Spring 2009 Prof. Hyesoon Kim
|
|
|
- Melanie Sharp
- 5 years ago
- Views:
Transcription


1 Spring 2009 Prof. Hyesoon Kim
2 Benchmarking is critical to make a design decision and measuring performance Performance evaluations: Design decisions Earlier time : analytical based evaluations From 90 s: heavy rely on simulations. Processor evaluations Workload characterizations: better understand the workloads
3 Benchmarks Real applications and application suites E.g., SPEC CPU2000, SPEC2006, TPC-C, TPC-H, EEMBC, MediaBench, PARSEC, SYSmark Kernels Representative parts of real applications Easier and quicker to set up and run Often not really representative of the entire app Toy programs, synthetic benchmarks, etc. Not very useful for reporting Sometimes used to test/stress specific functions/features
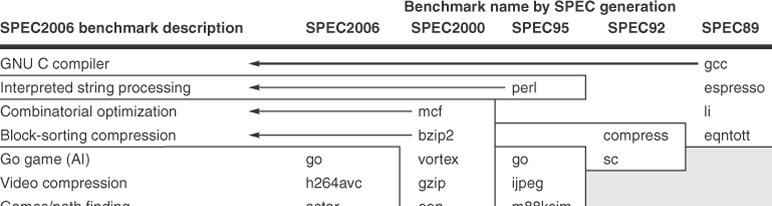

4 Representative applications keeps growing with time!
5
6 Test, train and ref Test: simple checkup Train: profile input, feedback compilation Ref: real measurement. Design to run long enough to use for real system -> Simulation? Reduced input set Statistical simulation Sampling
7 Measure transaction-processing throughput Benchmarks for different scenarios TPC-C: warehouses and sales transactions TPC-H: ad-hoc decision support TPC-W: web-based business transactions Difficult to set up and run on a simulator Requires full OS support, a working DBMS Long simulations to get stable results
8 SPLASH: Scientific computing kernels Who used parallel computers? PARSEC: More desktop oriented benchmarks NPB: NASA parallel computing benchmarks Not many
9 GFLOPS, TFLOPS MIPS (Million instructions per second)
10 Speedup of arithmeitc means!= arithmetic mean of speedup Use geometric mean: n n i=1 Normalized execution time on i Neat property of the geometric mean: Consistent whatever the reference machine Do not use the arithmetic mean for normalized execution times
11 Often when making comparisons in comparch studies: Program (or set of) is the same for two CPUs The clock speed is the same for two CPUs So we can just directly compare CPI s and often we use IPC s
12 Average CPI = (CPI 1 + CPI CPI n )/n A.M. of IPC = (IPC 1 + IPC IPC n )/n Not Equal to A.M. of CPI!!! Must use Harmonic Mean to remain to runtime
13 H.M.(x 1,x 2,x 3,,x n ) = n x 1 x 2 x 3 x n What in the world is this? Average of inverse relationships
14 Average IPC = 1 = 1 A.M.(CPI) CPI 1 + CPI 2 + CPI CPI n n n n n = n CPI 1 + CPI 2 + CPI CPI n = n = H.M.(IPC) IPC 1 IPC 2 IPC 3 IPC n
15 Stanford graphics benchmarks Simple graphics workload. Academic Mostly game applications 3DMark: kvantage Tom s hardware
16 Still graphics is the major performance bottlenecks Previous research: emphasis on graphics
17 Several genres of video games First Person Shooter Fast-paced, graphically enhanced Focus of this presentation Role-Playing Games Lower graphics and slower play Board Games Just plain boring
18 Physics Particle Event Collision Detection AI Rendering Display Computing
19 Current game design principles: higher frame rates imply the better game quality Recent study on frame rates [Claypool et al. MMCN 2006] very high frame rates are not necessary, very low frame rates impact the game quality severely


20 Snapshots of animation [Davis et al. Eurographics 2003] time
21 Game workload Computational workload Rendering workload Other workload Rasterization workload
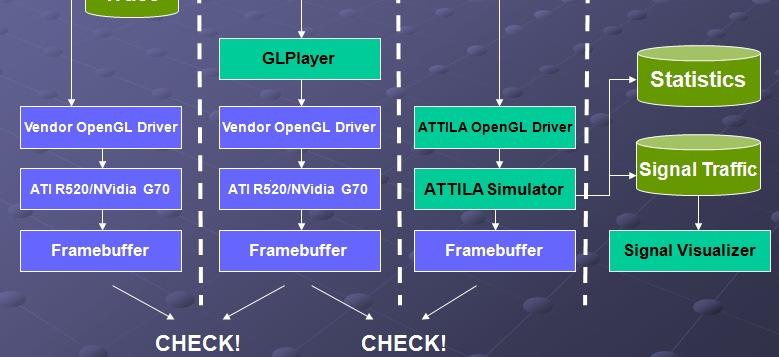
22 Case study Workload characterization of 3D games, Roca, et al. IISWC 2006 [WOR] Use ATTILA
23
24 Average primitives per frame Average vertex shader instructions Vertex cache hit ratio System bus bandwidths Percentage of clipped, culled, and traversed triangles Average trianglesizes
