie Mellon University 1 Clustering Problem Important Issues:
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised learning on Color Images
 Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Pattern Clustering with Similarity Measures
 Pattern Clustering with Similarity Measures Akula Ratna Babu 1, Miriyala Markandeyulu 2, Bussa V R R Nagarjuna 3 1 Pursuing M.Tech(CSE), Vignan s Lara Institute of Technology and Science, Vadlamudi, Guntur,
Pattern Clustering with Similarity Measures Akula Ratna Babu 1, Miriyala Markandeyulu 2, Bussa V R R Nagarjuna 3 1 Pursuing M.Tech(CSE), Vignan s Lara Institute of Technology and Science, Vadlamudi, Guntur,
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Unsupervised Learning
 Unsupervised Learning Pierre Gaillard ENS Paris September 28, 2018 1 Supervised vs unsupervised learning Two main categories of machine learning algorithms: - Supervised learning: predict output Y from
Unsupervised Learning Pierre Gaillard ENS Paris September 28, 2018 1 Supervised vs unsupervised learning Two main categories of machine learning algorithms: - Supervised learning: predict output Y from
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering