Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
|
|
|
- Kerry Gilbert Franklin
- 5 years ago
- Views:
Transcription

1 Michael Doggett Graphics Architecture Group April 2, 2008
2 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated Computing 2


3 ATI WhiteOut Demo [2007] Architecture 3
4 Chip Design Focus Point CPU Lots of instructions little data Out of order exec Branch prediction Reuse and locality Task parallel Needs OS Complex sync Latency machines GPU Few instructions lots of data SIMD Hardware threading Little reuse Data parallel No OS Simple sync Throughput machines 4
5 Typical CPU Operation One iteration at a time Single CPU unit Cannot reach 100% Hard to prefetch data Multi-core does not help Cluster does not help Limited number of outstanding fetches Wait for memory, gaps prevent peak performance Gap size varies dynamically Hard to tolerate latency 5
6 GPU THREADS (Lower Clock Different Scale) Overlapped fetch and alu Many outstanding fetches ALU units reach 100% utilization Hardware sync for final Output Lots of threads Fetch unit + ALU unit Fast thread switch In-order finish 6
7 RADEON 2900 Top Level Red Compute/ Fixed Function Yellow Cache Unified shader Shader R/W Cache Instr./Const. cache Unified texture cache Compression Tessellator Hierarchical Z Z/Stencil Cache Stream Out Memory Read/Write Cache Rasterizer Interpolators Command Processor Vertex Index Fetch Setup Unit Tessellator Geometry Vertex Assembler Assembler Ultra-Threaded Dispatch Processor Unified Shader Processors Shader Export Texture Units Shader Caches Instruction & Constant L1 Texture Cache L2 Texture Cache Render Back-Ends Color Cache 7
8 Ultra-Threaded Dispatch Processor/ Scheduler Main control for the shader core All workloads have threads of 64 elements 100 s of threads in flight Threads are put to sleep when they request a slow responding resource Arbitration policy Age/Need/Availability When in doubt favor pixels Programmable Hiera Stream O Interpolators Geometry Vertex Assembler Assembler Ultra-Threaded Dispatch Processor Caches ction & stant che L 8
9 Ultra-Threaded Dispatch Processor Setup Engine Arbiter Sequencer Sequencer Interpolators Vertex Shader Command Queue Geometry Shader Command Queue PIxel Shader Command Queue VS Thread 3 VS Thread 2 VS Thread 1 GS Thread 2 GS Thread 1 Arbiter Arbiter Arbiter Sequencer Sequencer Arbiter Sequencer Sequencer PS PS PS PS Arbiter Arbiter Sequencer Sequencer Thread Thread Thread Thread Texture Fetch Arbiter Vertex Fetch Arbiter Texture Fetch Sequencer Vertex Fetch Sequencer Instructions and Control SIMD Array SIMD Array 80 Stream Processing Units 80 Stream Processing Units 80 Stream Processing Units 80 Stream Processing Units Vertex / Texture Cache SIMD Array Vertex / Texture Units 9 SIMD Array Shader Constant Cache Arbiter Geometry Assembler Shader Instruction Cache UltraUltra-Threaded Dispatch Processor Vertex Assembler
10 Shader Core 4 parallel SIMD units Each unit receives independent ALU instruction Very Long Instruction Word (VLIW) ALU Instruction (1 to 7 64-bit words) 5 scalar ops 64 bits for src/dst/cntrls/op 2 additional for literal constant(s) 10

11 Stream Processing Units 5 Scalar Units Each scalar unit does FP Multiply- Add (MAD) and integer operations One also handles transcendental instructions IEEE 32-bit floating point precision Branch Execution Unit Flow control instructions Up to 6 operations co-issued General Purpose Registers Branch Execution Unit 11