25 GPU execution driven simulator Can simulate OpenGL at this moments

26
27 Index Buffer Vertex cache Streamer Vertex Request Buffer Primitive Assembly Clipping Triangle Setup Fragment Generation Hierarchical Z Z Cache Z test Z Cache Z test Hierarchical Z buffer HZ Cache Register File Shader Shader Shader Shader Shader Texture Filter Texture Cache Texture Address Attila architecture Unit Size Element width Streamer 48 16x4x32 bits Primitive Assembly 8 3x16x4x32 bits Clipping 4 3x4x32 bits Triangle Setup 12 3x4x32 bits Fragment Generation 16 3x4x32 bits Hierarchical Z 64 (2x16+4x32)x4 bits Z Tests 64 (2x16+4x32)x4 bits Interpolator Color Write 64 (2x16+4x32)x4 bits Unified Shader (vertex) x4x32 bits Unified Shader (fragment) x4x32 bits Table 2. Queue sizes and number of threads in the ATTILA reference architecture Interpolator Color cache Blend Color cache Blend MC0 MC1 MC2 MC3
28 Execution driven: Correctness, long development time, Execute binary Trace driven Easy to develop Simulation time could be shorten Large trace file size
29 No simulation is required To provide insights Statistical Methods CPU First-order GPU Warp level parallelism
30 CWP=4 Case1: Memory 7 Waiting period 8 MWP=2 2 Computation + 4 Memory (a) Case2: Computation + 4 Memory (b) Idle cycles Case3 : CWP= MWP > Case4 : Computation + 1 Memory 8 Computation + 1 Memory (a) (b)
31 Case6: (1 warp) Computation + 8 Memory (a) Case7: (2 warps) 5 Computation + 4 Memory (b)
32 Hardware performance counters Built in counters (instruction count, cache misses, branch mispredicitons) Profiler Architecture simulator Characterized items Cache miss, branch misprediciton, row-buffer hit ratio
33 Top design (instruction, data flow from memory to CPU and GPU), Data/control signals CPU design Pipeline stages, SMT support, Fetch address calculation, branch misprediction, cache miss handling path Memory address calculation stage, vector processing units At least 5 MUXes, register, ALU, latches, Memory system: Load/store buffers, queues GPU Design Show at least 10 ALUs
34 One of the following items Detailed CPU pipeline design (more muxes and more adders) Detailed survey (more information from other sources) Detailed GPU pipeline design (more muxes and more adders) Detailed memory system (more queues) Detailed memory controller
35 I/O just a box Cache just one box or (tag + data) Report: explanations are required. ECC: just a box Design review: 30 min Feedback for final report
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Lecture: Benchmarks, Pipelining Intro. Topics: Performance equations wrap-up, Intro to pipelining
 Lecture: Benchmarks, Pipelining Intro Topics: Performance equations wrap-up, Intro to pipelining 1 Measuring Performance Two primary metrics: wall clock time (response time for a program) and throughput
Lecture: Benchmarks, Pipelining Intro Topics: Performance equations wrap-up, Intro to pipelining 1 Measuring Performance Two primary metrics: wall clock time (response time for a program) and throughput
ECE 486/586. Computer Architecture. Lecture # 3
 ECE 486/586 Computer Architecture Lecture # 3 Spring 2014 Portland State University Lecture Topics Measuring, Reporting and Summarizing Performance Execution Time and Throughput Benchmarks Comparing and
ECE 486/586 Computer Architecture Lecture # 3 Spring 2014 Portland State University Lecture Topics Measuring, Reporting and Summarizing Performance Execution Time and Throughput Benchmarks Comparing and
Hardware-driven Visibility Culling Jeong Hyun Kim
 Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
ECE C61 Computer Architecture Lecture 2 performance. Prof. Alok N. Choudhary.