12 Programming 12
13 Programming model Vertex and pixel kernels (shaders) Parallel loops are implicit Performance aware code does not know how many cores or how many threads All sorts of queues maintained under covers All kinds of sync done implicitly Programs are very small 13
14 Parallelism Model All parallel operations are hidden via domain specific API calls Developers write sequential code + kernels Kernel operate on one vertex or pixel Developers never deal with parallelism directly No need for auto parallel compilers 14
15 Ruby Demo Series Four versions each done by experts to show of features of the chip as well as develop novel forward-looking graphics techniques First 3 written in DirectX9, fourth in DirectX10 15
16 DX Pixel Shader Length 4 Triangles in 1000 demo version d1 d2 d3 d4 1 Num Pixel Shaders demo 1 = 140 demo 2 = 163 demo 3 = 312 demo 4 = shader size 16

17 AMD Stream Computing 17
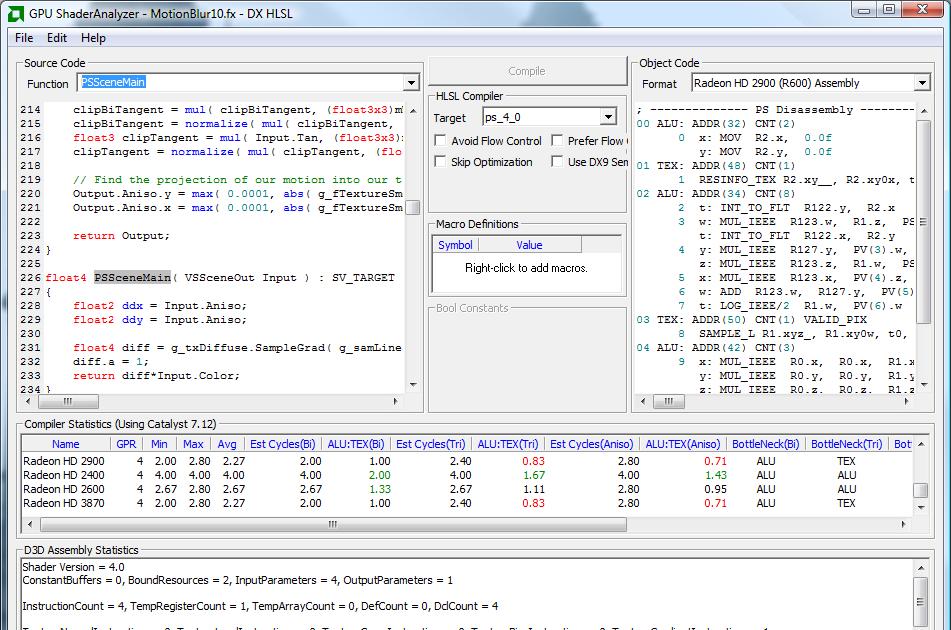
18 GPU ShaderAnalyzer 18



19 Architecture Challenges 19
20 GPU Directions Continued improvement and evolution in Graphics RADEON 2900 Tessellator Continued conversion/removal of fixed function Which fixed function? Increasing importance of GPU as an accelerator Generalization of GPU architecture More aggressive GPU thread scheduler Shader read-only via texture, write-only via color exports Need new GPU shader architectures to meet much wider requirements Already has a range of requirements across Graphics and Compute 20
21 Accelerated Computing 21
22 The Accelerated Computing Imperative Homogeneous multi-core becomes increasingly inadequate Targeted special purpose HW solutions can offer substantially better power efficiency and throughput than traditional microprocessors when operating on some of these new data types. Power constraints will force applications to be performance heterogeneous Applications can target the HW device to get this power benefit GPUs - high power efficiency, more than 2 GFLOPs/watt 20x > than dual-core CPU 22
23 AMD's Accelerated Computing Initiative Discrete CPUs + GPUs Full Integration - Fusion - Mutli-core CPU + GPU Accelerator Compatibility will continue to be a key enabler in our industry Need SW for new HW How should existing Compute APIs evolve? Do we need new API models? GPU parallelism is so successful because graphics APIs are sequential New APIs can t tie down GPU progress Need to replicate success of DX, need IHV input Can only use GPGPU APIs when performance is necessary and programmer understands machine Layers of computation Compilers that can target workloads at appropriate processors 23
24 Future GPU/Accelerated Computing Applications Which applications benefit from combined CPU+GPU and how? What type of architectural workload coupling between CPU+GPU do these applications require? What are the new data and communication requirements? What are the costs to existing performance to broaden what we do well? 24












25 Form Factors for Accelerated Computing Notebook Embedded space has already embraced heterogeneous computing models Desktop Home Media Server Game console Home Cinema HDTV UMPC Digital STB/PVR Handset OCUR 25