 ECE C61 Computer Architecture Lecture 2 performance Prof Alok N Choudhary choudhar@ecenorthwesternedu 2-1 Today s s Lecture Performance Concepts Response Time Throughput Performance Evaluation Benchmarks
ECE C61 Computer Architecture Lecture 2 performance Prof Alok N Choudhary choudhar@ecenorthwesternedu 2-1 Today s s Lecture Performance Concepts Response Time Throughput Performance Evaluation Benchmarks
Optimizing for DirectX Graphics. Richard Huddy European Developer Relations Manager
 Optimizing for DirectX Graphics Richard Huddy European Developer Relations Manager Also on today from ATI... Start & End Time: 12:00pm 1:00pm Title: Precomputed Radiance Transfer and Spherical Harmonic
Optimizing for DirectX Graphics Richard Huddy European Developer Relations Manager Also on today from ATI... Start & End Time: 12:00pm 1:00pm Title: Precomputed Radiance Transfer and Spherical Harmonic
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Copyright Khronos Group, Page Graphic Remedy. All Rights Reserved
 Avi Shapira Graphic Remedy Copyright Khronos Group, 2009 - Page 1 2004 2009 Graphic Remedy. All Rights Reserved Debugging and profiling 3D applications are both hard and time consuming tasks Companies
Avi Shapira Graphic Remedy Copyright Khronos Group, 2009 - Page 1 2004 2009 Graphic Remedy. All Rights Reserved Debugging and profiling 3D applications are both hard and time consuming tasks Companies
Next-Generation Graphics on Larrabee. Tim Foley Intel Corp
 Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Spring 2010 Prof. Hyesoon Kim. AMD presentations from Richard Huddy and Michael Doggett
 Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Graphics Hardware, Graphics APIs, and Computation on GPUs. Mark Segal
 Graphics Hardware, Graphics APIs, and Computation on GPUs Mark Segal Overview Graphics Pipeline Graphics Hardware Graphics APIs ATI s low-level interface for computation on GPUs 2 Graphics Hardware High
Graphics Hardware, Graphics APIs, and Computation on GPUs Mark Segal Overview Graphics Pipeline Graphics Hardware Graphics APIs ATI s low-level interface for computation on GPUs 2 Graphics Hardware High
Optimizing DirectX Graphics. Richard Huddy European Developer Relations Manager
 Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Performance of computer systems
 Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Designing for Performance. Patrick Happ Raul Feitosa
 Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
Graphics Hardware. Instructor Stephen J. Guy
 Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Hardware-driven visibility culling
 Hardware-driven visibility culling I. Introduction 20073114 김정현 The goal of the 3D graphics is to generate a realistic and accurate 3D image. To achieve this, it needs to process not only large amount
Hardware-driven visibility culling I. Introduction 20073114 김정현 The goal of the 3D graphics is to generate a realistic and accurate 3D image. To achieve this, it needs to process not only large amount
Security-Aware Processor Architecture Design. CS 6501 Fall 2018 Ashish Venkat
 Security-Aware Processor Architecture Design CS 6501 Fall 2018 Ashish Venkat Agenda Common Processor Performance Metrics Identifying and Analyzing Bottlenecks Benchmarking and Workload Selection Performance
Security-Aware Processor Architecture Design CS 6501 Fall 2018 Ashish Venkat Agenda Common Processor Performance Metrics Identifying and Analyzing Bottlenecks Benchmarking and Workload Selection Performance
Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson
 Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson Director, Graphics Research, ARM Outline ARM and Mobile Graphics Design Constraints for Mobile GPUs Mali Architecture Overview Multicore Scaling
Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson Director, Graphics Research, ARM Outline ARM and Mobile Graphics Design Constraints for Mobile GPUs Mali Architecture Overview Multicore Scaling
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Number Representation 09212011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Logic Circuits for Register Transfer
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Number Representation 09212011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Logic Circuits for Register Transfer
Performance OpenGL Programming (for whatever reason)
") Performance OpenGL Programming (for whatever reason) Mike Bailey Oregon State University Performance Bottlenecks In general there are four places a graphics system can become bottlenecked: 1. The computer