26 Accelerated Computing GPGPU APIs enable offloading compute to GPUs Without heroic programming efforts API compatibility enables Hardware innovation without new SW Improving performance on new HW without existing apps Broad range of possible accelerator designs We need both CPUs and GPUs Amdahl's law 26
27 Lots of Challenges Managing context state and exceptions This includes the program-visible state in the compute offload engine! Virtualizing the context state Communications/Messaging Simplified & fabric independent producer-consumer model Optimized communications is a key enabler It s the synchronization, stupid Memory BW and Data Movement Keeping up with the computation rates will require increasingly capable memory systems New and appropriate APIs Must offer a programming model that is actually easier than today s multi-core models Use abstraction to trade some performance for programmer productivity Live within bounds set by OS and Concurrent Runtimes 27

28 Processor World Map CPU GPU MPP HC 28
29 Questions? Internships ATI Fellowships Michael.doggett at amd.com 29
30 References Issues and Challenges in Compiling for Graphics Processors, Norm Rubin, Code Generation and Optimization 8 April, 2008 The Role of Accelerated Computing in the Multi-Core Era, Chuck Moore, March
Spring 2010 Prof. Hyesoon Kim. AMD presentations from Richard Huddy and Michael Doggett
 Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
AMD Radeon HD 2900 Highlights
 C O N F I D E N T I A L 2007 Hot Chips 19 AMD s Radeon HD 2900 2 nd Generation Unified Shader Architecture Mike Mantor Fellow AMD Graphics Products Group michael.mantor@amd.com AMD Radeon HD 2900 Highlights
C O N F I D E N T I A L 2007 Hot Chips 19 AMD s Radeon HD 2900 2 nd Generation Unified Shader Architecture Mike Mantor Fellow AMD Graphics Products Group michael.mantor@amd.com AMD Radeon HD 2900 Highlights
Architectures. Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1
 Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Real - Time Rendering. Graphics pipeline. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Anatomy of AMD s TeraScale Graphics Engine
 Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
Optimizing DirectX Graphics. Richard Huddy European Developer Relations Manager
 Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Graphics Architectures and OpenCL. Michael Doggett Department of Computer Science Lund university
 Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Optimizing for DirectX Graphics. Richard Huddy European Developer Relations Manager
 Optimizing for DirectX Graphics Richard Huddy European Developer Relations Manager Also on today from ATI... Start & End Time: 12:00pm 1:00pm Title: Precomputed Radiance Transfer and Spherical Harmonic
Optimizing for DirectX Graphics Richard Huddy European Developer Relations Manager Also on today from ATI... Start & End Time: 12:00pm 1:00pm Title: Precomputed Radiance Transfer and Spherical Harmonic
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
From Shader Code to a Teraflop: How GPU Shader Cores Work. Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian)
") From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Parallel Programming on Larrabee. Tim Foley Intel Corp
 Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
The Ultimate Developers Toolkit. Jonathan Zarge Dan Ginsburg