Performance OpenGL Programming (for whatever reason) Mike Bailey Oregon State University Performance Bottlenecks In general there are four places a graphics system can become bottlenecked: 1. The computer
PERFORMANCE METRICS. Mahdi Nazm Bojnordi. CS/ECE 6810: Computer Architecture. Assistant Professor School of Computing University of Utah
 PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Sept. 5 th : Homework 1 release (due on Sept.
PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Sept. 5 th : Homework 1 release (due on Sept.
Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary
![Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary](/thumbs/95/124913402.jpg "Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary") Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
PowerVR Series5. Architecture Guide for Developers
 Public Imagination Technologies PowerVR Series5 Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Series5 Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Architectures. Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1
 Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
CS451Real-time Rendering Pipeline
 1 CS451Real-time Rendering Pipeline JYH-MING LIEN DEPARTMENT OF COMPUTER SCIENCE GEORGE MASON UNIVERSITY Based on Tomas Akenine-Möller s lecture note You say that you render a 3D 2 scene, but what does
1 CS451Real-time Rendering Pipeline JYH-MING LIEN DEPARTMENT OF COMPUTER SCIENCE GEORGE MASON UNIVERSITY Based on Tomas Akenine-Möller s lecture note You say that you render a 3D 2 scene, but what does
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
GeForce4. John Montrym Henry Moreton
 GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
A Bandwidth Effective Rendering Scheme for 3D Texture-based Volume Visualization on GPU
 for 3D Texture-based Volume Visualization on GPU Won-Jong Lee, Tack-Don Han Media System Laboratory (http://msl.yonsei.ac.k) Dept. of Computer Science, Yonsei University, Seoul, Korea Contents Background
for 3D Texture-based Volume Visualization on GPU Won-Jong Lee, Tack-Don Han Media System Laboratory (http://msl.yonsei.ac.k) Dept. of Computer Science, Yonsei University, Seoul, Korea Contents Background
1.2.3 The Graphics Hardware Pipeline
 Figure 1-3. The Graphics Hardware Pipeline 1.2.3 The Graphics Hardware Pipeline A pipeline is a sequence of stages operating in parallel and in a fixed order. Each stage receives its input from the prior
Figure 1-3. The Graphics Hardware Pipeline 1.2.3 The Graphics Hardware Pipeline A pipeline is a sequence of stages operating in parallel and in a fixed order. Each stage receives its input from the prior
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
A MATLAB Interface to the GPU
 Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 11 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 11 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should
Chapter 1. Instructor: Josep Torrellas CS433. Copyright Josep Torrellas 1999, 2001, 2002,
 Chapter 1 Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Course Goals Introduce you to design principles, analysis techniques and design options in computer architecture
Chapter 1 Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Course Goals Introduce you to design principles, analysis techniques and design options in computer architecture
A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization
 A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization Jordi Roca Victor Moya Carlos Gonzalez Vicente Escandell Albert Murciego Agustin Fernandez, Computer Architecture
A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization Jordi Roca Victor Moya Carlos Gonzalez Vicente Escandell Albert Murciego Agustin Fernandez, Computer Architecture
Optimisation. CS7GV3 Real-time Rendering
 Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
The Bifrost GPU architecture and the ARM Mali-G71 GPU
 The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
Building scalable 3D applications. Ville Miettinen Hybrid Graphics
 Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
Real - Time Rendering. Pipeline optimization. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Pipeline optimization Michal Červeňanský Juraj Starinský Motivation Resolution 1600x1200, at 60 fps Hw power not enough Acceleration is still necessary 3.3.2010 2 Overview Application
Real - Time Rendering Pipeline optimization Michal Červeňanský Juraj Starinský Motivation Resolution 1600x1200, at 60 fps Hw power not enough Acceleration is still necessary 3.3.2010 2 Overview Application
Performance COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
CS230 : Computer Graphics Lecture 4. Tamar Shinar Computer Science & Engineering UC Riverside
 CS230 : Computer Graphics Lecture 4 Tamar Shinar Computer Science & Engineering UC Riverside Shadows Shadows for each pixel do compute viewing ray if ( ray hits an object with t in [0, inf] ) then compute
CS230 : Computer Graphics Lecture 4 Tamar Shinar Computer Science & Engineering UC Riverside Shadows Shadows for each pixel do compute viewing ray if ( ray hits an object with t in [0, inf] ) then compute
The Role of Performance
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
This Unit. CIS 501 Computer Architecture. As You Get Settled. Readings. Metrics Latency and throughput. Reporting performance
 This Unit CIS 501 Computer Architecture Metrics Latency and throughput Reporting performance Benchmarking and averaging Unit 2: Performance Performance analysis & pitfalls Slides developed by Milo Martin
This Unit CIS 501 Computer Architecture Metrics Latency and throughput Reporting performance Benchmarking and averaging Unit 2: Performance Performance analysis & pitfalls Slides developed by Milo Martin
Lecture 2. Shaders, GLSL and GPGPU
 Lecture 2 Shaders, GLSL and GPGPU Is it interesting to do GPU computing with graphics APIs today? Lecture overview Why care about shaders for computing? Shaders for graphics GLSL Computing with shaders
Lecture 2 Shaders, GLSL and GPGPU Is it interesting to do GPU computing with graphics APIs today? Lecture overview Why care about shaders for computing? Shaders for graphics GLSL Computing with shaders
CS130 : Computer Graphics. Tamar Shinar Computer Science & Engineering UC Riverside
 CS130 : Computer Graphics Tamar Shinar Computer Science & Engineering UC Riverside Raster Devices and Images Raster Devices Hearn, Baker, Carithers Raster Display Transmissive vs. Emissive Display anode
CS130 : Computer Graphics Tamar Shinar Computer Science & Engineering UC Riverside Raster Devices and Images Raster Devices Hearn, Baker, Carithers Raster Display Transmissive vs. Emissive Display anode
EE 4702 GPU Programming
 fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
X. GPU Programming. Jacobs University Visualization and Computer Graphics Lab : Advanced Graphics - Chapter X 1
 X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
General Purpose Computation (CAD/CAM/CAE) on the GPU (a.k.a. Topics in Manufacturing)
 on the GPU (a.k.a. Topics in Manufacturing)") ME 290-R: General Purpose Computation (CAD/CAM/CAE) on the GPU (a.k.a. Topics in Manufacturing) Sara McMains Spring 2009 Performance: Bottlenecks Sources of bottlenecks CPU Transfer Processing Rasterizer
ME 290-R: General Purpose Computation (CAD/CAM/CAE) on the GPU (a.k.a. Topics in Manufacturing) Sara McMains Spring 2009 Performance: Bottlenecks Sources of bottlenecks CPU Transfer Processing Rasterizer
The Application Stage. The Game Loop, Resource Management and Renderer Design
 1 The Application Stage The Game Loop, Resource Management and Renderer Design Application Stage Responsibilities 2 Set up the rendering pipeline Resource Management 3D meshes Textures etc. Prepare data
1 The Application Stage The Game Loop, Resource Management and Renderer Design Application Stage Responsibilities 2 Set up the rendering pipeline Resource Management 3D meshes Textures etc. Prepare data
Comparing Reyes and OpenGL on a Stream Architecture
 Comparing Reyes and OpenGL on a Stream Architecture John D. Owens Brucek Khailany Brian Towles William J. Dally Computer Systems Laboratory Stanford University Motivation Frame from Quake III Arena id
Comparing Reyes and OpenGL on a Stream Architecture John D. Owens Brucek Khailany Brian Towles William J. Dally Computer Systems Laboratory Stanford University Motivation Frame from Quake III Arena id
UberFlow: A GPU-Based Particle Engine
 UberFlow: A GPU-Based Particle Engine Peter Kipfer Mark Segal Rüdiger Westermann Technische Universität München ATI Research Technische Universität München Motivation Want to create, modify and render
UberFlow: A GPU-Based Particle Engine Peter Kipfer Mark Segal Rüdiger Westermann Technische Universität München ATI Research Technische Universität München Motivation Want to create, modify and render
MEASURING COMPUTER TIME. A computer faster than another? Necessity of evaluation computer performance