 The Ultimate Developers Toolkit Jonathan Zarge Dan Ginsburg February 20, 2008 Agenda GPU PerfStudio GPU ShaderAnalyzer RenderMonkey Additional Tools Tootle GPU MeshMapper CubeMapGen The Compressonator
The Ultimate Developers Toolkit Jonathan Zarge Dan Ginsburg February 20, 2008 Agenda GPU PerfStudio GPU ShaderAnalyzer RenderMonkey Additional Tools Tootle GPU MeshMapper CubeMapGen The Compressonator
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Lecture 7: The Programmable GPU Core. Kayvon Fatahalian CMU : Graphics and Imaging Architectures (Fall 2011)
") Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Project3 Cache Race Games night Monday, May 4 th, 5pm Come, eat, drink, have fun and be merry! Location: B17 Upson Hall
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Project3 Cache Race Games night Monday, May 4 th, 5pm Come, eat, drink, have fun and be merry! Location: B17 Upson Hall
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization
 A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization Jordi Roca Victor Moya Carlos Gonzalez Vicente Escandell Albert Murciego Agustin Fernandez, Computer Architecture
A SIMD-efficient 14 Instruction Shader Program for High-Throughput Microtriangle Rasterization Jordi Roca Victor Moya Carlos Gonzalez Vicente Escandell Albert Murciego Agustin Fernandez, Computer Architecture
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
ASYNCHRONOUS SHADERS WHITE PAPER 0
 ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
ASYNCHRONOUS SHADERS WHITE PAPER 0 INTRODUCTION GPU technology is constantly evolving to deliver more performance with lower cost and lower power consumption. Transistor scaling and Moore s Law have helped
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
HPG 2011 HIGH PERFORMANCE GRAPHICS HOT 3D
 HPG 2011 HIGH PERFORMANCE GRAPHICS HOT 3D AMD GRAPHIC CORE NEXT Low Power High Performance Graphics & Parallel Compute Michael Mantor AMD Senior Fellow Architect Michael.mantor@amd.com Mike Houston AMD
HPG 2011 HIGH PERFORMANCE GRAPHICS HOT 3D AMD GRAPHIC CORE NEXT Low Power High Performance Graphics & Parallel Compute Michael Mantor AMD Senior Fellow Architect Michael.mantor@amd.com Mike Houston AMD
Building scalable 3D applications. Ville Miettinen Hybrid Graphics
 Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
Graphics Hardware, Graphics APIs, and Computation on GPUs. Mark Segal
 Graphics Hardware, Graphics APIs, and Computation on GPUs Mark Segal Overview Graphics Pipeline Graphics Hardware Graphics APIs ATI s low-level interface for computation on GPUs 2 Graphics Hardware High
Graphics Hardware, Graphics APIs, and Computation on GPUs Mark Segal Overview Graphics Pipeline Graphics Hardware Graphics APIs ATI s low-level interface for computation on GPUs 2 Graphics Hardware High
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Breaking Down Barriers: An Intro to GPU Synchronization. Matt Pettineo Lead Engine Programmer Ready At Dawn Studios
 Breaking Down Barriers: An Intro to GPU Synchronization Matt Pettineo Lead Engine Programmer Ready At Dawn Studios Who am I? Ready At Dawn for 9 years Lead Engine Programmer for 5 I like GPUs and APIs!
Breaking Down Barriers: An Intro to GPU Synchronization Matt Pettineo Lead Engine Programmer Ready At Dawn Studios Who am I? Ready At Dawn for 9 years Lead Engine Programmer for 5 I like GPUs and APIs!
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
General Purpose GPU Programming. Advanced Operating Systems Tutorial 9
 General Purpose GPU Programming Advanced Operating Systems Tutorial 9 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
General Purpose GPU Programming Advanced Operating Systems Tutorial 9 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
CLICK TO EDIT MASTER TITLE STYLE. Click to edit Master text styles. Second level Third level Fourth level Fifth level
 CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
Bifrost - The GPU architecture for next five billion
 Bifrost - The GPU architecture for next five billion Hessed Choi Senior FAE / ARM ARM Tech Forum June 28 th, 2016 Vulkan 2 ARM 2016 What is Vulkan? A 3D graphics API for the next twenty years Logical successor
Bifrost - The GPU architecture for next five billion Hessed Choi Senior FAE / ARM ARM Tech Forum June 28 th, 2016 Vulkan 2 ARM 2016 What is Vulkan? A 3D graphics API for the next twenty years Logical successor
Graphics Hardware 2008
 AMD Smarter Choice Graphics Hardware 2008 Mike Mantor AMD Fellow Architect michael.mantor@amd.com GPUs vs. Multi-core CPUs On a Converging Course or Fundamentally Different? Many Cores Disruptive Change
AMD Smarter Choice Graphics Hardware 2008 Mike Mantor AMD Fellow Architect michael.mantor@amd.com GPUs vs. Multi-core CPUs On a Converging Course or Fundamentally Different? Many Cores Disruptive Change
From Shader Code to a Teraflop: How Shader Cores Work
 From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
Spring 2010 Prof. Hyesoon Kim. Xbox 360 System Architecture, Anderews, Baker
 Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
Today s Agenda. DirectX 9 Features Sim Dietrich, nvidia - Multisample antialising Jason Mitchell, ATI - Shader models and coding tips
 Today s Agenda DirectX 9 Features Sim Dietrich, nvidia - Multisample antialising Jason Mitchell, ATI - Shader models and coding tips Optimization for DirectX 9 Graphics Mike Burrows, Microsoft - Performance
Today s Agenda DirectX 9 Features Sim Dietrich, nvidia - Multisample antialising Jason Mitchell, ATI - Shader models and coding tips Optimization for DirectX 9 Graphics Mike Burrows, Microsoft - Performance
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Copyright Khronos Group Page 1
 Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Graphics Hardware. Instructor Stephen J. Guy
 Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
Original PlayStation: no vector processing or floating point support. Photorealism at the core of design strategy
 Competitors using generic parts Performance benefits to be had for custom design Original PlayStation: no vector processing or floating point support Geometry issues Photorealism at the core of design
Competitors using generic parts Performance benefits to be had for custom design Original PlayStation: no vector processing or floating point support Geometry issues Photorealism at the core of design
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
The NVIDIA GeForce 8800 GPU
 The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
Could you make the XNA functions yourself?
 1 Could you make the XNA functions yourself? For the second and especially the third assignment, you need to globally understand what s going on inside the graphics hardware. You will write shaders, which
1 Could you make the XNA functions yourself? For the second and especially the third assignment, you need to globally understand what s going on inside the graphics hardware. You will write shaders, which
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Parallel Programming for Graphics
 Beyond Programmable Shading Course ACM SIGGRAPH 2010 Parallel Programming for Graphics Aaron Lefohn Advanced Rendering Technology (ART) Intel What s In This Talk? Overview of parallel programming models
Beyond Programmable Shading Course ACM SIGGRAPH 2010 Parallel Programming for Graphics Aaron Lefohn Advanced Rendering Technology (ART) Intel What s In This Talk? Overview of parallel programming models
THE PROGRAMMER S GUIDE TO THE APU GALAXY. Phil Rogers, Corporate Fellow AMD
 THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
The Bifrost GPU architecture and the ARM Mali-G71 GPU
 The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
General Purpose GPU Programming. Advanced Operating Systems Tutorial 7
 General Purpose GPU Programming Advanced Operating Systems Tutorial 7 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
General Purpose GPU Programming Advanced Operating Systems Tutorial 7 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
Hardware-driven Visibility Culling Jeong Hyun Kim
 Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
GeForce4. John Montrym Henry Moreton
 GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
Graphics and Imaging Architectures
 Graphics and Imaging Architectures Kayvon Fatahalian http://www.cs.cmu.edu/afs/cs/academic/class/15869-f11/www/ About Kayvon New faculty, just arrived from Stanford Dissertation: Evolving real-time graphics
Graphics and Imaging Architectures Kayvon Fatahalian http://www.cs.cmu.edu/afs/cs/academic/class/15869-f11/www/ About Kayvon New faculty, just arrived from Stanford Dissertation: Evolving real-time graphics
GPU Computation Strategies & Tricks. Ian Buck NVIDIA
 GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
GPU Computation Strategies & Tricks Ian Buck NVIDIA Recent Trends 2 Compute is Cheap parallelism to keep 100s of ALUs per chip busy shading is highly parallel millions of fragments per frame 0.5mm 64-bit
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania
 OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
Day: Thursday, 03/19 Time: 16:00-16:50 Location: Room 212A Level: Intermediate Type: Talk Tags: Developer - Tools & Libraries; Game Development
 1 Day: Thursday, 03/19 Time: 16:00-16:50 Location: Room 212A Level: Intermediate Type: Talk Tags: Developer - Tools & Libraries; Game Development 2 3 Talk about just some of the features of DX12 that are
1 Day: Thursday, 03/19 Time: 16:00-16:50 Location: Room 212A Level: Intermediate Type: Talk Tags: Developer - Tools & Libraries; Game Development 2 3 Talk about just some of the features of DX12 that are
Pat Hanrahan. Modern Graphics Pipeline. How Powerful are GPUs? Application. Command. Geometry. Rasterization. Fragment. Display.