 Necessity of evaluation computer performance MEASURING COMPUTER PERFORMANCE For comparing different computer performances User: Interested in reducing the execution time (response time) of a task. Computer
Necessity of evaluation computer performance MEASURING COMPUTER PERFORMANCE For comparing different computer performances User: Interested in reducing the execution time (response time) of a task. Computer
Rendering Objects. Need to transform all geometry then
 Intro to OpenGL Rendering Objects Object has internal geometry (Model) Object relative to other objects (World) Object relative to camera (View) Object relative to screen (Projection) Need to transform
Intro to OpenGL Rendering Objects Object has internal geometry (Model) Object relative to other objects (World) Object relative to camera (View) Object relative to screen (Projection) Need to transform
EECS 487: Interactive Computer Graphics
 EECS 487: Interactive Computer Graphics Lecture 21: Overview of Low-level Graphics API Metal, Direct3D 12, Vulkan Console Games Why do games look and perform so much better on consoles than on PCs with
EECS 487: Interactive Computer Graphics Lecture 21: Overview of Low-level Graphics API Metal, Direct3D 12, Vulkan Console Games Why do games look and perform so much better on consoles than on PCs with
GPGPU introduction and network applications. PacketShaders, SSLShader
 GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
Computer Architecture CS372 Exam 3
 Name: Computer Architecture CS372 Exam 3 This exam has 7 pages. Please make sure you have all of them. Write your name on this page and initials on every other page now. You may only use the green card
Name: Computer Architecture CS372 Exam 3 This exam has 7 pages. Please make sure you have all of them. Write your name on this page and initials on every other page now. You may only use the green card
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Working with Metal Overview
 Graphics and Games #WWDC14 Working with Metal Overview Session 603 Jeremy Sandmel GPU Software 2014 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission
Graphics and Games #WWDC14 Working with Metal Overview Session 603 Jeremy Sandmel GPU Software 2014 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission
Graphics Architectures and OpenCL. Michael Doggett Department of Computer Science Lund university
 Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Programming on Larrabee. Tim Foley Intel Corp
 Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Computer Architecture
 Computer Architecture Architecture The art and science of designing and constructing buildings A style and method of design and construction Design, the way components fit together Computer Architecture
Computer Architecture Architecture The art and science of designing and constructing buildings A style and method of design and construction Design, the way components fit together Computer Architecture
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
2.11 Particle Systems
 2.11 Particle Systems 320491: Advanced Graphics - Chapter 2 152 Particle Systems Lagrangian method not mesh-based set of particles to model time-dependent phenomena such as snow fire smoke 320491: Advanced
2.11 Particle Systems 320491: Advanced Graphics - Chapter 2 152 Particle Systems Lagrangian method not mesh-based set of particles to model time-dependent phenomena such as snow fire smoke 320491: Advanced
Lecture - 4. Measurement. Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1
 Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
Introduction to Parallel Programming Models
 Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
1.3 Data processing; data storage; data movement; and control.
 CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques
 Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques Jonathan Zarge, Team Lead Performance Tools Richard Huddy, European Developer Relations Manager ATI
Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques Jonathan Zarge, Team Lead Performance Tools Richard Huddy, European Developer Relations Manager ATI
CSE 141 Summer 2016 Homework 2
 CSE 141 Summer 2016 Homework 2 PID: Name: 1. A matrix multiplication program can spend 10% of its execution time in reading inputs from a disk, 10% of its execution time in parsing and creating arrays
CSE 141 Summer 2016 Homework 2 PID: Name: 1. A matrix multiplication program can spend 10% of its execution time in reading inputs from a disk, 10% of its execution time in parsing and creating arrays
Write only as much as necessary. Be brief!
 1 CIS371 Computer Organization and Design Midterm Exam Prof. Martin Thursday, March 15th, 2012 This exam is an individual-work exam. Write your answers on these pages. Additional pages may be attached
1 CIS371 Computer Organization and Design Midterm Exam Prof. Martin Thursday, March 15th, 2012 This exam is an individual-work exam. Write your answers on these pages. Additional pages may be attached
Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]
![Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]](/thumbs/93/113797768.jpg "Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]") Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Mattan Erez. The University of Texas at Austin
 EE382V: Principles in Computer Architecture Parallelism and Locality Fall 2008 Lecture 10 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should we
EE382V: Principles in Computer Architecture Parallelism and Locality Fall 2008 Lecture 10 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should we
The NVIDIA GeForce 8800 GPU
 The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
Real - Time Rendering. Graphics pipeline. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Overview. Technology Details. D/AVE NX Preliminary Product Brief
 Overview D/AVE NX is the latest and most powerful addition to the D/AVE family of rendering cores. It is the first IP to bring full OpenGL ES 2.0/3.1 rendering to the FPGA and SoC world. Targeted for graphics
Overview D/AVE NX is the latest and most powerful addition to the D/AVE family of rendering cores. It is the first IP to bring full OpenGL ES 2.0/3.1 rendering to the FPGA and SoC world. Targeted for graphics
Real-World Applications of Computer Arithmetic
 1 Commercial Applications Real-World Applications of Computer Arithmetic Stuart Oberman General purpose microprocessors with high performance FPUs AMD Athlon Intel P4 Intel Itanium Application specific
1 Commercial Applications Real-World Applications of Computer Arithmetic Stuart Oberman General purpose microprocessors with high performance FPUs AMD Athlon Intel P4 Intel Itanium Application specific
Performance, Power, Die Yield. CS301 Prof Szajda
 Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
GeForce3 OpenGL Performance. John Spitzer
 GeForce3 OpenGL Performance John Spitzer GeForce3 OpenGL Performance John Spitzer Manager, OpenGL Applications Engineering jspitzer@nvidia.com Possible Performance Bottlenecks They mirror the OpenGL pipeline
GeForce3 OpenGL Performance John Spitzer GeForce3 OpenGL Performance John Spitzer Manager, OpenGL Applications Engineering jspitzer@nvidia.com Possible Performance Bottlenecks They mirror the OpenGL pipeline
CS 428: Fall Introduction to. OpenGL primer. Andrew Nealen, Rutgers, /13/2010 1
 CS 428: Fall 2010 Introduction to Computer Graphics OpenGL primer Andrew Nealen, Rutgers, 2010 9/13/2010 1 Graphics hardware Programmable {vertex, geometry, pixel} shaders Powerful GeForce 285 GTX GeForce480
CS 428: Fall 2010 Introduction to Computer Graphics OpenGL primer Andrew Nealen, Rutgers, 2010 9/13/2010 1 Graphics hardware Programmable {vertex, geometry, pixel} shaders Powerful GeForce 285 GTX GeForce480
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
GPU Computation Strategies & Tricks. Ian Buck NVIDIA
 GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
CS 341l Fall 2008 Test #2
 CS 341l all 2008 Test #2 Name: Key CS 341l, test #2. 100 points total, number of points each question is worth is indicated in parentheses. Answer all questions. Be as concise as possible while still answering
CS 341l all 2008 Test #2 Name: Key CS 341l, test #2. 100 points total, number of points each question is worth is indicated in parentheses. Answer all questions. Be as concise as possible while still answering