 How Powerful are GPUs? Pat Hanrahan Computer Science Department Stanford University Computer Forum 2007 Modern Graphics Pipeline Application Command Geometry Rasterization Texture Fragment Display Page
How Powerful are GPUs? Pat Hanrahan Computer Science Department Stanford University Computer Forum 2007 Modern Graphics Pipeline Application Command Geometry Rasterization Texture Fragment Display Page
Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques
 Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques Jonathan Zarge, Team Lead Performance Tools Richard Huddy, European Developer Relations Manager ATI
Squeezing Performance out of your Game with ATI Developer Performance Tools and Optimization Techniques Jonathan Zarge, Team Lead Performance Tools Richard Huddy, European Developer Relations Manager ATI
GPU A rchitectures Architectures Patrick Neill May
 GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
GPGPU COMPUTE ON AMD. Udeepta Bordoloi April 6, 2011
 GPGPU COMPUTE ON AMD Udeepta Bordoloi April 6, 2011 WHY USE GPU COMPUTE CPU: scalar processing + Latency + Optimized for sequential and branching algorithms + Runs existing applications very well - Throughput
GPGPU COMPUTE ON AMD Udeepta Bordoloi April 6, 2011 WHY USE GPU COMPUTE CPU: scalar processing + Latency + Optimized for sequential and branching algorithms + Runs existing applications very well - Throughput
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Introduction to Parallel Programming Models
 Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Efficient and Scalable Shading for Many Lights
 Efficient and Scalable Shading for Many Lights 1. GPU Overview 2. Shading recap 3. Forward Shading 4. Deferred Shading 5. Tiled Deferred Shading 6. And more! First GPU Shaders Unified Shaders CUDA OpenCL
Efficient and Scalable Shading for Many Lights 1. GPU Overview 2. Shading recap 3. Forward Shading 4. Deferred Shading 5. Tiled Deferred Shading 6. And more! First GPU Shaders Unified Shaders CUDA OpenCL
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
GPGPU. Peter Laurens 1st-year PhD Student, NSC
 GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
GPU Architecture. Robert Strzodka (MPII), Dominik Göddeke G. TUDo), Dominik Behr (AMD)
, Dominik Göddeke G. TUDo), Dominik Behr (AMD)") GPU Architecture Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
GPU Architecture Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
NVIDIA Fermi Architecture
 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Parallelism and Concurrency. COS 326 David Walker Princeton University
 Parallelism and Concurrency COS 326 David Walker Princeton University Parallelism What is it? Today's technology trends. How can we take advantage of it? Why is it so much harder to program? Some preliminary
Parallelism and Concurrency COS 326 David Walker Princeton University Parallelism What is it? Today's technology trends. How can we take advantage of it? Why is it so much harder to program? Some preliminary
High Performance Graphics 2010
 High Performance Graphics 2010 1 Agenda Radeon 5xxx Product Family Highlights Radeon 5870 vs. 4870 Radeon 5870 Top-Level Radeon 5870 Shader Core References / Links / Screenshots Questions? 2 ATI Radeon
High Performance Graphics 2010 1 Agenda Radeon 5xxx Product Family Highlights Radeon 5870 vs. 4870 Radeon 5870 Top-Level Radeon 5870 Shader Core References / Links / Screenshots Questions? 2 ATI Radeon